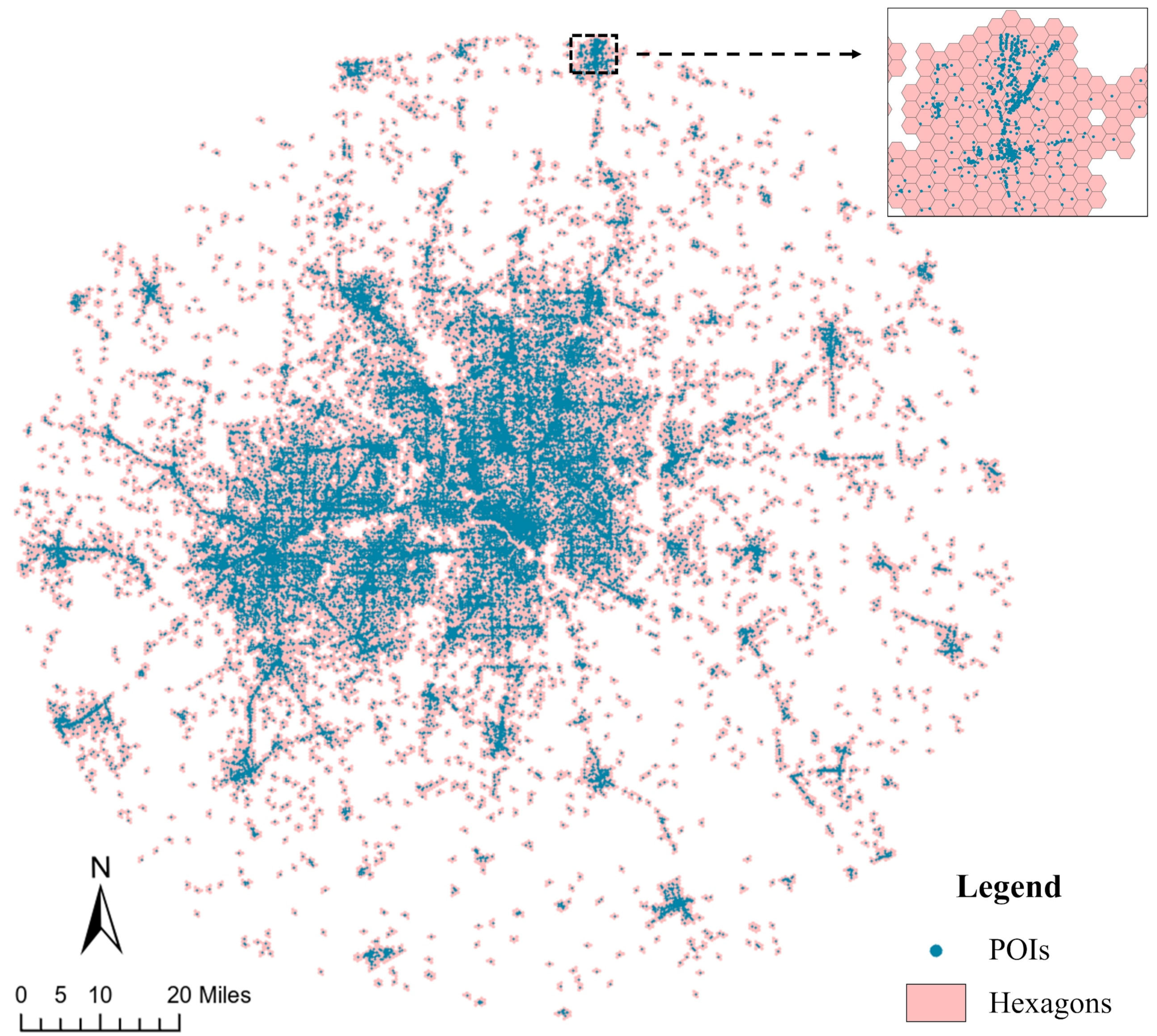
Each POI-hexagon served as a unit of analysis in our study to spatially associate places, people, and social event types. We developed a Bayesian Network model to explicitly compute the conditional probability of event occurrences, given the probabilities of sociodemographic quantities within a POI-hexagon and the POIs within 400 m of the POI-hexagon’s boundary. We then compared the Bayesian model with other conventional methods to affirm the advantages of Bayesian Network modeling.
We chose Bayesian Networks (BN), developed by Pearl [
34] and also known as belief networks or Bayes nets, to model probabilistic relationships among places, people, and social events for three reasons. First, popular machine learning methods, such as Random Forests (RF), Support Vector Machines (SVM), and Neural Networks (NN), despite their predictive power, are characterized by their black-box operations and limited interpretability to relate input variables to the output variable [
35]. BN can model multiple non-mutually exclusive distributions of predictive variables, but discriminative classifiers, like RF or SVM, are subject to the predicted probabilities summed to 100% [
36]. Second, generalized linear regression and its spatial extensions, such as spatial autoregressive (SAR) and conditional autoregressive (CAR) models, assume predefined relationships among variables and therefore lack the flexibility to model complex associations. BN, in contrast, requires no predefined rigid functional forms [
37]. The third reason is BN’s ability to maximize posterior queries to determine the most probable network configuration based on the learned joint distributions for a given observation.
4.1. Probability Modeling
BN modeling depends heavily on the underlying graphical structure that should align with the corresponding domain knowledge. In a graphical structure, nodes symbolize variables, and edges represent conditional dependencies between them. Network dependencies learned by data-driven approaches may sometimes contradict domain knowledge. For instance, in the context of this research, POIs support social events under the research assumption that an event takes place where material context and physical settings can meet the event’s functional needs. Therefore, the BN structure should direct edges from POI types to event types. Nevertheless, data-driven approaches may result in social events as precedents to POI types. While it is possible that a POI was built to host a preplanned event (such as building an arena for an Olympic game), this research is limited to using POIs to predict social events, as our interest is in the implications of what places we have in a community and what people do and relate to in the community.
To examine the validity of this research assumption, POI preceding social events, we calculated the presence rates of social events in POI-hexagons to show the POI effects on event presence. For social events, most POI presences are associated with higher event presence rates (
Figure A1). The only exception was with Management and Remediation Services (MgmEnterp) and Agriculture, Forestry, Fishing and Hunting (AgriFish) POI-hexagons. In contrast, the effects of social event types on POI presence are negligible (
Figure A2). Subsequently, we adopted the network structure with directed edges from POI types to social event types (
Figure 4).
A social event cannot take place without participants. Therefore, population characteristics can affect what kinds of social events are likely to occur in a community. We acquired five-year (2017–2021) estimates of demographic and socioeconomic (henceforth simply sociodemographic) data at the census tract level from American Community Surveys (ACS). The selected ACS variables included population density per square meter; age brackets of under 18, 18–44, 45–64, and over 64 years old; race categories of White, Black, Asian, and Other; educational attainment levels of completing middle school, high school, or college; per capita income; and poverty rates, for a total of 14 sociodemographic variables. We calculated the area-weighted average of each variable in individual POI-hexagons. These sociodemographic variables and POI-type probabilities are input variables to predict the probabilities of social events in every POI-hexagon. Micro-locales would be identified if a particular POI type exhibited robust predictability for a specific social event type. Spatial clusters of POI-hexagons with high probabilities of social event types of interest suggest meso- or macro-locales.
The added sociodemographic variables necessitated the consideration of a condition in which the two variables (POI types and social event types) become dependence-separated (i.e., d-separated) in the BN.
Figure 5 gives a d-separated example of a directed path from X
1 to S
1 through X
2. If X
2 is not an empty set, the path X
1 to S
1 is blocked by conditioning on the intermediary X
2; hence, X
1 and S
1 are dependence-separated upon X
2. Structural revisions to the Bayesian network aim to identify sociodemographic variables (X
1) that can mediate previously independent POI types (X
2) to a specific type of social event (S
1) and, therefore, improve the Bayesian network model’s predictability of social events. For illustrative purposes, let us examine the religious sociodemographic variable (e.g., Christianity, Islam, Hinduism) denoted as X
1. These variables are often associated with the presence of specific POIs, represented as X
2, such as churches, mosques, or temples. Consequently, the type of religious events (S
1) can be directly deduced from the type of worship place (POI), obviating the need for additional sociodemographic data in this context. In such instances, X
1 is deemed d-separated from S
1, with the observation of X
2. Conversely, in the absence of POI data, the local sociodemographic variables can still facilitate inferences about likely social events. Under these circumstances, X
1 is d-connected to S
1 in the absence of X
2 observations. An alternative, X
2 to S
1 through X
1, is also possible; some POI types may condition the dependence between sociodemographic variables and social event types. Because all hexagons under consideration have POIs and sociodemographic values (i.e., not empty sets), the proposed Bayesian Network model considered both d-separation alternatives.
BN modeling needs to account for the soundness and completeness of d-separation [
38]. Given that all predictors, encompassing both local sociodemographic and POIs, are observable in this study, dependencies among these variables will form d-separation to social events nodes, which will inflate the computational load without improving model performance. Consequently, we constructed a graph with direct edges from all predictors to social events nodes, as the priori assumption in BN. In practice, the validity of these edges was evaluated using mutual information, ensuring the accuracy of the dependency assumptions [
39]. This study considered 19 POI types, 14 demographic and sociodemographic variables, and 7 social event types. The conditional probability of presence for a given social event type (S
i) in a POI-hexagon is subject to the probabilities of a given possible state defined by the 33 variables characterizing POI types and sociodemographic conditions:
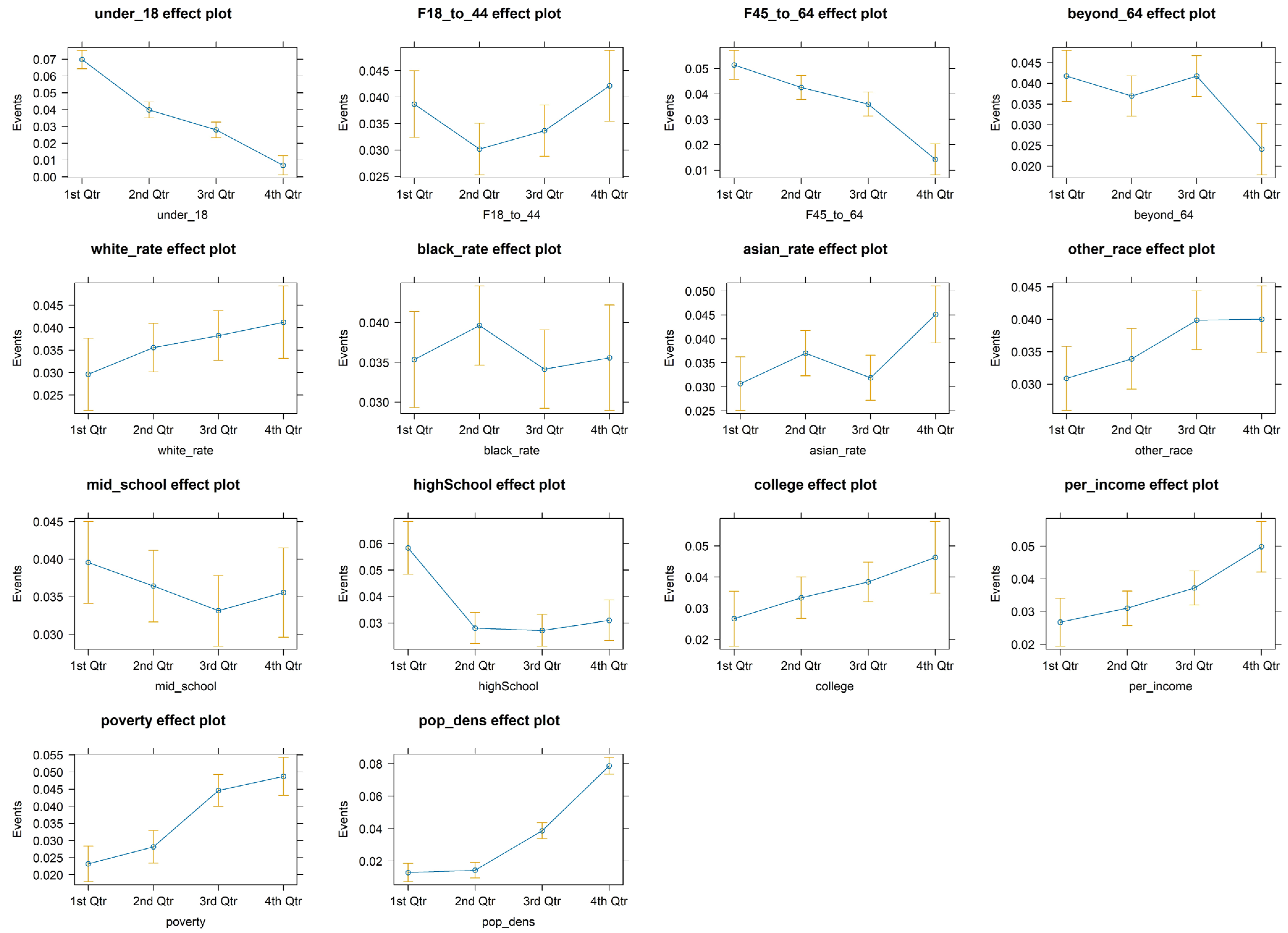
We treated POI types as binary variables to encode their presence (=1) or absence (=0) for each POI-hexagon. Sociodemographic variables were continuous values, and it would be infeasible to consider all possible combinations of unique values. As such, we transformed these sociodemographic data into categorical variables based on the quantile distributions of the respective variables. The percentages of POI-hexagons with social events varied across quantiles in each demographic and socioeconomic variable (see effects plots in
Figure A3). Most of these variables as quantiles exhibited negative or positive effects on the presence of social events, albeit with different degrees of uncertainty. For instance, increasing quantiles of residents under 18 decreased the percentage of POI-hexagons with social events from 8% to 1% with high confidence intervals across all four quartiles. The decreasing effects implied that the majority of social events from Meetup in the study area were for adult participants. On the other hand, middle school attainment and the percentage of the Black population showed wide confidence intervals. Therefore, the quantiles of neither variable had robust effects on the presence of social events.
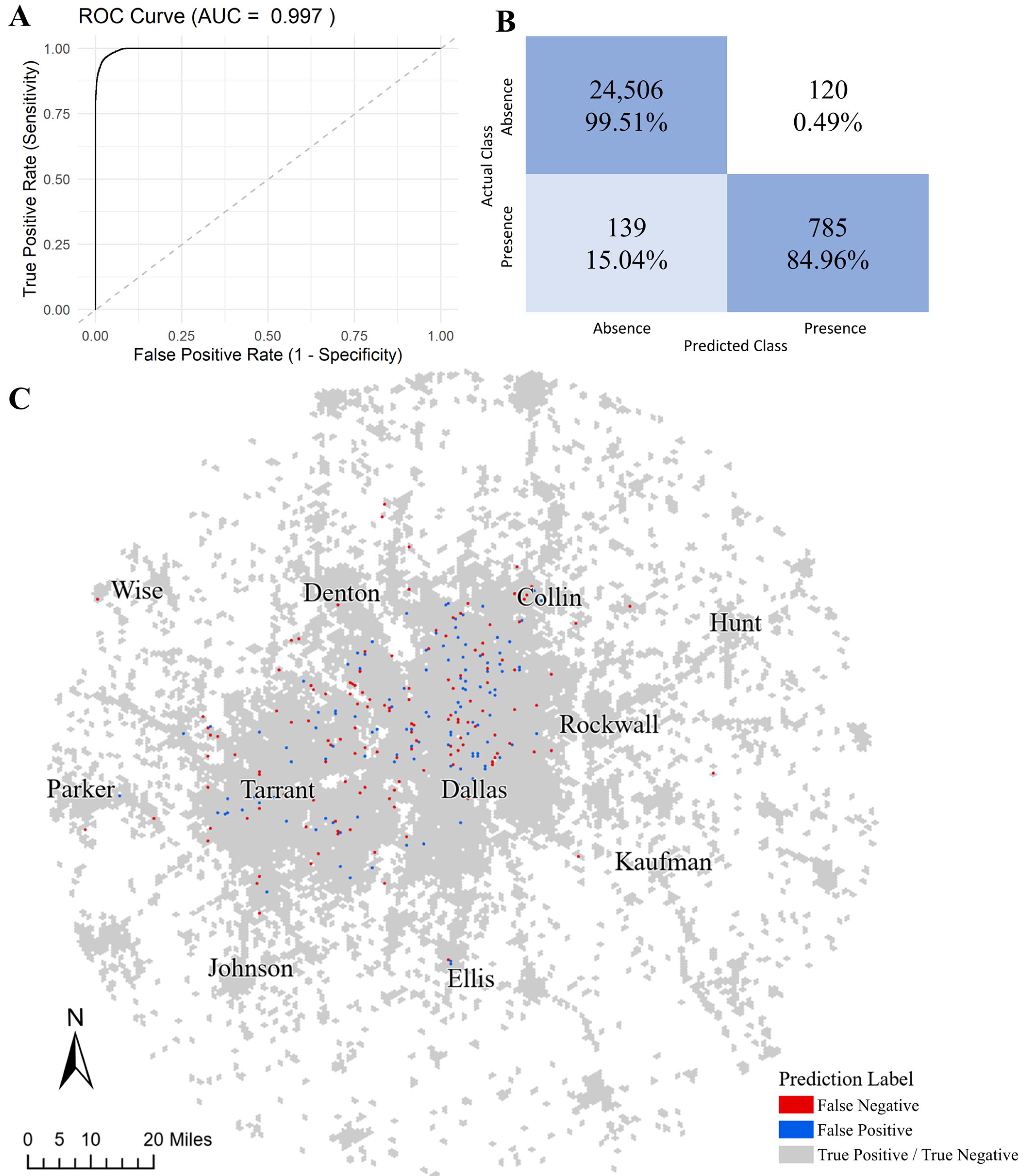
We applied a forward stepwise model selection approach to rank the predictive contributions of all 33 variables (19 POIs and 14 demographic and socioeconomic variables) under linear assumptions. For each iteration, the stepwise model selection added each variable into the model prediction and then compared the model performance with each added variable based on improvements in reducing the residual sum of squares and the Akaike Information Criterion (AIC) measure. While the study considered 33 variables, the results showed increases in the residual sum of square and AIC measures in the 27th iteration (
Table 3).
Improvements to model fit in residuals and AIC decreased as the number of variables increased and became negligible around the 20th rank. For computability, we considered the first 20 variables, 14 POI types, and 6 sociodemographic variables to build a BN model for predicting the probability of the presence of each social event type: a total of seven probabilities for seven event types in a local environment (e.g., a POI-hexagon in the analysis). This resulted in approximately 67 million states for conditional probabilities: . The final multivariate linear model accounted for 13.0–14.6% (95% confidence interval) of the spatial variance in social events, providing a baseline fit prior to BN modeling.
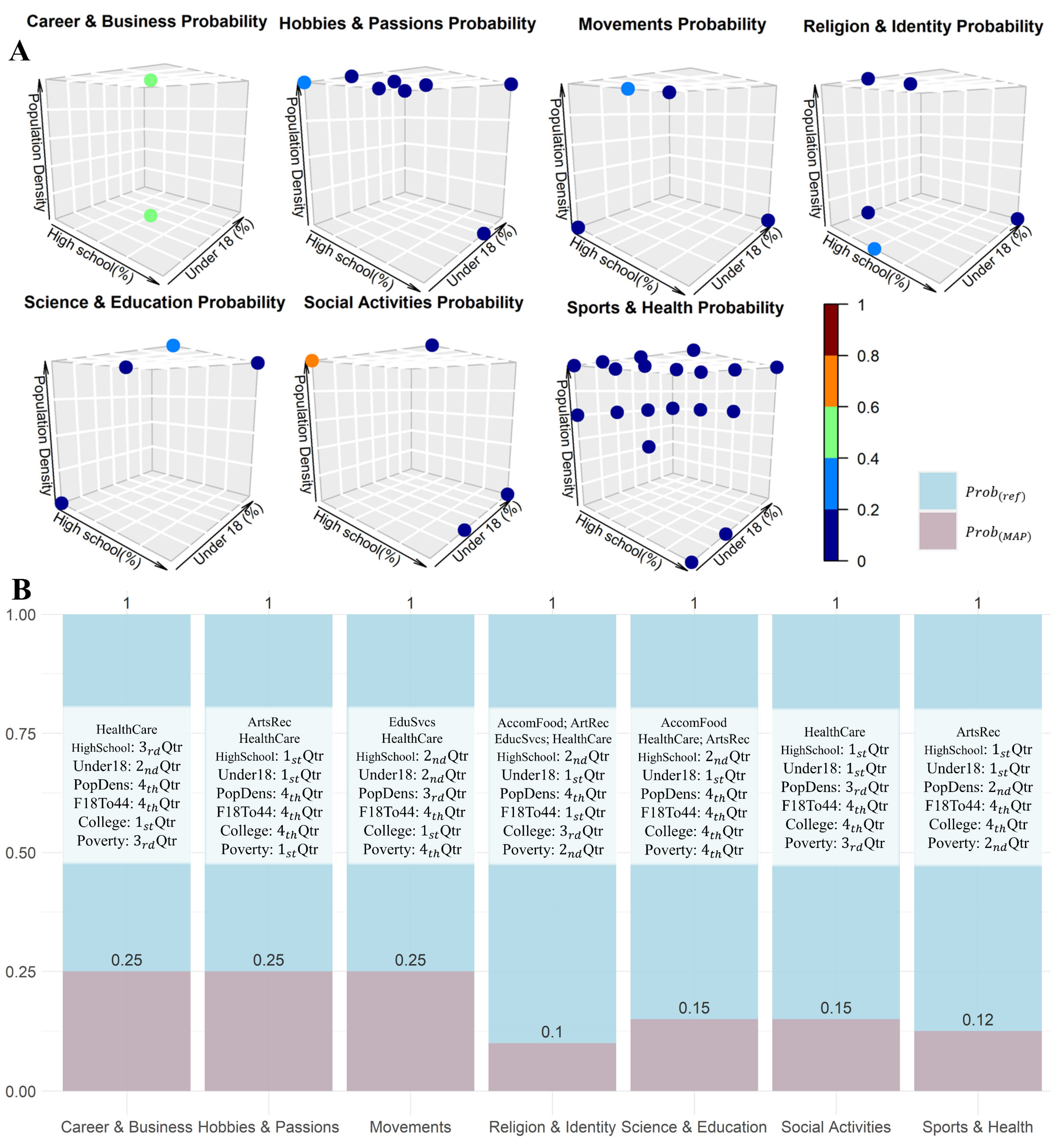
To further explore the influences on social event likelihoods, we applied conditional probability distributions (CPDs), a foundational statistical tool capturing event probabilities under specific conditions. This method models event probabilities in context-specific ways, offering insights into the collective contributions of different combinations of factors to social events [
40,
41]. Additionally, we utilized the Maximum A Posteriori (MAP) query to identify the most probable combinations of POIs and sociodemographic attributes in areas hosting social events. MAP, rooted in Bayesian statistics, estimates optimal parameter sets from observed data, effectively pinpointing pivotal factors facilitating social events. This approach is especially informative in urban studies, aiding urban planners and policymakers in making informed decisions about community engagement and urban development [
42]. These statistical techniques estimated event probability distributions under varying conditions, revealed the critical contextual determinants conducive to social events, and drew valuable insights into POIs as a social infrastructure that can enhance the fabric of urban community life [
43].




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}