
SLBRIN: A Spatial Learned Index Based on BRIN

Abstract
:1. Introduction
2. Related Work
2.1. Spatial Indices
2.2. Learned Indices
3. Methodology
3.1. SLBRIN Architecture
| Algorithm 1: Decimal Geohash Match |
| Input: A: a sorted decimal geohash array; q: a geohash query; (l, r): the initial left and right. Output: the key to q. 1: while l ≤ r do 2: mid(l + r)/2 3: if Amid = q then 4: return 5: else if Amid < q then 6: lmid+1 7: else 8: rmid-1 9: return r |
3.2. Build Processing
3.2.1. Ordering Data
| Algorithm 2: Build SLBRIN |
| Input: P: a spatial dataset; (TH, TL, TS, TM, TE): the thresholds Output: I: our index. 1: calculate the geohash encoding length of P to L 2: calculate and sort IEs by Geohash(L) to ieList 3: initial rangeStackand rangeList 4: rangeStack.push(CreateRange(0, 0, P.size, [0, P.size - 1])) 5: while rangeStack.size ≠ 0 do 6: rangerangeStack.pop(-1) 7: if range.num > TN and range.len < TL then 8: initial childs; lk, rkrange.keyBound; tlklk 9: for i[0, 3] do 10: lenrange.len + 2; valuerange.value + (i << L - len) 11: breakpointrange.value + (i + 1 << L - len) 12: trkDGM(ieList, breakpoint, tlk, rk); numtrk – rlk + 1 13: childs.push(CreateRange(value, len, num, [tlk, trk])); tlktrk + 1 14: rangeStack.push(Reverse(childs)) 15: else 16: rangeList.push(range) 17: create HR for each range in rangeList and store to HR Pages 18: create empty CR and store to CR Pages 19: create Meta and store to Meta Page 20: reorganize ieList and store to Data Pages 21: build and train M and store extract args to Model Pages 22: return I |
3.2.2. Building SLBRIN
3.2.3. Building Learned Model
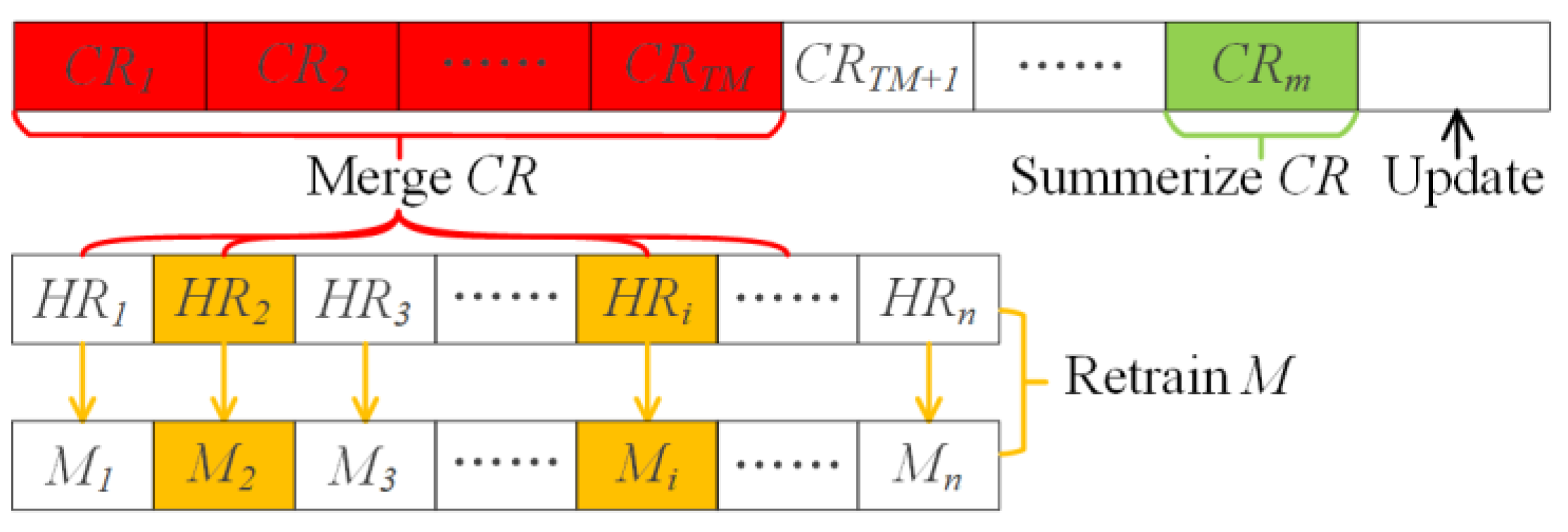
3.3. Update Processing
| Algorithm 3: Update SLBRIN |
| Input: p: the data item to be updated; I: our index. 1: gEncode(p, I.meta.L) 2: ie(g, p.spatialFields, p.key) 3: lastCR I.meta.lastCR 4: lastCR.numlastCR.num + 1 5: I.data.append(ie) 6: Listening Trigger: 7: lastCR.num > TS summarize full CRs 8: (lastCR – lastHR)/size(CR) > TM merge outdated CRs 9: newErr/oldErr > TE retrain models of inefficient HRs |
- For overall HR or any CR, in case of sufficient IEs, the spatial distribution tends to D.
- The scope of the local range can be encoded uniquely as g by Geohash. For any local range, in case of sufficient IEs, its spatial distribution Dg tends to the part of D in the scope g.
- The child’s input domain [−0.5, 0.5] corresponds that of parent [−0.5, −0.25], so the input layer of MLP is calculated as follow:
- 2.
- The child’s output domain [0, 1] corresponds that of parent [M(−0.5), M(−0.25)], so the output layer of MLP is calculated as follow:
3.4. Query Processing
3.4.1. Point Queries
| Algorithm 4: Point Query |
| Input: p: a point query; I: our index. Output: result: the key to p. 1: crLsitsearch cr from I.CRs where cr.value ⸧ p 2: resultsearch ie from crLsit where ie = p 3: gEncode(p, I.Meta.L) 4: hrDGM(I.HRs, g) 5: modelhr.model 6: premodel.predict(g) 7: result.push(MBS(I.IEs, pre, model)) 8: return result |
3.4.2. Range Queries
| Algorithm 5: Range Query |
| Input: qr: a range query; I: our index. Output: result: the keys falling in qr. 1: crListsearch cr from I.CRs where cr.value ∩ qr 2: resultsearch ie from crList where ie ⸦ qr 3: pb, ptqr; gb, gtEncode([pb, pt], I.Meta.L) 4: rangeListGeohashRangeQuery(gb, gt) 5: range.hrDGM(I.HRs, range.g) for each range in rangeList 6: group rangeList by range.hr and merge range.pos 7: for each range in rangeList do 8: get gb, gt with range.pos; preb, pretrange.hr.model.predict([gb, gt]) 9: keyb, keytMBS(I.IEs, [preb, pret], range.hr.model) 10: for k[keyb, keyt] do 11: if iek ⸦ qr then 12: result.push(k) 13: return result 14: 15: function GeohashRangeQuery(gb, gt) 16: initial rangeList; lMax(Len(gb), Len(gt)) 17: gxb, gyb, gxt gytDecode([gb, gt], l) 18: gxlgxt - gxb; gylgyt - gyb 19: gListEncode(gx, gy, L) for gx[gxb, gxt], gy[gyb, gyt] 20: for g in gList do 21: pos check position by gxl, gyl 22: rangeList.push(CreateRange(g, pos)) 23: sort rangeList by range.g 24: return rangeList |
- Calculate the granularity of candidate ranges. A moderate granularity helps to filter HRs effectively. The granularity l lies between the maximum geohash length of all candidate ranges and L. We used the larger geohash length of gb and gt, which yields the best performance in experiments (Line 16).
- Decode gb and gt into one-dimensional geohash code gxb, gyb, gxt, gyt by Geohash, and calculate the number of candidate ranges along horizontal and vertical directions as gxl and gyl (Lines 17–18).
- Create the Cartesian product by all one-dimensional geohash codes in the domain of [gxb, gxt] and [gyb, gyt], and encode each member by Geohash as gList (Line 19).
- In spatial, each range in gList is contained or intersected by qr. In lines 20–22, we marked the spatial relationship between range and qr with the spatial location code, which consists of four binary bits, indicating that range intersects the bottom, top, left, right of qr, respectively. For example, a spatial location code of [1 0 0 0] means the range intersects the bottom of qr. Based on the order of the Cartesian product, we confirmed that the first gxl ranges intersect the bottom of qr, and the last gxl ranges intersect the top of qr. In addition, the ranges whose sequence is divisible by gyl intersect the left of qr, and their previous ranges intersect the right of qr. All the others are contained by qr, initialized as [0 0 0 0]. As a range has multiple spatial relationships with qr, the spatial position codes can be combined with the OR operation, i.e., [1 0 0 0] | [0 0 1 0] = [1 0 1 0] means the range intersects the bottom and left corner of qr, and [1 1 1 1] means the range contains qr.
- Sort rangeList by decimal geohash code (Line 23).
3.4.3. kNN Queries
| Algorithm 6: kNN Query |
| Input: p: a point of kNN; k: a positive number of kNN. Output: pQueue: a priority queue contains the nearest k keys to p. 1: pQueuePriorityQueue((-1, +∞), k) 2: keypPointQuery(p) 3: for key [keyp - k, keyp + k] do 4: pQueue.offer(key, Distance(p, pkey)) 5: dstpQueue.peek() 6: construct qr with p and dst 7: pb, ptqr; gb, gtEncode([pb, pt], I.Meta.L) 8: rangeListGeohashRangeQuery(gb, gt) 9: range.hrDGM(I.HRs, range.g) for each range in rangeList 10: group rangeList by range.hr and merge range.pos 11: range.dstDistance(range.hr, p) for each range in rangeList 12: sort rangeList by range.dst 13: for each range in rangeList do 14: if range.dst > dst then 15: break 16: else 17: get gb, gt with range.pos; preb, pretrange.hr.model.predict([gb, gt]) 18: keyb, keytMBS(I.IEs, [preb, pret], range.hr.model) 19: for k[keyb, keyt] do 20: pQueue.offer(key, Distance(p, pkey)) 21: dstpQueue.peek() 22: update qr by dst 23: crListsearch cr from I.CRs where cr.value ∩ q 24: pQueue.offer(keyie, Distance(p, ie)) for each ie in crList 25: return pQueue |
4. Experiments
4.1. Experimental Settings
- NYCT is a historical repository of 750 million rides of taxi medallions over a period of four years (2010–2013) in New York City [47]. We extracted the part of January and February 2013, about 28,236,977 records (2.84 GB in size), with the pickup time as temporal field and the pickup coordinates as spatial fields.
- UNIFORM and NORMAL are synthetic datasets in uniform and normal distributions. The synthetic data falls into the unit square, with a random temporal field and the same cardinality as NYCT (1.58 GB in size).
- 3.
- R-tree [3] (RT): The most typical spatial index.
- 4.
- Point range quadtree [27] (PRQT): A variant of quad-tree, balancing the cardinality between partitions with a threshold, similar to HR.
- 5.
- BRIN-Spatial [14] (BRINS): The spatial variant of BRIN with MBR as summary info.
- 6.
- Z-order model [7] (ZM): A classical spatial learned index using Z-curve to reduce dimensionality. We used Geohash instead of Z-curve for ease of comparison.
- 7.
- LISA [15]: A spatial learned index structure designed for disk-resident spatial data, which has shown strong query performance.
4.2. Effect of Thresholds
4.3. Build Performance
4.4. Point Query Performance
4.5. Range Query Performance
4.6. kNN Query Performance
4.7. Update Performance
5. Discussion
6. Conclusions
- For update processing, we deconstructed update transactions into serial and parallel operations to improve parallelism, and made full use of the temporal proximity of spatial distribution to stabilize query performance and improve update performance.
- For query processing, we designed the strategies of point query, range query and kNN query based on the spatial learned index, and optimized them with the spatial partition of HR and the proposed spatial location code.
- Using synthetic and real data, our extensive experiments showed that SLBRIN outperformed all competitors in storage cost, query performance and update performance. Furthermore, SLBRIN offered the strongest performance stability in update processing.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhu, Q.; Hu, H.; Xu, C.; Xu, J.; Lee, W. Geo-social group queries with minimum acquaintance constraints. VLDB J. 2017, 26, 709–727. [Google Scholar] [CrossRef]
- Manolopoulos, Y.; Nanopoulos, A.; Papadopoulos, A.N.; Theodoridis, Y. R-Trees Have Grown Everywhere. Technical Report. 2003, p. 3. Available online: http://www.rtreeportal.org (accessed on 6 January 2022).
- Guttman, A. R-trees: A dynamic index structure for spatial searching. In Proceedings of the 1984 ACM SIGMOD International Conference on Management of Data, Boston, MA, USA, 18–21 June 1984; pp. 47–57. [Google Scholar]
- Rigaux, P.; Scholl, M.; Voisard, A. Spatial Databases: With Application to GIS; Morgan Kaufmann: Burlington, MA, USA, 2003; Volume 32, p. 111. [Google Scholar]
- Kraska, T.; Beutel, A.; Chi, E.H.; Dean, J.; Polyzotis, N. The case for learned index structures. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 489–504. [Google Scholar]
- Anselin, L. Lagrange multiplier test diagnostics for spatial dependence and spatial heterogeneity. Geogr. Anal. 1988, 20, 1–17. [Google Scholar] [CrossRef]
- Wang, H.; Fu, X.; Xu, J.; Lu, H. Learned index for spatial queries. In Proceedings of the 20th IEEE International Conference on Mobile Data Management, Hongkong, China, 10–13 June 2019; pp. 569–574. [Google Scholar]
- Wang, N.; Xu, J. Spatial queries based on learned index. In Proceedings of the 1st International Conference on Spatial Data and Intelligence, Hongkong, China, 18–19 December 2020; Springer: Hongkong, China, 2020; pp. 245–257. [Google Scholar]
- Davitkova, A.; Milchevski, E.; Michel, S. The ML-index: A multidimensional, learned index for point, range, and nearest-neighbor queries. In Proceedings of the 2020 23rd International Conference on Extending Database Technology, Copenhagen, Denmark, 30 March–2 April 2020; pp. 407–410. [Google Scholar]
- Hu, L. Efficient Learning Spatial-Temporal Query and Computing Framework for Geographic Flow Data. Ph.D. Thesis, Zhejiang University, Zhejiang, China, 2021. [Google Scholar]
- Qi, J.; Liu, G.; Jensen, C.S.; Kulik, L. Effectively learning spatial indices. Proc. VLDB Endow. 2020, 13, 2341–2354. [Google Scholar] [CrossRef]
- Gaede, V.; Günther, O. Multidimensional access methods. ACM Comput. Surv. 1998, 30, 170–231. [Google Scholar] [CrossRef]
- Herrera, A. Block Range Index. Available online: https://www.postgresql.org/docs/9.6/brin.html (accessed on 6 January 2022).
- Yu, J.; Sarwat, M. Indexing the pickup and drop-off locations of NYC taxi trips in PostgreSQL—Lessons from the road. In Proceedings of the 15th International Symposium on Spatial and Temporal Databases, Washington, DC, USA, 21–23 August 2017; pp. 145–162. [Google Scholar]
- Li, P.; Lu, H.; Zheng, Q.; Yang, L.; Pan, G. LISA: A learned index structure for spatial data. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 2119–2133. [Google Scholar]
- Sagan, H. Space-Filling Curves; Springer Science & Business Media: New York, NY, USA, 2012; p. 291. [Google Scholar]
- Ramsak, F.; Markl, V.; Fenk, R.; Zirkel, M.; Elhardt, K.; Bayer, R. Integrating the UB-tree into a database system kernel. In Proceedings of the 26th International Conference on Very Large Data Bases, San Francisco, CA, USA, 10–14 September 2000; pp. 263–272. [Google Scholar]
- Faloutsos, C.; Roseman, S. Fractals for secondary key retrieval. In Proceedings of the 8th ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, Philadelphia, PA, USA, 29–31 March 1989; pp. 247–252. [Google Scholar]
- Hughes, J.N.; Annex, A.; Eichelberger, C.N.; Fox, A.; Hulbert, A.; Ronquest, M. Geomesa: A distributed architecture for spatio-temporal fusion. In Proceedings of the Geospatial Informatics, Fusion, and Motion Video Analytics V, Baltimore, MD, USA, 20–24 April 2015; pp. 128–140. [Google Scholar]
- Li, R.; He, H.; Wang, R.; Huang, Y.; Liu, J.; Ruan, S.; He, T.; Bao, J.; Zheng, Y. Just: JD urban spatio-temporal data engine. In Proceedings of the IEEE 36th International Conference on Data Engineering, Dallas, TX, USA, 20–24 April 2020; pp. 1558–1569. [Google Scholar]
- Ni, E. Geohash. Available online: http://geohash.org (accessed on 6 January 2022).
- Google. S2 Geometry. Available online: http://s2geometry.io (accessed on 6 January 2022).
- Nievergelt, J.; Hinterberger, H.; Sevcik, K.C. The grid file: An adaptable, symmetric multi-key file structure. In Proceedings of the 3rd Conference of the European Cooperation in Informatics, Munich, Germany, 20–22 October 1981; pp. 236–251. [Google Scholar]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Finkel, R.A.; Bentley, J.L. Quad trees a data structure for retrieval on composite keys. Acta Inform. 1974, 4, 1–9. [Google Scholar] [CrossRef]
- Meagher, D. Geometric modeling using octree encoding. Comput. Graph. Image Process. 1982, 19, 129–147. [Google Scholar] [CrossRef]
- Samet, H. The quadtree and related hierarchical data structures. ACM Comput. Surv. 1984, 16, 187–260. [Google Scholar] [CrossRef] [Green Version]
- Leutenegger, S.T.; Lopez, M.A.; Edgington, J. STR: A simple and efficient algorithm for R-tree packing. In Proceedings of the 13th International Conference on Data Engineering, Birmingham, UK, 7–11 April 1997; pp. 497–506. [Google Scholar]
- Sellis, T.; Roussopoulos, N.; Faloutsos, C. The R+-Tree: A dynamic index for multi-dimensional objects. In Proceedings of the 13th International Conference on Very Large Data Bases, Brighton, UK, 1–4 September 1987; pp. 507–518. [Google Scholar]
- Beckmann, N.; Kriegel, H.; Schneider, R.; Seeger, B. The R*-tree: An efficient and robust access method for points and rectangles. In Proceedings of the 1990 ACM SIGMOD International Conference on Management of Data, Atlantic, NJ, USA, 23–25 May 1990; pp. 322–331. [Google Scholar]
- Xia, Y.; Prabhakar, S. Q+Rtree: Efficient indexing for moving object databases. In Proceedings of the 8th International Conference on Database Systems for Advanced Applications, Kyoto, Japan, 26–28 March 2003; pp. 175–182. [Google Scholar]
- Kamel, I.; Faloutsos, C. Hilbert R-tree: An improved R-tree using fractals. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago, Chile, 12–15 September 1994; pp. 500–509. [Google Scholar]
- Šaltenis, S.; Jensen, C.S.; Leutenegger, S.T.; Lopez, M.A. Indexing the positions of continuously moving objects. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 331–342. [Google Scholar]
- Li, X.; Li, J.; Wang, X. ASLM: Adaptive single layer model for learned index. In Proceedings of the 2019 24th International Conference on Database Systems for Advanced Applications, Chiang Mai, Thailand, 22–25 April 2019; pp. 80–95. [Google Scholar]
- Qu, W.; Wang, X.; Li, J.; Li, X. Hybrid indexes by exploring traditional B-tree and linear regression. In Proceedings of the 2019 16th International Conference on Web Information Systems and Applications, Qingdao, China, 20–22 September 2019; pp. 601–613. [Google Scholar]
- Galakatos, A.; Markovitch, M.; Binnig, C.; Fonseca, R.; Kraska, T. Fiting-tree: A data-aware index structure. In Proceedings of the 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 1189–1206. [Google Scholar]
- Hadian, A.; Heinis, T. Interpolation-friendly B-trees: Bridging the gap between algorithmic and learned indexes. In Proceedings of the 22nd International Conference on Extending Database Technology, Lisbon, Portugal, 26–29 March 2019; pp. 710–713. [Google Scholar]
- Ferragina, P.; Vinciguerra, G. The PGM-index: A fully-dynamic compressed learned index with provable worst-case bounds. Proc. VLDB Endow. 2020, 13, 1162–1175. [Google Scholar] [CrossRef]
- Hadian, A.; Heinis, T. Considerations for handling updates in learned index structures. In Proceedings of the 2019 2nd International Workshop on Exploiting Artificial Intelligence Techniques for Data Management, Amsterdam, The Netherlands, 5 July 2019; pp. 1–4. [Google Scholar]
- Kraska, T.; Alizadeh, M.; Beutel, A.; Chi, H.; Kristo, A.; Leclerc, G.; Madden, S.; Mao, H.; Nathan, V. SageDB: A learned database system. In Proceedings of the 2019 9th Biennial Conference on Innovative Data Systems Research, Asilomar, CA, USA, 13–16 January 2019. [Google Scholar]
- Nathan, V.; Ding, J.; Alizadeh, M.; Kraska, T. Learning multi-dimensional indexes. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 985–1000. [Google Scholar]
- Kipf, A.; Marcus, R.; van Renen, A.; Stoian, M.; Kemper, A.; Kraska, T.; Neumann, T. RadixSpline: A single-pass learned index. In Proceedings of the 3rd International Workshop on Exploiting Artificial Intelligence Techniques for Data Management, Portland, OR, USA, 14–20 June 2020; pp. 1–5. [Google Scholar]
- Li, Z.; Chan, T.N.; Yiu, M.L.; Jensen, C.S. PolyFit: Polynomial-based indexing approach for fast approximate range aggregate queries. arXiv 2020, arXiv:2003.08031. [Google Scholar] [CrossRef]
- Zhang, S.; Ray, S.; Lu, R.; Zheng, Y. Spatial interpolation-based learned index for range and kNN queries. arXiv 2021, arXiv:2102.06789. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Li, X.; Cao, C.; Chang, C. The first law of geography and spatial-temporal proximity. Chin. J. Nat. 2007, 29, 69–71. [Google Scholar] [CrossRef]
- NYC Open Data. Available online: https://data.ny.gov (accessed on 6 January 2022).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definitions |
|---|---|
| P | a spatial dataset |
| d, n, S | dimensionality, cardinality and scope of P |
| L | length of Geohash |
| HR, CR | history range and current range |
| M | a learned model |
| IE | an index entry |
| TN, TL | thresholds for HR’s number of IEs and actual geohash length |
| TS | threshold for CR’s number of IEs |
| TM | threshold for the number of CRs |
| TE | threshold for M’s error bounds |
| Range ID | Pages | BRIN (Min, Max) | BRIN-Spatial/SLBRIN CR (xmin, ymin, xmax, ymax) | SLBRIN HR (gmin) |
|---|---|---|---|---|
| 0 | 1, 128 | 0, 8 | 0, 0, 4, 4 | 0 |
| 1 | 129, 256 | 2, 7 | 1, 1, 8, 8 | 4 |
| 2 | 257, 384 | 4, 9 | 2, 0, 7, 2 | 8 |
| Physical Object | Logical Object | Attributes |
|---|---|---|
| Meta Page | Meta | int32 *lastHR, int32 *lastCR, int8 L, 5 × int16 thresholds |
| HR Pages | HR | int64 value, int8 len, int16 num, int32 *model, int8 state |
| CR Pages | CR | 4 × int64 value, int16 num, int8 state |
| Model Pages | M | Matrix matrices, int32 minErr, int32 maxErr |
| Data Pages | IE | int64 geohash, d × float64 spatialFields, int32 *data |
| Variant | Summarize CR | Merge CR | Retrain M | Retrain M with Old Weights |
|---|---|---|---|---|
| SBRIN_SCR | √ | × | × | × |
| SBRIN_MCR | √ | √ | × | × |
| SBRIN_RM | √ | √ | √ | × |
| SBRIN | √ | √ | × | √ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Hu, L.; Fu, C.; Yu, Y.; Tang, P.; Zhang, F.; Liu, R. SLBRIN: A Spatial Learned Index Based on BRIN. ISPRS Int. J. Geo-Inf. 2023, 12, 171. https://doi.org/10.3390/ijgi12040171
Wang L, Hu L, Fu C, Yu Y, Tang P, Zhang F, Liu R. SLBRIN: A Spatial Learned Index Based on BRIN. ISPRS International Journal of Geo-Information. 2023; 12(4):171. https://doi.org/10.3390/ijgi12040171
Chicago/Turabian StyleWang, Lijun, Linshu Hu, Chenhua Fu, Yuhan Yu, Peng Tang, Feng Zhang, and Renyi Liu. 2023. "SLBRIN: A Spatial Learned Index Based on BRIN" ISPRS International Journal of Geo-Information 12, no. 4: 171. https://doi.org/10.3390/ijgi12040171