1. Introduction
With the increase in mission complexity, new requirements are put forward for the autonomous decision-making ability and intelligent level of the onboard trajectory optimization algorithm [
1]. On the one hand, due to the limitation of long-distance communication and the complex uncertainty of the deep space environment, an advanced trajectory optimization algorithm is required to have stronger autonomy and adaptability [
2,
3,
4]. On the other hand, trajectory optimization algorithms are also required to be computationally efficient to make deep space exploration tasks accurate and stable while highly nonlinear dynamics model makes it more difficult [
5,
6,
7]. Therefore, it is particularly necessary to develop a real-time, autonomous and reliable advanced trajectory optimization algorithm [
8].
The optimal control and trajectory optimization task of spacecraft can essentially be described as an optimal control problem (OCP) which can traditionally be solved by two kinds of methods: direct method and indirect method [
9]. The direct method converts the OCP into a nonlinear programming problem by discretizing the state and control trajectory, and then uses the nonlinear solver such as SNOPT [
10] and IPOPT [
11] to solve it [
12]. Relatively speaking, the direct method has acceptable convergence, a better ability to deal with path constraints and stronger applicability. However, when high-precision solutions are required, the computational cost increases with the increase in the number of discrete variables, and the direct method cannot guarantee the first order necessary condition [
13,
14,
15,
16,
17,
18]. Based on the calculus of variations and Pontryagin’s minimum principle, the indirect method converts the OCP into a two-point boundary value problem (TPBVP) [
19]. The shooting methods can solve this TPBVP by guessing the initial costate and correcting it to obtain the optimal solution. The most attractive advantage of the indirect method is that it guarantees the local optimality of the solution from the theoretical level through the first-order necessity condition, and finally obtains a high-fidelity solution. However, the convergence range of the indirect method is very small and it can hardly deal with inequality constraints. Additionally, due to the lack of physical meaning, it is difficult to provide sufficiently accurate initial costate variables for the shooting method. An inaccurate initial costate makes the calculation time and the number of iterations greatly increase. Therefore, the real-time performance and stability are difficult to guarantee, which also hampers its onboard application [
20,
21,
22].
In recent years, in the aim of solving problems such as the high computational cost and small convergence region faced by traditional methods, researchers have proposed many methods based on artificial intelligence and machine learning to improve the performance of a trajectory optimization algorithm from different aspects. Izzo fitted the state and control commands at each moment through DNN, and then generated the optimal control model and realized the precise landing of the controlled object in real time [
23,
24]. Cheng and Wang used DNN to map the initial state and the costate variables, which guarantees the efficiency and success rate of the indirect methods and greatly improves the real-time performance and stability of an onboard trajectory optimization algorithm for spacecraft missions [
25,
26]. Biggs trained DNN using the pulse engine switching time for spacecraft, improved the trajectory accuracy of Bang-Bang control, and ensured the validity of a depth neural network using in discrete decision-making OCPs [
27]. In [
28], a deep neural network was combined with a traditional feedback control algorithm to ensure the reliability of a moon landing mission. Because DNN only takes limited simple vector/matrix multiplications [
29], the practice of treating DNN as the optimal control predictor greatly improves the real-time performance of onboard trajectory optimization algorithms. Additionally, to solve optimal reconfiguration, some scholars have introduced the neural network into the field of model predictive control and achieved good performance. In [
30], in the aim of solving the challenging problem of deep space spacecraft formation flight, the author proposed a new nonlinear adaptive neural control method. In [
31], Zhou incorporated neural network into the adaptive formation reconfiguration control scheme to improve the control accuracy while making the system robust to uncertain disturbances. For the nearly optimal reconfiguration and maintenance of a distributed formation flying spacecraft, Silvestrini, S. used a model-based reinforcement learning method and introduced inverse reinforcement learning and long short-term memory network into it. The simulation results showed that the proposed algorithm achieved good performance and solved the reconfiguration scenario, which are challenging tasks for traditional algorithms [
32,
33]. However, the deep neural network is a black box model and is not interpretable, so the safety of a trajectory optimization algorithm cannot be demonstrated [
34].
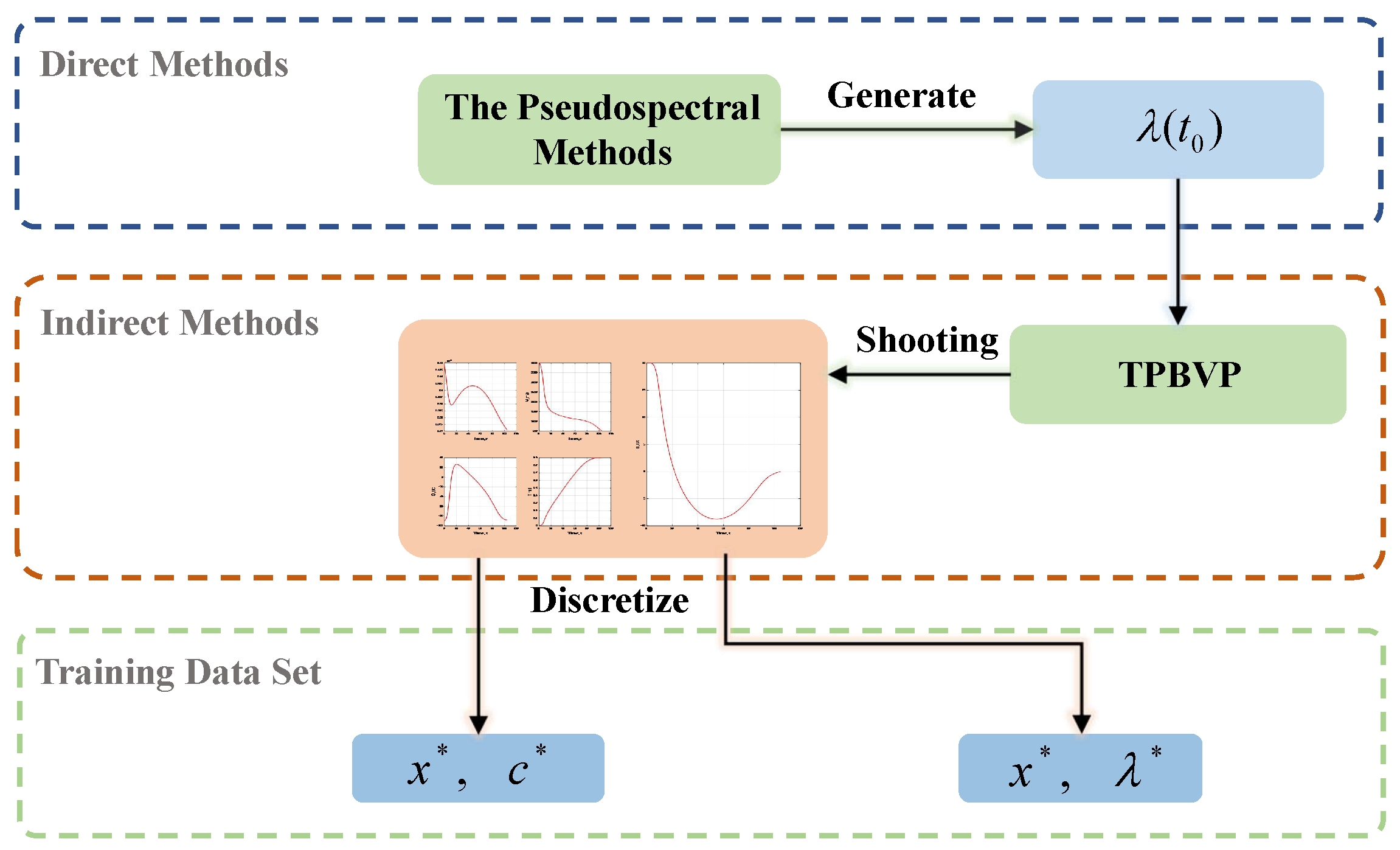
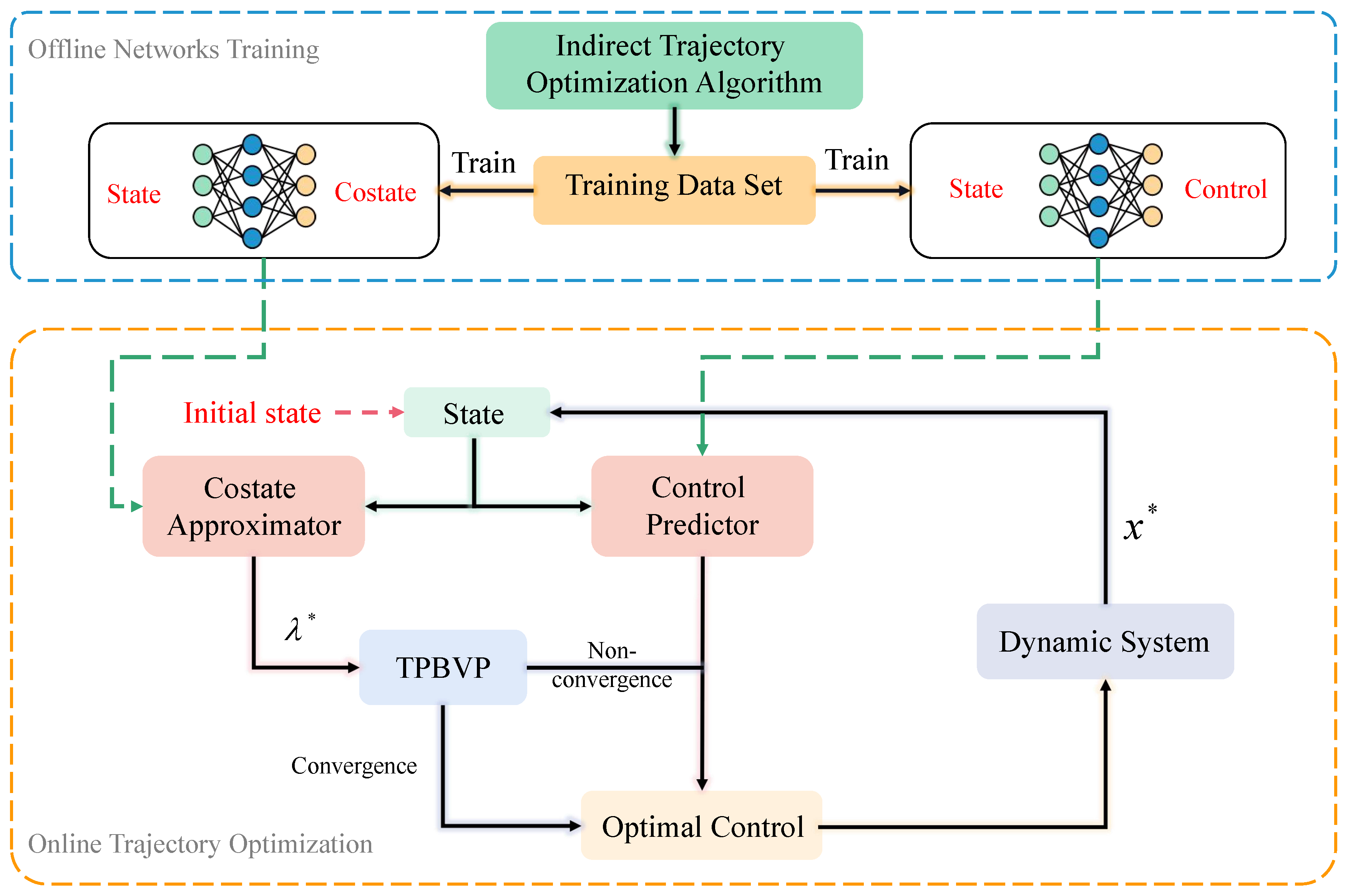
A traditional trajectory optimization algorithm is confronted with difficulties in onboard application due to time-consuming computational requirements, while the direct use of the neural networks as controllers may lead to a lack of reliability in a trajectory optimization algorithm. To solve this problem, in this paper, optimal control theory was tightly combined with a neural network to build a real-time and stable trajectory optimization algorithm with a certain level of intelligence. Specifically, the contributions of this paper are as follows: first, a neural network-based warm-started indirect trajectory optimization method is proposed to ensure its onboard application. The initial costate variables obtained from the well-trained neural network can warm-start the indirect method’s shooting. Second, in order to further ensure the security and stability of the algorithm, the neural network-based optimal action predictor is designed by mapping the nonlinear functional relationship between the state and the optimal action. Then, a backup optimal control variables generation strategy is provided in the case of indirect method shooting failure. Third, two typical spacecraft flight missions are used to verify the feasibility and versatility of the proposed algorithm.
The organization structure of this paper is as follows:
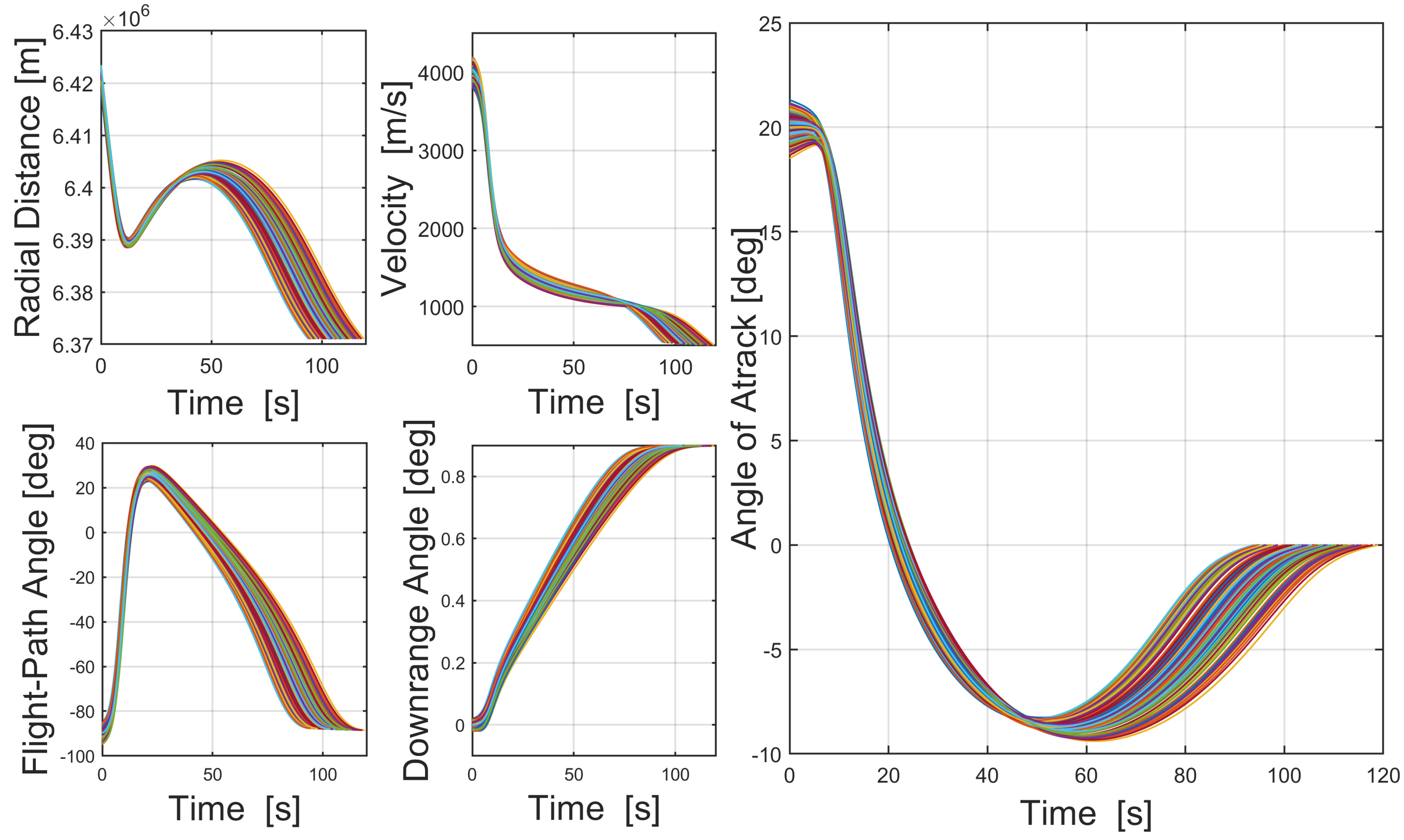
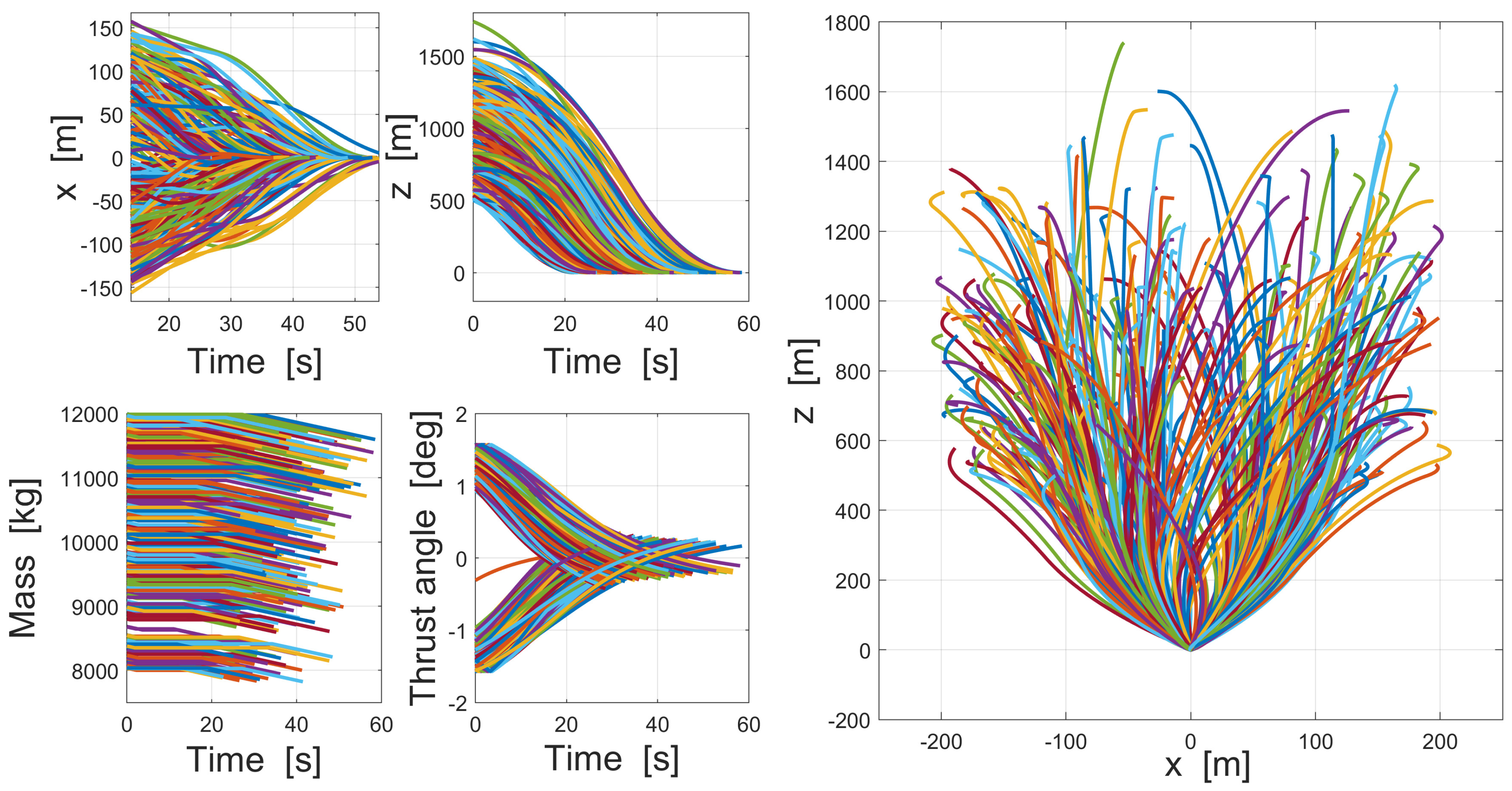
Section 2 presents the formulation of the hypersonic vehicle reentry (HVR) problem and fuel-optimal moon landing (FOML) problem. Then, based on Pontryagin’s minimize principle, the formulation of TPBVP and the optimal condition are derived in
Section 3, and the generation of training dataset is discussed. In
Section 4, the DNNs are trained and the proposed trajectory optimization method is presented. In
Section 5, the performance of the proposed method is verified by numerical simulations. Relevant work is summarized in
Section 6.
6. Conclusions
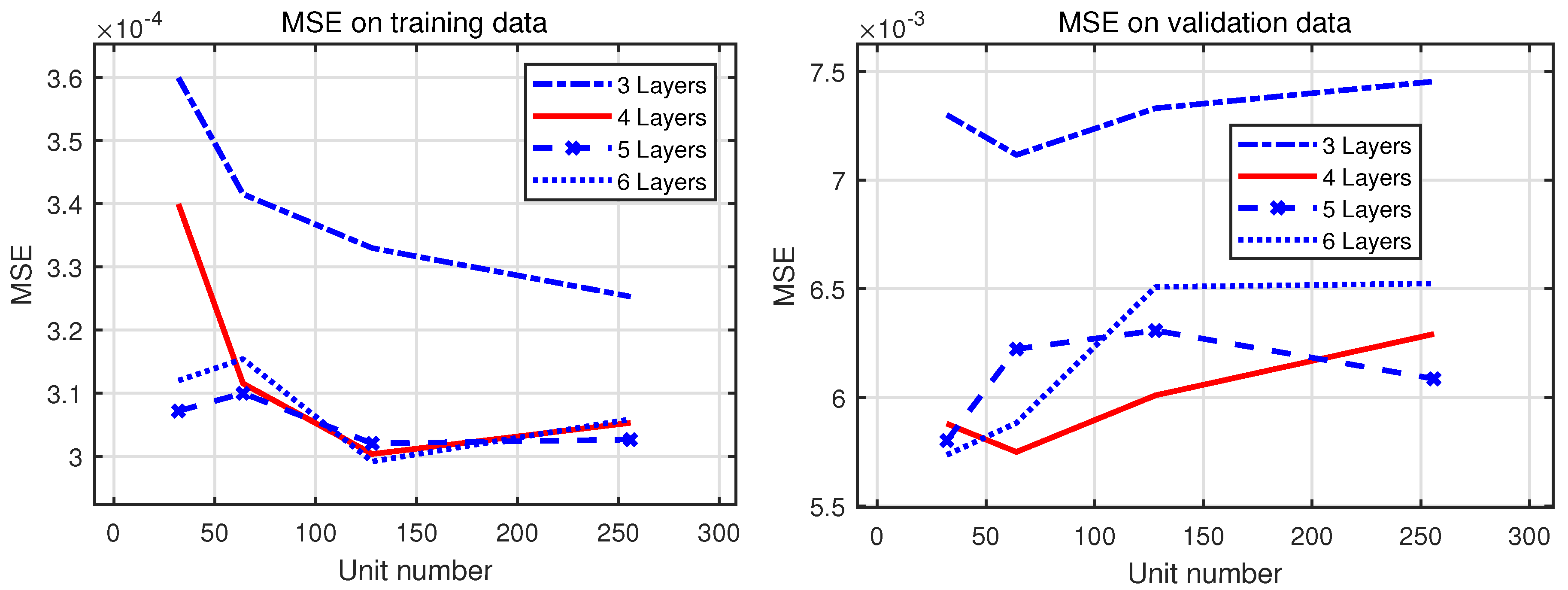
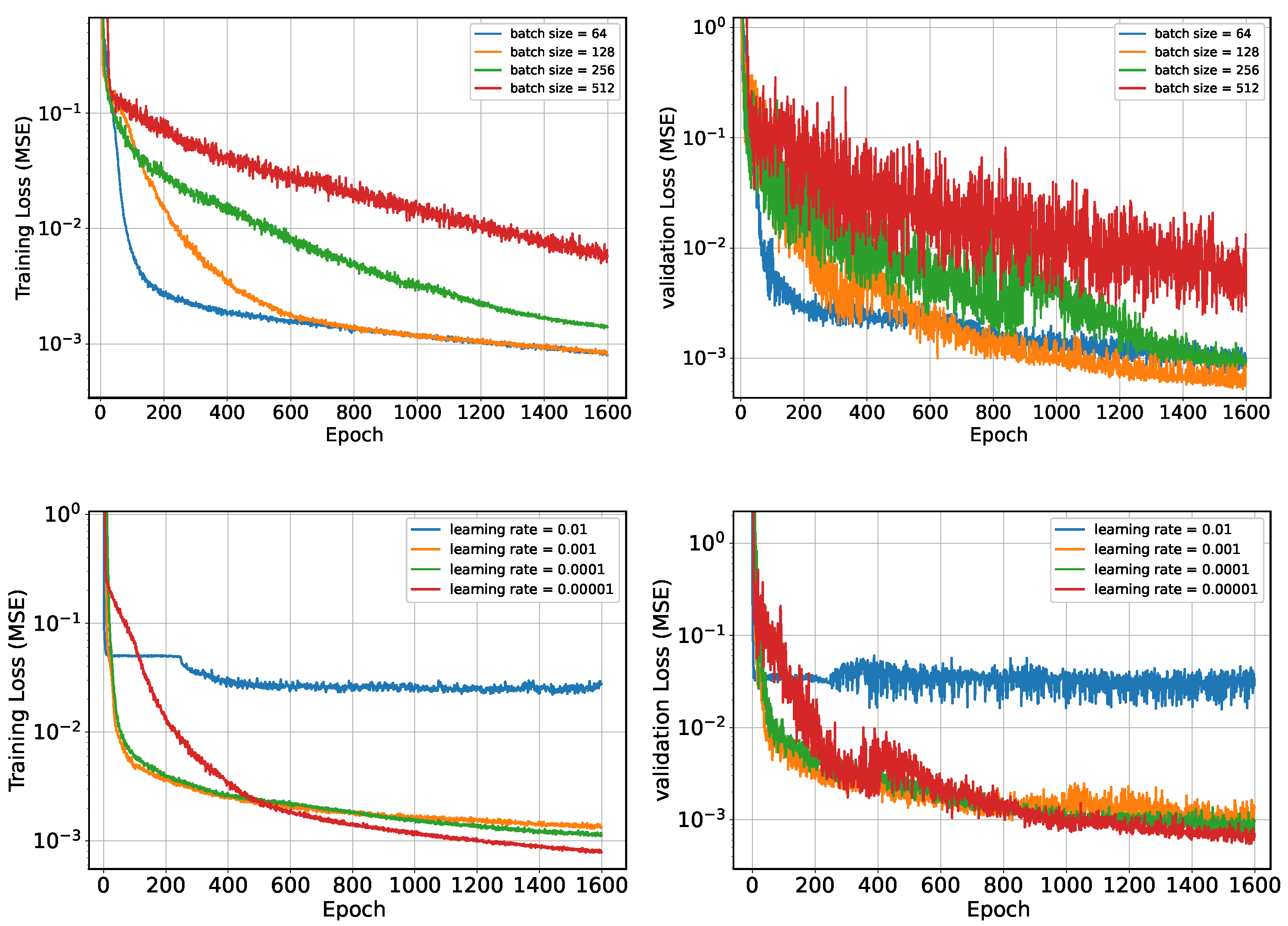
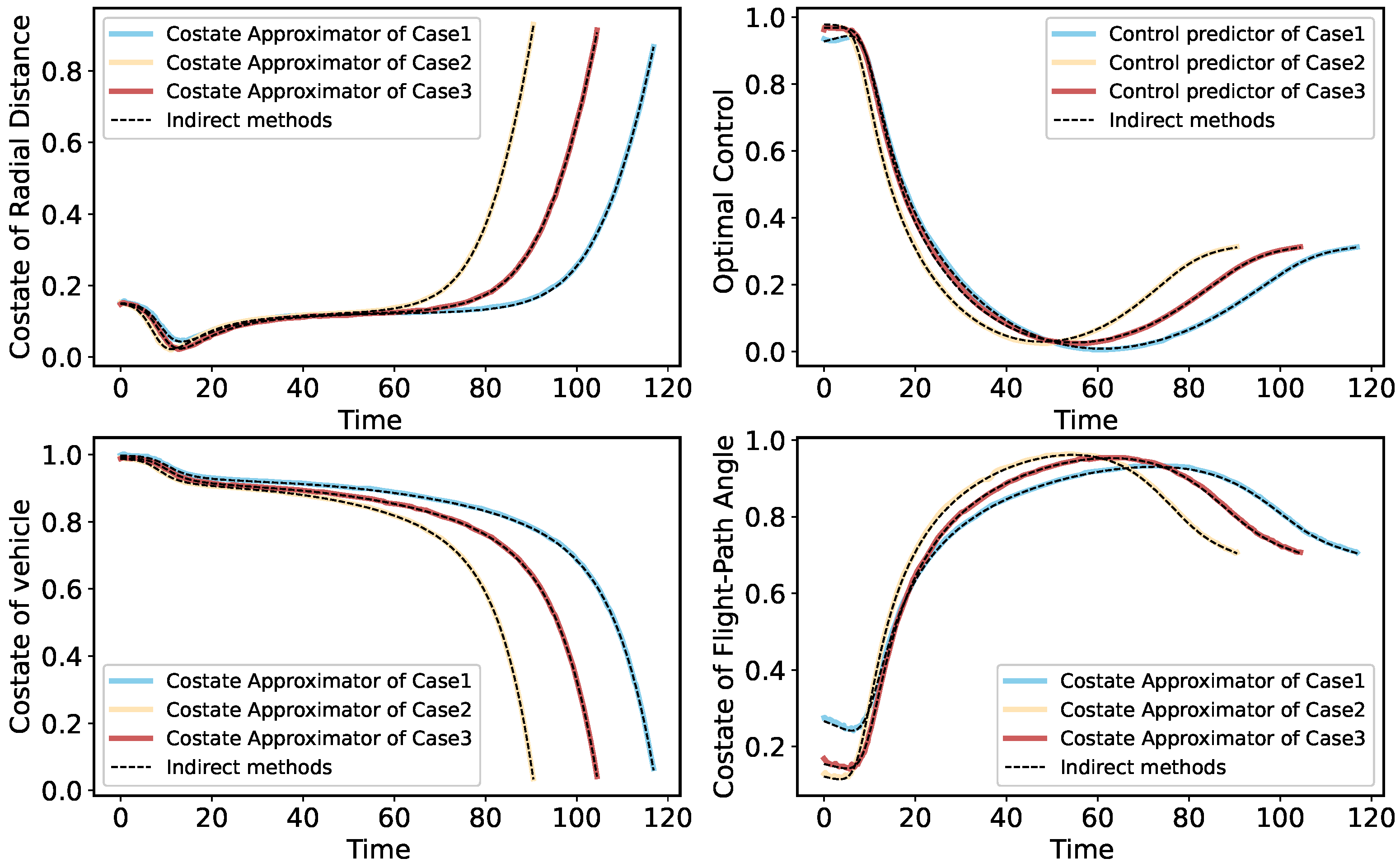
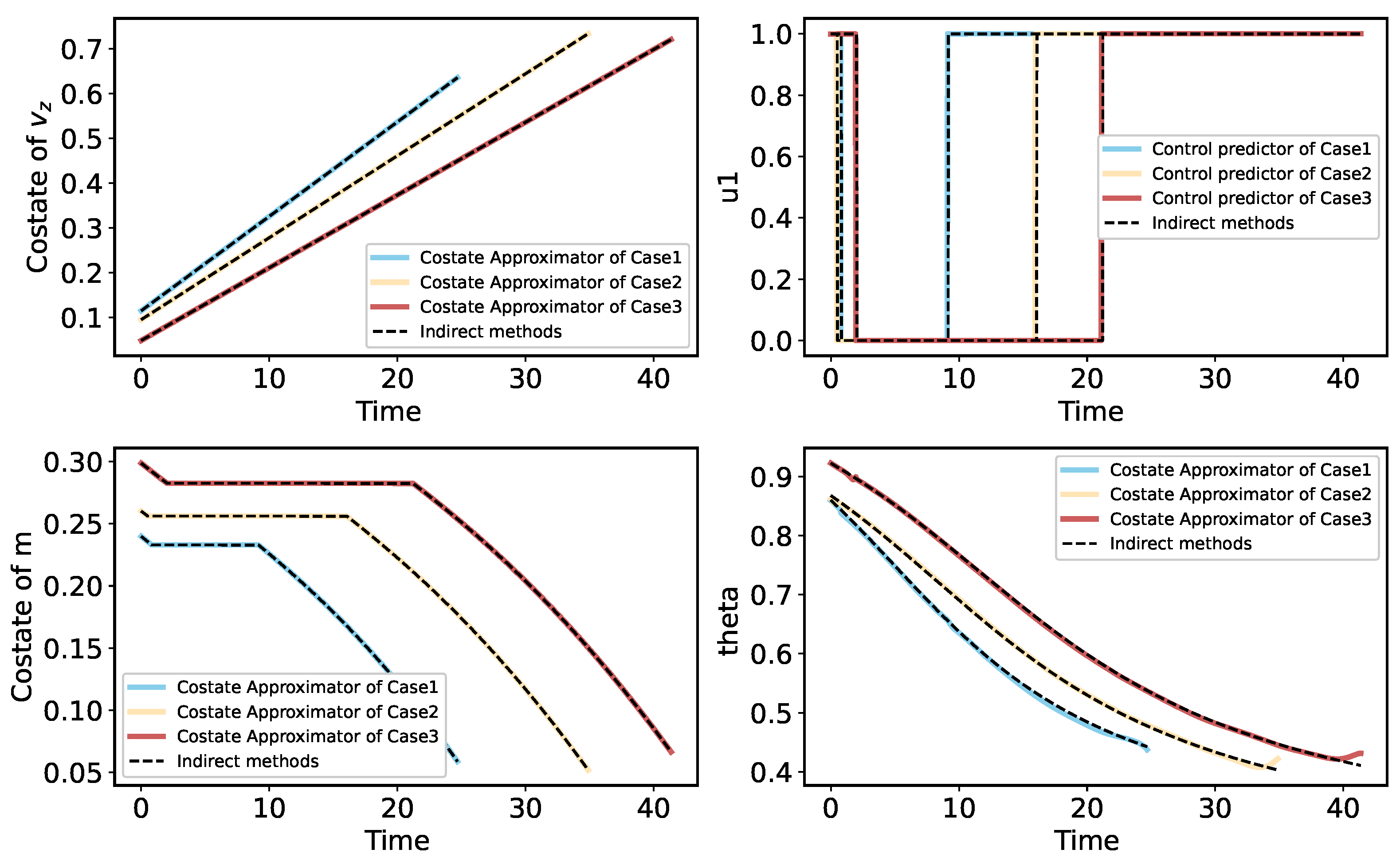
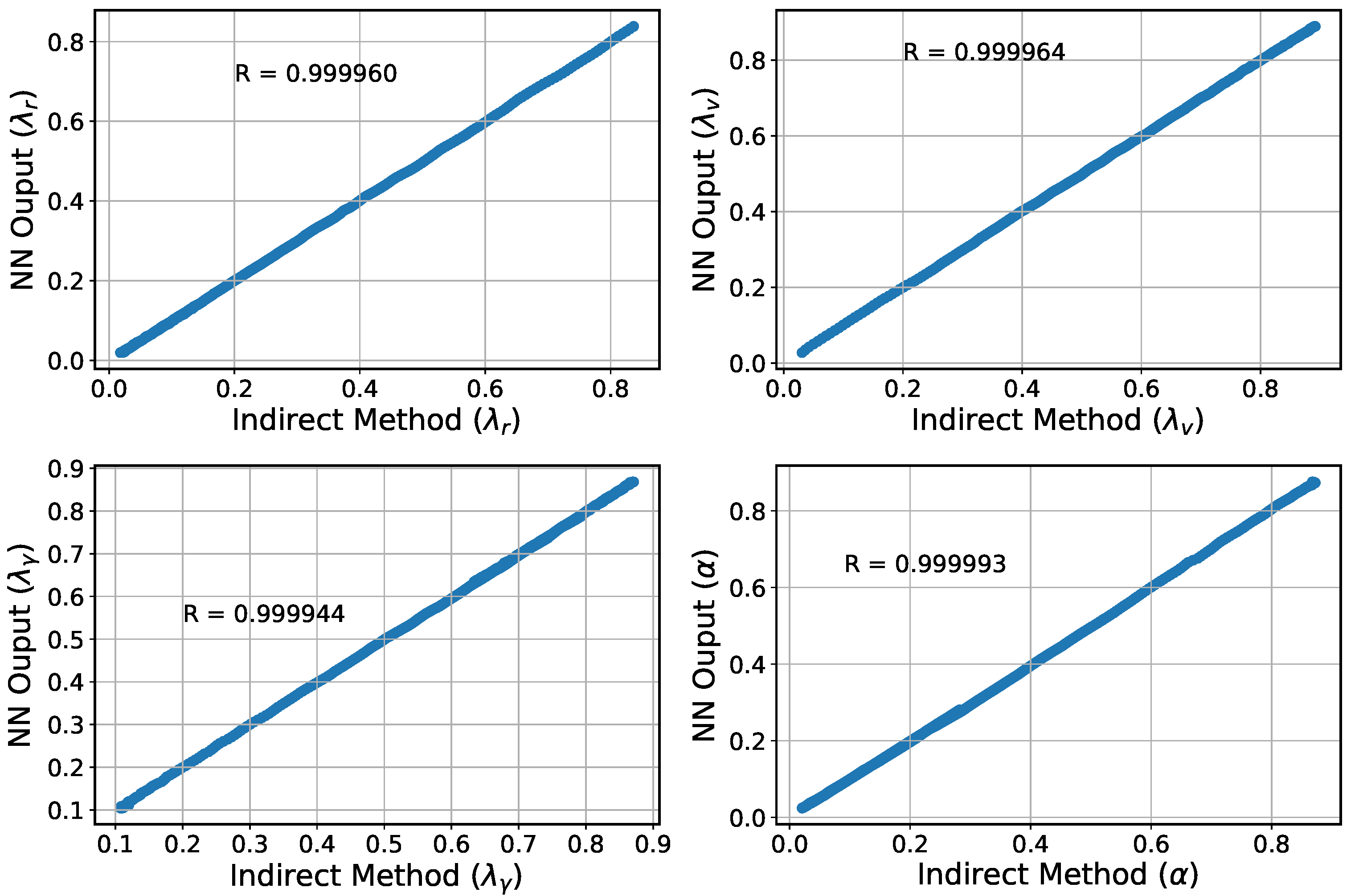
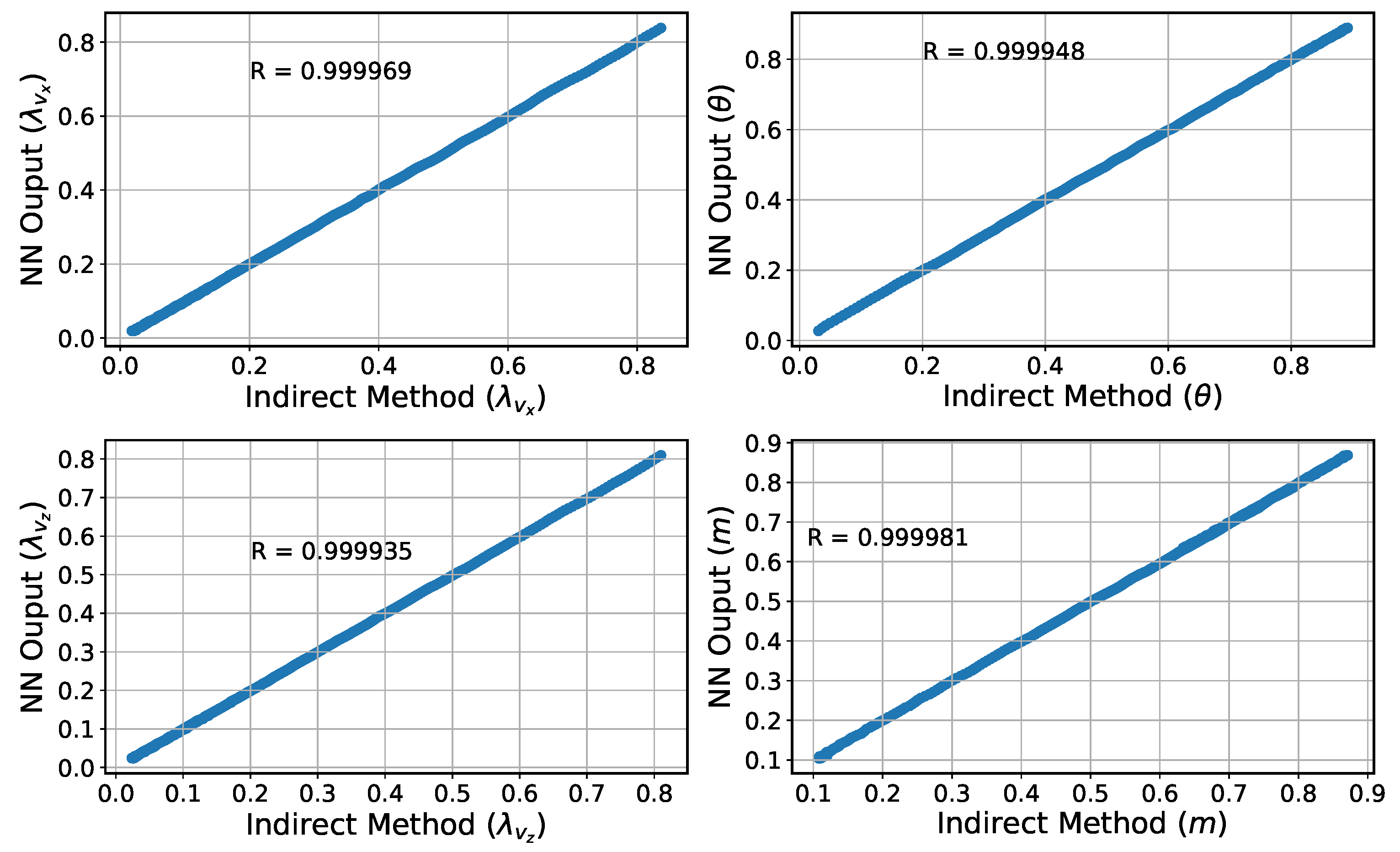
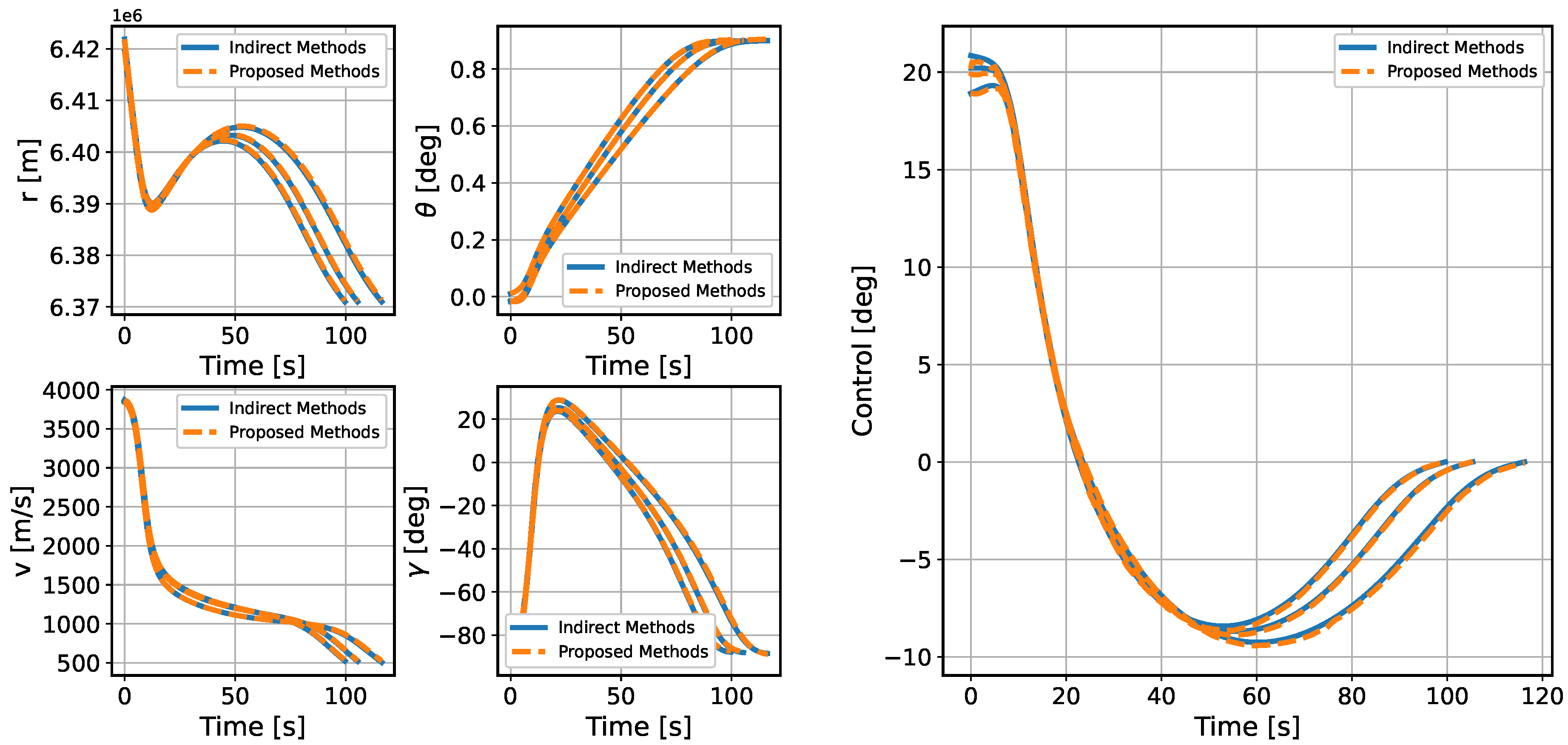
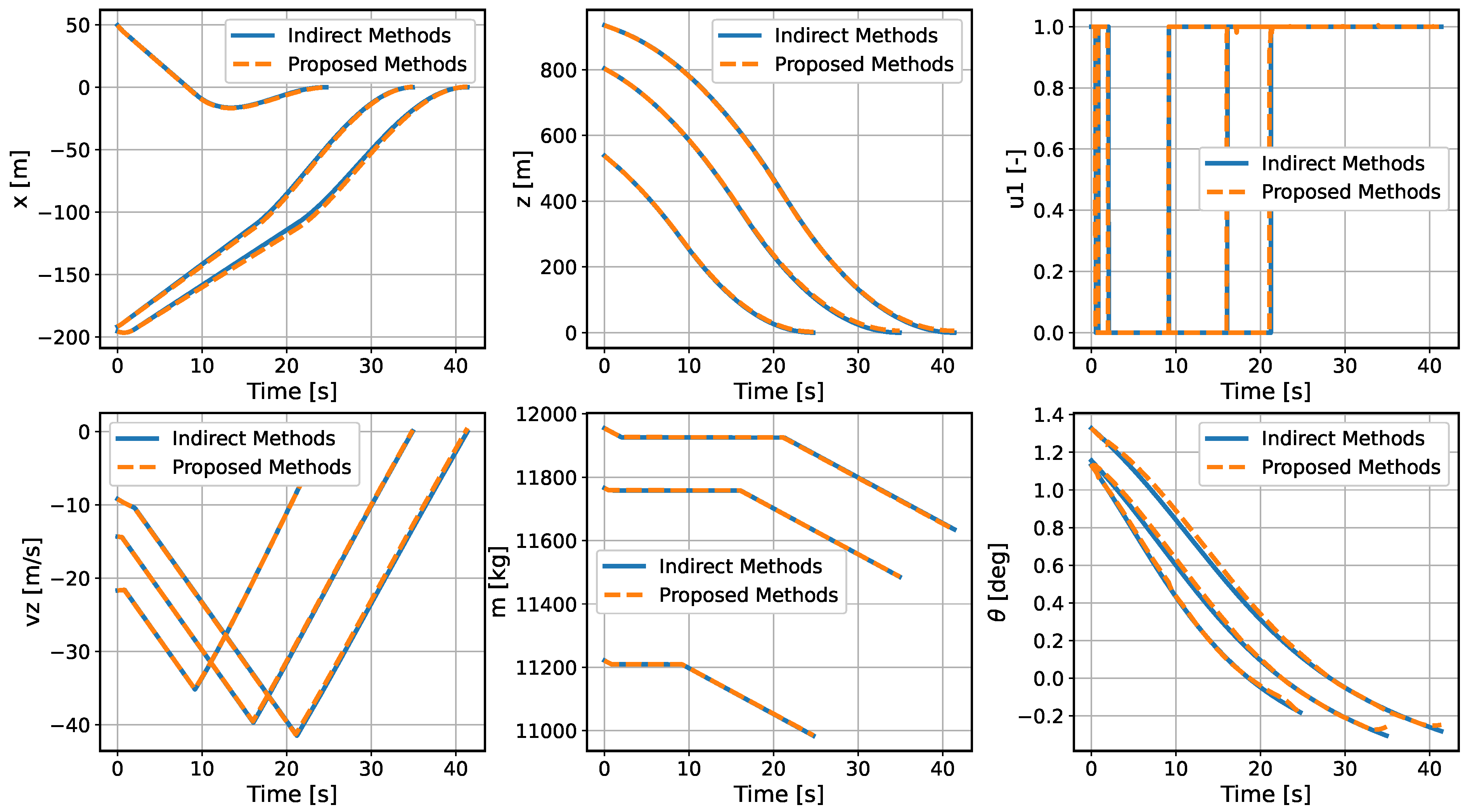
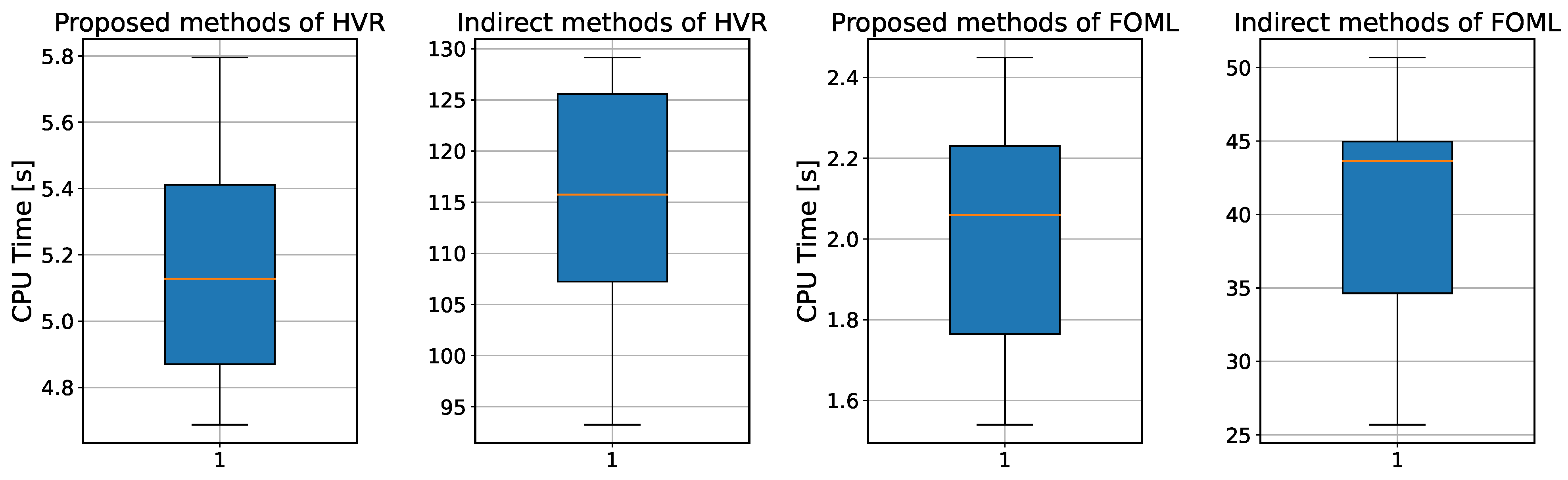
To improve the autonomous decision-making ability and intelligence level of the onboard trajectory optimization algorithm, this paper combines optimal control theory with deep learning method and develops a neural network warm-started indirect trajectory optimization method. First, two typical complex spacecraft flight missions are formulated as OCPs and the corresponding TPBVPs are derived. The pseudospectral method and the shooting method are combined to obtain a high fidelity solution for DNN training. Based on the well-trained DNN model, the proposed method achieves fast solutions to the trajectory optimization problems. Numerical simulations demonstrate that the neural network can learn the highly nonlinear relationship among the variables, and the proposed method has the advantages of good real-time performance, excellent convergence and generalization ability.
In the proposed method, the main strategy can approximate the costate, warm-start the indirect method’s shooting and then drive the spacecraft to achieve optimal control in real time. Furthermore, a backup strategy can further improve the security of onboard algorithms. The method of integrating advanced artificial intelligence algorithms into the traditional optimal control theory provides a novel idea for solving the OCP. Future research considers introducing more complex constraints to the dynamics model to verify the effectiveness of the proposed method. In addition, a nondimensionalized method and backward integration method can be used to accelerate the generation of a training dataset, and more elaborate network structures can be adopted to enhance the accuracy of the algorithm.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}