



Black Carbon Concentration Estimation with Mobile-Based Measurements in a Complex Urban Environment


Abstract
:1. Introduction
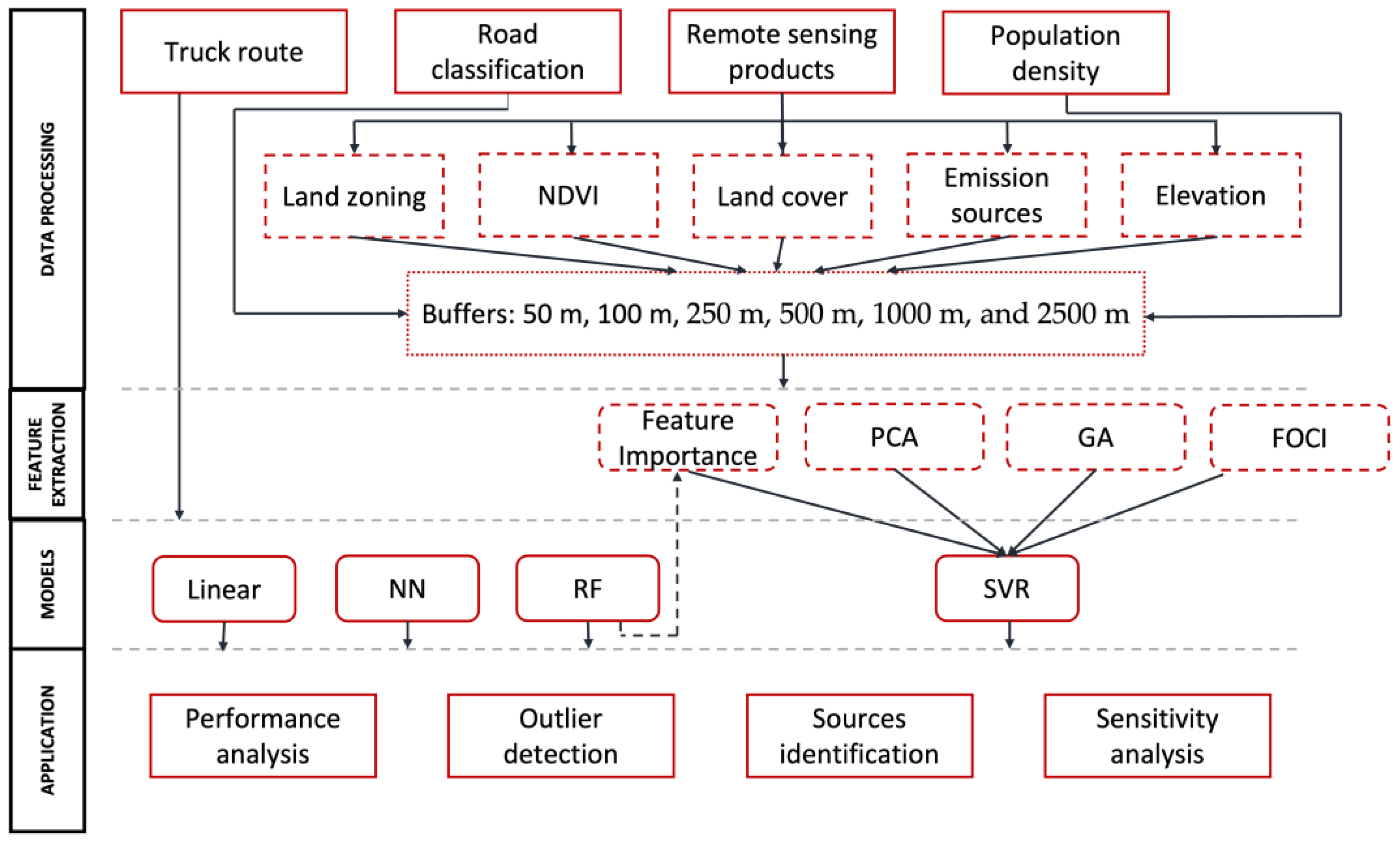
2. Materials and Methods
2.1. Study Area and Air Pollution Data
2.2. Land Use Model Specification
2.3. Model Specification
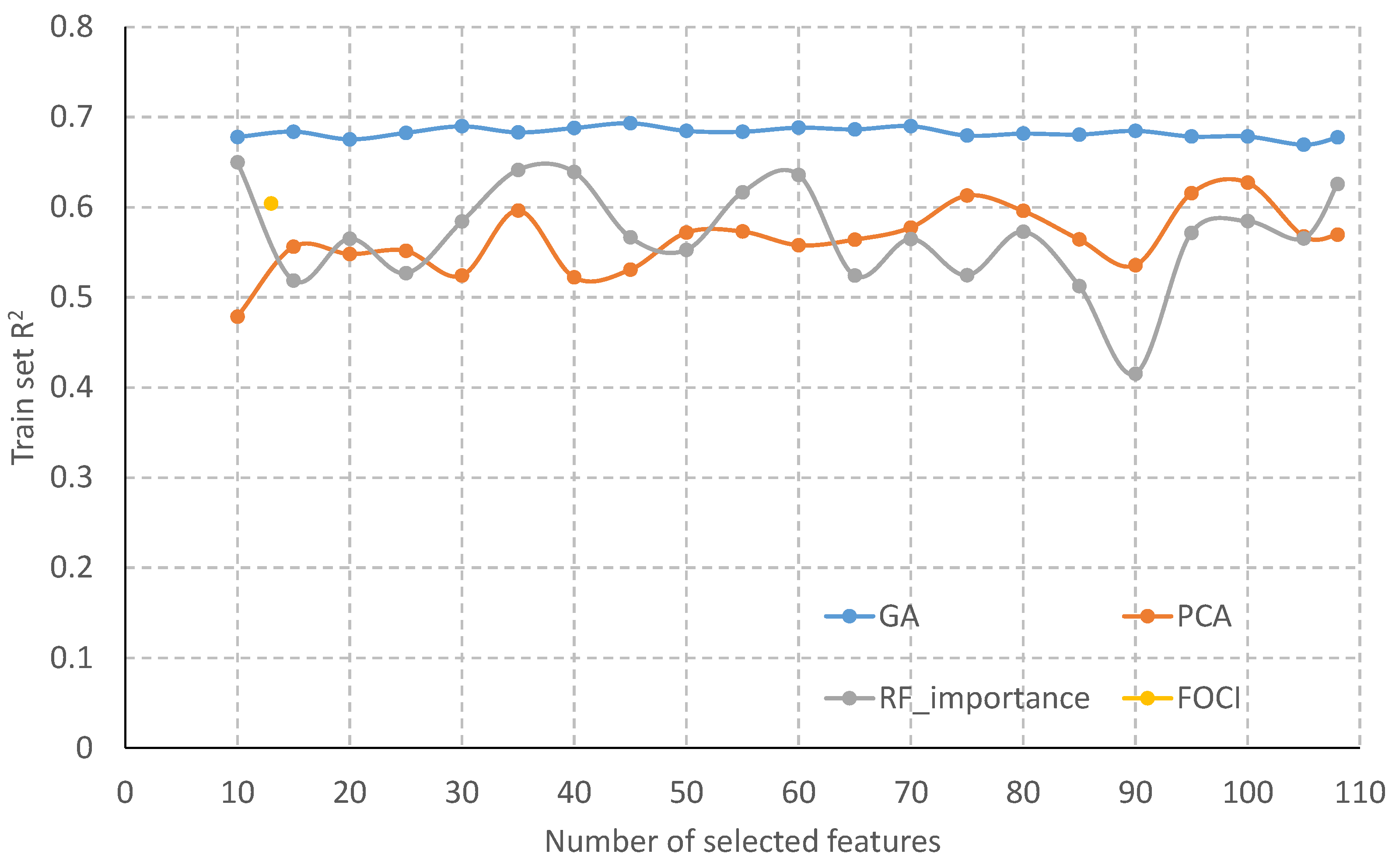
2.4. Model Tuning
2.5. Model Validation
3. Results
3.1. Model Development
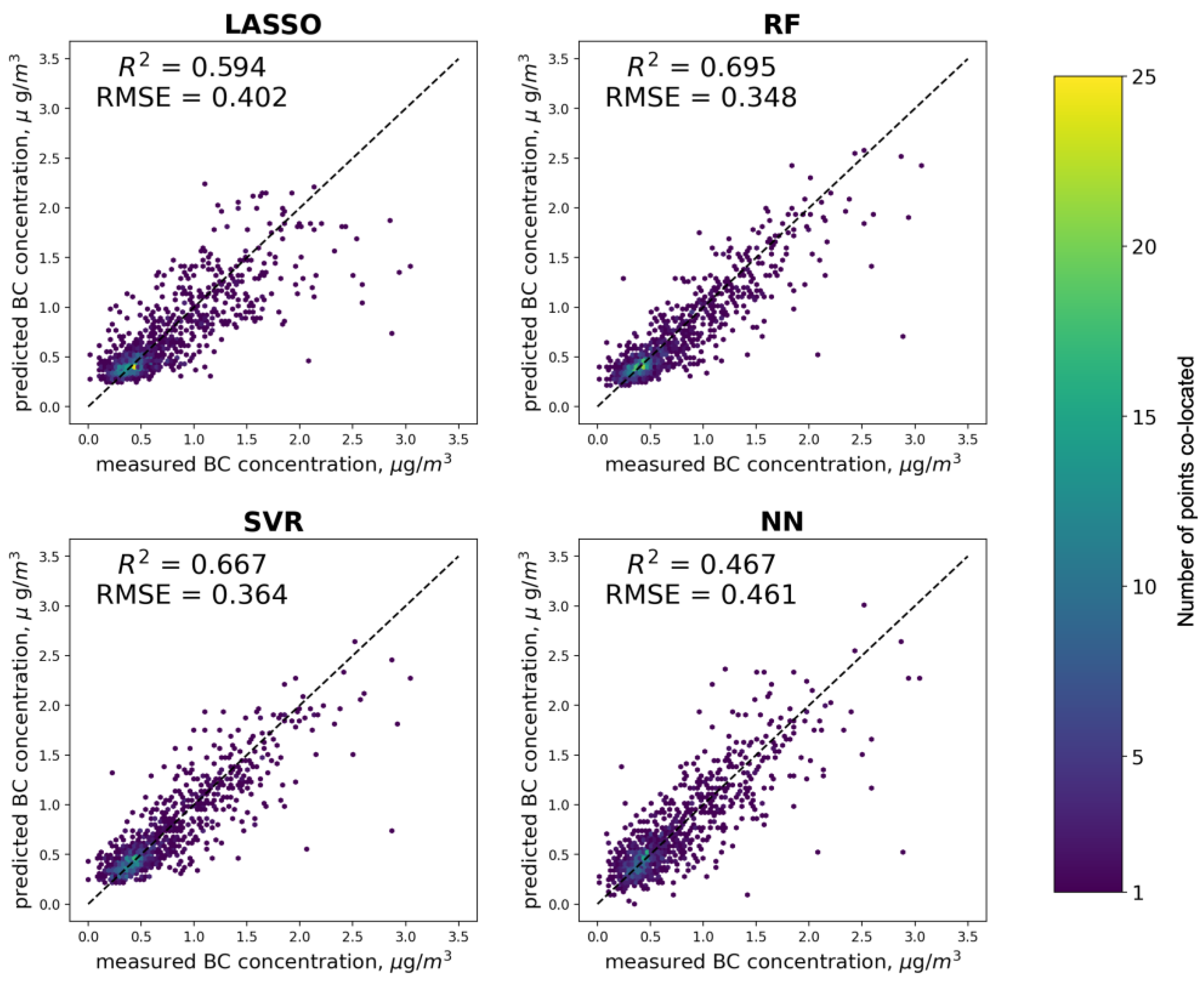
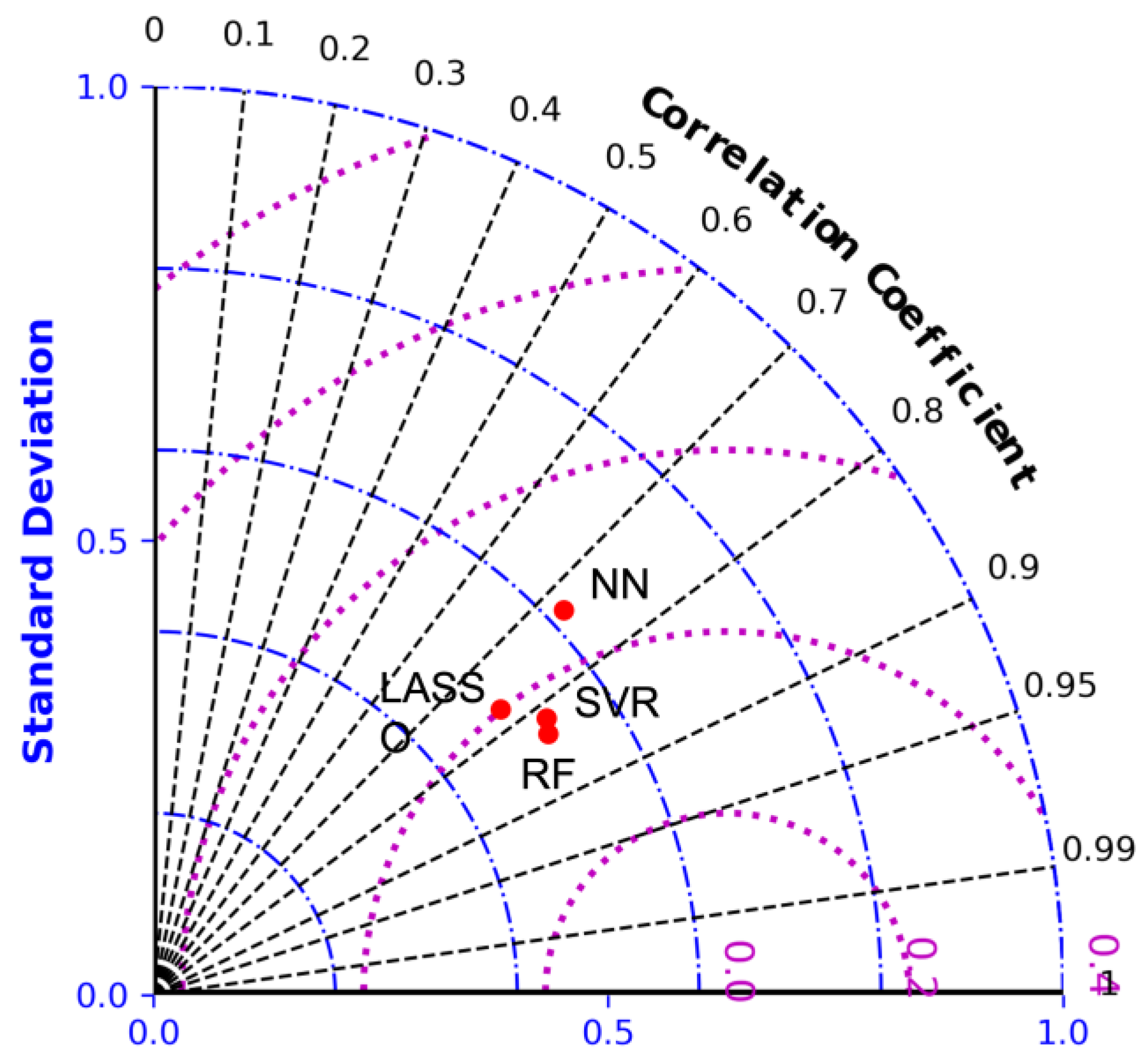
3.2. Model Performance Evaluation
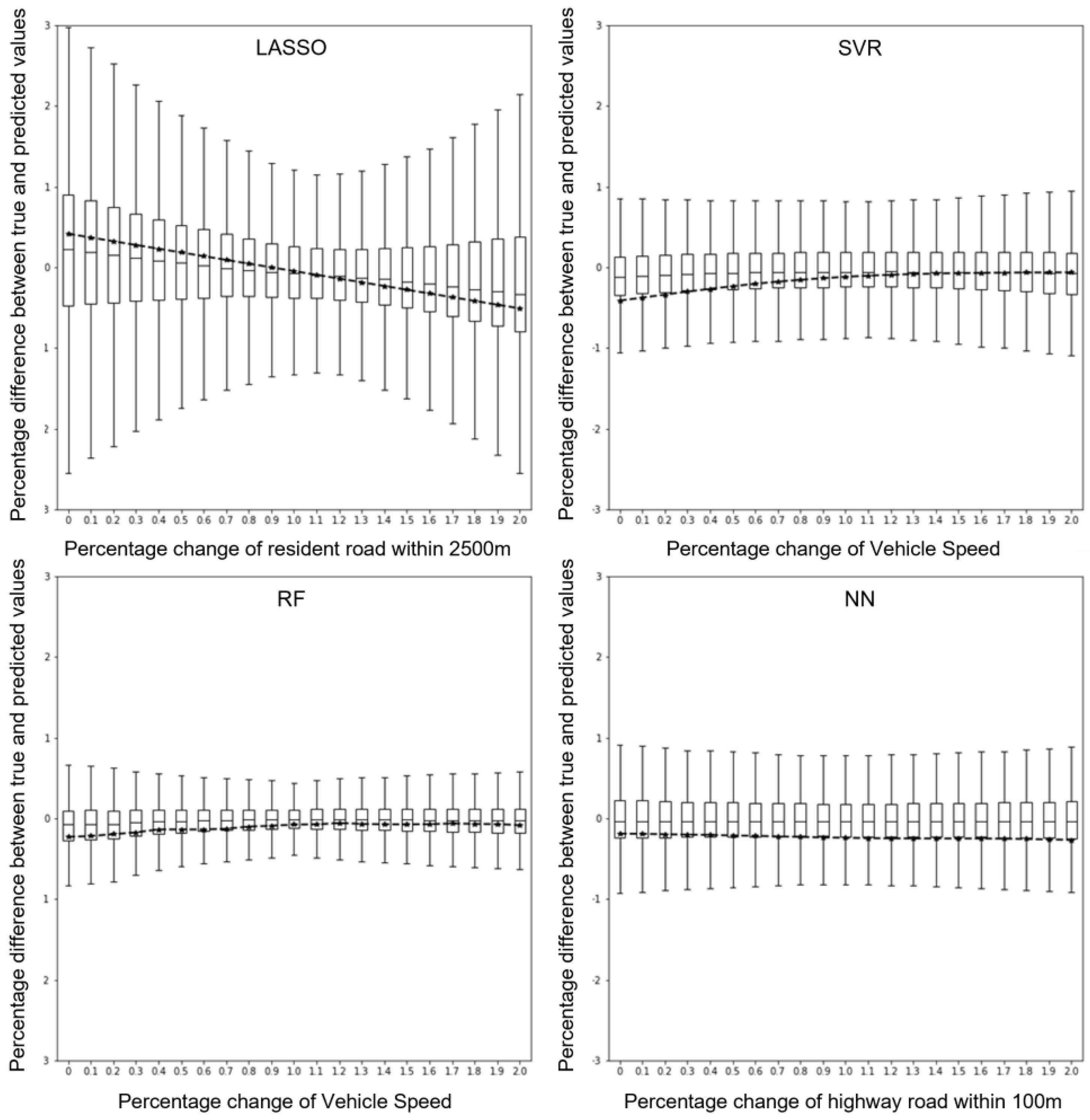
3.3. Sensitivity Analysis
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Pinault, L.L.; Weichenthal, S.; Crouse, D.L.; Brauer, M.; Erickson, A.; Van Donkelaar, A.; Martin, R.V.; Hystad, P.; Chen, H.; Finès, P.; et al. Associations between Fine Particulate Matter and Mortality in the 2001 Canadian Census Health and Environment Cohort. Environ. Res. 2017, 159, 406–415. [Google Scholar] [CrossRef]
- Lu, X.; Lin, C.; Li, W.; Chen, Y.; Huang, Y.; Fung, J.C.H.; Lau, A.K.H. Analysis of the Adverse Health Effects of PM2.5 from 2001 to 2017 in China and the Role of Urbanization in Aggravating the Health Burden. Sci. Total Environ. 2019, 652, 683–695. [Google Scholar] [CrossRef]
- Lin, H.; Tao, J.; Du, Y.; Liu, T.; Qian, Z.; Tian, L.; Di, Q.; Rutherford, S.; Guo, L.; Zeng, W.; et al. Particle Size and Chemical Constituents of Ambient Particulate Pollution Associated with Cardiovascular Mortality in Guangzhou, China. Environ. Pollut. 2016, 208, 758–766. [Google Scholar] [CrossRef]
- Yang, J.; Zhou, M.; Li, M.; Yin, P.; Hu, J.; Zhang, C.; Wang, H.; Liu, Q.; Wang, B. Fine Particulate Matter Constituents and Cause-Specific Mortality in China: A Nationwide Modelling Study. Environ. Int. 2020, 143, 105927. [Google Scholar] [CrossRef]
- Crouse, D.L.; Philip, S.; Van Donkelaar, A.; Martin, R.V.; Jessiman, B.; Peters, P.A.; Weichenthal, S.; Brook, J.R.; Hubbell, B.; Burnett, R.T. A New Method to Jointly Estimate the Mortality Risk of Long-Term Exposure to Fine Particulate Matter and Its Components. Sci. Rep. 2016, 6, 18916. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Sakhvidi, M.J.Z.; de Hoogh, K.; Vienneau, D.; Siemiatyck, J.; Zins, M.; Goldberg, M.; Chen, J.; Lequy, E.; Jacquemin, B. Long-Term Exposure to Black Carbon and Mortality: A 28-Year Follow-up of the GAZEL Cohort. Environ. Int. 2021, 157, 106805. [Google Scholar] [CrossRef]
- Wang, Y.; Pang, Y.; Huang, J.; Bi, L.; Che, H.; Zhang, X.; Li, W. Constructing Shapes and Mixing Structures of Black Carbon Particles with Applications to Optical Calculations. J. Geophys. Res. Atmos. 2021, 126, e2021JD034620. [Google Scholar] [CrossRef]
- Bond, T.C.; Doherty, S.J.; Fahey, D.W.; Forster, P.M.; Berntsen, T.; Deangelo, B.J.; Flanner, M.G.; Ghan, S.; Kärcher, B.; Koch, D.; et al. Bounding the Role of Black Carbon in the Climate System: A Scientific Assessment. J. Geophys. Res. Atmos. 2013, 118, 5380–5552. [Google Scholar] [CrossRef]
- Li, W.; Cao, Y.; Li, R.; Ma, X.; Chen, J.; Wu, Z.; Xu, Q. The Spatial Variation in the Effects of Air Pollution on Cardiovascular Mortality in Beijing, China. J. Expo. Sci. Environ. Epidemiol. 2018, 28, 297. [Google Scholar] [CrossRef] [PubMed]
- Moosmüller, H.; Chakrabarty, R.K.; Arnott, W.P. Aerosol Light Absorption and Its Measurement: A Review. J. Quant. Spectrosc. Radiat. Transf. 2009, 110, 844–878. [Google Scholar] [CrossRef]
- Tao, S.; Xu, H.; Ren, Y.; Zhang, W.; Meng, W.; Yun, X.; Yu, X.; Li, J.; Zhang, Y.; Shen, G.; et al. Updated Global Black Carbon Emissions from 1960 to 2017: Improvements, Trends, and Drivers. Environ. Sci. Technol. 2021, 55, 7869–7879. [Google Scholar] [CrossRef]
- Apte, J.S.; Messier, K.P.; Gani, S.; Brauer, M.; Kirchstetter, T.W.; Lunden, M.M.; Marshall, J.D.; Portier, C.J.; Vermeulen, R.C.H.; Hamburg, S.P. High-Resolution Air Pollution Mapping with Google Street View Cars: Exploiting Big Data. Environ. Sci. Technol. 2017, 51, 6999–7008. [Google Scholar] [CrossRef] [PubMed]
- Wang, A.; Xu, J.; Tu, R.; Saleh, M.; Hatzopoulou, M. Potential of Machine Learning for Prediction of Traffic Related Air Pollution. Transp. Res. Part D Transp. Environ. 2020, 88, 102599. [Google Scholar] [CrossRef]
- Xie, X.; Semanjski, I.; Gautama, S.; Tsiligianni, E.; Deligiannis, N.; Rajan, R.; Pasveer, F.; Philips, W. A Review of Urban Air Pollution Monitoring and Exposure Assessment Methods. ISPRS Int. J. Geo-Inf. 2017, 6, 389. [Google Scholar] [CrossRef] [Green Version]
- Farrell, W.J.; Weichenthal, S.; Goldberg, M.; Hatzopoulou, M. Evaluating Air Pollution Exposures across Cycling Infrastructure Types: Implications for Facility Design. J. Transp. L Use 2015, 8, 3. [Google Scholar] [CrossRef] [Green Version]
- Good, N.; Mölter, A.; Ackerson, C.; Bachand, A.; Carpenter, T.; Clark, M.L.; Fedak, K.M.; Kayne, A.; Koehler, K.; Moore, B.; et al. The Fort Collins Commuter Study: Impact of Route Type and Transport Mode on Personal Exposure to Multiple Air Pollutants. J. Expo. Sci. Environ. Epidemiol. 2015, 26, 397–404. [Google Scholar] [CrossRef]
- Krupnova, T.G.; Rakova, O.V.; Bondarenko, K.A.; Tretyakova, V.D. Environmental Justice and the Use of Artificial Intelligence in Urban Air Pollution Monitoring. Big Data Cogn. Comput. 2022, 6, 75. [Google Scholar] [CrossRef]
- Vu, T.; Shi, Z.; Cheng, J.; Zhang, Q.; He, K.; Wang, S.; Harrison, R. Assessing the Impact of Clean Air Action on Air Quality Trends in Beijing Using a Machine Learning Technique. Atmos. Chem. Phys. 2019, 19, 11303–11314. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Zhang, J.; Sun, X.; Xu, S.; Shan, M.; Yuan, Q.; Liu, L.; Du, Z.; Liu, D.; Xu, D.; et al. Variation in Concentration and Sources of Black Carbon in a Megacity of China during the COVID-19 Pandemic. Geophys. Res. Lett. 2020, 47, e2020GL090444. [Google Scholar] [CrossRef]
- Reid, C.E.; Jerrett, M.; Petersen, M.L.; Pfister, G.G.; Morefield, P.E.; Tager, I.B.; Raffuse, S.M.; Balmes, J.R. Spatiotemporal Prediction of Fine Particulate Matter during the 2008 Northern California Wildfires Using Machine Learning. Environ. Sci. Technol. 2015, 49, 3887–3896. [Google Scholar] [CrossRef]
- Di, Q.; Kloog, I.; Koutrakis, P.; Lyapustin, A.; Wang, Y.; Schwartz, J. Assessing PM2.5 Exposures with High Spatiotemporal Resolution across the Continental United States. Environ. Sci. Technol. 2016, 50, 4712–4721. [Google Scholar] [CrossRef] [Green Version]
- Di, Q.; Amini, H.; Shi, L.; Kloog, I.; Silvern, R.; Kelly, J.; Sabath, M.B.; Choirat, C.; Koutrakis, P.; Lyapustin, A.; et al. An Ensemble-Based Model of PM2.5 Concentration across the Contiguous United States with High Spatiotemporal Resolution. Environ. Int. 2019, 130, 104909. [Google Scholar] [CrossRef]
- Van den Hove, A.; Verwaeren, J.; Van den Bossche, J.; Theunis, J.; De Baets, B. Development of a Land Use Regression Model for Black Carbon Using Mobile Monitoring Data and Its Application to Pollution-Avoiding Routing. Environ. Res. 2020, 183, 108619. [Google Scholar] [CrossRef] [Green Version]
- Talaat, H.; Xu, J.; Hatzopoulou, M.; Abdelgawad, H. Mobile Monitoring and Spatial Prediction of Black Carbon in Cairo, Egypt. Environ. Monit. Assess. 2021, 193, 587. [Google Scholar] [CrossRef]
- Kerckhoffs, J.; Hoek, G.; Messier, K.P.; Brunekreef, B.; Meliefste, K.; Klompmaker, J.O.; Vermeulen, R. Comparison of Ultrafine Particle and Black Carbon Concentration Predictions from a Mobile and Short-Term Stationary Land-Use Regression Model. Environ. Sci. Technol. 2016, 50, 12894–12902. [Google Scholar] [CrossRef]
- Alexeeff, S.E.; Roy, A.; Shan, J.; Liu, X.; Messier, K.; Apte, J.S.; Portier, C.; Sidney, S.; Van Den Eeden, S.K. High-Resolution Mapping of Traffic Related Air Pollution with Google Street View Cars and Incidence of Cardiovascular Events within Neighborhoods in Oakland, CA. Environ. Heal A Glob. Access Sci. Source 2018, 17, 38. [Google Scholar] [CrossRef] [Green Version]
- Hasenfratz, D.; Saukh, O.; Walser, C.; Hueglin, C.; Fierz, M.; Arn, T.; Beutel, J.; Thiele, L. Deriving High-Resolution Urban Air Pollution Maps Using Mobile Sensor Nodes. Pervasive Mob. Comput. 2015, 16, 268–285. [Google Scholar] [CrossRef]
- Weichenthal, S.; Ryswyk, K.; Goldstein, A.; Bagg, S.; Shekkarizfard, M.; Hatzopoulou, M. A Land Use Regression Model for Ambient Ultrafine Particles in Montreal, Canada: A Comparison of Linear Regression and a Machine Learning Approach. Environ. Res. 2016, 146, 65–72. [Google Scholar] [CrossRef] [Green Version]
- Sabaliauskas, K.; Jeong, C.H.; Yao, X.; Reali, C.; Sun, T.; Evans, G.J. Development of a Land-Use Regression Model for Ultrafine Particles in Toronto, Canada. Atmos. Environ. 2015, 110, 84–92. [Google Scholar] [CrossRef]
- Bao, F.; Cheng, T.; Li, Y.; Gu, X.; Guo, H.; Wu, Y.; Wang, Y.; Gao, J. Retrieval of Black Carbon Aerosol Surface Concentration Using Satellite Remote Sensing Observations. Remote Sens. Environ. 2019, 226, 93–108. [Google Scholar] [CrossRef]
- Li, Y.; Yuan, S.; Fan, S.; Song, Y.; Wang, Z.; Yu, Z.; Yu, Q.; Liu, Y. Satellite Remote Sensing for Estimating PM 2.5 and Its Components. Curr. Pollut. Rep. 2021, 7, 72–87. [Google Scholar] [CrossRef]
- Van Donkelaar, A.; Martin, R.V.; Li, C.; Burnett, R.T. Regional Estimates of Chemical Composition of Fine Particulate Matter Using a Combined Geoscience-Statistical Method with Information from Satellites, Models, and Monitors. Environ. Sci. Technol. 2019, 53, 2595–2611. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Lau, A.K.H.; Fung, J.C.H.; Lao, X.Q.; Li, Y.; Li, C. Assessing the Effect of the Long-Term Variations in Aerosol Characteristics on Satellite Remote Sensing of PM2.5 Using an Observation-Based Model. Environ. Sci. Technol. 2019, 53, 2990–3000. [Google Scholar] [CrossRef]
- Silveira, C.; Ferreira, J.; Tuccella, P.; Curci, G.; Miranda, A.I. Combined Effect of High-Resolution Land Cover and Grid Resolution on Surface NO2 Concentrations. Climate 2022, 10, 19. [Google Scholar] [CrossRef]
- Tan, Q.; Ling, J.; Hu, J.; Qin, X.; Hu, J. Vehicle Detection in High Resolution Satellite Remote Sensing Images Based on Deep Learning. IEEE Access 2020, 8, 153394–153402. [Google Scholar] [CrossRef]
- Feroz, S.; Abu Dabous, S. UAV-Based Remote Sensing Applications for Bridge Condition Assessment. Remote Sens. 2021, 13, 1809. [Google Scholar] [CrossRef]
- Google Oakland_201506-201605_GoogleAclimaAQ. Available online: www.google.com (accessed on 1 November 2020).
- Messier, K.P.; Chambliss, S.E.; Gani, S.; Alvarez, R.; Brauer, M.; Choi, J.J.; Hamburg, S.P.; Kerckhoffs, J.; LaFranchi, B.; Lunden, M.M.; et al. Mapping Air Pollution with Google Street View Cars: Efficient Approaches with Mobile Monitoring and Land Use Regression. Environ. Sci. Technol. 2018, 52, 12563–12572. [Google Scholar] [CrossRef] [Green Version]
- Van Rossum, G.; Drake, F.L., Jr. Python Tutorial; Centrum voor Wiskunde en Informatica: Amsterdam, The Netherlands, 1995. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in {P}ython. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Bisong, E. Google Colaboratory BT—Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Bisong, E., Ed.; Apress: Berkeley, CA, USA, 2019; pp. 59–64. ISBN 978-1-4842-4470-8. [Google Scholar]
- Bergstra, J.; Yamins, D.; Cox, D. Making a Science of Model Search: Hyperparameter Optimization in Hundreds of Dimensions for Vision Architectures. In Proceedings of the International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 16–21 June 2013; pp. 115–123. [Google Scholar]
- Azadkia, M.; Chatterjee, S. A Simple Measure of Conditional Dependence. Ann. Stat. 2019, 49, 3070–3102. [Google Scholar] [CrossRef]
- Zhang, D.; Xiao, J.; Zhou, N.; Zheng, M.; Luo, X.; Jiang, H.; Chen, K. A Genetic Algorithm Based Support Vector Machine Model for Blood-Brain Barrier Penetration Prediction. Biomed. Res. Int. 2015, 2015, 292683. [Google Scholar] [CrossRef] [Green Version]
- Westerdahl, D.; Fruin, S.; Sax, T.; Fine, P.M.; Sioutas, C. Mobile Platform Measurements of Ultrafine Particles and Associated Pollutant Concentrations on Freeways and Residential Streets in Los Angeles. Atmos. Environ. 2005, 39, 3597–3610. [Google Scholar] [CrossRef]
- Abernethy, R.C.; Allen, R.W.; McKendry, I.G.; Brauer, M. A Land Use Regression Model for Ultrafine Particles in Vancouver, Canada. Environ. Sci. Technol. 2013, 47, 5217–5225. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Larson, T.; Henderson, S.B.; Brauer, M. Mobile Monitoring of Particle Light Absorption Coefficient in an Urban Area as a Basis for Land Use Regression. Environ. Sci. Technol. 2009, 43, 4672–4678. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Srivastava, N. Improving Neural Networks with Dropout. Univ. Tor. 2013, 182, 7. [Google Scholar]
- Lim, C.C.; Kim, H.; Vilcassim, M.J.R.; Thurston, G.D.; Gordon, T.; Chen, L.C.; Lee, K.; Heimbinder, M.; Kim, S.Y. Mapping Urban Air Quality Using Mobile Sampling with Low-Cost Sensors and Machine Learning in Seoul, South Korea. Environ. Int. 2019, 131, 105022. [Google Scholar] [CrossRef]
- Ren, X.; Mi, Z.; Georgopoulos, P.G. Comparison of Machine Learning and Land Use Regression for Fine Scale Spatiotemporal Estimation of Ambient Air Pollution: Modeling Ozone Concentrations across the Contiguous United States. Environ. Int. 2020, 142, 105827. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 5-Fold CV R2 for Train Set | R2 for Validation Set | RMSE for Validation Set, µg/m3 | |
|---|---|---|---|
| LASSO | 0.596 | 0.594 | 0.273 |
| SVR | 0.693 | 0.667 | 0.221 |
| RF | 0.701 | 0.695 | 0.210 |
| NN | 0.723 | 0.467 | 0.253 |
| BC Concentration Differences, µg/m3 | ||||||
|---|---|---|---|---|---|---|
| Outliers (<10th Percentile) | Inliers | Outliers (>90th Percentile) | ||||
| Mean | Standard Deviation | Mean | Standard Deviation | Mean | Standard Deviation | |
| LASSO | −0.52 | 0.35 | −0.01 | 0.16 | 0.32 | 0.19 |
| RF | −0.38 | 0.29 | −0.02 | 0.13 | 0.24 | 0.14 |
| SVR | −0.40 | 0.29 | 0.00 | 0.13 | 0.28 | 0.17 |
| NN | −0.41 | 0.32 | 0.00 | 0.16 | 0.33 | 0.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, M.; Acharya, T.D.; Niemeier, D.A. Black Carbon Concentration Estimation with Mobile-Based Measurements in a Complex Urban Environment. ISPRS Int. J. Geo-Inf. 2023, 12, 290. https://doi.org/10.3390/ijgi12070290
Tang M, Acharya TD, Niemeier DA. Black Carbon Concentration Estimation with Mobile-Based Measurements in a Complex Urban Environment. ISPRS International Journal of Geo-Information. 2023; 12(7):290. https://doi.org/10.3390/ijgi12070290
Chicago/Turabian StyleTang, Minmeng, Tri Dev Acharya, and Deb A. Niemeier. 2023. "Black Carbon Concentration Estimation with Mobile-Based Measurements in a Complex Urban Environment" ISPRS International Journal of Geo-Information 12, no. 7: 290. https://doi.org/10.3390/ijgi12070290