
Research on Dual-Arm Control of Lunar Assisted Robot Based on Hierarchical Reinforcement Learning under Unstructured Environment

Abstract
:1. Introduction
2. Hierarchical Reinforcement Learning
2.1. Multi-Objective Markov Decision Process
2.2. Multi-Objective Hierarchical Reinforcement Learning
3. Methodology
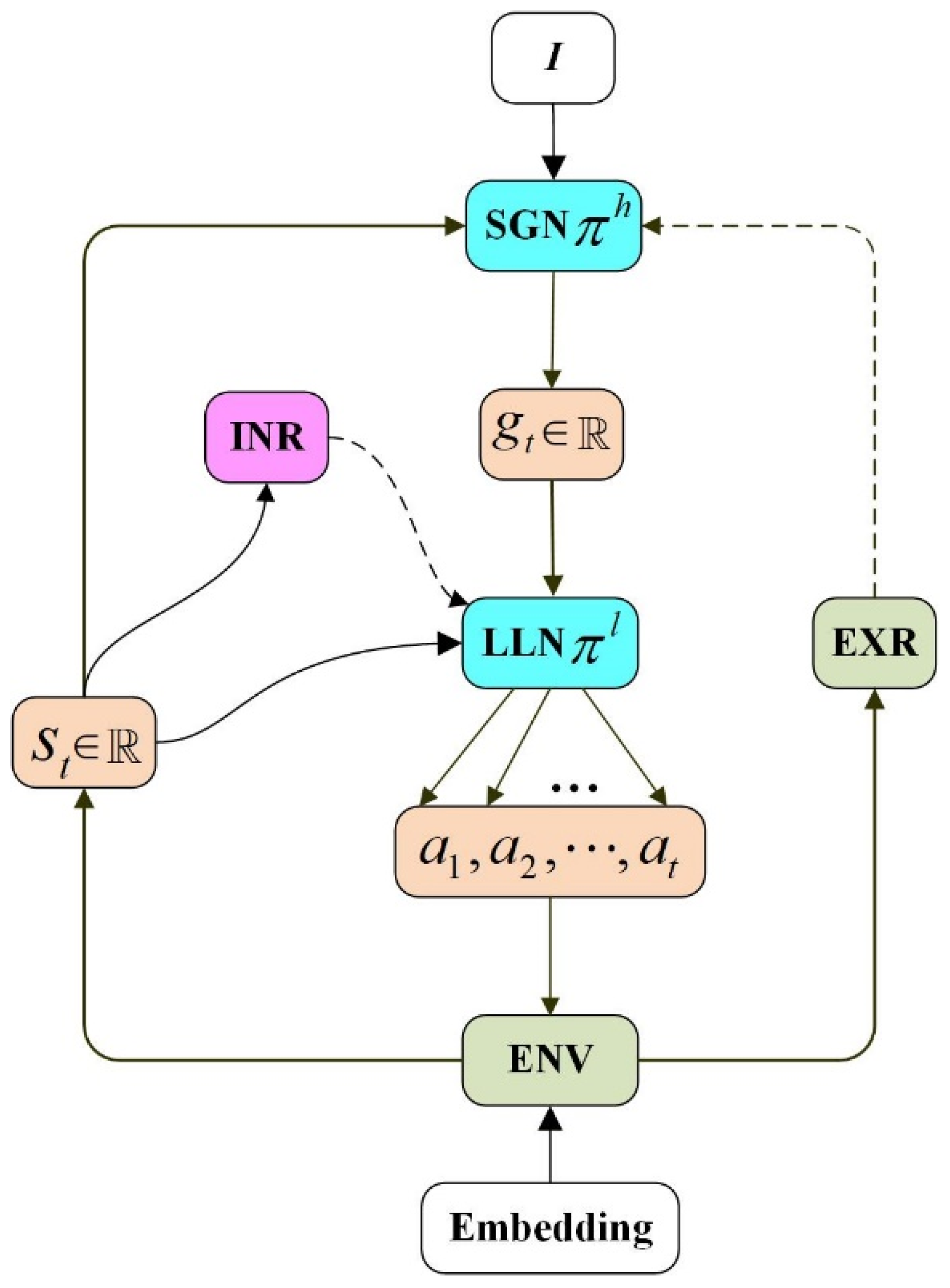
3.1. Network Framework
3.2. Reward Functions
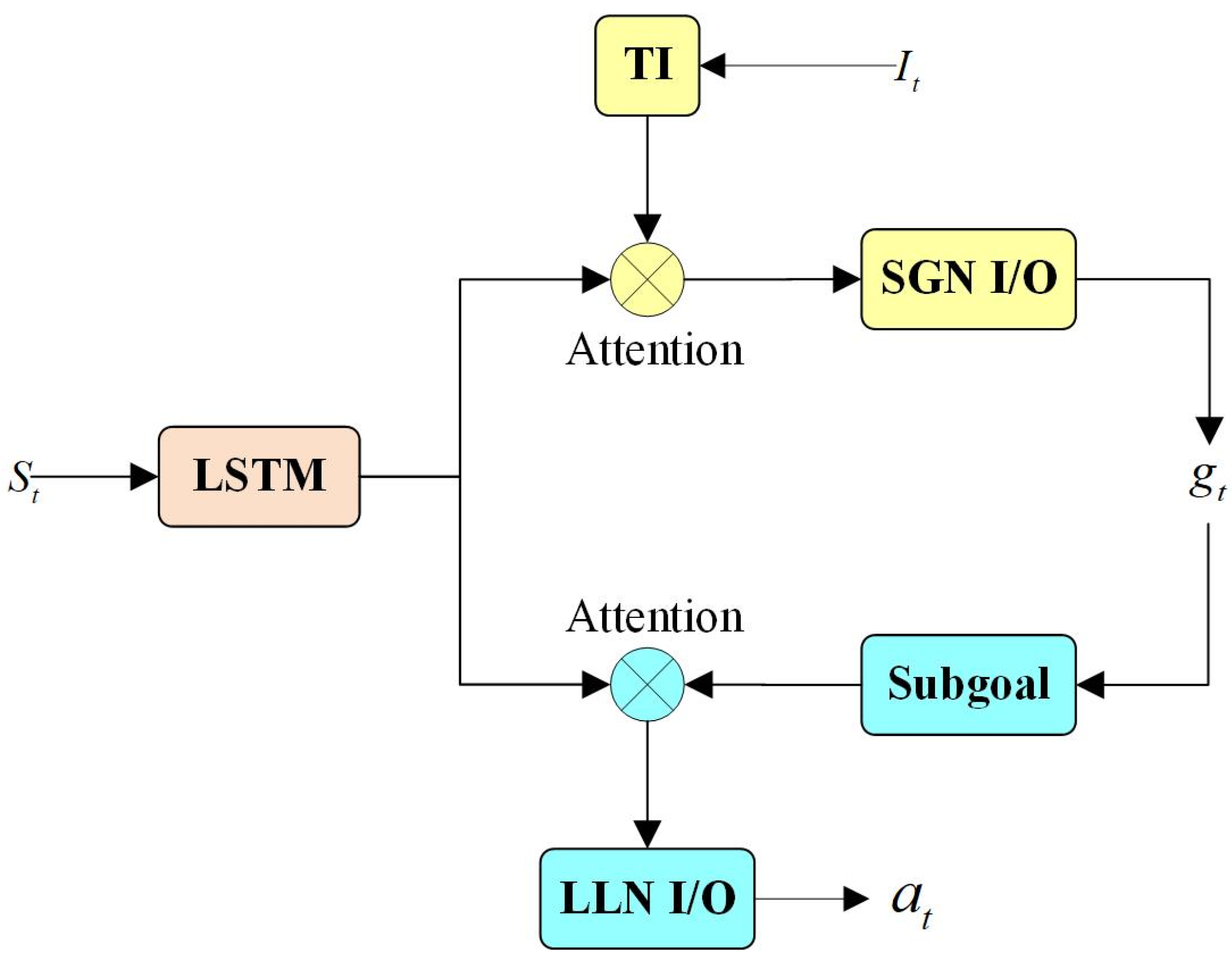
3.3. Network Structure
4. Experiments
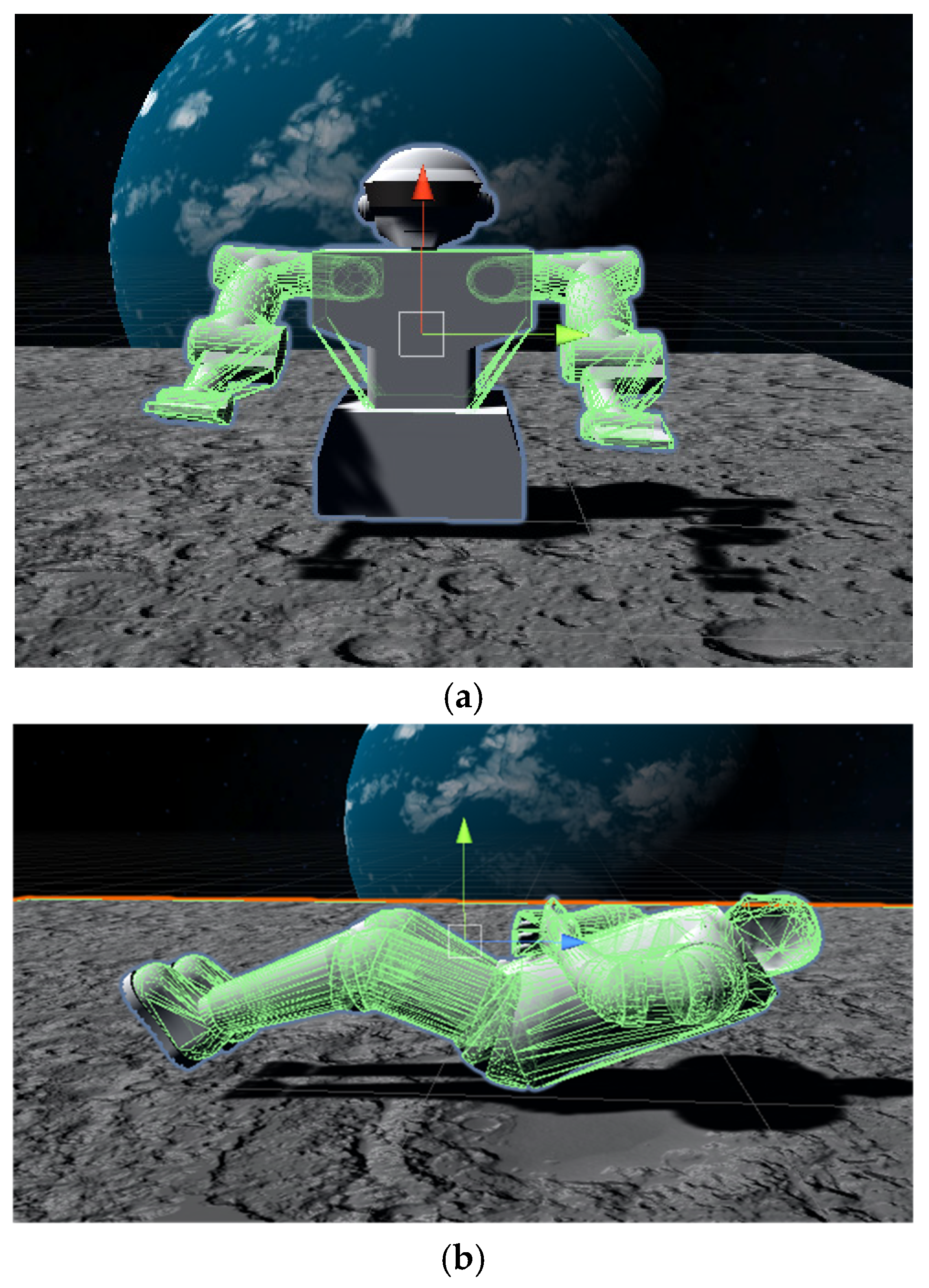
4.1. Experimental Setup
4.2. Evaluation Indicators
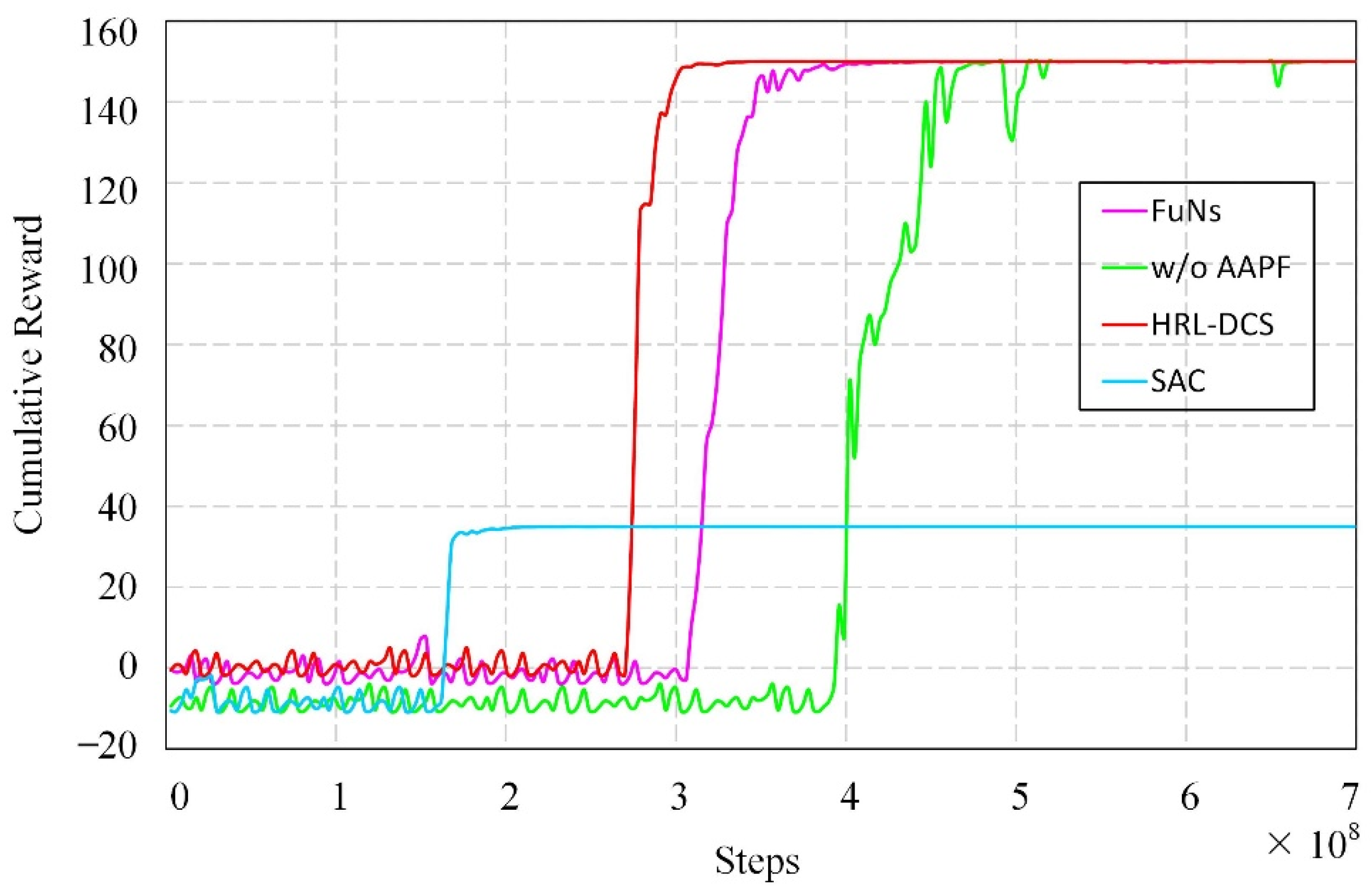
4.3. Comparative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hu, R.; Wang, Z.; Zhang, Y. A Lunar Robot Obstacle Avoidance Planning Method Using Deep Reinforcement Learning for Data Fusion. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 5365–5370. [Google Scholar]
- Izzo, D.; Märtens, M.; Pan, B. A survey on artificial intelligence trends in spacecraft guidance dynamics and control. Astrodynamics 2019, 3, 287–299. [Google Scholar] [CrossRef]
- Tang, G.; Hauser, K. A data-driven indirect method for nonlinear optimal control. Astrodynamics 2019, 3, 345–359. [Google Scholar] [CrossRef]
- Zhang, L.; Li, S.; Xiong, H.; Diao, X.; Ma, O.; Wang, Z. Prediction of Intentions Behind a Single Human Action: An Application of Convolutional Neural Network. In Proceedings of the 2019 IEEE 9th Annual International Conference on CYBER Technology in Automation, Control, and In-telligent Systems (CYBER), Suzhou, China, 29 July–2 August 2019; pp. 670–676. [Google Scholar]
- Nguyen-Tuong, D.; Peters, J. Model learning for robot control: A survey. Cogn. Processing 2011, 12, 319–340. [Google Scholar] [CrossRef] [PubMed]
- Shirobokov, M.; Trofimov, S.; Ovchinnikov, M. Survey of machine learning techniques in spacecraft control design. Acta Astronaut. 2021, 186, 87–97. [Google Scholar] [CrossRef]
- Li, Y.; Li, D.; Zhu, W.; Sun, J.; Zhang, X.; Li, S. Constrained Motion Planning of 7-DOF Space Manipulator via Deep Reinforcement Learning Combined with Artificial Potential Field. Aerospace 2022, 9, 163. [Google Scholar] [CrossRef]
- Dong, G.; Zhu, Z.H. Incremental visual servo control of robotic manipulator for autonomous capture of non-cooperative target. Adv. Robot. 2016, 30, 1458–1465. [Google Scholar] [CrossRef]
- Beltran-Hernandez, C.C.; Petit, D.; Ramirez-Alpizar, I.G.; Nishi, T.; Kikuchi, S.; Matsubara, T.; Harada, K. Learning force control for contact-rich manipulation tasks with rigid position-controlled robots. IEEE Robot. Autom. Lett. 2020, 5, 5709–5716. [Google Scholar] [CrossRef]
- Xiong, H.; Ma, T.; Zhang, L.; Diao, X. Comparison of end-to-end and hybrid deep reinforcement learning strategies for controlling cable-driven parallel robots. Neurocomputing 2020, 377, 73–84. [Google Scholar] [CrossRef]
- Shahid, A.A.; Roveda, L.; Piga, D.; Braghin, F. Learning Continuous Control Actions for Robotic Grasping with Reinforcement Learning. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020. [Google Scholar]
- Prianto, E.; Kim, M.S.; Park, J.H.; Bae, J.H.; Kim, J.S. Path Planning for Multi-Arm Manipulators Using Deep Reinforcement Learning: Soft Actor–Critic with Hindsight Experience Replay. Sensors 2020, 20, 5911. [Google Scholar] [CrossRef]
- Dong, G.; Zhu, Z.H. Predictive visual servo kinematic control for autonomous robotic capture of non-cooperative space target. Acta Astronaut. 2018, 151, 173–181. [Google Scholar] [CrossRef]
- Ota, K.; Jha, D.K.; Oiki, T.; Miura, M.; Mariyama, T. Trajectory Optimization for Unknown Constrained Systems using Reinforcement Learning. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019. [Google Scholar]
- Moghaddam, B.M.; Chhabra, R. On the guidance, navigation and control of in-orbit space robotic missions: A survey and prospective vision. Acta Astronaut. 2021, 184, 70–100. [Google Scholar] [CrossRef]
- Ren, W.; Ma, O.; Ji, H.; Liu, X. Human Posture Recognition Using a Hybrid of Fuzzy Logic and Machine Learning Approaches. IEEE Access 2020, 8, 135628–135639. [Google Scholar] [CrossRef]
- Rui, Z.; Zhaokui, W.; Yulin, Z. A person-following nanosatellite for in-cabin astronaut assistance: System design and deep-learning-based astronaut visual tracking implementation. Acta Astronaut. 2019, 162, 121–134. [Google Scholar] [CrossRef]
- Lingyun, G.; Lin, Z.; Zhaokui, W. Hierarchical Attention-Based Astronaut Gesture Recognition: A Dataset and CNN Model. IEEE Access 2020, 8, 68787–68798. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Time (h) | # of Tests | Accuracy (%) |
|---|---|---|---|
| Soft Actor-Critic | — | 1000 | — |
| FeUdal Networks | 67 | 1000 | 91.8 |
| HRL-DCS-w/oAAPF | 86 | 1000 | 87.3 |
| HRL-DCS | 59 | 1000 | 98.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, W.; Han, D.; Wang, Z. Research on Dual-Arm Control of Lunar Assisted Robot Based on Hierarchical Reinforcement Learning under Unstructured Environment. Aerospace 2022, 9, 315. https://doi.org/10.3390/aerospace9060315
Ren W, Han D, Wang Z. Research on Dual-Arm Control of Lunar Assisted Robot Based on Hierarchical Reinforcement Learning under Unstructured Environment. Aerospace. 2022; 9(6):315. https://doi.org/10.3390/aerospace9060315
Chicago/Turabian StyleRen, Weiyan, Dapeng Han, and Zhaokui Wang. 2022. "Research on Dual-Arm Control of Lunar Assisted Robot Based on Hierarchical Reinforcement Learning under Unstructured Environment" Aerospace 9, no. 6: 315. https://doi.org/10.3390/aerospace9060315