3.2. Optimizer and Loss Function
Our network was pre-trained on the ImageNet [
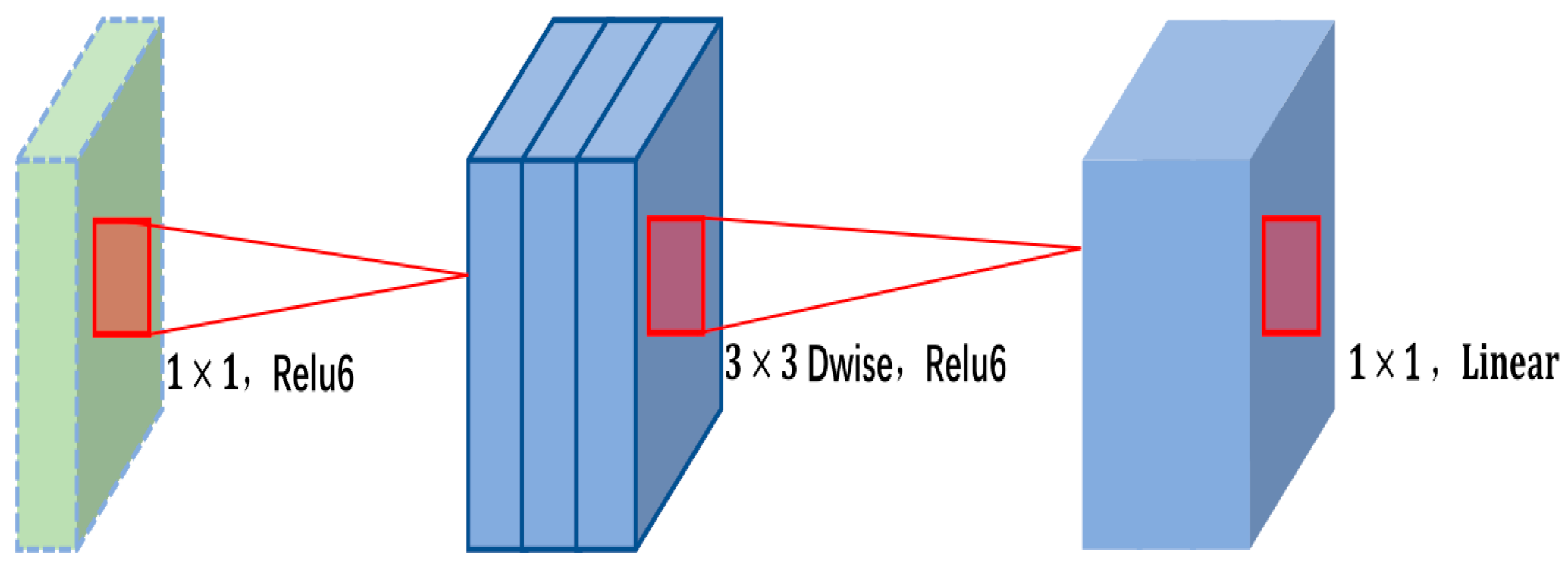
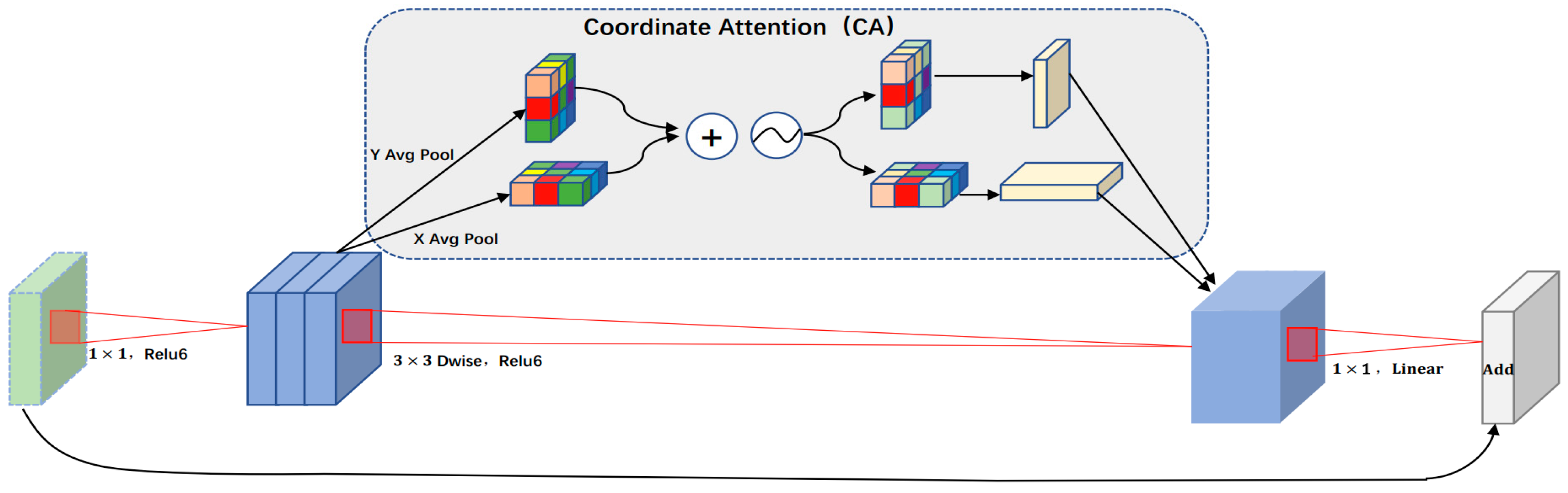
26] dataset using Mobilenetv2 after embedding coordinate attention (CA) as the backbone of the entire network. In this paper, experiments were conducted on the KITTI dataset. The concrete process is as follows: the Adam [
27] optimizer was used to train the network on the training set. During the first 50 epochs, the training of the backbone network was frozen, and only the model was slightly adjusted. The feature extraction network did not change. The initial learning rate was set to 10
−3 and the batch size was set to 16. After 50 epochs, the network backbone training was unfrozen. After the feature extraction network changed, all the parameters of the network would then change. The initial learning rate was 10
−4 and the batch size was 8. The multiplication factor and weight attenuation of the updated learning rate were 0.94 and 0.0005, respectively. The IoU threshold was set to 0.5. The mean average precision (mAP) of each class was evaluated on the validation set.
The loss function is an important index to evaluate the training effect of the network, and the corresponding loss function in this paper consisted of three parts: the location loss function (
), the confidence loss function (
) and the class loss function (
). The total loss function was
, where
represents the localization loss function coefficient,
represents the confidence loss function coefficient and
represents the category loss function coefficient.
1
. In different datasets, the values of
and
will change according to the specific situation. Additionally, the loss function of confidence and class adopted the cross-entropy loss function, and the loss function of location adopted CIoU [
28] loss. CIoU loss function makes the object box regression more stable, and it does not face problems such as scattering during IoU training, is sensitive to scale transformation and converges faster than IoU loss function. Then, for the bounding box localization loss
, the IoU loss function needs to be replaced by the CIoU loss function, which can be expressed as:
where
and
and
and
respectively, represent the width and height of the prediction frame and the true frame. The loss function
of the corresponding CIoU can be expressed as:
The prediction confidence loss function
is measured by the cross-entropy loss function, which can be expressed as:
where
is the number of divided grids and B is the number of prior frames contained in each grid.
and
indicate whether the
-th prior frame of the
-th grid contains an object and whether it is set to 1 or 0.
is the confidence error weight of the prior frame without objects; it has an extremely small value because positive samples and negative samples in prior frame are extremely unbalanced (there are very few prior frames with objects).
The class loss
was used to measure the class error between the prediction frame and the true frame, and was measured by the cross-entropy loss function, which can be expressed as:
where
and
represent the class probabilities of the prediction frame and the true frame, respectively.
3.4. Analysis of Experimental Results
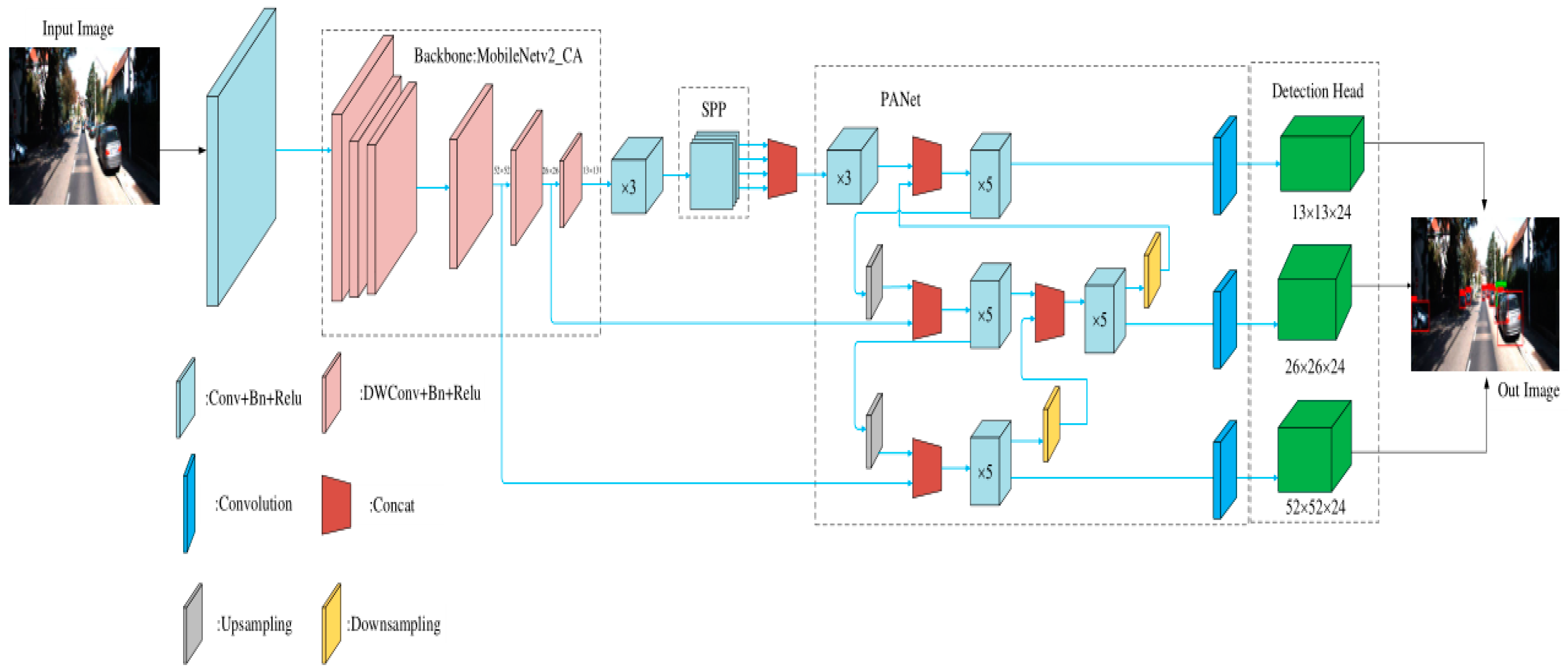
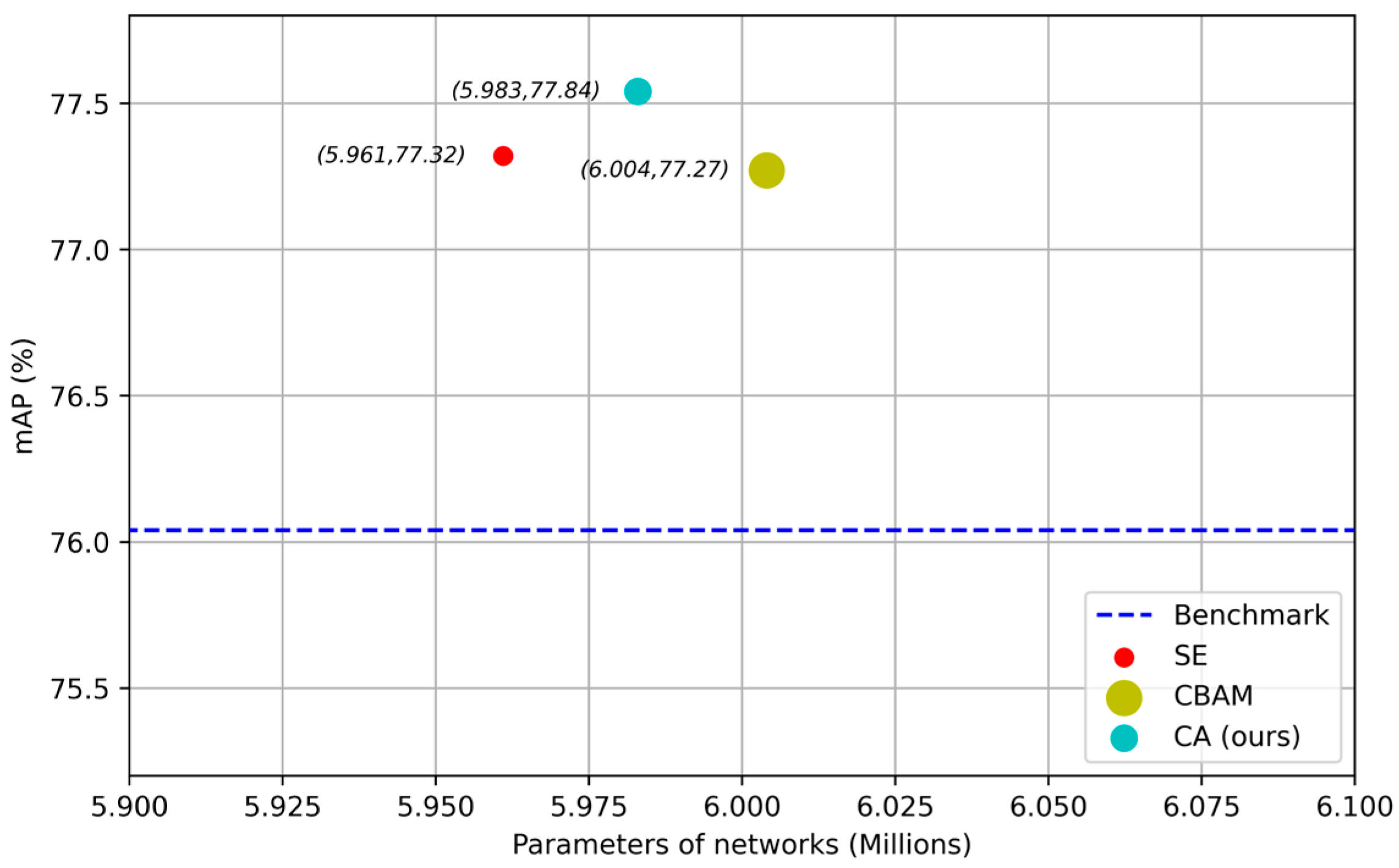
To verify the effectiveness of using the Mosaic image enhancement method and adding the coordinate attention (CA) mechanism to Mobilenetv2—the lightweight backbone feature extraction network—ablation experiments were designed for different modules. Ablation experiments were performed on two different datasets: KITTI and VOC.
Performing ablation experiments of the same module using a variety of different datasets can effectively verify whether each module can adapt to different task requirements in different scene datasets, and verify the actual contribution of each module to the network.
√ in
Table 3 represents the participation of the module. This module is represented in
Table 3. A denotes use of the Mobilenetv2 backbone network, B is with the addition of the coordinate attention (CA) mechanism to the backbone network, and C is with the addition of the Mosaic image enhancement to the data pre-processing stage. To verify that using the Mosaic image enhancement method and a lightweight backbone network incorporating a coordinated attention (CA) mechanism can improve the precision of network detection, a comparative experiment was designed.
Networks with the network backbone Mobilenetv1, networks with the network backbone Mobilenetv2, networks with a coordinated attention (CA) mechanism added to backbone Mobilenetv2 and networks with a coordinated attention (CA) mechanism added to backbone Mobilenetv2 using Mosaic image enhancement were trained separately and evaluated on two different datasets: KITTI and VOC. √ in
Table 3 represents the participation of this module. By using Mobilenetv2 as the backbone network, compared with the Mobilenetv1 backbone network, the accuracy improved by 2.7% on the KITTI dataset and 0.4% on the VOC dataset, but the detection speed was almost unchanged. Mobilenetv2 is shown to be an efficient and lightweight backbone network. After adding the attention mechanism CA to Mobilenetv2, the network considered both the relationship between the channels and the location information, which enhances the network’s sensitivity to direction and location information, strengthens the extraction of important features, and improves the network’s learning ability. The network accuracy was further improved—by 0.23% on the KITTI dataset and by 1% on the VOC dataset—proving the contribution of CA. After using the Mosaic image enhancement method, the network can detect objects outside the normal context, making the feature extraction of various objects more complete and continuous, allowing the attainment of more abundant image features. The detection accuracy was further improved on the KITTI dataset by 0.28%. On the VOC dataset, the detection accuracy was further improved by 0.31%, proving the contribution of Mosaic image enhancement. Compared with the original network, using Mobilenetv1 as the backbone, the detection accuracy on the KITTI dataset was increased by 3.21%, and the detection accuracy on the VOC dataset increased by 1.71%, which improved the overall generalization performance of the network.
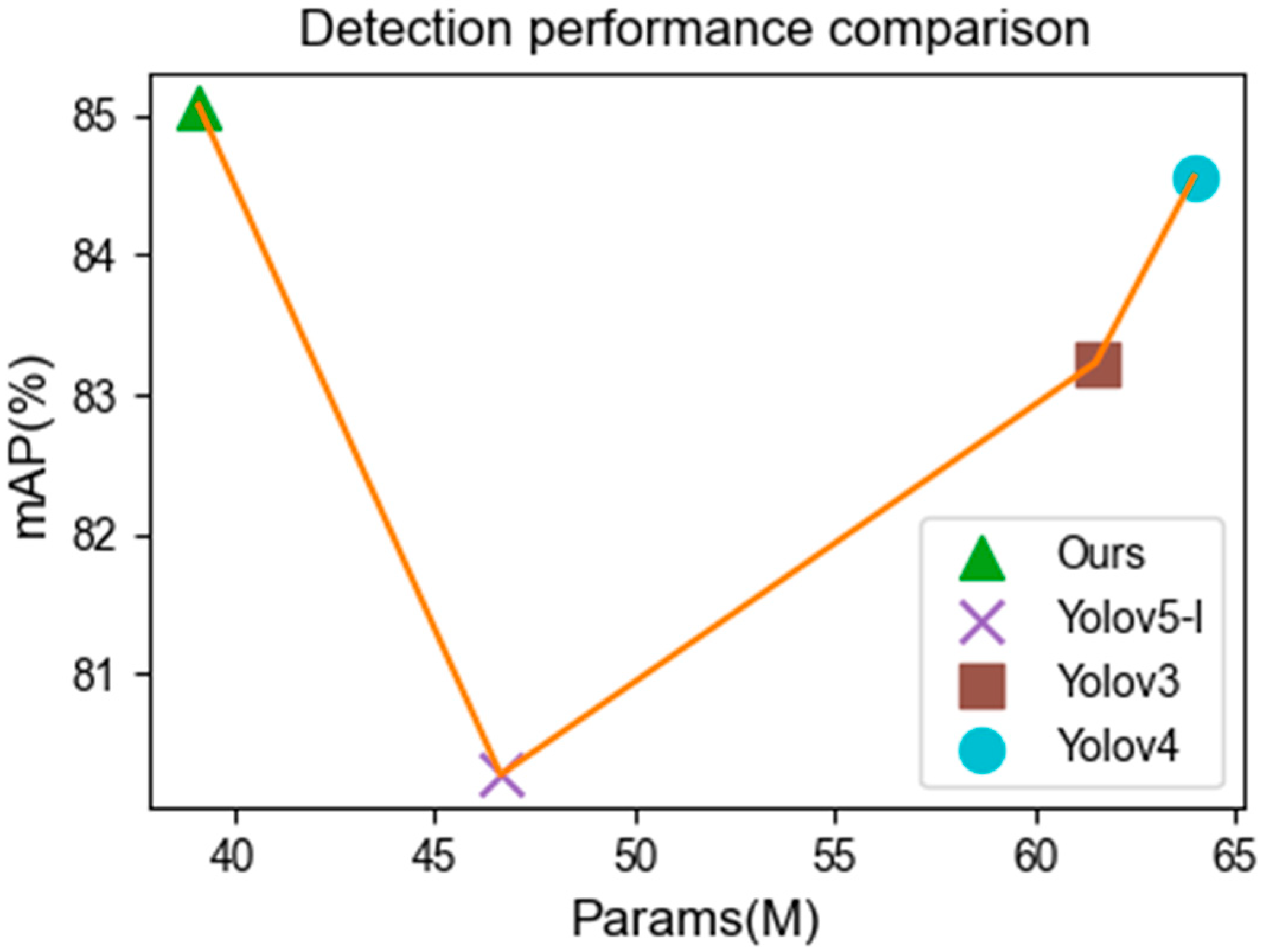
There are many kinds of current object detection networks. To verify the effectiveness of the networks in this paper, a variety of object detection networks were selected for experimental comparison on the KITTI dataset. Faster R-CNN [
3], SSD [
4], and YOLOv3 [
5], YOLOv4 [
21], YOLOv5-l [
29] and YOLOv4-tiny [
30] algorithms were selected to be trained on the KITTI dataset and compared with this detection network on the test set, focusing on average class accuracy, the number of model parameters, and detection speed.
The parameters in
Table 4 refer to the number of parameters of the network, and FPS refers to the number of images processed by the network each second, which can be used to characterize the network’s detection speed performance. As can be seen in
Table 4, compared with the Faster R-CNN algorithm, the detection speed of this paper was 3.1 times faster, the detection accuracy of the car improved by 15.14%, the detection accuracy of pedestrians improved by 18.71%, the detection accuracy of cyclists improved by 22.52% and the average detection accuracy (mAP) improved by 18.79%. However, the number of participants significantly decreased by 28.8%. Compared with the SSD algorithm, although the detection speed of this paper’s algorithm was reduced, the detection accuracy for cars improved by 9.57%, for pedestrians by 28.07%, for cyclists by 23.22% and the average detection accuracy (mAP) improved by 20.23% for the same number of model parameters. Compared with the YOLOv3 algorithm, the detection speed is slightly slower, the detection precision of cars is slightly higher, the detection precision of pedestrians improved by 2.73%, the detection precision of cyclists improved by 2.75%, the average detection precision (mAP) of this paper increased by 1.84% and the number of participants was only 63.8% of the YOLOv3 algorithm’s total number of participants. The network performance was better than that of the YOLOv3 algorithm. The network performance of this method was better than that of YOLOv3. Compared with YOLOv4, our algorithm improved by 0.67% in car detection accuracy, with almost the same level of accuracy as when detecting pedestrians. Additionally, an improvement of 1.05% was obtained in the detection accuracy of cyclists, and 0.51% in the average detection accuracy. Compared with YOLOv5, our algorithm improved by 6.23% in the detection accuracy of cars, 2.97% in the detection accuracy of pedestrians, 5.15% in the detection accuracy of cyclists and 4.79% in average detection accuracy. Compared with YOLOv4-tiny, our algorithm improved the average detection accuracy by 24.32%. We focused more on high detection accuracy than on increasing the detection speed. Taken together, the number of network parameters was significantly reduced in this paper, achieving the goal of excellent detection precision with a lightweight network.
In autonomous driving scenarios, cars, pedestrians and cyclists are the most common detection objects, and it is important to achieve high precision detection on the basis of real-time detection. During object detection, the real-time detection requirement is satisfied when the number of images per second that are processed by the network is more than 30 FPS. Therefore, the requirement of real-time detection can be met.
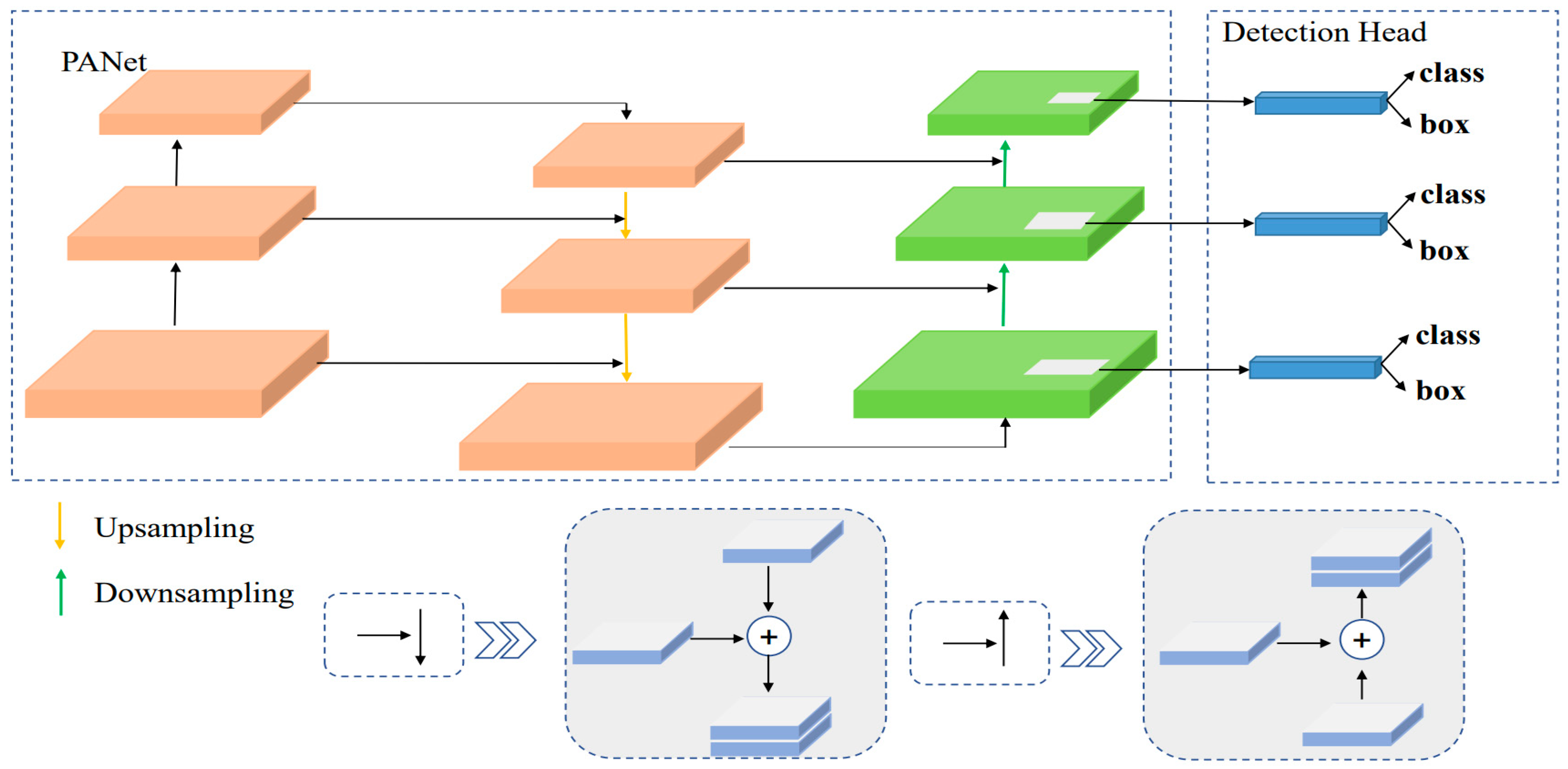
Table 4 shows that that the Faster R-CNN network does not meet the requirements of real-time detection, and the SSD network, although it achieved a faster detection speed, has a detection accuracy that is too low to meet the requirements of high-precision detection. Both the YOLOv3 network and the MobileNetv2_CA network in this paper can achieve real-time and high-precision detection. Therefore, the detection precision of the two networks are further compared in
Table 5, using the KITTI validation set and three different evaluation criteria. It can be seen that, under the three different criteria, the proposed network has a 2.25%, 1.38% and 0.9% higher detection precision than the YOLOv3 in the car class. The precision of pedestrian detection is 8.8%, 7.65% and 0.8% higher than that of YOLOv3, respectively. The detection precision of cyclists is 0.95%, 0.53% and 0.88% higher than that of YOLOv3, respectively. In conclusion, the detection precision of all the networks in this paper is better than that of the YOLOv3 network, and the number of parameters is only 63.58% of that of the YOLOv3 network. Although the FPS is slightly lower than that of the YOLOv3 network, because the Coordinate Attention (CA) mechanism added in this paper takes time to extract rich features, the detection precision of this network is higher if the real-time detection FPS is greater than 30 FPS. A scheme combining a better detection speed and precision was achieved under the premise of ensuring a lightweight network.
In the relevant traffic scenes of the autonomous driving KITTI dataset, vehicles (car) and pedestrians (pedestrian) are the main detection objects, and the pedestrian (pedestrian) class is a small target compared to the vehicle (car). During the data pre-processing stage, the Mosaic data enhancement method is used, and the network enhances the sensitivity of the network, allowing for it to detect small targets through pre-processing methods such as scaling the target image. When the backbone feature extraction network extracts relevant features, it coordinates the attention mechanism. In this algorithm, according to the uneven distribution of the large and small objects in the image, the information between the channels can be cooperatively processed, and more attention is paid to the adaptive extraction of the position information of objects of different sizes compared with the comparison algorithm without the attention mechanism. This increases the location information extraction of small targets. Therefore, compared with the vehicle (car) class detection accuracy, there were 2.25%, 1.38% and 0.9% gains under the different standards. In the pedestrian (pedestrian) class detection accuracy, higher gains of 8.8%, 7.65% and 0.8% were obtained under different standards. To show the difference in time taken by different layers in specific detection tasks in more detail, this paper split and refined different parts of the model for time series analysis.
Experiments on a single dataset may not be very convincing, and more datasets need to be tested and verified to draw better conclusions. Therefore, we selected several categories that are more common in autonomous driving scenarios for comparison. The results show that, on the Pascal Voc2007 + 2012 dataset, as show in
Table 6, our method improved the bus category by 0.29% compared to Faster R-CNN. The results were also 0.76% higher than SSD, 1.66% higher than Yolov3, 2.22% higher than Faster R-CNN in the motorbike category, 1.62% higher than SSD and 2.07% higher than Yolov3. In the person category, compared with Faster R-CNN, accuracy improved by 0.06%—by 5.31% compared with SSD and by 0.1% compared with Yolov3. Compared with Faster R-CNN on mAP, accuracy improved by 1.15%, was 3% higher than SSD and was 2.07% higher than Yolov3. Compared with YOLOv4, our algorithm showed little difference in terms of detection accuracy and detection speed, but the number of parameters in our model was almost half that of YOLOv4. Compared with YOLOv5, our algorithm improved the average detection accuracy by 6.26%. Compared with YOLOv4-tiny, our algorithm improved the average detection accuracy by 4.89%.
As shown in
Table 7, we also explored the effect of using different original image scaling ratios and width-to-height distortion ratios on the detection accuracy, and finally determined our parameter range to achieve the highest detection accuracy.
3.5. Network Detection Effect
To intuitively reflect the detection performance of this model, some pictures with a complex image environment that are difficult to distinguish were selected from the KITTI test set for detection.
Figure 8 shows the small object scene.
Figure 8a shows the Faster R-CNN detection effect. Although it can achieve more accurate object detection, its detection speed is too slow to meet the real-time detection requirements.
Figure 8b shows the SSD detection effect, which shows a more serious leakage phenomenon and does not detect any object.
Figure 8c shows the detection effect of YOLOv3 with some missed detections.
Figure 8d shows the detection effect of the network in this paper, which can more comprehensively and accurately detect the emerged objects.
Figure 9 shows low-light scenes.
Figure 9a shows the Faster R-CNN detection effect in low-light intensity scenes, while the vehicle located on the right side of the scene in the low-light environment was missed.
Figure 9b shows the SSD detection effect, where both the vehicle on the right side in the low-light environment and the vehicle on the left side, which belonged to a smaller target, were missed.
Figure 9c shows the detection effect of YOLOv3, which contains a high number of parameters despite achieving real-time detection of the target.
Figure 9d shows the detection effect of the network in this paper, which can precisely detect both vehicles in the low-light environment as well as vehicles belonging to smaller objects.
Figure 10 shows a complex scene containing small objects, occlusion, high light intensity and low light intensity, etc.
Figure 10a shows the Faster R-CNN detection effect. Although it can achieve a more accurate target detection, its detection speed is too slow to meet the real-time detection requirements.
Figure 10b shows the effect of SSD detection, and the detection phenomenon was missed for vehicles at a low light intensity and rear-obstructed vehicles.
Figure 10c shows the detection effect of YOLOv3, which can better detect the object, and
Figure 10d shows the detection effect of this network, which can correctly and simultaneously detect all the objects at a low light intensity, high light intensity and obscured objects. In summary, the network used in this paper can quickly and accurately complete detection tasks in different scenarios; therefore, the network proposed in this paper is a real-time object detection network with a light weight and high precision. To more clearly show the difference in the detection results of different models for targets in different KITTI dataset scenes, we visualized the final detection results of different models in a heat map. The first column in
Figure 11 shows the detection results of our work. It is clear that our model can accurately locate and detect hard-to-differentiate persons with the right shade in the first scenario, hard-to-differentiate two-vehicle targets with the left shade in the second scenario, and the smaller vehicle in the opposite lane and the vehicle target in the same direction in the third scenario. These scenarios took place in a poor lighting environment. In the fourth scenario, the smaller vehicle in the opposite lane and the vehicle in the same direction were accurately located and detected. This demonstrates the better robustness of our model compared toYOLOv4, YOLOv5, and YOLOv4-tiny in handling autonomous driving scenarios.
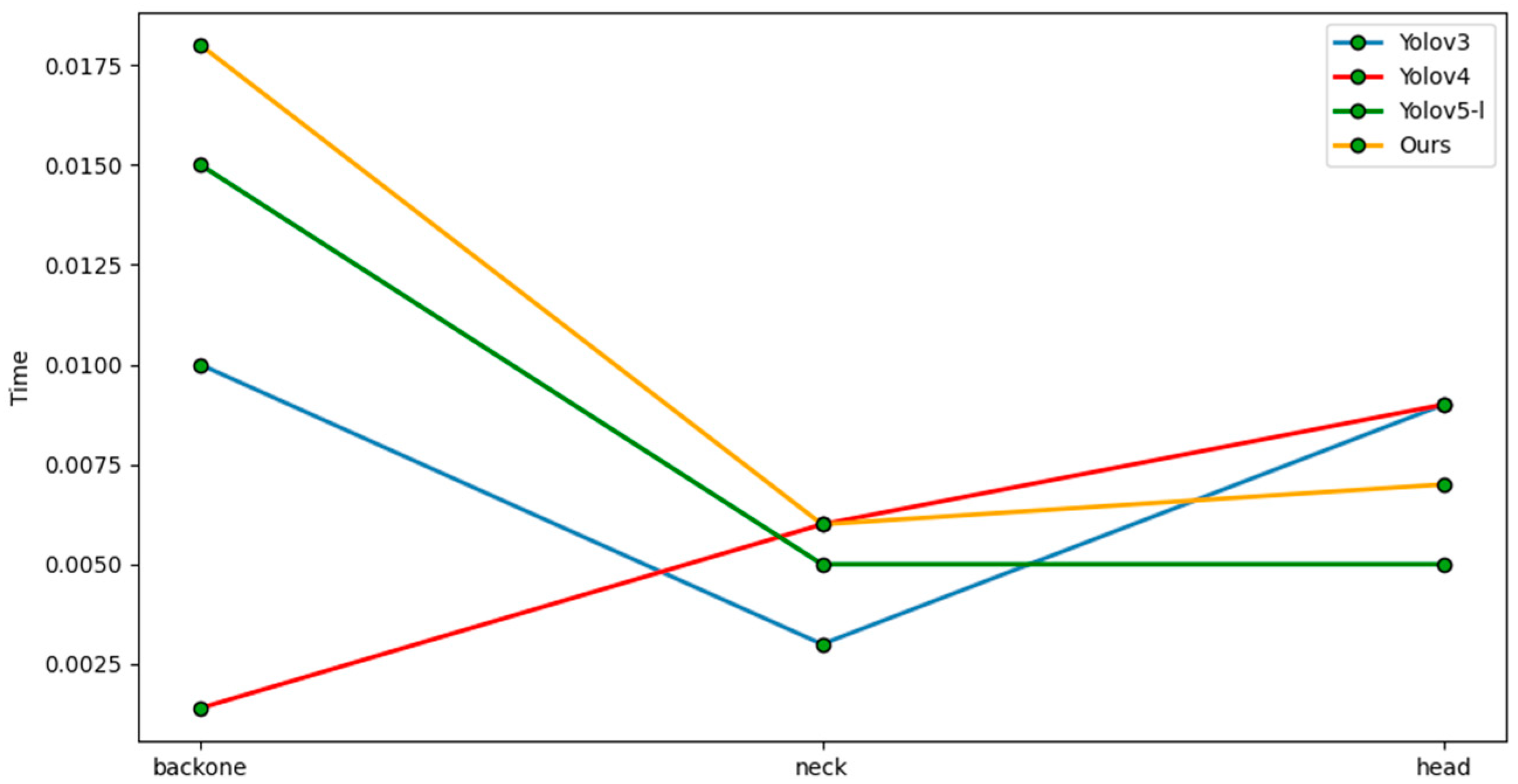
After comprehensively weighing the detection accuracy and the number of network parameters, our method could achieve real-time detection. A runtime comparison of each part of various detectors is shown in
Figure 11. To show the time-consuming differences between different layers during specific detection tasks in more detail, this paper split and refined the different parts of the model to analyze the runtime. Our model mainly uses the attention mechanism to extract backbone features. This is slightly more time-consuming, but real-time detection is still possible.
At the same time, in order to clearly show the superiority of our algorithm model in capturing small objects or occluded objects, we drew the heat map shown in
Figure 12 below, from which it can be seen that our algorithm model uses the attention mechanism in the process of network training and learning, strengthens some signals in the heat map and suppresses other parts, making the network extraction features more accurate.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}