Improving the Quality of Citizen Contributed Geodata through Their Historical Contributions: The Case of the Road Network in OpenStreetMap



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
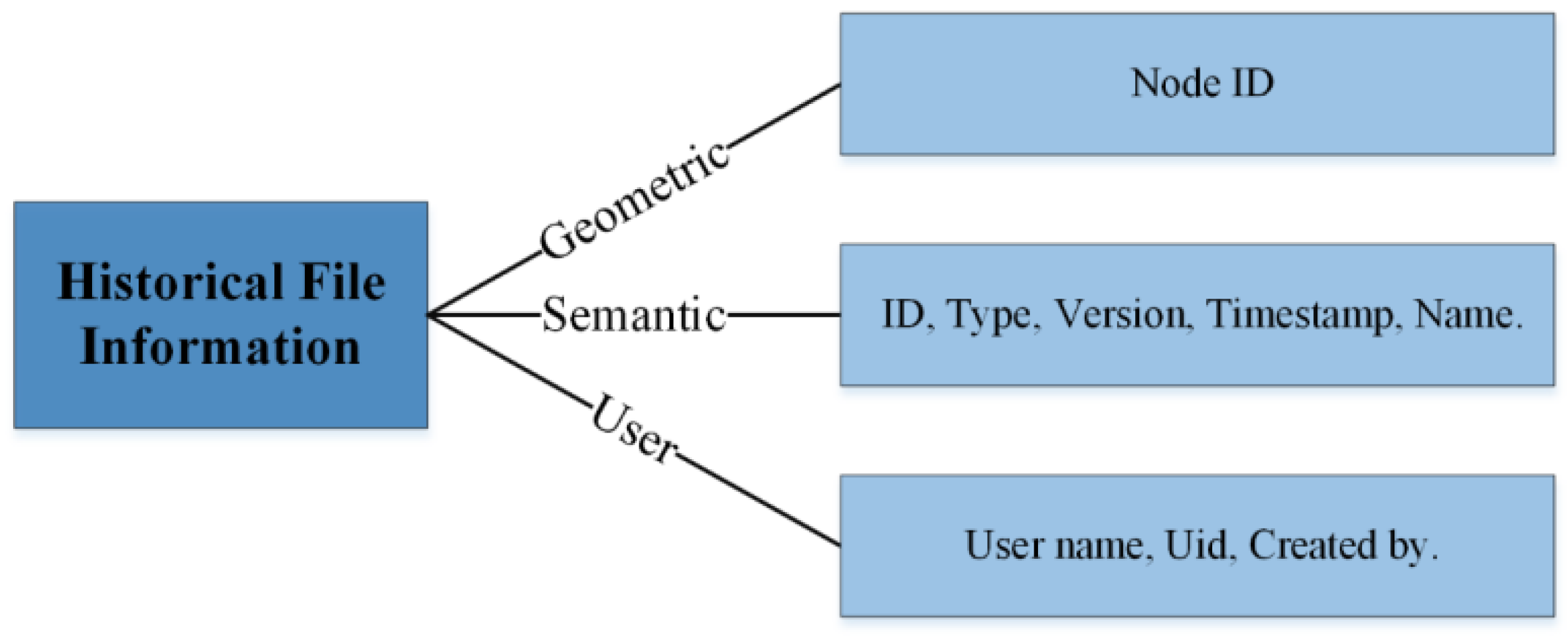
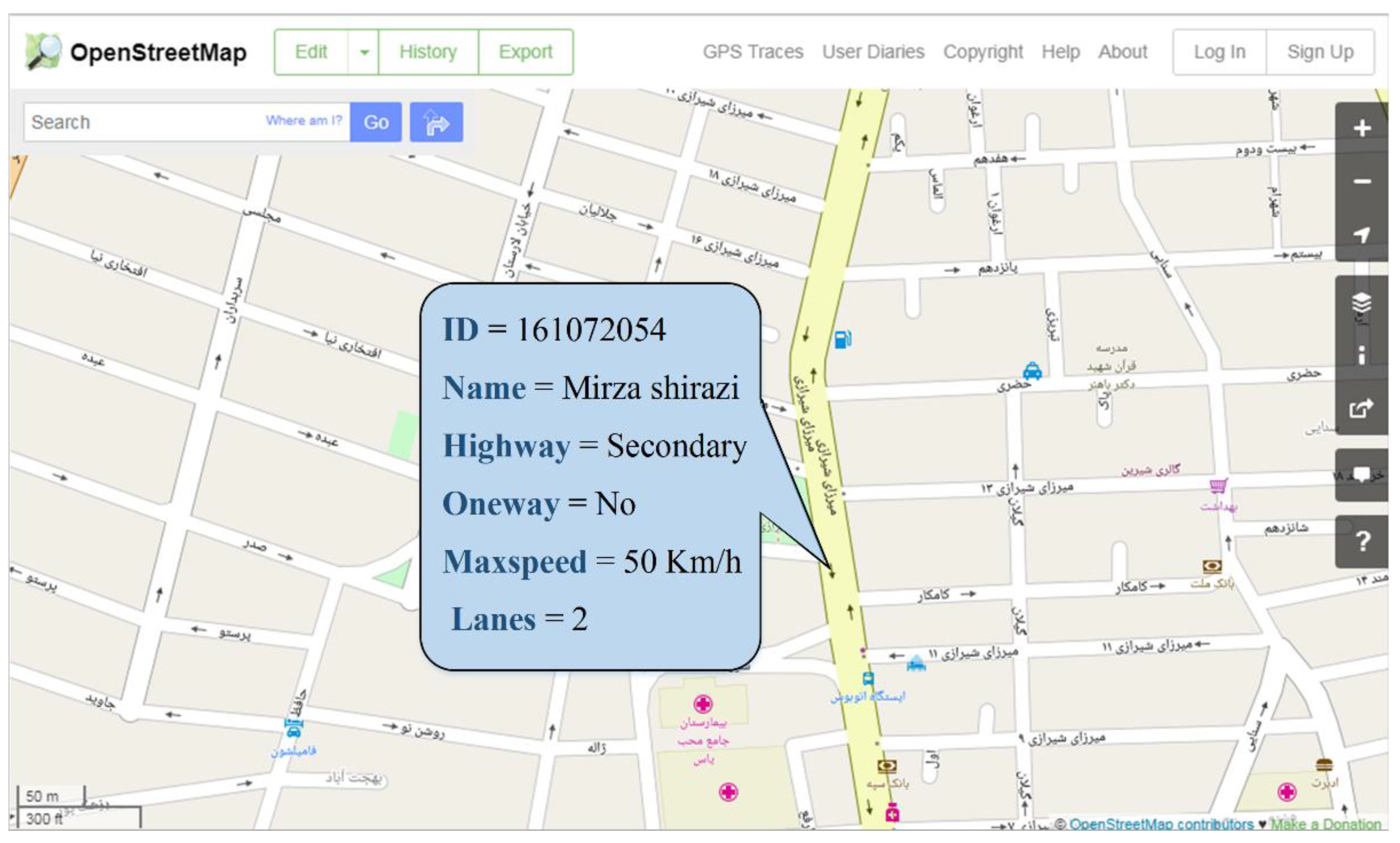
2. OSM History File
3. Theoretical Framework
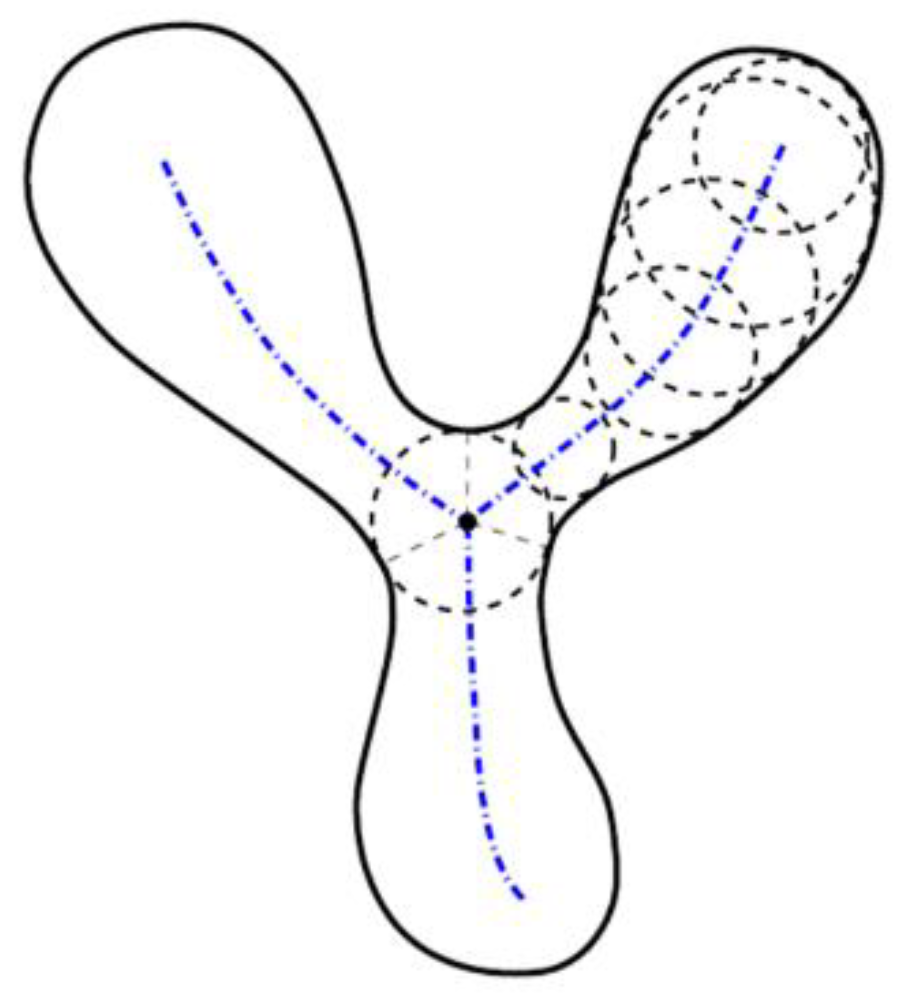
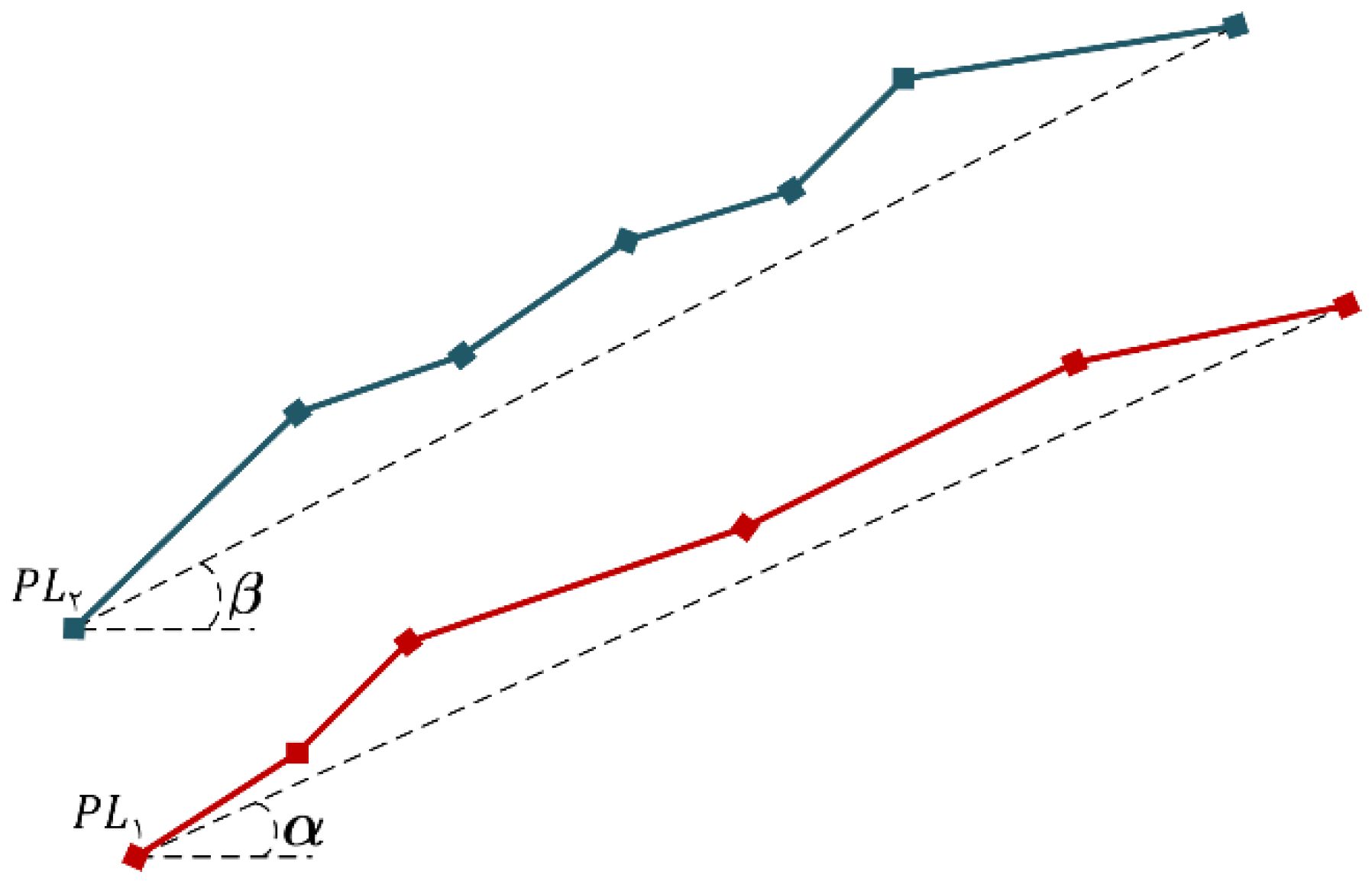
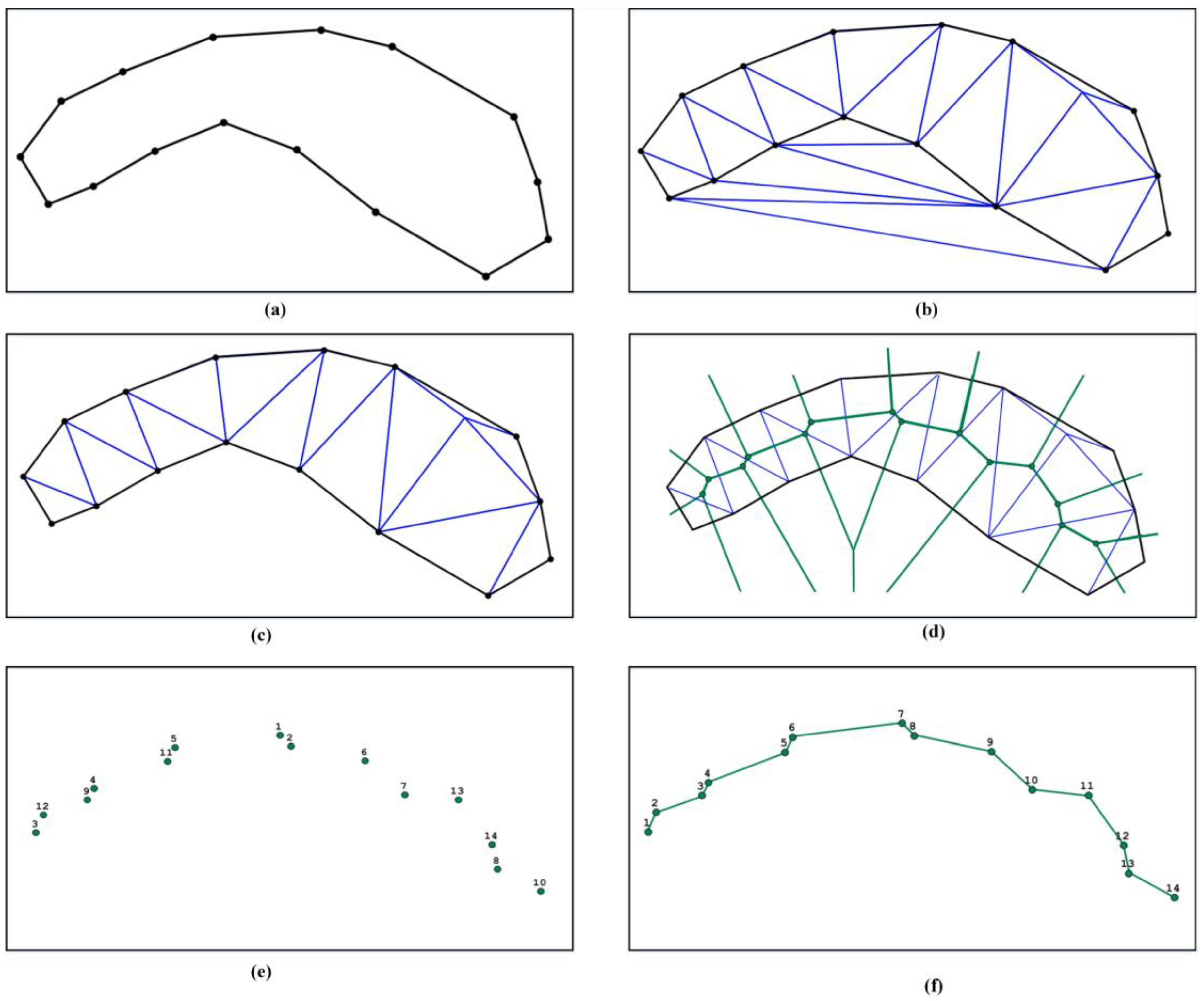
3.1. Medial Axis
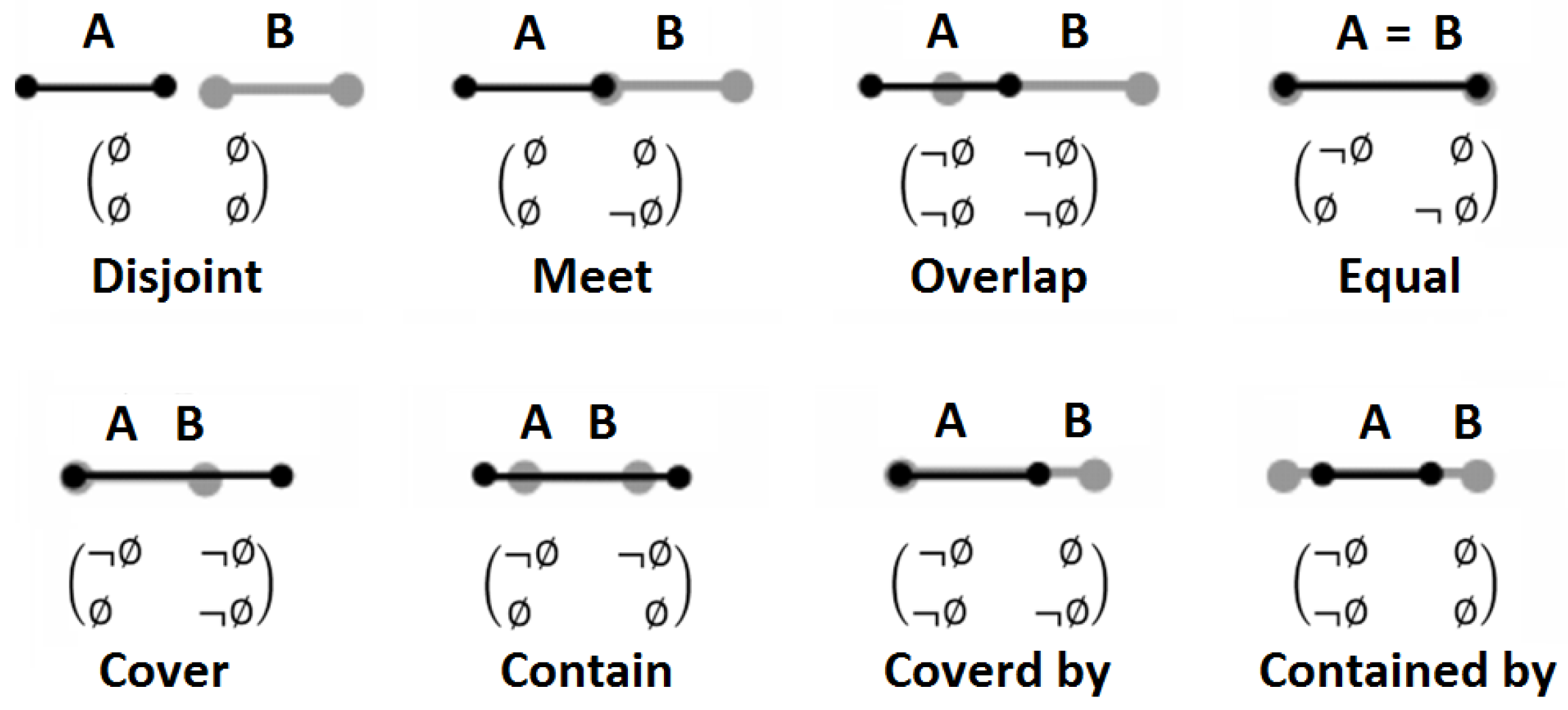
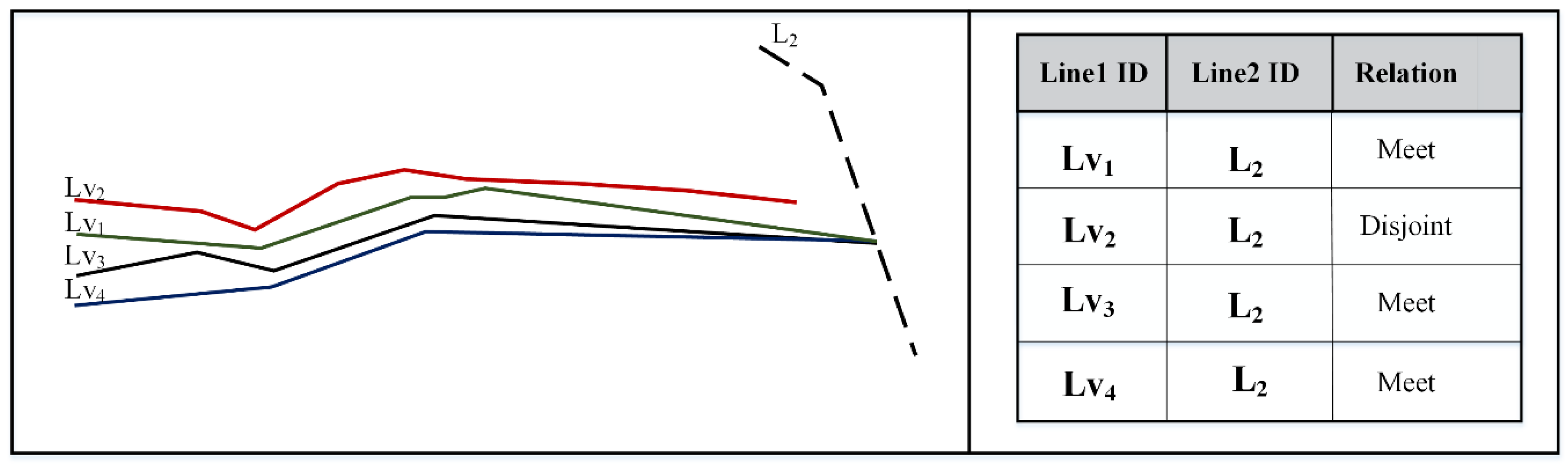
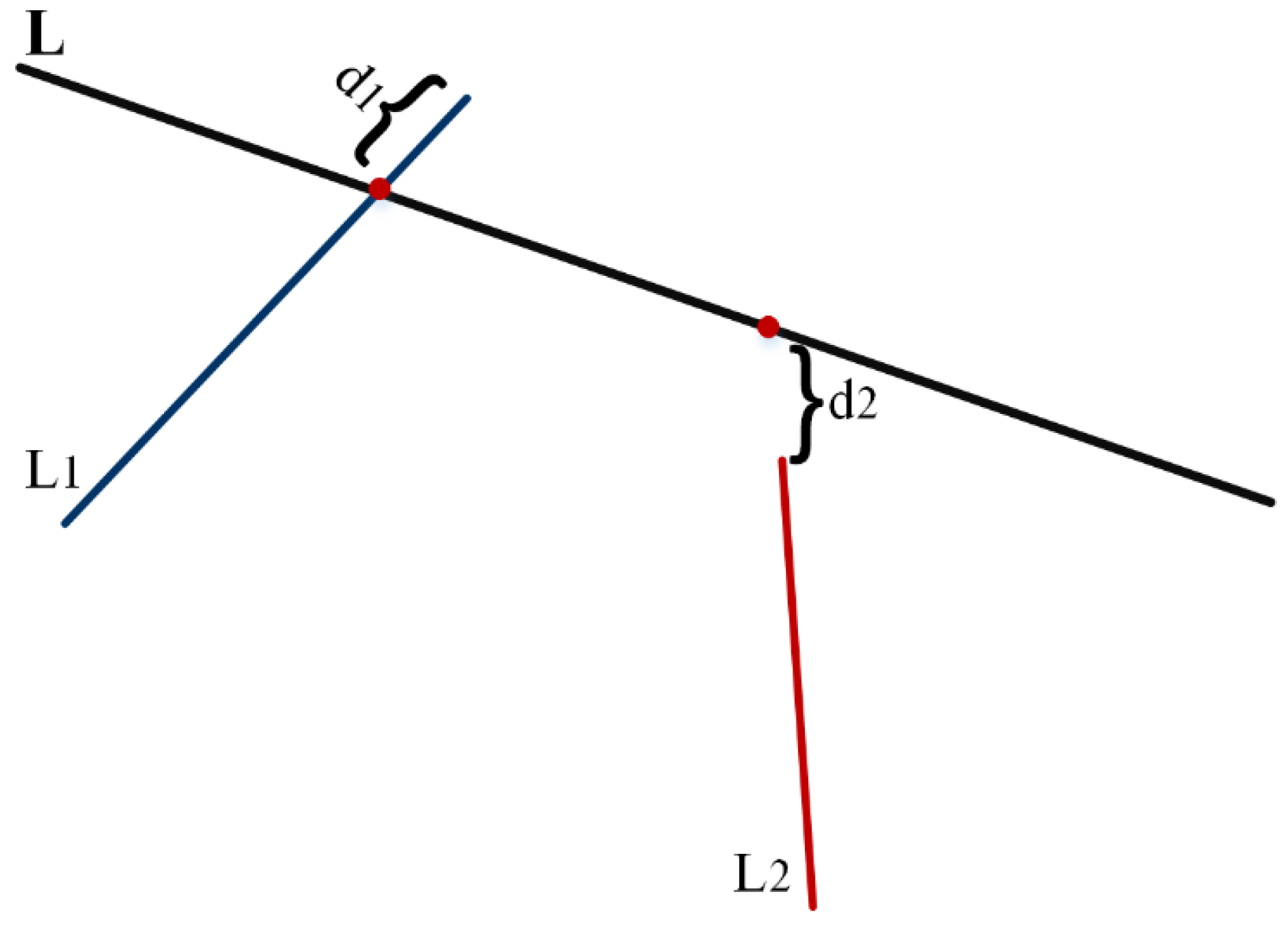
3.2. Topological Spatial Relationships
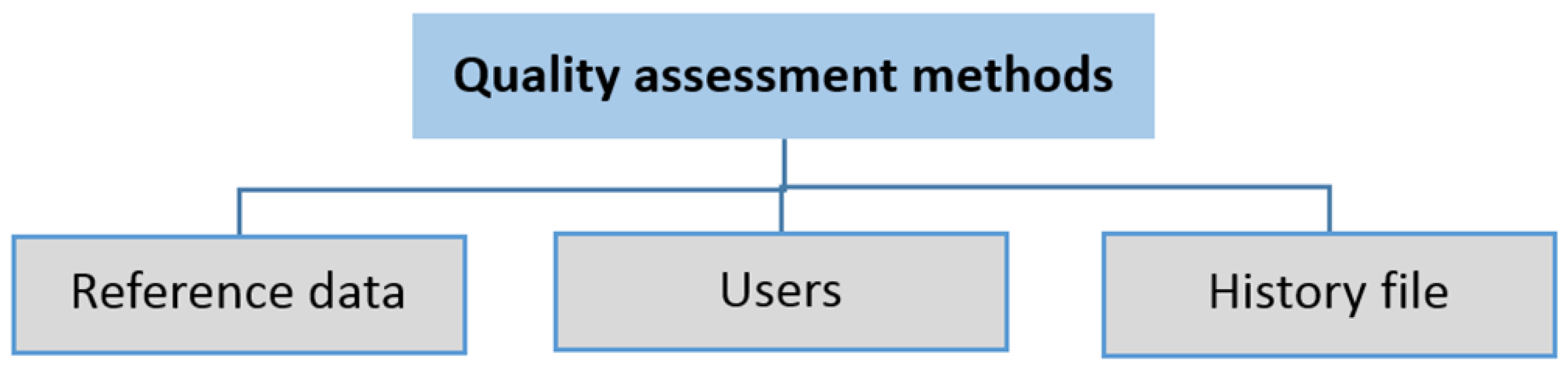
3.3. Data Quality Elements
3.3.1. Positional Accuracy
3.3.2. Completeness
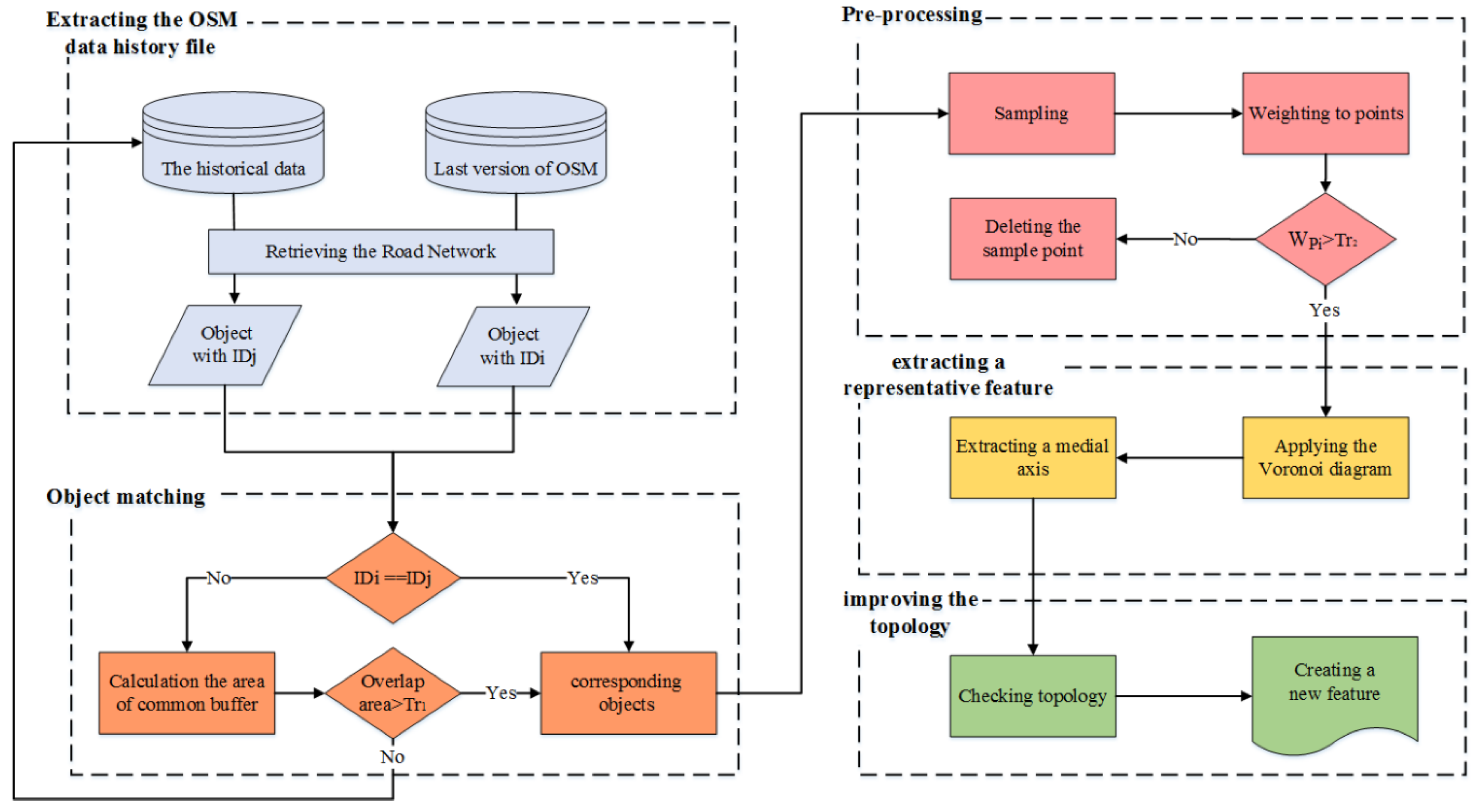
4. The Proposed Approach
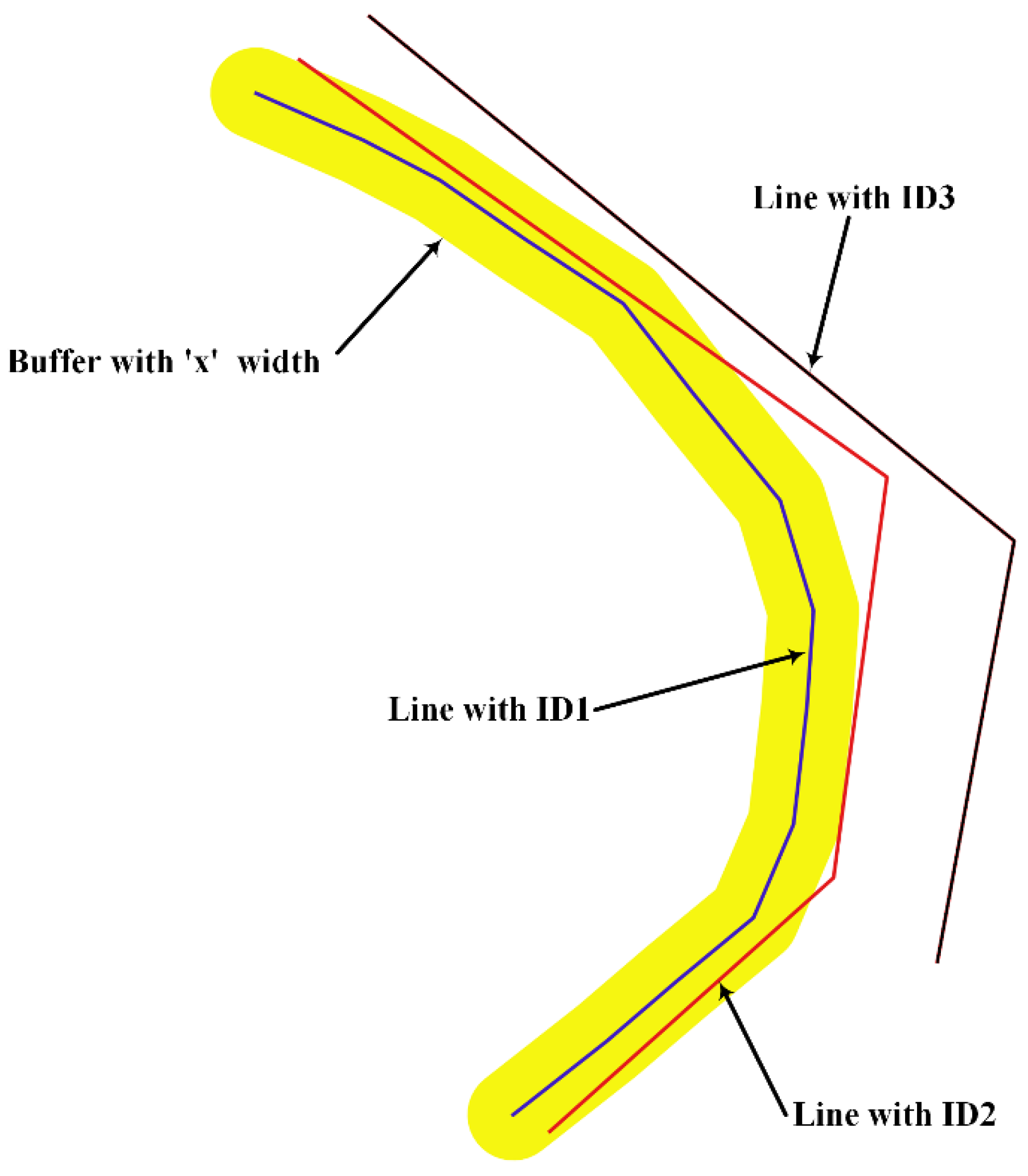
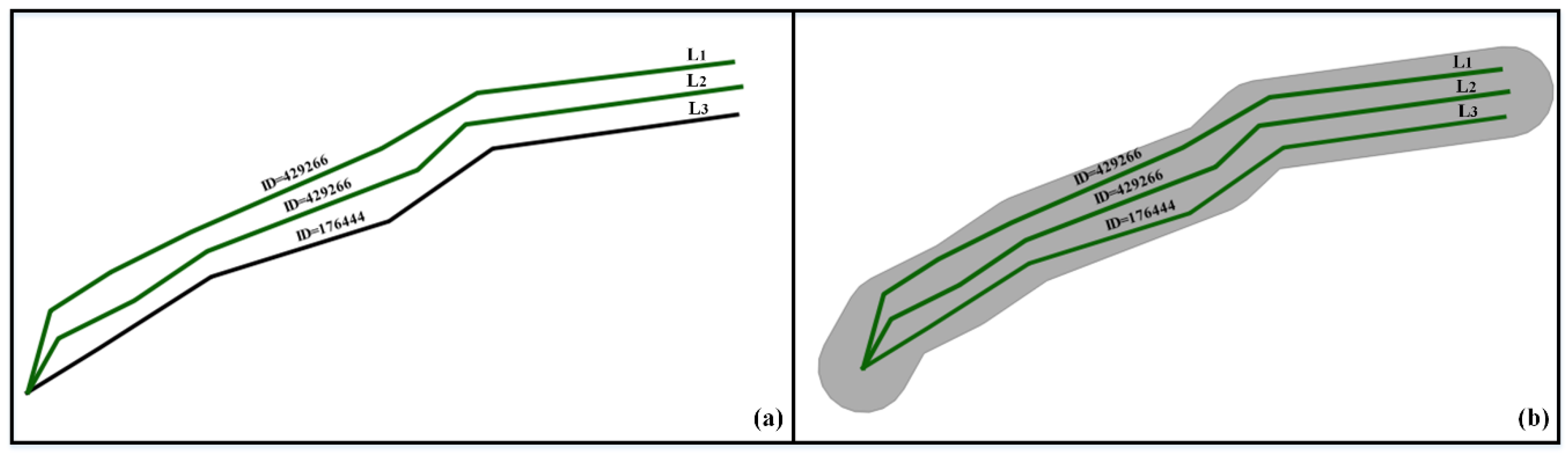
4.1. Object Matching
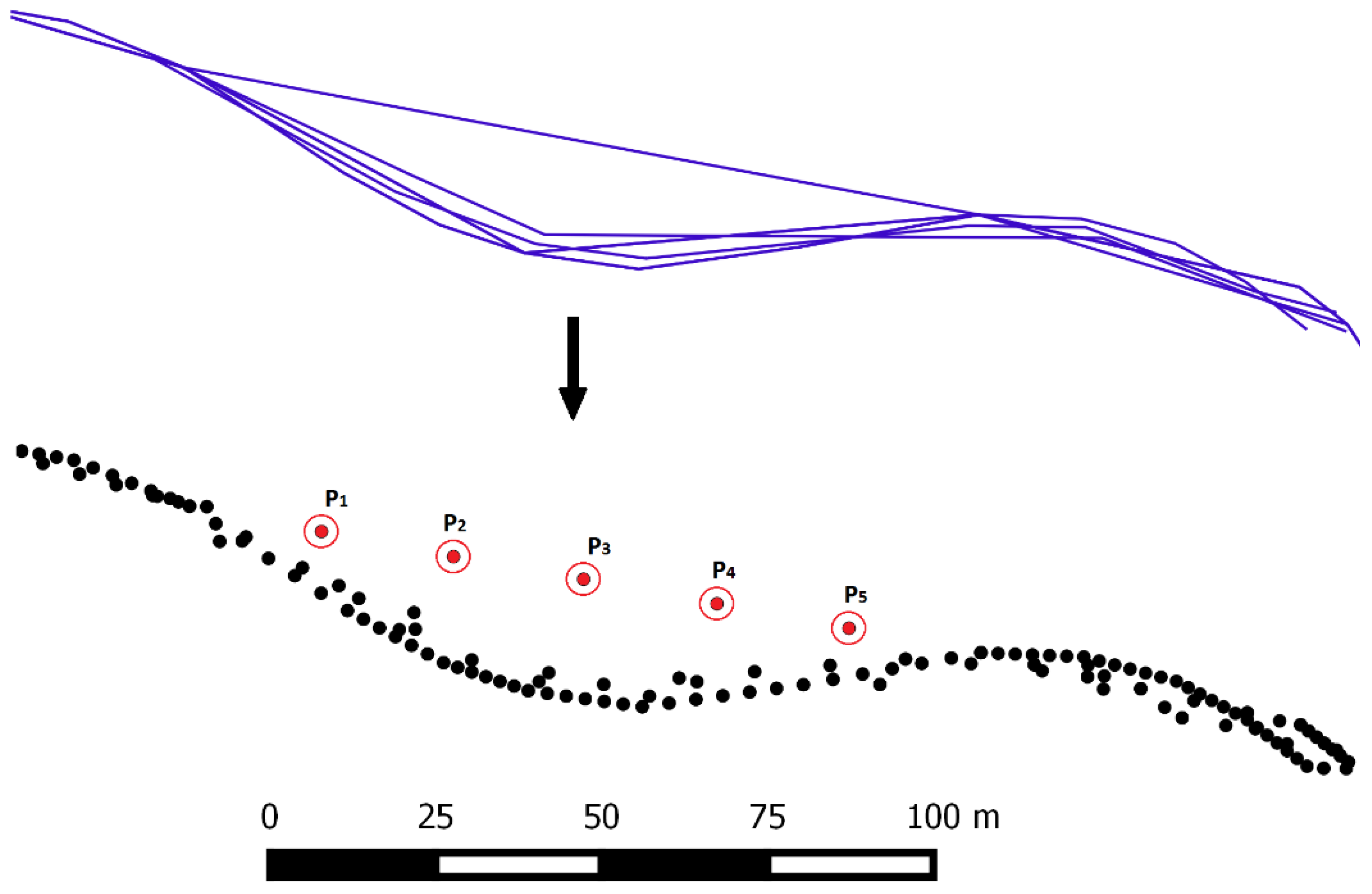
4.2. Identification and Removal of Outliers
5. Implementation
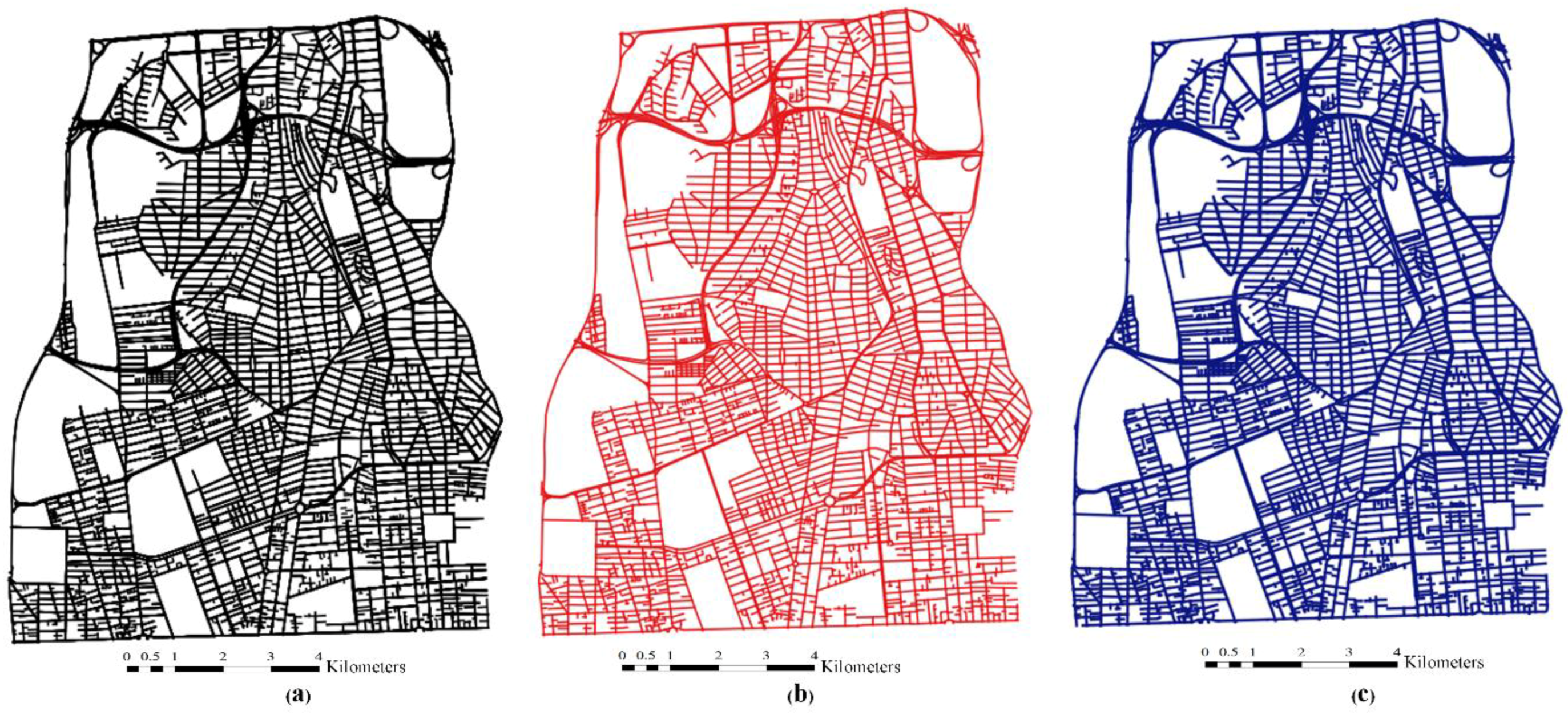
5.1. Case Studies
5.2. Identification of the Corresponding Objects in the History File
5.3. Preprocessing
5.4. Extracting the Medial Axis
5.5. Topological Check of the Objects
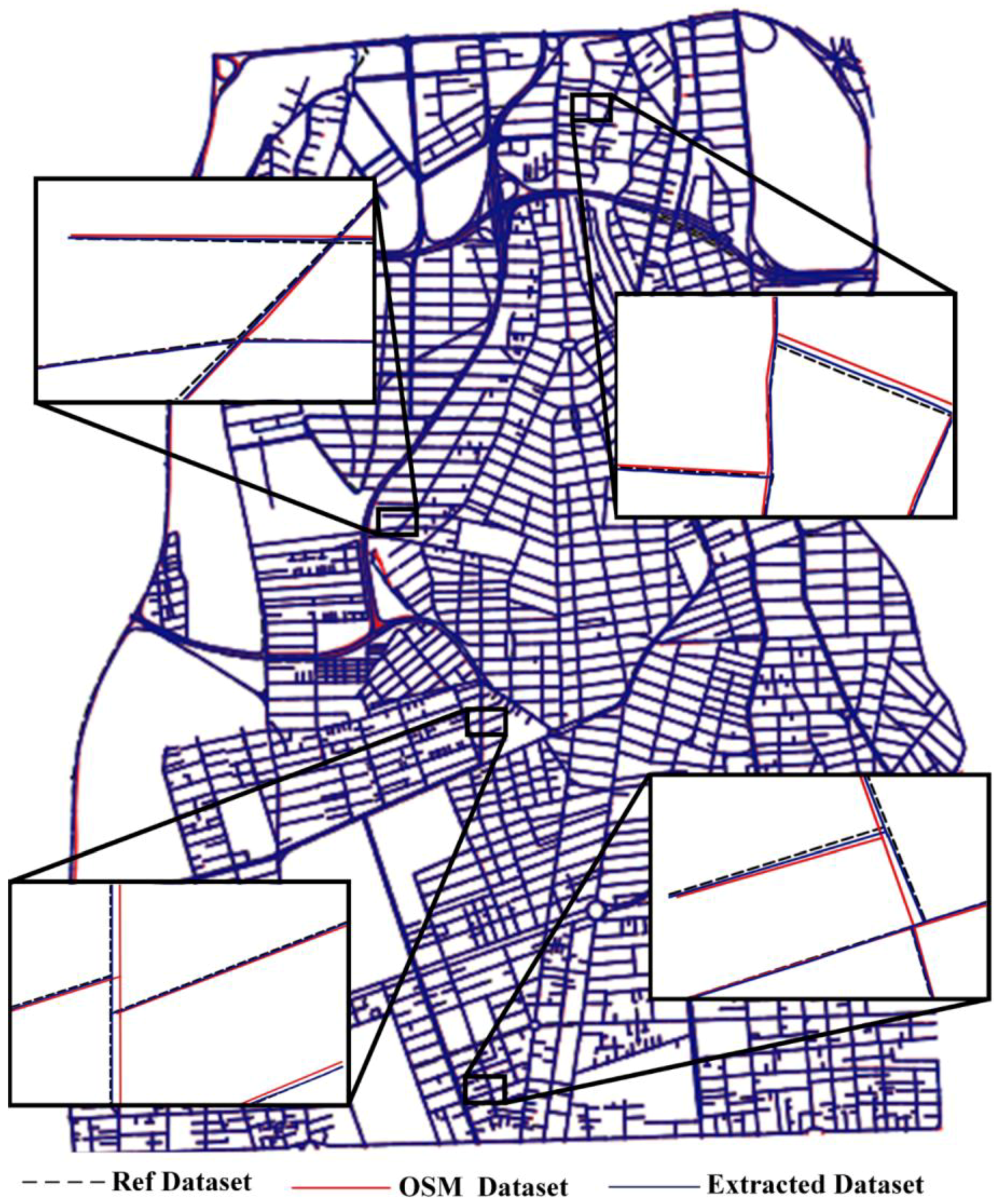
5.6. Evaluation of the Approach
6. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ballatore, A.; Jokar Arsanjani, J. Placing Wikimapia: An exploratory analysis. Int. J. Geogr. Inf. Sci. 2018, 32, 1–18. [Google Scholar] [CrossRef]
- Hashemi, P.; Abbaspour, R.A. Assessment of logical consistency in OpenStreetMap based on the spatial similarity concept. In Openstreetmap in Giscience; Springer: Berlin, Germany, 2015; pp. 19–36. [Google Scholar]
- Goetz, M. Towards generating highly detailed 3D CityGML models from OpenStreetMap. Int. J. Geogr. Inf. Sci. 2013, 27, 845–865. [Google Scholar] [CrossRef]
- OSM Statistics. Available online: http://wiki.Openstreetmap.Org/wiki/stats (accessed on 24 June 2017).
- Full History Dump. Available online: http://wiki.Openstreetmap.Org/wiki/planet.Osm/full (accessed on 23 June 2017).
- Barron, C.; Neis, P.; Zipf, A. A comprehensive framework for intrinsic OpenStreetMap quality analysis. Trans. GIS 2014, 18, 877–895. [Google Scholar] [CrossRef]
- Grira, J.; Bédard, Y.; Roche, S. Spatial data uncertainty in the VGI world: Going from consumer to producer. Geomatica 2010, 64, 61–72. [Google Scholar]
- Feick, R.; Roche, S. Understanding the value of VGI. In Crowdsourcing Geographic Knowledge; Springer: Berlin, Germany, 2013; pp. 15–29. [Google Scholar]
- De Longueville, B.; Ostländer, N.; Keskitalo, C. Addressing vagueness in volunteered geographic information (VGI)—A case study. Int. J. Spat. Data Infrastruct. Res. 2010, 5, 1725–0463. [Google Scholar]
- Kounadi, O. Assessing the Quality of OpenStreetMap Data. Master’s Thesis, Geographical Information Science, Department of Civil, Environmental and Geomatic Engineering, University College of London, London, UK, 2009. [Google Scholar]
- Girres, J.F.; Touya, G. Quality assessment of the french OpenStreetMap dataset. Trans. GIS 2010, 14, 435–459. [Google Scholar] [CrossRef]
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and ordnance survey datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Zielstra, D.; Zipf, A. A comparative study of proprietary geodata and volunteered geographic information for germany. In Proceedings of the 13th AGILE International Conference on Geographic Information Science, Guimaras, Portugal, 11–14 May 2010. [Google Scholar]
- Neis, P.; Zielstra, D.; Zipf, A. The street network evolution of crowdsourced maps: Openstreetmap in germany 2007–2011. Future Internet 2011, 4, 1–21. [Google Scholar] [CrossRef]
- Forghani, M.; Delavar, M.R. A quality study of the OpenStreetMap dataset for tehran. ISPRS Int. J. Geo-Inf. 2014, 3, 750–763. [Google Scholar] [CrossRef]
- Arsanjani, J.J.; Mooney, P.; Zipf, A.; Schauss, A. Quality assessment of the contributed land use information from OpenStreetMap versus authoritative datasets. In Openstreetmap in Giscience; Springer: Berlin, Germany, 2015; pp. 37–58. [Google Scholar]
- Mohammadi, N.; Malek, M. VGI and reference data correspondence based on location-orientation rotary descriptor and segment matching. Trans. GIS 2015, 19, 619–639. [Google Scholar] [CrossRef]
- Lyu, H.; Sheng, Y.; Guo, N.; Huang, B.; Zhang, S. Geometric quality assessment of trajectory-generated VGI road networks based on the symmetric arc similarity. Trans. GIS 2017, 21, 984–1009. [Google Scholar] [CrossRef]
- Brovelli, M.A.; Minghini, M.; Molinari, M.; Mooney, P. Towards an automated comparison of OpenStreetMap with authoritative road datasets. Trans. GIS 2017, 21, 191–206. [Google Scholar] [CrossRef]
- Dorn, H.; Törnros, T.; Zipf, A. Quality evaluation of VGI using authoritative data—A comparison with land use data in Southern Germany. ISPRS Int. J. Geo-Inf. 2015, 4, 1657–1671. [Google Scholar] [CrossRef]
- Arsanjani, J.J.; Barron, C.; Bakillah, M.; Helbich, M. Assessing the quality of OpenStreetMap contributors together with their contributions. In Proceedings of the AGILE, Vienna, Austria, 3–7 June 2013; pp. 14–17. [Google Scholar]
- Haklay, M.; Basiouka, S.; Antoniou, V.; Ather, A. How many volunteers does it take to map an area well? The validity of linus’ law to volunteered geographic information. Cartogr. J. 2010, 47, 315–322. [Google Scholar] [CrossRef]
- Leeuw, J.D.; Said, M.; Ortegah, L.; Nagda, S.; Georgiadou, Y.; DeBlois, M. An assessment of the accuracy of volunteered road map production in Western Kenya. Remote Sens. 2011, 3, 247–256. [Google Scholar] [CrossRef]
- Neis, P.; Zipf, A. Analyzing the contributor activity of a volunteered geographic information project—The case of OpenStreetMap. ISPRS Int. J. Geo-Inf. 2012, 1, 146–165. [Google Scholar] [CrossRef]
- Antoniou, V.; Touya, G.; Raimond, A.-M. Quality analysis of the parisian osm toponyms evolution. In European Handbook of Crowdsourced Geographic Information; Capineri, C., Haklay, M., Huang, H., Antoniou, V., Kettunen, J., Ostermann, F., Purves, R., Eds.; University of Zurich: Zurich, Switzerland, 2016; pp. 97–112. [Google Scholar]
- Jonietz, D.; Zipf, A. Defining fitness-for-use for crowdsourced points of interest (POI). ISPRS Int. J. Geo-Inf. 2016, 5, 149. [Google Scholar] [CrossRef]
- Keßler, C.; De Groot, R.T.A. Trust as a proxy measure for the quality of volunteered geographic information in the case of OpenStreetMap. In Geographic Information Science at the Heart of Europe; Springer: Berlin, Germany, 2013; pp. 21–37. [Google Scholar]
- Keßler, C.; Trame, J.; Kauppinen, T. Tracking editing processes in volunteered geographic information: The case of OpenStreetMap. In Proceedings of the Workshop on Identifying Objects, Processes and Events in Spatio-Temporally Distributed Data (IOPE 2011), Belfast, ME, USA, 12–16 September 2011. [Google Scholar]
- Rehrl, K.; Gröchenig, S. A framework for data-centric analysis of mapping activity in the context of volunteered geographic information. ISPRS Int. J. Geo-Inf. 2016, 5, 37. [Google Scholar] [CrossRef]
- Sehra, S.S.; Singh, J.; Rai, H.S. Assessing OpenStreetMap data using intrinsic quality indicators: An extension to the qgis processing toolbox. Future Internet 2017, 9, 15. [Google Scholar] [CrossRef]
- D’Antonio, F.; Fogliaroni, P.; Kauppinen, T. VGI edit history reveals data trustworthiness and user reputation. In Proceedings of the AGILE 2014, Castellón, Spain, 3–6 June 2014. [Google Scholar]
- Touya, G.; Antoniou, V.; Olteanu-Raimond, A.-M.; Van Damme, M.-D. Assessing crowdsourced poi quality: Combining methods based on reference data, history, and spatial relations. ISPRS Int. J. Geo-Inf. 2017, 6, 80. [Google Scholar] [CrossRef]
- Van Exel, M.; Dias, E.; Fruijtier, S. In The impact of crowdsourcing on spatial data quality indicators. In Proceedings of the 6th GIScience International Conference on Geographic Information Science, Zurich, Switzerland, 14–17 September 2010; p. 213. [Google Scholar]
- Mooney, P.; Corcoran, P. Characteristics of heavily edited objects in OpenStreetMap. Future Internet 2012, 4, 285–305. [Google Scholar] [CrossRef]
- Wiki. Available online: http://wiki.Openstreetmap.Org/wiki/planet.Osm (accessed on 25 July 2017).
- Blum, H. A transformation for extracting descriptors of shape. In Models for the Perception of Speech and Visual Form; MIT Press: Cambridge, MA, USA, 1967. [Google Scholar]
- Blum, H.; Nagel, R.N. Shape description using weighted symmetric axis features. Pattern Recognit. 1978, 10, 167–180. [Google Scholar] [CrossRef]
- Attali, D.; Boissonnat, J.-D.; Edelsbrunner, H. Stability and computation of medial axes-a state-of-the-art report. In Mathematical Foundations of Scientific Visualization, Computer Graphics, and Massive Data Exploration; Springer: Berlin, Germany, 2009; pp. 109–125. [Google Scholar]
- Armstrong, C.G. Modelling requirements for finite-element analysis. Comput. Aided Des. 1994, 26, 573–578. [Google Scholar] [CrossRef]
- Hisada, M.; Belyaev, A.G.; Kunii, T.L. A skeleton-based approach for detection of perceptually salient features on polygonal surfaces. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2002; pp. 689–700. [Google Scholar]
- Brandt, J.W.; Jain, A.K.; Algazi, V.R. Medial axis representation and encoding of scanned documents. J. Vis. Comm. Image Represent. 1991, 2, 151–165. [Google Scholar] [CrossRef]
- Gold, C.; Dakowicz, M. The crust and skeleton—Applications in GIS. In Proceedings of the 2nd International Symposium on Voronoi Diagrams in Science and Engineering, Seoul, Korea, 10–13 October 2005; pp. 33–42. [Google Scholar]
- Xia, H.; Tucker, P.G. Fast equal and biased distance fields for medial axis transform with meshing in mind. Appl. Math. Model. 2011, 35, 5804–5819. [Google Scholar] [CrossRef]
- Cheng, S.-W.; Funke, S.; Golin, M.; Kumar, P.; Poon, S.-H.; Ramos, E. Curve reconstruction from noisy samples. Comput. Geom. 2005, 31, 63–100. [Google Scholar] [CrossRef]
- Egenhofer, M.J.; Herring, J. Categorizing Binary Topological Relations between Regions, Lines, and Points in Geographic Databases; Technical Report; Department of Surveying Engineering, University of Maine: Orono, ME, USA, 1991. [Google Scholar]
- Egenhofer, M.J.; Franzosa, R.D. Point-set topological spatial relations. Int. J. Geogr. Inf. Syst. 1991, 5, 161–174. [Google Scholar] [CrossRef] [Green Version]
- ISO 19157:2013: Geographic information—Data Quality; International Organization for Standardization (ISO): Geneva, Switzerland, 2013.
- Chehreghan, A.; Ali Abbaspour, R. An assessment of spatial similarity degree between polylines on multi-scale, multi-source maps. Geocarto Int. 2017, 32, 471–487. [Google Scholar] [CrossRef]
- Abbas, I. Base de Données Vectorielles et Erreur Cartographique: Problèmes Posés par le Contrôle Ponctuel, une Méthode Alternative Fondée sur la Distance de Hausdorff: Le Contrôle Linéaire; ABES: Montpellier, France, 1994. [Google Scholar]
- Li, L.; Goodchild, M.F. An optimisation model for linear feature matching in geographical data conflation. Int. J. Image Data Fusion 2011, 2, 309–328. [Google Scholar] [CrossRef]
- Tong, X.; Liang, D.; Jin, Y. A linear road object matching method for conflation based on optimization and logistic regression. Int. J. Geogr. Inf. Sci. 2014, 28, 824–846. [Google Scholar] [CrossRef]
- Chehreghan, A.; Ali Abbaspour, R. An assessment of the efficiency of spatial distances in linear object matching on multi-scale, multi-source maps. Int. J. Geogr. Inf. Sci. 2017, 1–20. [Google Scholar] [CrossRef]
- Olteanu Raimond, A.-M.; Mustière, S. Data matching—A matter of belief. In Headway in Spatial Data Handling; Springer: Berlin, Germany, 2008; pp. 501–519. [Google Scholar]
- Zhang, M. Methods and Implementations of Road-Network Matching. Ph.D. Dissertation, Technical University of Munich, Munich, Germany, 2009. [Google Scholar]
- Veltkamp, R.C. Shape matching: Similarity measures and algorithms. In Proceedings of the International Conference onShape Modeling and Applications, Herzliya, Israel, 22–24 June 2001; IEEE: Piscataway, NJ, USA, 2001; pp. 188–197. [Google Scholar]
- Ali Abbaspour, R.; Chehreghan, A.; Karimi, A. Assessing the efficiency of shape-based functions and descriptors in multi-scale matching of linear objects. Geocarto Int. 2017, 33, 1–14. [Google Scholar] [CrossRef]
- Wang, M.; Li, Q.; Hu, Q.; Zhou, M. Quality analysis of OpenStreetMap data. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 2, W1. [Google Scholar]
- Samal, A.; Seth, S.; Cueto, K. A feature-based approach to conflation of geospatial sources. Int. J. Geogr. Inf. Sci. 2004, 18, 459–489. [Google Scholar] [CrossRef]
- Chehreghan, A.; Ali Abbaspour, R. A geometric-based approach for road matching on multi-scale datasets using a genetic algorithm. Cartogr. Geogr. Inf. Sci. 2017, 1–15. [Google Scholar] [CrossRef]
- Chehreghan, A.; Ali Abbaspour, R. A new descriptor for improving geometric-based matching of linear objects on multi-scale datasets. GISci. Remote Sens. 2017, 54, 836–861. [Google Scholar] [CrossRef]
- Dehghani, A.; Chehreghan, A.; Ali Abbaspour, R. Matching of urban pathways in a multi-scale database using fuzzy reasoning. Geod. Cartogr. 2017, 43, 92–104. [Google Scholar] [CrossRef]
- Mustière, S.; Devogele, T. Matching networks with different levels of detail. GeoInformatica 2008, 12, 435–453. [Google Scholar] [CrossRef]
- Fan, H.; Yang, B.; Zipf, A.; Rousell, A. A polygon-based approach for matching OpenStreetMap road networks with regional transit authority data. Int. J. Geogr. Inf. Sci. 2016, 30, 748–764. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques: Concepts and Techniques; Elsevier: New York, NY, USA, 2011. [Google Scholar]




















© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nasiri, A.; Ali Abbaspour, R.; Chehreghan, A.; Jokar Arsanjani, J. Improving the Quality of Citizen Contributed Geodata through Their Historical Contributions: The Case of the Road Network in OpenStreetMap. ISPRS Int. J. Geo-Inf. 2018, 7, 253. https://doi.org/10.3390/ijgi7070253
Nasiri A, Ali Abbaspour R, Chehreghan A, Jokar Arsanjani J. Improving the Quality of Citizen Contributed Geodata through Their Historical Contributions: The Case of the Road Network in OpenStreetMap. ISPRS International Journal of Geo-Information. 2018; 7(7):253. https://doi.org/10.3390/ijgi7070253
Chicago/Turabian StyleNasiri, Afsaneh, Rahim Ali Abbaspour, Alireza Chehreghan, and Jamal Jokar Arsanjani. 2018. "Improving the Quality of Citizen Contributed Geodata through Their Historical Contributions: The Case of the Road Network in OpenStreetMap" ISPRS International Journal of Geo-Information 7, no. 7: 253. https://doi.org/10.3390/ijgi7070253