Current data-hiding methods try to provide high embedding capacity with low distortion. We propose a novel LSB matching algorithm with low distortion that embeds high-capacity data in the cover images. The constructions of this paper are as follows: (1) the scanned document was pre-processed by halftone, quadtree, decimal coding, and S-Box; (2) a novel LSB matching algorithm with the lowest distortion was applied, based on the golden ratio.
3.2. Data Embedding
Mielikainen [
25] proposed a simple LSB matching algorithm by modifying the pixel ±1, and two pixels as an embedding unit. The embedding and extraction procedure of Milelikainen’s scheme was illustrated as follows:
Set
p and
q are the cover pixels pair, and
c1 and
c2 are two bits of secret data, respectively. The embedding equation is given in Equation (1). After embedding, the stego image is obtained, and
p′ and
q′ are the modified pixels pair. The secret data
c1 can be extracted from the least significant bit of
p′. The secret data
c2 can be extracted according to Equation (2).
In this section, the information compressed by halftone, quadtree, decimal coding, and S-Box substitution was embedded into a cover image by a novel revisited LSB matching method. To improve the capacity of data hiding and transmission security, the secret data were compressed then embedded into the cover image by an LSB matching algorithm based on the golden ratio. For the first time, the golden ratio point was used to find the best embedding position and applied as the basic criterion to design the mapping function. First, because the output of the S-Box was 4 bits, the cover image was divided into non-overlapping pixel pairs, and every four pixels were defined as a group. Second, the optimal embedding positions were found according to the golden ratio. Finally, the XOR operation assembled the eight least-significant bits to yield four original bits from the embedding unit. Our new scheme is described below:
➀ In raster scan order, the cover image was divided into non-overlapping pixel pairs, each pair including four pixels. Assuming the four pixels , , and comprise a hiding unit, the four bits of secret information were .
➁ Each pixel was converted into eight binary bits, and the embedding positions were found according to the calculations 8 × (1 − 0.618) ≈ 3. Normally, the change of the lowest three significant bits of the pixel value does not affect human vision. To get better visual quality, the optimal embedding position was found according to the calculations 3 × (1 − 0.618) ≈ 1. The least significant bit can be used to embed information. Assuming
,
,
,
, the four bits of secret data are embedded into the exact location. Here, we defined four values
A,
B,
C, and
D, and they were obtained according to Equation (3):
As shown in Equation (1), the values of A and D were controlled by changing of . Similarly, the values of A and B were controlled by the least significant bit of . B and C were controlled by the least significant bit of . C and D were controlled by the least significant bit of . When the pixel was an odd number, A was controlled by modifying bit and by . When the pixel was an even number, A was controlled by modifying bit and by . Similarly, B, C, and D were controlled by modifying the least significant bit and the second least significant bit of , , and .
➂ We compared four secret data with four values to see whether they were the same. The four pixels did not need to be altered in the data-hiding process if they were equal. Otherwise, we needed to modify the four pixels until they were equal. We describe the scheme in detail as follows:
Step 1: If there was , the four pixels did not need to be altered in the data-hiding process.
Step 2: If only or or or , and the pixel was an odd number, we needed to control it with ; otherwise, we controlled it with , so that . In the same way, if the pixel was an odd number, we needed to control it with ; otherwise, we controlled it with , so that . If the pixel was an odd number, we needed to control it with ; otherwise, we controlled it with , so that . If the pixel was an odd number, we needed to control it with ; otherwise, we controlled it with , so that .
Step 3: If only or or or or or, if the pixel was an odd number, we needed to control it with , otherwise, we controlled it with , so that. In the same manner, if the pixels and were odd numbers, we needed to control them with , , otherwise, we controlled them with , , so that. If the pixel was an odd number, we needed to control it with ; otherwise, we controlled it with , so that . If the pixel was an odd number, we needed to control it with ; otherwise, we controlled it b with y , so that . If the pixel , were odd numbers, we needed to control them with , ; otherwise, we controlled them with , , so that . If the pixel was an odd number, we needed to control it with ; otherwise, we controlled it with , so that .
Step 4: If or or or . If was an odd number, we needed to control it with ; otherwise, we controlled it with . If was an odd number, we needed to control it with ; otherwise, we controlled it with , so that . In the same manner, we modified the other pixels and obtained , , .
Step 5: If, when was an odd number, we needed to control it with ; otherwise, we controlled it with . If was an odd number, we needed to control it with ; otherwise, we controlled it with . If was an odd number, we needed to control it with ; otherwise, we controlled it with . Lastly, we obtained .
According to the scheme above, four bits of the secret data, , , and , were ensured to be embedded into the pixel pairs , , and respectively.
For example, as
Table 2 shows,
,
,
and
represent any four bits of secret information. When
,
,
,
, we obtained
A = 1,
B = 0,
C = 1, and
D = 0 according to Equation (1). We adjusted the pixel values by the above rule and let
,
,
,
denote the adjusted pixel values.
As seen from
Table 1, the probability of four pixels that needed to be modified was 1/16, the probability of three pixels that need to be modified was 4/16, the probability of two pixels that needed to be modified was 6/16, the probability of one pixel that needed to be modified was 4/16, and the probability of the preserved original pixels was 1/16. The expected value of the changed pixels of the proposed algorithm was:
The expected number of modifications per pixel was: (29/16) ÷ 4 ≈ 0.453.
As
Table 3 shows, one of the most important factors of the proposed LSB matching revisited scheme was that at most, only one pixel at a time can be modified by +1 or −1 when carrying four bits of secret information. Changing four pixels at the same time does not occur. The probability of two pixels needing modification was 7/16, the probability of one pixel needing modification was 8/16, and the probability of the preserved original pixels was 1/16. The expected value of the changed pixels of the proposed algorithm was (7/16) × 2 + (8/16) × 1 + (1/16) × 0 = 22/16. The expected number of modifications per pixel was (22/16) ÷ 4 ≈ 0.344. The secret data were pre-processed: when the secret data were a bit stream, the expected number of modifications per pixel was (22/16) ÷ 6 ≈ 0.229. When the secret data in the document were scanned, the expected number of modifications per pixel was (22/16) ÷ 32 ≈ 0.0430. This result demonstrates that the proposed approach effectively prevents pixel distortion after data hiding.
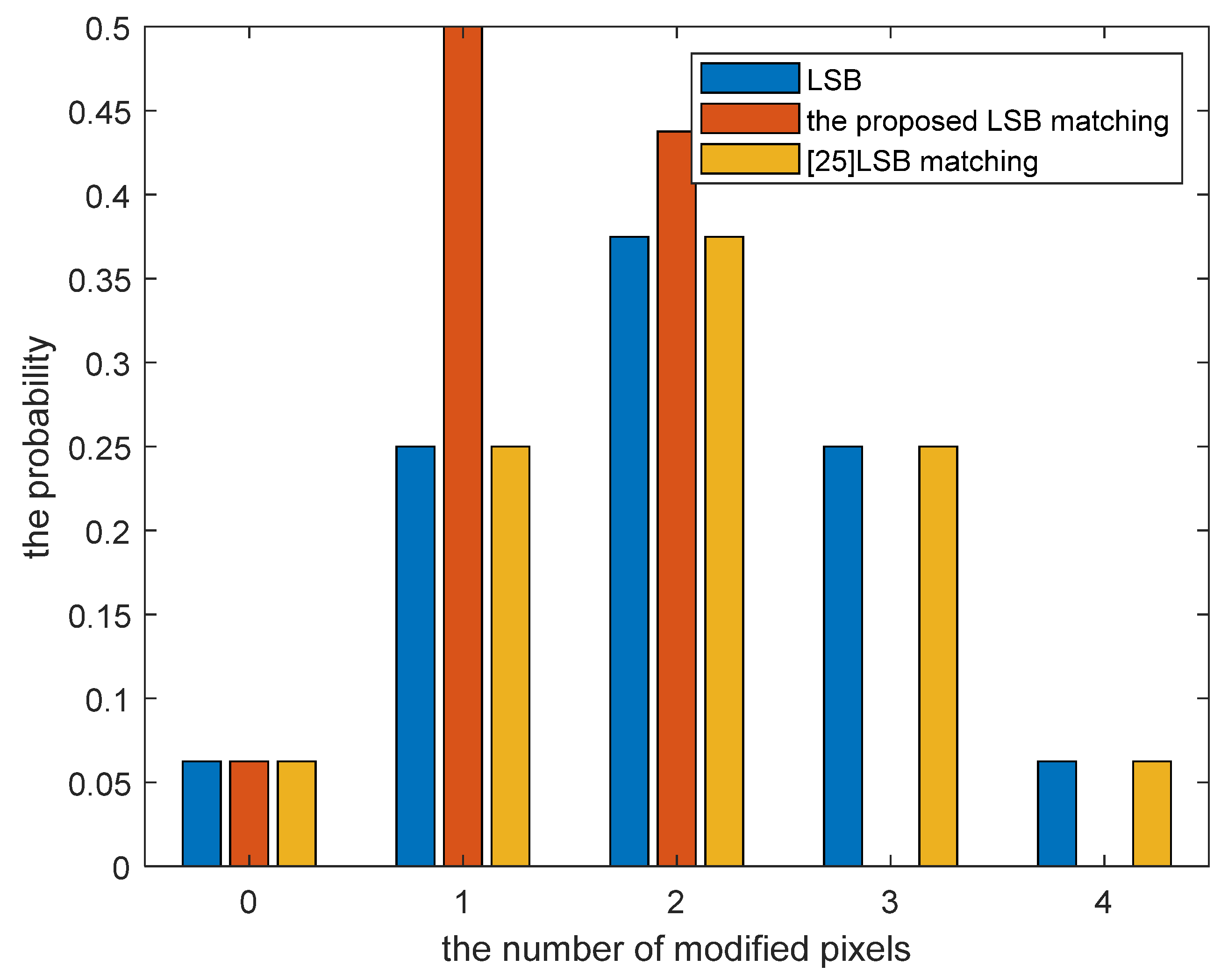
Figure 2 shows the comparison of the probability of modifying pixels of the three methods. Mielikainen [
25] proposed an LSB matching revisited scheme and groups two pixels as an embedding unit. For every four bits of data embedded, the pixel modification probability of the LSB method and Mielikainen’s scheme. However, the LSB matching scheme has low computation complexity. It can be seen that our proposed method modified at most two pixels every four pixels, and the magnitude of the modification was 1. The LSB scheme and Mielikainen’s approach modified more pixel values. Our study set every four pixels as a unit, and the computational complexity was lower.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}