

LBS Tag Cloud: A Centralized Tag Cloud for Visualization of Points of Interest in Location-Based Services

Abstract
:1. Introduction
2. Related Work
2.1. Visualization of Point Data
2.2. From Tag Cloud to Tag Map
2.2.1. Post-Association Tag Map
2.2.2. Pre-Association Tag Map
3. Methodology
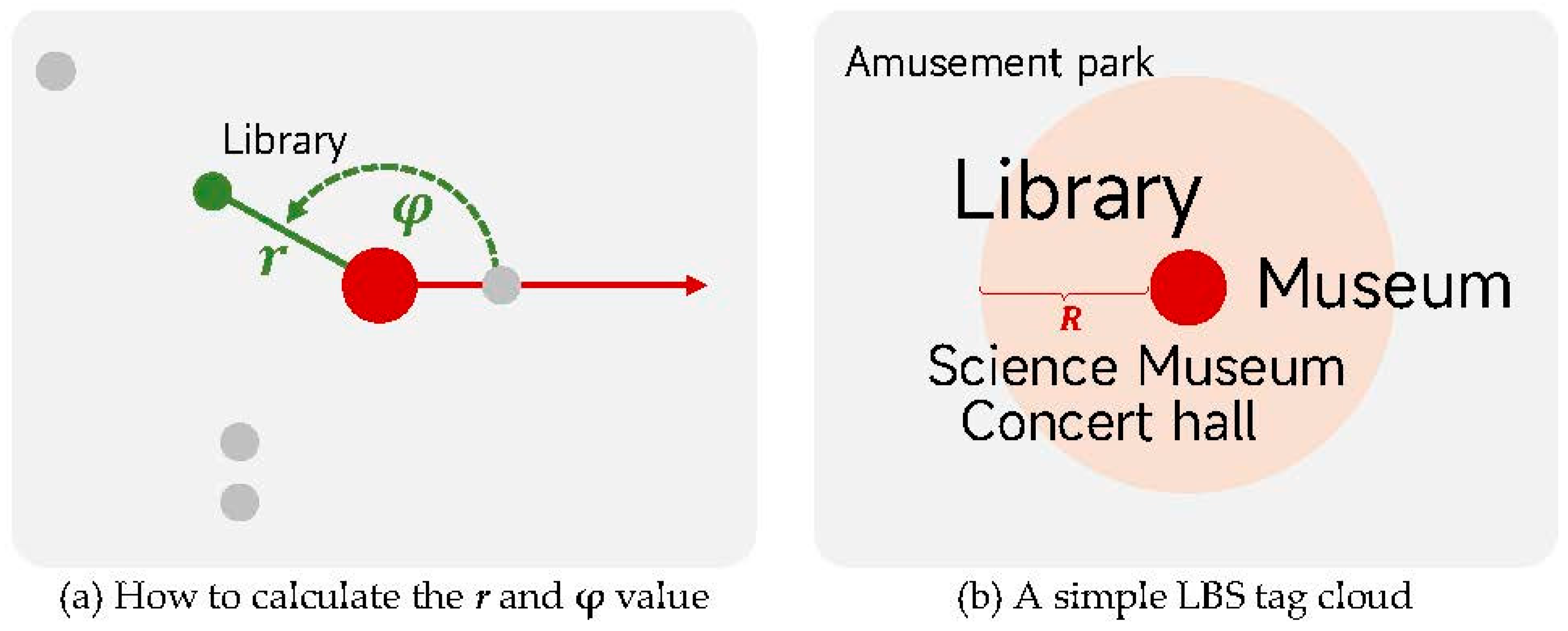
3.1. The Conceptual Model of LBS Tag Cloud
3.2. The Layout Algorithm of LBS Tag Cloud
3.2.1. The Design Idea of the Layout Algorithm
3.2.2. Steps and Processes of the Layout Algorithm
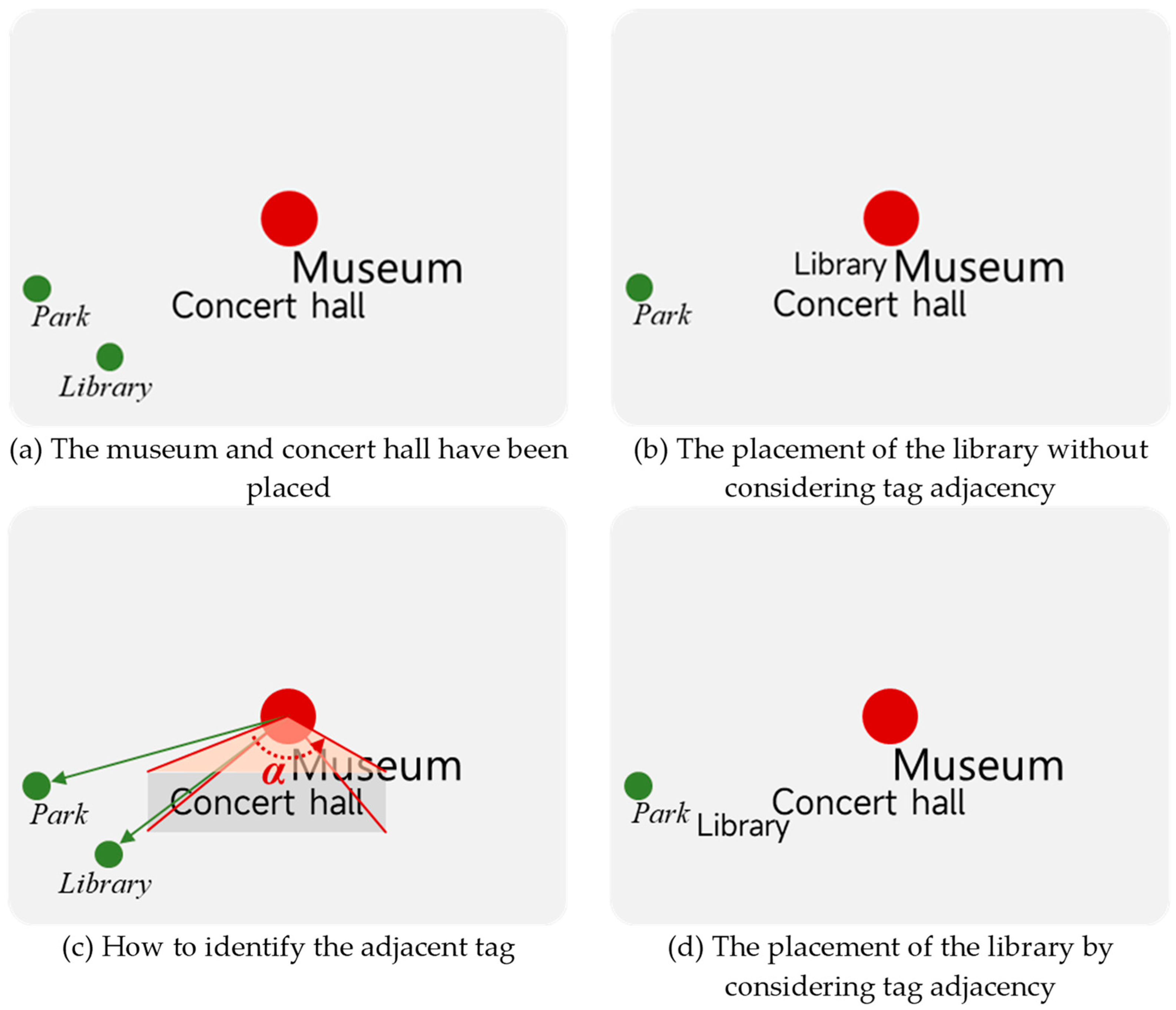
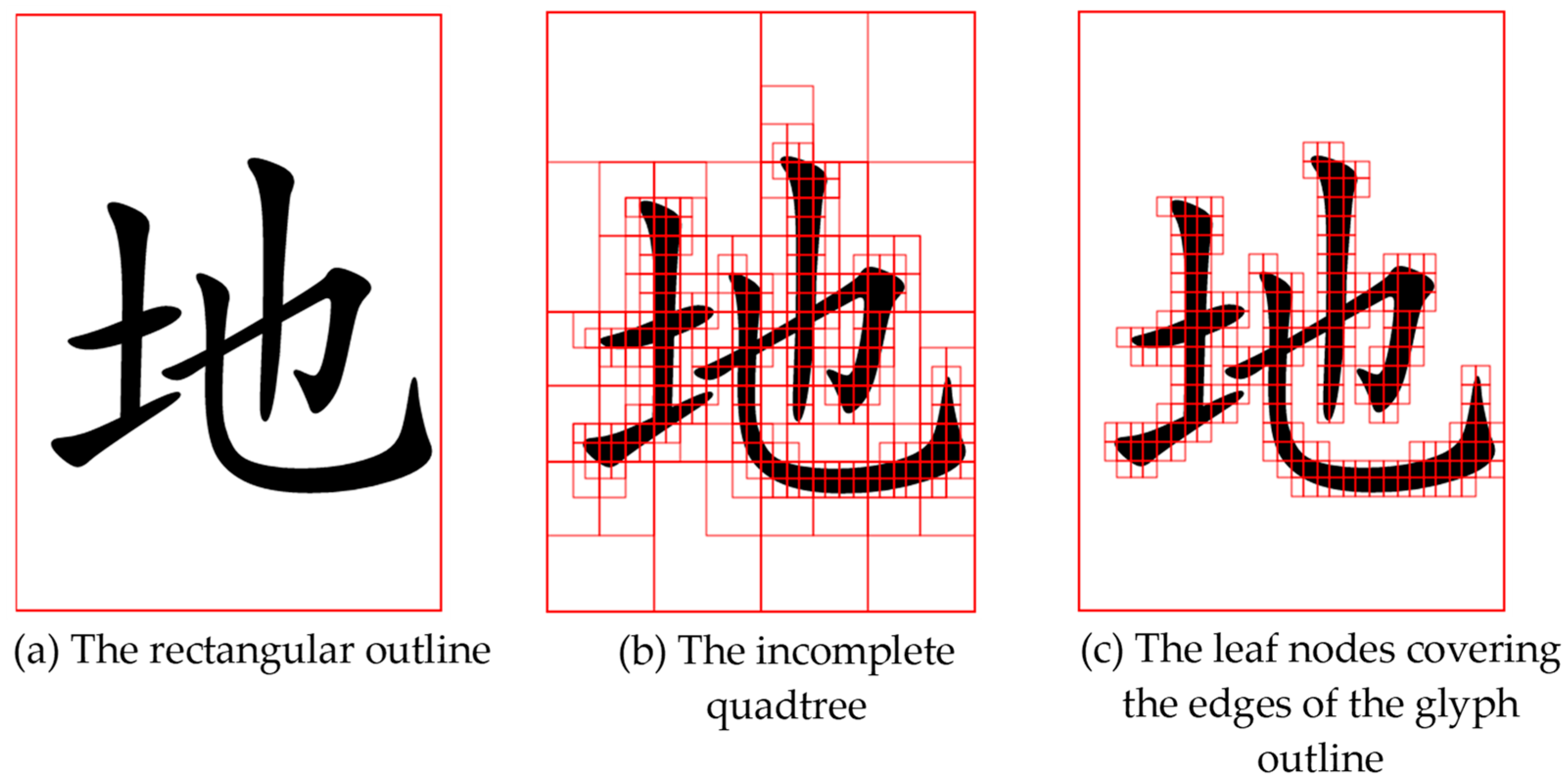
3.2.3. Tag Collision Detection
4. Experiment Setup
5. Results and Discussion
5.1. LBS Tag Cloud for All Tourist Attractions
- The size of the initial canvas is 2000 × 1000 px, and the background is black.
- The number of user comments is taken as a proxy indicator of the popularity of the tourist attraction, and a simple assumption is made that the more comments, the higher the popularity of the attraction. The value is divided into five levels, and the correspondence with the font size is established. The lowest level corresponds to the minimum font size of 10 px, the highest level corresponds to the maximum font size of 30 px, and the adjacent level font size difference is 5 px.
- The minimum cell size of a leaf node in quadtree segmentation is 5 px.
- The value of parameter R is 200 px, while the value of parameter Dfar is taken for 60 min.
- All 123 attractions are completely expressed, and each attraction can be uniquely identified by its name. Users can quickly understand what attractions are around them.
- Attractions with larger font sizes are easier to attract users’ attention and bring users “more important” psychological feelings, which is in line with the representation needs of tourist attractions.
- Most attractions with short travel times are placed close to the central point, while attractions with longer travel times are more often placed in peripheral areas. The relative direction of the attraction to the central point also remains unchanged. However, it should be noted that the positional relationship of the tags in the tag cloud is an order relationship, which can only represent the order of new and far and cannot convey the precise travel time. In addition, such a relationship only applies to tags in the same or adjacent directions, such as “Mulan Grassland” which is farther away than “Peace Park”. For tags in different directions, the relationship between near and far is not comparable; for example, the “Yellow Crane Tower” at the bottom left of the central word looks significantly farther away than the “Hubei Provincial Museum” at the bottom right, which is inconsistent with the facts.
5.1.1. Introduction of the Color Variable
5.1.2. Color Variable for More Generalized Relationships
5.2. LBS Tag Cloud for Attractions with Convenient Transportation
5.3. LBS Tag Cloud for High-Quality Tourist Attractions
6. Usability Evaluation
6.1. LBS Tag Cloud versus Existing Methods
- More POIs can be displayed. The current map extent has completely covered the main urban area of Wuhan, but there are only 10 numeric symbols and about 30 circular symbols, and the number of attractions that can be displayed is much smaller than the LBS tag cloud. In addition, the annotations for visible attractions are not fully displayed. The list on the left can be used to view the names of the numeric symbols one by one; however, the names of circular symbols cannot be viewed.
- Global context and local details can be maintained. Users can zoom in on the map to explore more attractions, but at the same time, some attractions will fall out of the viewport, so users need to zoom and pan frequently, and in this process, it is difficult for users to consider the local details and global context of the map. In contrast, the LBS tag cloud contains both adjacent and distant POIs, so users can not only understand the distribution of POIs at the macro level but also explore the details of each POI at the micro level. If the interactive functions of zooming and panning are developed for the LBS tag cloud in the future, a better information communication effect can be achieved.
- The relationship between the user and the POI can be represented. The rich and powerful visual variables in the tag cloud can fully express the multi-dimensional attributes of POI, especially the relationship between the POI and the user. Conversely, in Figure 13, neither attributes nor relationships are well expressed. The number in the numeric symbol is positively correlated with the popularity of the attraction, which can guide users to pay attention to the popular attractions but also require them to browse sequentially in the left list. The Euclidean distance from each POI can be estimated based on the geographical location of the symbol, but the obstruction of natural barriers and artificial features will cause considerable estimation errors. In addition, travel time and other meaningful relationships are difficult to estimate.
- The graphic layout is simple and pure. In the LBS tag cloud, there are only text tags and no other graphic symbols that may cause interference. Users who know the text can quickly understand the meaning of the tag cloud. In stark contrast, there are too many features on the web map, resulting in cumbersome visualizations that interfere with users quickly capturing key information.
6.2. User Experiments
6.3. Summarization and Future Work
- Text tags are simple in form but also rich in expression. The tag cloud only contains tags and does not contain complex graphic symbols, which simplifies the cognitive process on the one hand and avoids the occupation of space by graphic symbols on the other. However, the visual variables commonly used in the text symbol are rich enough that, in addition to font size, color, and position, other visual variables such as font, italic, luminescence, shading, etc., can also be combined with the LBS tag cloud to express meaningful multivariate information.
- Coupling of first-order attributes with second-order attributes. LBS tag clouds can not only represent the attributes of the POI but also convey the relationship between the POI and the user’s location. It is worth mentioning that the visual variable mapping scheme adopted by the LBS tag cloud is flexible. In the LBS tag cloud containing all attractions, a typical visual variable mapping scheme in line with people’s cognitive habits is designed, which uses font size to express the first-order “popularity” of the POI and color and position to jointly express the second-order “convenience”.
- Overview and detailed information can be represented together. When using the LBS tag cloud, users can quickly overview all POIs and understand the macro distribution without any complex operations. At the same time, the detailed information about each POI can be quickly identified through its corresponding tag.
- The number of tags that fit best. While the LBS tag cloud can show more POIs than the web map, there is an upper limit. In the user experiment, some subjects have suggested that the tags in the LBS tag cloud are too dense, causing information overload. Exploring the optimal number or density of tags will be the focus of subsequent usability assessment research.
- What kind of user interaction should be designed? The current LBS tag cloud only supports simple user interaction, and in the future, operations such as clicking and zooming will be added to the LBS tag cloud based on the usage logic of touchscreen devices to provide richer information content.
- Optimization and innovation of layout methods. On the one hand, it takes a long time to generate an LBS tag cloud. Each tag takes about 1 s for radial displacement and collision detection. Such a speed obviously does not meet the requirements of real-time applications. and the efficiency of the current layout algorithm needs to be optimized. On the other hand, this study is just a simple attempt at a layout method based on radial displacement, and many studies can be conducted in this regard, such as radial displacement to change the radial coordinates; can the angular coordinates of the tag be changed? If there are multiple centers, how should the tags be placed? How to employ the relationship between POIs to determine placement, etc.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schiller, J.; Voisard, A. Location-Based Services; Elsevier: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Jiang, B.; Yao, X. Location Based Services and GIS in Perspective. In Location Based Services and Telecartography; Gartner, G., Cartwright, W., Peterson, M.P., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 27–45. [Google Scholar]
- Anagnostopoulos, V.; Havlena, M.; Kiefer, P.; Giannopoulos, I.; Schindler, K.; Raubal, M. Gaze-Informed location-based services. Int. J. Geogr. Inf. Sci. 2017, 31, 1770–1797. [Google Scholar] [CrossRef]
- Chuang, H.-M.; Chang, C.-H.; Kao, T.-Y.; Cheng, C.-T.; Huang, Y.-Y.; Cheong, K.-P. Enabling maps/location searches on mobile devices: Constructing a POI database via focused crawling and information extraction. Int. J. Geogr. Inf. Sci. 2016, 30, 1405–1425. [Google Scholar] [CrossRef]
- Liu, K.; Yin, L.; Lu, F.; Mou, N. Visualizing and exploring POI configurations of urban regions on POI-type semantic space. Cities 2020, 99, 102610. [Google Scholar] [CrossRef]
- Cai, L.; Xu, J.; Liu, J.; Pei, T. Integrating spatial and temporal contexts into a factorization model for POI recommendation. Int. J. Geogr. Inf. Sci. 2018, 32, 524–546. [Google Scholar] [CrossRef]
- Liu, Y.; Seah, H.S. Points of interest recommendation from GPS trajectories. Int. J. Geogr. Inf. Sci. 2015, 29, 953–979. [Google Scholar] [CrossRef]
- Gröbe, M.; Burghardt, D. Micro diagrams: Visualization of categorical point data from location-based social media. Cartogr. Geogr. Inf. Sci. 2020, 47, 305–320. [Google Scholar] [CrossRef]
- Gedicke, S.; Bonerath, A.; Niedermann, B.; Haunert, J.H. Zoomless Maps: External Labeling Methods for the Interactive Exploration of Dense Point Sets at a Fixed Map Scale. IEEE Trans. Vis. Comput. Graph. 2021, 27, 1247–1256. [Google Scholar] [CrossRef] [PubMed]
- Niedermann, B.; Haunert, J.-H. Focus+context map labeling with optimized clutter reduction. Int. J. Cartogr. 2019, 5, 158–177. [Google Scholar] [CrossRef]
- Touya, G. LostInZoom. Available online: https://lostinzoom.github.io/home/ (accessed on 10 August 2023).
- Beilschmidt, C.; Mattig, M.; Fober, T.; Seeger, B. An efficient aggregation and overlap removal algorithm for circle maps. GeoInformatica 2019, 23, 473–498. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, L.; Long, Y.; Zheng, Y. Real-Time Displacement of Point Symbols Based on Spatial Distribution Characteristics. ISPRS Int. J. Geo-Inf. 2019, 8, 426. [Google Scholar] [CrossRef]
- Yuan, K.; Cheng, X.; Gui, Z.; Li, F.; Wu, H. A quad-tree-based fast and adaptive Kernel Density Estimation algorithm for heat-map generation. Int. J. Geogr. Inf. Sci. 2019, 33, 2455–2476. [Google Scholar] [CrossRef]
- Gedicke, S.; Jabrayilov, A.; Niedermann, B.; Mutzel, P.; Haunert, J.-H. Point feature label placement for multi-page maps on small-screen devices. Comput. Graph. 2021, 100, 66–80. [Google Scholar] [CrossRef]
- Xiao, Y.; Ai, T.; Yang, M.; Zhang, X. A Multi-Scale Representation of Point-of-Interest (POI) Features in Indoor Map Visualization. ISPRS Int. J. Geo-Inf. 2020, 9, 239. [Google Scholar] [CrossRef]
- Viégas, F.B.; Wattenberg, M.; Feinberg, J. Participatory Visualization with Wordle. IEEE Trans. Vis. Comput. Graph. 2009, 15, 1137–1144. [Google Scholar] [CrossRef] [PubMed]
- Viégas, F.B.; Wattenberg, M. TIMELINES Tag clouds and the case for vernacular visualization. Interactions 2008, 15, 49–52. [Google Scholar] [CrossRef]
- Seifert, C.; Kump, B.; Kienreich, W.; Granitzer, G.; Granitzer, M. On the Beauty and Usability of Tag Clouds. In Proceedings of the 2008 12th International Conference Information Visualisation, London, UK, 9–11 July 2008; pp. 17–25. [Google Scholar]
- Felix, C.; Franconeri, S.; Bertini, E. Taking Word Clouds Apart: An Empirical Investigation of the Design Space for Keyword Summaries. IEEE Trans. Vis. Comput. Graph. 2018, 24, 657–666. [Google Scholar] [CrossRef] [PubMed]
- Hearst, M.A.; Pedersen, E.; Patil, L.; Lee, E.; Laskowski, P.; Franconeri, S. An Evaluation of Semantically Grouped Word Cloud Designs. IEEE Trans. Vis. Comput. Graph. 2020, 26, 2748–2761. [Google Scholar] [CrossRef] [PubMed]
- Schrammel, J.; Leitner, M.; Tscheligi, M. Semantically structured tag clouds: An empirical evaluation of clustered presentation approaches. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 8 October 2009; pp. 2037–2040. [Google Scholar]
- Lee, B.; Riche, N.H.; Karlson, A.K.; Carpendale, S. SparkClouds: Visualizing Trends in Tag Clouds. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1182–1189. [Google Scholar] [CrossRef]
- Knittel, J.; Koch, S.; Ertl, T. PyramidTags: Context-, Time- and Word Order-Aware Tag Maps to Explore Large Document Collections. IEEE Trans. Vis. Comput. Graph. 2021, 27, 4455–4468. [Google Scholar] [CrossRef]
- Liu, S.; Wang, X.; Collins, C.; Dou, W.; Ouyang, F.; El-Assady, M.; Jiang, L.; Keim, D.A. Bridging Text Visualization and Mining: A Task-Driven Survey. IEEE Trans. Vis. Comput. Graph. 2019, 25, 2482–2504. [Google Scholar] [CrossRef]
- Alexander, E.C.; Chang, C.C.; Shimabukuro, M.; Franconeri, S.; Collins, C.; Gleicher, M. Perceptual Biases in Font Size as a Data Encoding. IEEE Trans. Vis. Comput. Graph. 2018, 24, 2397–2410. [Google Scholar] [CrossRef] [PubMed]
- Bereuter, P.; Weibel, R. Real-time generalization of point data in mobile and web mapping using quadtrees. Cartogr. Geogr. Inf. Sci. 2013, 40, 271–281. [Google Scholar] [CrossRef]
- Luboschik, M.; Schumann, H.; Cords, H. Particle-based labeling: Fast point-feature labeling without obscuring other visual features. IEEE Trans. Vis. Comput. Graph. 2008, 14, 1237–1244. [Google Scholar] [CrossRef] [PubMed]
- Hu, M.; Wongsuphasawat, K.; Stasko, J. Visualizing Social Media Content with SentenTree. IEEE Trans. Vis. Comput. Graph. 2017, 23, 621–630. [Google Scholar] [CrossRef] [PubMed]
- Jaffe, A.; Naaman, M.; Tassa, T.; Davis, M. Generating summaries and visualization for large collections of geo-referenced photographs. In Proceedings of the 8th ACM International Workshop on Multimedia Information Retrieval, Santa Barbara, CA, USA, 26–27 October 2006; pp. 89–98. [Google Scholar]
- Slingsby, A.; Dykes, J.; Wood, J.; Clarke, K. Interactive Tag Maps and Tag Clouds for the Multiscale Exploration of Large Spatio-temporal Datasets. In Proceedings of the 2007 11th International Conference Information Visualization (IV ‘07), Zurich, Switzerland, 4–6 July 2007; pp. 497–504. [Google Scholar]
- Wood, J.; Dykes, J.; Slingsby, A.; Clarke, K. Interactive Visual Exploration of a Large Spatio-temporal Dataset: Reflections on a Geovisualization Mashup. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1176–1183. [Google Scholar] [CrossRef] [PubMed]
- Reckziegel, M.; Cheema, M.F.; Scheuermann, G.; Janicke, S.; Scheuermann, G.; Cheema, M.F.; Reckziegel, M.; Janicke, S. Predominance Tag Maps. IEEE Trans. Vis. Comput. Graph. 2018, 24, 1893–1904. [Google Scholar] [CrossRef] [PubMed]
- Paelke, V.; Dahinden, T.; Eggert, D.; Mondzech, J. Location based context awareness through tag-cloud visualizations. In Proceedings of the Joint International Conference on Theory, Data Handing and Modeling in Geo Spatial Information Science, Hong Kong, China, 26–28 May 2010. [Google Scholar]
- Cidell, J. Content clouds as exploratory qualitative data analysis. Area 2010, 42, 514–523. [Google Scholar] [CrossRef]
- Ferreira, N.; Lins, L.; Fink, D.; Kelling, S.; Wood, C.; Freire, J.; Silva, C. BirdVis: Visualizing and Understanding Bird Populations. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2374–2383. [Google Scholar] [CrossRef]
- Thom, D.; Bosch, H.; Koch, S.; Worner, M.; Ertl, T. Spatiotemporal anomaly detection through visual analysis of geolocated Twitter messages. In Proceedings of the 2012 IEEE Pacific Visualization Symposium, Songdo, Republic of Korea, 28 February–2 March 2012; pp. 41–48. [Google Scholar]
- Buchin, K.; Creemers, D.; Lazzarotto, A.; Speckmann, B.; Wulms, J. Geo word clouds. In Proceedings of the 2016 IEEE Pacific Visualization Symposium (PacificVis), Taipei, Taiwan, China, 19–22 April 2016; pp. 144–151. [Google Scholar]
- Bhore, S.; Ganian, R.; Li, G.; Nöllenburg, M.; Wulms, J. Worbel: Aggregating Point Labels into Word Clouds. In Proceedings of the 29th International Conference on Advances in Geographic Information Systems, Beijing, China, 2–5 November 2021; pp. 256–267. [Google Scholar]
- Nguyen, D.Q.; Schumann, H. Taggram: Exploring Geo-data on Maps through a Tag Cloud-Based Visualization. In Proceedings of the 2010 14th International Conference Information Visualisation, Washington, DC, USA, 26–29 July 2010; pp. 322–328. [Google Scholar]
- De Chiara, D.; Del Fatto, V.; Sebillo, M.; Tortora, G.; Vitiello, G. Tag@Map: A Web-Based Application for Visually Analyzing Geographic Information through Georeferenced Tag Clouds. In Proceedings of the Web and Wireless Geographical Information Systems: 11th International Symposium, W2GIS 2012, Naples, Italy, 12–13 April 2012; pp. 72–81. [Google Scholar]
- Martin, M.E.; Schuurman, N. Area-Based Topic Modeling and Visualization of Social Media for Qualitative GIS. Ann. Am. Assoc. Geogr. 2017, 107, 1028–1039. [Google Scholar] [CrossRef]
- Yang, N.; MacEachren, A.M.; Yang, L. TIN-based Tag Map Layout. Cartogr. J. 2019, 56, 101–116. [Google Scholar] [CrossRef]
- Yang, N.; MacEachren, A.M.; Domanico, E. Utility and usability of intrinsic tag maps. Cartogr. Geogr. Inf. Sci. 2020, 47, 291–304. [Google Scholar] [CrossRef]
- Forsch, A.; Dehbi, Y.; Niedermann, B.; Oehrlein, J.; Rottmann, P.; Haunert, J.-H. Multimodal travel-time maps with formally correct and schematic isochrones. Trans. GIS 2021, 25, 3233–3256. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Visualization Capabilities | LBS Tag Cloud | Web Maps | Zoomless Map | Focus + Context |
|---|---|---|---|---|---|
| 1 | The names of all POIs are visible | Yes | No | No | No |
| 2 | Multi-dimensional attributes visualization | Yes | By a list | Yes | No |
| 3 | Flexible combination of visual variables | Yes | Yes | No | Yes |
| 4 | Accurate geographic location | No | Yes | Yes | No |
| 5 | Visualization of the relationship with the user’s location | Yes | By a list | No | No |
| 6 | The number of POIs that can be clearly visualized | About 100 | About 20 | Unknown | Unknown |
| 8 | Showing both the whole and the part | Yes | By zooming | By paging | Yes |
| 6 | Georeference provided by topographic features | No | Yes | Yes | Yes |
| 9 | Interference from topographic features | No | Yes | Yes | Yes |
| 10 | User interaction | Simple | Rich | Rich | Simple |
| 11 | Language-independent | No | Yes | Yes | Yes |
| Indicator | Aesthetics | Compactness | Recognizability | Layout Satisfaction | Task Completion |
|---|---|---|---|---|---|
| Mean | 6.37 | 7.74 | 7.04 | 6.96 | 7.44 |
| Median | 6 | 8 | 7 | 7 | 8 |
| Mode | 6 | 8 | 8 | 7 | 8 |
| Standard Deviation | 1.86 | 1.77 | 2.00 | 1.95 | 1.82 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, X.; Liu, Z.; Wu, H.; Xiao, H. LBS Tag Cloud: A Centralized Tag Cloud for Visualization of Points of Interest in Location-Based Services. ISPRS Int. J. Geo-Inf. 2023, 12, 360. https://doi.org/10.3390/ijgi12090360
Cheng X, Liu Z, Wu H, Xiao H. LBS Tag Cloud: A Centralized Tag Cloud for Visualization of Points of Interest in Location-Based Services. ISPRS International Journal of Geo-Information. 2023; 12(9):360. https://doi.org/10.3390/ijgi12090360
Chicago/Turabian StyleCheng, Xiaoqiang, Zhongyu Liu, Huayi Wu, and Haibo Xiao. 2023. "LBS Tag Cloud: A Centralized Tag Cloud for Visualization of Points of Interest in Location-Based Services" ISPRS International Journal of Geo-Information 12, no. 9: 360. https://doi.org/10.3390/ijgi12090360