
Decoupling Induction and Multi-Order Attention Drop-Out Gating Based Joint Motion Deblurring and Image Super-Resolution


Abstract
:1. Introduction
- We propose a novel joint motion deblurring and image SR model based on decoupling induction and multi-order attention drop-out gating. The proposed method can overcome the limitation of the single type degeneration assumption to achieve joint recovery with the aid of decoupling induction multi-task learning.
- We propose the use of decoupling dual-branch multi-order attention features for clear HR image reconstruction and select the drop-out gating learning method to enhance the robustness and the generalization of features’ fusion.
- We validate and compare the presented model, not only with the publicly available and widely used natural image datasets, but also with synthetic images completely different from the training images. We show that, through decoupling induction and multi-order attention drop-out gating learning, our method can produce visual results of a quality that competes with the most advanced motion deblurring and image SR methods for LR and blurred images.
2. Related Work
2.1. Joint Image Deblur and SR
2.2. Attention
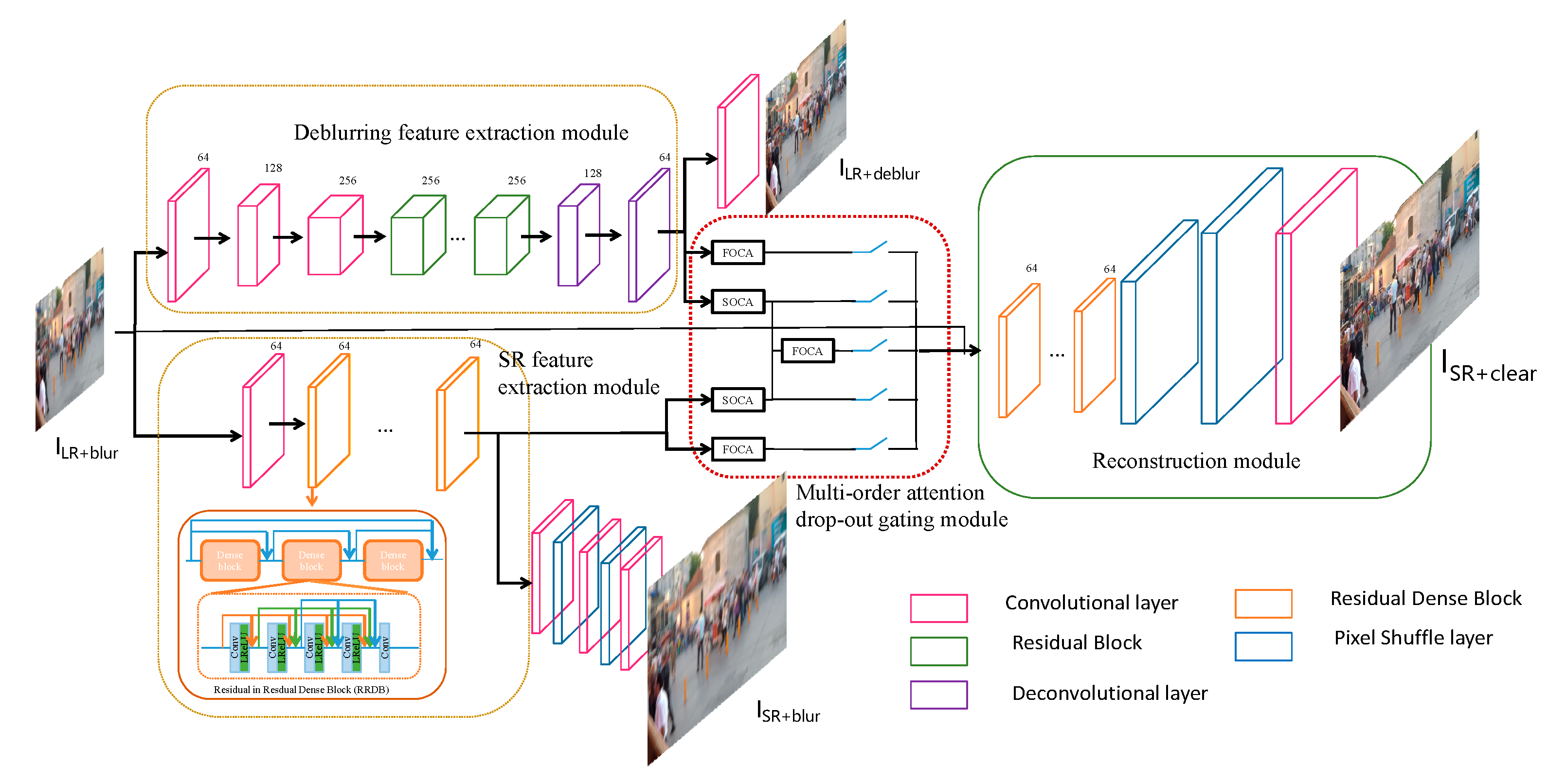
3. Methodology
3.1. Multiple Degradation Decoupling Induction
3.2. Multi-Order Attention Gating
3.3. Network Architecture
3.3.1. Deblurring Feature Extraction
3.3.2. SR Feature Extraction
3.3.3. Multi-Order Attention Drop-Out Gating
3.3.4. Reconstruction Module
3.4. Loss Functions
4. Experimental Results
4.1. Datasets and Training Details
4.2. Experiments and Comparisons
5. Ablation Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 769–777. [Google Scholar] [CrossRef] [Green Version]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar] [CrossRef]
- Xi, S.; Wei, J.; Zhang, W. Pixel-Guided Dual-Branch Attention Network for Joint Image Deblurring and Super-Resolution. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 532–540. [Google Scholar] [CrossRef]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8174–8182. [Google Scholar] [CrossRef]
- Xu, X.; Sun, D.; Pan, J.; Zhang, Y.; Pfister, H.; Yang, M.-H. Learning to super-resolve blurry face and text images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, HI, USA, 21–26 July 2017; pp. 251–260. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, F.; Dong, H.; Guo, Y. A deep encoder-decoder networks for joint deblurring and super-resolution. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Alberta, AB, Canada, 15–20 April 2018; pp. 1448–1452. [Google Scholar] [CrossRef]
- Zhang, X.; Dong, H.; Hu, Z.; Hu, Z.; Lai, W.-S.; Wang, F.; Yang, M.-H. Gated fusion network for joint image deblurring and super-resolution. In British Machine Vision Conference (BMVC); Springer: London, UK, 2018. [Google Scholar] [CrossRef] [Green Version]
- Ying, T.; Jian, Y.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar] [CrossRef]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 August 2018; pp. 286–301. [Google Scholar] [CrossRef] [Green Version]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.-T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, NY, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Fu, Z.; Han, J.; Shao, L.; Hou, S.; Chu, Y. Single image super resolution using multi-scale deep encoder-decoder with phase congruency edge map guidance. Inf. Sci. 2019, 473, 44–58. [Google Scholar] [CrossRef] [Green Version]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Farley, W.D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Xu, L.; Ren, J.S.; Liu, C.; Jia, J. Deep convolutional neural network for image deconvolution. In Advances in Neural Information Processing Systems; Cornel University: Ithaca, NY, USA, 2014; pp. 1790–1798. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.709.7888&rep=rep1&type=pdf (accessed on 1 November 2021).
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar] [CrossRef] [Green Version]
- Ramakrishnan, S.; Pachori, S.; Gangopadhyay, A.; Raman, S. Deep generative filter for motion deblurring. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2993–3000. [Google Scholar] [CrossRef] [Green Version]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar] [CrossRef] [Green Version]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Gan. arXiv 2017. Available online: https://arxiv.org/abs/1701.07875 (accessed on 1 November 2021).
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar] [CrossRef] [Green Version]
- Manzo, M.; Pellino, S. Voting in transfer learning system for ground-based cloud classification. In Machine Learning and Knowledge Extraction; Cornel University: Ithaca, NY, USA, 2021; Volume 3, pp. 542–553. [Google Scholar] [CrossRef]
- Xu, R.; Xiao, Z.; Huang, J.; Zhang, Y.; Xiong, Z. EDPN: Enhanced deep pyramid network for blurry image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 414–423. [Google Scholar] [CrossRef]
- Liang, Z.; Zhang, D.; Shao, J. Jointly solving deblurring and super-resolution problems with dual supervised network. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 790–795. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Zhang, L. Deep plug-and-play super-resolution for arbitrary blur kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1671–1681. [Google Scholar] [CrossRef]
- Zhang, D.; Liang, Z.; Shao, J. Joint image deblurring and super-resolution with attention dual supervised network. Neurocomputing 2020, 412, 187–196. [Google Scholar] [CrossRef]
- Wang, X.; Chan, K.C.; Yu, K.; Dong, C.; Loy, C.C. Edvr: Video restoration with enhanced deformable convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 1954–1963. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 18–20 June 2019; pp. 3146–3154. [Google Scholar] [CrossRef] [Green Version]
- Niu, W.; Zhang, K.; Luo, W.; Zhong, Y. Blind motion deblurring super-resolution: When dynamic spatio-temporal learning meets static image understanding. IEEE Trans. Image Process. 2021, 30, 7101–7111. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lai, W.-S.; Huang, J.-B.; Hu, Z.; Ahuja, N.; Yang, M.-H. A comparative study for single image blind deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1701–1709. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super resolution network for multiple degradations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3262–3271. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Lai et al. [34] | GOPRO [2] |
|---|---|---|
| Synthetic/Real | Synthetic and Real | Real |
| Blur type | Uniform and Non-uniform | Uniform |
| Ground-truth images | 125 | 3214 |
| Blurred images | 300 | 3214 |
| Depth variation | Yes | No |
| Measures | RDN [10] | SRN [5] | SCG-AN [6] | RCAN [11] | RDN [10] + SRN [5] | ED-DSRN [7] | Zhang et al. [33] | GFN [8] | Our Proposed |
|---|---|---|---|---|---|---|---|---|---|
| PSNR | 24.370 | 25.829 | 22.791 | 25.328 | 26.211 | 26.331 | 25.80 | 27.81 | 27.82 |
| SSIM | 0.739 | 0.782 | 0.783 | 0.804 | 0.792 | 0.810 | 0.768 | 0.83 | 0.848 |
| Parameters | 178 M | 28.8 M | 15 M | 1.5 M | 305 M | 25 M | 7 M | 11 M | 27 M |
| Training/Inference time | 1.0 day/2.8 s | 3 days/0.4 s | 1.5 days/0.68 s | 1.5 day/0.55 s | 3.8 days/4 s | 1.5 days/0.22 s | 2 days/1.3 s | 2 days/0.07 s | 2 day/0.33 s |
| Measures | RDN [10] | SRN [5] | SCG-AN [6] | RCAN [11] | RDN [10] + SRN [5] | ED-DSRN [7] | Zhang et al. [33] | GFN [8] | Our Proposed |
|---|---|---|---|---|---|---|---|---|---|
| PSNR | 17.780 | 17.444 | 18.572 | 17.729 | 18.861 | 18.791 | 19.003 | 19.12 | 19.17 |
| SSIM | 0.416 | 0.408 | 0.460 | 0.471 | 0.423 | 0.473 | 0.466 | 0.574 | 0.59 |
| Inference time | 2.3 s | 0.3 s | 0.50 s | 0.9 s | 2.2 s | 0.20 s | 1.1 s | 0.42 s | 0.5 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, Y.; Zhang, X.; Liu, H. Decoupling Induction and Multi-Order Attention Drop-Out Gating Based Joint Motion Deblurring and Image Super-Resolution. Mathematics 2022, 10, 1837. https://doi.org/10.3390/math10111837
Chu Y, Zhang X, Liu H. Decoupling Induction and Multi-Order Attention Drop-Out Gating Based Joint Motion Deblurring and Image Super-Resolution. Mathematics. 2022; 10(11):1837. https://doi.org/10.3390/math10111837
Chicago/Turabian StyleChu, Yuezhong, Xuefeng Zhang, and Heng Liu. 2022. "Decoupling Induction and Multi-Order Attention Drop-Out Gating Based Joint Motion Deblurring and Image Super-Resolution" Mathematics 10, no. 11: 1837. https://doi.org/10.3390/math10111837