1. Introduction
Electricity is one of the most important basic energy sources in the world. It can provide basic support for industrial production and processing, and sustain people’s daily life. Since there is no high-quality storage carrier for electric energy at this stage, low storage efficiency occurs when battery packs or pumped energy storage power stations are solely adopted. Therefore, power generation should be roughly equal to the demand, otherwise it will lead to consequences like the wasting of resources [
1]. In addition, thermal power generation is the main way of generating electricity in most parts of the world, so excessive power generation will also cause serious environmental pollution. Furthermore, in the course of modern electric power development, there have been numerous incidents of insufficient power supply and shortage of power which seriously affected China’s economic and social development. In the United States, from 14 February 2021 on, widespread rolling blackouts in Texas amid extremely cold weather left millions of people living without electricity. About 30% of the power generating units in Texas were off-grid during the extreme weather. Moreover, starting on 23 September 2021, many places in Northeastern China issued notifications of power rationing and implemented the policy of orderly power consumption for non-residents. The occurrence of the above-mentioned events was caused by insufficient power supply to a certain extent. However, at the same time there existed inappropriate prior power dispatching caused by the inaccurate estimation of power demand. It can be seen that the supply capacity of the power industry is closely related to the national macroeconomic development. If the total power required by a population can be predicted in advance, the waste of power resources can be avoided to the greatest extent. The economic benefits of power enterprises can be improved and damage to the environment can be reduced. The ever-increasing demand for power resources has also led to higher requirements for power operation and management. Any deviation will bring incalculable losses. At this stage, China’s “smart grid” is developing at rapid speed. The construction of power facilities, power supply and power sales all depend on accurate forecasts of power demand [
2].
Power demand forecasting refers to making predictions about the electricity demand of the electricity market in the future. Generally, it is divided into three categories according to the time span: short-term forecasting, medium-term forecasting and long-term forecasting. Short-term forecasting generally refers to forecasting using the day as the smallest unit. Commonly used methods include the linear recursive least squares method and the state space method based on a Kalman filter, etc. [
3]. Medium-term forecasting generally refers to forecasting based on months or quarters as the smallest unit. Commonly used methods include the seasonal index method and the ARIMA model method [
4]. Long-term forecasting generally refers to forecasting by year as the smallest unit, and the commonly used methods mainly include the moving average method and the neural network method [
5]. From the perspective of forecasting characteristics, the amount of historical data utilized in short-term forecasting is relatively large, and it will be affected differently during different holidays, so comprehensive consideration is needed in forecasting; the data of medium-term forecasting has obvious seasonal characteristics, so it is necessary to carry out forecasting in combination with this feature. For long-term forecasting, due to limited historical data and many external interference factors, it is necessary to fully mine data characteristics during forecasting so as to obtain better forecasting results. With regard to short-term forecasting, it can provide corresponding decision-making guidance for real-time grid dispatching [
6]; while long-term forecasting can provide data support for expansion of both the grid and its capacity on the basis of guiding power system planning and construction [
7].
In the past, power forecasting technology mainly applies to time series in statistics [
8], multiple linear regression [
9], ARIMA [
10], and other methods. Due to their simplicity in theory and because they require less amounts of calculation, these methods are more frequently applied in the initial research on power forecasting. However, it is to carry out forecasting in combination with external factors, thus the forecasting accuracy is largely limited, which makes it difficult to meet the actual needs. Since the 1980s, researchers begin to introduce intelligent algorithms from other fields into electricity forecasting. In 1991, PARK D. C. and other scholars first used artificial neural networks for power prediction and achieved satisfactory results [
11]. Compared with traditional statistical prediction methods, artificial intelligence technology can analyze and learn from a large amount of data in a short period of time, and significantly improve the prediction accuracy, which has obvious advantages.
At present, the methods adopted by domestic researchers more often refer to neural networks [
12,
13,
14], support vector machines [
15], and the joint model [
16]. Reference [
17] proposes a power demand forecasting model based on a second-order gray neural network. First, the wavelet sequence is used to perform stationarity processing on the original data set, and then the power demand is predicted using a second-order gray neural network. Reference [
18] adopts the grayscale model of a neural network to predict the power demand, and obtains a relatively good prediction effect. Reference [
19] proposes a LSSVM_PSO model for power demand forecasting. The model utilizes a particle swarm optimization algorithm to adjust the learning rate to reduce the prediction error of the support vector machine and improve its reliability. Compared with the least squares support vector machine, this method achieves higher convergence rates and prediction performance. Reference [
20] combines the feedback of the neural network and ARMA models to predict the power generation of wind power plants, and this model achieves high accuracy and interpretability. Reference [
21] proposes a power load forecasting model based on extreme gradient enhancement to solve the problem whereby traditional forecasting models have difficulty in dealing with massive data when power data grows exponentially in some cases. Through the analysis of meteorological factors and the long-term regularity of the daily power load, the model achieves higher prediction accuracy and smoother prediction error compared with traditional machine algorithms. Reference [
22] combines the two models of Xgboost and ARMA, and uses the power consumption data of enterprise users to make predictions. Through a series of comparative experiments, it is found that this method achieves more accurate prediction results than traditional methods.
Through the above analysis, and in view of the problems that short- and medium- term power data is less informative and difficult to predict, after considering the impact of meteorological factors on power consumption, this paper integrates LGB, XGB and GBDT, and fully explores the correlation between electricity demand and weather data through the integrated model. The model is trained by using the time series relationship existing in the data so as to obtain a more accurate prediction effect.
3. Methodology
3.1. Boosting and Decision Tree
Ensemble learning completes the learning task by constructing and combining multiple learners. By combining multiple learners, it is often possible to obtain significantly better generalization performance compared to a single learner. There are three common ensemble learning ideas, including bagging, boosting, and stacking.
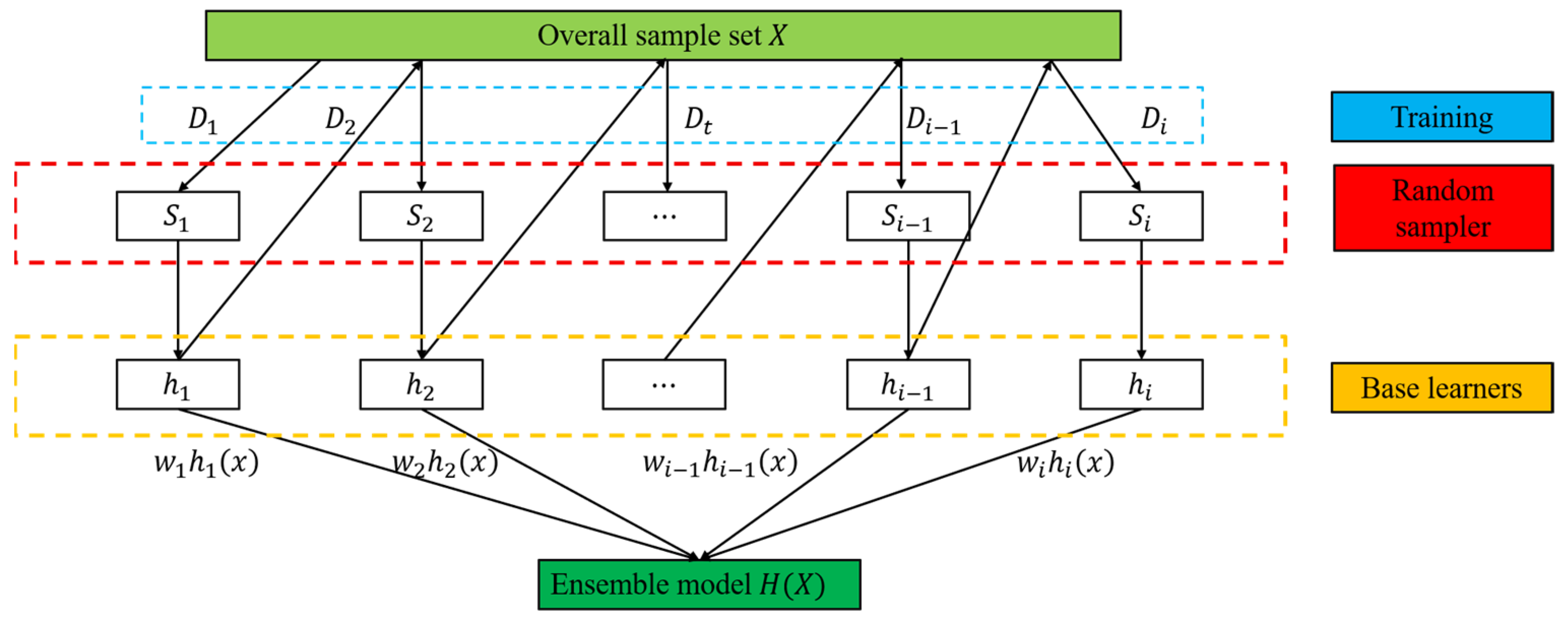
Boosting is a kind of algorithm that can upgrade a weak learner to a strong learner. The working mechanism is as follows: firstly, train a base learner from the initial training set, and then adjust the distribution of training samples according to the performance of the base learner, so that the training samples made by the previous base learner will receive more attention in the follow-up. The next base learner is then trained based on the adjusted sample distribution. This is repeated until the number of base learners reaches the specified value
, and finally the
base learners are weighted together. The flow chart of the algorithm is shown in
Figure 2:
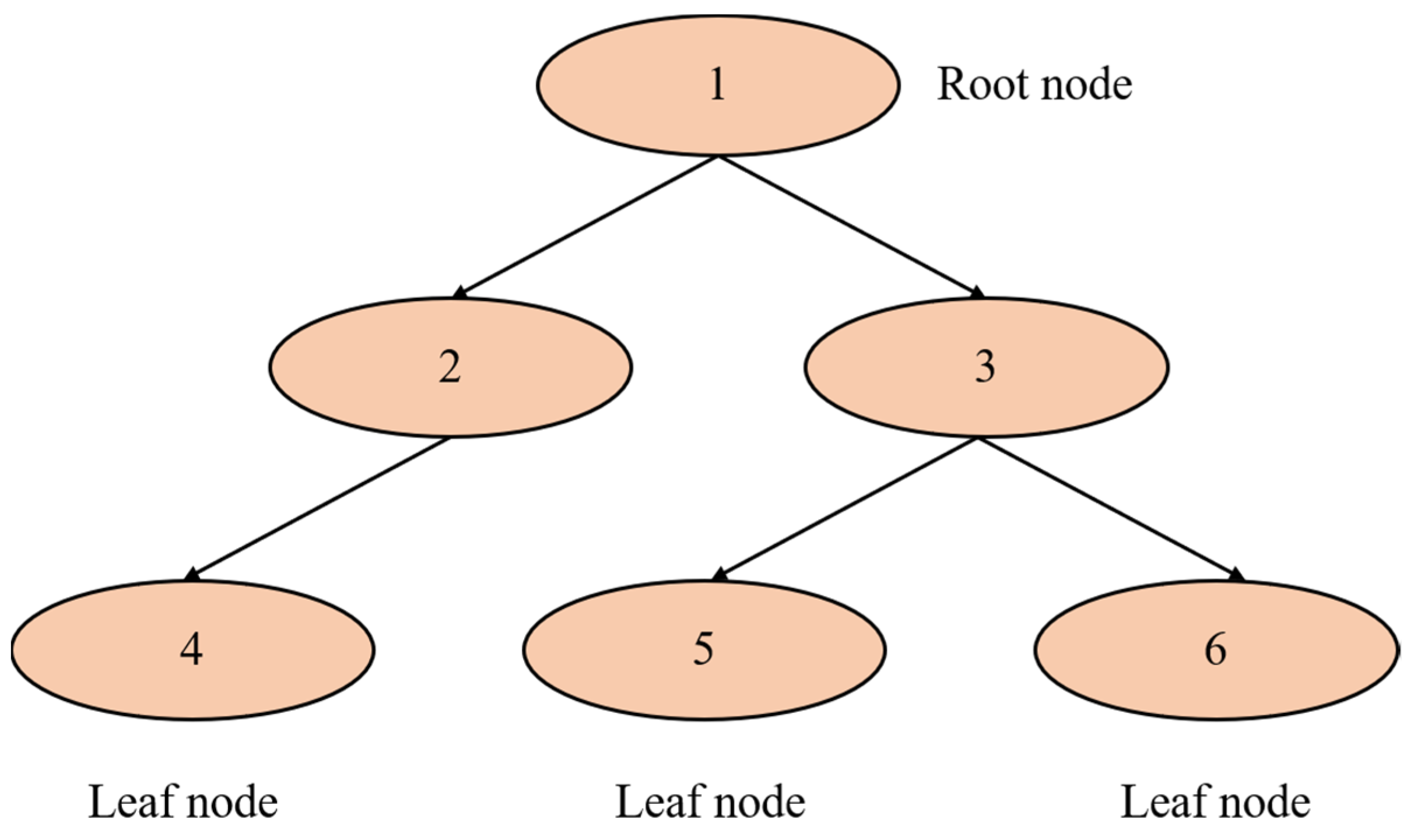
A decision tree is an important model in ensemble learning, and its core is a tree structure, as shown in
Figure 3. The figure represents the mapping relationship between object attributes and object values. The root node and inner node represent the segmentation of features, and each branch denotes the output of the feature corresponding to the parent node in the regional space here.
Decision trees are generally divided into classification trees and regression trees. Classification trees are often used in class division, while regression trees are often used in numerical prediction [
24]. During the growth of the regression tree, each leaf node can get a predicted value, and the threshold of each feature value is exhausted during segmentation. The optimal segmentation variable and optimal segmentation point are found by minimizing the squared error, and then the minimized square error is utilized to find the most credible segmentation basis so as to ensure that the predicted value of the current branch node is unique, or at a certain artificial threshold. If the data of each leaf node is not unique, the average value of the node data is used as the predicted value.
The growth of the above regression tree generally has the following five steps:
Step 1: Enter the training data set, as follows:
Step 2: Traverse all feature variables
. When the fixed segmentation variable
is encountered, segmentation point
is scanned.
At this time, the optimal segmentation variable and the segmentation point with the smallest overall square error loss are obtained.
Step 3: After the segmentation scheme at the value
of the first attribute
is obtained, calculate the output of the two sub-regions:
Step 4: Continue to call steps 2 and 3 for the two sub-regions to find the optimal variable characteristics of each branch node. The growth of the regression tree ends when all regions meet the threshold or exhaust all attributes for its growth.
Step 5: The input space is divided into M regions,
, and there is a fixed output value
in each divided unit region. The final decision tree is generated as follows:
3.2. Gradient Boosting Decision Algorithm
The gradient boosting decision algorithm is a representative algorithm in the boosting series of algorithms, which consists of multiple decision trees, and the conclusions of all trees are accumulated as the final answer [
25]. The main idea of the gradient boosting decision tree is to take advantage of the squared error to denote the loss function, in which each regression tree learns the conclusions and residuals of all previous trees, and fits a current residual regression tree. The residual is the difference between the true value and the predicted value. The boosting tree is the accumulation of the regression trees generated by the entire iterative process. However, the gradient boosting decision tree requires that the weak learner must be a CART regression tree model, and GBDT requires that the sample loss predicted by the model be as small as possible during model training. The process of using GBDT as a regression algorithm to predict the power demand is as follows:
Assume that the training set samples are , the maximum number of iterations is , the loss function commonly uses mean square error function , and the output is the strong learner . The regression algorithm process is as follows:
Step 1: Initialize the weak learner. The mean of
can be set to the mean of the sample
.
Step 2: For the number of iterations
, calculate the negative gradient for samples
.
Step 3: Use to fit a CART regression tree to get the th regression tree. Its corresponding leaf node area is , where is the number of leaf nodes of the regression tree .
Step 4: With regard to the leaf region
, there is the best fitting value at this time.
Step 5: Update the strong learner.
Finally, the expression of the strong learner
is obtained:
GBDT can be applied to most regression problems [
26,
27]. For dense data such as electricity demand, a variety of distinguishing features and feature combinations can be found through this model, which has strong generalization and expression ability to achieve a better fitting effect.
3.3. LightGBM Model
In order to improve model training efficiency and reduce memory consumption, based on the traditional GBDT algorithm, the Light Gradient Boosting Machine (LightBGM) algorithm is proposed [
28]. The pre-sorting algorithm commonly used in the boosting algorithm performs feature selection and splitting. This method can accurately find the splitting point, but the memory usage and computational cost are high. Therefore, the LightBGM algorithm uses Histogram to improve the speed of processing training samples. The Histogram algorithm constructs a piecewise function in advance before training, converts continuous eigenvalues into
discrete bin values, and then establishes a histogram containing
items. The constructed histogram is utilized to traverse the training samples. During this process, the LightBGM algorithm accumulates statistics in the histogram according to
discrete values and finally finds the best split point from the discrete values. This method can significantly reduce the computational memory and computational cost, and significantly improve the computational speed.
In addition, the leaves of the GBDT algorithm use a level-wise growth method, which does not distinguish the leaves of the same layer. However, in fact, the split of many leaves brings a low gain, which brings the waste of computing resources and memory resources [
29]. In response to this problem, the LightBGM algorithm adopts a more efficient Leaf-wise algorithm that grows according to leaves. It splits by finding the largest splitting gain from a certain layer of leaves and repeats it continuously, which enables the algorithm to achieve higher accuracy under the same number of splits. Meanwhile, overfitting can be avoided by limiting the depth of the tree when the sample size is small.
It can be seen from the above that the LightBGM algorithm, based on the core idea of the GBDT algorithm, improves the feature splitting process and tree growth method by introducing a new method, which makes the model simpler, requires less computational cost, and achieves more accurate predictions.
3.4. XGBoost Algorithm
Based on the decision tree boosting optimization model, the XGBoost algorithm converts weak learners into strong learners through iteration [
29]. In the XGBoost algorithm, the CART regression tree is used as a weak learner to first determine the optimal structure of the tree, such as the number of leaf nodes and the depth of the tree. Next, the distributed forward additive model is adopted. Each time a single tree is generated, the weight of the last misclassified data is increased and used for the current tree, and the overall error of the model is gradually reduced by continuously adding trees until the end of training [
30].
When the XGBoost algorithm is adopted to train samples, the model for each tree is as follows:
In the equation,
is the leaf node score value.
represents the input sample data,
denotes the leaf node corresponding to the sample
, and
is the number of leaf nodes of the tree. The equation for adding the
th tree to the model is as follows:
To train a single CART tree [
31], the objective function needs to be determined first:
The objective function is divided into two parts, including loss function
and regularization
. For regression, the loss of the square of the residual between the predicted value and the true value, that is, the L2 loss, is generally used to evaluate the degree of model fitting, and the regularization term acts as a penalty term for the model to prevent overfitting. The regularization term is defined as:
In the equation,
refers to the number of leaf nodes and
refers to the
regularity of leaf node scores.
and
are used to control the complexity of the tree. From this, the regularization term can be calculated. Equations (12), (13), and (15) are brought into the objective function, and the second-order Taylor formula is used to obtain the form of the leaf node of the
th tree, which is as follows:
Let
,
. Bring them into Equation (16) and obtain the partial derivative of the objective function with respect to
. Set the value of the derivative function to 0, and obtain:
Bring it into the objective function and obtain:
This paper used to evaluate the quality of a single CART regression tree structure. XGBoost enumerated the splitting schemes of all features from the tree with a depth of 0 and calculated its objective function value to determine the optimal structure of the tree. When the tree reached the maximum depth and the sum of the sample weights was less than the set threshold, the establishment of the decision tree was stopped. The sampling ratio of each tree was controlled by the set parameters, and the structure training process of a tree was finally optimized through parameter adjustment.
XGBoost applied boosting to carry out the next round of training after training one tree, obtaining the optimized training model structure through continuous iteration. After one iteration, XGBoost multiplied the weight of the leaf node and the learning rate, thereby weakening the influence of each tree and providing a larger learning space for subsequent trees. Finally, the optimal number of iterations of the model was determined, and the training of the model was completed.
3.5. LR Model
The LR model is mainly represented by a conditional probability distribution
in the form of a parameterized logistic distribution. Among them, the value range of
as a random variable is a real number, and the value range of
as a random variable is 1 or 0. The conditional distribution of the LR model is as follows:
In the equation,
refers to the input,
refers to the output,
and
are the parameters,
is the weight vector,
is the bias, and
is
w and the inner product of
.
For a given input , and can be solved according to Equations (19) and (20). Logistic regression compares two conditional probability values and finds a class with a larger probability value, thereby assigning input to that class.
The weight vector
and the input vector
are extended to get
,
. At the moment, the LR model is as follows:
The probability of an event occurring divided by the probability of an event not occurring is the probability of the event. At this time, assume that the probability of an event occurring is
, the probability of it not occurring is
, thus the probability of the event is
. The logarithmic probability of the event is as follows, which can also be called the logit function.
For logistic regression, the following equation can be obtained from Equations (21) and (22).
It can be seen from the above equation that in the LR model, the logit function with the output has a linear relationship with the input . The value domain of the linear function is the real number domain, and the input can be split by a linear function.
Since
,
, the linear function
can be converted into a probability by taking advantage of Equation (19):
When the linear function
infinitely approaches positive infinity, the value of the conditional probability approaches 1; when the linear function
infinitely approaches negative infinity, the value of the conditional probability approaches 0.
A training dataset
, where
,
, is given. The maximum likelihood estimation method is used here to estimate the LR model parameters.
At this moment, the likelihood function is
, and the log-likelihood function is
The estimated value of can be obtained by solving the local maximum of Equation (28).
Next, we optimize the objective function, which is the log-likelihood function. In logistic regression, gradient descent and quasi-Newton methods are often used. Assume that
is the maximum likelihood estimate of
, and the resulting LR model is
Due to the limited learning ability of the LR model, it is often necessary to combine it with other models [
32]. Corresponding feature combinations are obtained by other models through training, and then the LR model gives the corresponding predicted values.
4. Power Demand Forecasting Model Based on Stacking
In view of the fact that no single model can meet the requirements of training performance and stability well, this paper attempts to use the Stacking to synthesize the advantages of various boosting models [
33]. Moreover, combining it with the LR regression model enables the fusion model to have strong discrimination and stability, and does not require too frequent iterations on the basis of achieving good results.
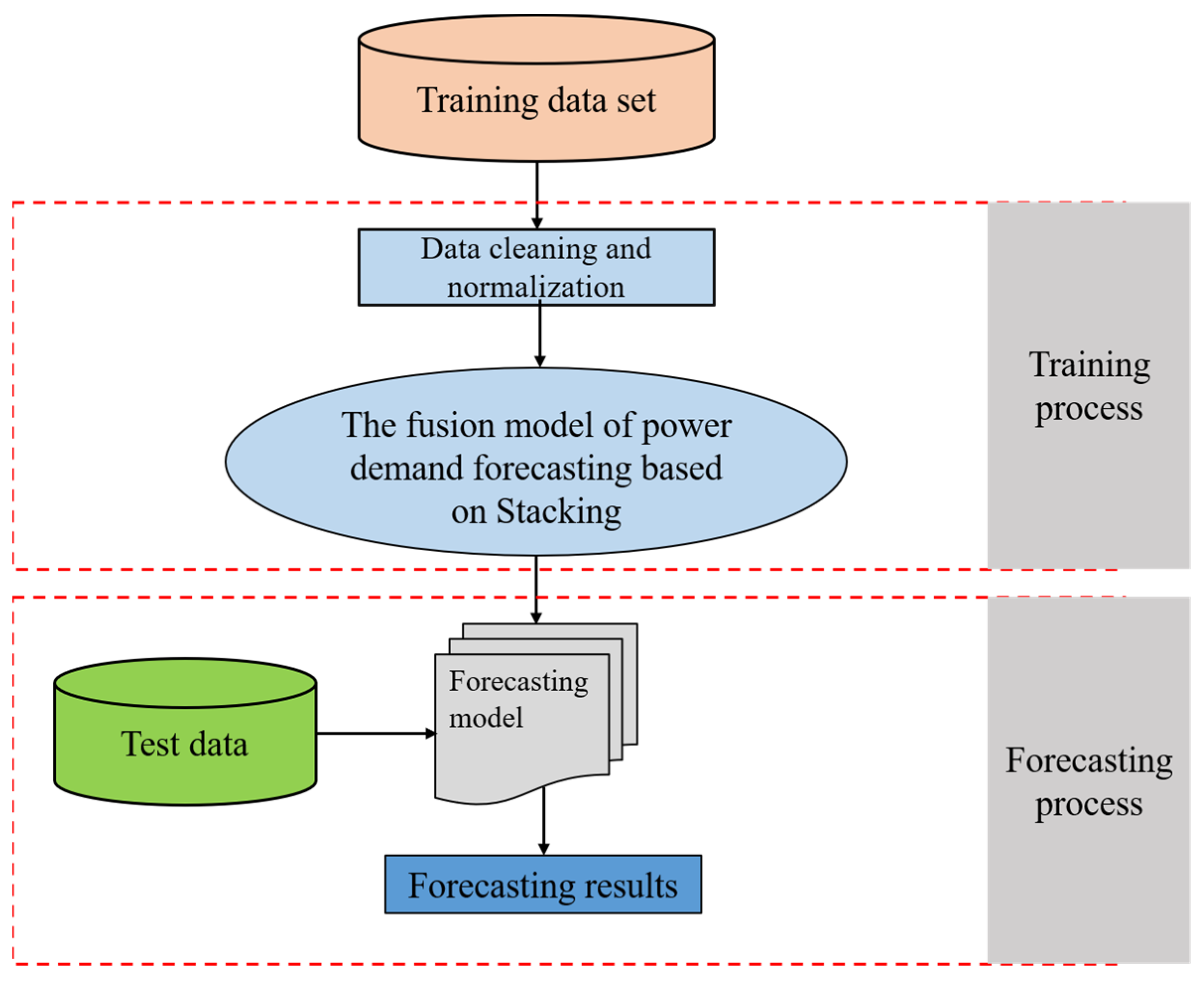
The overall design of model training and testing in this study is shown in
Figure 4. First, the original data is cleaned and normalized, and then the power demand forecasting model based on stacking is trained to obtain the corresponding forecasting model. Next, the test data is used for prediction.
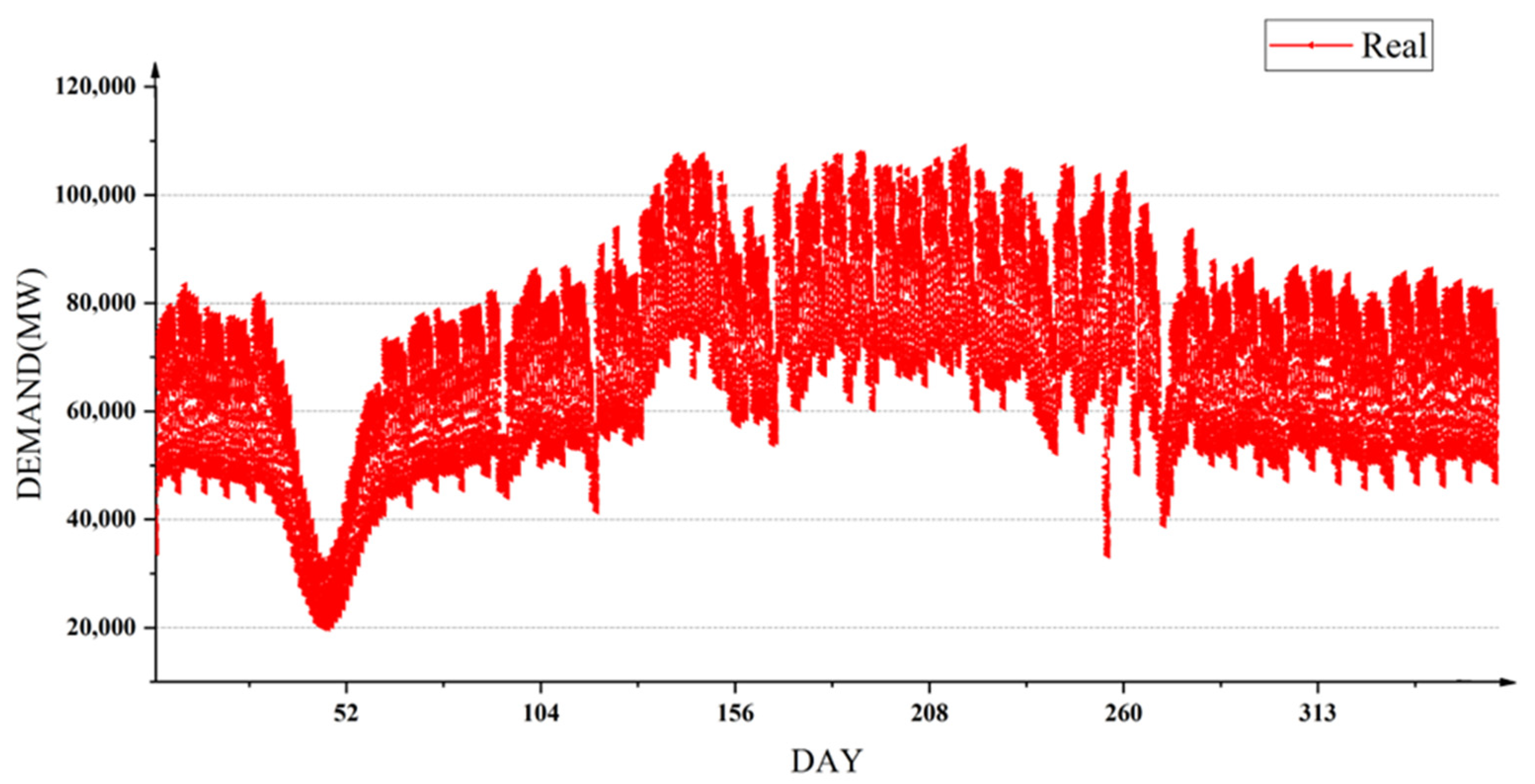
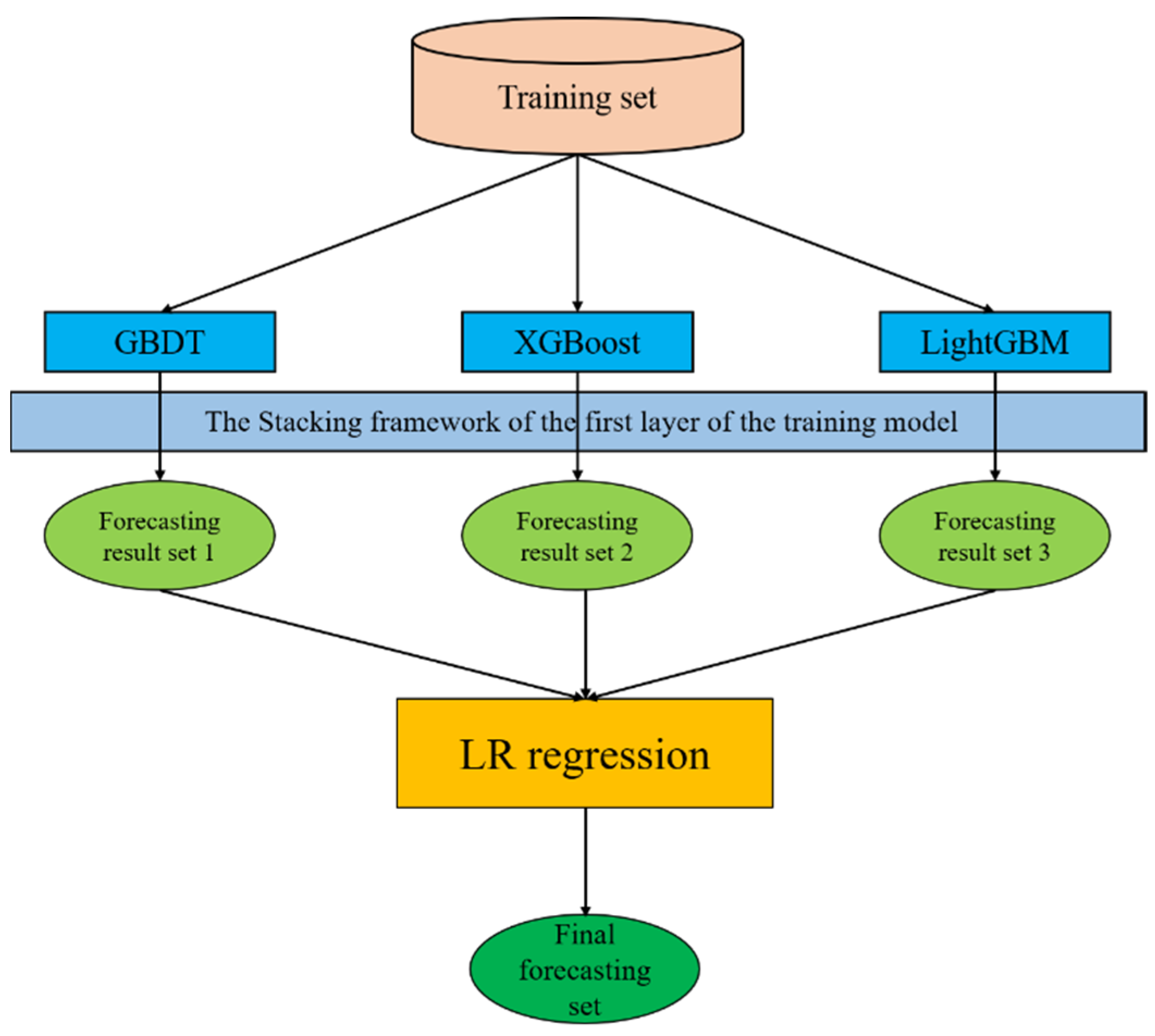
The process of model training is then described in detail. Through the previous analysis, it can be found that the power demand data involved in this study has strong regularity in the time series when they are divided by day, month and season after the data on special holidays is removed. Meanwhile, the amount of data is limited, so the model based on decision tree is more suitable for solving this kind of problem. Three models, including GBDT, XGBoost and LightGBM, have their own advantages and disadvantages in predicting different scenarios. The fusion of the three models can achieve a joint gain effect. Stacking is an ensemble framework for hierarchical models [
34]. The first layer is composed of a number of different base learners. This paper selected three models, including GBDT, XGBoost and LightGBM. When each model was adjusted to achieve good results, they were integrated to predict, thereby reducing the deviation of the model and achieving better results. The LR regression model was selected for the second layer, which further avoided the occurrence of overfitting, effectively reduced the variance of the model, and made the model more stable. The specific steps of the power demand forecasting model based on stacking are as follows:
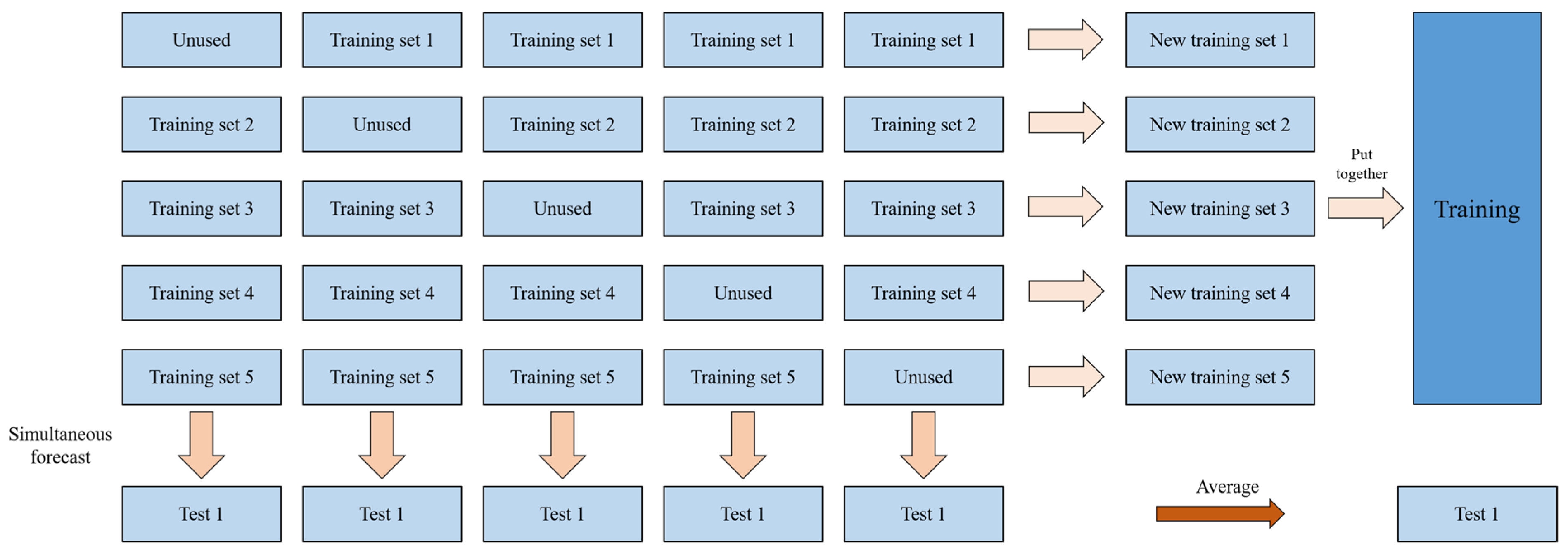
Step 1: First, the overall data set consisting of meteorological factor and power demand was divided into training data (training set) and prediction data (testing set). Then the training samples were divided into groups of data with the same amount.
Step 2: The training data set was trained multiple times with each base learner. Each training utilized pieces of data as training samples, and the remaining one was used as a validation set. The data of meteorological factor in the validation set was utilized to predict power demand, so as to obtain copies of the prediction data through the validation set. In addition, the prediction samples would be predicted during each training process to obtain copies of prediction data. It should be noted that only the training set needs to do this step. The validation set and test set do not need it.
Step 3: Combine the
pieces of prediction data obtained through the validation set to get new training sample data. The obtained
pieces of prediction data were averaged to obtain new prediction data. The specific process is shown in
Figure 5.
Step 4: Input the data obtained in Step 3 into the second layer, and finally get the final prediction result. The process is shown in
Figure 6.
The power demand model constructed in this paper used GBDT, XGBoost and LightGBM, the three boosting models in the first layer of the stacking framework. The second layer of the stacking framework adopted the LR model to directly output the prediction results. The overall framework of the model is shown in
Figure 6.
The optimal parameters of each basic model are summarized in
Table 2. In this study, some key hyperparameters in GBDT, XGBoost, and LightGBM algorithms were adjusted, as shown in
Table 2.
Table 2 also explains the specific meaning of these hyperparameters. According to the maximum average precision, the best value of each set of hyperparameters is obtained, as shown in
Table 2.
6. Discussion
It can be seen from the above experiments that although the power demand could be well predicted using GBDT, XGBoost and LightGBM models, the prediction results made by different algorithms under different scenarios were not stable. Two reasons may account for this. One is that the data characteristics in the different scenarios were not the same, which would affect the model training and learning process. The other reason is related to the data set used in this paper having a limited amount of data, which would affect the quality of the data to a certain extent. As data-driven methods, the prediction performance of GBDT, XGBoost, and LightGBM models was greatly affected by the quantity and quality of training data. Therefore, in order to effectively solve these problems, this paper proposes an XLG-LR model for power demand forecasting based on stacking, which effectively solves various problems existing in the single use of GBDT, XGBoost and LightGBM models. Experiments suggest that the XLG-LR model in this paper has achieved high accuracy in different forecasting scenarios, effectively improving the power demand forecasting accuracy.
In recent years, with the continuous development of neural networks, a growing number of scholars have begun to apply neural networks into power demand forecasting [
36], and frequently used models include the gated recurrent unit (GRU) [
37], long short-term memory networks (LSTM) [
38], and the temporal convolutional network (TCN) [
39], etc. In order to verify the advancement and effectiveness of the XLG-LR model, the power demand data of this paper was used to train the above GRU, LSTM, TCN models and the XLG-LR model, and utilized the test set to test the training results.
As a long-term memory neural network, LSTM is widely used for correlation learning and prediction in sequence data. Since the vanishing gradient of recurrent neural network (RNN) hinders the network from learning long-term dependencies, LSTM reduces the occurrence of the problem by introducing the forget gate, input gate and output gate, which can achieve better results. On the basis of this method, Wang et al. [
40] forecast short-term photovoltaic power and this study conducts comparative experiments. Temporal CNN (TCN) is a simple one-dimensional convolutional network that can be applied to time series data. The layers in the network have temporal properties and are used to learn global and local features of the data. Convolutional layers also help improve model latency, allowing prediction to conduct parallel processing. Based on this method, Wang et al. [
41] predicts the short-term electricity consumption of industrial users, and this study carries out comparative experiments. As for the GRU model, more attention is paid to the role of gate control, especially the feature weight introduced into its formula to enhance the ability to extract data features. Based on the method, Gao et al. [
42] carries out short-term power load forecasting. A power load in the next 48 h with one hour as a unit is predicted. In this study, a comparative experiment is conducted on the basis of this method.
During the comparison, the relevant parameters in the GRU, LSTM and TCN models need to be set. The parameter settings of each model are shown in
Table 6 during the comparative experiment stage.
In the training and testing of the power demand forecasting model based on stacking, the input form of data refers to data usage × data feature number. In contrast with this model, when GRU, LSTM and TCN are trained and tested, the form of data input refers to data usage × data feature number × time window length. The size of the time window needs to be adjusted according to the forecast demand of different durations.
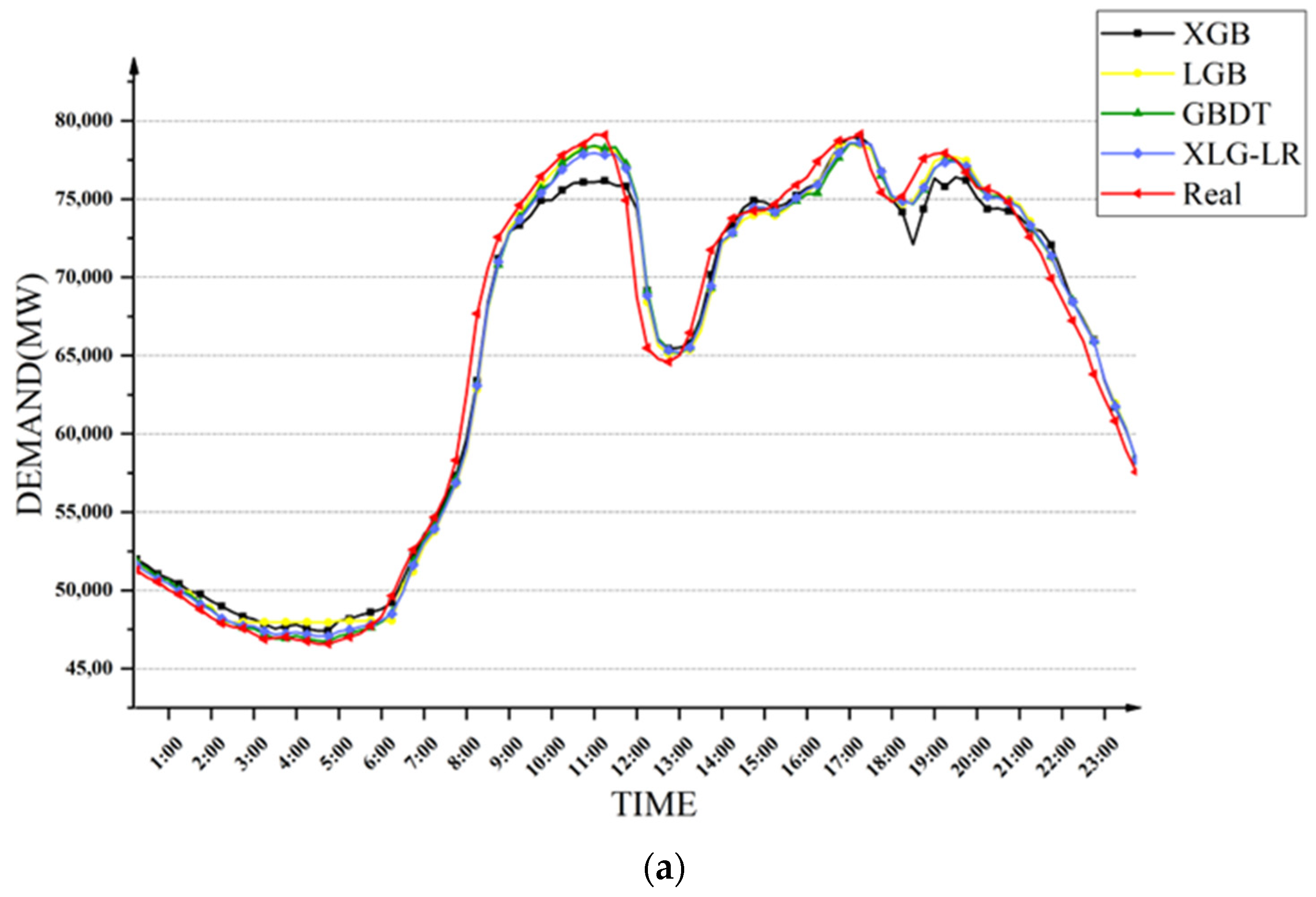
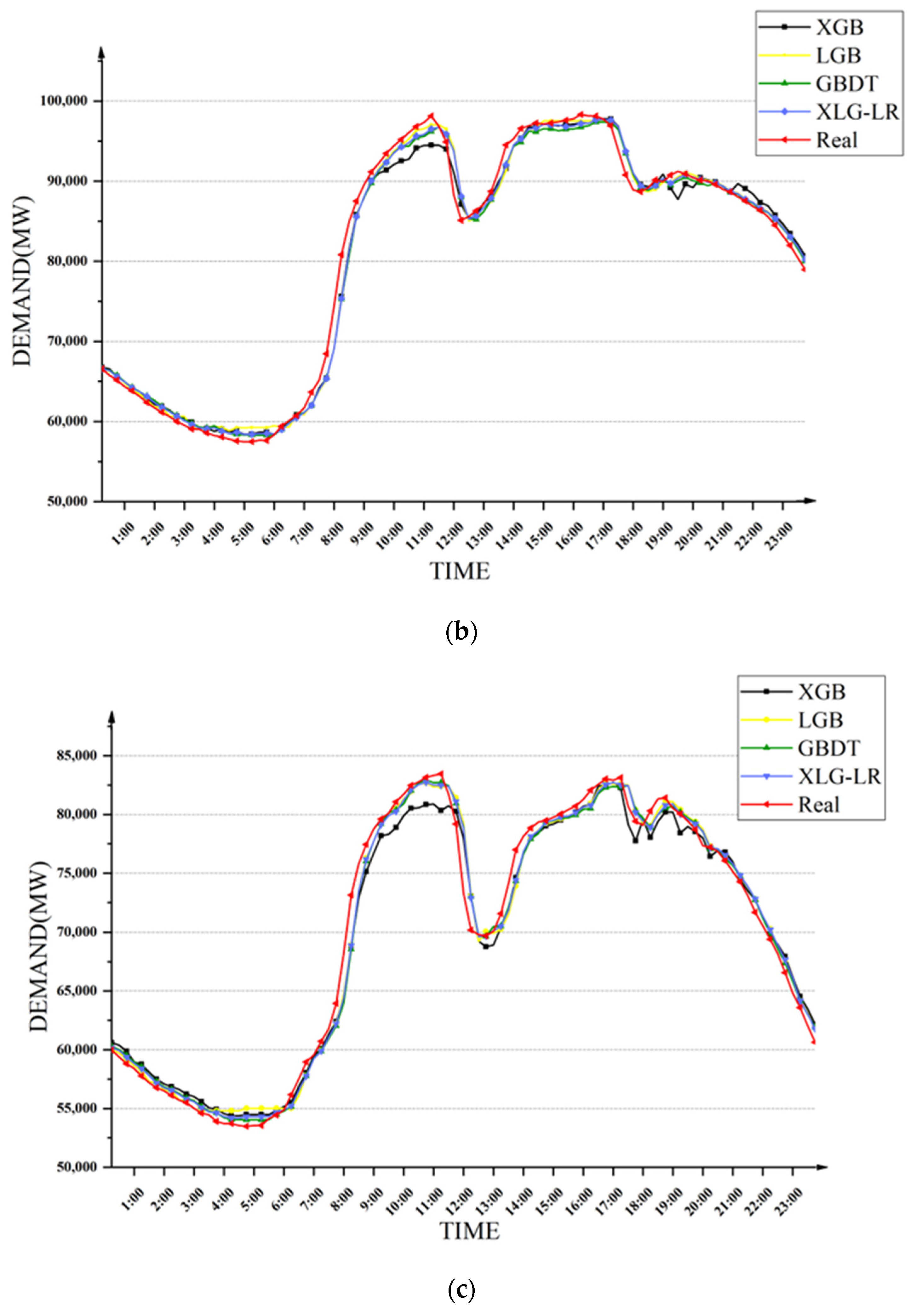
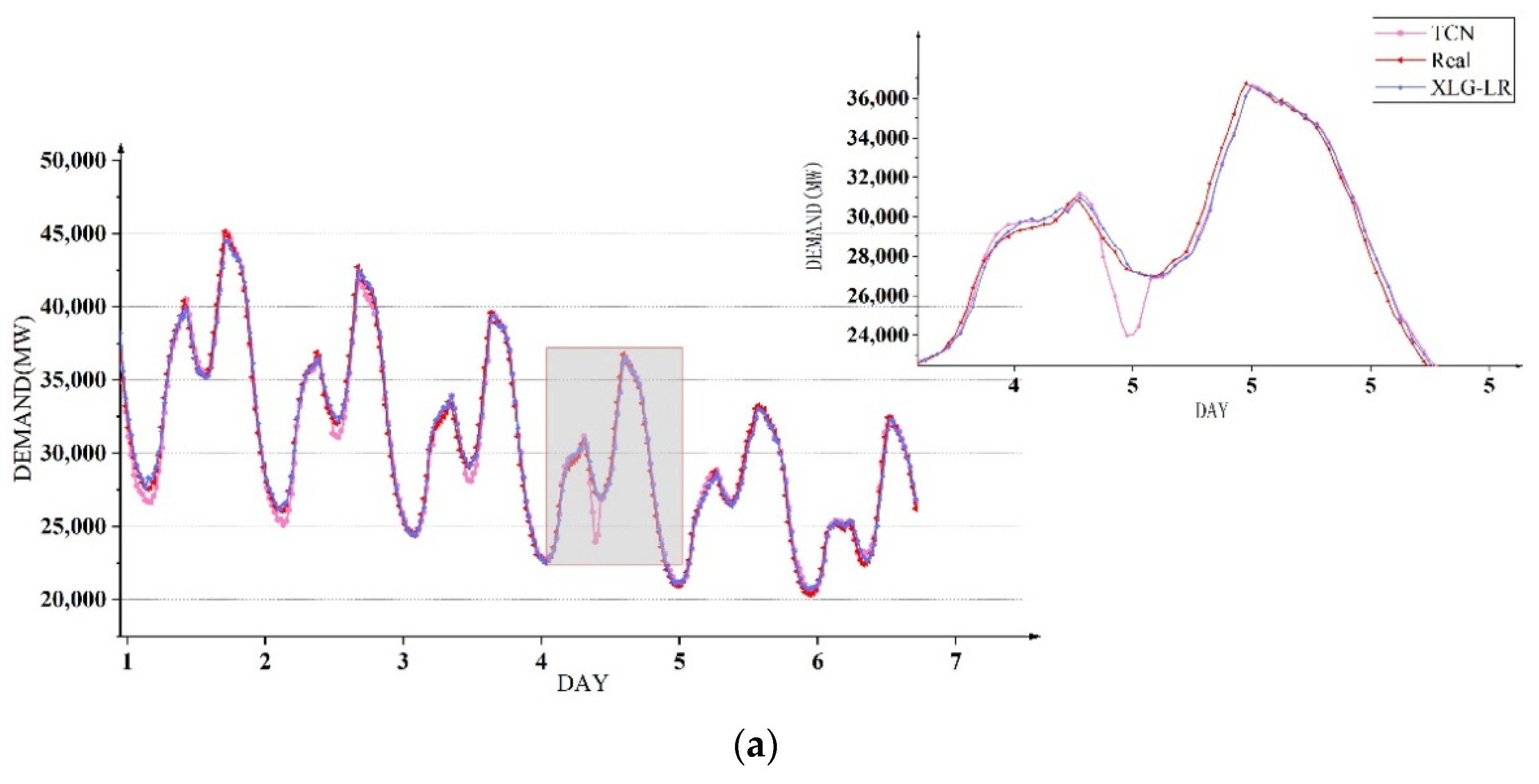
First, four methods were used to compare the seasonal power demand forecasting, and the same training set and test set as
Section 5.2 were utilized to carry out experiments to investigate the accuracy of power demand forecasting in different periods of a day in a certain season. The prediction results of the four models for different seasons of electricity demand are shown in
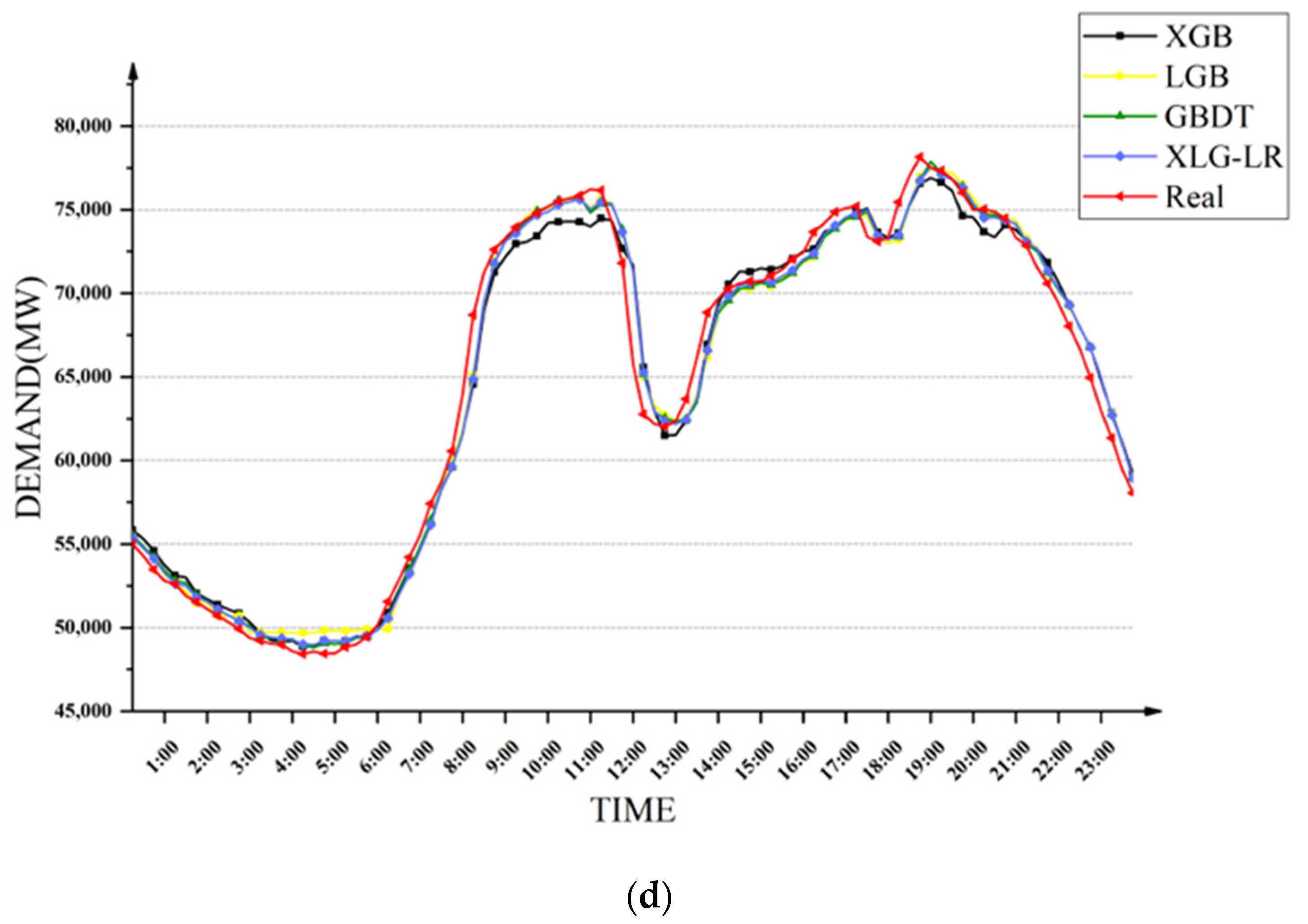
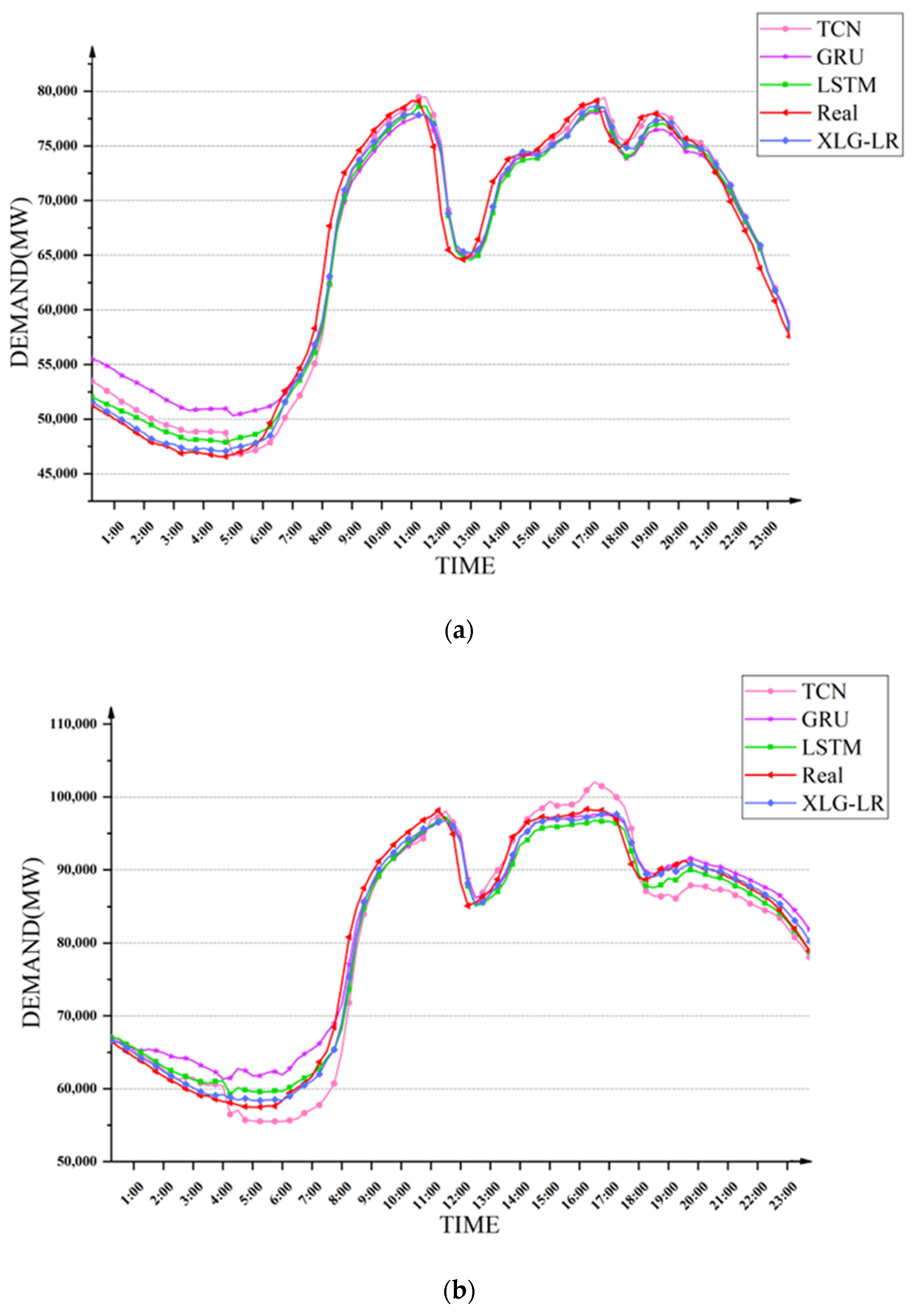
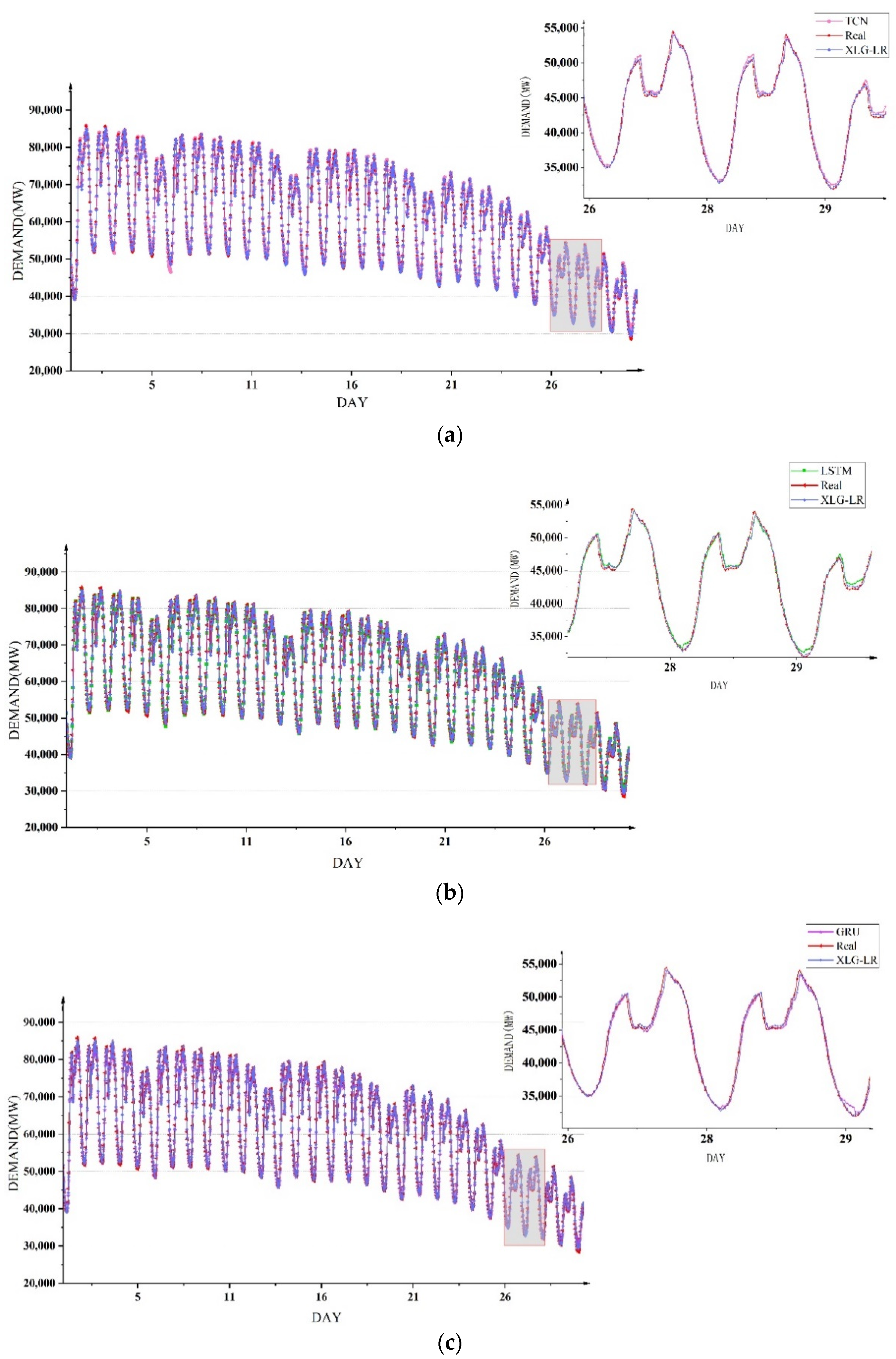
Figure 10. It can be seen that the XLG-LR model was the closest to the true value in most time periods.
The comparison between the XLG-LR model in this paper and the other three neural network methods is shown in
Table 7. It can be seen that compared with the three models of GRU, LSTM and TCN, the XLG-LR model has significant advantages in forecasting power demand in different seasons under the four evaluation indicators.
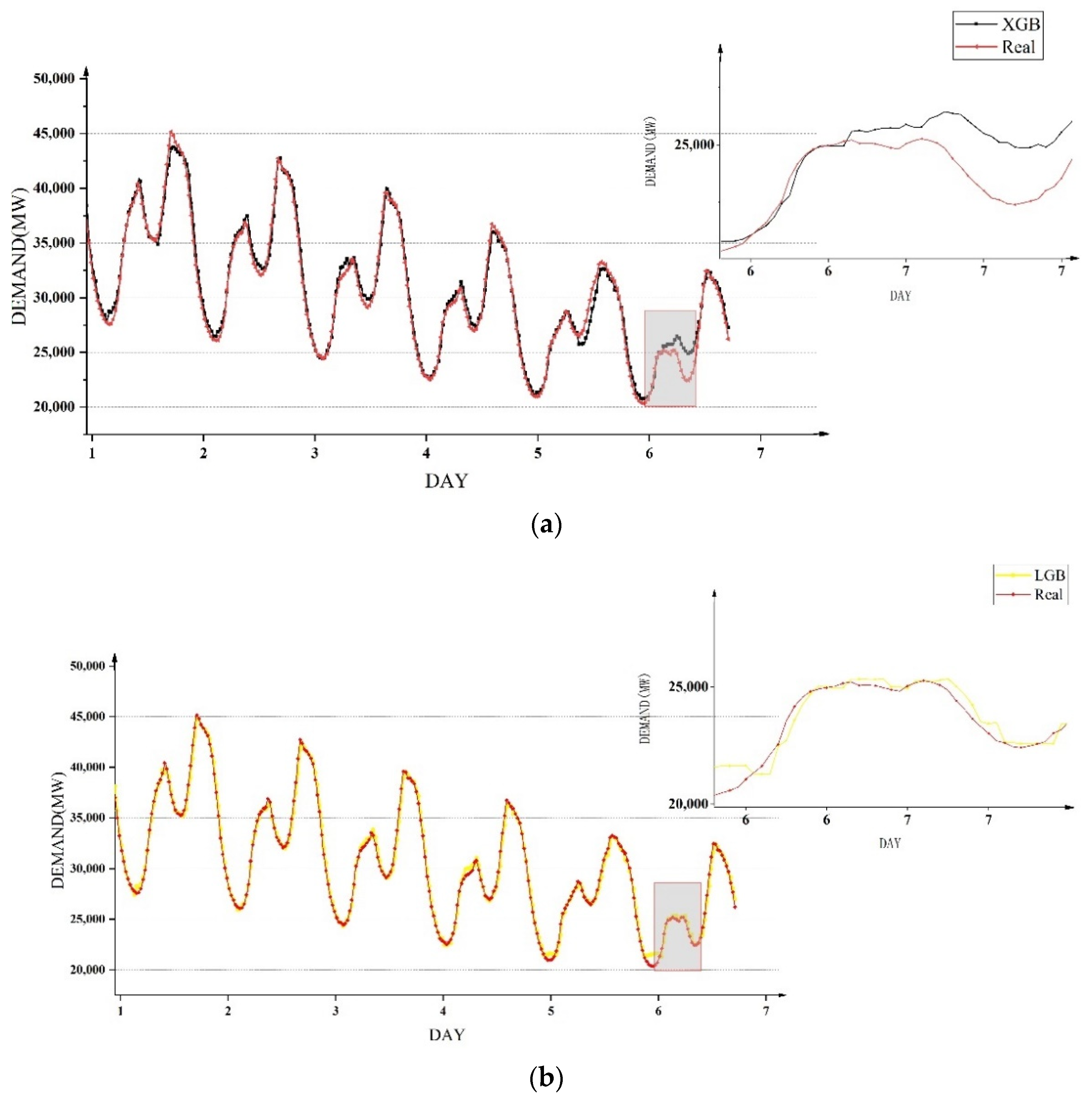
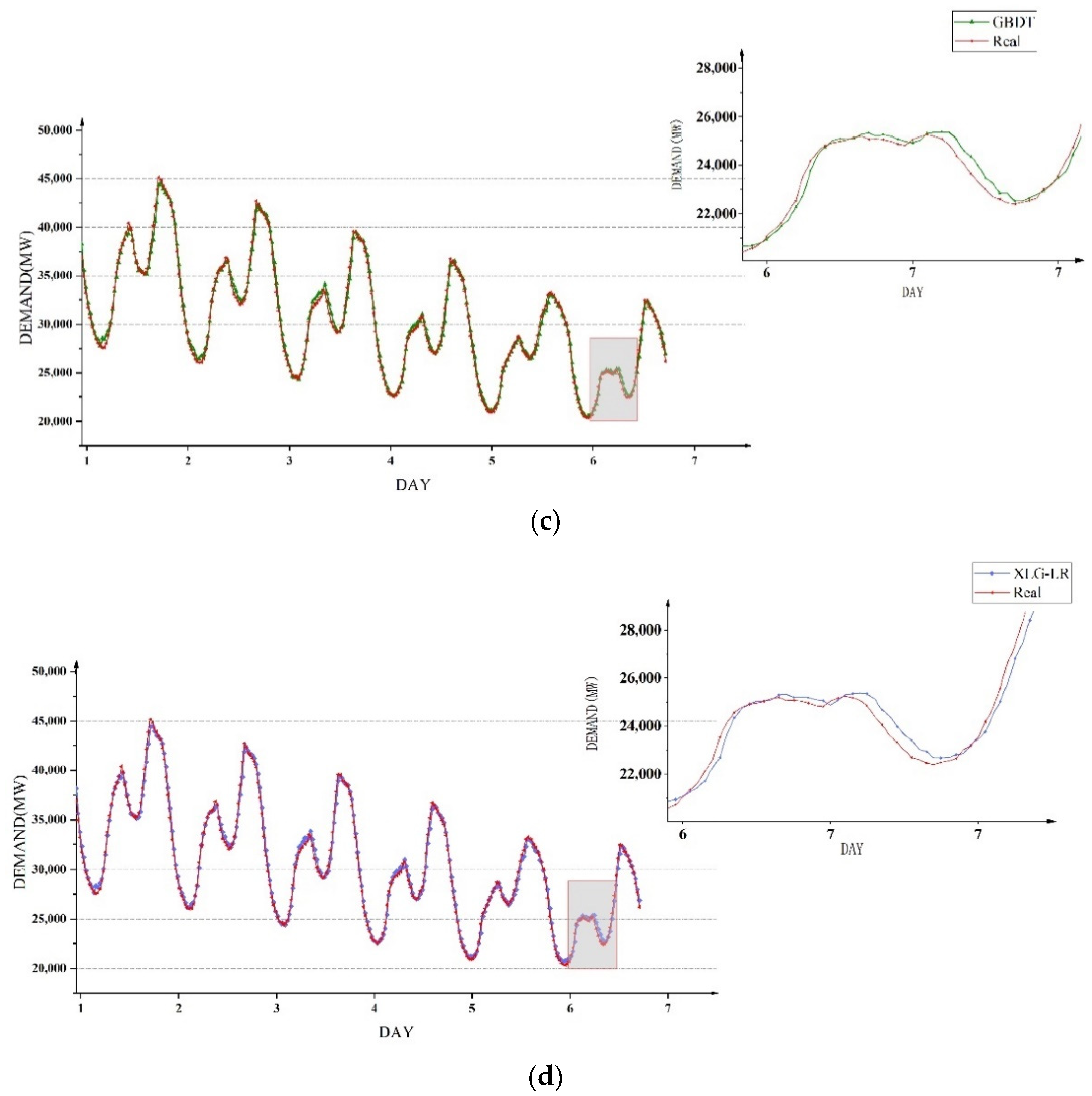
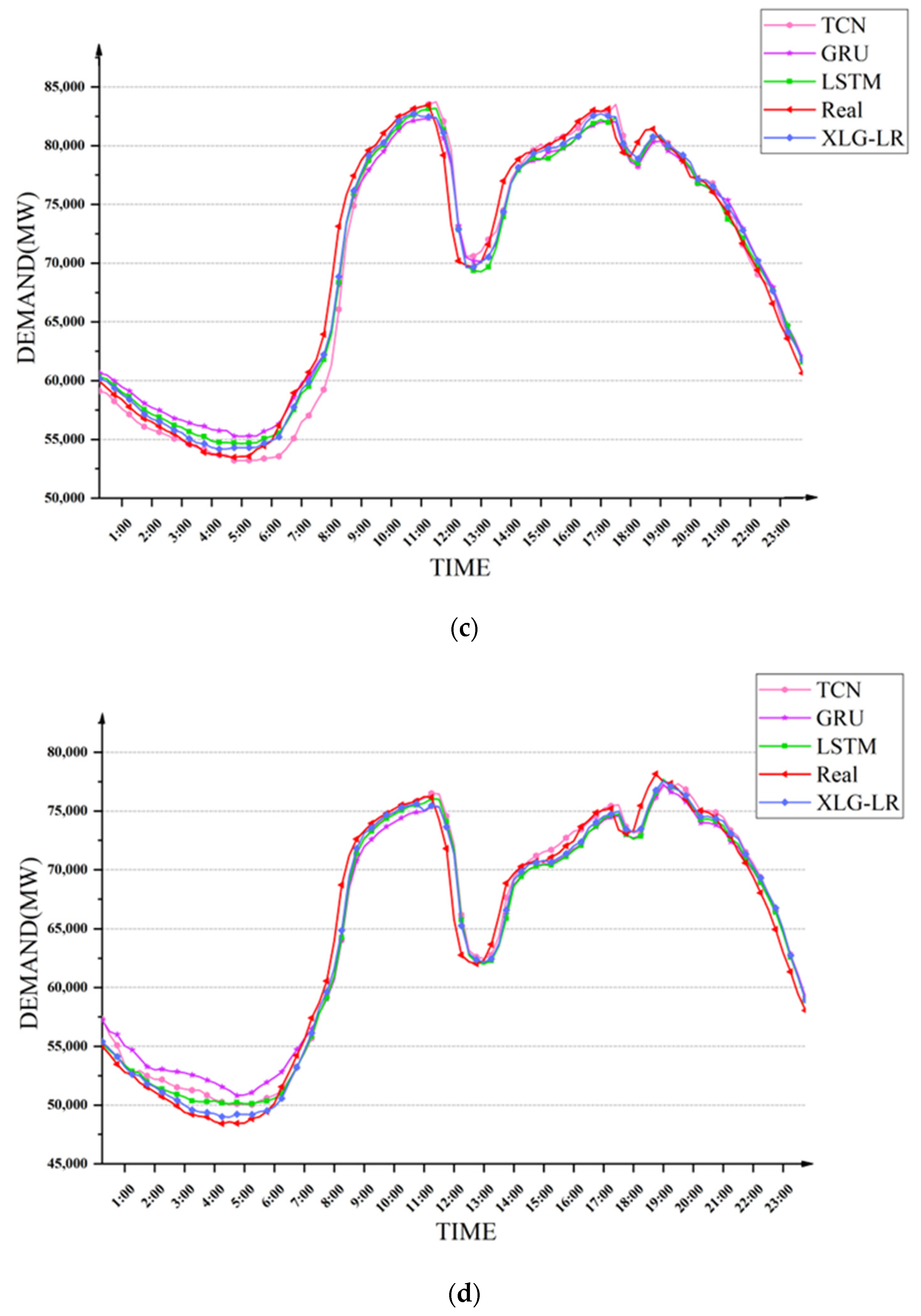
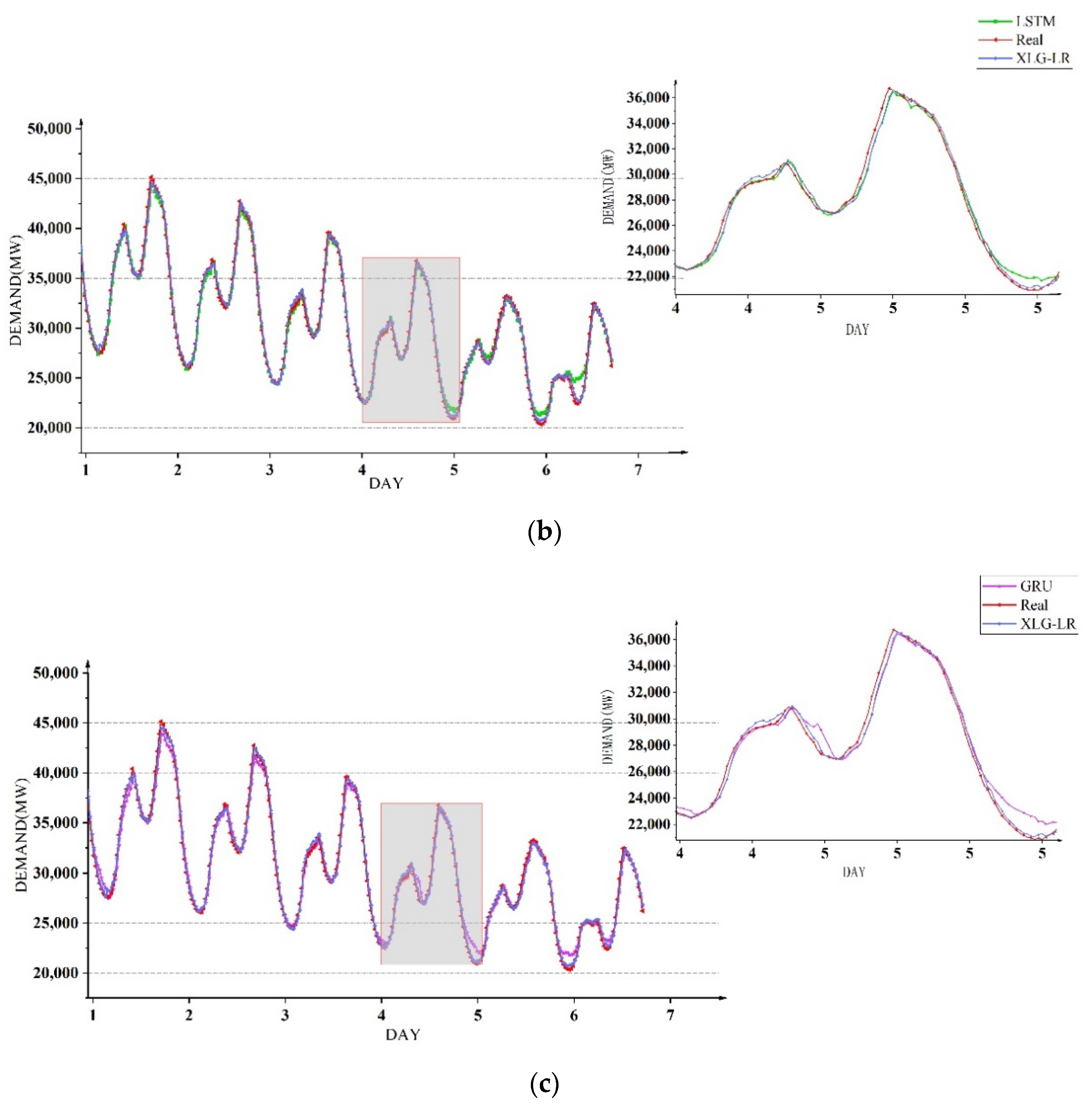
Secondly, four methods were used to compare power demand forecasting in weeks, and the same training set and test set as in
Section 5.3 were utilized to conduct experiments to examine the accuracy of power demand forecasting at different time periods in a week. The prediction results of the four models for the trend of electricity demand in one week are shown in
Figure 11. It can be seen that the three models GRU, LSTM and TCN had obvious prediction deviations in the periods of high and low electricity demand, while the XLG-LR model could accurately predict the change trend of power demand in most time periods.
The comparison between the XLG-LR model and the other three neural network methods are shown in
Table 8. It can be seen that compared with the three models of GRU, LSTM and TCN, the XLG-LR model had obvious advantages in the power demand forecasting on a weekly basis under the four evaluation indicators, and all indicators were ahead of other models.
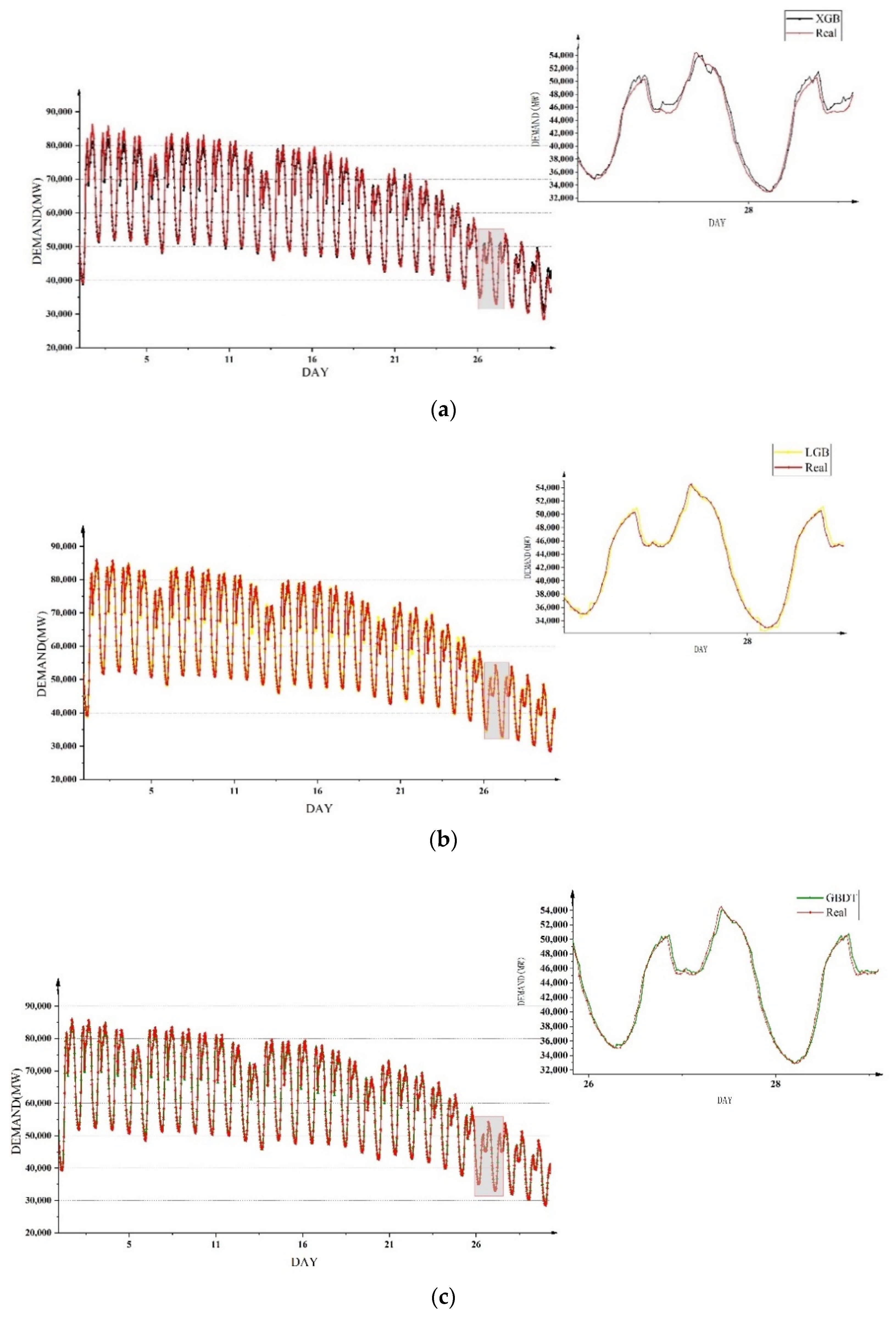
Then four methods were used to compare the power demand forecasting on a monthly basis, and the same training set and test set as
Section 5.3 were utilized to conduct experiments to examine the accuracy of power demand forecasting at different time periods during the 30 days.
Figure 12 shows the forecast results of the four models for the trend of electricity demand in one month. It can be seen from the figure that the three models of GRU, LSTM and TCN had obvious forecast deviations in the period of low electricity demand, while the XLG-LR model could basically match the real demand in most time periods.
The comparison between the XLG-LR model and the other three neural network methods are shown in
Table 9. It can be seen that compared with the three models of GRU, LSTM and TCN, the XLG-LR model had significant advantages in forecasting electricity demand on a monthly basis under the four evaluation indicators, and the curve fitting effect was the best and the power demand forecast error was the smallest.
The prediction time of the model was related to the convenience of the model in reality. This paper adopted the same training data to compare the time consumption of the XLG-LR model and the other three neural network methods in the prediction stage. The specific structure is shown in
Table 10.
It can be seen from the table that the XLG-LR model could complete the prediction in the shortest time in each forecasting scenario. And the time required was at least one order of magnitude different than the other three neural network methods, which fully showed that the XLG-LR model had an absolute advantage in prediction time.
Through the above comparative experiments, it could be considered that the XLG-LR model had obvious advantages in terms of prediction accuracy and prediction time consumption compared with the classical neural network algorithms. The construction of the XLG-LR model mainly relies on the principle of a decision tree, and the global optimal solution is finally obtained by continuously optimizing the local optimal solution in the solving process. The neural network needs to compare the data features extracted from the test data with the trained model to give the optimal solution. However, the data in the training model has numerous features as well as a certain similarity, so it performs not as well as the XLG-LR model in terms of accuracy and time consumption. Therefore, it can be considered that the XLG-LR model in this study could achieve ideal prediction results for the power demand forecasting in different scenarios.
Although the method proposed in this paper has achieved relatively ideal power demand forecasting results, there are still some problems that need to be solved in the future.
(1) The dataset is relatively small and contains a limited amount of information. At present, the dataset used in this paper has only 13 months of data, which reduces the generalization and reliability of the model to a certain extent. The GBDT, XGBoost and LightGBM algorithms used in this paper can achieve better prediction results on small data sets, but if the data is more abundant, it should be able to achieve better prediction results. Therefore, in future research and exploration, the current dataset can be supplemented by collecting more months of data to build a larger and more informative dataset for electricity demand forecasting.
(2) More indicators other than meteorological factors may also be able to influence the forecast results. The electricity demand can be affected by many factors, including the level of local economic development and industrial structure. Although the indicators used in this study can exert the necessary influences on electricity demand to a certain extent, some other indicators may also affect it. Therefore, in the future, researchers can learn of other factors affecting electricity demand indicators from experts in related fields, and collect more index data that can have an impact on electricity demand to supplement the current data set.
7. Conclusions
Regarded as an important task in the power industry, power demand forecasting guarantees normal operation of economic development, sustains people’s daily life, and directs electric power production. This study utilized 13 months of electricity and meteorological data and adopted three models: GBDT, XGBoost and LightGBM, in order to build an XLG-LR power demand forecasting model based on stacking fusion. After the data was divided into a training set and a test set, the above four models were trained, and the test set was used to verify the feasibility of the model. The experiments in this study were carried out under the following software and hardware conditions. Software conditions required python3.7, tensorflow2.8.0, with the sklearn, seaborn, numpy, matplotlib, and the pandas development kits installed. The hardware environment required that the graphics card model was AMD Radeon(TM) Vega 8 Graphics and that the memory was 8 GB.
Verification started with different time lengths such as seasonal forecasting, weekly forecasting and monthly forecasting. It was found that under different time lengths, except for the XGBoost model, the GBDT, LightGBM and XLG-LR models all achieved relatively satisfactory results, among which the XLG-LR model proposed in this paper works best. From the perspective of prediction accuracy, the overall prediction accuracy ranked as XLG-LR > GBDT > LightGBM > XGBoost. In addition, this paper also compared the power demand prediction results of the XLG-LR model with that of the three mainstream neural network models of TCN, GRU and LSTM. The results showed that the XLG-LR model in this paper can also achieve the best experimental results in this dataset compared to the neural network model. Through the above discussion, the reliability and validity of the XLG-LR model in this paper for power demand forecasting was verified. When the power demand data or the meteorological data changes, only a new data set is needed to train the model to form a new prediction model, which can cope with the data changes and carry out the corresponding prediction. The method in this study can also be applied to power demand forecasting in other regions, and a new data set is needed to train a new forecasting model. In addition, the method has been encapsulated into corresponding software with good interoperability. It will be able to be used in a wider range of practical applications in the days to come.
In the future, more power demand data can be collected to build a larger power demand database so as to verify the accuracy and advancement of the algorithm in this paper in power demand forecasting. At the same time, under the premise that the amount of data is sufficient enough, this method could be adopted to carry out long-term electricity demand forecasting, such as forecasting the electricity demand in the next year. In addition, electricity demand is also closely related to other factors besides meteorological ones, such as the level of economic development and the regional industrial layout. In the days to come, these data can be supplemented to improve the prediction accuracy of this method. Furthermore, the method can also be applied to other fields, including the prediction of water demand and coal resource demand.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}