

Efficient Estimation and Inference in the Proportional Odds Model for Survival Data
Abstract
:1. Introduction
2. MM Algorithm
2.1. Basic Principle
2.2. Commonly Used Inequalities
3. Proportional Odds Model
3.1. Profile MM Method
3.2. Non-Profile MM Method
- Let the initial value of to be .
- Update using Equation (6).
- Use the updated value of , calculate the estimate of using Equation (7).
- Iterate step 2 and 3 until convergence.
4. Variable Selection in the Proportional Odds Model
4.1. Parameter Separated Estimation Method
4.2. The Variable Selection Based on SCAD and MCP Penalties
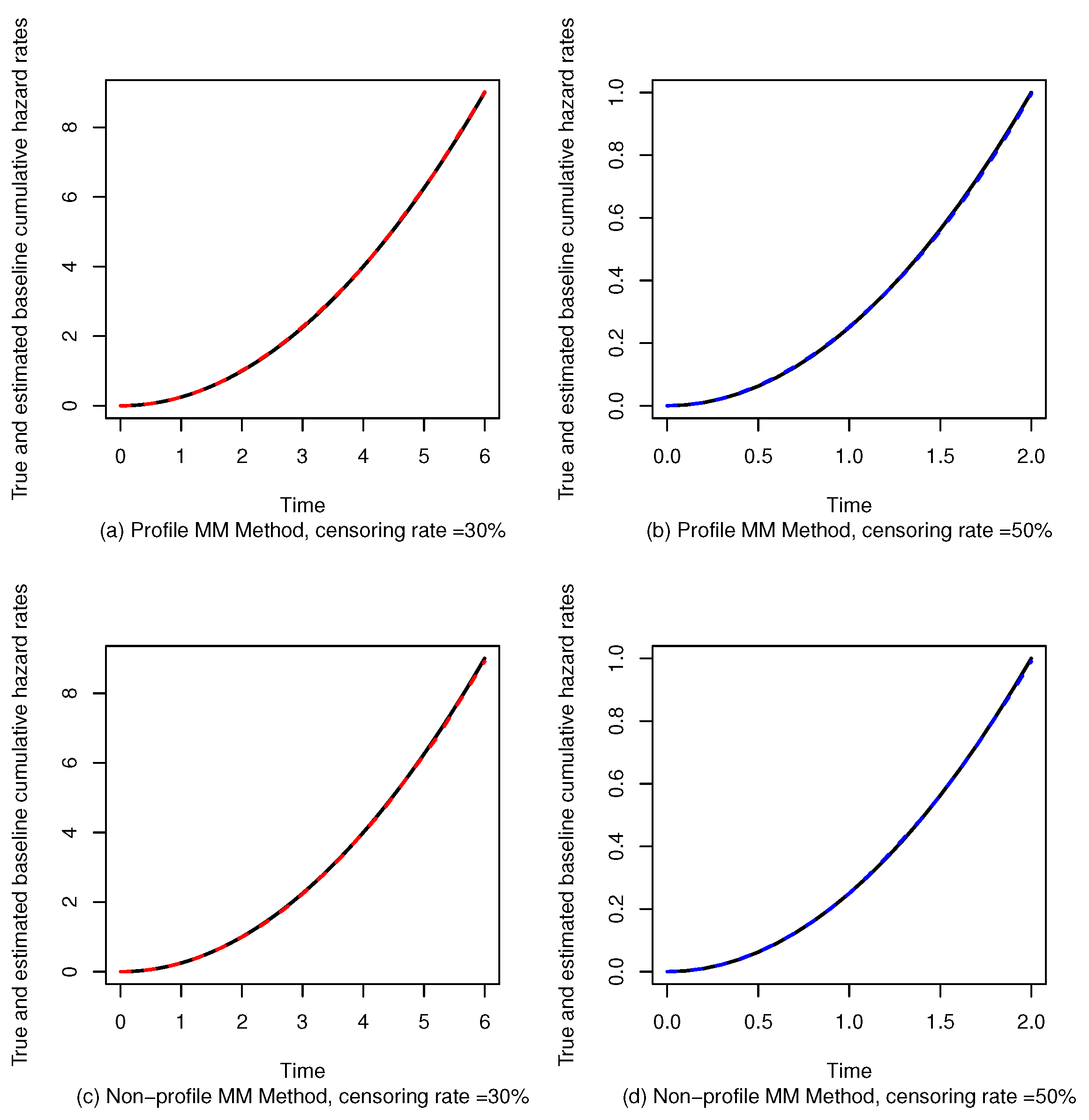
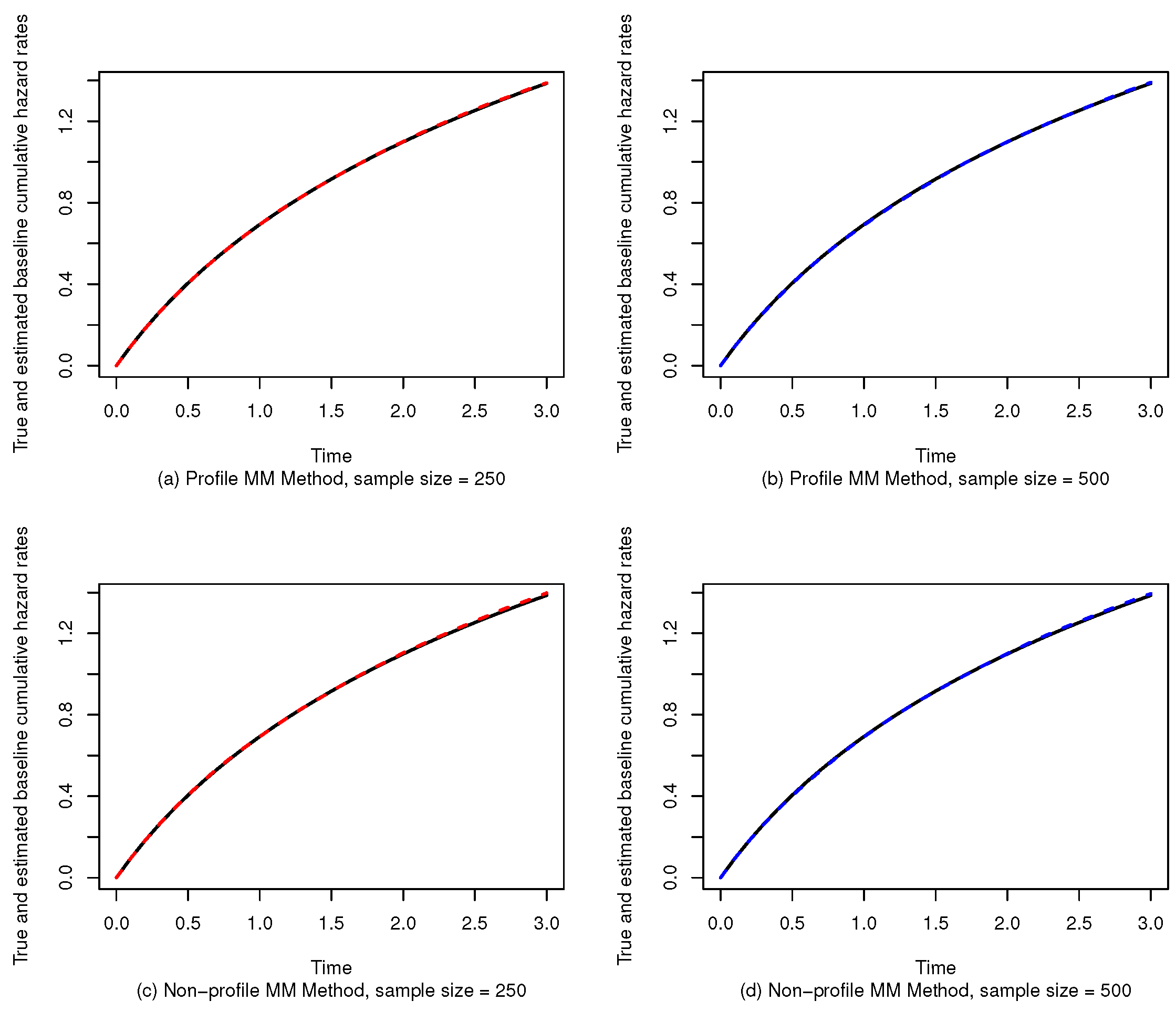
5. Simulation Study
5.1. Parameter Estimation of the Proportional Odds Model
5.2. Simulation on Variable Selection
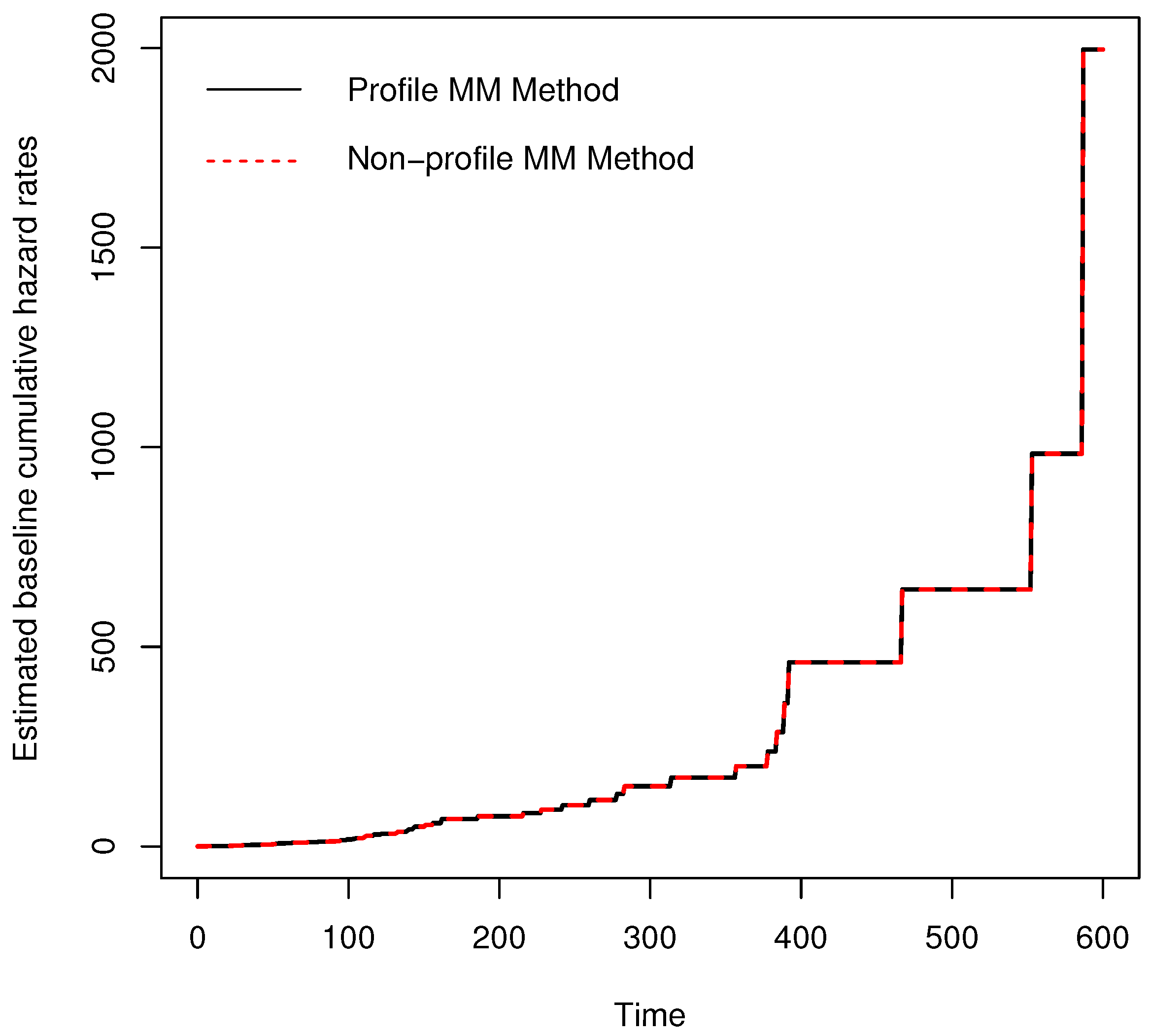
6. Real Data Analysis
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- McCullagh, P. A logistic model for paired comparisons with ordered categorical data. Biometrika 1977, 64, 449–453. [Google Scholar] [CrossRef]
- McCullagh, P. Regression models for ordinal data. J. R. Stat. Soc. Ser. B 1980, 42, 109–127. [Google Scholar] [CrossRef]
- Bennett, S. Analysis of survival data by the proportional odds model. Stat. Med. 1983, 2, 273–277. [Google Scholar] [CrossRef] [PubMed]
- Bennett, S. Log-logistic regression models for survival data. J. R. Stat. Soc. Ser. C 1983, 32, 165–171. [Google Scholar] [CrossRef]
- Pettitt, A. Proportional odds models for survival data and estimates using ranks. J. R. Stat. Soc. Ser. C 1984, 33, 169–175. [Google Scholar] [CrossRef]
- Rossini, A.; Tsiatis, A. A semiparametric proportional odds regression model for the analysis of current status data. J. Am. Stat. Assoc. 1996, 91, 713–721. [Google Scholar] [CrossRef]
- Murphy, S.; Rossini, A.; van der Vaart, A.W. Maximum likelihood estimation in the proportional odds model. J. Am. Stat. Assoc. 1997, 92, 968–976. [Google Scholar] [CrossRef]
- Huang, J.; Rossini, A. Sieve estimation for the proportional-odds failure-time regression model with interval censoring. J. Am. Stat. Assoc. 1997, 92, 960–967. [Google Scholar] [CrossRef]
- Shen, X. Propotional odds regression and sieve maximum likelihood estimation. Biometrika 1998, 85, 165–177. [Google Scholar] [CrossRef]
- Rabinowitz, D.; Betensky, R.A.; Tsiatis, A.A. Using conditional logistic regression to fit proportional odds models to interval censored data. Biometrics 2000, 56, 511–518. [Google Scholar] [CrossRef]
- Lam, K.; Leung, T. Marginal likelihood estimation for proportional odds models with right censored data. Lifetime Data Anal. 2001, 7, 39–54. [Google Scholar] [CrossRef] [PubMed]
- Hunter, D.R.; Lange, K. Computing estimates in the proportional odds model. Ann. Inst. Stat. Math. 2002, 54, 155–168. [Google Scholar] [CrossRef]
- Royston, P.; Parmar, M.K. Flexible parametric proportional-hazards and proportional-odds models for censored survival data, with application to prognostic modelling and estimation of treatment effects. Stat. Med. 2002, 21, 2175–2197. [Google Scholar] [CrossRef]
- Banerjee, S.; Dey, D.K. Semiparametric proportional odds models for spatially correlated survival data. Lifetime Data Anal. 2005, 11, 175–191. [Google Scholar] [CrossRef]
- Wang, L.; Dunson, D.B. Semiparametric Bayes’ proportional odds models for current status data with underreporting. Biometrics 2011, 67, 1111–1118. [Google Scholar] [CrossRef]
- Lin, X.; Wang, L. Bayesian proportional odds models for analyzing current status data: Univariate, clustered, and multivariate. Commun. Stat.-Simul. Comput. 2011, 40, 1171–1181. [Google Scholar] [CrossRef]
- Augustin, N.H.; Kim, S.W.; Uhlig, A.; Hanser, C.; Henke, M.; Schumacher, M. A flexible multivariate random effects proportional odds model with application to adverse effects during radiation therapy. Biom. J. 2017, 59, 1339–1351. [Google Scholar] [CrossRef]
- Bao, Y.; Vicente Garibay, C.; Francisco, L.; Adriano Kamimura, S. Cure rate proportional odds models with spatial frailties for interval-censored data. Commun. Stat. Appl. Methods 2017, 24, 605–625. [Google Scholar] [CrossRef]
- Kumar, D.; Sankaran, P. Proportional odds model—A quantile approach. J. Appl. Stat. 2019, 46, 1937–1955. [Google Scholar] [CrossRef]
- Chen, J.; Terrell, G.R.; Kim, I.; Daviglus, M.L. Proportional odds model with log-concave density estimation. Stat. Sin. 2020, 30, 877–901. [Google Scholar] [CrossRef]
- Wang, L.; Wang, L. Regression analysis of arbitrarily censored survival data under the proportional odds model. Stat. Med. 2021, 40, 3724–3739. [Google Scholar] [CrossRef] [PubMed]
- Zhu, L.; Tong, X.; Cai, D.; Li, Y.; Sun, R.; Srivastava, D.K.; Hudson, M.M. Maximum likelihood estimation for the proportional odds model with mixed interval-censored failure time data. J. Appl. Stat. 2021, 48, 1496–1512. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Wang, L. An EM algorithm for analyzing right-censored survival data under the semiparametric proportional odds model. Commun. Stat. Theory Methods 2020, 51, 5284–5297. [Google Scholar] [CrossRef]
- Tibshirani, R. The lasso method for variable selection in the Cox model. Stat. Med. 1997, 16, 385–395. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable selection for Cox’s proportional hazards model and frailty model. Ann. Stat. 2002, 30, 74–99. [Google Scholar] [CrossRef]
- Zou, H. A note on path-based variable selection in the penalized proportional hazards model. Biometrika 2008, 95, 241–247. [Google Scholar] [CrossRef]
- Lu, W.; Zhang, H.H. Variable selection for proportional odds model. Stat. Med. 2007, 26, 3771–3781. [Google Scholar] [CrossRef]
- Hunter, D.R.; Lange, K. Quantile regression via an MM algorithm. J. Comput. Graph. Stat. 2000, 9, 60–77. [Google Scholar]
- Hunter, D.R. MM algorithms for generalized Bradley-Terry models. Ann. Stat. 2004, 32, 384–406. [Google Scholar] [CrossRef]
- Zhou, H.; Lange, K. MM algorithms for some discrete multivariate distributions. J. Comput. Graph. Stat. 2010, 19, 645–665. [Google Scholar] [CrossRef]
- Tian, G.L.; Ding, X.; Liu, Y.; Tang, M.L. Some new statistical methods for a class of zero-truncated discrete distributions with applications. Comput. Stat. 2019, 34, 1393–1426. [Google Scholar] [CrossRef]
- Hunter, D.R.; Li, R. Variable selection using MM algorithms. Ann. Stat. 2005, 33, 1617–1642. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.D.; McLachlan, G.J. Maximum likelihood estimation of Gaussian mixture models without matrix operations. Adv. Data Anal. Classif. 2015, 9, 371–394. [Google Scholar] [CrossRef]
- Huang, X.; Xu, J.; Tian, G. On profile MM algorithms for gamma frailty survival models. Stat. Sin. 2019, 29, 895–916. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Zhang, C.H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Benjamini, Y.; Hochberg, Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B 1995, 57, 289–300. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| n | Parameter | Profile MM | Non-Profile MM | ||||||
|---|---|---|---|---|---|---|---|---|---|
| BIAS | MSE | SD | K | BIAS | MSE | SD | K | ||
| 250 | −0.0066 | 0.0316 | 0.1777 | 0.0024 | 0.0324 | 0.1801 | |||
| −0.0077 | 0.0204 | 0.1426 | 0.0092 | 0.0182 | 0.1348 | ||||
| −0.0001 | 0.0513 | 0.2267 | 104 | −0.0139 | 0.0486 | 0.2203 | 298 | ||
| 0.0085 | 0.0003 | 0.0172 | 0.0002 | 0.0003 | 0.0166 | ||||
| 0.0052 | 0.0035 | 0.0593 | 0.0004 | 0.0028 | 0.0528 | ||||
| 500 | −0.0068 | 0.0143 | 0.1195 | −0.0085 | 0.0151 | 0.1226 | |||
| 0.0007 | 0.0089 | 0.0943 | 0.0016 | 0.0101 | 0.1008 | ||||
| −0.0154 | 0.0241 | 0.1545 | 102 | −0.0128 | 0.0219 | 0.1474 | 289 | ||
| −0.0002 | 0.0001 | 0.0114 | 0.0005 | 0.0001 | 0.0120 | ||||
| −0.0028 | 0.0013 | 0.0362 | −0.0004 | 0.0014 | 0.0368 | ||||
| n | Parameter | Profile MM | Non-Profile MM | ||||||
|---|---|---|---|---|---|---|---|---|---|
| BIAS | MSE | SD | K | BIAS | MSE | SD | K | ||
| 250 | −0.0029 | 0.0462 | 0.2151 | −0.0100 | 0.0369 | 0.1921 | |||
| −0.0021 | 0.0235 | 0.1534 | 0.0037 | 0.0249 | 0.1580 | ||||
| 0.0001 | 0.0682 | 0.2614 | 106.5 | 0.0027 | 0.0648 | 0.2548 | 310 | ||
| −0.0003 | 0.0003 | 0.0166 | 0.0004 | 0.0003 | 0.0177 | ||||
| −0.0001 | 0.0032 | 0.0565 | −0.0003 | 0.0035 | 0.0531 | ||||
| 500 | 0.0012 | 0.0196 | 0.1402 | −0.0033 | 0.0184 | 0.1359 | |||
| −0.0105 | 0.0116 | 0.1076 | −0.0078 | 0.0131 | 0.1145 | ||||
| 0.0063 | 0.0348 | 0.1867 | 105 | 0.0020 | 0.0310 | 0.1763 | 304 | ||
| −0.0002 | 0.0002 | 0.0125 | 0.0005 | 0.0002 | 0.0126 | ||||
| −0.0017 | 0.0018 | 0.0422 | 0.0027 | 0.0016 | 0.0395 | ||||
| n | Parameter | Profile MM | Non-Profile MM | ||||||
|---|---|---|---|---|---|---|---|---|---|
| BIAS | MSE | SD | K | BIAS | MSE | SD | K | ||
| 250 | 0.0147 | 0.0336 | 0.1831 | 0.0316 | 0.0435 | 0.2065 | |||
| 0.0075 | 0.0207 | 0.1438 | 0.0129 | 0.0258 | 0.1604 | ||||
| −0.0328 | 0.0777 | 0.2772 | 53 | −0.0049 | 0.0768 | 0.2774 | 151 | ||
| 0.0074 | 0.0089 | 0.0945 | −0.0068 | 0.0082 | 0.0908 | ||||
| 0.0138 | 0.0242 | 0.1553 | −0.0090 | 0.0233 | 0.1527 | ||||
| 500 | 0.0041 | 0.0186 | 0.1367 | 0.0134 | 0.0199 | 0.1409 | |||
| −0.0042 | 0.0120 | 0.1096 | 0.0027 | 0.0135 | 0.1166 | ||||
| −0.0015 | 0.0398 | 0.1998 | 53 | −0.0001 | 0.0371 | 0.1929 | 148 | ||
| −0.0015 | 0.0039 | 0.0625 | −0.0020 | 0.0043 | 0.0659 | ||||
| −0.0005 | 0.0115 | 0.1075 | −0.0043 | 0.0114 | 0.1068 | ||||
| n | Parameter | Profile MM | Non-Profile MM | ||||||
|---|---|---|---|---|---|---|---|---|---|
| BIAS | MSE | SD | K | BIAS | MSE | SD | K | ||
| 200 | −0.0711 | 0.1664 | 0.4020 | −0.0840 | 0.1842 | 0.4213 | |||
| −0.0208 | 0.0640 | 0.2524 | −0.0515 | 0.0697 | 0.2593 | ||||
| 0.0020 | 0.0433 | 0.2083 | 4251 | 0.0174 | 0.0443 | 0.2099 | 2016 | ||
| 0.0496 | 0.1134 | 0.3335 | 0.0691 | 0.1150 | 0.3323 | ||||
| 0.1008 | 0.2523 | 0.4925 | 0.0966 | 0.2571 | 0.4983 | ||||
| 400 | −0.0230 | 0.0663 | 0.2567 | −0.0108 | 0.0714 | 0.2673 | |||
| −0.0149 | 0.0317 | 0.1777 | −0.0005 | 0.0313 | 0.1771 | ||||
| 0.0093 | 0.0177 | 0.1328 | 3959 | 0.0065 | 0.0189 | 0.1375 | 1851 | ||
| 0.0139 | 0.0451 | 0.2121 | −0.0026 | 0.0471 | 0.2172 | ||||
| 0.0372 | 0.0982 | 0.3114 | 0.0080 | 0.1068 | 0.3271 | ||||
| n | Parameter | Profile MM | Non-Profile MM | ||||||
|---|---|---|---|---|---|---|---|---|---|
| BIAS | MSE | SD | K | BIAS | MSE | SD | K | ||
| 200 | 0.0135 | 0.0253 | 0.1587 | 1076 | 0.0273 | 0.0304 | 0.1724 | 467 | |
| −0.0474 | 0.0438 | 0.2040 | −0.0419 | 0.0458 | 0.2102 | ||||
| 0.0216 | 0.0977 | 0.3122 | 0.0368 | 0.1120 | 0.3330 | ||||
| 0.0060 | 0.0899 | 0.3000 | 0.0064 | 0.0975 | 0.3125 | ||||
| 400 | 0.0085 | 0.0127 | 0.1125 | >1025.5 | 0.0128 | 0.0128 | 0.1128 | 446 | |
| −0.0178 | 0.0193 | 0.1382 | −0.0167 | 0.0203 | 0.1418 | ||||
| 0.0337 | 0.0465 | 0.2133 | 0.0228 | 0.0484 | 0.2191 | ||||
| −0.0084 | 0.0411 | 0.2029 | −0.0027 | 0.0371 | 0.1928 | ||||
| n | Index | Profile MM | Non-Profile MM | ||
|---|---|---|---|---|---|
| SCAD | MCP | SCAD | MCP | ||
| 200 | FDR | 0 | 0 | 0 | 0 |
| PSR | 0.9927 | 0.9387 | 0.996 | 0.9333 | |
| RMSE | 0.1205 | 0.1480 | 0.1182 | 0.1574 | |
| 400 | FDR | 0 | 0 | 0 | 0 |
| PSR | 0.9987 | 0.9740 | 1 | 0.9686 | |
| RMSE | 0.0794 | 0.0927 | 0.0733 | 0.1054 | |
| Method | n | Parameter | Profile MM | Non-Profile MM | ||||
|---|---|---|---|---|---|---|---|---|
| BIAS | MSE | SD | BIAS | MSE | SD | |||
| SCAD | 200 | 0.0242 | 0.0475 | 0.2167 | 0.0279 | 0.0495 | 0.2210 | |
| −0.0639 | 0.1089 | 0.3242 | −0.0510 | 0.0990 | 0.3108 | |||
| −0.0215 | 0.0628 | 0.2501 | −0.0270 | 0.0632 | 0.2502 | |||
| 400 | 0.0143 | 0.0295 | 0.1714 | 0.0026 | 0.0207 | 0.1440 | ||
| −0.0228 | 0.0381 | 0.1941 | −0.0127 | 0.0276 | 0.1658 | |||
| −0.0007 | 0.0357 | 0.1892 | −0.0027 | 0.0285 | 0.1692 | |||
| MCP | 200 | 0.0707 | 0.0692 | 0.2537 | 0.0971 | 0.0702 | 0.2468 | |
| −0.1722 | 0.2078 | 0.4225 | −0.2093 | 0.2544 | 0.4594 | |||
| −0.0619 | 0.0707 | 0.2588 | 0.0571 | 0.0637 | 0.2462 | |||
| 400 | 0.0376 | 0.0388 | 0.1935 | 0.0504 | 0.0358 | 0.1827 | ||
| −0.0735 | 0.0894 | 0.2902 | −0.1179 | 0.1421 | 0.3584 | |||
| −0.0348 | 0.0334 | 0.1796 | −0.0262 | 0.0329 | 0.1796 | |||
| Covariate | Detailed Description |
|---|---|
| Trt | treatment, 1 = Standard 2 = test |
| Celltype | Squamous, smallcell, adeno, large |
| Time | Survival time |
| Status | Censoring status |
| Karno | Karnofsky performance score (100 = good) |
| Diagtime | Months from diagnosis to randomisation |
| Age | In years |
| Prior | Prior therapy (0 = no, 10 = yes) |
| Variable | MLE | SE | CI1 | CI2 |
|---|---|---|---|---|
| karno | −0.0532 | 0.0105 | [−0.0741,−0.0329] | [−0.0714,−0.0363] |
| squamous vs. large | −0.1814 | 0.6382 | [−1.4255,1.0761] | [−1.2761,0.8135] |
| small vs. large | 1.3827 | 0.4816 | [0.4820,2.3699] | [0.6734,2.2438] |
| adenovs large | 1.3138 | 0.4691 | [0.4521,2.2910] | [0.6341,2.1755] |
| Variable | MLE | SE | CI1 | CI2 |
|---|---|---|---|---|
| karno | −0.0532 | 0.0106 | [−0.0746,−0.0329] | [−0.0722,−0.0377] |
| squamous vs. large | −0.1814 | 0.6589 | [−1.4696,1.1134] | [−1.2175,0.8777] |
| small vs. large | 1.3827 | 0.5105 | [0.4431,2.4442] | [0.6459,2.2644] |
| adeno vs. large | 1.3138 | 0.4659 | [0.4654,2.2919] | [0.6267,2.1613] |
| Variable | (Bennett [3]) | (Pettitt [5]) | (Murphy et al. [7]) | (Lam & Leung [11]) |
|---|---|---|---|---|
| karno | −0.053 | −0.055 | −0.055 | −0.053 |
| squamous vs. large | −0.181 | −0.177 | −0.217 | −0.247 |
| small vs. large | 1.383 | 1.438 | 1.440 | 1.367 |
| adeno vs. large | 1.314 | 1.302 | 1.339 | 1.316 |
| Variable | Profile MM | Non-Profile MM | ||||
|---|---|---|---|---|---|---|
| MLE | SCAD | MCP | MLE | SCAD | MCP | |
| trt | −0.0141 | 0 | 0 | −0.0141 | 0 | 0 |
| squamous vs. large | −0.0348 | 0 | 0 | −0.0348 | 0 | 0 |
| small vs. large | 1.2412 | 1.1960 | 1.1944 | 1.2412 | 1.1873 | 1.1859 |
| adeno vs. large | 1.3251 | 1.3653 | 1.3670 | 1.3250 | 1.3596 | 1.3593 |
| karno | −0.0597 | −0.0582 | −0.0590 | −0.0597 | −0.0589 | −0.0590 |
| diagtime | −0.0025 | 0 | 0 | −0.0025 | 0 | 0 |
| age | −0.0141 | 0 | 0 | −0.0141 | 0 | 0 |
| prior | −0.1663 | 0 | 0 | −0.1663 | 0 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Xiong, C.; Jiang, T.; Lu, J.; Xu, J. Efficient Estimation and Inference in the Proportional Odds Model for Survival Data. Mathematics 2022, 10, 3362. https://doi.org/10.3390/math10183362
Huang X, Xiong C, Jiang T, Lu J, Xu J. Efficient Estimation and Inference in the Proportional Odds Model for Survival Data. Mathematics. 2022; 10(18):3362. https://doi.org/10.3390/math10183362
Chicago/Turabian StyleHuang, Xifen, Chaosong Xiong, Tao Jiang, Junfeng Lu, and Jinfeng Xu. 2022. "Efficient Estimation and Inference in the Proportional Odds Model for Survival Data" Mathematics 10, no. 18: 3362. https://doi.org/10.3390/math10183362