
Joint Deep Learning and Information Propagation for Fast 3D City Modeling
Abstract
:1. Introduction
2. Materials and Methods
2.1. Acquisition of the Initial Depth Information Based on Existing Neural Network
2.2. Optimization of Superpixel Depth Information Propagation
2.3. Linear Plane Optimization of Depth Information Combined with Superpixel Optimization
2.4. Deep Optimization Based on Pixel-by-Pixel Information Propagation
2.5. Multiview Image Depth Estimation Method Implementation
3. Results
3.1. Setup
3.2. Results
3.2.1. Experimental Results of Depth Estimation
3.2.2. Experimental Results for 3D Modeling
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hirschmuller, H. Stereo Processing by Semiglobal Matching and Mutual Information. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Tatar, N.; Arefi, H.; Hahn, M. High-Resolution Satellite Stereo Matching by Object-Based Semiglobal Matching and Iterative Guided Edge-Preserving Filter. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1841–1845. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, H. A High-Throughput Depth Estimation Processor for Accurate Semiglobal Stereo Matching Using Pipelined Inter-Pixel Aggregation. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 411–422. [Google Scholar] [CrossRef]
- Khan, M.A.U.; Nazir, D.; Pagani, A.; Mokayed, H.; Liwicki, M.; Stricker, D.; Afzal, M.Z. A Comprehensive Survey of Depth Completion Approaches. Sensors 2022, 22, 6969. [Google Scholar] [CrossRef] [PubMed]
- Liao, Y.H.; Zhang, S. Semi-Global Matching Assisted Absolute Phase Unwrapping. Sensors 2022, 30, 411. [Google Scholar] [CrossRef] [PubMed]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch: A Randomized Correspondence Algorithm for Structural Image Editing. ACM Trans. Graph. 2009, 28, 24. [Google Scholar] [CrossRef]
- Bleyer, M.; Rhemann, C.; Rother, C. PatchMatch Stereo-Stereo Matching with Slanted Support Windows. In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August – 2 September 2011; pp. 1–11. [Google Scholar] [CrossRef] [Green Version]
- Shen, S. Accurate Multiple View 3D Reconstruction Using Patch-Based Stereo for Large-Scale Scenes. IEEE Trans. Image Process. 2013, 22, 1901–1914. [Google Scholar] [CrossRef] [PubMed]
- Zheng, E.; Dunn, E.; Jojic, V.; Frahm, J.M. PatchMatch Based Joint View Selection and Depthmap Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1510–1517. [Google Scholar] [CrossRef]
- Xu, Q.; Tao, W. Multi-View Stereo with Asymmetric Checkerboard Propagation and Multi-Hypothesis Joint View Selection. arXiv 2018, arXiv:1805.07920. [Google Scholar] [CrossRef]
- Yang, X.; Jiang, G. A Practical 3D Reconstruction Method for Weak Texture Scenes. Remote Sens. 2021, 13, 3103. [Google Scholar] [CrossRef]
- Ji, M.; Gall, J.; Zheng, H.; Liu, Y.; Fang, L. SurfaceNet: An End-to-End 3D Neural Network for Multiview Stereopsis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2326–2334. [Google Scholar] [CrossRef] [Green Version]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. MVSNet: Depth Inference for Unstructured Multi-view Stereo. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 1–17. [Google Scholar] [CrossRef] [Green Version]
- Xu, Q.; Su, W.; Qi, Y.; Tao, W.; Pollefeys, M. Learning Inverse Depth Regression for Pixelwise Visibility-Aware Multi-View Stereo Networks. Int. J. Comput. Vis. 2022, 130, 2040–2059. [Google Scholar] [CrossRef]
- Dong, Y. Spatio-Temporally Coherent 4D Reconstruction from Multiple View Video; Information Engineering University: Zhengzhou, China, 2020. [Google Scholar] [CrossRef]
- Furukawa, Y.; Ponce, J. Accurate, Dense, and Robust Multiview Stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1362–1376. [Google Scholar] [CrossRef] [PubMed]
- Hernandez, C.; Vogiatzis, G.; Cipolla, R. Probabilistic Visibility for Multi-View Stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Campbell, N.D.F.; Vogiatzis, G.; Hernández, C.; Cipolla, R. Using Multiple Hypotheses to Improve Depth-Maps for Multi-View Stereo. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 766–779. [Google Scholar] [CrossRef] [Green Version]
- Lhuillier, M.; Quan, L. A Quasi-Dense Approach to Surface Reconstruction from Uncalibrated Images. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 418–433. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Habbecke, M.; Kobbelt, L. A Surface-Growing Approach to Multi-View Stereo Reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Zhu, Z. Research on Dense 3D Reconstruction from Unordered Images; National University of Defense Technology: Changsha, China, 2015; Available online: https://cdmd.cnki.com.cn/Article/CDMD-90002-1017834269.htm (accessed on 19 November 2022).
- Curless, B.; Levoy, M. A Volumetric Method for Building Complex Models from Range Images. In Proceedings of the Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 303–312. [Google Scholar] [CrossRef] [Green Version]
- Zach, C.; Pock, T.; Bischof, H. A Globally Optimal Algorithm for Robust TV-L1 Range Image Integration. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Vogiatzis, G.; Torr, P.H.; Cipolla, R. Multi-View Stereo via Volumetric Graph-Cuts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 21–23 September 2005; pp. 391–398. [Google Scholar] [CrossRef] [Green Version]
- Sinha, S.N.; Mordohai, P.; Pollefeys, M. Multi-View Stereo via Graph Cuts on the Dual of an Adaptive Tetrahedral Mesh. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Furukawa, Y.; Curless, B.; Seitz, S.M.; Szeliski, R. Reconstructing Building Interiors from Images. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 80–87. [Google Scholar] [CrossRef]
- Goesele, M.; Curless, B.; Seitz, S.M. Multi-View Stereo Revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2402–2409. [Google Scholar] [CrossRef]
- Strecha, C.; Fransens, R.; Van Gool, L. Combined Depth and Outlier Estimation in Multi-View Stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2394–2401. [Google Scholar] [CrossRef] [Green Version]
- Vogiatzis, G.; Esteban, C.H.; Torr, P.H.S.; Cipolla, R. Multiview Stereo via Volumetric Graph-Cuts and Occlusion Robust Photo-Consistency. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2241–2246. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goesele, M.; Snavely, N.; Curless, B.; Hoppe, H.; Seitz, S.M. Multi-View Stereo for Community Photo Collections. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Hu, X.; Mordohai, P. Least Commitment, Viewpoint-Based, Multi-View Stereo. In Proceedings of the International Conference on 3D Imaging, Modeling, Processing, Visualization & Transmission, Zurich, Switzerland, 13–15 October 2012; pp. 531–538. [Google Scholar] [CrossRef]
- Bailer, C.; Finckh, M.; Lensch, H.P. Scale Robust Multi View Stereo. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 398–411. [Google Scholar] [CrossRef]
- Galliani, S.; Lasinger, K.; Schindler, K. Massively Parallel Multiview Stereopsis by Surface Normal Diffusion. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 873–881. [Google Scholar] [CrossRef]
- Schonberger, J.L.; Zheng, E.; Frahm, J.-M.; Pollefeys, M. Pixelwise View Selection for Unstructured Multi-View Stereo. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 501–518. [Google Scholar] [CrossRef]
- Wei, J.; Resch, B.; Lensch, H. Multi-View Depth Map Estimation With Cross-View Consistency. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014; pp. 1–13. [Google Scholar] [CrossRef] [Green Version]
- Romanoni, A.; Matteucci, M. TAPA-MVS: Textureless-Aware PAtchMatch Multi-View Stereo. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10412–10421. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.; Liu, Y.; Shi, X.; Wang, Y.; Zheng, Y. MARMVS: Matching Ambiguity Reduced Multiple View Stereo for Efficient Large Scale Scene Reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5980–5989. [Google Scholar] [CrossRef]
- Xu, Q.; Kong, W.; Tao, W.; Pollefeys, M. Multi-Scale Geometric Consistency Guided and Planar Prior Assisted Multi-View Stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4945–4963. [Google Scholar] [CrossRef] [PubMed]
- Hartmann, W.; Galliani, S.; Havlena, M.; Van Gool, L.; Schindler, K. Learned Multi-patch Similarity. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1595–1603. [Google Scholar] [CrossRef] [Green Version]
- Kar, A.; Häne, C.; Malik, J. Learning a Multi-View Stereo Machine. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 364–375. [Google Scholar] [CrossRef]
- Gu, X.; Fan, Z.; Zhu, S.; Dai, Z.; Tan, F.; Tan, P. Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2492–2501. [Google Scholar] [CrossRef]
- Wang, F.; Galliani, S.; Vogel, C.; Speciale, P.; Pollefeys, M. PatchmatchNet: Learned Multi-View Patchmatch Stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 14189–14198. [Google Scholar] [CrossRef]
- Thomas, S.; Johannes, L.S.; Silvano, G.; Torsten, S.; Konrad, S.; Marc, P.; Andreas, G. ETH3D Benchmark. Available online: https://www.eth3d.net (accessed on 19 November 2022).
- Dong, Y.; Fan, D.; Ji, S.; Lei, R. The Purification Method of Matching Points Based on Principal Component Analysis. Acta Geod. Cartogr. Sin. 2017, 46, 228–236. [Google Scholar] [CrossRef]
- Yamaguchi, K.; McAllester, D.; Urtasun, R. Efficient Joint Segmentation, Occlusion Labeling, Stereo and Flow Estimation. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 756–771. [Google Scholar] [CrossRef] [Green Version]
- Schönberger, J.L.; Frahm, J. Structure-from-Motion Revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar] [CrossRef]
- Schöps, T.; Sattler, T.; Pollefeys, M. BAD SLAM: Bundle Adjusted Direct RGB-D SLAM. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 134–144. [Google Scholar] [CrossRef]
- Schöps, T.; Schönberger, J.L.; Galliani, S.; Sattler, T.; Schindler, K.; Pollefeys, M.; Geiger, A. A Multi-view Stereo Benchmark with High-Resolution Images and Multi-camera Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2538–2547. [Google Scholar] [CrossRef]
- Liao, J.; Fu, Y.; Yan, Q.; Xiao, C. Pyramid Multi-View Stereo with Local Consistency. Comput. Graph. Forum 2019, 38, 335–346. [Google Scholar] [CrossRef]
- Locher, A.; Perdoch, M.; Van Gool, L. Progressive Prioritized Multi-view Stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3244–3252. [Google Scholar] [CrossRef] [Green Version]
- Fuhrmann, S.; Langguth, F.; Goesele, M. MVE—A Multi-View Reconstruction Environment. In Proceedings of the Eurographics Workshop on Graphics and Cultural Heritage, Darmstadt, Germany, 6–8 October 2014; pp. 11–18. [Google Scholar] [CrossRef]
- Cernea, D. OpenMVS: Multi-View Stereo Reconstruction Library. Available online: https://cdcseacave.github.io/openMVS (accessed on 19 November 2022).
- Ren, C.; Prisacariu, V.; Reid, I. gSLICr: SLIC superpixels at over 250Hz. arXiv 2015, arXiv:1509.04232. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aanæs, H.; Jensen, R.R.; Vogiatzis, G.; Tola, E.; Dahl, A.B. Large-Scale Data for Multiple-View Stereopsis. Int. J. Comput. Vis. 2016, 120, 153–168. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
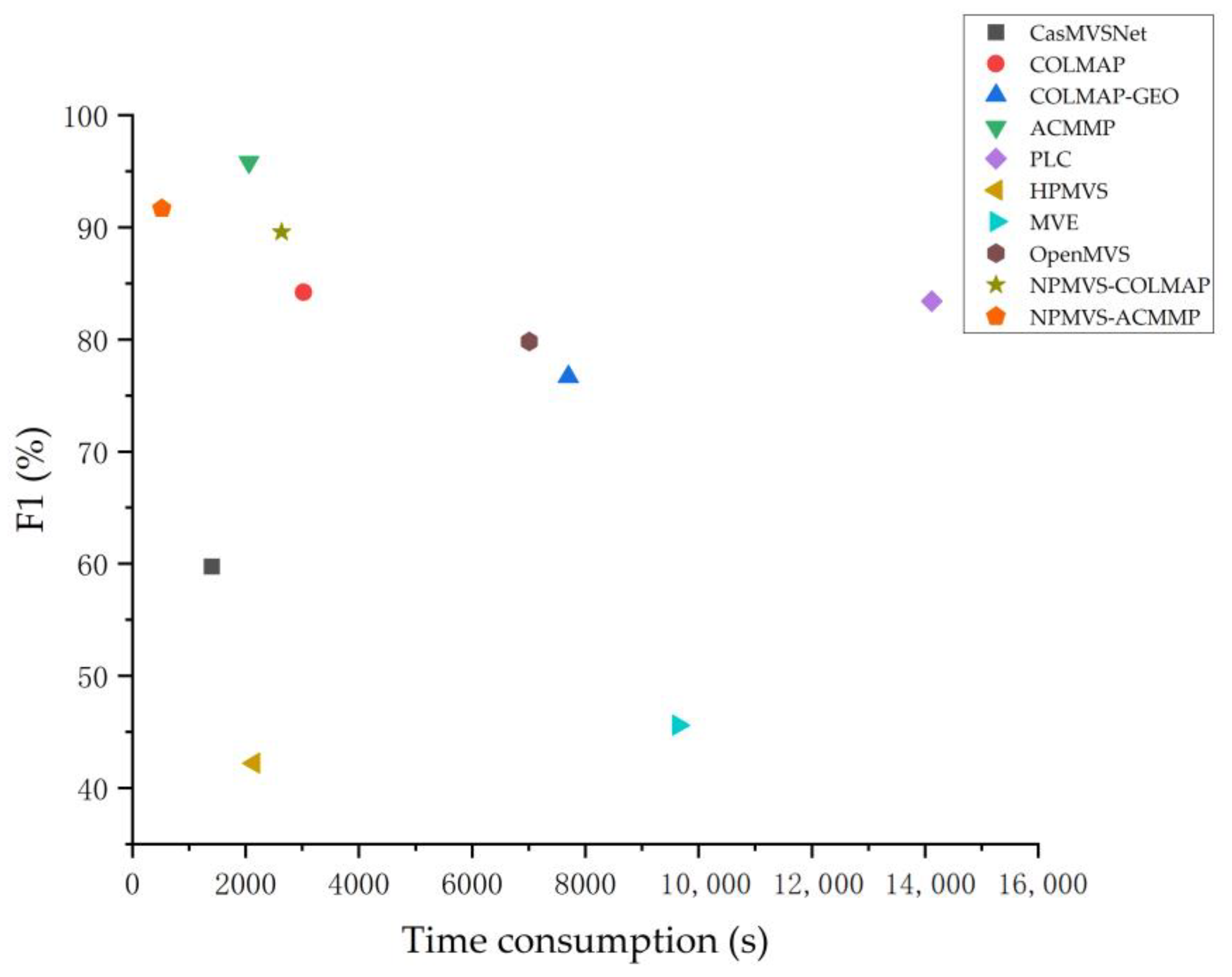{kind=link}
| Method | Avg. | Indoor | Outdoor | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Deli. | Kick. | Offi. | Pipes | Relief | Relief. | Terra. | Cour. | Elec. | Facade | Mead. | Play. | Terrace | ||
| CasMVSNet | 1402.73 | 1365.37 | 846.29 | 633.50 | 304.26 | 1677.70 | 1521.94 | 1996.85 | 1290.27 | 1111.33 | 5401.17 | 292.76 | 1046.92 | 747.20 |
| COLMAP | 3026.71 | 3446.42 | 2074.49 | 1655.43 | 962.18 | 3117.86 | 2956.17 | 3774.24 | 2972.35 | 3402.33 | 9414.43 | 951.66 | 2728.46 | 1891.15 |
| COLMAP-GEO | 7698.31 | 8052.55 | 5132.84 | 4516.79 | 2555.34 | 9294.34 | 9157.88 | 11,965.90 | 6555.20 | 8116.39 | 19,570.60 | 2431.57 | 6371.15 | 6357.46 |
| ACMMP | 2059.67 | 2790.42 | 2098.65 | 1275.53 | 536.13 | 2189.36 | 2042.35 | 3240.24 | 2713.84 | 3094.78 | - | 756.23 | 2696.27 | 1282.25 |
| PLC | 14,119.26 | 14,841.40 | 11,282.70 | 9123.19 | 4942.87 | 14,851.40 | 12,981.40 | 19,964.30 | 12,741.80 | 15,277.70 | 33,320.80 | 5194.15 | 18,613.90 | 10,414.80 |
| HPMVS | 2146.69 | 918.91 | 300.09 | 157.98 | 87.38 | 8457.83 | 6242.12 | 4455.22 | 1284.50 | 702.88 | 2475.84 | 127.21 | 218.60 | 2478.46 |
| MVE | 9641.91 | 10,037.30 | 3211.70 | 919.13 | 837.05 | 14,792.30 | 14,060.00 | 7257.59 | 13,933.70 | 6519.10 | 39,942.40 | 719.75 | 5251.61 | 7863.16 |
| OpenMVS | 7010.35 | 8782.24 | 4898.89 | 3246.76 | 1960.22 | 6820.72 | 7151.68 | 9224.69 | 9196.07 | 8209.61 | 18,647.80 | 2107.62 | 6225.12 | 4663.11 |
| NPMVS–COLMAP (ours) | 2635.92 | 2768.04 | 2139.06 | 1384.57 | 722.16 | 2577.81 | 2546.97 | 3027.74 | 2669.81 | 2798.57 | 8840.57 | 847.28 | 2353.23 | 1591.15 |
| NPMVS–ACMMP (ours) | 521.18 | 660.51 | 451.13 | 356.19 | 203.21 | 480.40 | 484.50 | 635.52 | 555.80 | 662.46 | 1145.96 | 239.10 | 548.03 | 352.48 |
| Method | Avg. | Indoor | Outdoor | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Deli. | Kick. | Offi. | Pipes | Relief | Relief. | Terra. | Cour. | Elec. | Facade | Mead. | Play. | Terrace | ||
| CasMVSNet | 76.63% | 81.80% | 76.59% | 87.73% | 85.17% | 86.59% | 80.67% | 75.11% | 83.41% | 91.54% | 73.77% | 55.80% | 56.74% | 61.33% |
| COLMAP | 95.58% | 96.50% | 93.60% | 94.27% | 96.22% | 97.65% | 96.78% | 94.77% | 97.46% | 97.62% | 95.30% | 92.25% | 94.35% | 95.80% |
| COLMAP-GEO | 98.79% | 99.38% | 99.42% | 99.55% | 99.53% | 99.61% | 99.53% | 98.88% | 99.06% | 99.62% | 98.54% | 93.28% | 98.66% | 99.22% |
| ACMMP | 97.72% | 98.75% | 92.96% | 94.64% | 98.88% | 98.43% | 98.34% | 98.35% | 99.55% | 99.01% | - | 96.56% | 98.27% | 98.93% |
| PLC | 98.02% | 99.40% | 97.40% | 95.87% | 97.99% | 99.61% | 99.55% | 98.87% | 98.93% | 99.73% | 98.34% | 90.20% | 98.83% | 99.58% |
| HPMVS | 96.22% | 95.08% | 96.34% | 98.73% | 95.42% | 98.59% | 98.86% | 96.52% | 94.63% | 97.66% | 95.65% | 88.27% | 97.86% | 97.29% |
| MVE | 94.61% | 86.23% | 94.49% | 96.81% | 95.87% | 98.10% | 97.50% | 93.58% | 96.86% | 94.37% | 96.26% | 92.04% | 96.76% | 91.03% |
| OpenMVS | 97.45% | 98.20% | 97.35% | 97.59% | 99.11% | 98.27% | 98.16% | 97.17% | 97.85% | 98.27% | 95.73% | 96.37% | 96.28% | 96.44% |
| NPMVS–COLMAP (ours) | 93.99% | 96.83% | 82.17% | 86.14% | 94.63% | 97.70% | 97.04% | 94.89% | 97.88% | 97.76% | 95.28% | 91.43% | 93.84% | 96.34% |
| NPMVS–ACMMP (ours) | 98.27% | 99.20% | 97.21% | 98.43% | 99.11% | 99.36% | 99.31% | 98.59% | 98.64% | 99.44% | 97.76% | 92.05% | 98.90% | 99.54% |
| Method | Avg. | Indoor | Outdoor | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Deli. | Kick. | Offi. | Pipes | Relief | Relief. | Terra. | Cour. | Elec. | Facade | Mead. | Play. | Terrace | ||
| CasMVSNet | 52.07% | 66.41% | 55.11% | 37.23% | 28.05% | 75.69% | 71.41% | 80.94% | 48.12% | 53.37% | 48.28% | 13.78% | 24.80% | 73.76% |
| COLMAP | 76.32% | 87.22% | 70.91% | 52.05% | 52.13% | 83.05% | 81.97% | 90.99% | 83.90% | 83.96% | 78.27% | 56.82% | 77.12% | 93.76% |
| COLMAP-GEO | 64.35% | 79.84% | 45.05% | 39.52% | 42.12% | 73.09% | 74.74% | 80.07% | 73.46% | 75.21% | 70.03% | 39.18% | 58.21% | 86.07% |
| ACMMP | 94.12% | 98.19% | 94.19% | 95.65% | 90.17% | 94.06% | 93.52% | 97.54% | 97.93% | 96.94% | - | 80.42% | 93.09% | 97.70% |
| PLC | 73.34% | 85.76% | 77.13% | 64.21% | 59.78% | 75.78% | 52.44% | 88.43% | 82.49% | 78.86% | 78.65% | 53.24% | 69.11% | 87.52% |
| HPMVS | 28.01% | 31.88% | 21.95% | 10.31% | 15.08% | 32.95% | 30.71% | 21.16% | 52.63% | 21.80% | 40.75% | 28.20% | 20.08% | 36.61% |
| MVE | 31.84% | 37.11% | 19.90% | 14.49% | 6.37% | 31.41% | 38.86% | 43.08% | 51.76% | 21.25% | 50.20% | 14.45% | 33.02% | 52.05% |
| OpenMVS | 69.50% | 85.92% | 47.40% | 44.41% | 49.68% | 77.02% | 77.44% | 85.42% | 84.74% | 82.37% | 69.27% | 41.25% | 64.76% | 93.86% |
| NPMVS–COLMAP (ours) | 86.06% | 92.44% | 92.98% | 89.13% | 73.57% | 85.23% | 86.37% | 94.39% | 92.20% | 86.02% | 82.61% | 67.53% | 79.67% | 96.62% |
| NPMVS–ACMMP (ours) | 86.19% | 95.35% | 83.41% | 74.41% | 80.48% | 88.45% | 87.16% | 97.43% | 94.58% | 91.43% | 84.74% | 71.12% | 78.13% | 93.84% |
| Method | Avg. | Indoor | Outdoor | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Deli. | Kick. | Offi. | Pipes | Relief | Relief. | Terra. | Cour. | Elec. | Facade | Mead. | Play. | Terrace | ||
| CasMVSNet | 59.75% | 73.31% | 64.10% | 52.27% | 42.20% | 80.78% | 75.76% | 77.92% | 61.03% | 67.43% | 58.37% | 22.10% | 34.51% | 66.97% |
| COLMAP | 84.21% | 91.62% | 80.69% | 67.07% | 67.62% | 89.76% | 88.77% | 92.84% | 90.17% | 90.28% | 85.95% | 70.33% | 84.87% | 94.77% |
| COLMAP-GEO | 76.69% | 88.54% | 62.00% | 56.58% | 59.19% | 84.31% | 85.37% | 88.48% | 84.36% | 85.71% | 81.87% | 55.18% | 73.22% | 92.18% |
| ACMMP | 95.82% | 98.47% | 93.57% | 95.14% | 94.32% | 96.19% | 95.87% | 97.94% | 98.73% | 97.97% | - | 87.75% | 95.61% | 98.31% |
| PLC | 83.41% | 92.08% | 86.09% | 76.91% | 74.25% | 86.08% | 68.69% | 93.36% | 89.96% | 88.07% | 87.40% | 66.96% | 81.34% | 93.17% |
| HPMVS | 42.22% | 47.75% | 35.76% | 18.67% | 26.05% | 49.39% | 46.86% | 34.72% | 67.64% | 35.65% | 57.15% | 42.74% | 33.33% | 53.20% |
| MVE | 45.59% | 51.89% | 32.88% | 25.21% | 11.95% | 47.58% | 55.57% | 59.00% | 67.47% | 34.69% | 65.99% | 24.97% | 49.24% | 66.23% |
| OpenMVS | 79.82% | 91.65% | 63.76% | 61.05% | 66.18% | 86.36% | 86.58% | 90.92% | 90.83% | 89.62% | 80.38% | 57.78% | 77.44% | 95.14% |
| NPMVS–COLMAP (ours) | 89.58% | 94.58% | 87.24% | 87.61% | 82.78% | 91.04% | 91.39% | 94.64% | 94.96% | 91.51% | 88.49% | 77.69% | 86.17% | 96.48% |
| NPMVS–ACMMP (ours) | 91.68% | 97.23% | 89.78% | 84.75% | 88.83% | 93.59% | 92.84% | 98.01% | 96.57% | 95.27% | 90.79% | 80.24% | 87.30% | 96.60% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Y.; Song, J.; Fan, D.; Ji, S.; Lei, R. Joint Deep Learning and Information Propagation for Fast 3D City Modeling. ISPRS Int. J. Geo-Inf. 2023, 12, 150. https://doi.org/10.3390/ijgi12040150
Dong Y, Song J, Fan D, Ji S, Lei R. Joint Deep Learning and Information Propagation for Fast 3D City Modeling. ISPRS International Journal of Geo-Information. 2023; 12(4):150. https://doi.org/10.3390/ijgi12040150
Chicago/Turabian StyleDong, Yang, Jiaxuan Song, Dazhao Fan, Song Ji, and Rong Lei. 2023. "Joint Deep Learning and Information Propagation for Fast 3D City Modeling" ISPRS International Journal of Geo-Information 12, no. 4: 150. https://doi.org/10.3390/ijgi12040150