
Kiwi Plant Canker Diagnosis Using Hyperspectral Signal Processing and Machine Learning: Detecting Symptoms Caused by Pseudomonas syringae pv. actinidiae

 , , ,
, , ,  , and
, and 
Abstract
:1. Introduction
2. Results
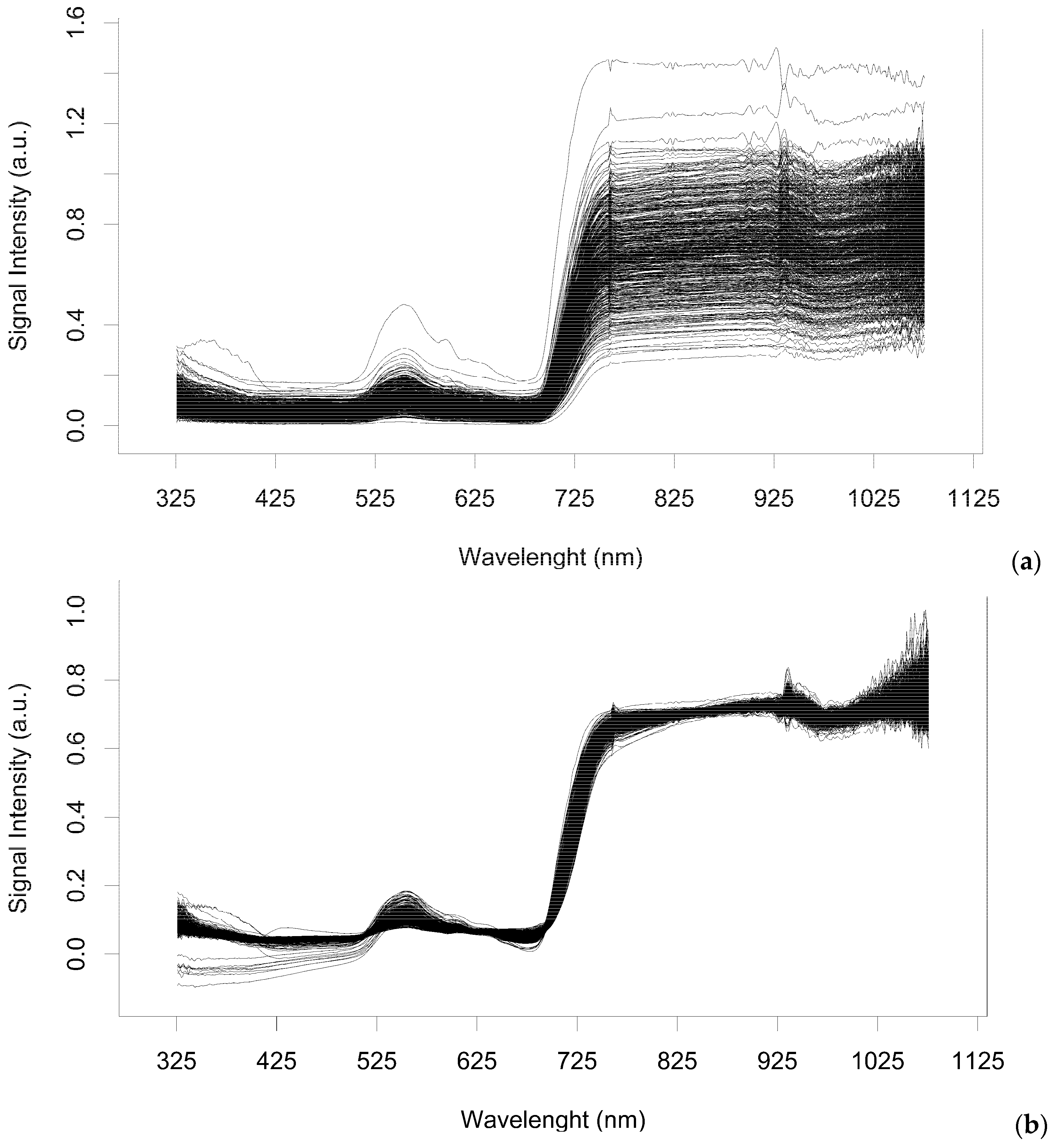
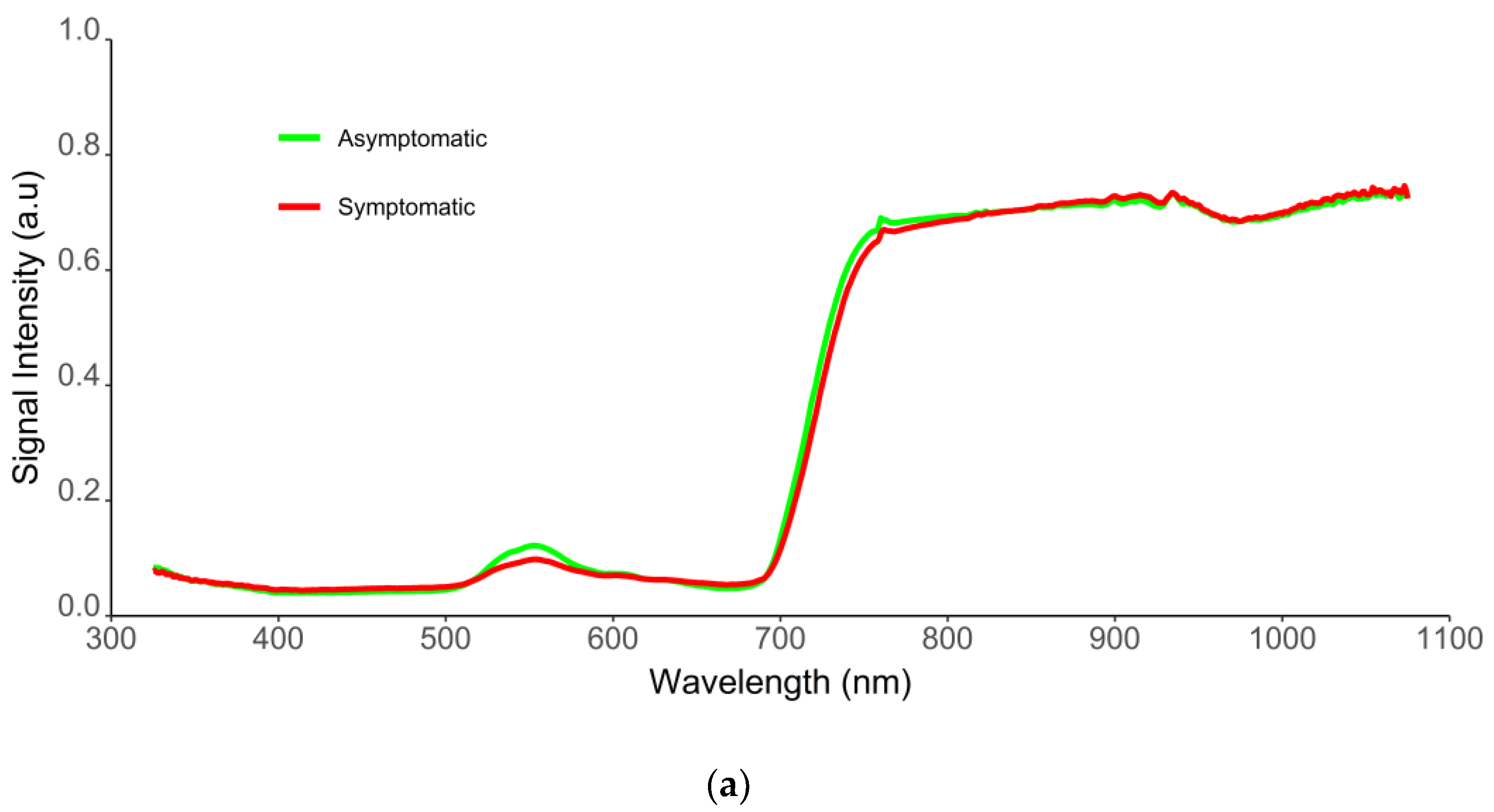
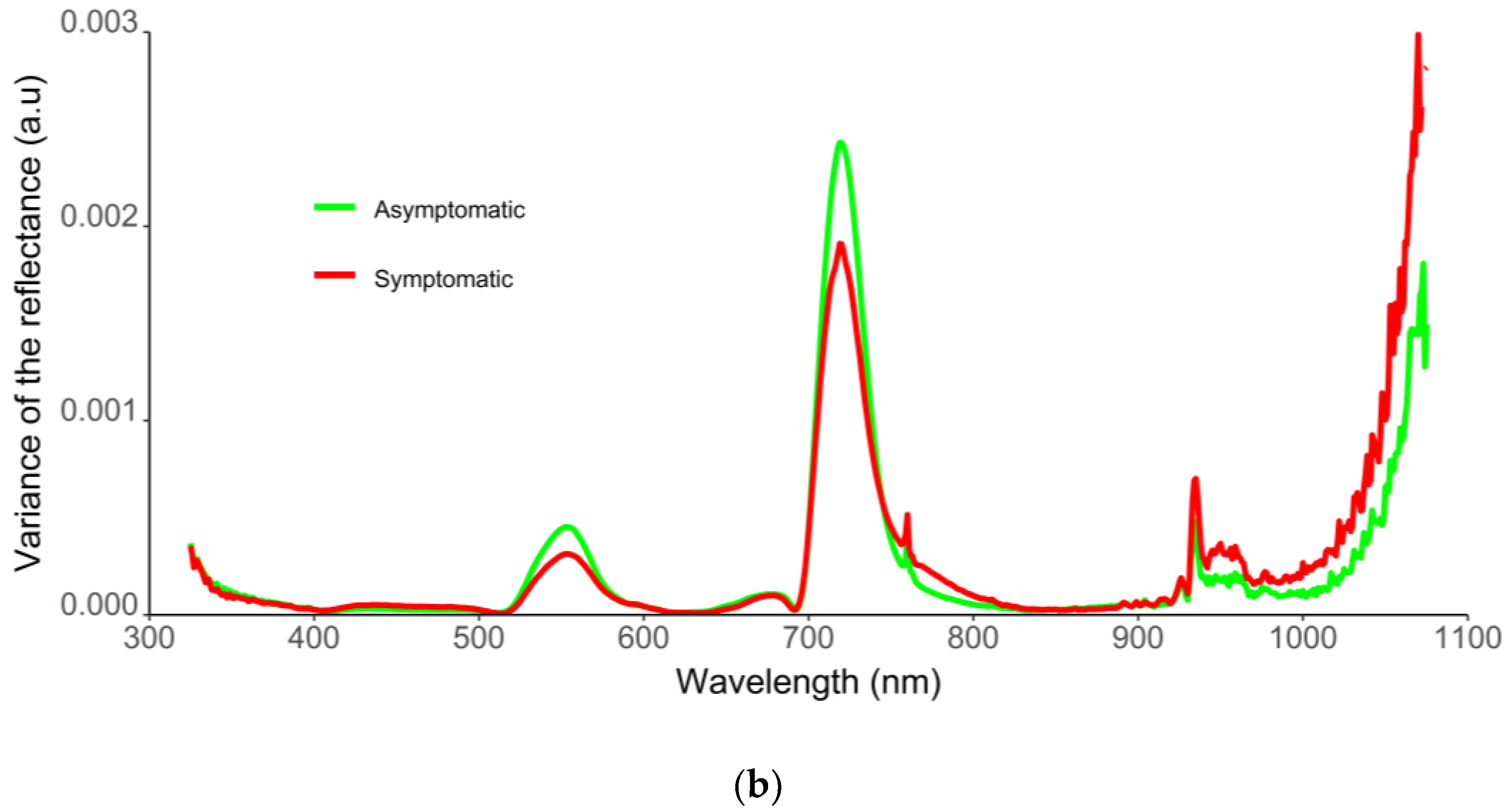
2.1. Spectra Filtering and Feature Selection
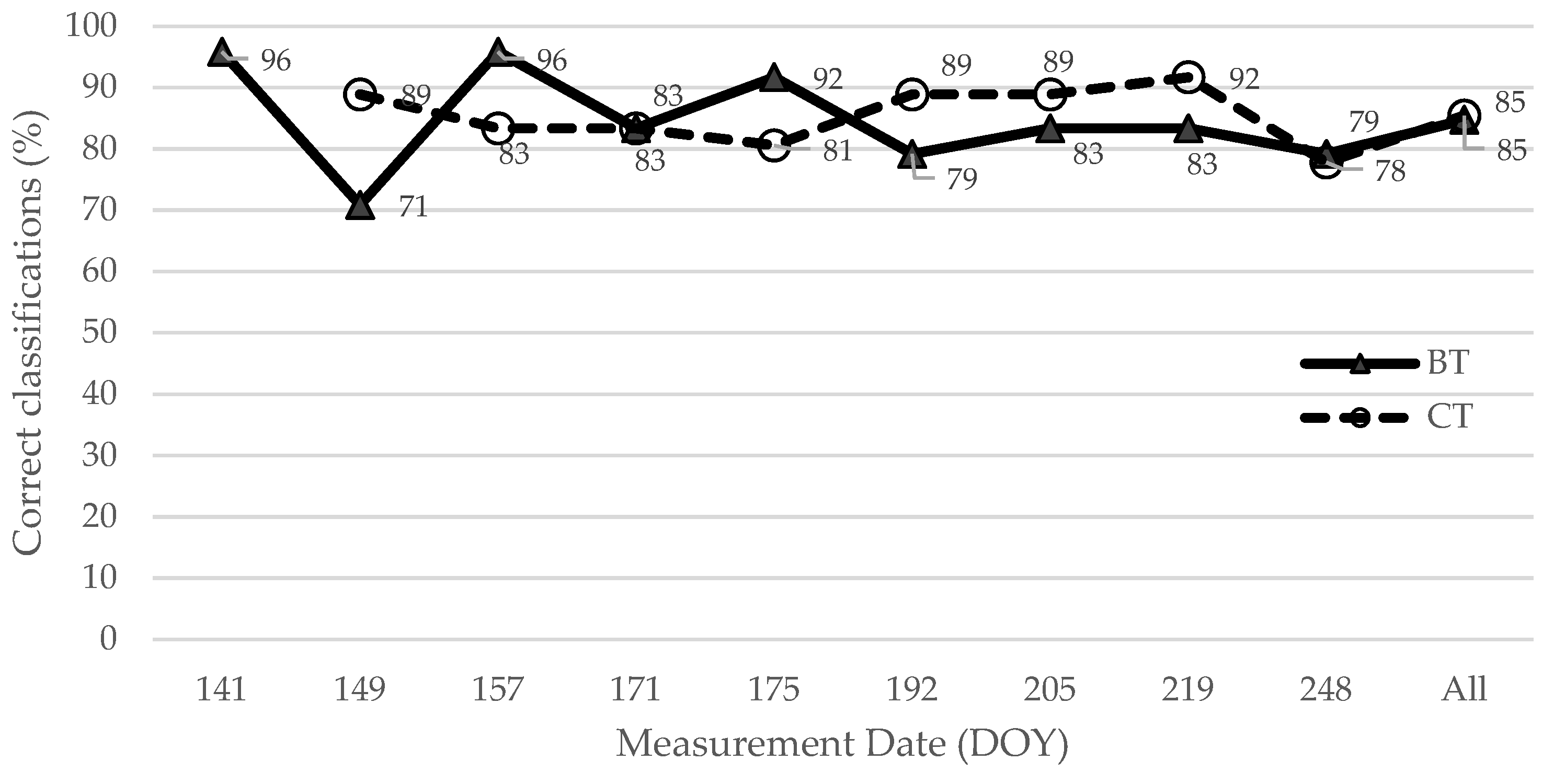
2.2. Model Discrimination of Psa Leaf Symptoms
3. Discussion
4. Materials and Methods
4.1. Study Area
4.2. Spectral Reflectance Acquisition through Ground Measurements
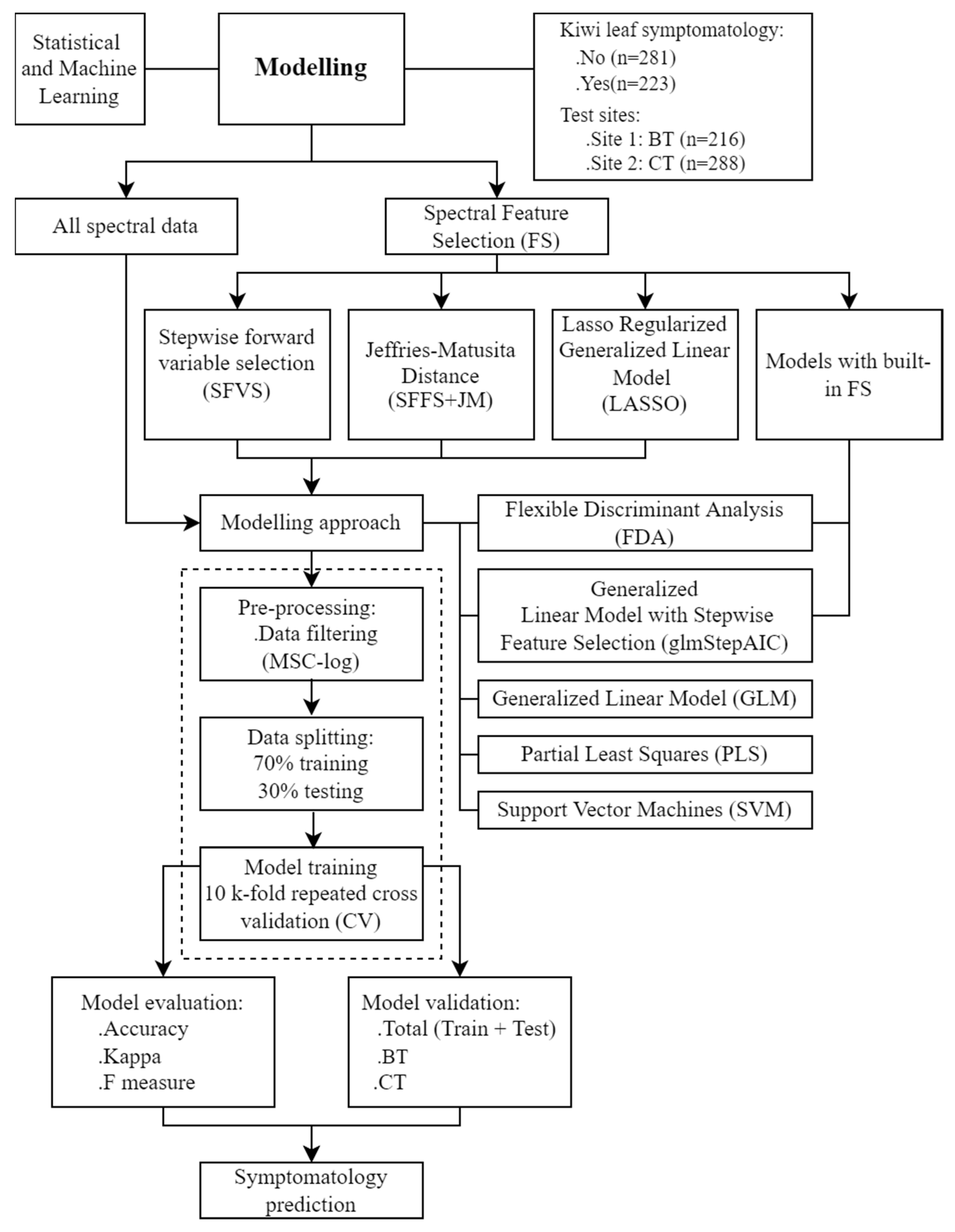
4.3. Modelling Approaches
4.3.1. Feature Selection
Sequential Forward Floating Selection Search Strategy and the Jeffries–Matusita (SFFS + JM) Distance
Stepwise Forward Variable Selection Method Using Wilk’s Lambda Criterion (SFVS)
Lasso Regularized Generalized Linear Models (LASSO)
4.3.2. Predictive Modeling in Classification Mode
Flexible Discriminant Analysis (FDA)
Generalized Linear Model (GLM)
Partial Least Squares (PLS) Classification
Support Vector Machines (SVM)
Model Development and Selection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Scortichini, M.; Marcelletti, S.; Ferrante, P.; Petriccione, M.; Firrao, G. Pseudomonas syringae pv. actinidiae: A re-emerging, multi-faceted, pandemic pathogen. Mol. Plant Pathol. 2012, 13, 231–240. [Google Scholar]
- Kim, G.H.; Kim, K.H.; Son, K.I.; Choi, E.D.; Lee, Y.S.; Jung, J.S.; Koh, Y.J. Outbreak and Spread of Bacterial Canker of Kiwifruit Caused by Pseudomonas syringae pv. actinidiae Biovar 3 in Korea. Plant Pathol. J. 2016, 32, 545–551. [Google Scholar] [CrossRef] [PubMed]
- Vanneste, J. Recent progress on detecting understanding and controlling Pseudomonas syringae pv actinidiae a short review. N. Z. Plant Prot. 2013, 66, 170–177. [Google Scholar] [CrossRef]
- Balestra, G.; Mazzaglia, A.; Quattrucci, A.; Renzi, M.; Rossetti, A. Current status of bacterial canker spread on kiwifruit in Italy. Australas. Plant Dis. Notes 2009, 4, 34–36. [Google Scholar]
- Saavedra, J.; Abud, C.; Cuevas, R.; Gonzalez, P. Impact of plastic covers on the progression of Pseudomonas syringae pv. actinidiae and fruit productivity in a yellow-kiwifruit orchard. Ix Int. Symp. Kiwifruit 2018, 1218, 341–345. [Google Scholar] [CrossRef]
- Donati, I.; Cellini, A.; Buriani, G.; Mauri, S.; Kay, C.; Tacconi, G.; Spinelli, F. Pathways of flower infection and pollen-mediated dispersion of Pseudomonas syringae pv. actinidiae, the causal agent of kiwifruit bacterial canker. Hortic Res-Engl. 2018, 5, 56. [Google Scholar] [CrossRef]
- Donati, I.; Cellini, A.; Sangiorgio, D.; Vanneste, J.L.; Scortichini, M.; Balestra, G.M.; Spinelli, F. Pseudomonas syringae pv. actinidiae: Ecology, Infection Dynamics and Disease Epidemiology. Microb. Ecol. 2020, 80, 81–102. [Google Scholar] [CrossRef]
- Lowe, A.; Harrison, N.; French, A.P. Hyperspectral image analysis techniques for the detection and classification of the early onset of plant disease and stress. Plant Methods 2017, 13, 80. [Google Scholar] [CrossRef]
- Parker, S.R.; Shaw, M.W.; Royle, D.J. The reliability of visual estimates of disease severity on cereal leaves. Plant Pathol. 1995, 44, 856–864. [Google Scholar] [CrossRef]
- Ali, M.M.; Bachik, N.A.; Muhadi, N.A.; Yusof, T.N.T.; Gomes, C. Non-destructive techniques of detecting plant diseases: A review. Physiol. Mol. Plant Pathol. 2019, 108, 101426. [Google Scholar] [CrossRef]
- Mahlein, A.K. Plant Disease Detection by Imaging Sensors—Parallels and Specific Demands for Precision Agriculture and Plant Phenotyping. Plant Dis. 2016, 100, 241–251. [Google Scholar] [CrossRef]
- Sankaran, S.; Mishra, A.; Ehsani, R.; Davis, C. A review of advanced techniques for detecting plant diseases. Comput. Electron. Agric. 2010, 72, 1–13. [Google Scholar] [CrossRef]
- Khaled, A.Y.; Abd Aziz, S.; Bejo, S.K.; Nawi, N.M.; Abu Seman, I.; Onwude, D.I. Early detection of diseases in plant tissue using spectroscopy—Applications and limitations. Appl. Spectrosc. Rev. 2018, 53, 36–64. [Google Scholar] [CrossRef]
- Fang, Y.; Ramasamy, R.P. Current and Prospective Methods for Plant Disease Detection. Biosensors 2015, 5, 537–561. [Google Scholar] [CrossRef] [PubMed]
- Martinelli, F.; Scalenghe, R.; Davino, S.; Panno, S.; Scuderi, G.; Ruisi, P.; Villa, P.; Stroppiana, D.; Boschetti, M.; Goulart, L.R.; et al. Advanced methods of plant disease detection. A review. Agron. Sustain. Dev. 2015, 35, 1–25. [Google Scholar] [CrossRef]
- Zhang, N.; Yang, G.J.; Pan, Y.C.; Yang, X.D.; Chen, L.P.; Zhao, C.J. A Review of Advanced Technologies and Development for Hyperspectral-Based Plant Disease Detection in the Past Three Decades. Remote Sens. 2020, 12, 3188. [Google Scholar] [CrossRef]
- Golhani, K.; Balasundram, S.K.; Vadamalai, G.; Pradhan, B. A review of neural networks in plant disease detection using hyperspectral data. Inf. Process. Agric. 2018, 5, 354–371. [Google Scholar] [CrossRef]
- Delalieux, S.; van Aardt, J.; Keulemans, W.; Schrevens, E.; Coppin, P. Detection of biotic stress (Venturia inaequalis) in apple trees using hyperspectral data: Non-parametric statistical approaches and physiological implications. Eur. J. Agron. 2007, 27, 130–143. [Google Scholar] [CrossRef]
- Blackburn, G.A.; Ferwerda, J.G. Retrieval of chlorophyll concentration from leaf reflectance spectra using wavelet analysis. Remote Sens. Environ. 2008, 112, 1614–1632. [Google Scholar] [CrossRef]
- Thenkabail, P.S.; Smith, R.B.; De Pauw, E. Hyperspectral vegetation indices and their relationships with agricultural crop characteristics. Remote Sens. Environ. 2000, 71, 158–182. [Google Scholar] [CrossRef]
- Martins, R.C.; Barroso, T.G.; Jorge, P.; Cunha, M.; Santos, F. Unscrambling spectral interference and matrix effects in Vitis vinifera Vis-NIR spectroscopy: Towards analytical grade ‘in vivo’ sugars and acids quantification. Comput. Electron. Agric. 2022, 194, 106710. [Google Scholar] [CrossRef]
- Monteiro-Silva, F.; Jorge, P.A.S.; Martins, R.C. Optical Sensing of Nitrogen, Phosphorus and Potassium: A Spectrophotometrical Approach toward Smart Nutrient Deployment. Chemosensors 2019, 7, 51. [Google Scholar] [CrossRef]
- Zhang, J.C.; Wang, N.; Yuan, L.; Chen, F.N.; Wu, K.H. Discrimination of winter wheat disease and insect stresses using continuous wavelet features extracted from foliar spectral measurements. Biosyst. Eng. 2017, 162, 20–29. [Google Scholar] [CrossRef]
- Herrmann, I.; Berenstein, M.; Paz-Kagan, T.; Sade, A.; Karnieli, A. Spectral assessment of two-spotted spider mite damage levels in the leaves of greenhouse-grown pepper and bean. Biosyst. Eng. 2017, 157, 72–85. [Google Scholar] [CrossRef]
- Yu, K.; Anderegg, J.; Mikaberidze, A.; Karisto, P.; Mascher, F.; McDonald, B.A.; Walter, A.; Hund, A. Hyperspectral Canopy Sensing of Wheat Septoria Tritici Blotch Disease. Front. Plant Sci. 2018, 9, 1195. [Google Scholar] [CrossRef]
- Skoneczny, H.; Kubiak, K.; Spiralski, M.; Kotlarz, J. Fire Blight Disease Detection for Apple Trees: Hyperspectral Analysis of Healthy, Infected and Dry Leaves. Remote Sens. 2020, 12, 2101. [Google Scholar] [CrossRef]
- Bagheri, N.; Mohamadi-Monavar, H.; Azizi, A.; Ghasemi, A. Detection of Fire Blight disease in pear trees by hyperspectral data. Eur. J. Remote Sens. 2018, 51, 1–10. [Google Scholar] [CrossRef]
- Morellos, A.; Tziotzios, G.; Orfanidou, C.; Pantazi, X.E.; Sarantaris, C.; Maliogka, V.; Alexandridis, T.K.; Moshou, D. Non-Destructive Early Detection and Quantitative Severity Stage Classification of Tomato Chlorosis Virus (ToCV) Infection in Young Tomato Plants Using Vis–NIR Spectroscopy. Remote Sens. 2020, 12, 1920. [Google Scholar] [CrossRef]
- Gold, K.M.; Townsend, P.A.; Chlus, A.; Herrmann, I.; Couture, J.J.; Larson, E.R.; Gevens, A.J. Hyperspectral Measurements Enable Pre-Symptomatic Detection and Differentiation of Contrasting Physiological Effects of Late Blight and Early Blight in Potato. Remote Sens. 2020, 12, 286. [Google Scholar] [CrossRef]
- Curran, P.J. Remote-Sensing of Foliar Chemistry. Remote Sens. Environ. 1989, 30, 271–278. [Google Scholar] [CrossRef]
- Tosin, R.; Pocas, I.; Novo, H.; Teixeira, J.; Fontes, N.; Graca, A.; Cunha, M. Assessing predawn leaf water potential based on hyperspectral data and pigment’s concentration of Vitis vinifera L. in the Douro Wine Region. Sci. Hortic-Amst. 2021, 278, 109860. [Google Scholar] [CrossRef]
- Thenkabail, P.S.; Gumma, M.K.; Teluguntla, P.; Mohammed, I.A. Hyperspectral Remote Sensing of Vegetation and Agricultural Crops. Photogramm. Eng. Remote Sens. 2014, 80, 697–709. [Google Scholar]
- Tosin, R.; Martins, R.; Pôças, I.; Cunha, M. Canopy VIS-NIR spectroscopy and self-learning artificial intelligence for a generalised model of predawn leaf water potential in Vitis vinifera. Biosyst. Eng. 2022, 219, 235–258. [Google Scholar] [CrossRef]
- Hunt, E.R.; Rock, B.N. Detection of changes in leaf water content using Near- and Middle-Infrared reflectances. Remote Sens. Environ. 1989, 30, 43–54. [Google Scholar]
- Jones, H.G.; Vaughan, R.A. Remote Sensing of Vegetation: Principles, Techniques, and Applications; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Martins, R.C. Unscrambling Complex Sample Composition, Variability and Multi-scale Interference in Optical Spectroscopy. Proc. Spie 2019, 11207, 448–453. [Google Scholar] [CrossRef]
- Blackburn, G.A. Hyperspectral remote sensing of plant pigments. J. Exp. Bot. 2007, 58, 855–867. [Google Scholar] [CrossRef]
- Caicedo, J.P.R.; Verrelst, J.; Muñoz-Marí, J.; Moreno, J.; Camps-Valls, G. Toward a semiautomatic machine learning retrieval of biophysical parameters. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1249–1259. [Google Scholar] [CrossRef]
- Rivera, J.P.; Verrelst, J.; Delegido, J.; Veroustraete, F.; Moreno, J. On the semi-automatic retrieval of biophysical parameters based on spectral index optimization. Remote Sens. 2014, 6, 4927–4951. [Google Scholar] [CrossRef]
- Saleem, M.H.; Potgieter, J.; Mahmood Arif, K. Plant Disease Detection and Classification by Deep Learning. Plants 2019, 8, 468. [Google Scholar] [CrossRef]
- Mahlein, A.K.; Rumpf, T.; Welke, P.; Dehne, H.W.; Plümer, L.; Steiner, U.; Oerke, E.C. Development of spectral indices for detecting and identifying plant diseases. Remote Sens. Environ. 2013, 128, 21–30. [Google Scholar] [CrossRef]
- Mahlein, A.K.; Steiner, U.; Dehne, H.W.; Oerke, E.C. Spectral signatures of sugar beet leaves for the detection and differentiation of diseases. Precis. Agric. 2010, 11, 413–431. [Google Scholar] [CrossRef]
- Thenkabail, P.S.; Lyon, J.G.; Huete, A. Hyperspectral Indices and Image Classifications for Agriculture and Vegetation; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Ahmadi, P.; Muharam, F.M.; Ahmad, K.; Mansor, S.; Abu Seman, I. Early Detection of Ganoderma Basal Stem Rot of Oil Palms Using Artificial Neural Network Spectral Analysis. Plant Dis. 2017, 101, 1009–1016. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Fang, Y.; Chu, G.; Yan, H.; Hu, L.; Huang, L. Identification of Leaf-Scale Wheat Powdery Mildew (Blumeria graminis f. sp. Tritici) Combining Hyperspectral Imaging and an SVM Classifier. Plants 2020, 9, 936. [Google Scholar] [CrossRef] [PubMed]
- Saha, D.; Manickavasagan, A. Machine learning techniques for analysis of hyperspectral images to determine quality of food products: A review. Curr. Res. Food Sci. 2021, 4, 28–44. [Google Scholar] [CrossRef] [PubMed]
- Sankaran, S.; Ehsani, R.; Inch, S.A.; Ploetz, R.C. Evaluation of visible-near infrared reflectance spectra of avocado leaves as a non-destructive sensing tool for detection of laurel wilt. Plant Dis. 2012, 96, 1683–1689. [Google Scholar] [CrossRef]
- Bajwa, S.G.; Rupe, J.C.; Mason, J. Soybean Disease Monitoring with Leaf Reflectance. Remote Sens. 2017, 9, 127. [Google Scholar] [CrossRef]
- Meng, R.; Lv, Z.; Yan, J.; Chen, G.; Zhao, F.; Zeng, L.; Xu, B. Development of spectral disease indices for southern corn rust detection and severity classification. Remote Sens. 2020, 12, 3233. [Google Scholar] [CrossRef]
- Gold, K.M.; Townsend, P.A.; Herrmann, I.; Gevens, A.J. Investigating potato late blight physiological differences across potato cultivars with spectroscopy and machine learning. Plant Sci. 2020, 295, 110316. [Google Scholar] [CrossRef]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. In Encyclopedia of Database Systems; Liu, L., ÖZsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 532–538. [Google Scholar]
- Krstajic, D.; Buturovic, L.J.; Leahy, D.E.; Thomas, S. Cross-validation pitfalls when selecting and assessing regression and classification models. J. Cheminform. 2014, 6, 10. [Google Scholar] [CrossRef]
- Mariotto, I.; Thenkabail, P.S.; Huete, A.; Slonecker, E.T.; Platonov, A. Hyperspectral versus multispectral crop-productivity modeling and type discrimination for the HyspIRI mission. Remote Sens. Environ. 2013, 139, 291–305. [Google Scholar] [CrossRef]
- Naidu, R.A.; Perry, E.M.; Pierce, F.J.; Mekuria, T. The potential of spectral reflectance technique for the detection of Grapevine leafroll-associated virus-3 in two red-berried wine grape cultivars. Comput. Electron. Agric. 2009, 66, 38–45. [Google Scholar] [CrossRef]
- Junges, A.H.; Almança, M.A.K.; Fajardo, T.V.M.; Ducati, J.R. Leaf hyperspectral reflectance as a potential tool to detect diseases associated with vineyard decline. Trop. Plant Pathol. 2020, 45, 522–533. [Google Scholar] [CrossRef]
- Ashourloo, D.; Mobasheri, M.R.; Huete, A. Developing Two Spectral Disease Indices for Detection of Wheat Leaf Rust (Pucciniatriticina). Remote Sens. 2014, 6, 4723–4740. [Google Scholar] [CrossRef]
- Wu, D.; Cao, F.; Zhang, H.; Feng, L.; He, Y. Study on disease level classification of rice panicle blast based on visible and near infrared spectroscopy. Spectrosc. Spectr. Anal. 2009, 29, 3295–3299. [Google Scholar]
- Verrelst, J.; Rivera, J.P.; Veroustraete, F.; Muñoz-Marí, J.; Clevers, J.G.P.W.; Camps-Valls, G.; Moreno, J. Experimental Sentinel-2 LAI estimation using parametric, non-parametric and physical retrieval methods—A comparison. ISPRS J. Photogramm. Remote Sens. 2015, 108, 260–272. [Google Scholar] [CrossRef]
- Hatfield, J.L.; Prueger, J.H.; Sauer, T.J.; Dold, C.; O’Brien, P.; Wacha, K. Applications of Vegetative Indices from Remote Sensing to Agriculture: Past and Future. Inventions 2019, 4, 71. [Google Scholar] [CrossRef]
- Xue, J.R.; Su, B.F. Significant Remote Sensing Vegetation Indices: A Review of Developments and Applications. J. Sens. 2017, 1353691. [Google Scholar] [CrossRef]
- Morcillo-Pallares, P.; Rivera-Caicedo, J.P.; Belda, S.; De Grave, C.; Burriel, H.; Moreno, J.; Verrelst, J. Quantifying the Robustness of Vegetation Indices through Global Sensitivity Analysis of Homogeneous and Forest Leaf-Canopy Radiative Transfer Models. Remote Sens. 2019, 11, 2418. [Google Scholar] [CrossRef]
- Luts, J.; Ojeda, F.; Van de Plas, R.; De Moor, B.; Van Huffel, S.; Suykens, J.A.K. A tutorial on support vector machine-based methods for classification problems in chemometrics. Anal. Chim. Acta 2010, 665, 129–145. [Google Scholar] [CrossRef]
- Lu, J.; Ehsani, R.; Shi, Y.; Abdulridha, J.; de Castro, A.I.; Xu, Y. Field detection of anthracnose crown rot in strawberry using spectroscopy technology. Comput. Electron. Agric. 2017, 135, 289–299. [Google Scholar] [CrossRef]
- Huang, L.S.; Ding, W.J.; Liu, W.J.; Zhao, J.L.; Huang, W.J.; Xu, C.; Zhang, D.Y.; Liang, D. Identification of wheat powdery mildew using in-situ hyperspectral data and linear regression and support vector machines. J. Plant Pathol. 2019, 101, 1035–1045. [Google Scholar] [CrossRef]
- Penuelas, J.; Filella, I. Visible and near-infrared reflectance techniques for diagnosing plant physiological status. Trends Plant Sci. 1998, 3, 151–156. [Google Scholar] [CrossRef]
- Asner, G.P. Biophysical and Biochemical Sources of Variability in Canopy Reflectance. Remote Sens. Environ. 1998, 64, 234–253. [Google Scholar] [CrossRef]
- Pudil, P.; Novovičová, J.; Kittler, J. Floating search methods in feature selection. Pattern Recognit. Lett. 1994, 15, 1119–1125. [Google Scholar] [CrossRef]
- Richards, J.A.; Richards, J. Remote Sensing Digital Image Analysis; Springer: Berlin/Heidelberg, Germany, 1999; Volume 3. [Google Scholar]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Tree species classification in the Southern Alps based on the fusion of very high geometrical resolution multispectral/hyperspectral images and LiDAR data. Remote Sens. Environ. 2012, 123, 258–270. [Google Scholar] [CrossRef]
- Laliberte, A.S.; Browning, D.; Rango, A. A comparison of three feature selection methods for object-based classification of sub-decimeter resolution UltraCam-L imagery. Int. J. Appl. Earth Obs. Geoinf. 2012, 15, 70–78. [Google Scholar] [CrossRef]
- El Ouardighi, A.; El Akadi, A.; Aboutajdine, D. Feature selection on supervised classification using Wilk’s Lambda statistic. In Proceedings of the 2007 International Symposium on Computational Intelligence and Intelligent Informatics, Agadir, Morocco, 4 June 2007. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R.; Narasimhan, B.; Tay, K.; Simon, N.; Qian, J. Package ‘Glmnet’. CRAN R Repository. 2021. Available online: https://cran.r-project.org/web/packages/glmnet/index.html (accessed on 1 July 2022).
- Hastie, T.; Qian, J. Glmnet Vignette. Available online: https://hastie.su.domains/Papers/Glmnet_Vignette.pdf (accessed on 23 June 2022).
- Kuhn, M. Caret: Classification and Regression Training. Astrophysics Source Code Library: Online, 2015. Available online: https://github.com/topepo/caret/ (accessed on 17 June 2022).
- Hastie, T.; Tibshirani, R.; Buja, A. Flexible discriminant analysis by optimal scoring. J. Am. Stat. Assoc. 1994, 89, 1255–1270. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- McCullagh, P.; Nelder, J.A. Generalized Linear Models; Routledge: London, UK, 2019. [Google Scholar]
- Ye, J.C.; Tak, S.; Jang, K.E.; Jung, J.; Jang, J. NIRS-SPM: Statistical parametric mapping for near-infrared spectroscopy. NeuroImage 2009, 44, 428–447. [Google Scholar] [CrossRef]
- Wold, S.; Sjöström, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemom. Intell. Lab. Syst. 2001, 58, 109–130. [Google Scholar] [CrossRef]
- Liu, Z.-y.; Huang, J.-f.; Shi, J.-j.; Tao, R.-x.; Zhou, W.; Zhang, L.-l. Characterizing and estimating rice brown spot disease severity using stepwise regression, principal component regression and partial least-square regression. J. Zhejiang Univ. Sci. B 2007, 8, 738–744. [Google Scholar] [CrossRef] [PubMed]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin, Germany, 1999. [Google Scholar]
- Mosavi, A.; Sajedi Hosseini, F.; Choubin, B.; Taromideh, F.; Ghodsi, M.; Nazari, B.; Dineva, A.A. Susceptibility mapping of groundwater salinity using machine learning models. Environ. Sci. Pollut. Res. 2021, 28, 10804–10817. [Google Scholar] [CrossRef]
- Ballabio, C.; Sterlacchini, S. Support vector machines for landslide susceptibility mapping: The Staffora River Basin case study, Italy. Math. Geosci. 2012, 44, 47–70. [Google Scholar] [CrossRef]
- Ding, X.; Liu, J.; Yang, F.; Cao, J. Random radial basis function kernel-based support vector machine. J. Frankl. Inst. 2021, 358, 10121–10140. [Google Scholar] [CrossRef]
- Patle, A.; Chouhan, D.S. SVM kernel functions for classification. In Proceedings of the 2013 International Conference on Advances in Technology and Engineering (ICATE), Mumbai, India, 23–25 January 2013; pp. 1–9. [Google Scholar]
- Xulei, Y.; Qing, S.; Cao, A. Weighted support vector machine for data classification. In Proceedings of the Proceedings 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 852, pp. 859–864. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; Volume 26. [Google Scholar]
- Lantz, B. Machine Learning with R: Expert Techniques for Predictive Modeling; Packt publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- Valier, A. The Cross Validation in Automated Valuation Models: A Proposal for Use. In Proceedings of the Computational Science and Its Applications—ICCSA 2020, Cagliari, Italy, 1–4 July 2020; pp. 585–596. [Google Scholar]
- Berrar, D. Cross-Validation. 2019. Available online: https://www.researchgate.net/profile/Daniel-Berrar/publication/324701535_Cross-Validation/links/5cb4209c92851c8d22ec4349/Cross-Validation.pdf (accessed on 1 July 2022).
- Team, R.C. R: A Language and Environment for Statistical Computing. 2021. Available online: https://cran.microsoft.com/snapshot/2014-09-08/web/packages/dplR/vignettes/xdate-dplR.pdf (accessed on 1 July 2022).
- Kuhn, M.; Johnson, K.; Kuhn, M.M.; CORElearn, I. Package ‘AppliedPredictiveModeling’. 2013. Available online: https://cran.revolutionanalytics.com/web/packages/AppliedPredictiveModeling/AppliedPredictiveModeling.pdf (accessed on 1 July 2022).
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F.; Chang, C.-C.; Lin, C.-C.; Meyer, M.D. Package ‘e1071′. R J. 2019. Available online: http://r.meteo.uni.wroc.pl/web/packages/e1071/e1071.pdf (accessed on 1 July 2022).
- Milborrow, M.S. Package ‘Earth’. R Softw. Package. 2019. Available online: http://cran-r.c3sl.ufpr.br/web/packages/earth/earth.pdf (accessed on 1 July 2022).
- Villanueva, R.A.M.; Chen, Z.J. ggplot2: Elegant Graphics for Data Analysis. Meas. Interdiscip. Res. Perspect. 2019, 17, 160–167. [Google Scholar] [CrossRef]
- Karatzoglou, A.; Smola, A.; Hornik, K.; Karatzoglou, M.A. Package ‘Kernlab’. CRAN R Proj. 2019. Available online: http://cran.rediris.es/web/packages/kernlab/kernlab.pdf (accessed on 1 July 2022).
- Roever, C.; Raabe, N.; Luebke, K.; Ligges, U.; Szepannek, G.; Zentgraf, M.; Ligges, M.U.; SVMlight, S. Package ‘klaR’. 2022. Available online: http://mirror.psu.ac.th/pub/cran/web/packages/klaR/klaR.pdf (accessed on 1 July 2022).
- Ripley, B.; Venables, B.; Bates, D.M.; Hornik, K.; Gebhardt, A.; Firth, D.; Ripley, M.B. Package ‘Mass’. 2022. Available online: http://ftp.gr.xemacs.org/pub/CRAN/web/packages/MASS/MASS.pdf (accessed on 1 July 2022).
- Hastie, M.T. Package ‘Mda’. 2022. Available online: http://cran.ma.ic.ac.uk/web/packages/mda/mda.pdf (accessed on 1 July 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Selected Discriminative Wavelengths (nm) |
|---|---|
| SFFS + JM (n = 33) | 326, 327, 329, 330, 335, 336, 352, 359, 360, 364, 365, 408, 562, 583, 762, 777, 778, 779, 786, 828, 897, 908, 923, 995, 1018, 1031, 1038, 1045, 1057, 1059, 1061, 1067, 1068 |
| SFVS (n = 35) | 388, 401, 406, 414, 415, 419, 443, 446, 510, 515, 556, 671, 724, 754, 759, 781, 794, 807, 969, 970, 981, 983, 1009, 1027, 1031, 1032, 1035, 1045, 1048, 1049, 1050, 1053, 1066, 1068, 1070 |
| FDA (n = 7) | 424, 464, 549, 716, 753, 759, 935 |
| glmStepAIC (n = 20) | 388, 414, 415, 419, 443, 510, 759, 794, 970, 981, 982, 1001, 1031, 1035, 1045, 1048, 1049, 1050, 1053, 1066 |
| LASSO (n = 22) | 329, 369, 375, 510, 531, 536, 617, 671, 771, 772, 778, 903, 932, 959, 969, 970, 1045, 1048, 1050, 1052, 1061, 1070 |
| Feature Selection | Model | Validation Set | Statistics of Validation Sets | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Total | BT | CT | Mean | CV | ||||||||||||
| Acc | K | F1 | Acc | K | F1 | Acc | K | F1 | Acc | K | F1 | Acc | K | F1 | ||
| None | PLS | 0.7083 | 0.4047 | 0.6589 | 0.6806 | 0.3329 | 0.7356 | 0.7292 | 0.3536 | 0.5412 | 0.7060 | 0.3637 | 0.6452 | 3.4530 | 10.1605 | 15.1756 |
| N = 751 | SVM-L | 0.8274 | 0.6444 | 0.7883 | 0.8012 | 0.6154 | 0.8313 | 0.8403 | 0.6167 | 0.7262 | 0.8230 | 0.6255 | 0.7819 | 2.4209 | 2.6188 | 6.7574 |
| SVM-LW | 0.8115 | 0.6274 | 0.8104 | 0.7917 | 0.5464 | 0.8421 | 0.8264 | 0.6324 | 0.7685 | 0.8099 | 0.6021 | 0.8070 | 2.1494 | 8.0180 | 4.5747 | |
| SVM-R | 0.7857 | 0.5628 | 0.7500 | 0.7593 | 0.5015 | 0.7969 | 0.8056 | 0.5435 | 0.6818 | 0.7835 | 0.5359 | 0.7429 | 2.9643 | 5.8482 | 7.7908 | |
| Built-in | SVM-RW | 0.8056 | 0.6066 | 0.7822 | 0.7778 | 0.5367 | 0.8154 | 0.8264 | 0.6073 | 0.7368 | 0.8033 | 0.5835 | 0.7781 | 3.0356 | 6.9508 | 5.0708 |
| N = 7 | FDA | 0.7698 | 0.5339 | 0.7411 | 0.7546 | 0.4876 | 0.7969 | 0.7812 | 0.5013 | 0.6631 | 0.7685 | 0.5076 | 0.7337 | 1.7364 | 4.6856 | 9.1599 |
| N = 20 | glmStepAIC | 0.8147 | 0.6243 | 0.8342 | 0.7824 | 0.5471 | 0.7283 | 0.8392 | 0.6318 | 0.8814 | 0.8121 | 0.6011 | 0.8049 | 3.5081 | 7.8006 | 13.4507 |
| Mean | 0.7890 | 0.5720 | 0.7552 | 0.7609 | 0.5034 | 0.8030 | 0.8015 | 0.5425 | 0.6863 | 0.7866 | 0.5456 | 0.7539 | 2.7431 | 5.9137 | 5.1895 | |
| SFVS | GLM | 0.7937 | 0.5806 | 0.7636 | 0.7454 | 0.4754 | 0.7826 | 0.8299 | 0.6121 | 0.7380 | 0.7897 | 0.5560 | 0.7614 | 5.3686 | 12.8742 | 2.9395 |
| N = 35 | PLS | 0.7679 | 0.5249 | 0.7247 | 0.7685 | 0.527 | 0.7984 | 0.7674 | 0.4553 | 0.6215 | 0.7679 | 0.5024 | 0.7149 | 0.0717 | 8.1217 | 12.4302 |
| SVM-L | 0.7619 | 0.5115 | 0.7143 | 0.7454 | 0.4942 | 0.7769 | 0.7708 | 0.4649 | 0.6292 | 0.7609 | 0.4902 | 0.7068 | 1.3715 | 4.8054 | 10.4888 | |
| SVM-R | 0.8512 | 0.6994 | 0.8344 | 0.8426 | 0.6773 | 0.864 | 0.8542 | 0.6667 | 0.7742 | 0.8485 | 0.6811 | 0.8242 | 0.8821 | 2.4494 | 5.5521 | |
| SVM-LW | 0.7897 | 0.583 | 0.7854 | 0.7778 | 0.5153 | 0.8322 | 0.8125 | 0.595 | 0.7404 | 0.7933 | 0.5644 | 0.7860 | 2.2226 | 7.6132 | 5.8401 | |
| SVM-RW | 0.8532 | 0.7035 | 0.8370 | 0.8472 | 0.6831 | 0.8716 | 0.8542 | 0.6753 | 0.7857 | 0.8515 | 0.6873 | 0.8314 | 0.4446 | 2.1187 | 5.1982 | |
| Mean | 0.8029 | 0.6004 | 0.7766 | 0.7882 | 0.5621 | 0.8210 | 0.8148 | 0.5782 | 0.7148 | 0.8020 | 0.5803 | 0.7708 | 1.6668 | 3.3257 | 6.9143 | |
| SFFS + JM | GLM | 0.7202 | 0.4327 | 0.6831 | 0.7222 | 0.4109 | 0.7778 | 0.7500 | 0.4162 | 0.5955 | 0.7308 | 0.4199 | 0.6855 | 2.2794 | 2.7074 | 13.3009 |
| N = 33 | PLS | 0.7242 | 0.4355 | 0.6729 | 0.7407 | 0.4501 | 0.7926 | 0.7257 | 0.3209 | 0.4968 | 0.7302 | 0.4022 | 0.6541 | 1.2495 | 17.5938 | 22.7478 |
| SVM-L | 0.7222 | 0.4253 | 0.6517 | 0.7593 | 0.4894 | 0.8074 | 0.7153 | 0.2849 | 0.4605 | 0.7323 | 0.3999 | 0.6399 | 3.2317 | 26.1576 | 27.1545 | |
| SVM-R | 0.7639 | 0.5117 | 0.7047 | 0.7639 | 0.5184 | 0.7935 | 0.8194 | 0.5618 | 0.6829 | 0.7824 | 0.5306 | 0.6270 | 4.0955 | 5.1256 | 31.9489 | |
| SVM-LW | 0.7381 | 0.4637 | 0.6887 | 0.7639 | 0.4984 | 0.8118 | 0.7188 | 0.2957 | 0.4706 | 0.7403 | 0.4193 | 0.6570 | 3.0567 | 25.8569 | 26.2985 | |
| SVM-RW | 0.8075 | 0.6057 | 0.7707 | 0.7824 | 0.5532 | 0.8127 | 0.8333 | 0.6022 | 0.7176 | 0.8077 | 0.5870 | 0.7670 | 3.1509 | 5.0002 | 6.2135 | |
| Mean | 0.7440 | 0.4747 | 0.6419 | 0.7460 | 0.4791 | 0.6453 | 0.7554 | 0.4867 | 0.7993 | 0.7539 | 0.4598 | 0.6718 | 0.9695 | 8.7409 | 17.3572 | |
| LASSO | GLM | 0.7560 | 0.5056 | 0.7248 | 0.7176 | 0.4021 | 0.7732 | 0.7847 | 0.4973 | 0.6517 | 0.7528 | 0.4683 | 0.7166 | 4.4724 | 12.2796 | 8.5361 |
| N = 22 | PLS | 0.7560 | 0.5028 | 0.7172 | 0.7407 | 0.4501 | 0.7926 | 0.7674 | 0.437 | 0.5939 | 0.7547 | 0.4633 | 0.7012 | 1.7752 | 7.5177 | 14.3045 |
| SVM-L | 0.7599 | 0.5127 | 0.7269 | 0.7361 | 0.4393 | 0.7897 | 0.7778 | 0.4725 | 0.6279 | 0.7579 | 0.4748 | 0.7148 | 2.7601 | 7.7407 | 11.4114 | |
| SVM-R | 0.8353 | 0.6654 | 0.8118 | 0.8009 | 0.5842 | 0.8352 | 0.8611 | 0.6774 | 0.7778 | 0.8324 | 0.6423 | 0.8083 | 3.6282 | 7.8933 | 3.5709 | |
| SVM-LW | 0.7639 | 0.523 | 0.7373 | 0.7269 | 0.4217 | 0.4807 | 0.7917 | 0.5213 | 0.6739 | 0.7608 | 0.4887 | 0.6306 | 4.2728 | 11.8692 | 21.1945 | |
| SVM-RW | 0.8373 | 0.6708 | 0.8178 | 0.8009 | 0.5828 | 0.8365 | 0.8646 | 0.6913 | 0.7914 | 0.8343 | 0.6483 | 0.8152 | 3.8307 | 8.8915 | 2.7795 | |
| Mean | 0.7847 | 0.5634 | 0.7560 | 0.7539 | 0.4800 | 0.7513 | 0.8079 | 0.5495 | 0.6861 | 0.7822 | 0.5310 | 0.7311 | 3.4659 | 8.4093 | 5.3430 | |
| BT (n = 216) | CT (n = 288) | ALL (n = 504) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Actual value | Actual value | Actual value | |||||||||
| ‘No’ | ‘Yes’ | ‘No’ | ‘Yes’ | ‘No’ | ‘Yes’ | ||||||
| Predicted | ‘No’ | 71 | 15 | Predicted | ‘No’ | 169 | 19 | Predicted | ‘No’ | 240 | 33 |
| ‘Yes’ | 18 | 112 | ‘Yes’ | 23 | 77 | ‘Yes’ | 41 | 190 | |||
| Test Site | Sites | Dates | Plants | Asymptomatic Leaves | Symptomatic Leaves | Total Measurements |
|---|---|---|---|---|---|---|
| Briteiros (BT) | 1 | 9 | 8 | 89 | 127 | 216 |
| Caldas das Taipas (CT) | 1 | 8 | 12 | 192 | 96 | 288 |
| Total | 2 | 9 | 20 | 281 | 223 | 504 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reis-Pereira, M.; Tosin, R.; Martins, R.; Neves dos Santos, F.; Tavares, F.; Cunha, M. Kiwi Plant Canker Diagnosis Using Hyperspectral Signal Processing and Machine Learning: Detecting Symptoms Caused by Pseudomonas syringae pv. actinidiae. Plants 2022, 11, 2154. https://doi.org/10.3390/plants11162154
Reis-Pereira M, Tosin R, Martins R, Neves dos Santos F, Tavares F, Cunha M. Kiwi Plant Canker Diagnosis Using Hyperspectral Signal Processing and Machine Learning: Detecting Symptoms Caused by Pseudomonas syringae pv. actinidiae. Plants. 2022; 11(16):2154. https://doi.org/10.3390/plants11162154
Chicago/Turabian StyleReis-Pereira, Mafalda, Renan Tosin, Rui Martins, Filipe Neves dos Santos, Fernando Tavares, and Mário Cunha. 2022. "Kiwi Plant Canker Diagnosis Using Hyperspectral Signal Processing and Machine Learning: Detecting Symptoms Caused by Pseudomonas syringae pv. actinidiae" Plants 11, no. 16: 2154. https://doi.org/10.3390/plants11162154