
Use of Repeated Measures Data Analysis for Field Trials with Annual and Perennial Crops



Abstract
:1. Introduction
2. Importance of Modeling Correlation and Covariance Components in a Model
3. Building t-Tests
4. Experimental Design Used for Data Collection on Examples Used in the Manuscript
5. Section I: Choosing the Best Approach for Statistical Analysis for the Corn Study
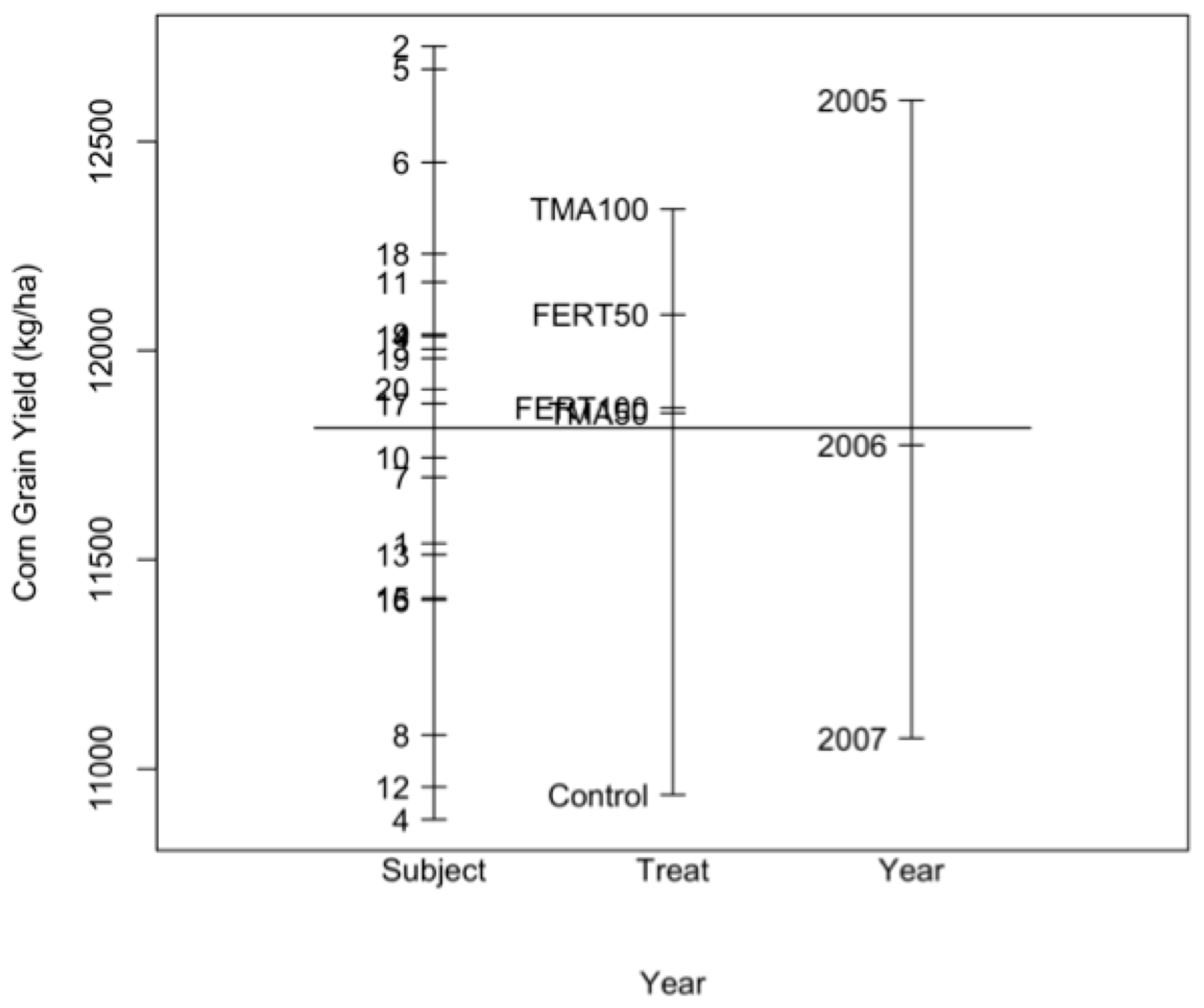
5.1. Visual Display
5.2. Constructing the Statistical Models for the Corn Study
5.3. Corn Analysis Results: Comparison of the Different Approaches
5.3.1. Year as a Fixed Effect
- proc mixed cl data = Corn;
- class block treat year;
- model yield = treat year treat * year/ddfm = kr;
- random block;
- lsmeans treat * year/diff;
- estimate ‘Control vs. TMA’
- treat 2 -1 -1 0;
- estimate ‘Control vs. Fert’
- treat 2 0 0 -1 -1;
- estimate ‘TMA vs. Fert’
- treat 0 1 1 -1 -1;
- estimate ‘50 vs. 100 kg P2O5 ha−1’
- treat 0 1 -1 1 -1;
- estimate ‘Control vs. All’
- treat 4 -1 -1 -1 -1;
- run;
5.3.2. Year as a Random Effect
- proc mixed cl data = Corn;
- class block treat year;
- model yield = treat;
- random block year year * treat;
- estimate ‘Control vs. TMA’
- treat 2 -1 -1 0;
- estimate ‘Control vs. Fert’
- treat 2 0 0 -1 -1;
- estimate ‘TMA vs. Fert’
- treat 0 1 1 -1 -1;
- estimate ‘50 vs. 100 kg P2O5 ha−1’
- treat 0 1 -1 1 -1;
- estimate ‘Control vs. All’
- treat 4 -1 -1 -1 -1;
- run;
5.3.3. Year as a Repeated Measure
- proc mixed cl data = corn;
- class block treat year;
- model yield = treat year treat * year/ddfm =kr;
- random block;
- repeated/sub = block * treat type = AR(1) r rcorr;
- lsmeans treat|year/diff;
- estimate ‘Control vs. TMA’
- treat 2 -1 -1 0;
- estimate ‘Control vs. Fert’
- treat 2 0 0 -1 -1;
- estimate ‘TMA vs. Fert’
- treat 0 1 1 -1 -1;
- estimate ‘50 vs. 100 kg P2O5 ha−1’
- treat 0 1 -1 1 -1;
- estimate ‘Control vs. All’
- treat 4 -1 -1 -1 -1;
- run;
6. Section II: Constructing the Statistical Models for the Alfalfa Study
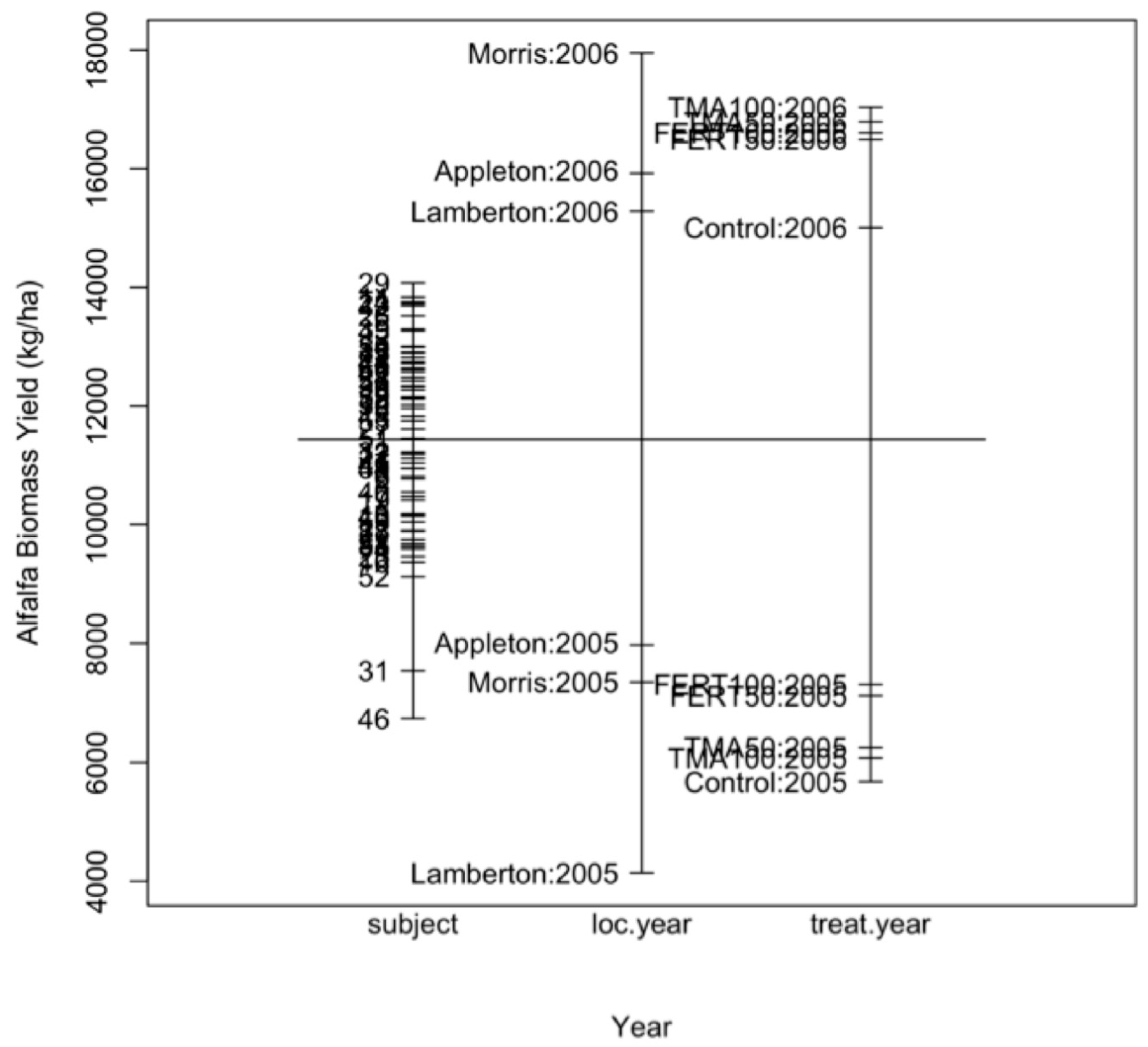
6.1. Visual Display
6.2. Inference on Random Effect Interactions
6.3. Assessing Main Effects and Interaction to Be Tested
- proc mixed cl data = Alfalfa_RMA nobound;
- class site block treat year;
- model yield = treat year treat * year;
- random site block(site) site*year site*treat site * treat * year;
- run;
6.3.1. Step One
- proc mixed cl data = alfalfa_study;
- class rep loc treat year;
- model yield = treat year treat * year/ddfm = KR;
- random loc rep(loc) loc * treat loc * year;
- repeated year/sub = rep * treat * loc type = un R Rcorr;
- contrast ‘Location effect at Year 1’
- |loc 1 −1 0
- loc * year 1 0 −1 0,
- |loc 0 1 −1
- loc * year 0 0 1 0 −1 0,
- |loc 1 0 −1
- loc * year 1 0 0 0 −1 0;
- contrast ‘Location effect at Year 2’
- |loc 1 −1 0
- loc * year 0 1 0 −1,
- |loc 0 1 −1
- loc * year 0 0 0 1 0 −1,
- |loc 1 0 −1
- loc * year 0 1 0 0 0 −1;
- Run;
6.3.2. Step Two
- intercept 1
- year 1 0
- |loc 1 0 0
- loc * year 1 0;
- intercept 1
- year 0 1
- |loc 0 0 1
- loc * year 0 0 0 0 0 1;
- | loc 1 −1 0
- loc * year 1 0 0 0 −1 0;
- | loc 0 1 −1
- loc * year 0 0 1 0 −1 0;
- | loc 1 0 −1
- loc * year 0 1 0 0 0 −1;
- | loc 0 1 −1
- loc * year 0 0 0 1 0 −1;
6.3.3. Step Three
7. Conclusions
8. Contributions and Future Work Needed
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cullis, B.R.; McGilchrist, C.A. A model for the analysis of growth data from designed experiments. Biometrics 1990, 46, 131–142. [Google Scholar] [CrossRef] [PubMed]
- Littell, R.C.; Milliken, G.A.; Stroup, W.W.; Wolfinger, R.D.; Schabenberger, O. SAS for Mixed Models, 2nd ed.; SAS Institute Inc.: Cary, NC, USA, 2006. [Google Scholar]
- Littell, R.C.; Henry, P.R.; Ammerman, C.B. Statistical analysis of repeated measures data using SAS procedures. J. Anim. Sci. 1998, 76, 1216–1231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Loughin, T.M. Improved Experimental Design and Analysis for Long-Term Experiments. Crop Sci. 2006, 46, 2492–2502. [Google Scholar] [CrossRef] [Green Version]
- Loughin, T.M.; Roediger, M.P.; Milliken, G.A.; Schimdt, J.P. On the analysis of long-term experiments. J. R. Statist. Soc. A 2007, 170, 29–42. [Google Scholar] [CrossRef]
- Littell, R.C.; Pendergast, J.; Natarajan, R. Modelling covariance structure in the analysis of repeated measures data. Statist. Med. 2000, 19, 1793–1819. [Google Scholar] [CrossRef]
- Wolfinger, R. Covariance structure selection in general mixed models. Commun. Stat.-Simul. Comput. 1993, 22, 1079–1106. [Google Scholar] [CrossRef]
- Diggle, J. An approach to the analysis of repeated measurements. Biometrics 1988, 44, 959–971. [Google Scholar] [CrossRef] [PubMed]
- SAS Institute Inc. SAS/STAT® 9.1 User’s Guide; SAS Institute Inc.: Cary, NC, USA, 2004. [Google Scholar]
- Pagliari, P.; Rosen, C.; Strock, J.; Russelle, M. Phosphorus availability and early corn growth response in soil amended with turkey manure ash. Commun. Soil Sci. Plant Anal. 2010, 41, 1369–1382. [Google Scholar] [CrossRef]
- Pagliari, P.H.; Rosen, C.J.; Strock, J.S. Turkey Manure Ash Effects on Alfalfa Yield, Tissue Elemental Composition, and Chemical Soil Properties. Commun. Soil Sci. Plant Anal. 2009, 40, 2874–2897. [Google Scholar] [CrossRef]
- Kutner, M.H.; Nachtsheim, C.J.; Neter, J.; Li, W. Applied Linear Statistical Models, 5th ed.; McGraw-Hill: New York, NY, USA, 2005. [Google Scholar]
- Keselman, H.J.; Algina, J.; Kowalchuk, R.K.; Wolfinger, R.D. A comparison of two approaches for selecting covariance structures in the analysis of repeated measurements. Commun. Stat.-Simul. Comput. 1998, 27, 591–604. [Google Scholar] [CrossRef]
- Kenward, M.G.; Roger, J.H. Small sample inference for fixed effects from restricted maximum likelihood. Biometrics 1997, 53, 983–997. [Google Scholar] [CrossRef] [PubMed] [Green Version]



{kind=link}
{kind=link}
| Covariance Parameter Estimates | |||||||
|---|---|---|---|---|---|---|---|
| Cov Parm Group | Estimate | Alpha | Lower | Upper | |||
| block | 132,860 | 0.05 | 34,207 | 7,832,096 | |||
| Residual | 592,634 | 0.05 | 402,912 | 957,381 | |||
| Fit Statistics | |||||||
| −2 Res Log Likelihood | 751.1 | ||||||
| AIC (smaller is better) | 755.1 | ||||||
| AICC (smaller is better) | 755.4 | ||||||
| BIC (smaller is better) | 753.8 | ||||||
| Type 3 Tests of Fixed Effects | |||||||
| Num | Den | F Value | Pr > F | ||||
| Effect | DF | DF | |||||
| treat | 4 | 42 | 5.68 | 0.001 | |||
| year | 2 | 42 | 19.69 | <0.0001 | |||
| treat * year | 8 | 42 | 0.87 | 0.5466 | |||
| Estimates | |||||||
| Label | Estimate | Standard Error | DF | t Value | Pr > |t| | ||
| Control vs. TMA | −2314.83 | 544.35 | 42 | −4.25 | 0.0001 | ||
| Control vs. Fert | −2074.5 | 544.35 | 42 | −3.81 | 0.0004 | ||
| TMA vs. Fert | 240.33 | 444.46 | 42 | 0.54 | 0.5915 | ||
| 50 vs. 100 kg P2O5 ha−1 | −264.83 | 444.46 | 42 | −0.6 | 0.5545 | ||
| Control vs. All | −4389.33 | 993.84 | 42 | −4.42 | <0.0001 | ||
| Differences of Least Square Means | |||||||
| Effect | t yr | _t_yr | Estimate | Standard Error | DF | t Value | Pr > |t| |
| treat * year | 1 1 | 1 2 | 835.5 | 544.35 | 42 | 1.53 | 0.1323 |
| treat * year | 1 1 | 1 3 | 1947 | 544.35 | 42 | 3.58 | 0.0009 |
| treat * year | 1 1 | 2 1 | −344.25 | 544.35 | 42 | −0.63 | 0.5305 |
| treat * year | 1 1 | 2 2 | −23.5 | 544.35 | 42 | −0.04 | 0.9658 |
| treat * year | 1 1 | 2 3 | 409.25 | 544.35 | 42 | 0.75 | 0.4564 |
| Covariance Parameter Estimates | ||||||
|---|---|---|---|---|---|---|
| Cov Parm | Estimate | Alpha | Lower | Upper | ||
| block | 132,860 | 0.05 | −143,500 | 409,219 | ||
| year | 557,598 | 0.05 | −586,261 | 1,701,457 | ||
| treat * year | −18,805 | 0.05 | −160,525 | 122,916 | ||
| Residual | 592,634 | 0.05 | 402,912 | 957,381 | ||
| Fit Statistics | ||||||
| −2 Res Log Likelihood | 908.9 | |||||
| AIC (smaller is better) | 916.9 | |||||
| AICC (smaller is better) | 917.7 | |||||
| BIC (smaller is better) | 914.4 | |||||
| Type 3 Tests of Fixed Effects | ||||||
| Effect | Num | Den | F Value | Pr > F | ||
| DF | DF | |||||
| treat | 4 | 8 | 6.5 | 0.0124 | ||
| Estimates | ||||||
| Label | Estimate | Standard Error | DF | t Value | Pr > |t| | |
| Control vs. TMA | −2314.83 | 508.63 | 8 | −4.55 | 0.0019 | |
| Control vs. Fert | −2074.5 | 508.63 | 8 | −4.08 | 0.0035 | |
| TMA vs. Fert | 240.33 | 415.3 | 8 | 0.58 | 0.5787 | |
| 50 vs. 100 kg P2O5 ha−1 | −264.83 | 415.3 | 8 | −0.64 | 0.5415 | |
| Control vs. All | −4389.33 | 928.63 | 8 | −4.73 | 0.0015 | |
| Estimated R Matrix for Subject 1 | |||||
|---|---|---|---|---|---|
| Row | Col1 | Col2 | Col3 | ||
| 1 | 620,963 | 248,471 | 99,423 | ||
| 2 | 248,471 | 620,963 | 248,471 | ||
| 3 | 99,423 | 248,471 | 620,963 | ||
| Estimated R Correlation Matrix for Subject 1 | |||||
| Row | Col1 | Col2 | Col3 | ||
| 1 | 1 | 0.4001 | 0.1601 | ||
| 2 | 0.4001 | 1 | 0.4001 | ||
| 3 | 0.1601 | 0.4001 | 1 | ||
| Covariance Parameter Estimates | |||||
| Cov Parm Subject | Estimate | Alpha | Lower | Upper | |
| block | 94,701 | 0.05 | 18,728 | 1.06 × 108 | |
| AR(1) treat * year | 0.4001 | 0.05 | 0.07588 | 0.7244 | |
| Residual | 620,963 | 0.05 | 399,907 | 1,093,942 | |
| Fit Statistics | |||||
| −2 Res Log Likelihood | 746.2 | ||||
| AIC (smaller is better) | 752.2 | ||||
| AICC (smaller is better) | 752.8 | ||||
| BIC (smaller is better) | 750.3 | ||||
| Type 3 Tests of Fixed Effects | |||||
| Effect | Num | Den | F Value | Pr > F | |
| DF | DF | ||||
| treat | 4 | 13.6 | 3.42 | 0.0388 | |
| year | 2 | 30 | 21.2 | <0.0001 | |
| treat * year | 8 | 30.3 | 1.12 | 0.3751 | |
| Estimates | |||||
| Estimate | Standard Error | DF | Pr > |t| | ||
| t Value | |||||
| Control vs. TMA | −2314.83 | 700.99 | 13.6 | −3.3 | 0.0054 |
| Control vs. Fert | −2074.5 | 700.99 | 13.6 | −2.96 | 0.0106 |
| TMA vs. Fert | 240.33 | 572.35 | 13.6 | 0.42 | 0.6811 |
| 50 vs. 100 kg P2O5 ha−1 | −264.83 | 572.35 | 13.6 | −0.46 | 0.6509 |
| Control vs. All | −4389.33 | 1279.82 | 13.6 | −3.43 | 0.0042 |
| Differences of Least Square Means | |||||||
|---|---|---|---|---|---|---|---|
| Effect | t yr | _t_yr | Estimate | Standard Error | DF | t Value | Pr > |t| |
| treat * year | 1 1 | 1 2 | 835.5 | 439.08 | 28.7 | 1.9 | 0.0671 |
| treat * year | 1 1 | 1 3 | 1947 | 523.93 | 41.2 | 3.72 | 0.0006 |
| treat * year | 1 1 | 2 1 | −344.25 | 557.21 | 31.3 | −0.62 | 0.5412 |
| treat * year | 1 1 | 2 2 | −23.5 | 557.21 | 31.3 | −0.04 | 0.9666 |
| treat * year | 1 1 | 2 3 | 409.25 | 557.21 | 31.3 | 0.73 | 0.4681 |
| Covariance Parameter Estimates | ||||
|---|---|---|---|---|
| Cov Parm Group | Estimate | Alpha | Lower | Upper |
| loc | 1,583,509 | 0.05 | −3,242,629 | 6,409,646 |
| block (loc) | 163,907 | 0.05 | −98,528 | 426,342 |
| Loc * year | 1,383,329 | 0.05 | −1,476,742 | 4,243,401 |
| Loc * treat | −11,951 | 0.05 | −265,153 | 241,251 |
| loc * treat * year | 83,594 | 0.05 | −296,906 | 464,093 |
| Residual | 1,174,233 | 0.05 | 882,445 | 1,639,922 |
| Fit Statistics | |||||
|---|---|---|---|---|---|
| −2 Res Log Likelihood | 1889.8 | ||||
| AIC (smaller is better) | 1903.8 | ||||
| AICC (smaller is better) | 1904.9 | ||||
| BIC (smaller is better) | 1897.5 | ||||
| Type 3 Tests of Fixed Effects | |||||
| Effect | Num | Den | F Value | Pr > F | |
| DF | DF | ||||
| treat | 4 | 9.14 | 4.84 | 0.0226 | |
| year | 1 | 2 | 99.76 | 0.0099 | |
| treat * year | 4 | 53 | 2.78 | 0.0360 | |
| Contrasts | |||||
| Label | Num | Den | F Value | Pr > F | |
| DF | DF | ||||
| Location effect at year 1 | 2 | 25.2 | 49.7 | <0.0001 | |
| Location effect at year 2 | 2 | 58.7 | 13.3 | <0.0001 | |
| Estimate | |||||
|---|---|---|---|---|---|
| Standard | |||||
| Label | Estimate | Error | DF | t Value | Pr > |t| |
| Loc 1 vs. Loc 3 Year 1 | −3122 | 397.57 | 13.8 | −7.85 | 0.0001 |
| Loc 2 vs. Loc 3 Year 1 | −606 | 397.57 | 13.8 | −1.52 | 0.1500 |
| Loc 1 vs. Loc 3 Year 2 | −657 | 516.66 | 31.7 | −1.27 | 0.2127 |
| Loc 2 vs. Loc 3 Year 2 | 1918 | 516.66 | 31.7 | 3.71 | 0.0008 |
| Estimate | |||||
| Standard | |||||
| Label | Estimate | Error | DF | t Value | Pr > |t| |
| Location 1 year 1 | 4203 | 281.85 | 13.6 | 14.91 | <0.0001 |
| Location 1 year 2 | 15,308 | 367.82 | 30.9 | 41.62 | <0.0001 |
| Location 2 year 1 | 7325 | 281.85 | 13.6 | 25.99 | <0.0001 |
| Location 2 year 2 | 17,883 | 367.82 | 30.9 | 48.62 | <0.0001 |
| Location 3 year 1 | 7931 | 281.85 | 13.6 | 28.14 | <0.0001 |
| Location 3 year 2 | 15,965 | 367.82 | 30.9 | 43.4 | <0.0001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pagliari, P.; Galindo, F.S.; Strock, J.; Rosen, C. Use of Repeated Measures Data Analysis for Field Trials with Annual and Perennial Crops. Plants 2022, 11, 1783. https://doi.org/10.3390/plants11131783
Pagliari P, Galindo FS, Strock J, Rosen C. Use of Repeated Measures Data Analysis for Field Trials with Annual and Perennial Crops. Plants. 2022; 11(13):1783. https://doi.org/10.3390/plants11131783
Chicago/Turabian StylePagliari, Paulo, Fernando Shintate Galindo, Jeffrey Strock, and Carl Rosen. 2022. "Use of Repeated Measures Data Analysis for Field Trials with Annual and Perennial Crops" Plants 11, no. 13: 1783. https://doi.org/10.3390/plants11131783