1. Introduction
Data clustering, also known as cluster analysis, is the process of partitioning a set of data objects into some clusters based on a similarity measure without any prior knowledge. The objects in each cluster are similar to each other, and different from data objects in other clusters [
1]. All of these clusters are usually referred to as a clustering result. The core of data clustering is to discover the inherent structure from the unlabeled data. Thus, it is usually employed as an effective tool to understand raw data in the initial phase of processing, particularly for the problems where prior knowledge is absent or expensive to obtain. Driven by the demand of acquiring knowledge from various complicated data, clustering analysis has become a research hotspot. Over the past decades, many studies have focused on the solution of data clustering from diverse perspectives, such as clustering algorithms with different similarity criteria [
2], extensions and modification for particular data types [
3], identifying the optimal number of clusters [
4], subspace clustering and multiview clustering [
5,
6], clustering results evaluation [
7], and applications of data clustering [
8].
Unlike supervised learning methods, data clustering is essentially an ill-posed problem [
9] because the results of different clustering algorithms can be equally accepted without prior knowledge. In other words, any clustering result may be superior to others in a particular pattern distribution. This problem results in a dilemma: users need to select an appropriate clustering algorithm according to the inherent characteristics of data and domain knowledge. The clustering ensemble appears in this background, and it can generate an excellent and stable cluster assignment by combining multiple clustering results [
10]. Clustering ensemble outperforms the single clustering algorithm in several aspects [
11,
12]: (i) the average performance of clustering ensemble on different data types and pattern distributions is superior to its optimal ensemble member; (ii) it can obtain a consistent result that cannot be achieved by any single clustering algorithm; (iii) it is more robust to noises, outliers, and sampling changes than single clustering algorithm; (iv) it outperforms the single clustering algorithm in terms of parallelizability and scalability; and (v) it can integrate multiple clustering results generated from distributed data sources or features. Generally, clustering ensemble comprises two main phases. In the first phase, a group of base clustering results is produced. In the second phase, a consensus function is designed to generate a final cluster assignment by combing base clustering results. The base clustering members can be produced in many ways, such as by using different clustering algorithms, employing one clustering algorithm with different parameters, and utilizing subsets of data or features [
13]. The typical methods used to design a consensus function include a relabeling strategy [
14], feature-based methods [
15,
16], pairwise-similarity-based algorithms [
17,
18], and graph-based approaches [
19,
20]. In general, three ensemble-information matrices [
11] can be acquired from the base clustering results: the label-assignment matrix, pairwise similarity matrix, and binary cluster association matrix. Each ensemble strategy mentioned above utilizes one of these matrices to combine base clustering results. That is to say, the clustering ensemble results of these methods are derived either from a reorganized data description in feature space or from the relationships between data objects in structure space. In reality, the data characteristics that are expressed by features or attributes and the structure information manifested as relationships between objects are two presentations of the data from different perspectives. Therefore, both of them provide valuable guidance on producing the final ensemble result. However, the existing clustering ensemble algorithms, according to our knowledge, seldom consider combining these two data descriptions in the design of the consensus function.
Data characteristics and structure information focus on different aspects of data description. Thus, their combination can potentially improve thereliability of clustering ensemble. With this motivation, we develop a novel clustering ensemble framework to integrate data characteristics with structure information. To serve this purpose, our work is focused on addressing the following two key issues: (i) What structural information should be employed to construct the consensus function? Many local relationships are commonly used to describe structure information, such as the label-assignment information originally obtained from an ensemble, co-association matrix, or associations between data objects or those among clusters [
13]. In general, the structural information represents the implicit relationships between data objects. It includes not only the local similarity between objects, but also a global structure implying the intrinsic pattern of the data. Therefore, using only the local structure to design the clustering consensus function is far from sufficient, and determining how to effectively extract and utilize suitable structure information is an important problem. (ii) How can we integrate data characteristics and structure information to produce the consensus clustering result? If only concentrating on data characteristics, the deep clustering algorithms [
21,
22,
23] provide an effective data partitioning strategy using the powerful representation learning ability of deep learning. For example, an autoencoder (AE) [
24] is a commonly used framework with multiple layers, in which, each layer captures specific latent information from data characteristics, while in a clustering ensemble context, one can acquire various forms of structure information from the data and its base clusterings. Therefore, what is the interaction relationship between data characteristics and structure information in the generation of the final clustering result? Furthermore, how can these two different types of information be combined elegantly, and how can they be represented in a suitable form for clustering ensemble? These problems constitute the other key issue of our work.
To address the first problem, we intend to capture the structural information of the data from a set of base clusterings. All of the base clusterings are produced on the same data; thus, some forms of relationships certainly exist between base clusterings, between clusters, and between objects. Viewed from this aspect, the intrinsic structure information can be captured from a set of base clustering results by explicating and coupling the above relationships.
We employ a variational graph autoencoder (VGAE) module [
25] to cope with the second key issue by learning the joint representations of data characteristics and structure information suitable for the clustering objective. On this basis, we derive a joint optimization model that incorporates representation learning and consensus cluster partitioning into a unified framework.
In this study, we propose a novel framework, namely clustering ensemble viewed from graph embedding (CEvGE), to integrate data characteristics with structure information by employing the powerful representation ability of GNNs. Our work can be viewed as an improvement on a clustering ensemble model by learning appropriate representations in the latent space. In addition, it can be viewed as an improvement on a deep clustering method by imposing a global structure constraint. Our main contributions can be summarized as follows:
- (i)
We develop a novel clustering ensemble framework viewed from GNNs that produces the ensemble result by exploiting both data characteristics and structure information.
- (ii)
We reconstruct raw data as an object similarity graph, and integrate data characteristics and structure information elegantly by learning their joint representations in a variational GNN. We employ a Gaussian mixture model (GMM) to predict the consensus cluster assignment for the latent embeddings, which is a natural model for clustering.
- (iii)
We construct a unified optimization model to integrate the objectives of joint embedding learning and final cluster assignment, in which, clustering can provide a correct guidance for embedding learning.
- (iv)
We conduct extensive experiments on synthetic and real-world data sets. The results demonstrate the validity and superiority of our framework against reference algorithms.
The remainder of this paper is organized as follows.
Section 2 introduces some closely related works. In
Section 3, we discuss the construction and implementation of our CEvGE framework in detail. In
Section 4, we compare the CEvGE with several state-of-the-art clustering ensemble models and deep clustering algorithms in a series of experiments Finally, we conclude this work in
Section 5.
3. The Proposed Framework
For a set of N data objects in the D-dimensional space, let represent a set of T base clusterings for , where is the th clustering member, denotes the number of clusters in , and is the th cluster. For the object , denotes its cluster label in the th base clustering. The label set, including all of the different labels in , is denoted by , and the objects assigned with label in are marked as . The task of clustering ensemble is to produce a consensus partition for by combining all of the base clusterings, where K is the number of clusters in , and denotes the th cluster in the consensus result.
3.1. Overview of the Framework
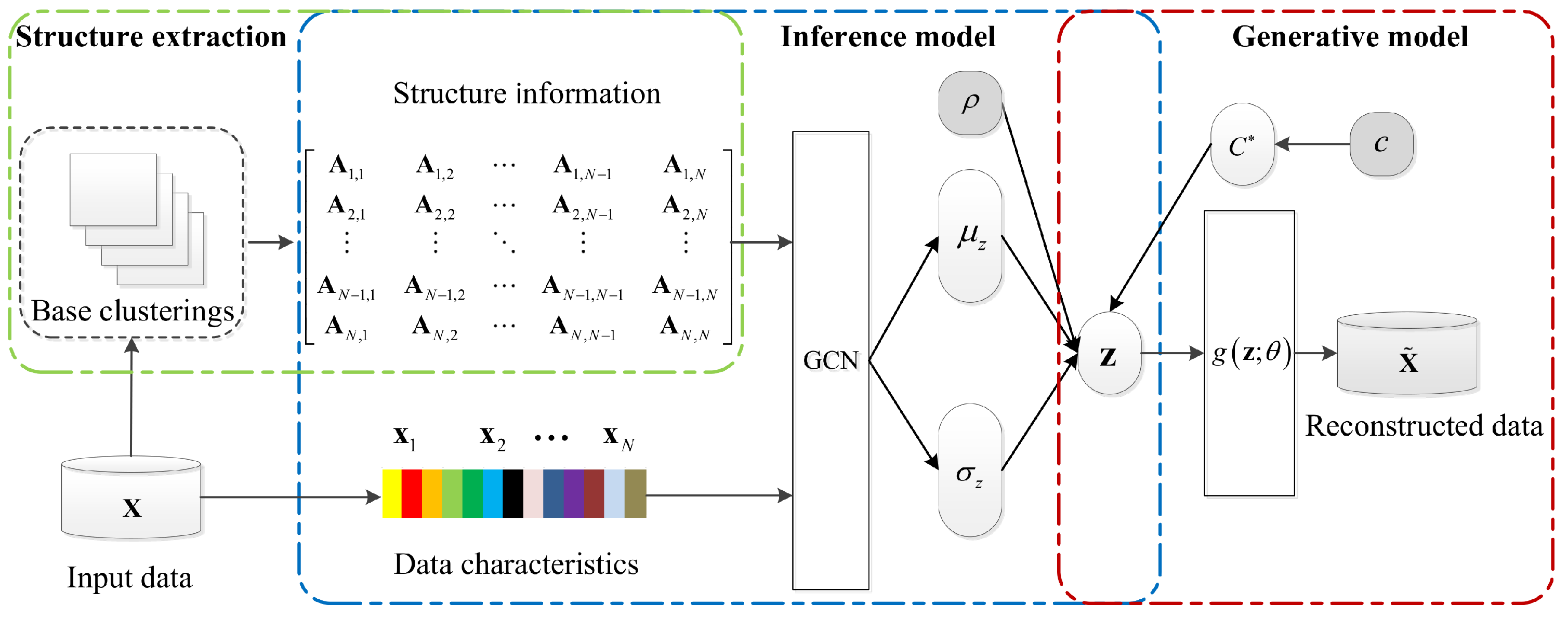
The integral construction of the CEvGE framework is illustrated in
Figure 1. In the CEvGE, the structure information of data is firstly extracted from a set of base clusterings. With the help of the structure information, the data set can be reorganized as an an object similarity graph. Then, the data characteristics and structure information are integrated in a VGAE module viewed from graph embedding perspective. In the latent space, a GMM is applied to predict the consensus cluster assignment for the joint embedding. Finally, the VGAE module and the GMM are trained jointly in a unified optimization model, which integrates objectives of graph embedding and consensus cluster assignment.
3.2. Extraction of Structure Information
An affinity matrix is always constructed to describe the data structure, where each element represents relationships between two data objects evaluated by a certain similarity measure. Thus, an adequate similarity measure that can express the inherent data relationships comprehensively is very important when describing structure information. In the original data space before clustering, the data structure can be directly captured by calculating pairwise similarity. However, this form of structure information can only describe presentational relationships from a local perspective. In the clustering ensemble context, we can explore extra structure information from a set of base clusterings. On the one hand, data relationships are reflected in the inner-dependence within a base clustering, and, on the other hand, they are also implied in the inter-dependence among different base clusterings. As a result, the global structure information that reveals an intrinsic pattern of data can be acquired by uncovering the coupling relationships between base clusterings, between clusters, and between data objects. In this work, the coupling relationships are in terms of two elements: interactions between base clusterings and between data objects [
17]. We propose capturing and incorporating them to tease out the implicit global relationships in the data, which will be used subsequently to construct the affinity matrix.
3.2.1. Coupling of Base Clusterings
All base clustering results are different partitionings on the same data; as a result, there must be some relationships among these base results. From intra and inner perspectives, the coupling of base clusterings comprises two components: the intra-coupling impresses the interaction between cluster labels within one base clustering, whereas the inner-coupling indicates the interaction between two base clusterings. According to this idea, we use the coupled clustering similarity for clusters (CCSC) between two cluster labels to describe the coupling relationship of base clusterings:
where
is the CCSC between two cluster labels
and
.
is the intra-coupled clustering similarity (IaCS) between
and
, used to describe the intra-coupling of base clusterings by calculating the frequency of cluster labels within a base clustering.
is the inter-coupled relative similarity (IeRS) between
and
based on another base clustering
, used to characterize the intra-coupling of base clusterings by comparing the co-occurrence of the cluster labels among different base clusterings, where
is the label set of
. The IaCS is defined as:
The IeRS is defined as:
where
is the weight of the base clustering
,
, and
is defined as:
In Equation (
4),
denotes the set
, where
is the label set of
in
.
3.2.2. Coupling of Data Objects
Similarly, the coupling relationships between objects can also be described from the following two perspectives. In terms of the intra-perspective, we use the intra-coupled object similarity (IaOS) to measure the similarity between two objects, which is defined as the average sum of the CCSC between the associated cluster labels ranging over all of the base clusterings. The IaOS between
and
can be calculated as
whereas, from the inter-perspective, we reflect the interaction between data objects by mining their neighbors’ correlation. Accordingly, we utilize the common neighbors between two objects to mesure the inter-coupled object similarity (IeOS), which is defined as
In Equation (
6) where
denotes the IeOS between objects
and
.
represents the neighbor set of
, and is defined as
is a Gaussian kernel function with a threshold
, which is defined as
where
and
are the normalizer and width of the kernel function, respectively, and
denotes a certain similarity measure for data objects.
The location of a data object in a clustering is determined by the cluster it belongs to. Accordingly, we can integrate the relationships from the inner-perspectives and inter-perspectives together through the associated clusters. In particular, we induce the coupled similarity of objects by specifying the similarity measure employed in Equation (
8) to be IaOS, and we have
Then, the IeOS can be converted to a new similarity measure for objects, namely coupled clustering and object similarity (CCOS). The CCOS between
and
can be calculated as
where the neighbor sets are defined as
and
, respectively. In this manner, both the intra-coupled and inter-coupled relationships between data objects are considered in the CCOS. In the meantime, the intra-coupled and inter-coupled interactions between base clusterings are also taken into account by the new similarity measure.
3.2.3. Structure Information Organized by a Affinity Matrix
According to the above discussion, a global structure description can be extracted from a set of base clusterings, i.e., CCOS. Compared with previous local similarity measurements, the CCOS expresses comprehensive relationships between data objects from multiple perspectives by exploiting base clusterings. Thus, we use the CCOS to construct an affinity matrix
that organizes the structure information of the data. The element
in the matrix is denoted as
3.3. Clustering Ensemble Viewed from Graph Embedding Perspective
The affinity matrix of structure information can be seen as geometric constraints of the data. As a result, we can reorganize the input data as an objects similarity graph , which includes both the characteristics and structure of the data. In this way, the clustering ensemble task on is transformed into a clustering problem on the reorganized graph . To this end, we develop a joint model within the VGAE framework. In this model, data characteristics and structure information are integrated by learning their joint embeddings in latent space, and, subsequently, a GMM is utilized to predict the final cluster assignments for the latent embeddings.
3.3.1. Inference Model
The inference model is used to integrate data characteristics and structure information jointly by mapping the graph-reorganized data to latent embeddings, which are parameterized by a two-layer GCN as
In Equation (
12),
denotes the embedding of the data in latent space. For a certain data object
, the corresponding embedding can be acquired from the following distribution:
where
denotes the associated row in the affinity matrix. The vectors
and
are the mean and variance of the latent distribution, respectively. They are all learned by the GCN, whose structure is defined as
where the function
is a graph convolutional layer [
39], and
and
are learnable weight matrices of the first and second layers, respectively.
is shared between
and
.
3.3.2. Generative Model
In our framework, the generative model functions are used to reconstruct input data from the learned embeddings, as well as to predict the consensus cluster assignment. Specifically, we assume the input data are generated from a mixture of Gaussian distributions. Thus, we approximate the clustering ensemble result by a GMM, and introduce a K-dimensional vector to indicate the prior probabilities of each cluster in the consensus cluster assignment. The generative process can be modeled as follows:
Sample a cluster from the consensus clustering result , where is the categorical distribution of parameterized by .
Sample a vector from the picked cluster, where and denote the mean and variance of the kth Gaussian component, respectively.
Sample a vector from the reconstructed data . For binary data, the vector can be sampled from a multivariate Bernoulli distribution as , where is computed by , whereas, for real-value data, the vector can be sampled from a multivariate Gaussian distribution, where and are learned by . is a nonlinear function parameterized by . In our framework, the inner product decoder is employed.
According to the above generative process, the joint probability
can be factorized as
Since
and
are independently conditioned on
, we have
3.4. Learning Algorithm
Our CEvGE framework can be tuned by maximizing the log-likelihood of the input data as
Using the Jensen’s inequality, we have
where
denotes the ELBO of
, and
is the variational approximation of the true posterior
. By using a mean-field distribution,
can be factorized as
According to Equations (
16) and (
22),
can be rewritten as
Substituting Equations (
13), (
17), (
18) and (
19), into Equation (
23), and using the Monte Carlo SGVB estimator, we can further transform
into
where
M is the total number of samples in the SGVB estimator,
D and
R are the dimensionalities of the input data and latent embedding, respectively,
is the
th feature of
, and the operators
and
denote the
th and
th component of the vector •, respectively.
is calculated by
, in which,
is the
th Monte Carlo sample picked from
. The reparameterization trick is used to employ gradient backpropagation on the stochastic layer, and
is calculated as
In Equation (
25), the learning rate
is sampled from
and the symbol * denotes the element-wise multiplication operator.
and
are learned by the GCN formulated in Equation (
14).
In the proposed CEvGE framework, the posterior distribution
that maximizes the ELBO must be found to obtain the final clustering result.
can be rewritten by regrouping Equation (
23) as
where
is the Kullback–Leibler (KL) divergence function used for the divergence between two distributions, and
is the Gaussian prior distribution for the latent embedding. The first term in Equation (
26) is independent of
, and the second term is non-negative according to the definition of KL divergence. Thus,
can achieve the maximum value when
holds. Accordingly, the optimal cluster assignment
can be estimated by
The latent embedding
will be an appropriate representation for clustering ensemble as the embedding learning and the cluster assignment are incorporated into the joint framework. The information loss caused by the mean-field assumption in Equation (
22) can be preserved by the relationship between
and
implied in
.
To further explore how our optimization model can work, we rewrite the ELBO in Equation (
21) as
In Equation (
28), the first term is obviously a reconstruction component, which helps our framework to explain the relationships between data objects well by employing latent embeddings and their cluster assignments, whereas the second term represents the divergence between the variational posterior distritution
and the prior distribution
modeled by a GMM. This divergence can be considered as a regularization term in our optimization model, which makes the learned embedding
lie on a Gaussian mixture manifold. Accordingly, we can draw the following conclusions: (i) the data characteristics and structure information of data are integrated elegantly in a generative graph embedding framework; (ii) the joint embeddings are learned with the guidance of the process of clustering, and, meanwhile, the prediction of cluster assignments is enhanced by the appropriate representations; (iii) the validity and reliability of the clustering ensemble result produced by the CEvGE framework can be improved.
3.5. Overall Implementation
The implementation of the developed CEvGE framework is formally summarized in Algorithm 1.
| Algorithm 1 The implementation of CEvGE framework |
Data objects , learning rate , number of Monte Carlo samples in SGVB estimator M, epochs L. Consistent clustering result . - 1:
Produce an ensemble of base clusterings for ; - 2:
From Equation ( 11), construct affinity matrix to represent structure information for - 3:
Choose - 4:
fordo - 5:
for do - 6:
; - 7:
; - 8:
Sample - 9:
Sample - 10:
Generate reconstructed - 11:
From Equation ( 24), compute - 12:
Backpropagate gradients - 13:
end for - 14:
end for - 15:
From Equation ( 27), obtain the category assignment - 16:
return
|
5. Conclusions and Future Work
Data characteristics and structure information play different roles in describing the intrinsic pattern of the data. A GNN-based clustering ensemble framework, namely CEvGE, was developed to utilize these two types of information effectively for the production of a consensus clustering result. In this framework, the structure information of data was extracted from base clusterings and used to reorganize the data as an object similarity graph. Subsequently, the data characteristics and structure information were combined elegantly in the form of graph embedding. Lastly, a joint optimization model was constructed to unify the objectives of graph embedding and cluster partitioning, which makes the final clustering result that is produced by appropriate data representations enhanced by structure information. In the experimental analysis, we compared our framework with several state-of-the-art clustering ensemble and deep clustering algorithms on both synthetic and real data sets. The results reflect the validity of the proposed framework.
This work mainly focuses on a general issue of how to enhance clustering ensemble by integrating data characteristics and structure information. It provides a novel research perspective for the clustering ensemble problem. Meanwhile, some specific problems are yet to be solved. For example, the scalability issue of the proposed framework cannot be overlooked, which potentially impedes its usage on large scale data. Concerning this issue, we plan to improve the computational efficiency by optimizing its calculation mode and execution mechanism in the coming research. In addition, extending the availability of the framework for different data types and application contexts is another focus of our future plan.








{kind=link}
{kind=link}
{kind=link}
{kind=link}