
Generalized Accelerated Failure Time Models for Recurrent Events


1
The Institute of Statistics and Big Data, Renmin University of China, Beijing 100872, China
2
School of Mathematics, Yunnan Normal University, Kunming 650092, China
*
Author to whom correspondence should be addressed.
Mathematics 2022, 10(15), 2662; https://doi.org/10.3390/math10152662
Submission received: 29 June 2022
/
Revised: 22 July 2022
/
Accepted: 25 July 2022
/
Published: 28 July 2022
(This article belongs to the Special Issue Recent Advances in Computational Statistics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:For analyzing recurrent event data, we consider a generalization of the classical accelerated failure time model. In the proposed approach, the general function is no longer assumed to be a singleton but allowed to be time-varying. This is in the same spirit as in quantile regression and the counting process techniques can be utilized. Theoretical properties such as consistency and asymptotic normality are obtained. The illustration of the methodology using simulation studies and then the application to the bladder cancer data is also given.
Keywords:
accelerated failure time model; censored quantile regression; counting processes; recurrent events; time-varying general functionMSC:
46N30; 65C601. Introduction
Recurrence event data refer to the situation in which events of interest occur repeatedly over time, and these are wildly used in science and technology, especially in medical research, e.g., epileptic seizures, tumor recurrences, or asthma attack. When the investigators studied the recurrent events, they are often interested in the estimation of covariates on recurrent event times, which can help them perform further predictions. The establishment of models can be approached in many ways; meanwhile, the concept of intensity functions and the counting process are also useful. The nonparametric method used to generalize the intensity estimator for the censored failure time data, independently started by [1,2], also denoted the Nelson–Aalen estimator, is one of the methods widely used by investigators. Refs. [3,4], among others, also studied multiplicative models for the rate and mean functions, an approach which can be used with more general models, including regression. Ref. [5] proposed a generalization of the accelerated failure time model, the so-called accelerated recurrence time model, which resembles quantile regression as well as allows for the evolution of covariate effects.
In this paper, we also extend the quantile regression approach and utilize the counting process techniques. For a time-to-event response T, Ref. [6] proposed that a form may assume for , where , so can also be seen as the -th quantile of T given that the covariates Z and . Here, and t denote the time to event, the quantile level, and a non-negative real number, respectively. Since its introduction, quantile regression has been widely used and researched, mainly in survival analysis. Ref. [7] extended the LAD estimation method to more general quantiles, and can also improve efficiency when the error terms are identically distributed. Ref. [5] developed a new quantile regression approach to the counting process, and Ref. [8] adopted a constant general function in quantile regression which it applied to recurrence event data. In the application and algorithm estimation of quantile regression, efforts have also been made by many people. Ref. [9] proposed a locally weighted censored quantile regression approach that can solve covariate-dependent censoring. Ref. [10] proposed a semi-parametric approach using empirical likelihood to a random effects quantile regression model.
Overall, this work considers a situation wherein the general function of the accelerated failure time model is affected by time, sharing the same spirit of the parametric estimation method, while we will use the nonparametric method to estimate the effect. Then, we developed a new counting process model extended from the quantile regression models of this general function. This method provides some ideas for the development of more diverse estimation methods for the counting process.
2. Model
2.1. Accelerated Recurrent Events Time Model
Defining the , where is the indicator function. The observed counting process shows that the observation is limited to follow-up time L and ∧ is the minimization operator, meanwhile, the at-risk process and . We also have , and Z is a p-vector as the covariates of interest. The original accelerated recurrence time models considered covariates’ effects as time scale changes, which also share the same spirit as quantile regression, and the inverse function is
in a general setting, and denotes the time to expected frequency u. However, using a constant to estimate the expected frequency has some limitations. For example, the effect of the intervention of interest factors affecting the occurrence of an event may change over time. In this case, the model which combines a constant and variable coefficient may be more effective. As such, we proposed a new accelerated recurrence time model, and the right side of the inequality in the inverse function is instead of , where is the function of time t. Regardless of the form of inverse function, it can be written in the following form:
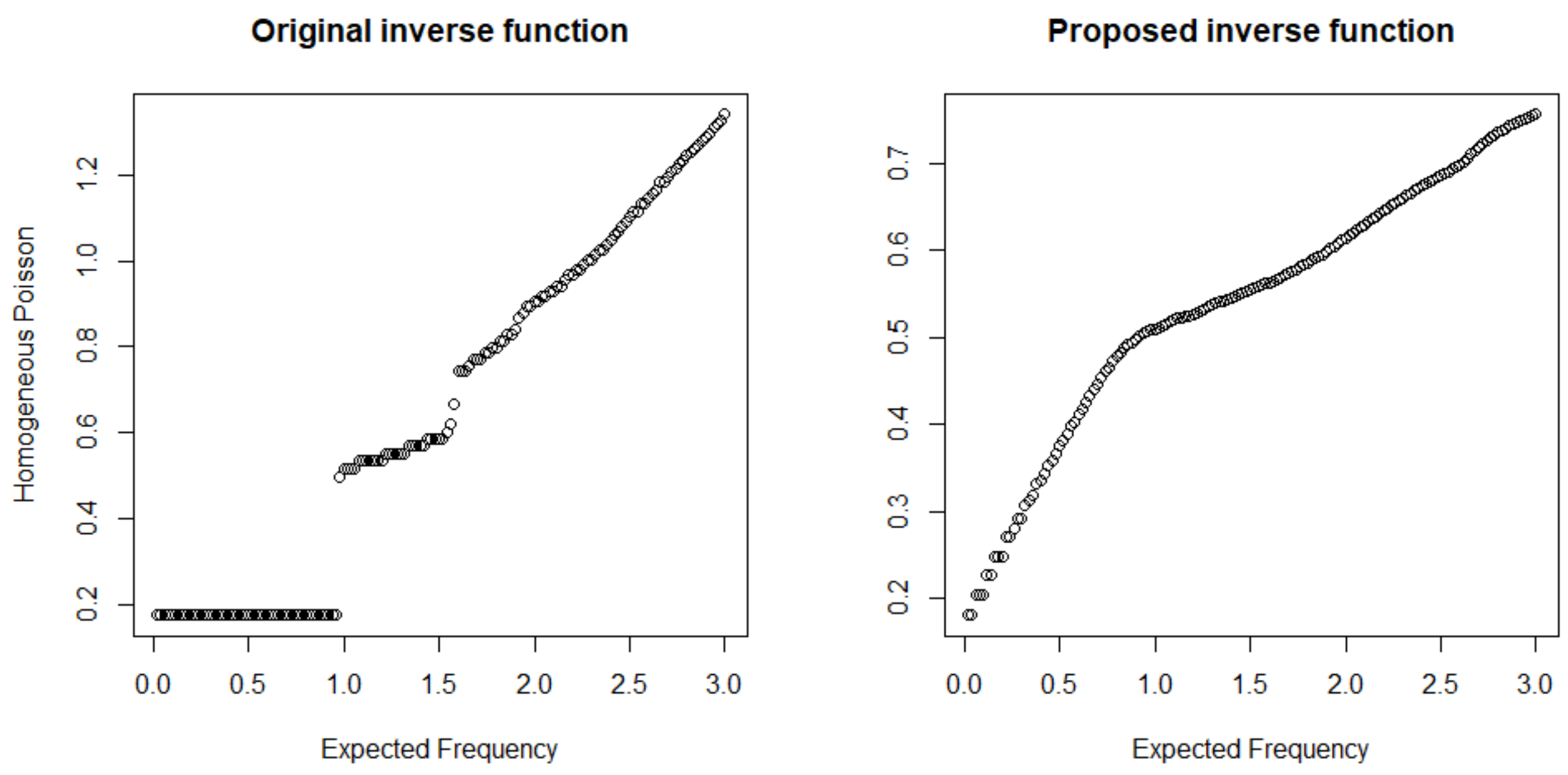
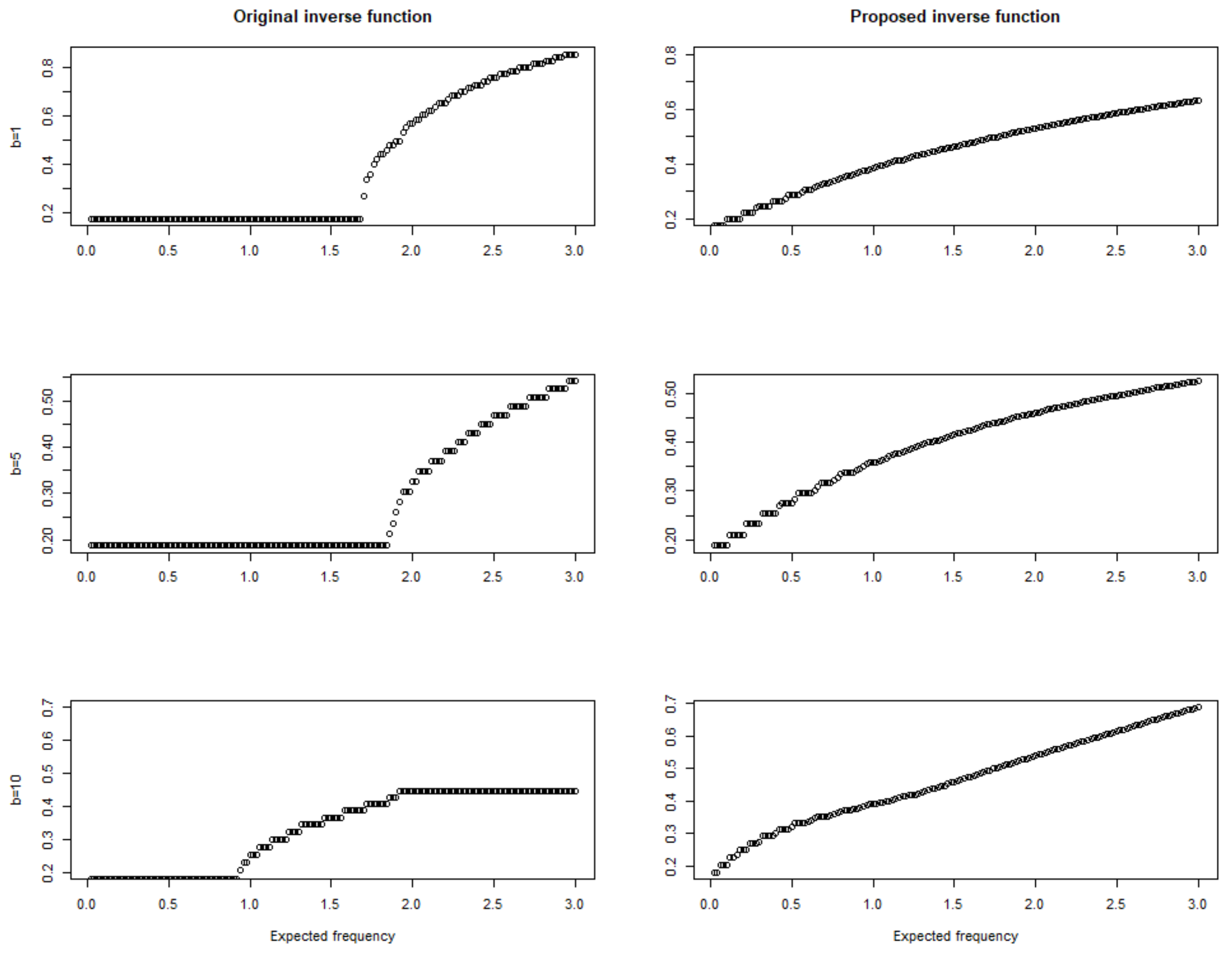
As can be seen from the above formula, should be linear. Compared to the original accelerated recurrence model and the improved model, when the recurrent event T follows a homogeneous Poisson distribution, as shown in Figure 1, the estimated log by both models is approximately linear when the recurrent event is a non-homogeneous Poisson process, which has an intensity function related to time t. In Figure 2, we compare three different situations, namely when and . As b increases, the estimation of the original accelerated recurrence model tends to be more and more nonlinear, while the proposed improved model still shows a strong linear relationship. In that way, the proposed recurrent event time model can be used in a more general situation.
In this paper, we consider the situation that , then model 2 can be rewritten as
if and only if , and the left-hand side should be monotone, then the above equation can be transformed into
where and ∨ denotes the maximization operator. Then, we can come up with the following theorem:
Theorem 1.
For , if (1) hold and , define for vector v, is the derivative of , let , and assume
- (C1)
- is non-singular;
- (C2)
- for all .Then,where
The proof of this result, as well as the proofs for Theorems 2 and 3 below, are given in Appendix A. Powell extended these results for censored quantile regression when the censoring time is observed [7]. We will then combine the counting process model and apply this method to the recurrence events data.
2.2. The Recurrent Events Model
For the counting process model, we begin with a review of Gill and Andersen’s study [11], which extended the Cox proportional hazards model [12] to a multivariate counting process. The intimate connection of the study on the multivariate counting process and the use of martingale methods can allow us to derive more properties of the statistical estimation and testing procedures. As each component of a multivariate counting process has a cumulative hazard function , there exist local martingales defined by . Since the cumulative hazard function is the integral of the hazard function, then according to [11], the counting process formation of the Cox model can be given by
where denotes the baseline hazard function, and this model can accommodate recurrent events data well. Peng and Huang conducted a re-examination work [5], which combined the quantile regression method for survival data with the above counting process model.
which has a nice monotonicity property. In model 6, the estimated cumulative hazard function . Huang also showed that a singleton model, where an estimated cumulative hazard function is a constant u, can also be applied in the counting process model [13]. When the singleton model is combined with quantile regression, this extended the following model to a more general situation of recurrent events [8], and the estimation formula is given by
where . In fact, in model 7, the estimated cumulative hazard function , which is a constant. According to Theorem 1 and the above models, we can propose a new counting process model that takes the form
where in our model, we can also show that
Therefore, we also have an alternative representation of the model that
The proof of this recurrence events setting is also shown in the Appendix A. In the simulation part, we will show that our estimation method performs better when the recurrent event time follows the non-homogeneous Poisson distribution.
2.3. The Proposed Estimation Procedure
From Theorem 1, we can define the objective function
Theorem 1 leads to the estimation of , that is .
It can be seen that the objective function is not convex. An algorithm was developed to find the local minimizer that is asymptotically equivalent to the global minimizer [13]. Since we proposed the counting process-based model (model 7), then we can propose an equation to estimate :
where
As the results proposed in [11], although is a local square integrable martingale, it has the same asymptotic property as a global martingale, and if we let , then follows the martingale property of given that .
Equation (8) boils down to the estimation of censored quantile regression in [5]. A common method used to predict is the grid-based estimation procedure by denoting as a right-continuous piecewise-constant function that jumps on a grid. More specifically, we define , and for our recurrence setting, the U in the grid can be greater than 1. The size of , denoted by , is the maximum value of where . It is also noteworthy that . Thus, based on model 9, we can estimate by sequentially solving the estimating equation
Since Equation (10) is not continuous, the exact root may not exist. Fygenson and Ritov proposed a generalization solution of for monotone estimating equations [14]. To find the generalization solution of Equation (10), we need to perform some simple algebraic manipulations, and then the solution-finding problem is equivalent to locating the minimizer of the following -type convex function:
where is a very large number and . One can also solve the by using statistical software, such as the function in R package or the function in S-PLUS.
2.4. Asymptotic Properties
In this section, we establish the uniform consistency and weak convergence of the proposed estimator . Firstly, some regularity conditions should be stated.
Define , , , , , . By using simple algebra, we also define , . Suppose the assumptions in Theorem 1 hold and is strongly consistent for . Assume the following conditions:
- (C1’)
- Z and are bounded;
- (C2’)
- (a) is bounded and continuous at , as well as uniform in Z, and (b) is a Lipschitz function of u;
- (C3’)
- (a) each component of is uniformly bound on , where is a neighborhood containing , (b) and is positive definite;
- (C4’)
- for any , where denotes the minimum eigenvalue of a matrix.
Condition (C1’) implies the boundedness of covariates and the number of observed events, and (C2’) gives the smoothness of , condition (C3’) sets additional mild assumptions such as the positive definite. Noted that (C4’) is a key condition that ensures the consistency of the proposed estimator. Then, we have the following theorems.
Theorem 2.
Under conditions C1’–C4’, when , then
where .
Theorem 3.
Under condition C1’–C4’, when , then
converge weakly to a Gaussian process for , where .
The proofs are also in the Appendix A.
3. Simulation Studies
In this part, we conducted the Monte Carlo simulations to test our model. Combining the methods of Huang and Peng [13], recurrent events were generated from both homogeneous Poisson and non-homogeneous Poisson processes. We also generated two covariates, and , following the distribution and separately. The recurrent event time was generated by:
where in one case, was a recurrent event time from the standard homogeneous Poisson process, in other words, the gap times of are independent and identically variables; in other cases, is a recurrent event time from the non-homogeneous Poisson process with the intensity function . Furthermore, the frailty followed the Gamma distribution for the homogeneous Poisson process, we considered two situations, that is the variance of was chosen to be 0 and 0.5, for the non-homogeneous Poisson process, and we only consider the variance of to be 0. Under our simulation setup, we have
For censoring time L, we generated it from . For each selection of the variance of , we generated 500 datasets of sample size . Since we adopted the grid-based method to estimate the , an equally spaced grid on with step size 0.02 was conducted in our simulation.
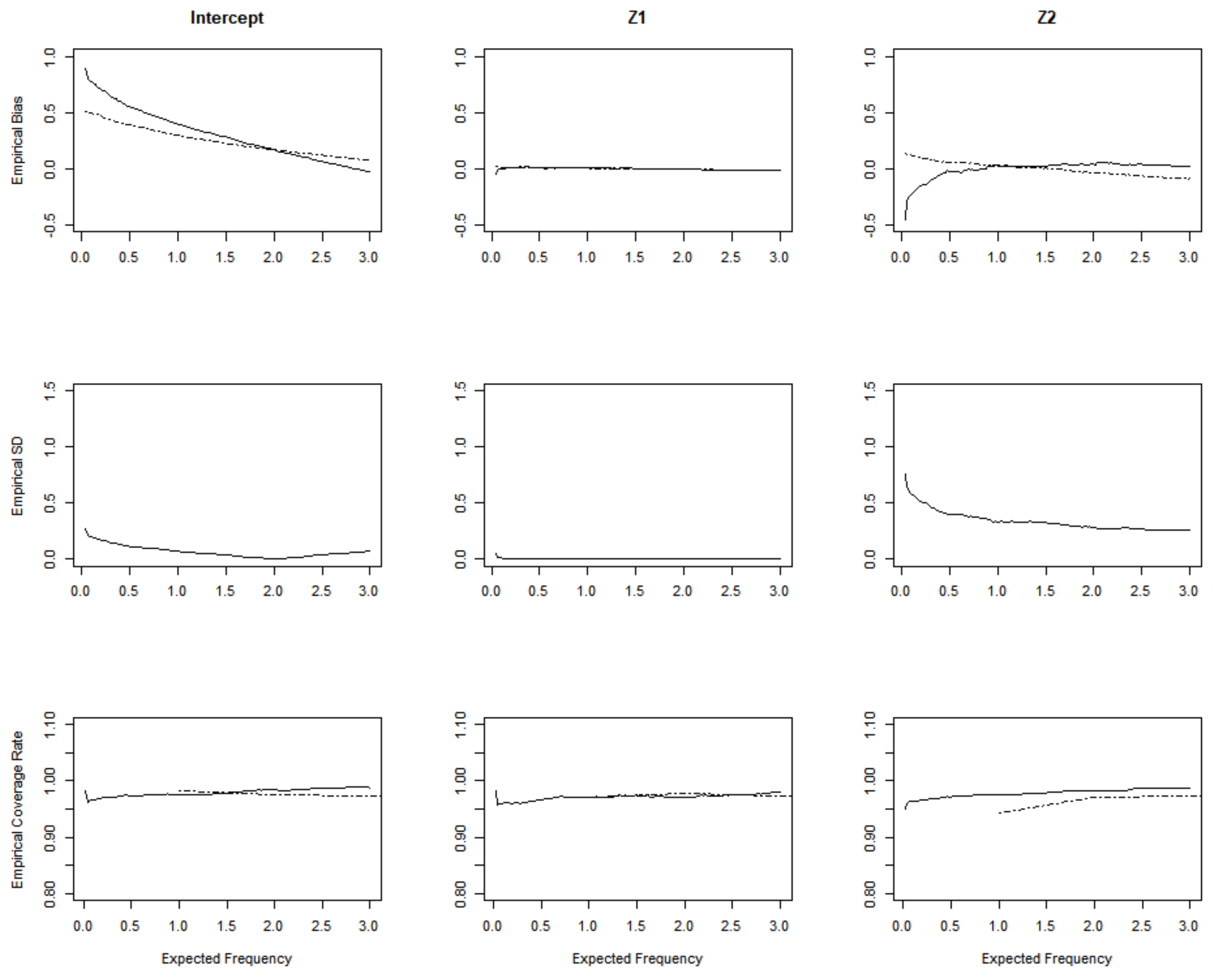
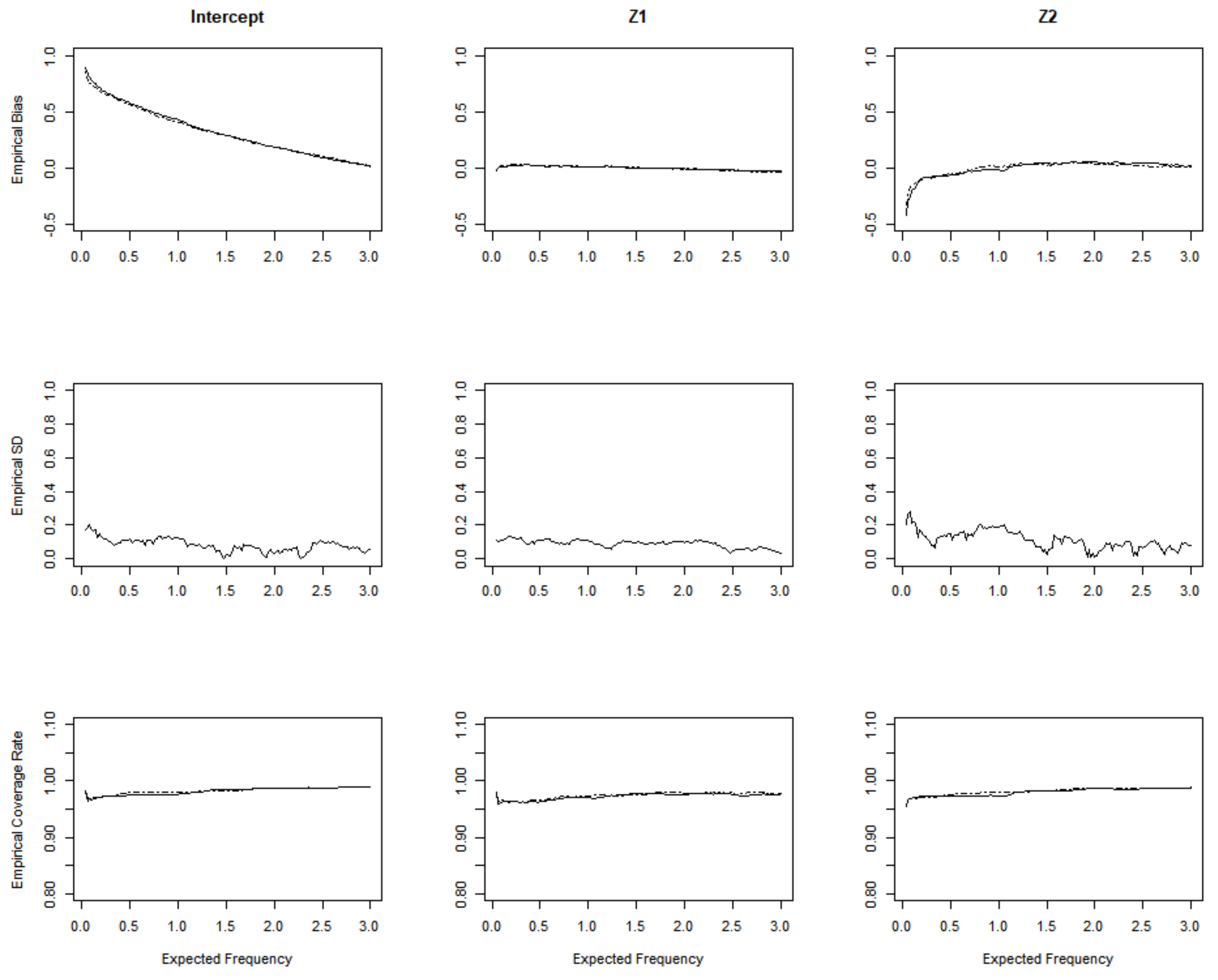
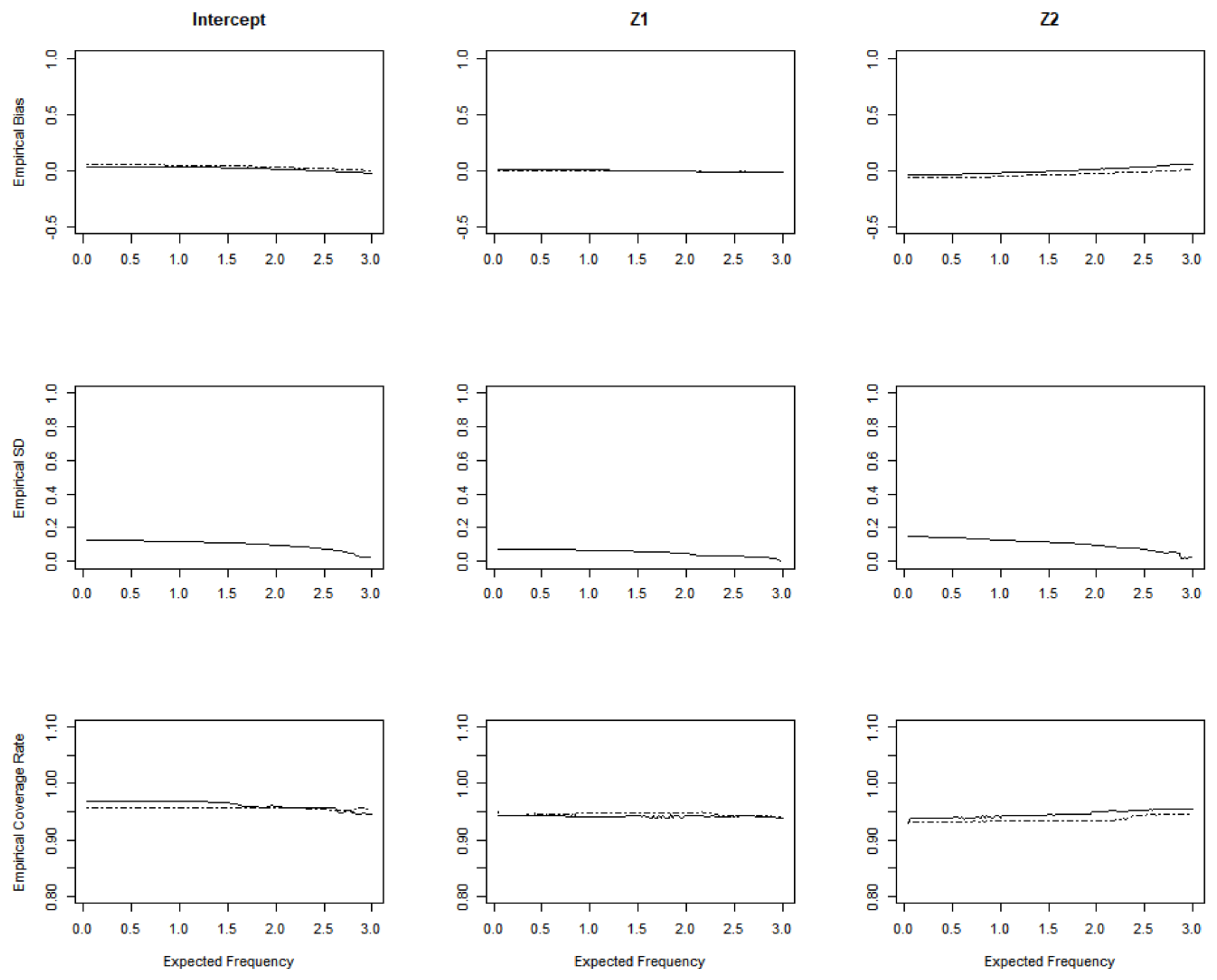
Figure 3 and Figure 4 are the simulation results for the homogeneous Poisson process from the set-up with a Gamma frailty of variance 0 and 0.5. In the first row, we plot the empirical bias of the proposed estimator (solid lines) and the empirical bias of the Sun’s estimator (dashed lines) [8]. Sun considered the double censored situation while we only consider the right-censored event time to suit a more general situation. In the second row of the plots, we depicted the empirical mean squared error (MSE) versus the expected frequency u. The third row presents the coverage probabilities of 95% confidence intervals obtained from the proposed estimator (solid lines) and Sun’s estimator (dashed lines). We can see that both methods have a slight bias which converges to 0, and the empirical MSE also tends to be stable as u increases. In the homogeneous Poisson process, when the variance of gamma frailty equals 0, the empirical MSE shows less fluctuation compared to the variance that is equal to 0.5.
Figure 5 depicts the same parameters as Figure 3 and Figure 4, while the difference is that the results are from the non-homogeneous Poisson process. We can see that, in the first and second rows of Figure 5, both methods performed quite similarly in terms of the bias and SD. However, from the third row, in terms of the coverage probability, the proposed estimator (solid lines) performed slightly better than the Sun’s estimator (dashed lines), than for the simulation of the non-homogeneous Poisson process.
4. Application to the Bladder Tumor Studies
We applied our proposed estimated method to a well-known bladder tumor study [15]. This dataset was conducted to analyze the effect of two treatments, pyridoxine and thiotepa, based on the recurrence of bladder tumors. A total of 118 subjects were recorded, 48 were treated with placebo, 32 were pyridoxine, and 38 with thiotepa. The covariates also contained the initial number of tumors, the size of the largest initial tumor and others. The maximum observed number of recurrences is 9.
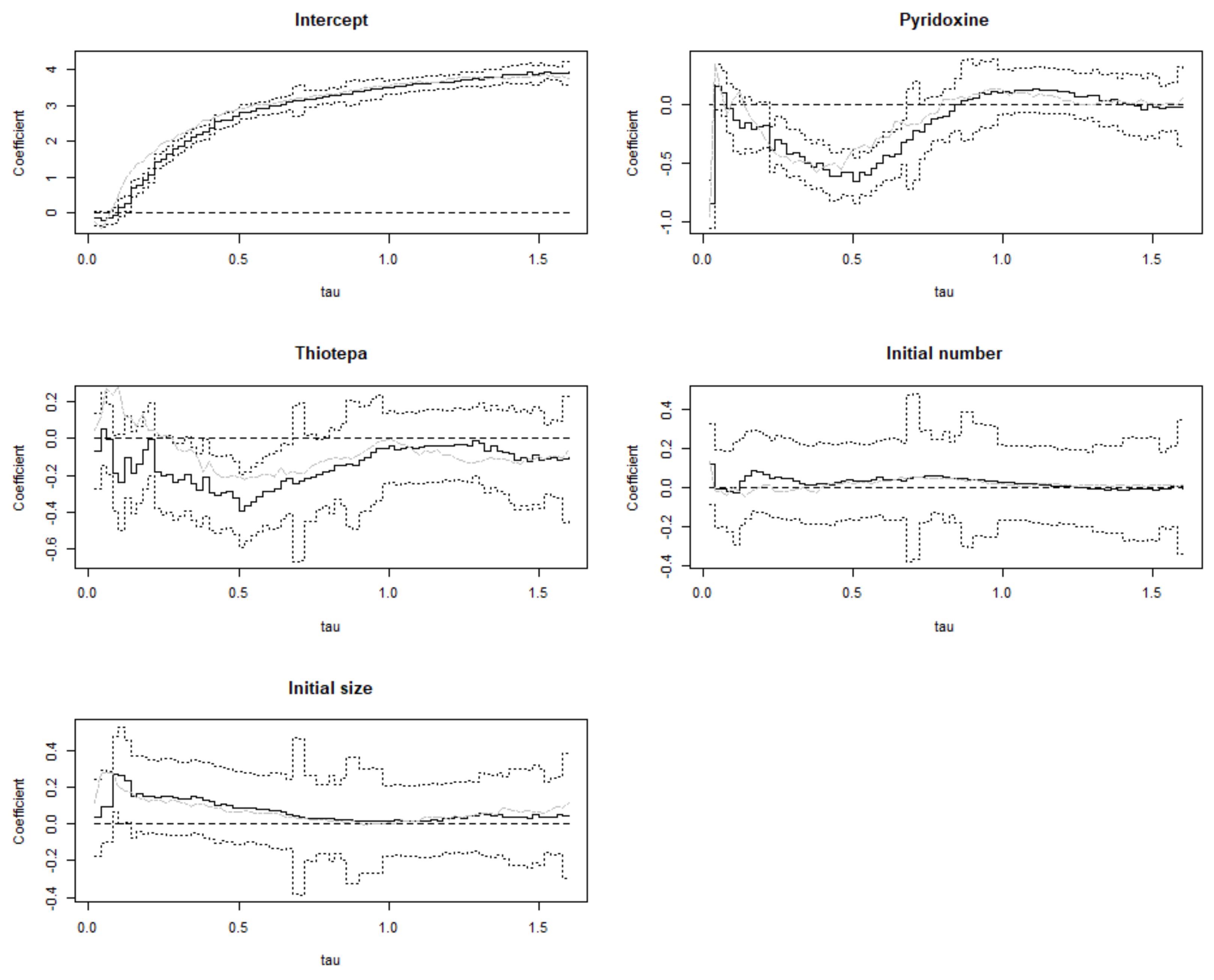
We selected four covariates and the intercept: the two treatment methods and the initial tumor size and number. In Figure 6, we displayed our estimation result of the proposed method (solid lines) and Sun’s method (gray line) [8], surrounded by point-wise Wald 95% confidence intervals (dashed lines). The grid-based estimation method estimated the regression coefficients over [0, 1.6]. The intercept coefficient estimates represent the log time to the expected frequency of the bladder tumor recurrence, consisting of patients who had no pyridoxine and thiotepa treatment. The intercept term indicates that as time increases, the bladder tumor recurrence also increases, which is in line with expectations. The negative non-intercept coefficient estimates pyridoxine and thiotepa show that these two treatments can inhibit tumor recurrence. In contrast, the initial tumor size and number of covariates are positive, suggesting a negative effect on tumor recurrence. From Figure 6, we can see that our method and Sun’s method do not have much difference, and the overall trend is the same.
5. Discussion
In this article, we introduced the accelerated recurrence time model for recurrence events, and then considered a new situation when the expected frequency of the accelerated recurrence time model was affected by the time-varying and combined this model with the counting process model. This new counting process model with a non-singleton general function is similar to Cox’s regression model but can be transformed into quantile regression. This method can also estimate more general situations, such as the non-homogeneous Poisson process.
We can generalize our estimation procedure from double-censored to right-censored situations. In the recurrence events setting, the most popular choice of , which may be , as well as , we introduce our new estimation method with . The assumption is that a constant hazard is rarely tenable in practical problems. Therefore, in the parametric estimation process, a more general distribution of the hazard function is the Weibull distribution, which is for , so we have . When , the Weibull distribution function becomes a constant, but resembles the accelerated recurrence time model. When , the model became our proposed method. Thus, after combining the parametric and nonparametric methods, we can make the estimation method more diverse and adapt to different types of datasets.
Author Contributions
Conceptualization, J.X.; Data curation, X.W.; Formal analysis, X.W.; Investigation, X.W. and J.X.; Methodology, J.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Proof of Theorem 1.
If we want to estimate the , the left-hand side of the following equation should be monotone,
taking derivative with respect to on both sides of equation that
then, under condition (2), the Equation (A1) can be monotone. Meanwhile, straightforward algebra gives
and for any ,
in order to eliminate the minimization operator, we consider the following situations:
- when and ,
- when and ,
- when , since is the unique value that minimizesconsidering the monotonicity of , therefore . By the non-singularity of ,
Thus, the proof is completed. □
Proof of Theorem 2.
Define , , and
Noted that for any , ,
which only occurs when by condition (C3’). Then, there exists a one-to-one map from to that we denoted by and for any .
Furthermore, by the properties of the martingale stochastic process
we have
where .
Then, the following notations are defined:
By the Glivenko–Cantelli theorem, we have
Since . Then, is equivalent to
By the arguments as [5], the can be bounded almost surely by , where . Given and , we have
where , , , and are some positive constant. Since are arbitrarily and , then we can know that . By the application of the Taylor expansion of around , the conclusion can be reached. □
Proof of Theorem 3.
From the arguments made by [13], we have the following lemma:
and the above lemma implies that
since , then . Then, we can use the product integration theory to obtain the following equation:
where , which is a one-to-one map from to . By our definition, and g is left-continuous with a right limit, . Meanwhile,
Since the definition given by [16] is followed, is a VC-class. For , let , suppose that , then
where , this implies that is a Lipschitz in x. The above arguments show that
is a Donsker class. By the Donsker theorem, we can know that converge weakly to a Gaussian process, then is also a Gaussian process for is a linear operator. By the continuous mapping theory and Taylor expansion of around , we can know that converge weakly to a Gaussian process with a mean of zero and a covariance matrix , where , and . □
Recurrent Event Setting
Suppose model 6 holds, then according to the following definition:
and the inequality can also be written as following the definition of . Then
In model 6, , so it follows from the above equation that for ,
Therefore, the model 5 is satisfied.
Suppose that model 5 holds, then taking the derivative with respect to u on both sides of equation in model 5, we have
that is, , then and model 6 are satisfied.
References
- Nelson, W. Hazard plotting for incomplete failure data. J. Qual. Technol. 1969, 1, 27–52. [Google Scholar] [CrossRef]
- Altshuler, B. Theory for the measurement of competing risks in animal experiments. Math. Biosci. 1970, 6, 1–11. [Google Scholar] [CrossRef]
- Lawless, J.F. Regression methods for Poisson process data. J. Am. Stat. Assoc. 1987, 82, 808–815. [Google Scholar] [CrossRef]
- Lin, D.Y.; Wei, L.J.; Yang, I.; Ying, Z. Semiparametric regression for the mean and rate functions of recurrent events. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2000, 62, 711–730. [Google Scholar] [CrossRef] [Green Version]
- Peng, L.; Huang, Y. Survival analysis with quantile regression models. J. Am. Stat. Assoc. 2008, 103, 637–649. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G., Jr. Regression quantiles. Econom. J. Econom. Soc. 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Powell, J.L. Censored regression quantiles. J. Econom. 1986, 32, 143–155. [Google Scholar] [CrossRef]
- Sun, X.; Peng, L.; Huang, Y.; Lai, H.J. Generalizing quantile regression for counting processes with applications to recurrent events. J. Am. Stat. Assoc. 2016, 111, 145–156. [Google Scholar] [CrossRef]
- Wang, H.J.; Wang, L. Locally weighted censored quantile regression. J. Am. Stat. Assoc. 2009, 104, 1117–1128. [Google Scholar] [CrossRef] [Green Version]
- Kim, M.O.; Yang, Y. Semiparametric approach to a random effects quantile regression model. J. Am. Stat. Assoc. 2011, 106, 1405–1417. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Andersen, P.K.; Gill, R.D. Cox’s regression model for counting processes: A large sample study. Ann. Stat. 1982, 10, 1100–1120. [Google Scholar] [CrossRef]
- Cox, D.R. Regression models and life-tables. J. R. Stat. Soc. Ser. B (Methodol.) 1972, 34, 187–202. [Google Scholar] [CrossRef]
- Huang, Y.; Peng, L. Accelerated recurrence time models. Scand. J. Stat. 2009, 36, 636–648. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fygenson, M.; Ritov, Y. Monotone estimating equations for censored data. Ann. Stat. 1994, 22, 732–746. [Google Scholar] [CrossRef]
- Byar, D. The veterans administration study of chemoprophylaxis for recurrent stage i bladder tumours: Comparisons of placebo, pyridoxine and topical thiotepa. In Bladder Tumors and Other Topics in Urological Oncology; Springer: Berlin/Heidelberg, Germany, 1980; pp. 363–370. [Google Scholar]
- Vaart, A.V.D.; Wellner, J.A. Weak convergence and empirical processes with applications to statistics. J. R. Stat. Soc.-Ser. A Stat. Soc. 1997, 160, 596–608. [Google Scholar]
Figure 1.
Estimation results of homogeneous Poisson process.

Figure 2.
Estimation results of non-homogeneous Poisson process.

Figure 3.
Simulation results with sample size n = 100 and the set-up with Gamma frailty of variance 0.
Figure 3.
Simulation results with sample size n = 100 and the set-up with Gamma frailty of variance 0.

Figure 4.
Simulation results with sample size n = 100 and the set-up with Gamma frailty of variance 0.5.
Figure 4.
Simulation results with sample size n = 100 and the set-up with Gamma frailty of variance 0.5.

Figure 5.
Simulation results of non-homogeneous Poisson process with sample size n = 100 and the set-up with Gamma frailty of variance 0.
Figure 5.
Simulation results of non-homogeneous Poisson process with sample size n = 100 and the set-up with Gamma frailty of variance 0.

Figure 6.
Bladder data example: coefficient estimates and 95% pointwise confidence.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wen, X.; Xu, J. Generalized Accelerated Failure Time Models for Recurrent Events. Mathematics 2022, 10, 2662. https://doi.org/10.3390/math10152662
AMA Style
Wen X, Xu J. Generalized Accelerated Failure Time Models for Recurrent Events. Mathematics. 2022; 10(15):2662. https://doi.org/10.3390/math10152662
Chicago/Turabian StyleWen, Xiaoyi, and Jinfeng Xu. 2022. "Generalized Accelerated Failure Time Models for Recurrent Events" Mathematics 10, no. 15: 2662. https://doi.org/10.3390/math10152662
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.