
HA-RoadFormer: Hybrid Attention Transformer with Multi-Branch for Large-Scale High-Resolution Dense Road Segmentation


Abstract
:1. Introduction
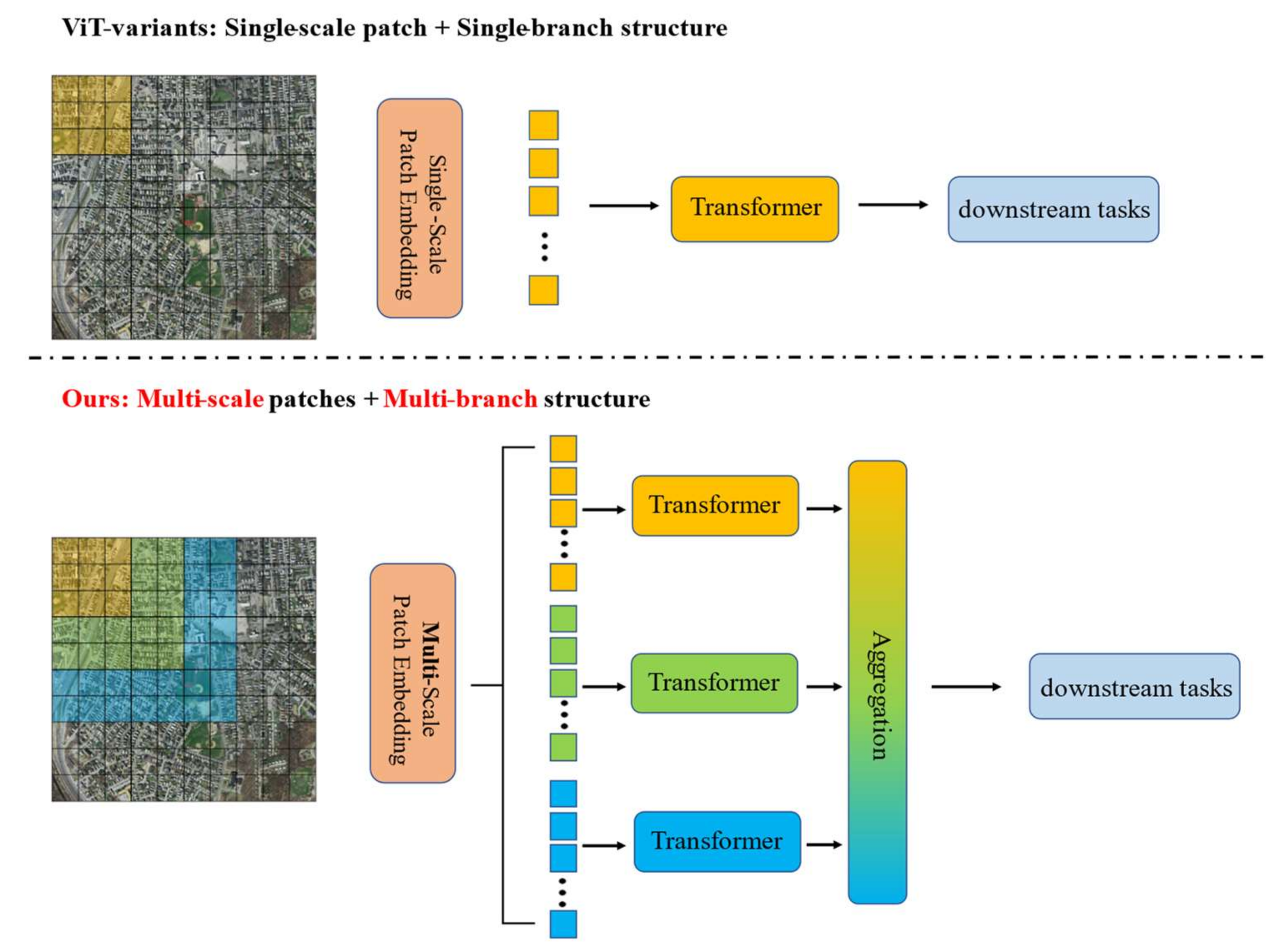
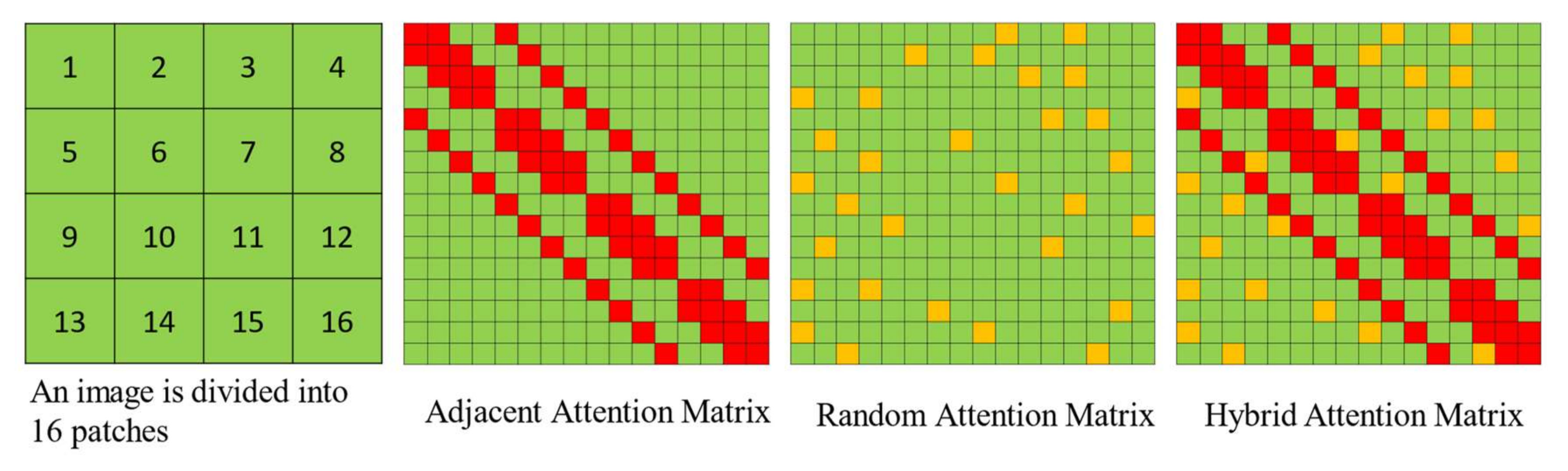
- To reduce the high computational complexity of large-scale high-resolution remote sensing images, we propose a hybrid attention mechanism with linear complexity. Hybrid attention focuses on a few sampling points around the reference point. It assigns a small number of fixed keys to each query, which can alleviate the problem of limited input resolution. To retain the acquisition ability of long-distance dependence, we use random attention as a supplement.
- We explore multiscale patch embedding and multi-branch structure from a unique perspective. Tokens of different scales are sent to the Transformer encoder independently through multiple paths. Then, the generated features are aggregated to realize coarse to fine feature representation at the same feature level.
2. Related Work
2.1. Road Segmentation in Remote Sensing Image
2.2. Transformer with Local Attention Enhancement
2.3. Vision Transformer for Semantic Segmentation
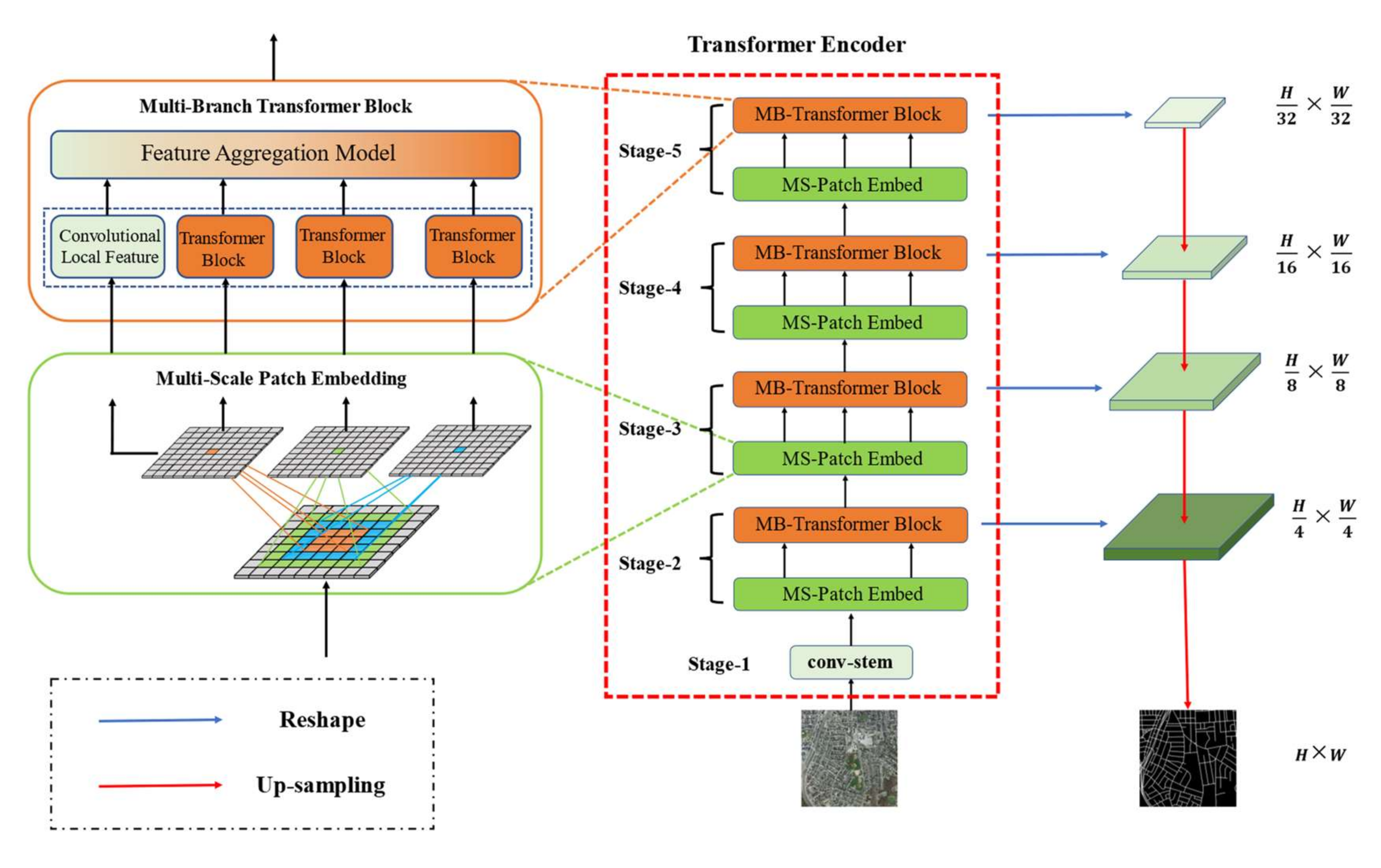
3. Method
3.1. Overall Structure
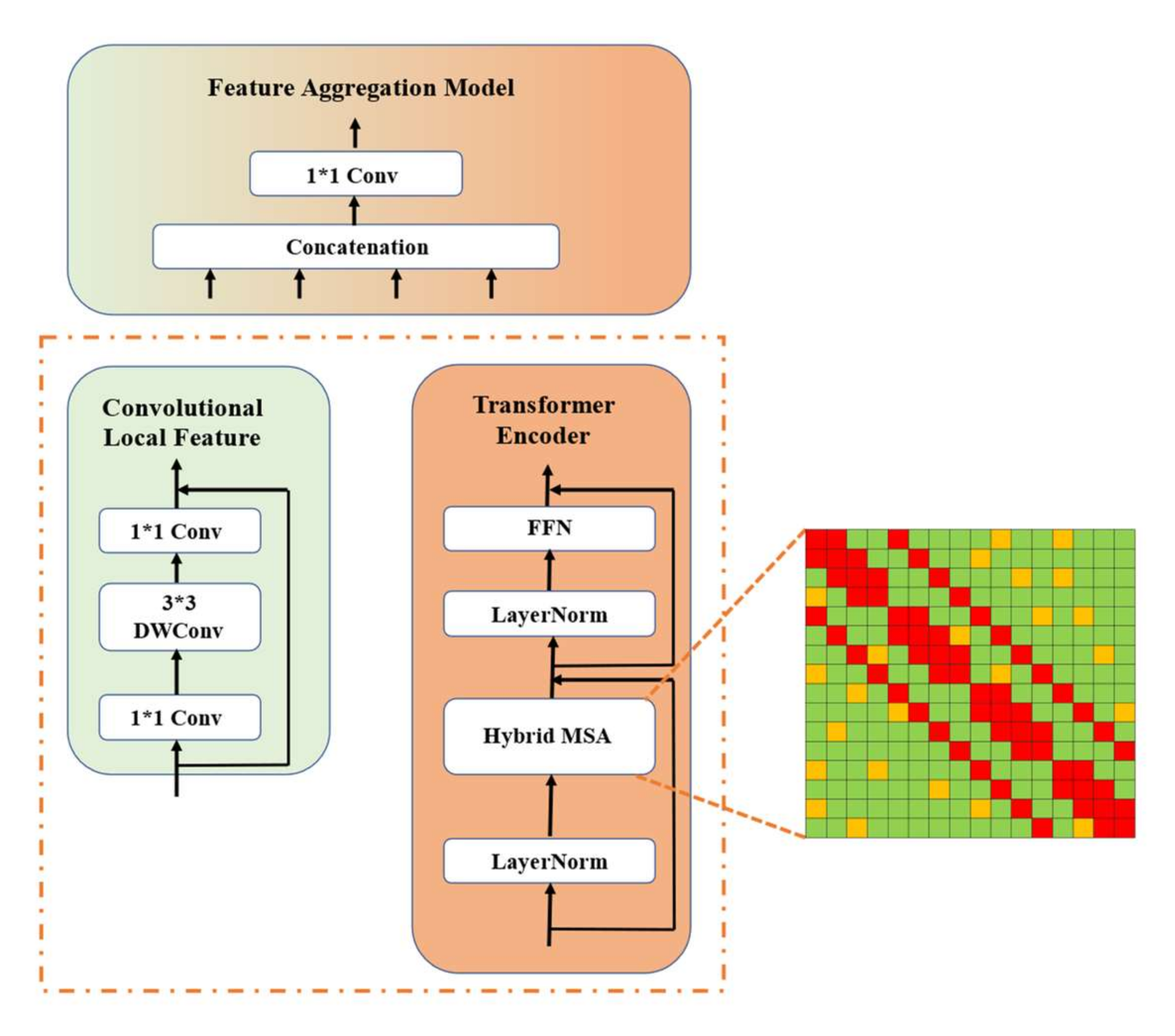
3.2. Hybrid Attention with Linear Complexity
3.3. Multiscale Patch Embedding
4. Experiment
4.1. Dataset and Preprocessing
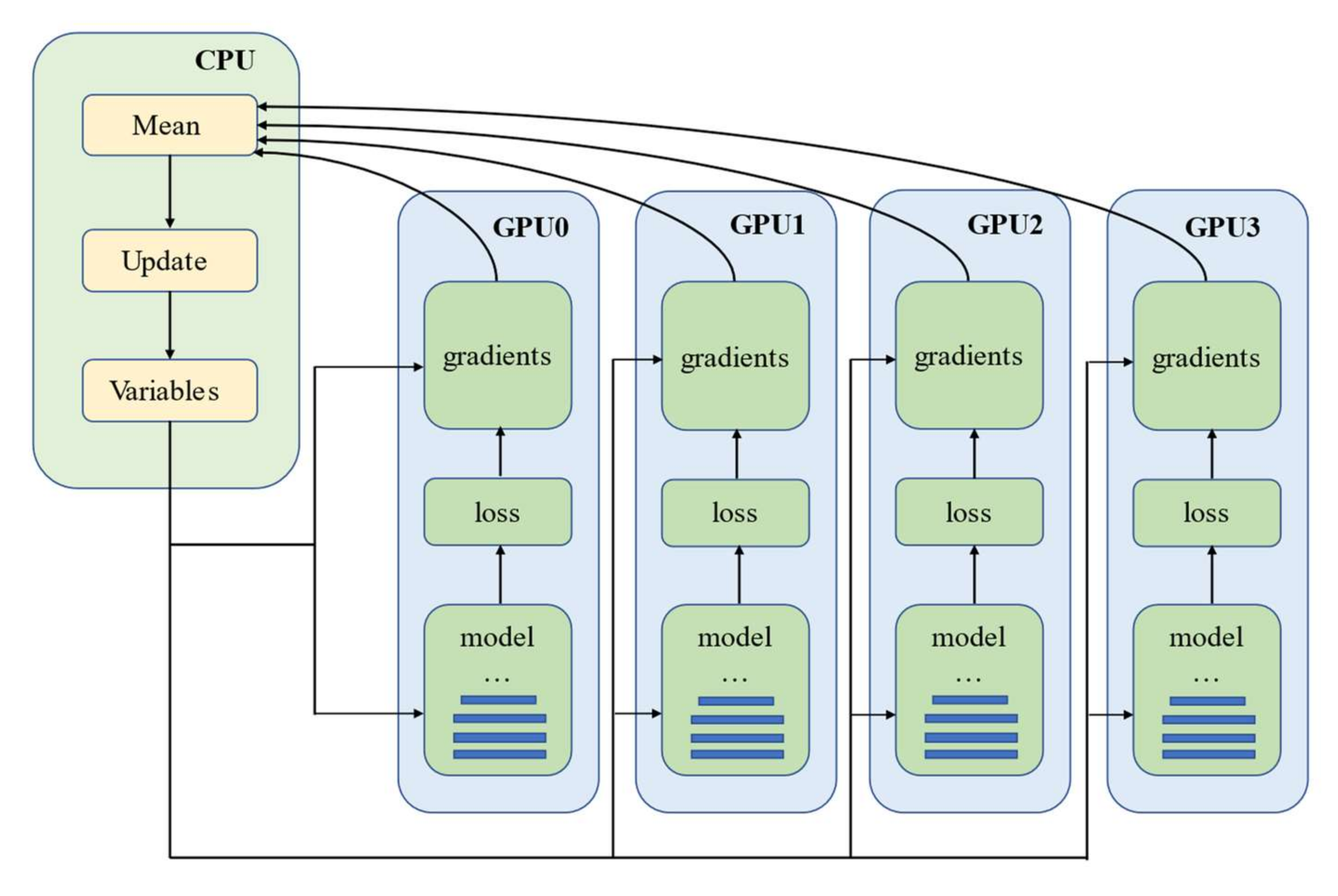
4.2. Implementation Details
4.3. Evaluation Metrics
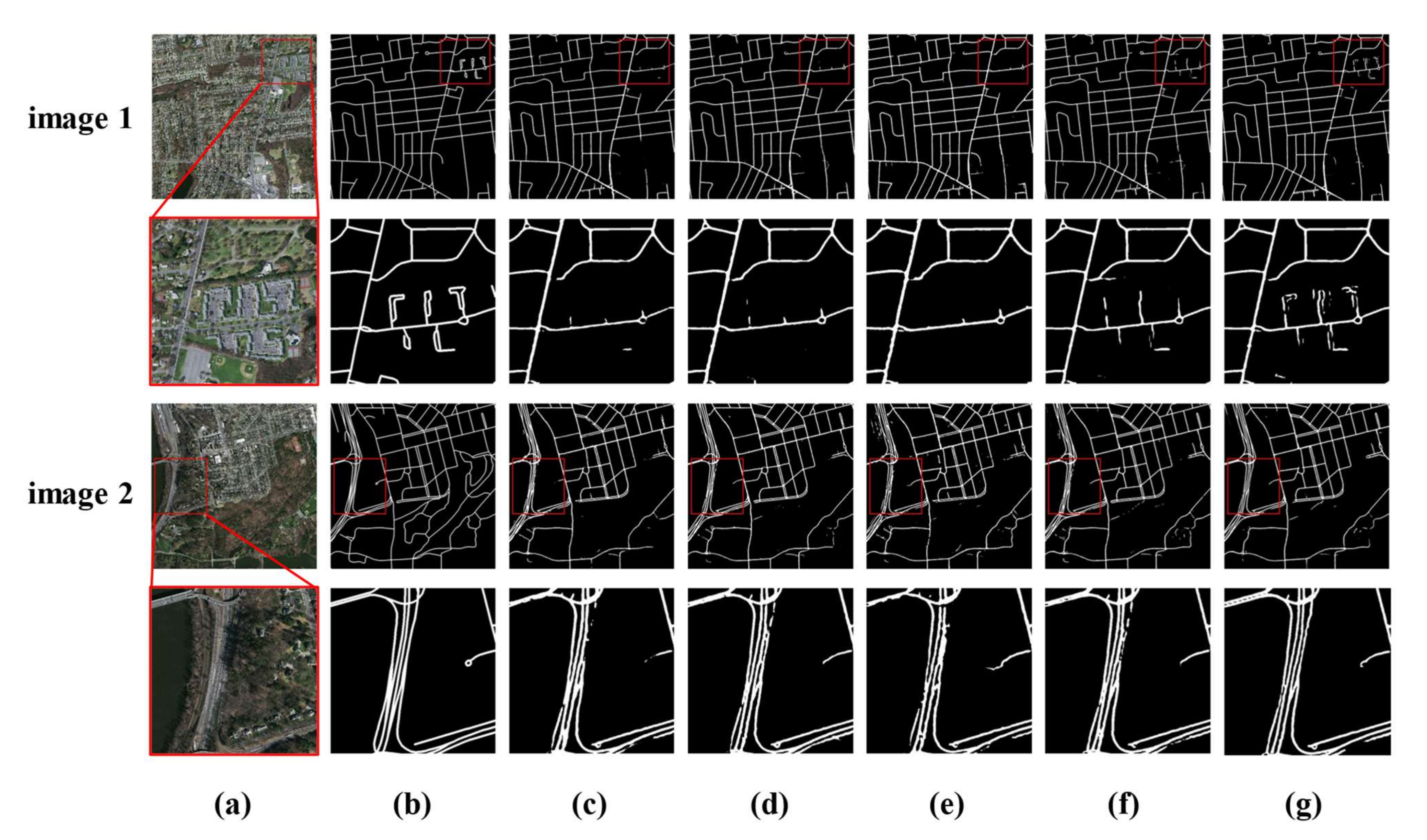
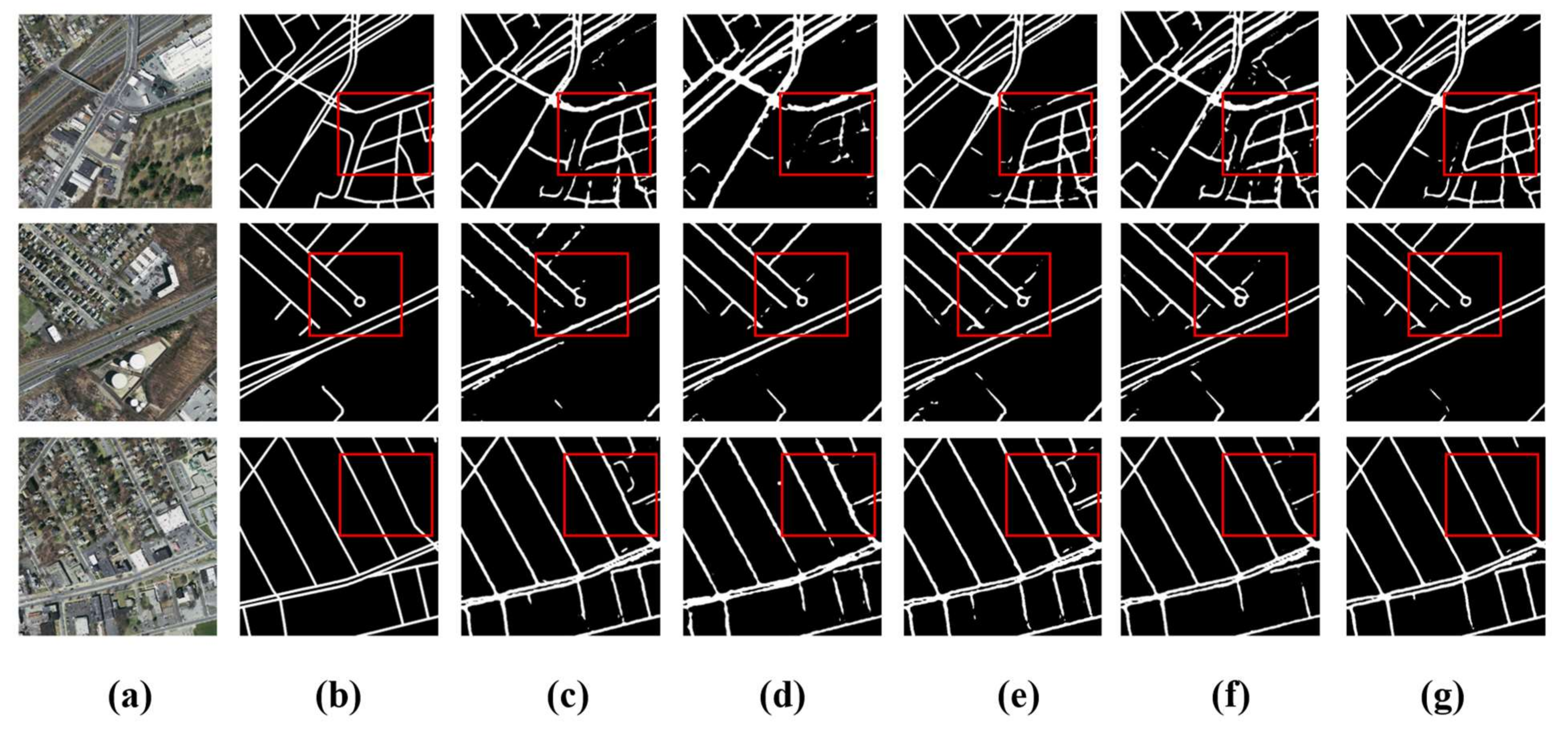
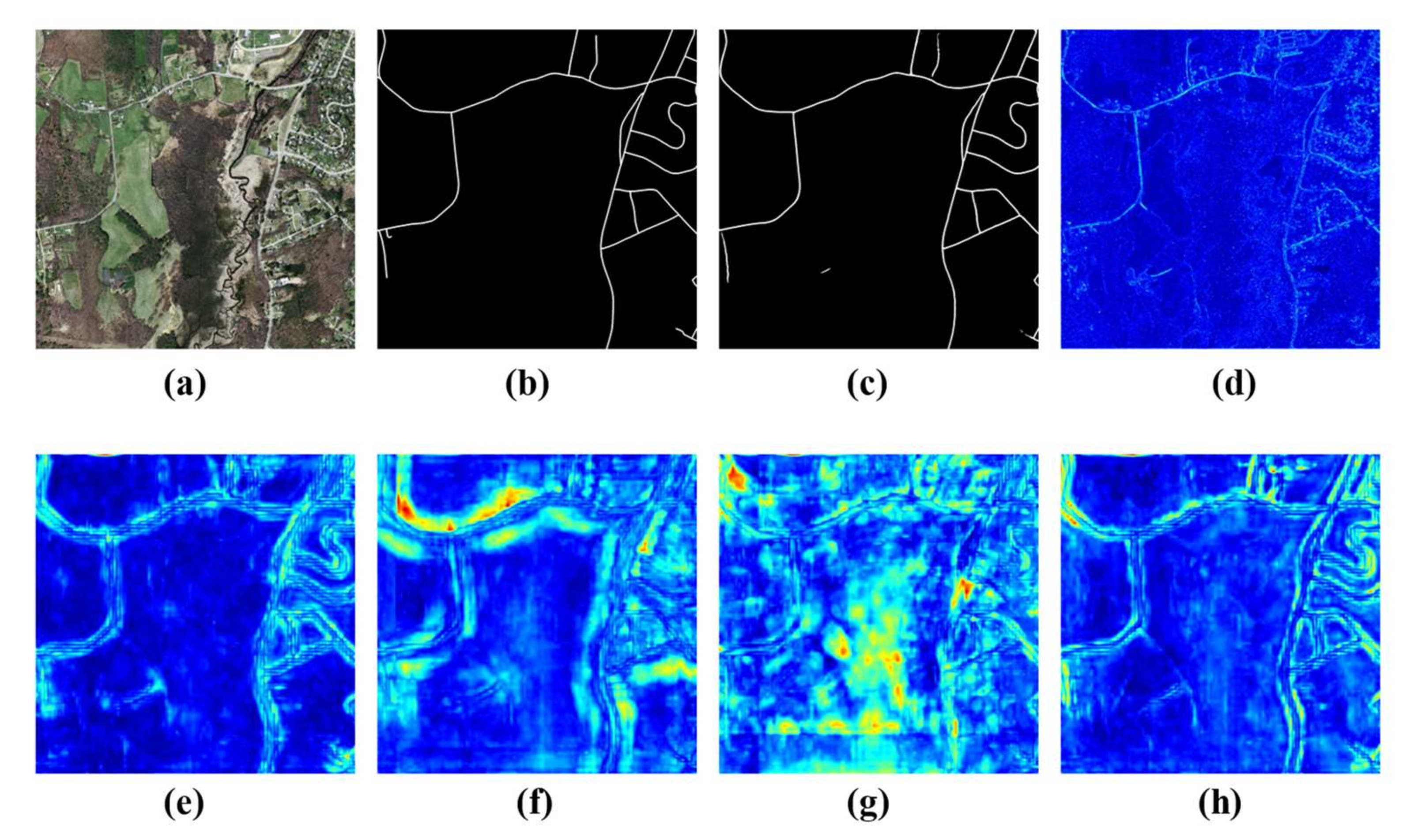
4.4. Experimental Results on Massachusetts Road Dataset
4.5. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hinz, S.; Baumgartner, A.; Ebner, H. Modeling contextual knowledge for controlling road extraction in urban areas. In Proceedings of the IEEE/ISPRS Joint Workshop on Remote Sensing and Data Fusion over Urban Areas (Cat. No. 01EX482), Rome, Italy, 8–9 November 2001; IEEE: Piscataway, NJ, USA, 2001; pp. 40–44. [Google Scholar]
- Wang, J.; Qin, Q.; Gao, Z.; Zhao, J.; Ye, X. A New Approach to Urban Road Extraction Using High-Resolution Aerial Image. ISPRS Int. J. Geo-Inf. 2016, 5, 114. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Miao, Z.; Debayle, J. An Integrated Method for Urban Main-Road Centerline Extraction from Optical Remotely Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 3359–3372. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-Hrnet: A lightweight high-resolution network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10440–10450. [Google Scholar]
- Oliveira, G.L.; Burgard, W.; Brox, T. Efficient deep models for monocular road segmentation. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 4885–4891. [Google Scholar]
- Levi, D.; Garnett, N.; Fetaya, E.; Herzlyia, I. StixelNet: A deep convolutional network for obstacle detection and road segmentation. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015; Volume 1, p. 4. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y. A Survey on Visual Transformer. arXiv 2020, arXiv:2012.12556. [Google Scholar]
- Zhang, Z.; Xu, Z.; Liu, C.; Tian, Q.; Wang, Y. Cloudformer: Supplementary Aggregation Feature and Mask-Classification Network for Cloud Detection. Appl. Sci. 2022, 12, 3221. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6836–6846. [Google Scholar]
- Chen, Z.; Xie, L.; Niu, J.; Liu, X.; Wei, L.; Tian, Q. Visformer: The vision-friendly transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 589–598. [Google Scholar]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards Deeper Vision Transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows. arXiv 2021, arXiv:2107.00652. [Google Scholar]
- Broggi, A. Parallel and Local Feature Extraction: A Real-Time Approach to Road Boundary Detection. IEEE Trans. Image Processing 1995, 4, 217–223. [Google Scholar] [CrossRef]
- Li, H.-C.; Hu, W.-S.; Li, W.; Li, J.; Du, Q.; Plaza, A. A3CLNN: Spatial, Spectral and Multiscale Attention ConvLSTM Neural Network for Multisource Remote Sensing Data Classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 747–761. [Google Scholar] [CrossRef]
- Ma, F.; Zhang, F.; Xiang, D.; Yin, Q.; Zhou, Y. Fast Task-Specific Region Merging for SAR Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5222316. [Google Scholar] [CrossRef]
- Ma, F.; Zhang, F.; Yin, Q.; Xiang, D.; Zhou, Y. Fast SAR Image Segmentation With Deep Task-Specific Superpixel Sampling and Soft Graph Convolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5214116. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Chen, J.; Li, J.; Feng, Y.; Xu, T. FAIR1M: A Benchmark Dataset for Fine-Grained Object Recognition in High-Resolution Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- Yang, J.-Y.; Li, H.-C.; Hu, W.-S.; Pan, L.; Du, Q. Adaptive Cross-Attention-Driven Spatial-Spectral Graph Convolutional Network for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 6004705. [Google Scholar] [CrossRef]
- Yue, Z.; Gao, F.; Xiong, Q.; Wang, J.; Huang, T.; Yang, E.; Zhou, H. A Novel Semi-Supervised Convolutional Neural Network Method for Synthetic Aperture Radar Image Recognition. Cogn. Comput. 2021, 13, 795–806. [Google Scholar] [CrossRef] [Green Version]
- Gao, X.; Sun, X.; Zhang, Y.; Yan, M.; Xu, G.; Sun, H.; Jiao, J.; Fu, K. An End-to-End Neural Network for Road Extraction from Remote Sensing Imagery by Multiple Feature Pyramid Network. IEEE Access 2018, 6, 39401–39414. [Google Scholar] [CrossRef]
- Xin, J.; Zhang, X.; Zhang, Z.; Fang, W. Road Extraction of High-Resolution Remote Sensing Images Derived from DenseUNet. Remote Sens. 2019, 11, 2499. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Miao, C.; Liu, C.; Tian, Q. DCS-TransUperNet: Road Segmentation Network Based on CSwin Transformer with Dual Resolution. Appl. Sci. 2022, 12, 3511. [Google Scholar] [CrossRef]
- Yu, T.; Zhao, G.; Li, P.; Yu, Y. BOAT: Bilateral Local Attention Vision Transformer. arXiv 2022, arXiv:2201.13027. [Google Scholar]
- Lin, H.; Cheng, X.; Wu, X.; Yang, F.; Shen, D.; Wang, Z.; Song, Q.; Yuan, W. Cat: Cross Attention in Vision Transformer. arXiv 2021, arXiv:2106.05786. [Google Scholar]
- Bulat, A.; Perez Rua, J.M.; Sudhakaran, S.; Martinez, B.; Tzimiropoulos, G. Space-Time Mixing Attention for Video Transformer. Adv. Neural Inf. Processing Syst. 2021, 34, 5223512. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in Transformer. Adv. Neural Inf. Processing Syst. 2021, 34, 5216488. [Google Scholar]
- Zhang, C.; Wan, H.; Liu, S.; Shen, X.; Wu, Z. Pvt: Point-Voxel Transformer for 3d Deep Learning. arXiv 2021, arXiv:2108.06076. [Google Scholar]
- Heo, B.; Yun, S.; Han, D.; Chun, S.; Choe, J.; Oh, S.J. Rethinking Spatial Dimensions of Vision Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11936–11945. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.-H.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-Token Vit: Training Vision Transformers from Scratch on Imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 558–567. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Chen, C.-F.R.; Fan, Q.; Panda, R. Crossvit: Cross-Attention Multi-Scale Vision Transformer for Image Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 357–366. [Google Scholar]
- Ali, A.; Touvron, H.; Caron, M.; Bojanowski, P.; Douze, M.; Joulin, A.; Laptev, I.; Neverova, N.; Synnaeve, G.; Verbeek, J. Xcit: Cross-Covariance Image Transformers. Adv. Neural Inf. Processing Syst. 2021, 34, 5241254. [Google Scholar]
- Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jégou, H.; Douze, M. LeViT: A Vision Transformer in ConvNet’s Clothing for Faster Inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12259–12269. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Fukui, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 10705–10714. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Levy, J.I.; Houseman, E.A.; Spengler, J.D.; Loh, P.; Ryan, L. Fine Particulate Matter and Polycyclic Aromatic Hydrocarbon Concentration Patterns in Roxbury, Massachusetts: A Community-Based GIS Analysis. Environ. Health Perspect. 2001, 109, 341–347. [Google Scholar] [CrossRef]
- Ding, C.; Weng, L.; Xia, M.; Lin, H. Non-Local Feature Search Network for Building and Road Segmentation of Remote Sensing Image. ISPRS Int. J. Geo-Inf. 2021, 10, 245. [Google Scholar] [CrossRef]
- Bella, G.; Massacci, F.; Paulson, L.C. An Overview of the Verification of SET. Int. J. Inf. Secur. 2005, 4, 17–28. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wan, J.; Xie, Z.; Xu, Y.; Chen, S.; Qiu, Q. DA-RoadNet: A Dual-Attention Network for Road Extraction from High Resolution Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6302–6315. [Google Scholar] [CrossRef]
- Prechelt, L. Early Stopping-but When? In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 1998; pp. 55–69. [Google Scholar]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Road Segmentation of Remotely-Sensed Images Using Deep Convolutional Neural Networks with Landscape Metrics and Conditional Random Fields. Remote Sens. 2017, 9, 680. [Google Scholar] [CrossRef] [Green Version]
- Sun, Z.; Geng, H.; Lu, Z.; Scherer, R.; Woźniak, M. Review of Road Segmentation for SAR Images. Remote Sens. 2021, 13, 1011. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Liu, Z.; Feng, R.; Wang, L.; Zhong, Y.; Cao, L. D-Resunet: Resunet and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3927–3930. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | Inference (ms) |
|---|---|---|---|---|---|
| DeepLabV3+ | 75.47 | 72.23 | 73.81 | 58.86 | 1.65 |
| D-LinkNet | 77.91 | 69.85 | 73.66 | 58.54 | 1.22 |
| D-ResUnet | 75.95 | 77.58 | 76.75 | 61.69 | 2.32 |
| ViT | 80.55 | 77.64 | 79.06 | 63.85 | 2.45 |
| DCS-TransUperNet | 82.44 | 78.43 | 80.38 | 65.56 | 2.84 |
| HA-RoadFormer | 82.94 | 79.43 | 81.14 | 67.36 | 1.86 |
| Method | IoU (%) | Inference (ms) |
|---|---|---|
| HA-RoadFormer with two patches | 64.27 | 1.66 |
| HA-RoadFormer with one patch | 63.94 | 1.40 |
| RoadFormer | 66.50 | 2.94 |
| HA-RoadFormer with three patches | 67.36 | 1.86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Miao, C.; Liu, C.; Tian, Q.; Zhou, Y. HA-RoadFormer: Hybrid Attention Transformer with Multi-Branch for Large-Scale High-Resolution Dense Road Segmentation. Mathematics 2022, 10, 1915. https://doi.org/10.3390/math10111915
Zhang Z, Miao C, Liu C, Tian Q, Zhou Y. HA-RoadFormer: Hybrid Attention Transformer with Multi-Branch for Large-Scale High-Resolution Dense Road Segmentation. Mathematics. 2022; 10(11):1915. https://doi.org/10.3390/math10111915
Chicago/Turabian StyleZhang, Zheng, Chunle Miao, Changan Liu, Qing Tian, and Yongsheng Zhou. 2022. "HA-RoadFormer: Hybrid Attention Transformer with Multi-Branch for Large-Scale High-Resolution Dense Road Segmentation" Mathematics 10, no. 11: 1915. https://doi.org/10.3390/math10111915