
Distributional and Acoustic Characteristics of Filler Particles in German with Consideration of Forensic-Phonetic Aspects

Abstract
:1. Introduction
1.1. Frequency Distribution
1.2. Duration of Filler Particles
1.3. Vowel Quality
1.4. Voice Quality
1.5. Hypotheses
1.6. Importance for Forensic Phonetics
1.7. Outline of the Paper
2. Filler Particle Phenomena
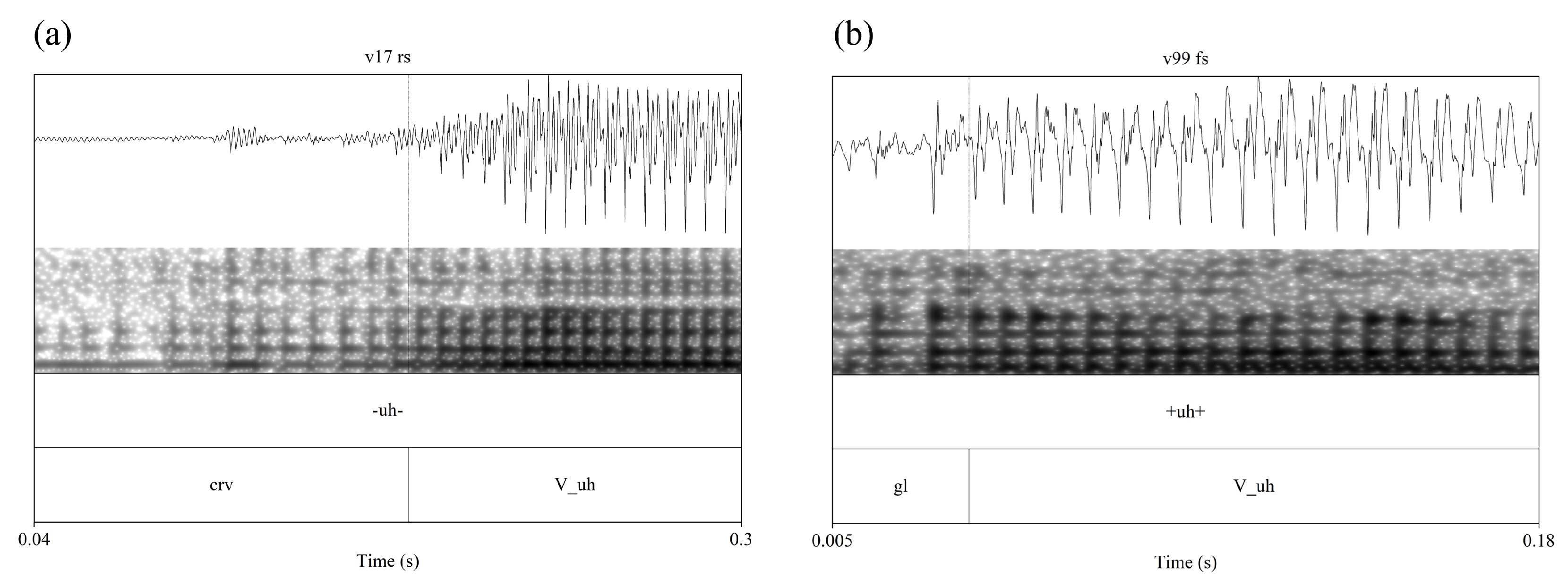
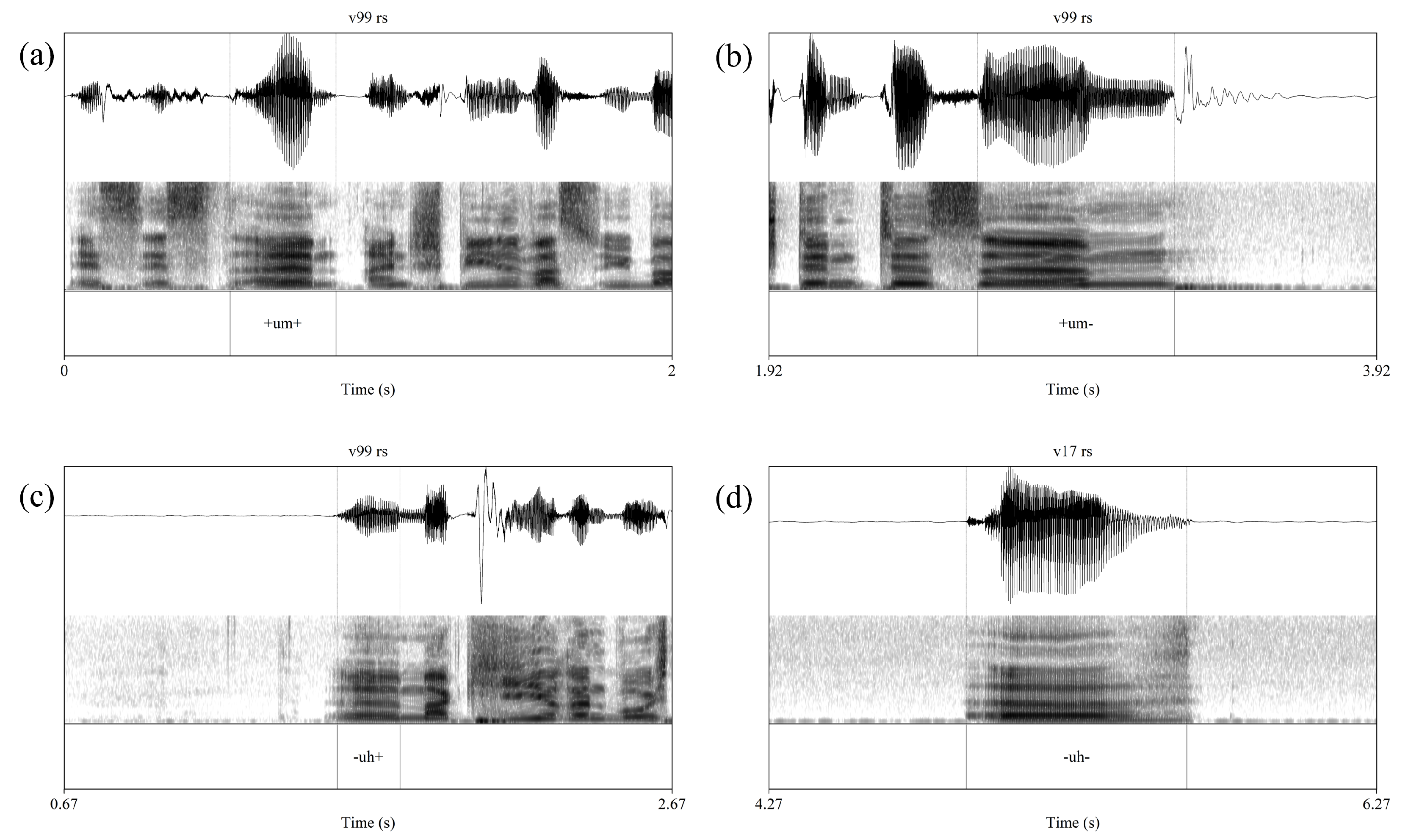
2.1. Typical Filler Particles (uh and um)
2.2. Nasal FP hm
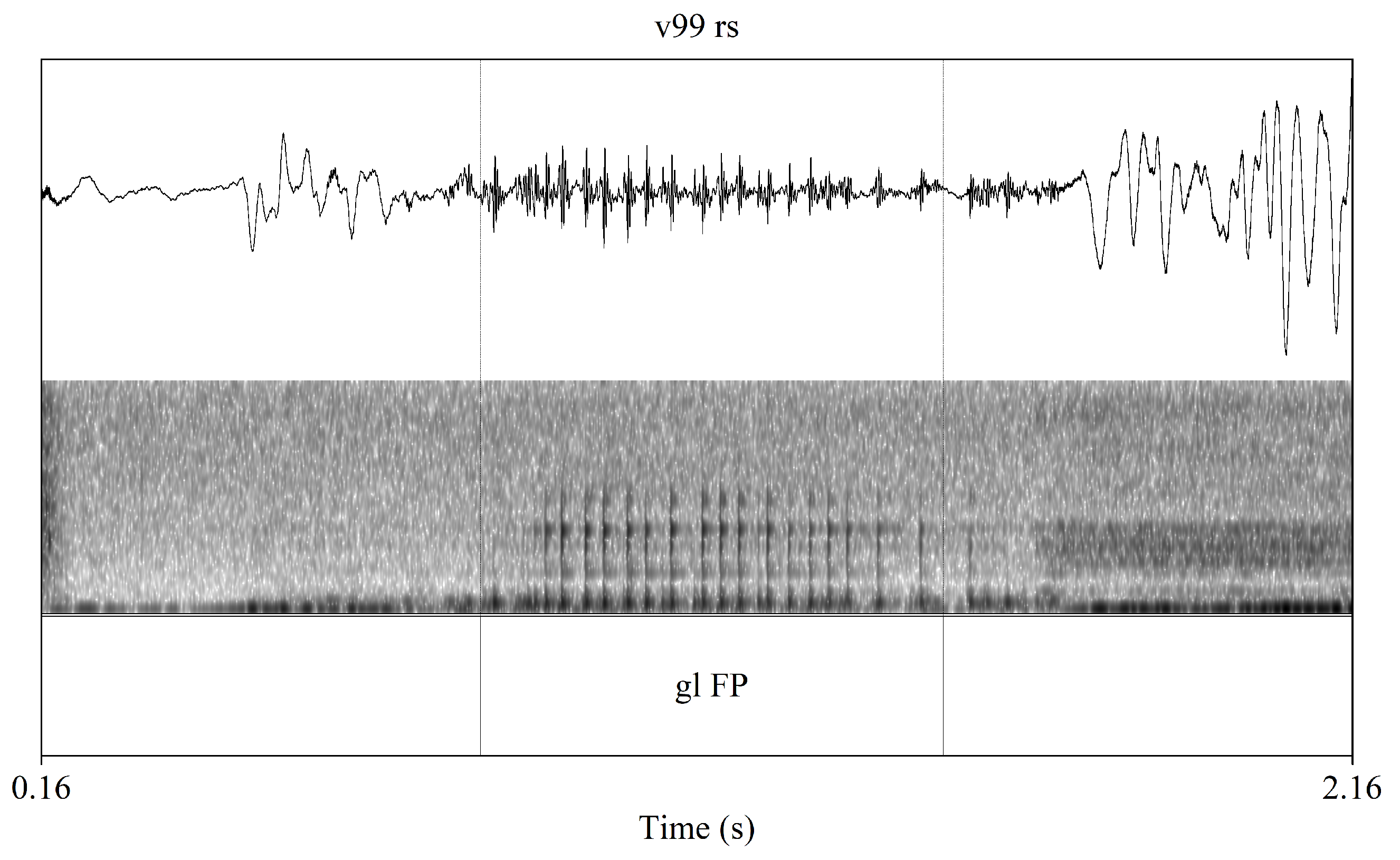
2.3. Glottal Filler Particle
2.4. Tongue Clicks
3. Materials
3.1. Corpus
3.2. Annotations
3.3. Speaking Tempo
3.4. Statistical Methods
4. General Results
4.1. Frequency Distribution
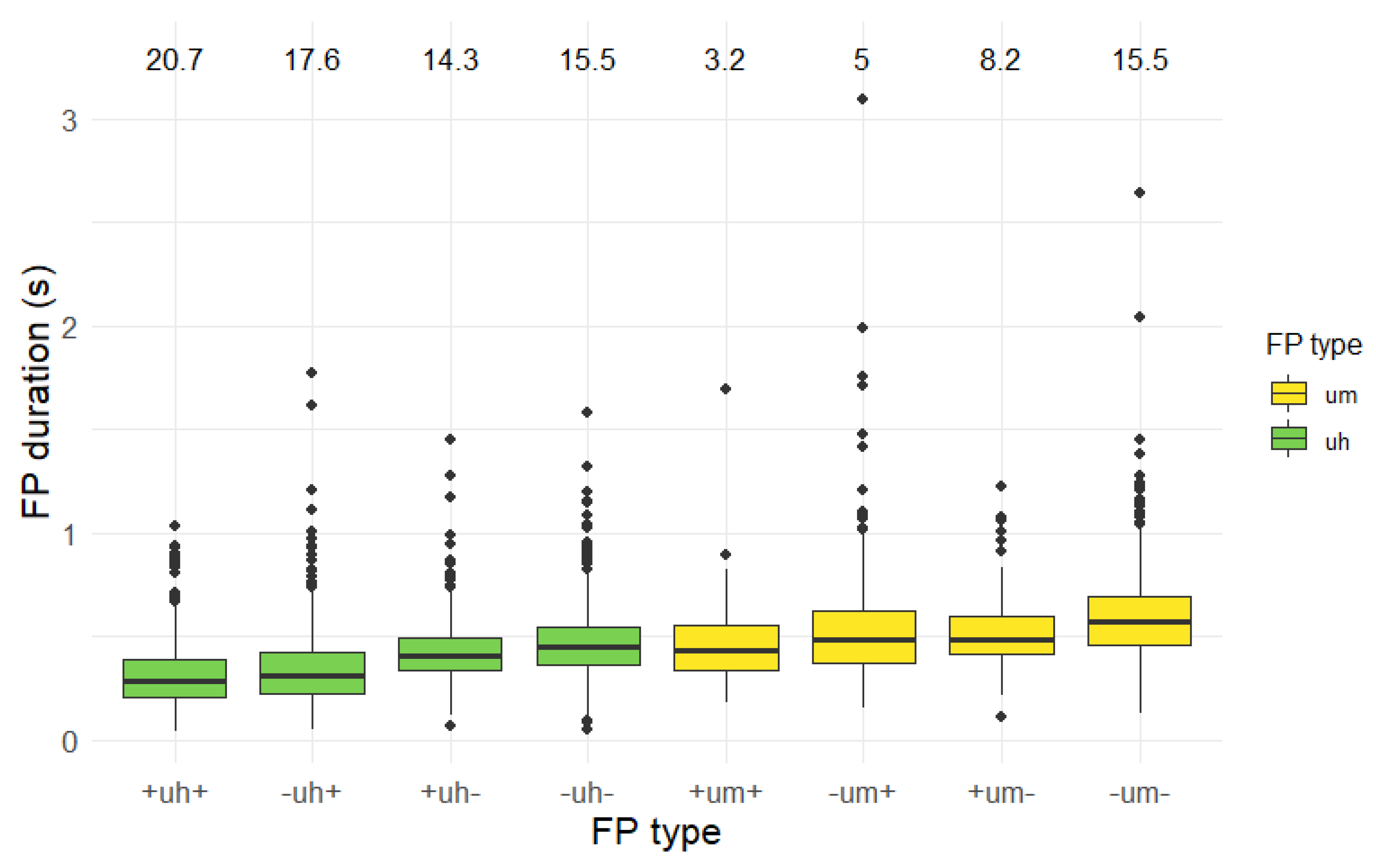
4.2. Duration
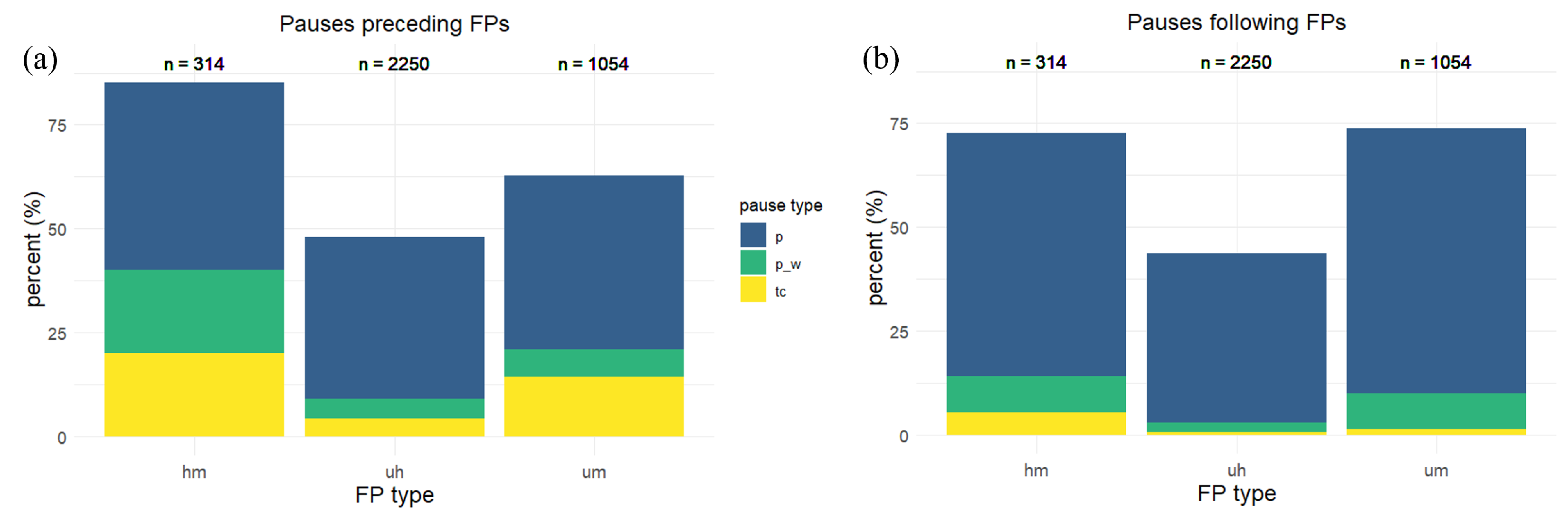
4.3. Pause Context
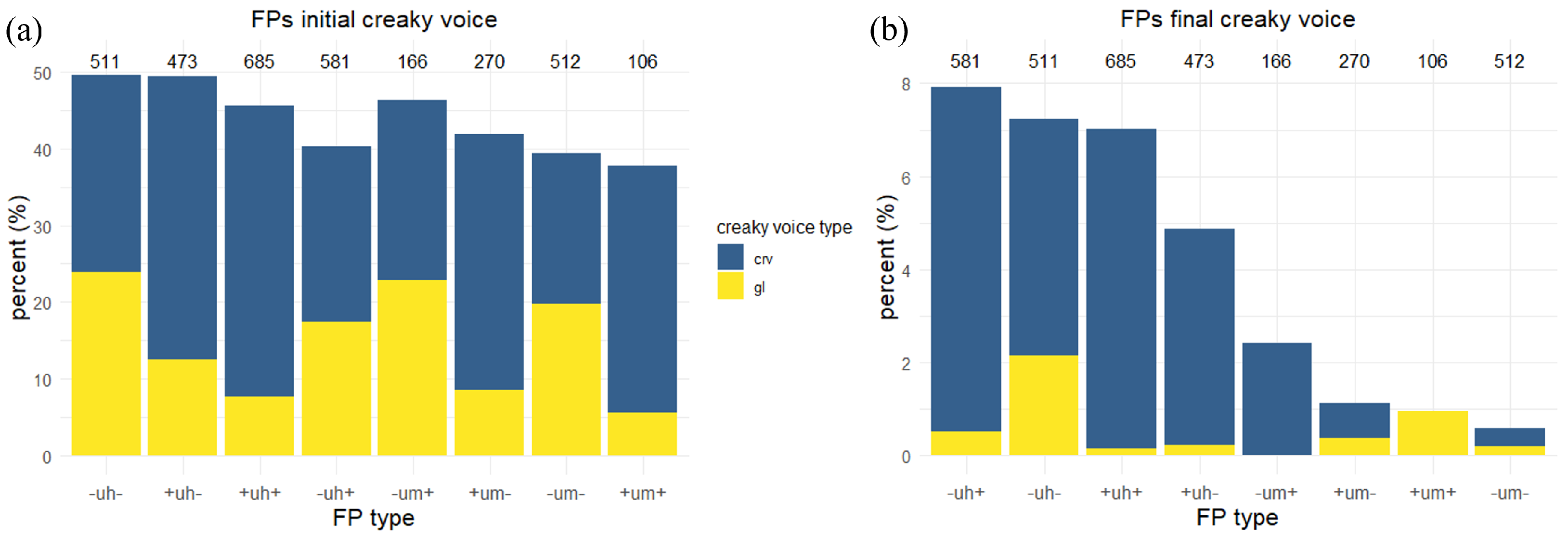
4.4. Voice Quality
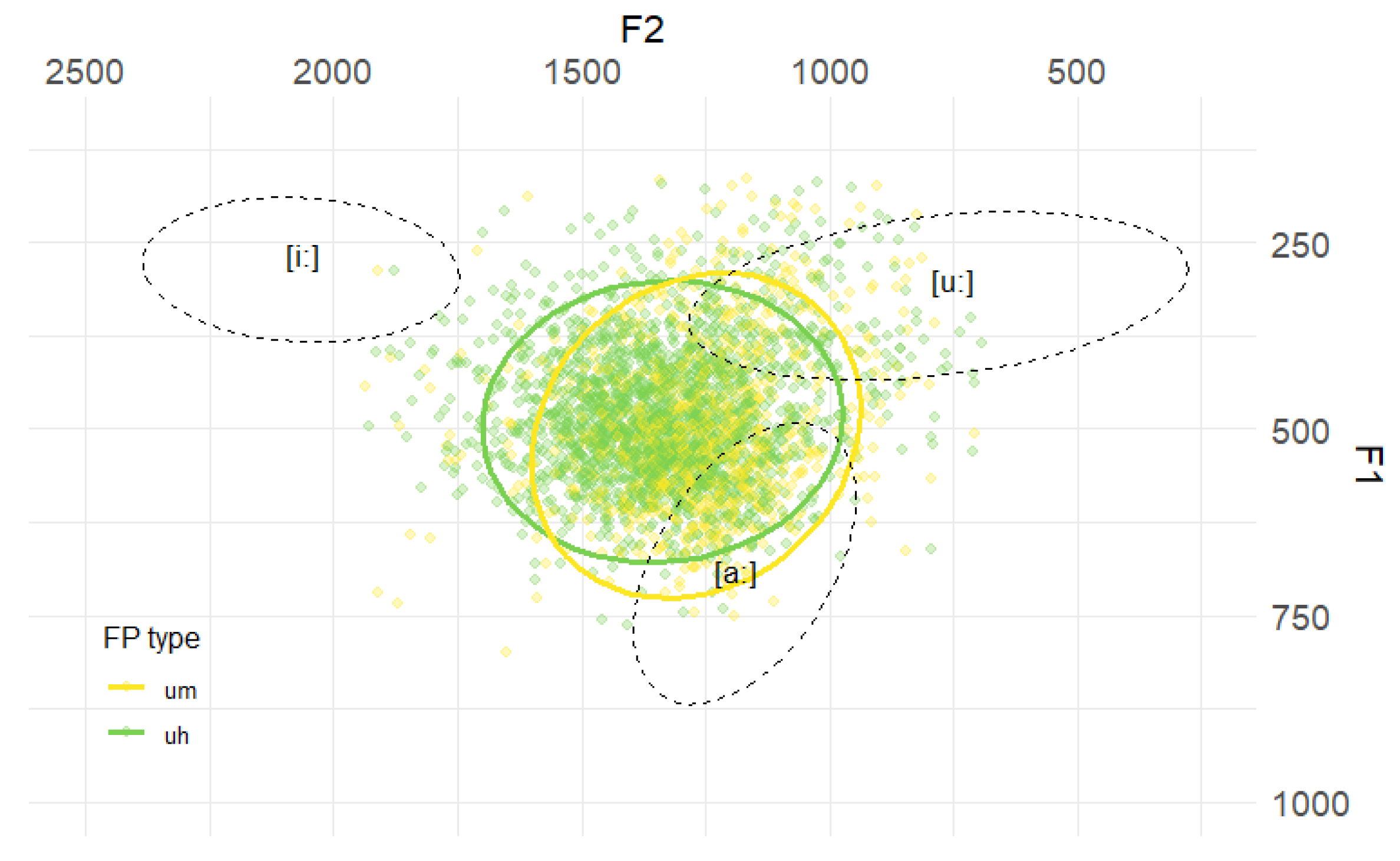
4.5. Vowel Quality
4.6. Discussion
5. Normal vs. Lombard Speech Condition
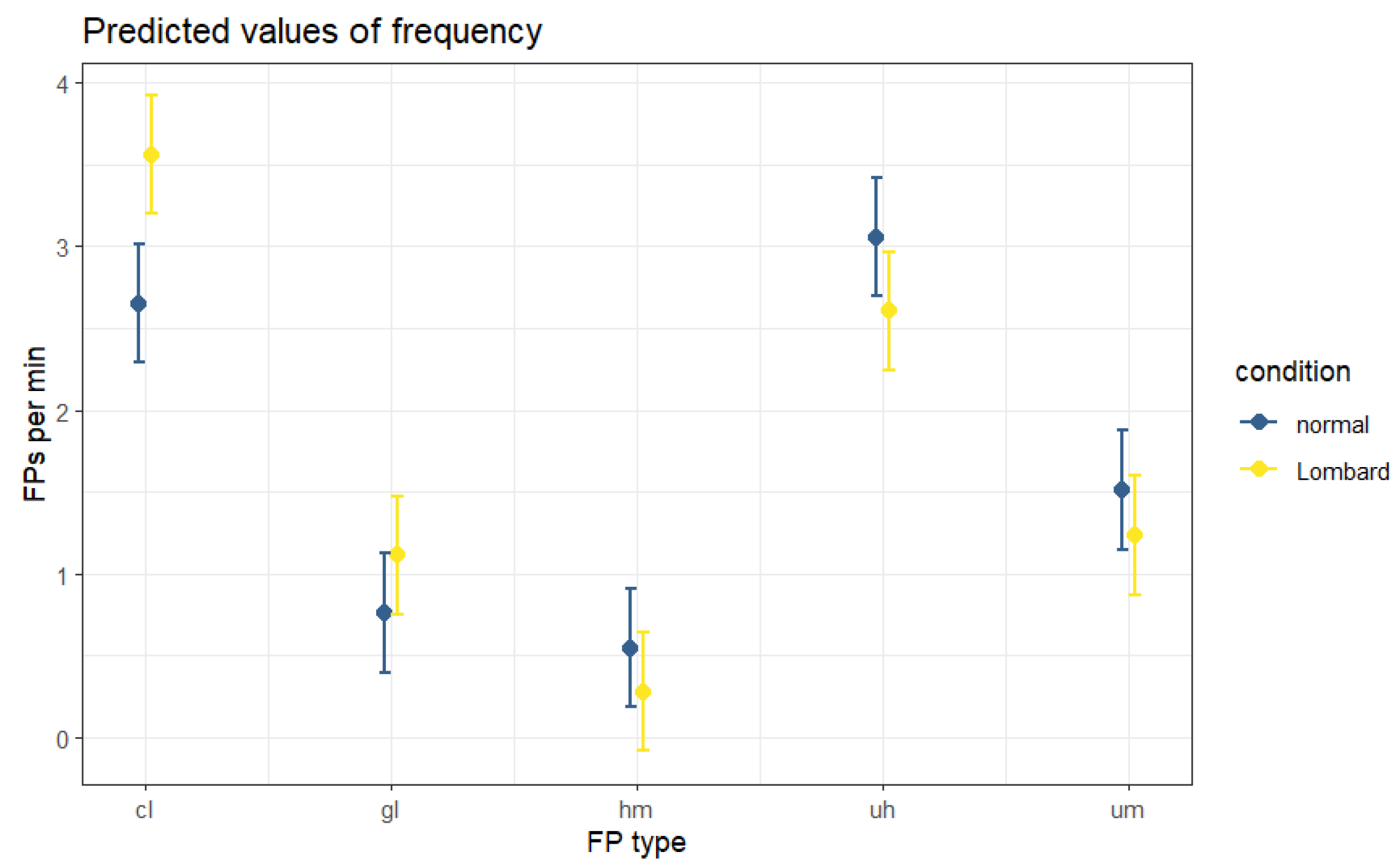
5.1. Frequency Distribution
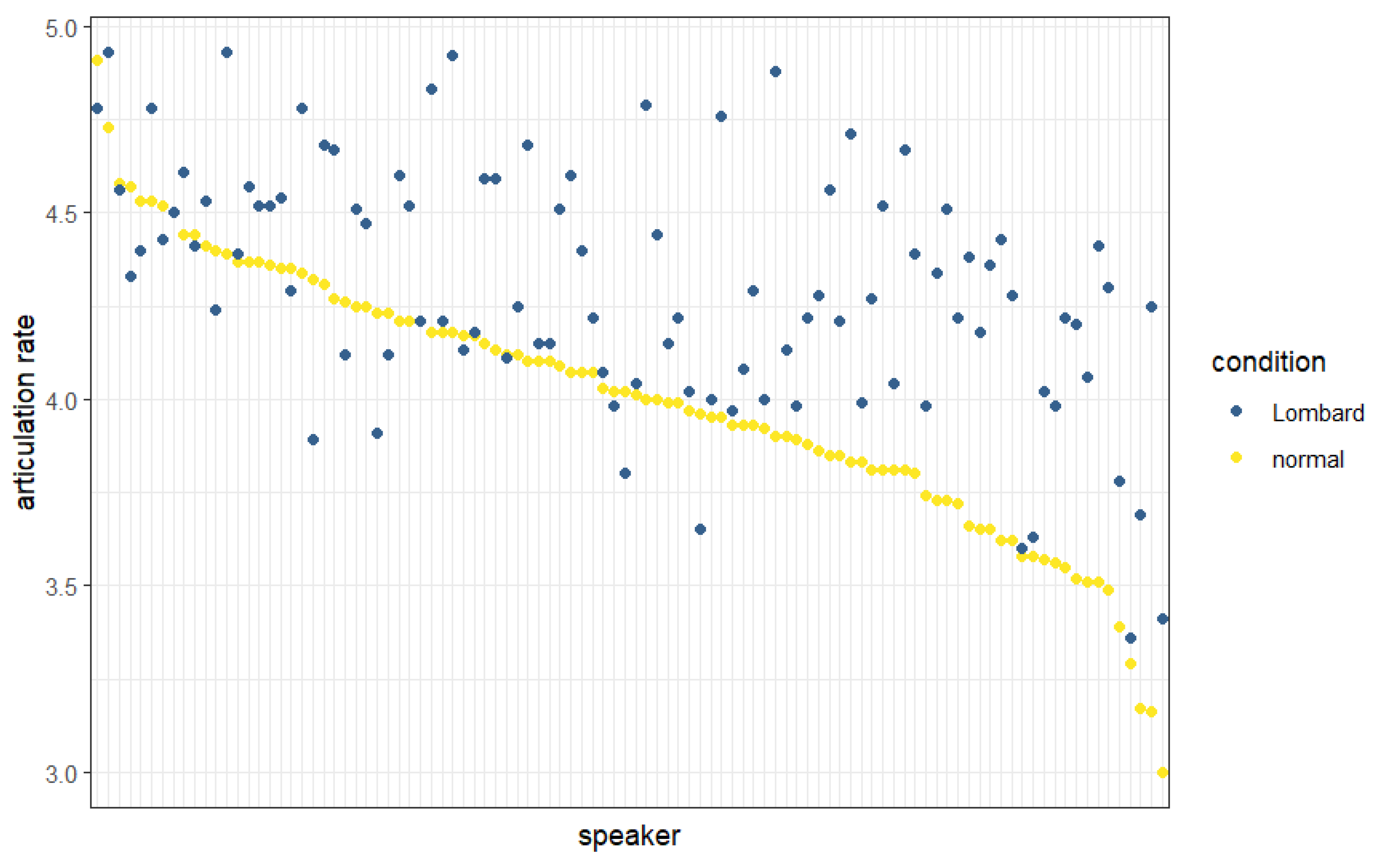
5.2. Duration
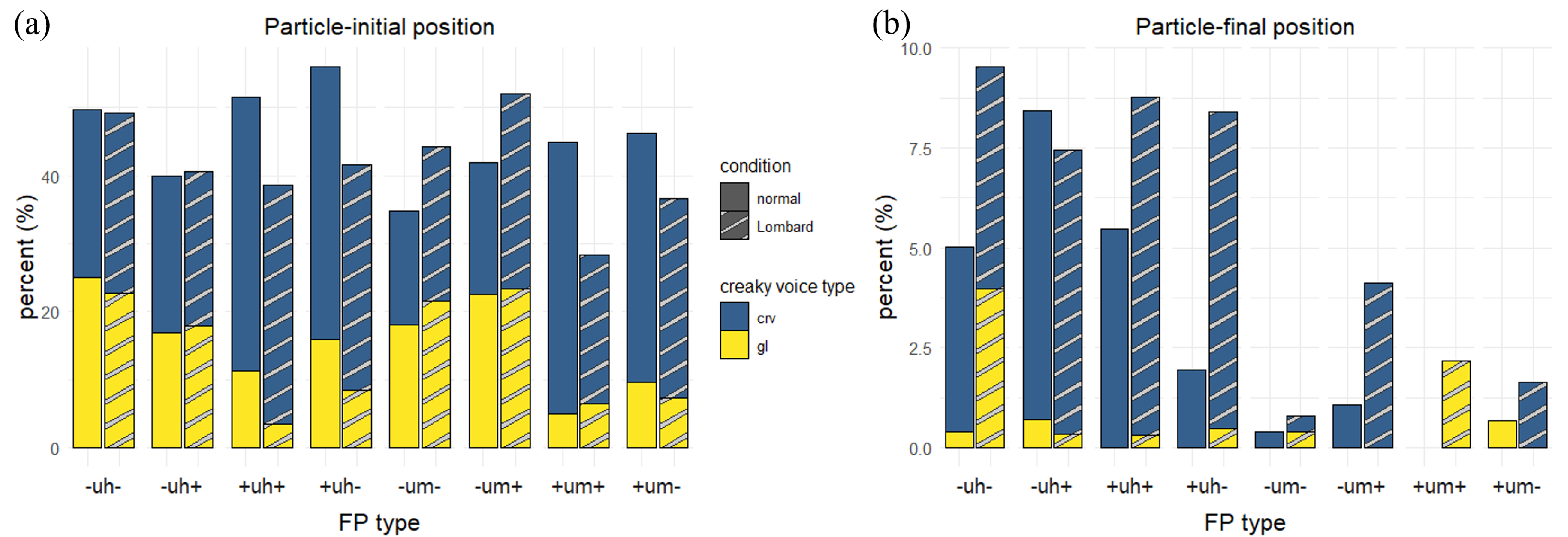
5.3. Pause Context
5.4. Voice Quality
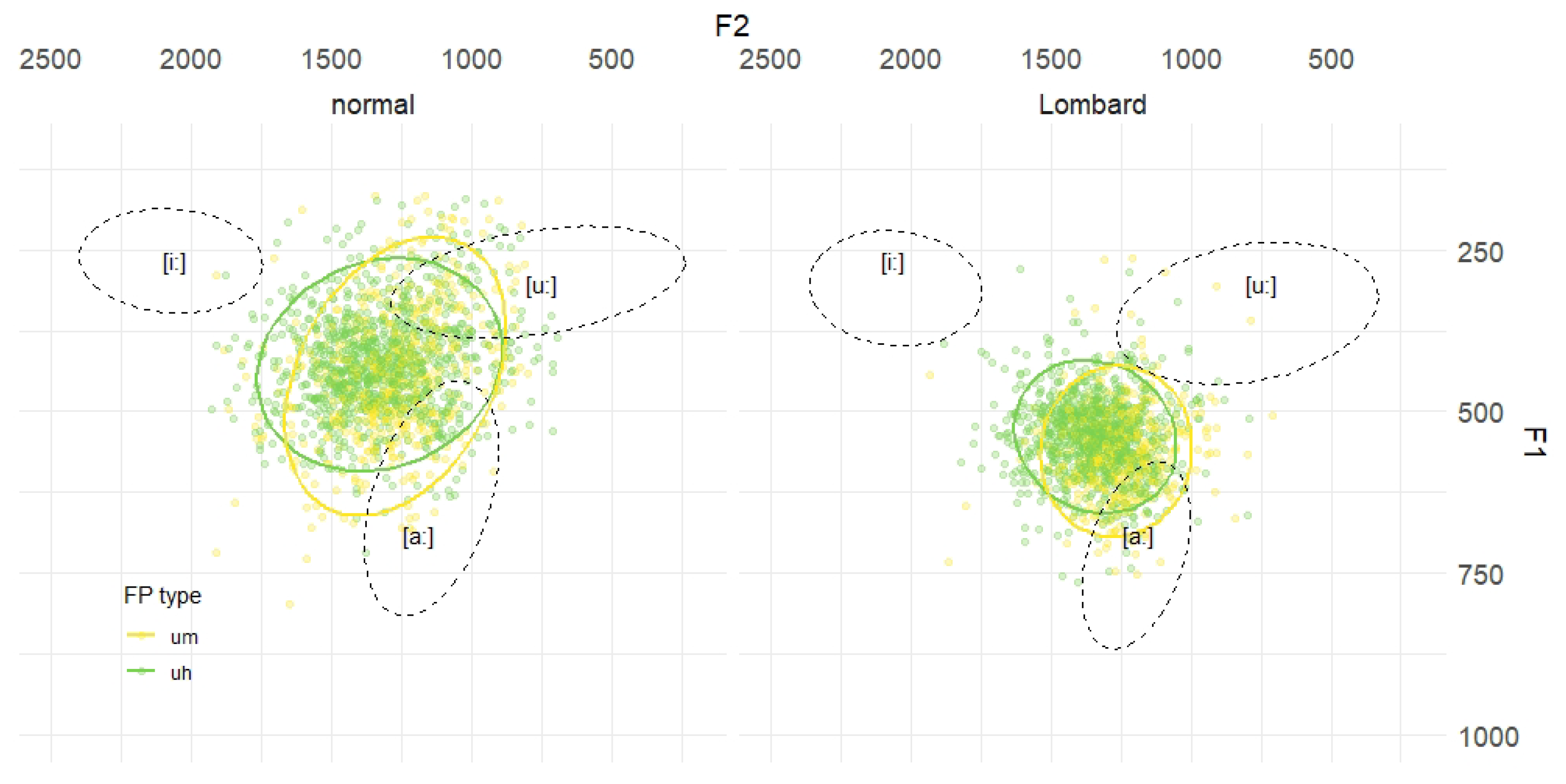
5.5. Vowel Quality
5.6. Discussion
6. Speaker Specificity
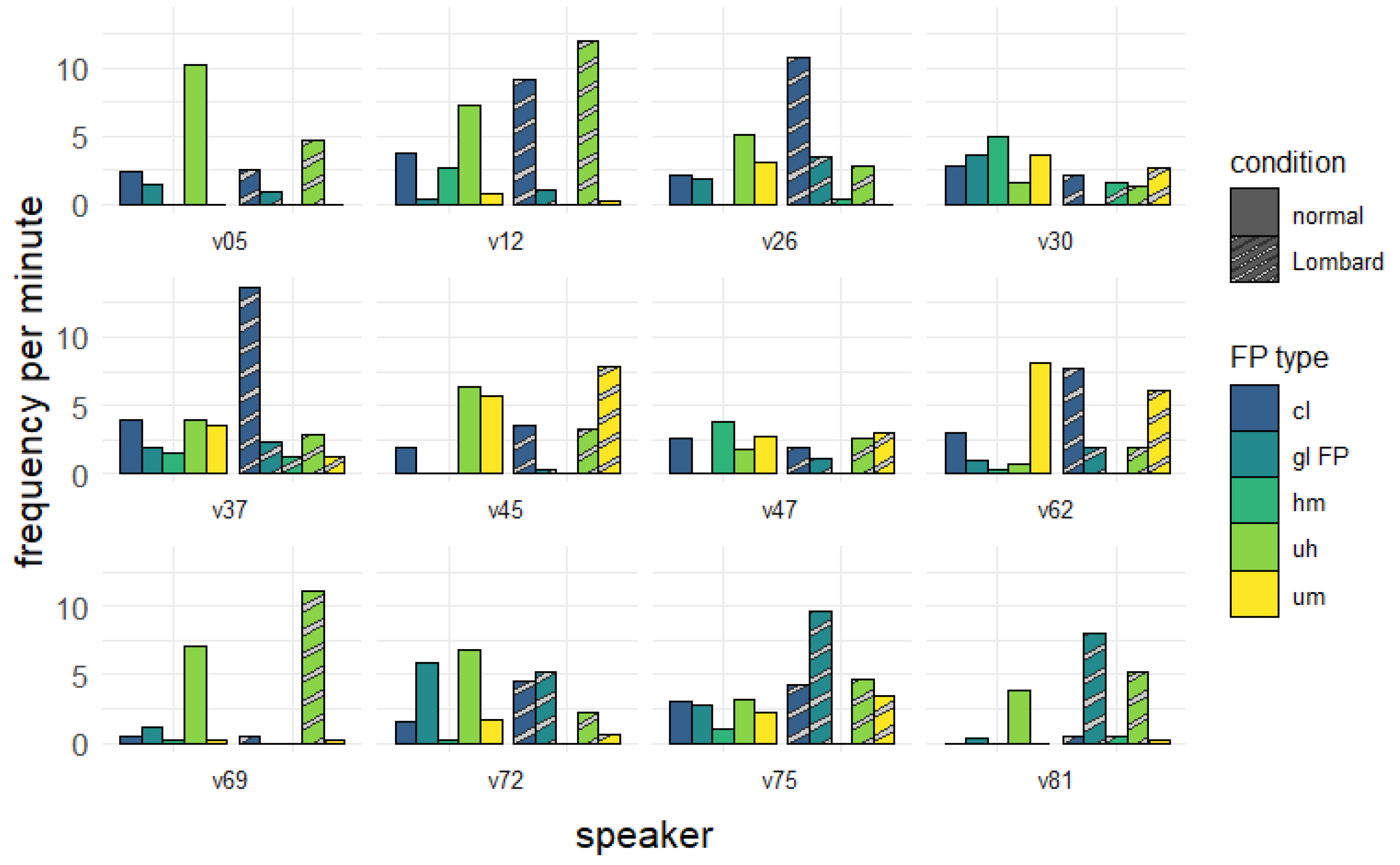
6.1. Frequency Distribution
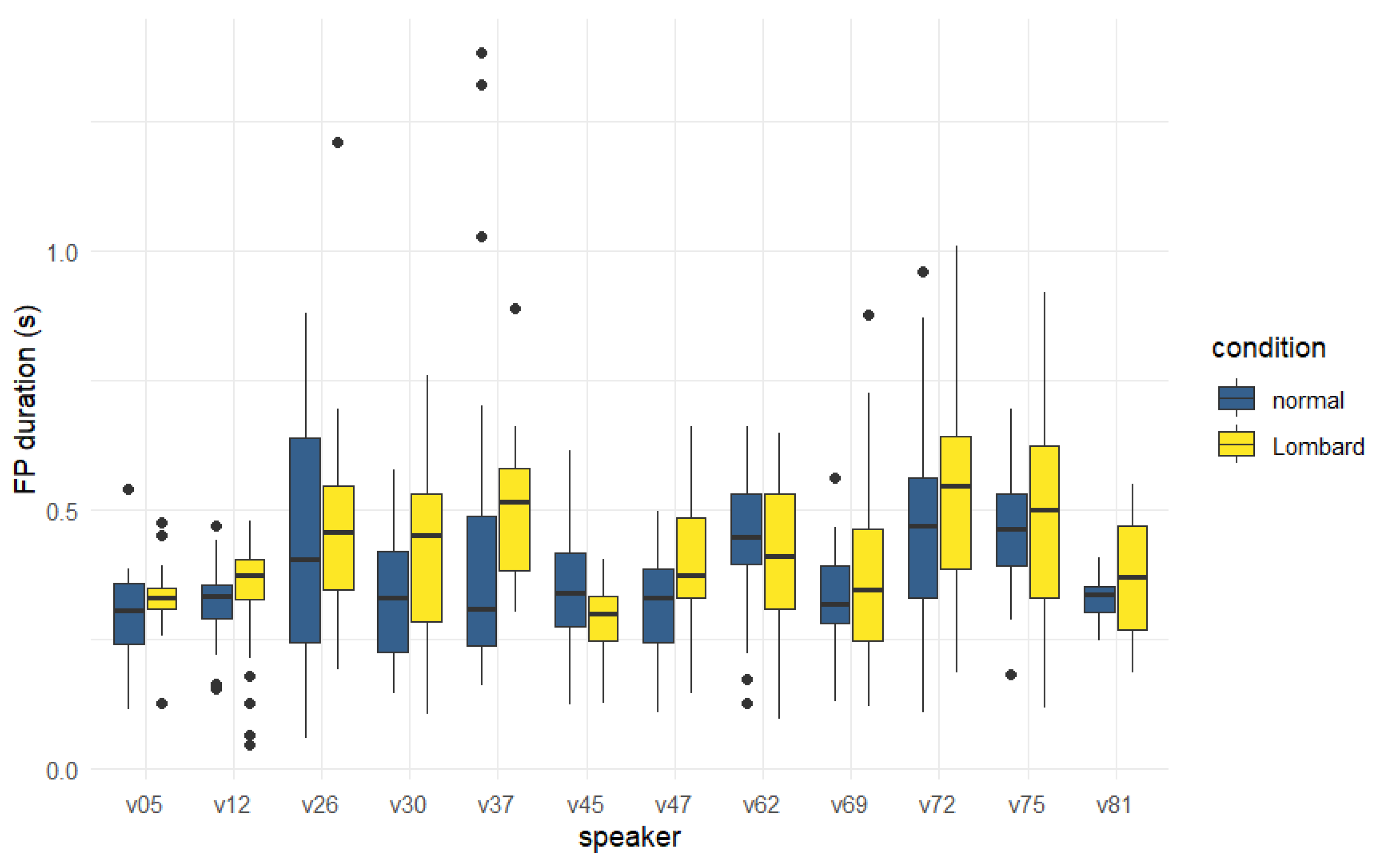
6.2. Duration
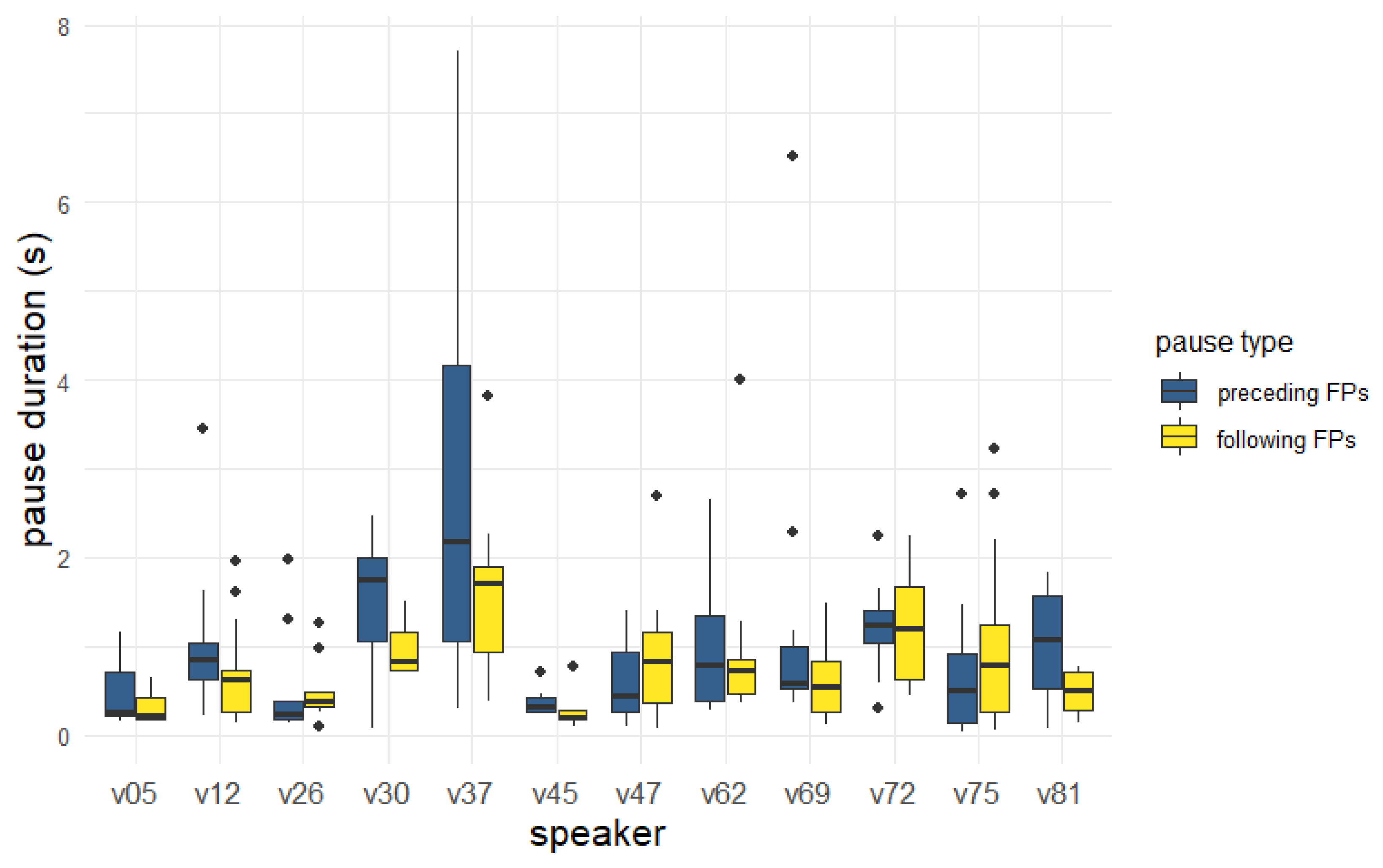
6.3. Pause Context
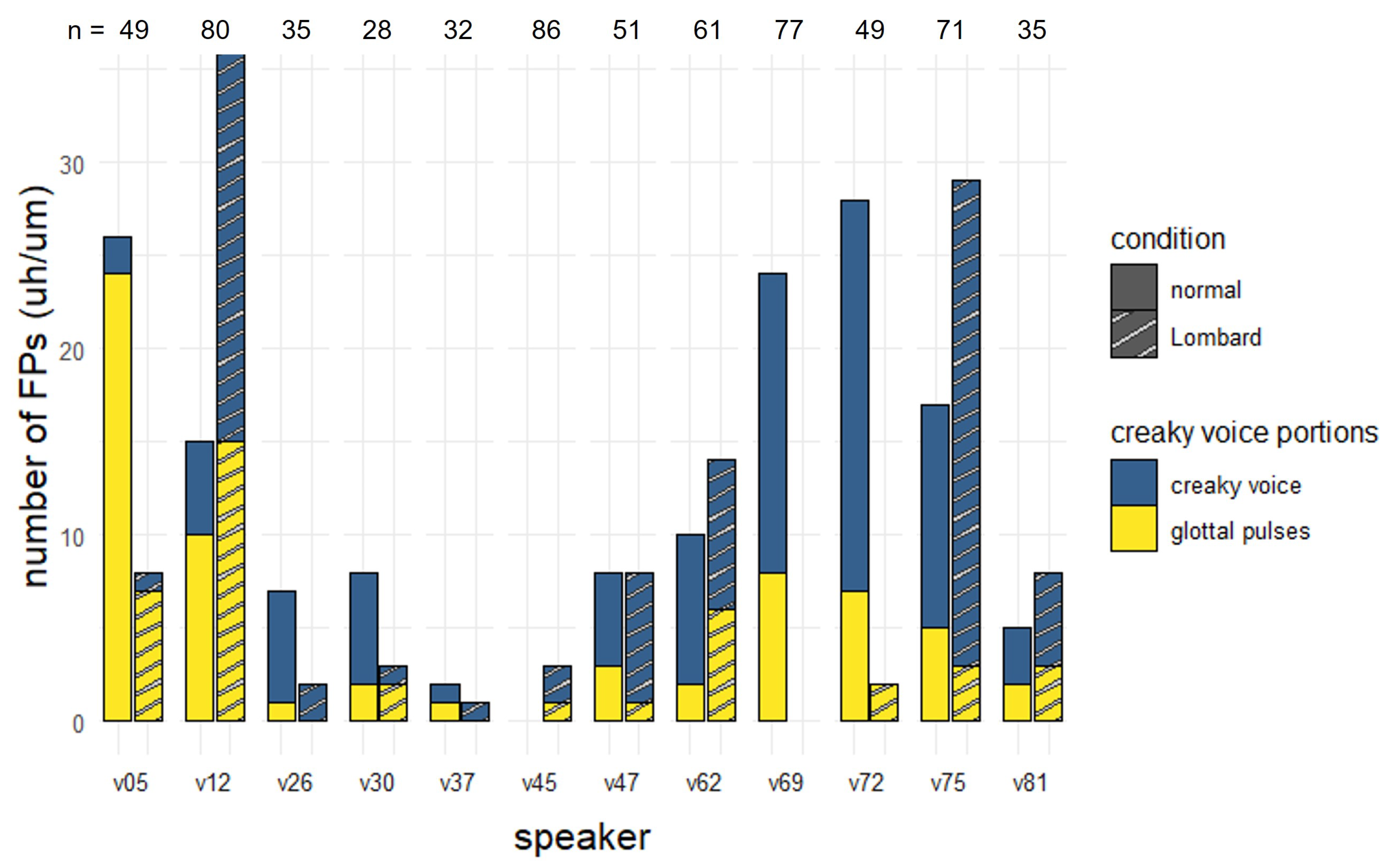
6.4. Voice Quality
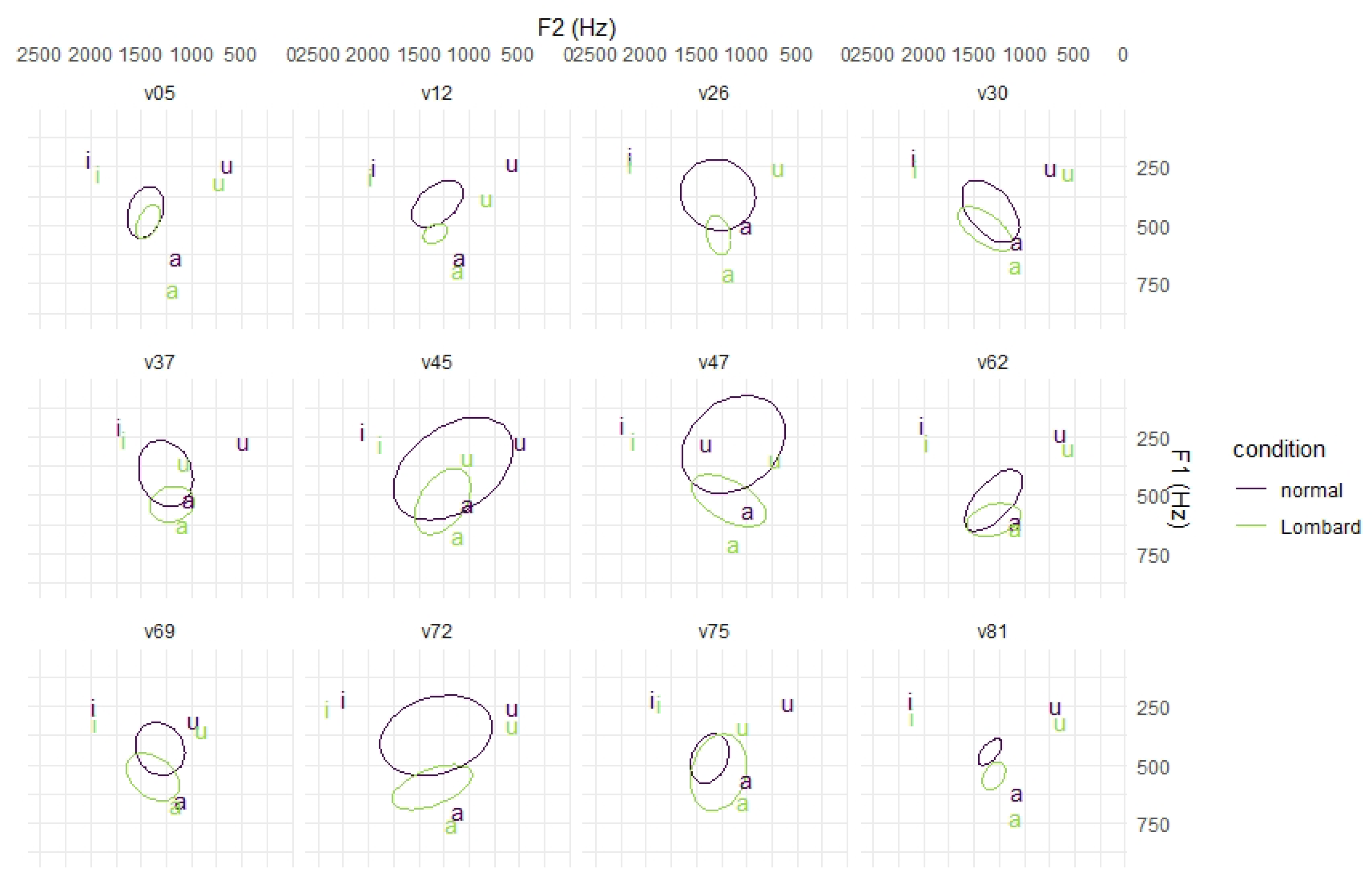
6.5. Vowel Quality
6.6. Discussion
7. General Discussion
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Linear Models Output

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Estimate | Std. Error | t-Value | Pr (<|t|) | |
|---|---|---|---|---|
| (Intercept) | 1.083 | 0.036 | 30.32 | <0.001 *** |
| typepre | 0.094 | 0.053 | 1.77 | 0.08 |
| pausetypep_w | 1.202 | 0.121 | 9.96 | <0.001 *** |
| pausetypetc | 2.477 | 0.227 | 10.92 | <0.001 *** |
| typepre:pausetypep_w | 0.803 | 0.16 | 5.02 | <0.001 *** |
| typepre:pausetypetc | 0.308 | 0.246 | 1.26 | 0.21 |
| Estimate | Std. Error | df | t-Value | Pr (<|t|) | |
|---|---|---|---|---|---|
| (Intercept) | 3.31 | 0.87 | 280.07 | 3.81 | <0.001 *** |
| fp_typegl | −1.89 | 0.24 | 890.83 | −7.81 | <0.001 *** |
| fp_typehm | −2.1 | 0.24 | 890.83 | −8.7 | <0.001 *** |
| fp_typeuh | 0.41 | 0.24 | 890.83 | 1.67 | 0.09 |
| fp_typeum | −1.14 | 0.24 | 890.83 | −4.71 | <0.001 *** |
| conditionLombard | 0.91 | 0.25 | 947.46 | 3.65 | <0.001 *** |
| articulationrate | −0.16 | 0.21 | 266.15 | −0.75 | 0.45 |
| fp_typegl:conditionLombard | −0.56 | 0.34 | 890.83 | −1.63 | 0.1 |
| fp_typehm:conditionLombard | −1.18 | 0.34 | 890.83 | −3.45 | <0.001 *** |
| fp_typeuh:conditionLombard | −1.36 | 0.34 | 890.83 | −3.98 | <0.001 *** |
| fp_typeum:conditionLombard | −1.19 | 0.34 | 890.83 | −3.47 | <0.001 *** |
| Estimate | Std. Error | df | t-Value | Pr (<|t|) | |
|---|---|---|---|---|---|
| (Intercept) | 0.502 | 0.065 | 724.9 | 7.7 | <0.001 *** |
| conditionLombard | 0.048 | 0.009 | 3027 | 5.55 | <0.001 *** |
| fp_typeum | 0.162 | 0.01 | 3289 | 16.11 | <0.001 *** |
| articulationrate | −0.017 | 0.016 | 772 | −1.04 | 0.3 |
| prepause+ | −0.037 | 0.007 | 3296 | −5.63 | <0.001 *** |
| postpause+ | −0.109 | 0.007 | 3280 | −16.26 | <0.001 *** |
| conditionLombard:fp_typeum | −0.023 | 0.013 | 3261 | −1.73 | 0.08 |
| Estimate | Std. Error | t-Value | Pr (<|t|) | |
|---|---|---|---|---|
| (Intercept) | 0.985 | 0.048 | 20.53 | <0.001 *** |
| typepre | 0.045 | 0.072 | 0.62 | 0.54 |
| pausetypep_w | 1.204 | 0.165 | 7.31 | <0.001 *** |
| pausetypetc | 2.206 | 0.284 | 7.78 | <0.001 *** |
| conditionLombard | 0.211 | 0.07 | 2.99 | <0.01 ** |
| typepre:pausetypep_w | 0.408 | 0.213 | 1.92 | 0.06 |
| typepre:pausetypetc | 0.152 | 0.31 | 0.49 | 0.62 |
| typepre:conditionLombard | 0.09 | 0.105 | 0.85 | 0.39 |
| pausetypep_w:conditionLombard | −0.012 | 0.238 | −0.05 | 0.96 |
| pausetypetc:conditionLombard | 0.765 | 0.46 | 1.66 | 0.1 |
| typepre:pausetypep_w:conditionLombard | 1.048 | 0.317 | 3.31 | <0.001 *** |
| typepre:pausetypetc:conditionLombard | 0.253 | 0.496 | 0.51 | 0.61 |
| Estimate | Std. Error | df | t-Value | Pr (<|t|) | |
|---|---|---|---|---|---|
| (Intercept) | 312 | 34 | 1115.03 | 9.27 | <0.001 *** |
| conditionLombard | 97 | 4 | 2978.47 | 22.32 | <0.001 *** |
| fp_typeum | 0.6 | 5 | 3061.22 | 0.12 | 0.9 |
| articulationrate | 30 | 8 | 1181.06 | 3.61 | <0.001 *** |
| fp_dur | 10 | 9 | 3054.38 | 1.18 | 0.24 |
| prepause+ | −10 | 3 | 3046.97 | −3.08 | <0.01 ** |
| postpause+ | −0.5 | 3 | 3031.99 | −0.14 | 0.89 |
| conditionLombard:fp_typeum | 12 | 7 | 3010.67 | 1.85 | 0.06 |
| Estimate | Std. Error | df | t-Value | Pr (<|t|) | |
|---|---|---|---|---|---|
| (Intercept) | 1307 | 74 | 1383.6 | 17.63 | <0.001 *** |
| conditionLombard | 15 | 9 | 3020.62 | 1.61 | 0.11 |
| fp_typeum | 10 | 11 | 3056.78 | 0.93 | 0.35 |
| articulationrate | 10 | 18 | 1506.81 | 0.55 | 0.59 |
| fp_dur | −107 | 19 | 3047.17 | −5.63 | <0.001 *** |
| prepause+ | −4 | 7 | 3039.32 | −0.54 | 0.59 |
| postpause+ | 29 | 7 | 3025.15 | 3.99 | <0.001 *** |
| conditionLombard:fp_typeum | −34 | 14 | 3007.09 | −2.47 | <0.05 * |
| 1 | As opposed to “true” acoustic silence, where background noise is absent. |
| 2 | The majority of forensic phonetic casework deals with male voices, which is why most research in this area focuses on this speaker group. |
| 3 | Maclay and Osgood (1959) found a mean of 152 words/min. |
| 4 | Converting this unit to a rate per minute is more difficult than for the rate per 100 words, as syllable duration is highly depend on the syllable structure and the stress and pause context (Crystal and House 1990). We reached an approximation by taking the most frequent syllable structure (CVC) reported by Crystal and House (1990) and calculating the mean duration of the CVC type before and after pauses in stressed and unstressed position (mean = 250 ms). |
| 5 | Due to legal issues, the corpus is not freely available though the data files and our R script are available on OSF: https://osf.io/yf3et/ (accessed on 20 October 2022). |
| 6 | In certain cases there may be one or four taboo words instead. |
| 7 | Note that these are not the same as glottal FPs, as a vowel may still be discernible. |
| 8 | Maximum formant: 5000 Hz; maximum number of formants: 5; window length: 0.025 s; dynamic range: 50 Hz. |
References
- Adams, Martin R., and John Hutchinson. 1974. The effects of three levels of auditory masking on selected vocal characteristics and the frequency of disfluency of adult stutterers. Journal of Speech and Hearing 17: 682–88. [Google Scholar] [CrossRef] [PubMed]
- Alexander, Anil, Damien Dessimoz, Filippo Botti, and Andrzej Drygajlo. 2005. Aural and automatic forensic speaker recognition in mismatched conditions. International Journal of Speech, Language and the Law 12: 214–34. [Google Scholar] [CrossRef]
- Bates, Douglas, Martin Mächler, Benjamin M. Bolker, and Steven C. Walker. 2015. Fitting Linear Mixed-Effects Models using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Batliner, Anton, Andreas Kießling, Susanne Burger, and Elmar Nöth. 1995. Filled Pauses in Spontaneous Speech. Paper presented at International Congress of Phonetic Sciences (ICPhS), Stockholm, Sweden, August 13–19; pp. 472–75. [Google Scholar]
- Bellinghausen, Charlotte, Simon Betz, Katharina Zahner, Alina Sasdrich, Marin Schröer, and Bernhard Schröder. 2019. Disfluencies in German adult-and infant-directed speech. Paper presented at SEFOS: 1st International Seminar on the Foundations of Speech. Breathing, Pausing and The Voice, Sønderborg, Denmark, December 1–3; pp. 44–46. [Google Scholar]
- Belz, Malte. 2017. Glottal filled pauses in German. In Workshop on Disfluency in Spontaneous Speech (DiSS 2017). Stockholm: KTH Royal Institute of Technology, pp. 5–8. [Google Scholar]
- Belz, Malte. 2018. Vowel quality of German äh and ähm in dialogue moves. In Phonetik und Phonologie im Deutschsprachigen Raum (P&P14). Wien: Universität Wien, pp. 13–17. [Google Scholar]
- Belz, Malte. 2019. GECO-FP. Berlin: Humboldt-Universität zu. [Google Scholar] [CrossRef]
- Belz, Malte. 2021. Die Phonetik von äh und ähm: Akustische Variation von Füllpartikeln im Deutschen. Berlin: Metzler. [Google Scholar] [CrossRef]
- Belz, Malte. 2023. Defining filler particles: A phonetic account of the terminology, form, and grammatical classification of “filled pauses”. Languages 8: 57. [Google Scholar] [CrossRef]
- Belz, Malte, and Myriam Klapi. 2013. Pauses following fillers in L1 and L2 German Map Task Dialogues. Paper presented at Workshop on Disfluency in Spontaneous Speech (DiSS 2013), Stockholm, Sweden, August 21–23; pp. 9–12. [Google Scholar]
- Belz, Malte, and Christine Mooshammer. 2020. Berlin Dialogue Corpus (BeDiaCo). (Version 1). Berlin: Humboldt-Universität zu. [Google Scholar]
- Belz, Malte, and Uwe D. Reichel. 2015. Pitch Characteristics of Filled Pauses. Paper presented at 7th Workshop on Disfluency in Spontaneous Speech (DiSS 2015), Edinburgh, UK, August 8–9; pp. 1–4. [Google Scholar]
- Belz, Malte, Simon Sauer, Anke Lüdeling, and Christine Mooshammer. 2017. Fluently disfluent?: Pauses and repairs of advanced learners and native speakers of German. International Journal of Learner Corpus Research 3: 118–48. [Google Scholar] [CrossRef]
- Belz, Malte, and Jürgen Trouvain. 2019. Are ‘silent’ pauses always silent? Paper presented at International Congress of Phonetic Sciences (ICPhS), Melbourne, Australia, August 5–9; pp. 2744–48. [Google Scholar]
- Boersma, Paul, and David Weenink. 2022. Praat: Doing Phonetics by Computer. Available online: https://www.fon.hum.uva.nl/praat/ (accessed on 20 October 2022).
- Bortfeld, Heather, Silvia D. Leon, Jonathan E. Bloom, Michael F. Schober, and Susan E Brennan. 2001. Disfluency rates in conversation: Effects of age, relationship, topic, role, and gender. Language and Speech 44: 123–47. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Braun, Angelika, and Annabelle Rosin. 2015. On the speaker-specificity of hesitation markers. In International Congress of Phonetic Sciences (ICPhS). Glasgow: International Phonetic Association. [Google Scholar]
- Butterworth, Brian. 1975. Hesitation and semantic planning in speech. Journal of Psycholinguistic Research 4: 75–87. [Google Scholar] [CrossRef]
- Campione, Estelle, and Jean Véronis. 2002. A large-scale multilingual study of pause duration. Paper presented at International Conference on Speech Prosody, Aix-en-Provence, France, April 11–13; pp. 199–202. [Google Scholar]
- Candea, Maria, Ioana Vasilescu, and Martine Adda-Decker. 2005. Inter- and intra-language acoustic analysis of autonomous fillers. Paper presented at Workshop on Disfluency in Spontaneous Speech Workshop (DiSS 2005), Aix-en-Provence, France, September 10–12; pp. 47–52. [Google Scholar]
- Cataldo, Violetta, Loredana Schettino, Renata Savy, Isabella Poggi, Antonio Origlia, Alessandro Ansani, Isora Sessa, and Alessandra Chiera. 2019. Phonetic and functional features of pauses, and concurrent gestures, in tourist guides’ speech. Audio Archives at the Crossroads of Speech Sciences, Digital Humanities and Digital Heritage 6: 205–231. [Google Scholar]
- Clark, Herbert H., and Jean E. Fox Tree. 2002. Using uh and um in spontaneous speaking. Cognition 84: 73–111. [Google Scholar] [CrossRef]
- Clark, John, Colin Yallop, and Janet Fletcher. 2007. An Introduction to Phonetics and Phonology, 3rd ed. Malden: Blackwell Publishing. [Google Scholar]
- Corley, Martin, and Oliver W. Stewart. 2008. Hesitation disfluencies in spontaneous speech: The meaning of um. Language and Linguistics Compass 2: 589–602. [Google Scholar] [CrossRef] [Green Version]
- Crystal, Thomas H., and Arthur S. House. 1990. Articulation rate and the duration of syllables and stress groups in connected speech. Journal of the Acoustical Society of America 88: 101–12. [Google Scholar] [CrossRef] [PubMed]
- de Jong, Nivja H., and Ton Wempe. 2009. Praat script to detect syllable nuclei and measure speech rate automatically. Behavior Research Methods 41: 385–90. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- de Leeuw, Esther. 2007. Hesitation markers in English, German, and Dutch. Journal of Germanic Linguistics 19: 85–114. [Google Scholar] [CrossRef]
- Fox Tree, Jean E. 1995. The effects of false starts and repetitions on the processing of subsequent words in spontaneous speech. Journal of Memory and Language 34: 709–38. [Google Scholar] [CrossRef]
- Fuchs, Susanne, and Amélie Rochet-Capellan. 2021. The respiratory foundations of spoken language. Annual Review of Linguistics 7: 1–18. [Google Scholar] [CrossRef]
- Garnier, Maëva, Lucie Bailly, Marion Dohen, Pauline Welby, and Hélène Lœvenbruck. 2006. An acoustic and articulatory study of Lombard speech: Global effects on the utterance. Paper presented at Annual Conference of the International Speech Communication Association (INTERSPEECH), Pittsburgh, PA, USA, September 17–21; pp. 2246–49. [Google Scholar] [CrossRef]
- Gerstenberg, Annette, Susanne Fuchs, Julie Marie Kairet, Claudia Frankenberg, and Johannes Schröder. 2018. A cross-linguistic, longitudinal case study of pauses and interpausal units in spontaneous speech corpora of older speakers of German and French. Paper presented at International Conference on Speech Prosody, Poznań, Poland, June 13–16; pp. 211–15. [Google Scholar] [CrossRef] [Green Version]
- Gick, Bryan, Ian Wilson, Karsten Koch, and Clare Cook. 2004. Language-specific articulatory settings: Evidence from inter-utterance rest position. Phonetica 61: 220–33. [Google Scholar] [CrossRef] [PubMed]
- Gold, Erica, and Peter French. 2011. International practices in forensic speaker comparison. International Journal of Speech, Language and the Law 18: 293–307. [Google Scholar] [CrossRef]
- Gold, Erica, Peter French, and Philip Harrison. 2013. Clicking behavior as a possible speaker discriminant in English. Journal of the International Phonetic Association 43: 339–49. [Google Scholar] [CrossRef]
- Goldman-Eisler, Frieda. 1972. Pauses, clauses, sentences. Language and Speech 15: 103–13. [Google Scholar] [CrossRef]
- Goodwin, Charles. 1981. Conversation Organization: Interaction Between Speakers and Hearers. New York: Academic Press. [Google Scholar]
- Gósy, Mária, and Vered Silber-Varod. 2021. Attached filled pauses: Occurrences and durations. Paper presented at Workshop on Disfluency in Spontaneous Speech (DiSS 2021), Paris, France, August 25–26; pp. 71–76. [Google Scholar]
- Gully, Amelia J, Paul Foulkes, Peter French, Philip Harrison, and Vincent Hughes. 2019. The Lombard effect in MRI Noise. Paper presented at International Congress of Phonetic Sciences (ICPhS), Melbourne, Australia, August 5–9; pp. 800–4. [Google Scholar]
- Harrington, Lauren, Richard Rhodes, and Vincent Hughes. 2021. Style variability in disfluency analysis for forensic speaker comparison. International Journal of Speech Language and the Law 28: 31–58. [Google Scholar] [CrossRef]
- Hay, Jennifer, Ryan Podlubny, Katie Drager, and Megan McAuliffe. 2017. Car-talk: Location-specific speech production and perception. Journal of Phonetics 65: 94–109. [Google Scholar] [CrossRef]
- Hughes, Vincent, Sophie Wood, and Paul Foulkes. 2016. Strength of forensic voice comparison evidence from the acoustics of filled pauses. International Journal of Speech, Language and the Law 23: 99–132. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, Omnia, Ivan Yuen, Marjolein van Os, Bistra Andreeva, and Bernd Möbius. 2022. The combined effects of contextual predictability and noise on the acoustic realisation of German syllables. The Journal of the Acoustical Society of America 152: 911–20. [Google Scholar] [CrossRef] [PubMed]
- Jessen, Michael. 2007. Forensic reference data on articulation rate in German. Science and Justice 47: 50–67. [Google Scholar] [CrossRef] [PubMed]
- Jessen, Michael. 2012. Phonetische und Linguistische Prinzipien des Forensischen Stimmenvergleichs. München: Lincom. [Google Scholar]
- Jessen, Michael. 2018. Forensic voice comparison. In Handbook of Communication in the Legal Sphere. Edited by Jacqueline Visconti and Monika Rathert. Berlin: Mouton de Gruyter, pp. 219–55. [Google Scholar]
- Jessen, Michael, Olaf Köster, and Stefan Gfroerer. 2005. Influence of vocal effort on average and variability of fundamental frequency. International Journal of Speech Language and the Law 12: 174–213. [Google Scholar] [CrossRef]
- Keating, Patricia, Marc Garellek, and Jody Kreiman. 2015. Acoustic properties of different kinds of creaky voice. Paper presented at International Congress of Phonetic Sciences (ICPhS). Number 1, Glasgow, UK, August 10–14; pp. 2–7. [Google Scholar]
- Kelley, Matthew C., and Benjamin V. Tucker. 2020. A comparison of four vowel overlap measures. The Journal of the Acoustical Society of America 147: 137–45. [Google Scholar] [CrossRef]
- Kjellmer, Göran. 2003. Hesitation. In defence of ER and ERM. English Studies 84: 170–98. [Google Scholar] [CrossRef]
- Klug, Katharina, and Marie König. 2012. Untersuchung zur sprecherspezifischen Verwendung von Häsitationspartikeln anhand der Parameter Grundfrequenz und Vokalqualität. In Erforschung und Optimierung der Callcenterkommunikation. Edited by Ursula Hirschfeld and Baldur Neuber. Berlin: Frank & Timme, pp. 175–93. [Google Scholar]
- Kohler, Klaus J. 1994. Glottal stops and glottalization in German: Data and theory of connected speech processes. Phonetica 51: 38–51. [Google Scholar] [CrossRef]
- Krech, Eva Maria. 1968. Sprechwissenschaftlich-Phonetische Untersuchungen zum Gebrauch des Glottisschlageinsatzes in der Allgemeinen Deutschen Hochlautung. Basel and New York: Kager. [Google Scholar]
- Künzel, Hermann J. 1987. Sprechererkennung. Grundzüge Forensischer Sprachverarbeitung. Heidelberg: Kriminalistik Verlag. [Google Scholar]
- Kuznetsova, Alexandra, Per Bruun Brockhoff, and Rune Haubo Bojesen Christensen. 2017. lmerTest Package: Tests in Linear Mixed Effects Models. Journal of Statistical Software 82: 1–26. [Google Scholar] [CrossRef] [Green Version]
- Labov, William. 1990. The intersection of sex and social class in the course of linguistic change. Language Variation and Change 2: 205–54. [Google Scholar] [CrossRef] [Green Version]
- Li, Xiaoting. 2020. Click-initiated self-repair in changing the sequential trajectory of actions-in-progress. Research on Language and Social Interaction 53: 90–117. [Google Scholar] [CrossRef]
- Lindblom, Björn E. F. 1968. Temporal organization of syllable production. In Speech Transmission Lab. Quarterly Progress Status Report. Stockholm: KTH Department of Speech, Music, and Hearing, vol. 9, pp. 1–5. [Google Scholar]
- Lo, Justin J. H. 2020. Between äh(m) and euh(m): The distribution and realization of filled pauses in the speech of German-French simultaneous bilinguals. Language and Speech 63: 746–68. [Google Scholar] [CrossRef] [PubMed]
- Lombard, Etienne. 1911. Le signe de l’élévation de la voix. Annales des Maladies de L’oreille et du Larynx 37: 101–19. [Google Scholar]
- Maclay, Howard, and Charles E. Osgood. 1959. Hesitation Phenomena in Spontaneous English Speech. Word 15: 19–44. [Google Scholar] [CrossRef]
- McDougall, Kirsty, and Martin Duckworth. 2017. Profiling fluency: An analysis of individual variation in disfluencies in adult males. Speech Communication 95: 16–27. [Google Scholar] [CrossRef] [Green Version]
- McDougall, Kirsty, and Martin Duckworth. 2018. Individual patterns of disfluency across speaking styles: A forensic phonetic investigation of Standard Southern British English. International Journal of Speech, Language and the Law 25: 205–30. [Google Scholar] [CrossRef]
- Muhlack, Beeke. 2020. L1 and L2 production of non-lexical hesitation particles of German and English native speakers. Paper presented at Workshop on Laughter and Other Non-Verbal Vocalisations, Bielefeld, Germany, October 5; pp. 44–47. [Google Scholar]
- Niebuhr, Oliver, and Kerstin Fischer. 2019. Do not hesitate!-Unless you do it shortly or nasally: How the phonetics of filled pauses determine their subjective frequency and perceived speaker performance. Paper presented at Annual Conference of the International Speech Communication Association (INTERSPEECH), Graz, Austria, September 15–19; pp. 544–48. [Google Scholar] [CrossRef] [Green Version]
- O’Connell, Daniel C., and Sabine Kowal. 2005. Uh and um revisited: Are they interjections for signaling delay? Journal of Psycholinguistic Research 34: 555–76. [Google Scholar] [CrossRef]
- O’Connell, Daniel C., and Sabine Kowal. 2008. Communicating with One Another: Toward a Psychology of Spontaneous Spoken Discourse. New York: Springer. [Google Scholar]
- Ogden, Richard. 2013. Clicks and percussives in English conversation. Journal of the International Phonetic Association 43: 299–320. [Google Scholar] [CrossRef]
- Ogden, Richard. 2020. Audibly not saying something with clicks. Research on Language and Social Interaction 53: 66–89. [Google Scholar] [CrossRef]
- Oliveira, Miguel. 2002. The role of pause pccurrence and pause duration in the signaling of narrative structure. In Advances in Natural Language Processing. Berlin and Heidelberg: Springer, pp. 43–51. [Google Scholar] [CrossRef]
- Pätzold, Matthias, and Adrian Simpson. 1995. An acoustic analysis of hesitation particles in German. Paper presented at International Congress of Phonetic Sciences (ICPhS), Stockholm, Sweden, August 13–19; vol. 3, pp. 512–15. [Google Scholar]
- Pistor, Tillmann. 2017. Prosodische Universalien bei Diskurspartikeln. Zeitschrift für Dialektologie und Linguistik 84: 46–76. [Google Scholar] [CrossRef]
- Quené, Hugo. 2007. On the just noticeable difference for tempo in speech. Journal of Phonetics 35: 353–62. [Google Scholar] [CrossRef]
- R Core Team. 2022. R: A Language and Environment for Statistical Computing. In R Foundation for Statistical Computing. R version 4.1.3. Vienna. [Google Scholar]
- Reitbrecht, Sandra. 2017. Häsitationsphänomene in der Fremdsprache Deutsch und ihre Bedeutung für die Sprechwirkung. Berlin: Frank & Timme. [Google Scholar]
- Roach, Peter J. 2009. English Phonetics and Phonology: A Practical Course, 4th ed. Cambridge, New York and Melbourne: Cambridge University Press. [Google Scholar]
- Rose, Philip. 2002. Forensic Speaker Identification. London: Taylor & Francis. [Google Scholar]
- Schmidt, Jürgen Erich. 2001. Bausteine der Intonation? Germanistische Linguistik 157–158: 9–32. [Google Scholar]
- Schulman, Richard. 1989. Articulatory dynamics of loud and normal speech. Journal of the Acoustical Society of America 85: 295–312. [Google Scholar] [CrossRef]
- Shriberg, Ee. 1994. Preliminaries to a Theory of Speech Disfluencies. Ph. D. thesis, University of California, Berkeley, CA, USA. [Google Scholar]
- Shriberg, Elizabeth. 2001. To ‘errrr’ is human: Ecology and acoustics of speech disfluencies. Journal of the International Phonetic Association 31: 153–69. [Google Scholar] [CrossRef] [Green Version]
- Šimko, Juraj, Štefan Beňuš, and Martti Vainio. 2016. Hyperarticulation in Lombard speech: Global coordination of the jaw, lips and the tongue. The Journal of the Acoustical Society of America 139: 151–62. [Google Scholar] [CrossRef] [PubMed]
- Simpson, Adrian P. 2007. Acoustic and auditory correlates of non-pulmonic sound production in German. Journal of the International Phonetic Association 37: 173–82. [Google Scholar] [CrossRef]
- Smiljanić, Rajka, and Ann R. Bradlow. 2009. Speaking and hearing clearly: Talker and listener factors in speaking style changes. Language and Linguistics Compass 3: 236–64. [Google Scholar] [CrossRef] [Green Version]
- Smith, Vicki L., and Herbert H. Clark. 1993. On the course of answering questions. Journal of Memory and Language 32: 25–38. [Google Scholar] [CrossRef]
- Swerts, Marc. 1998. Filled pauses as markers of discourse structure. Journal of Pragmatics 30: 485–96. [Google Scholar] [CrossRef] [Green Version]
- Trouvain, Jürgen. 2004. Tempo Variation in Speech Production. Implications for Speech Synthesis. Phonus 8. Saarbrücken: Saarland University. [Google Scholar]
- Trouvain, Jürgen, and Zofia Malisz. 2016. Inter-speech clicks in an Interspeech keynote. Paper presented at Annual Conference of the International Speech Communication Association (Interspeech), San Francisco, CA, USA, September 8–12; pp. 1397–401. [Google Scholar] [CrossRef] [Green Version]
- Trouvain, Jürgen, and Raphael Werner. 2022. A phonetic view on annotating speech pauses and pause-internal phonetic particles. In Transkription und Annotation gesprochener Sprache und multimodaler Interaktion. Edited by Cordula Schwarze and Sven Grawunder. Tübingen: Narr, pp. 55–73. [Google Scholar]
- Tuomainen, Outi, Linda Taschenberger, Stuart Rosen, and Valerie Hazan. 2021. Speech modifications in interactive speech: Effects of age, sex and noise type. Philosophical Transactions of the Royal Society B 377: 20200398. [Google Scholar] [CrossRef]
- Van Summers, W., David B. Pisoni, Robert H. Bernacki, Robert I. Pedlow, and Michael A. Stokes. 1988. Effects of noise on speech production: Acoustic and perceptual analyses. Journal of the Acoustical Society of America 84: 917–28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Whalen, D. H., Wei-Rong Chen, Christine H. Shadle, and Sean A. Fulop. 2022. Formants are easy to measure; resonances, not so much: Lessons from Klatt (1986). The Journal of the Acoustical Society of America 152: 933–41. [Google Scholar] [CrossRef] [PubMed]
- Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy D’Agostino McGowan, Romain Francois, Garrett Grolemund, Alex Hayes, Lionel Henry, Jim Hester, and et al. 2019. Welcome to the tidyverse. Journal of Open Source Software 4: 1686. [Google Scholar] [CrossRef] [Green Version]
- Wieling, Martijn, Jack Grieve, Gosse Bouma, Josef Fruehwald, John Coleman, and Mark Liberman. 2016. Variation and change in the use of hesitation markers in Germanic languages. Language Dynamics and Change 6: 199–234. [Google Scholar] [CrossRef] [Green Version]
- Wohlert, Amy B., and Vicki L. Hammen. 2000. Lip muscle activity related to speech rate and loudness. Journal of Speech, Language, and Hearing Research 43: 1229–39. [Google Scholar] [CrossRef] [PubMed]
- Zellers, Margaret. 2022. An overview of discourse clicks in Central Swedish. Paper presented at Annual Conference of the International Speech Communication Association (Interspeech), Incheon, Republic of Korea, September 18–22; pp. 3423–27. [Google Scholar] [CrossRef]
















| FP Type | Absolute | Rate: FPs/min | Duration Mean (sd) | Vowel Duration Mean (sd) |
|---|---|---|---|---|
| uh | 2250 | 2.9 | 382 (180) | 382 (180) |
| um | 1054 | 1.4 | 559 (234) | 281 (125) |
| hm | 314 | 0.4 | 442 (224) | NA |
| glottal FP | 757 | 1.0 | 244 (332) | NA |
| clicks | 2359 | 3.0 | NA | NA |
| Pause Type | Pre FP | Post FP |
|---|---|---|
| simple pause (p) | 1177 (1222) | 1083 (1227) |
| waiting pause (p_w) | 3182 (2302) | 2285 (1563) |
| task change (tc) | 3962 (2706) | 3560 (2283) |
| Pause Position | Pause Type | Normal Mean (sd) in ms | Lombard Mean (sd) in ms | Difference in ms |
|---|---|---|---|---|
| −FP | p | 1030 (919) | 1330 (1457) | 300 |
| p_w | 2642 (1473) | 3978 (2984) | 1336 | |
| tc | 3389 (1903) | 4706 (3346) | 1317 | |
| FP− | p | 985 (1123) | 1196 (1329) | 211 |
| p_w | 2189 (1313) | 2388 (1795) | 199 | |
| tc | 3192 (1807) | 4167 (2863) | 975 |
| FP Type | Minimum | Maximum |
|---|---|---|
| uh | 188 (69) | 448 (278) |
| um | 334 (46) | 648 (315) |
| hm | 161 (82) | 721 (349) |
| gl FP | 93 (24) | 629 (615) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muhlack, B.; Trouvain, J.; Jessen, M. Distributional and Acoustic Characteristics of Filler Particles in German with Consideration of Forensic-Phonetic Aspects. Languages 2023, 8, 100. https://doi.org/10.3390/languages8020100
Muhlack B, Trouvain J, Jessen M. Distributional and Acoustic Characteristics of Filler Particles in German with Consideration of Forensic-Phonetic Aspects. Languages. 2023; 8(2):100. https://doi.org/10.3390/languages8020100
Chicago/Turabian StyleMuhlack, Beeke, Jürgen Trouvain, and Michael Jessen. 2023. "Distributional and Acoustic Characteristics of Filler Particles in German with Consideration of Forensic-Phonetic Aspects" Languages 8, no. 2: 100. https://doi.org/10.3390/languages8020100