
Privacy and Explainability: The Effects of Data Protection on Shapley Values

Abstract
:1. Introduction
- Data protection, through masking, does permit explainability using Shapley values, as they are not significantly affected under moderate protection;
- The use of different machine learning models causes different behaviors in Shapley values. For example, we see that among the methods, linear models are the ones in which Shapley values change the most.
2. Preliminaries
2.1. Masking Methods
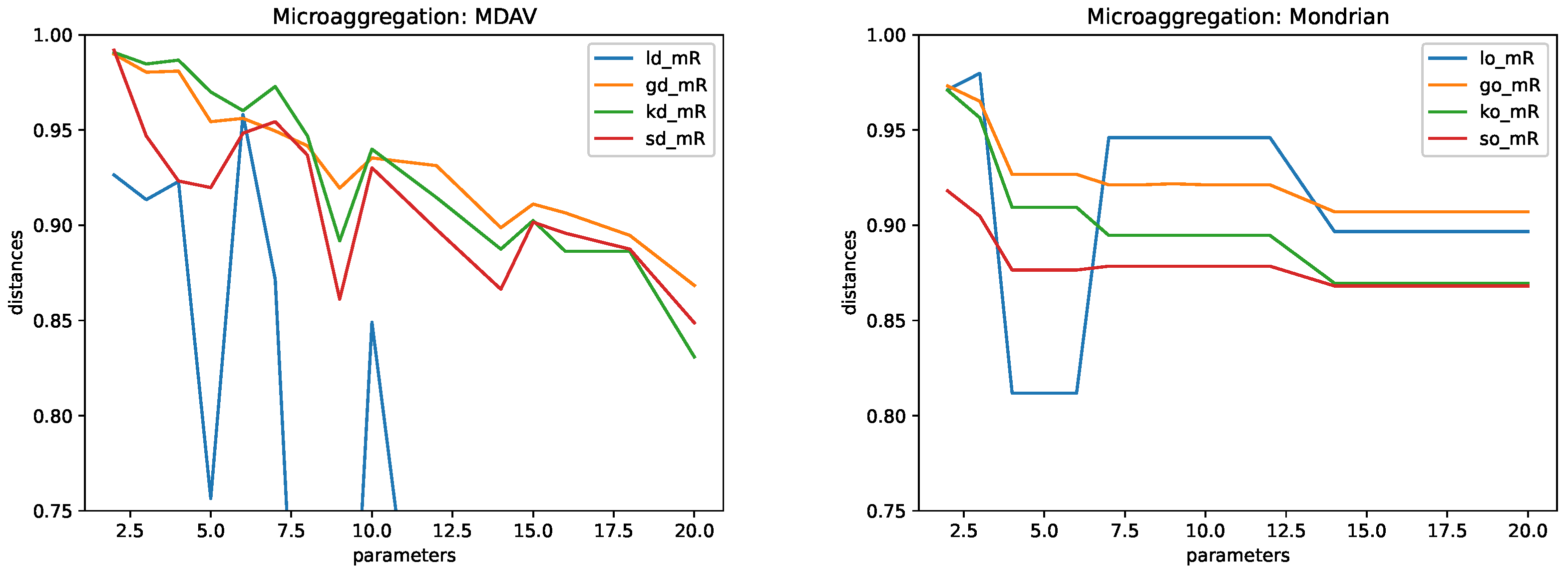
- Microaggregation.
- This method consists of building small clusters of the original data and then replacing each original record by the cluster center. Protection is achieved by means of controlling the minimum number of records in a cluster. This corresponds to the parameter k. The larger the k, the larger the protection and the larger the distortion. Microaggregation has been proven to provide a good trade-off between privacy and utility. We used two methods of microaggregation: MDAV [22,23] and Mondrian [24]. That is, two different ways of building the clusters.
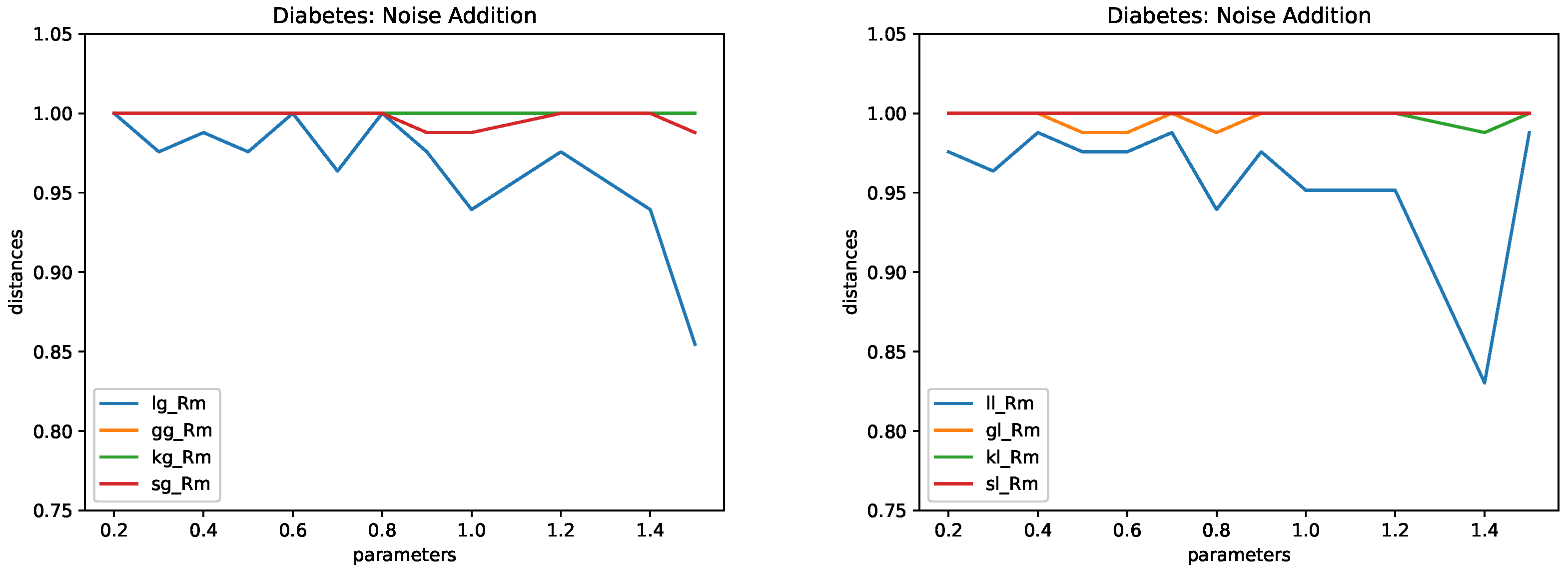
- Noise addition.
- This method replaces each numerical value x by , where follows a given distribution. We use two types of distributions: a normal distribution with mean zero and standard deviation and a Laplace distribution with mean zero and standard deviation as above. Here, k is the parameter. The larger the k, the larger the protection and the larger the distortion.
- SVD.
- We apply a singular value decomposition to the file, and then rebuild the matrix but only with some of the components. The number of components is a parameter of the system. We use k to denote this parameter. The smaller the number of components, the larger the distortion and larger the privacy.
- PCA.
- This is similar to the previous method using principal components. We use k to denote the number of components. Therefore, the smaller the k and the number of components, the larger the protection and distortion.
- NMF.
- This approach corresponds to non-negative matrix factorization [25]. The first use of NMF in data privacy seems to be by Wang et al. [26]. Our approach follows Algorithm 1, and it is based on the implementation of one of the authors [27]. Again, the smaller the number of components k, the larger the privacy. NMF needs the data to be positive, thus, data are scaled into [0,1] before the application of NMF.
| Algorithm 1: Algorithm for masking data using NMF. Here, X is the original file with N records and attributes. Protected files are produced. |
|
2.2. Shapley-Value-Based Explainability
3. Methodology
- Split the data set X in training and testing .
- Define as the machine learning model learned from the original data.
- For each , define its game according to the existing literature. Formally, for a set of features S, we define . Then, compute the Shapley value of this game. Use all records in to compute the mean Shapley value. We obtain a mean Shapley value for each masking method and parameter. That is, .
- Produce for each pair masking method and parameter .
- Produce the corresponding machine learning model .
- For each , compute the games and the corresponding Shapley values associated to models . We denote them by and for each . Use all records in to compute the mean Shapley value .
- The following comparisons are considered:
- -
- Compare the mean Shapley of the original and masked files using the Euclidean distance. That is, .
- -
- Compare the mean Shapley of the original and masked files using Spearman’s rank correlation.
- -
- Compare the Shapley values for each x using the Euclidean distance, and then compute the average distance. Formally, this corresponds to:
- -
- Compare the Shapley values for each x using Spearman’s rank coefficient.
4. Experiments and Analysis
4.1. Implementation
4.2. Parameters
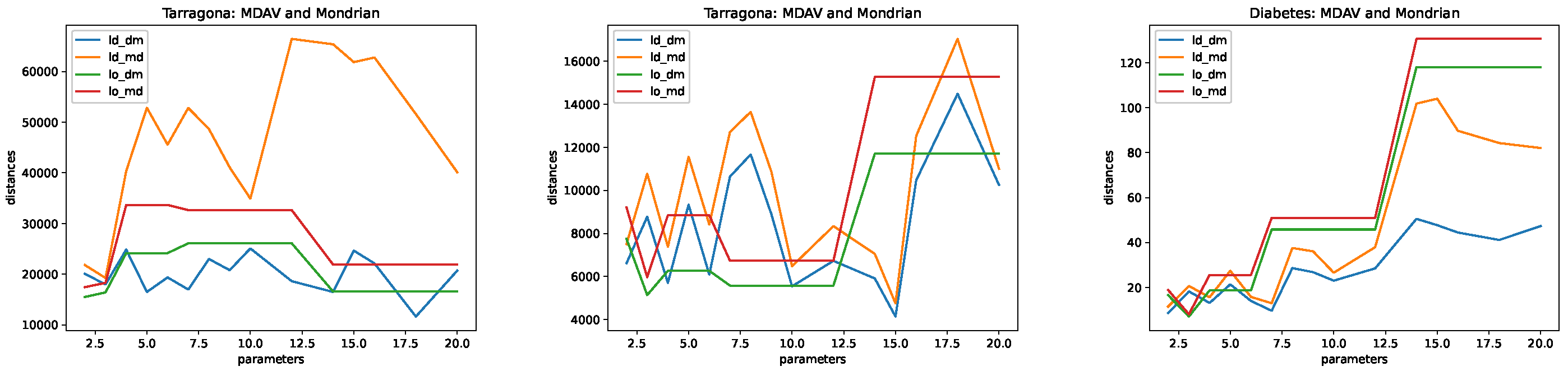
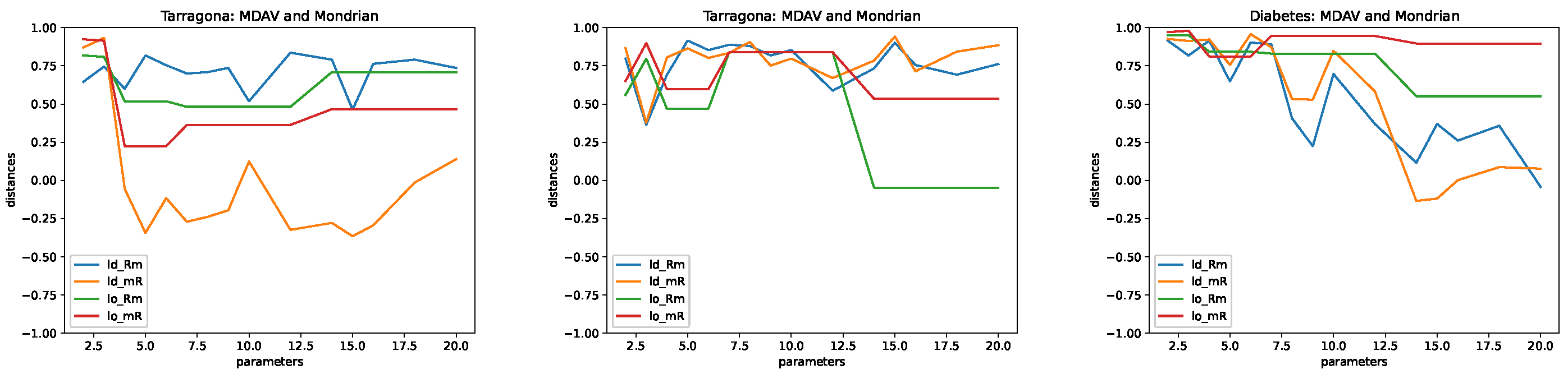
- Microaggregation. As explained above, we considered two different microaggregation algorithms: MDAV and Mondrian. The difference in the algorithms is in how clusters are built. For both algorithms, the cluster centers are defined in terms of the means of the associated records. The following values of the parameter k were used: .
- Noise addition. We considered Normal and Laplacian distribution. The following values of k were used: .
- SVD. We considered the singular value decomposition and the reconstruction of the matrix using different number of values. In our experiments, we considered .
- PCA. As in the case of SVD, we considered .
- NMF. The selection of the parameter that approximates well the matrix is a difficult problem [30]. We considered here a different number of components in the factorization. We used .
4.3. Data Sets and Machine Learning Algorithms
- Tarragona. This data set contains 834 records described in terms of 13 attributes. We used the first 12 attributes as the independent ones and the 13th attribute (last column in the file) as the dependent one.
- Diabetes. This data set contains 442 records with information on 10 attributes. An additional numerical attribute is also included in the data set, for prediction.
- Iris. This data set contains 150 records described in terms of 4 attributes and a class (which corresponds to a fifth attribute). We used the 4 attributes as the independent variables, used the class as a numerical value, and used one as a numerical dependent.
4.4. Machine Learning Algorithms
- linear_model.LinearRegression (linear regression);
- sklearn.linear_model.SGDRegressor (linear model implemented with stochastic gradient descent);
- sklearn.kernel_ridge.KernelRidge (linear least squares with l2-norm regularization, with the kernel trick);
- sklearn.svm.SVR (Epsilon-Support Vector Regression).
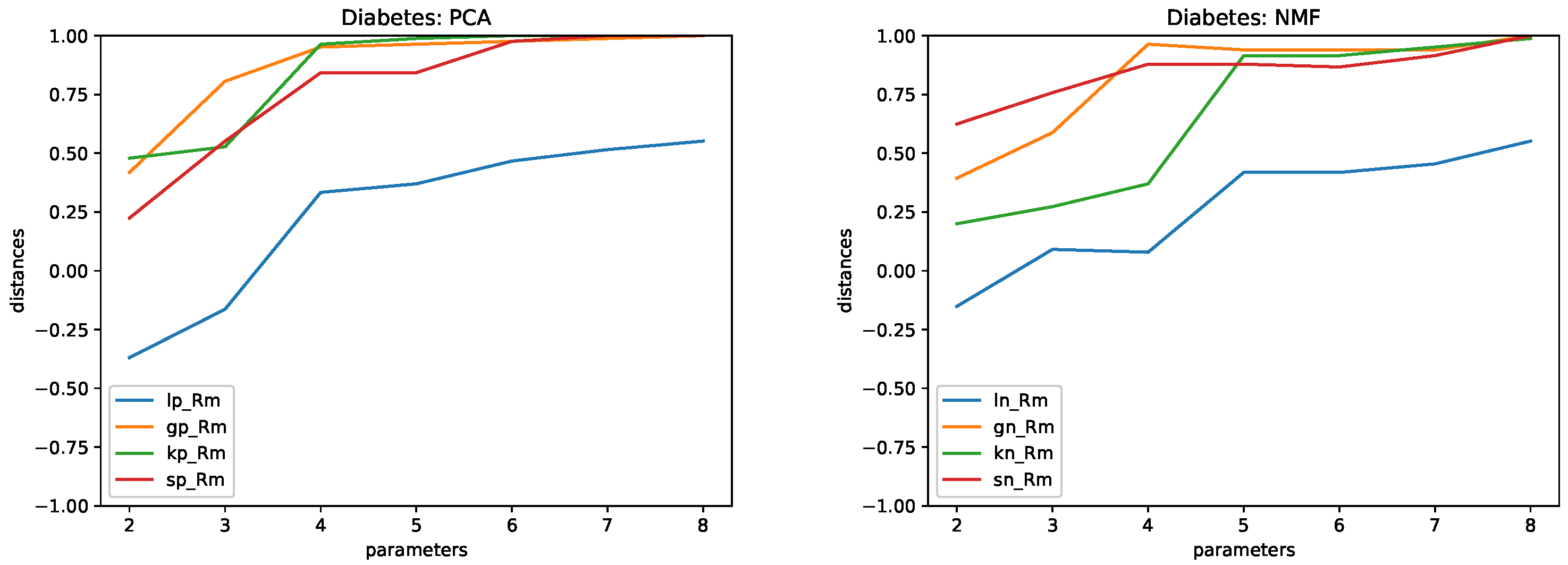
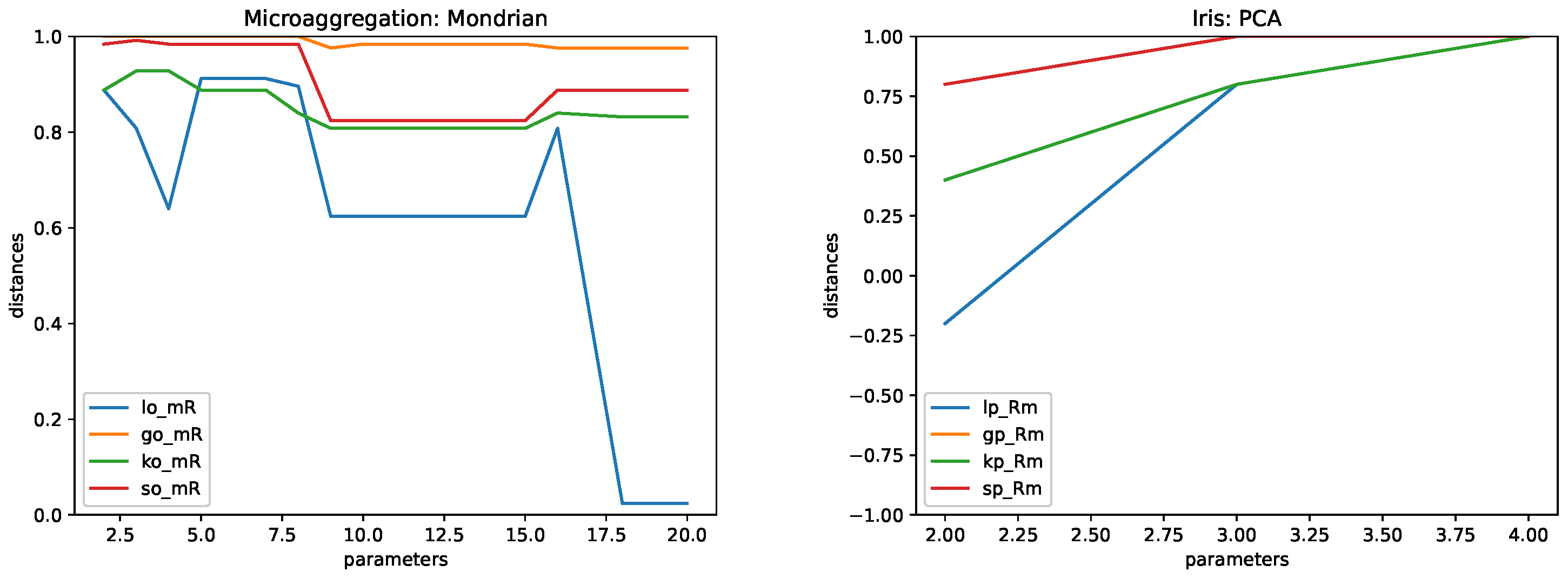
4.5. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hundepool, A.; Domingo-Ferrer, J.; Franconi, L.; Giessing, S.; Nordholt, E.S.; Spicer, K.; de Wolf, P.-P. Statistical Disclosure Control; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Torra, V. Data Privacy: Foundations, New Developments and the Big Data Challenge; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Abowd, J.; Ashmead, R.; Cumings-Menon, R.; Garfinkel, S.; Kifer, D.; Leclerc, P.; Sexton, W.; Simpson, A.; Task, C.; Zhuravlev, P. An Uncertainty Principle Is a Price of Privacy-Preserving Microdata. In Proceedings of the 35th Conference on Neural Information Processing Systems, Virtual, 6–14 December 2021. [Google Scholar]
- Pastore, A.; Gastpar, M.C. Locally differentially-private randomized response for discrete distribution learning. J. Mach. Learn. Res. 2021, 22, 1–56. [Google Scholar]
- Reimherr, M.; Awan, J. Elliptical Perturbations for Differential Privacy. In Proceedings of the NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Riveiro, M.; Thill, S. The challenges of providing explanations of AI systems when they do not behave like users expect. In Proceedings of the 30th ACM Conference on User Modeling, Adaptation and Personalization, Barcelona, Spain, 4–7 July 2022; pp. 110–120. [Google Scholar]
- Riveiro, M.; Thill, S. “That’s (not) the output I expected!” On the role of end user expectations in creating explanations of AI systems. Artif. Intell. 2021, 298, 103507. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the NeurIPS 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, O.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. Explainable AI for Trees: From Local Explanations to Global Understanding. arXiv 2019, arXiv:1905.04610. [Google Scholar] [CrossRef] [PubMed]
- Shapley, L. A value for n-person games. Ann. Math. Stud. 1953, 28, 307–317. [Google Scholar]
- Dubey, P. On the uniqueness of the Shapley value. Int. J. Game Theory 1975, 4, 131–140. [Google Scholar] [CrossRef]
- Roth, A.E. (Ed.) The Shapley Value; Cambridge University Press: Cambridge, MA, USA, 1988. [Google Scholar]
- Grant, T.D.; Wischik, D.J. Show Us the Data: Privacy, Explainability, and Why the Law Can’t Have Both. Geo. Wash. L. Rev. 2020, 88, 1350. [Google Scholar]
- Bozorgpanah, A.; Torra, V. Explainable machine learning models with privacy. 2021; manuscript. [Google Scholar]
- Torra, V. A Guide to Data Privacy; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Samarati, P. Protecting Respondents’ Identities in Microdata Release. IEEE Trans. Knowl. Data Eng. 2001, 13, 1010–1027. [Google Scholar] [CrossRef] [Green Version]
- Samarati, P.; Sweeney, L. Protecting Privacy When Disclosing Information: k-Anonymity and Its Enforcement through Generalization and Suppression; SRI International Technical Report, 1998. Available online: https://epic.org/wp-content/uploads/privacy/reidentification/Samarati_Sweeney_paper.pdf (accessed on 23 September 2022).
- Jaro, M.A. Advances in record-linkage methodology as applied to matching the 1985 Census of Tampa, Florida. J. Am. Stat. Assoc. 1989, 84, 414–420. [Google Scholar] [CrossRef]
- Winkler, W.E. Re-identification methods for masked microdata, PSD 2004. Lect. Notes Comput. Sci. 2004, 3050, 216–230. [Google Scholar]
- Evfimievski, A.; Gehrke, J.; Srikant, R. Limiting privacy breaches in privacy preserving data mining. In Proceedings of the Twenty-Second ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, San Diego, CA, USA, 9–12 June 2003. [Google Scholar]
- Kasiviswanathan, S.P.; Lee, H.K.; Nissim, K.; Raskhodnikova, S.; Smith, A. What can we learn privately? In Proceedings of the Annual Symposium on Foundations of Computer Science, Washington, DC, USA, 25–28 October 2008. [Google Scholar]
- Domingo-Ferrer, J.; Mateo-Sanz, J.M. Practical data-oriented microaggregation for statistical disclosure control. IEEE Trans. Knowl. Data Eng. 2002, 14, 189–201. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Domingo-Ferrer, J.; Martinez-Balleste, A.; Mateo-Sanz, J.M.; Sebe, F. Efficient Multivariate Data-Oriented Microaggregation. Int. J. Very Large Databases 2006, 15, 355–369. [Google Scholar] [CrossRef]
- LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Multidimensional k-Anonymity; Technical Report 1521; University of Wisconsin: Madison, WI, USA, 2005. [Google Scholar]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nat. Vol. 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhang, J. NNMF-based factorization techniques for high-accuracy privacy protection on non-negative-valued datasets. In Proceedings of the Sixth IEEE International Conference on Data Mining—Workshops (ICDMW’06), Hong Kong, China, 18–22 December 2006. [Google Scholar]
- Aliahmadipour, L.; Valipour, E. A new method for preserving data privacy based on the non-negative matrix factorization clustering. Fuzzy Syst. Its Appl. 2022. (In Persian) [Google Scholar] [CrossRef]
- Myerson, R.B. Game Theory; Harvard University Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Code Python of Our Software. Available online: www.mdai.cat/code (accessed on 23 September 2022).
- Berry, M.W.; Browne, M.; Langville, A.M.; Pauca, V.P.; Plemmons, R.J. Algorithms and applications for approximate nonnegative matrix factorization. Comput. Stat. Data Anal. 2007, 52, 155–173. [Google Scholar] [CrossRef]
- Brand, R.; Domingo-Ferrer, J.; Mateo-Sanz, J.M. Reference Datasets to Test and Compare SDC Methods for Protection of Numerical Microdata; Technical Report; European Project IST-2000-25069 CASC, 2002; Available online: https://research.cbs.nl/casc/CASCrefmicrodata.pdf (accessed on 23 September 2022).
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2019; Available online: http://archive.ics.uci.edu/ml (accessed on 23 September 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Explanation |
|---|---|
| X | Data file |
| Test data set | |
| Training data set | |
| Masking method with parameter p | |
| A | Machine learning algorithm |
| Machine learning model from original data | |
| Machine learning model from masked data using | |
| Machine learning model that uses as input only attributes in S | |
| Shapley value of a machine learning model for an instance/record x | |
| Mean Shapley value of a machine learning model for all instances/records x in X |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bozorgpanah, A.; Torra, V.; Aliahmadipour, L. Privacy and Explainability: The Effects of Data Protection on Shapley Values. Technologies 2022, 10, 125. https://doi.org/10.3390/technologies10060125
Bozorgpanah A, Torra V, Aliahmadipour L. Privacy and Explainability: The Effects of Data Protection on Shapley Values. Technologies. 2022; 10(6):125. https://doi.org/10.3390/technologies10060125
Chicago/Turabian StyleBozorgpanah, Aso, Vicenç Torra, and Laya Aliahmadipour. 2022. "Privacy and Explainability: The Effects of Data Protection on Shapley Values" Technologies 10, no. 6: 125. https://doi.org/10.3390/technologies10060125