1. Introduction
Natural hazards such as earthquakes, floods and tornadoes threaten millions of people all over the world [
1]. The effects of these hazards on society and infrastructure depend on the vulnerability towards the hazards [
2]. These vulnerabilities are highly dynamic as some are decreasing due to new building codes, preparedness actions and resilient planning, while others are increasing due to rapid urbanization, increased industrialization, aging infrastructure and stronger interdependencies in modern societies [
3,
4]. Regardless of the different hazards or even combinations of them, it is key for emergency planning, resilience building and first response to catastrophes to understand the risks that a society is exposed to. Because risk is the combination of hazard, exposure and vulnerability, all three aspects of the risk chain need to be well understood for any measure to be taken to reduce it [
5].
In this paper, we focus on the exposure part of the risk chain. Exposure models, describing the spatial distribution of assets (usually buildings and people) and the relative distribution of different building types, show different levels of resolution and precision [
6]. In well-regulated countries, such models may describe the location of each building. In high-resolution studies, each building may be individually described in all relevant parameters. However, in many areas of the world, exposure models are rather coarse and are aggregated over large areas, sometimes even over entire countries. This results in them being useful only if the damage or losses are estimated at this aggregation level too. To address local planning or local emergency response, exposure models with high resolution down to the building scale are desired. To create exposure models on the building scale, the location and additional parameters of the buildings such as the building footprint, building height and building material need to be known. This information is usually provided by cadastral data. However, such data is not available everywhere, either because its use is restricted, expensive or it does not even exist [
7].
The free and open geographic data community project OpenStreetMap (OSM) is potentially able to fill this gap. Although OSM data have been used extensively in disaster mapping and management [
8], their completeness is heterogeneous, with some areas very well mapped and other areas lacking basic features [
9,
10,
11]. For example, the completeness of highly populated urban areas is often higher than that of remote and rural areas [
10,
12]. There are also differences between developed and developing countries [
11,
13]. These disparities depend on social factors, such as population distribution and population density, as well as the location of contributing users [
14].
Therefore, the assessment of the spatially heterogeneous data quality in OSM is of great importance. Current approaches can be distinguished mainly in extrinsic and intrinsic approaches. Extrinsic approaches use reference datasets as a benchmark to compare OSM against using indicators such as the length of the road network or the number of buildings or the positional accuracy of features such as buildings [
10,
15,
16]. These approaches face the challenge of missing reference data of sufficient quality, especially for large parts of the global South. For building footprints Biljecki et al. [
17] provide an overview about available administrative data. Object detection by deep learning approaches seems promising to provide reference data for OSM objects. For land-cover OSM objects, Schott et al. [
18] demonstrated the potential of noise-robust deep-learning approaches used on satellite imagery to detect potential errors in OSM land-use information. For building footprints, datasets such as the Microsoft building footprints layer [
19] are a potential reference for an increasing—but still limited—number of countries and have been used to assess the completeness of building footprints for 13,189 urban agglomerations by fitting a machine learning model to them [
13]. Research by Herfort et al. [
13] has shown that crowd-sourcing approaches, such as the one presented here, and deep-learning approaches might complement each other.
Even if reference data are available, it might be less current than OSM and cover only a subset of the relevant features [
20]. To overcome these issues, intrinsic approaches have been developed which address different aspects of data quality only based on the historical development of OSM [
21,
22,
23,
24]. Completeness of map features is thereby, for example, addressed by fitting saturation curves to the OSM contribution time series to assess the difference between fitted asymptote and current number of objects [
12] or by deriving community activity stages [
25,
26]. The completeness assessment based on saturation curves can only be used for areas with a reasonably high number of OSM features. Other approaches have tried to estimate the expected number of objects based on covariates, such as building density or geometric indicators at street-block level to estimate building completeness [
27,
28], socioeconomic indicators, population density or urban–rural gradients [
12,
29,
30]. Given large regional differences in both real-world features (such as building density) and mapping activity, the latter approaches are limited with respect to their transferability between regions, especially across urban–rural gradients or cultural boundaries. Schott et al. [
31] have implemented and tested a set of 32 intrinsic and semi-intrinsic indicators for different aspects of data quality. While they tested for land-use- and land-cover-related feature classes, many indicators are presumably transferable to other domains such as building footprints.
The Humanitarian OpenStreetMap Team (HOT) [
32] and other humanitarian organizations have been addressing the issue of OSM data completeness since 2010 by activating volunteers to map buildings and roads. HOT stimulated volunteers through mostly catastrophe-related activities in collaboration with first responders in need of good maps with building locations. This imminent benefit of the volunteers’ work for first responders has certainly drawn a lot of attention to humanitarian mapping activities in OSM. However, HOT and other organizations have not limited their activities to ongoing or imminent catastrophes, but expanded them to mapping larger areas [
11,
14]. This led to the missing maps network that aims to move from reaction to action, putting vulnerable areas/people on the map before the next disaster hits [
33].
While a lot of resources and tools are in place to ease mapping in OSM, some learning effort is still needed for newcomers wanting to contribute. To ease that initial hurdle, the smartphone application MapSwipe [
34] has been designed as a tool that requires only a minimum training effort and that uses a simple and easy-to-learn user interface. The tool has been developed and is maintained by the Heidelberg Institute for Geoinformation Technology (HeiGIT) in cooperation with the British Red Cross (BRC), the Humanitarian OpenStreetMap Team (HOT), Médecins Sans Frontières (MSF) and volunteers. MapSwipe introduced the aspect of gamification to the detection of buildings by showing the user satellite imagery prompting for the selection of areas in which buildings can be identified by the user [
35]. Once these areas are marked, the user swipes the satellite imagery aside to receive the next images—hence the name MapSwipe.
The images are categorized into groups: those with buildings and those without buildings. This process simplifies the task of digitizing the building footprints for OSM contributors, as they no longer have to scan through the entire area for buildings. This pre-selection of areas for mapping activities has proven useful as nearly 50,000 MapSwipe users have mapped more than 1,750,000 sqkm and finished about 500 projects. The data are publicly available for further use [
36]. The HOT activities, together with MapSwipe as well as regular OSM volunteer mapping, have made data in OSM become a ubiquitous part of disaster planning, emergency management and first response [
37]. The intended target group for MapSwipe has been users that lack experience in mapping in the OSM ecosystem. Therefore, the app was designed to require only a minimum training effort, which is reflected in an easy-to-learn user interface.
MapSwipe conceptually extends desktop-based approaches such as Tomnod to the smartphone, thereby further lowering the bar for volunteers by enabling them to contribute easily during idle periods such as while riding a subway or waiting for a bus. Tomnod—a former project of the satellite company DigitalGlobe—was known for its campaigns such as searching for the missing Malaysian Airlines flight MH370, which attracted over eight million participants [
38] before being discontinued in August 2019.
Gamification in MapSwipe was implemented by experience points the users obtain for completed tasks which are reflected in experience levels through the badges gained. This simple approach has been frequently used for crowd-sourcing applications with relatively simple repetitive tasks [
39]. The user-level information about MapSwipe activity accessible for registered users is comparable to other approaches in the OSM ecosystem such as for the HOT tasking manager or “How did you contribute to OSM?” [
40]. User level comparison such as those implemented for OSM users by “OSMFight” [
41] was not implemented at the time of writing.
Because risk assessment models that use OSM data also have to address the spatially varying completeness, it is important to identify areas with complete OSM building footprints for which detailed exposure models can be provided. Furthermore, emergency groups can plan additional mapping efforts in unmapped areas that are particularly affected by natural catastrophes. In contrast to the previous MapSwipe project types that are used to provide information about the presence or absence of buildings on satellite imagery, we introduced a completeness project type that classifies areas with regard to the completeness of OSM building footprints. This is intended to steer mapping activities of volunteers, for example in the HOT tasking manger, to areas where information is missing for activities such as disaster response or forecast-based financing. The new project type was designed with the intended target group of unexperienced users in mind. Therefore, the design was kept simple at the cost of limited user input options.
This study aims at investigating the robustness of the completeness data produced by this crowd-sourced approach and aims to examine the following specific research questions:
- 1.
What factors influence the performance of the OSM building completeness classification?
- 2.
How well can the completeness feature produce reliable results so that it can be used in applications of risk-assessment solutions, such as exposure modeling?
- 3.
How well can building completeness be captured by the MapSwipe approach compared to existing approaches?
The new completeness feature in the MapSwipe application is part of a larger project. The Heidelberg University, the German Research Centre for Geosciences (GFZ) in Potsdam, the Karlsruhe Institute of Technology (KIT), the Research Center for Information Technology (FZI) in Karlsruhe and the company Aeromey GmbH have teamed up in the project LOKI (Airborne Observation of Critical Infrastructures) to deliver a system based on OSM data for rapid damage assessment after earthquakes using a variety of technologies including unmanned aerial vehicles (UAV), machine learning, crowd-sourcing for recording the disaster scene and exposure models at the building scale. LOKI combines in an interdisciplinary way new technologies with existing expertise in earthquake research and earthquake-engineering knowledge [
42]. In this light, the completeness feature from MapSwipe aims to increase the resolution of existing exposure models from aggregated exposure information to a detailed building-by-building description, and to identify areas where further mapping effort is required.
6. Discussion
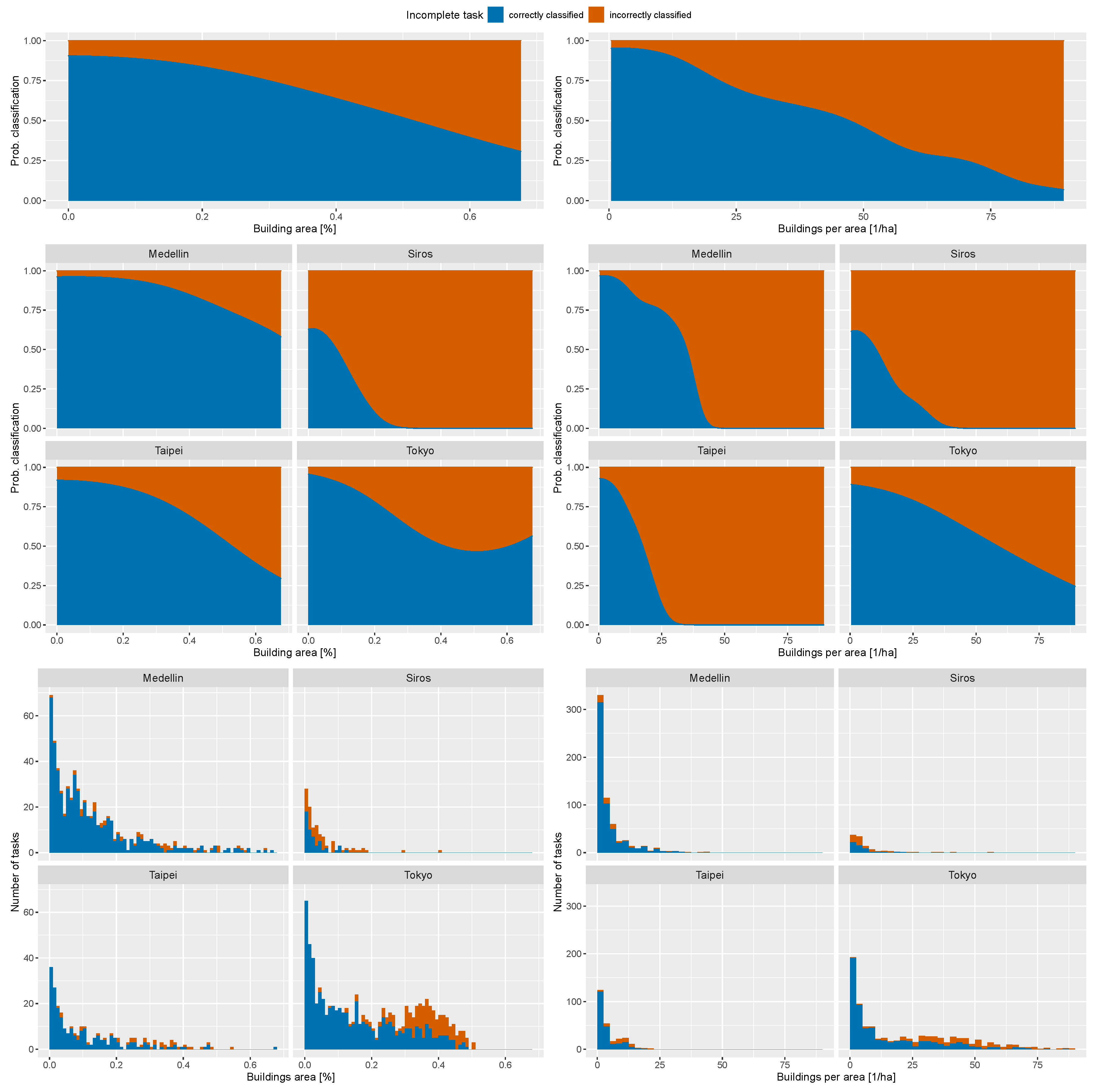
In this study, we analyzed the quality of the crowd-sourced classification of the completeness of OSM building footprints. We showed that the completeness feature in MapSwipe has the potential to produce spatially explicit information about the completeness of OSM building footprints. A factor that influenced the OSM building completeness classification were tasks with a high OSM building density, expressed both by the number of buildings or their footprint area. More buildings or a larger share of the area covered by building footprints distracted the users from a correct “incomplete” classification. After correcting for the correlated error structure, the share of the footprint area led to a slightly improved model compared to the model based on the number of buildings. Moreover, the classification performance was dependent on how exactly the OSM layer aligned with the satellite imagery. Presumably, the currentness of the satellite imagery used in MapSwipe is of importance for the quality of the assessment as well. Unfortunately, image offsets often differ between imagery from different providers. The offset might even vary across the imagery, especially in hilly or mountainous terrain. Using more recent imagery in MapSwipe than that used for the mapping of the buildings in OSM might therefore introduce a challenge for volunteers if this introduces an offset between OSM building footprints and imagery. Herfort et al. [
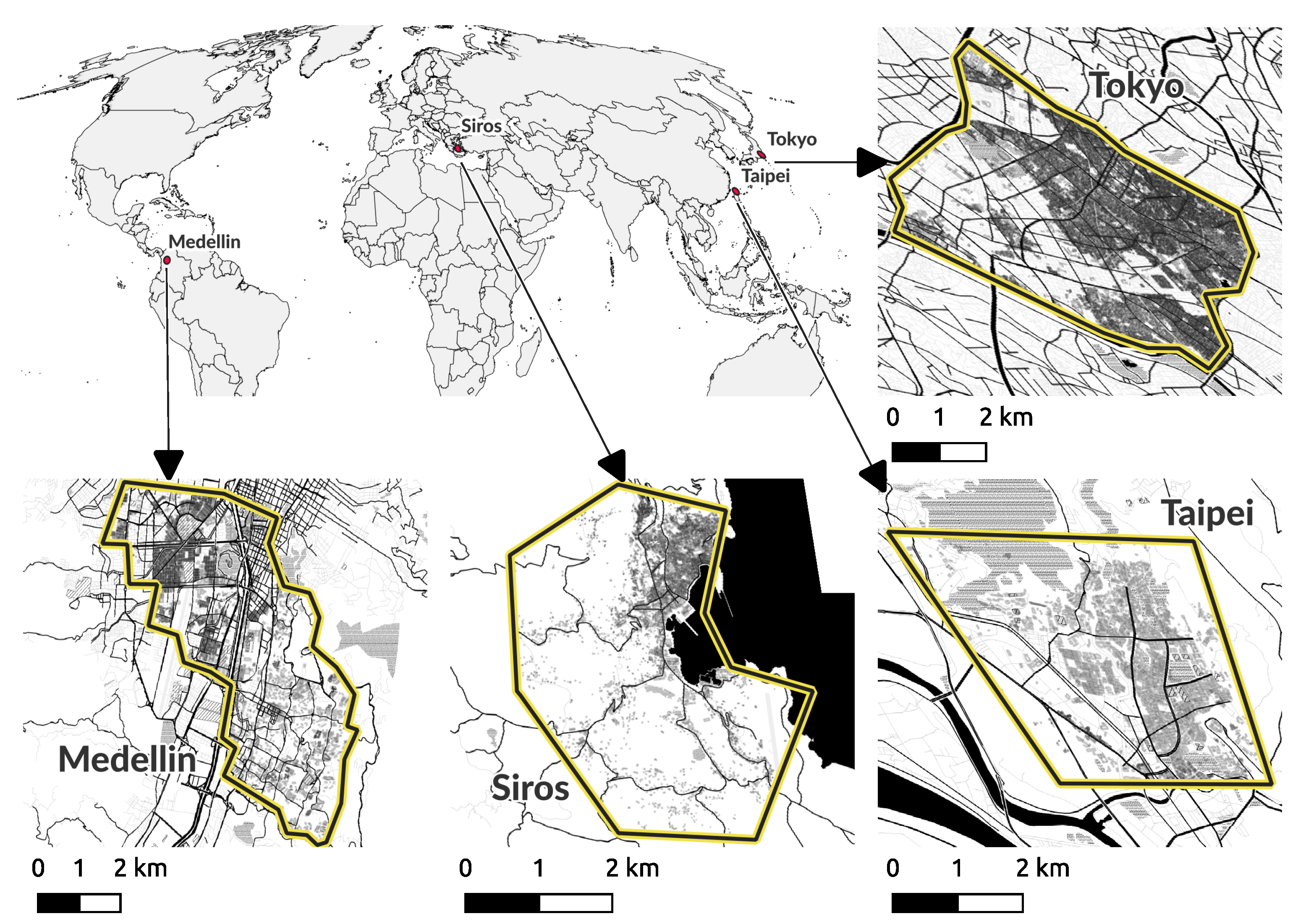
35] have shown that other factors, such as the resolution of the satellite imagery, missing images as well as presence of clouds, might also influence the quality of the classification. By successfully testing the approach at four different sites with different building textures, we suggest that the completeness feature in MapSwipe can be applied to most inhabited areas.
A main limitation of this study is the low number of volunteers taking part in the completeness mapping event. It is important to highlight that other authors have shown for OSM that a higher number of volunteers is positively related to the accuracy of the produced data [
15]. Because the answer of each MapSwipe volunteer is also prone to errors, a larger group of volunteers would presumably reduce the overall uncertainty (“wisdom of the crowd”). The same applies to the number of experts. The quality of the classification task clearly depends not only on the properties of the task (such as building density, alignment of OSM and satellite imagery) but also on the experience of the volunteers with such pattern recognition tasks, on the knowledge of potential building types in the area as well as on factors influencing the concentration and motivation of the volunteers [
55,
56,
57]. These factors are, by design, not available for the researcher as MapSwipe does not request personal data from the user.
A further limitation of this study was that incomplete tasks did not provide quantitative information about the number of missing buildings. Therefore, the completeness feature does not provide information about the share of missing buildings in the incomplete tasks. While it would be possible to extend the MapSwipe completeness tool with respect to additional classes—such as “mostly complete”, “up to 50% complete”, etc.—this would come at the cost of increasing complexity. MapSwipe was designed as a tool that requires only minimum training effort and that uses a simple and easy-to-learn user interface. Extending the tool with more complex features might reduce its attractiveness for its intended users. Future work will assess how far increasing the complexity of MapSwipe tasks correlates with decreasing user satisfaction and decreasing classification quality. The current idea is that MapSwipe is used to identify areas that demand more mapping and that the mapping itself is done in established OSM editors. The amount of missing buildings could later on be derived by an analysis of the newly mapped features by tools such as the ohsome API [
23].
Herfort et al. [
58] proposed a workflow combining deep-learning and crowd-sourcing methods to generate human settlement maps. An extension to this study could be used to perform an automated approach within the incomplete tiles in order to automatically identify the share of missing human settlements. Completely mapped tiles from nearby areas might be used in this context as a training dataset. As Pisl et al. [
59] have shown, it is possible to fine-tune pre-trained deep neural networks for building detection based on a relatively small set of additional training data. Furthermore, new products such as the World Settlement Footprint 2015 or similar datasets on the global distribution of built-up areas have already relied on crowd-sourcing approaches to assess classification performance and completeness of built-up areas [
60]. In this light, the completeness feature in MapSwipe could be used in future applications to complement automated approaches by generating training as well as validation datasets and could also address specific cases in which automated approaches do not perform well.
Despite the low number of volunteers taking part in the completeness mapping project, this study has shown the characteristics of the data produced by the completeness feature from MapSwipe, which can be useful for exposure models. The misclassifications mostly happened in nearly complete tasks. For exposure modeling, these are of minor importance, since results will only be affected marginally if a few buildings in nearly complete tiles are unmapped. It would have been more problematic if actually incomplete tiles with a big share of unmapped buildings had been considered as “complete”.
The comparison of the MapSwipe completeness assessment with the other two approaches showed clear differences. The comparison was complicated by the different spatial units as well as by the different granularity of the results, as the MapSwipe assessment returned only binary classification at the level of the tiles, while the comparison of model predictions with observed OSM buildings returned continuous complete estimates. For regions where only a few buildings are missing per tile, the MapSwipe-based assessment might therefore be too pessimistic. The quality of the intrinsic approach relies on a area what is big enough to capture the mapping dynamics in the region. The 2 km buffer chosen here might not be well suited for all study sites; further research is needed to establish better knowledge on adequate region sizes. The quality of the machine-learning-based approach [
13] differs between urban areas, so it is not clear how well the model predicts the building footprints for a specific area. The MapSwipe assessment by volunteers was able to provide, for all three considered study sites, a good estimate for the expert judgment. The other two approaches showed stronger variability, which makes a judgment based on those approaches more uncertain for a new study site. In addition, one should consider that the volunteer-based approach offered a much finer and detailed view on the OSM completeness as it is available at the level of the MapSwipe tiles. The OSM completeness estimation based on the model by Herfort et al. [
13] was currently only available for urban centers at 1 sqkm grid cell level, which might be sufficient enough for disaster-based applications. The intrinsic approach requires integration across larger areas and can therefore be less detailed. However, the different approaches presumably complement each other as the labor-intensive MapSwipe approach can only be applied to smaller-scale areas while the approach by Herfort et al. [
13] provides coarser-scale prediction for urban centers worldwide and the intrinsic approach can be easily applied at a bit larger scale. The MapSwipe approach and the intrinsic approach can be extended to other OSM feature classes such as roads relatively easily, while the machine learning approach requires extensive training data as well as huge training effort for other OSM feature classes.
User experience presumably constitutes another relevant factor for the quality of contributions. As the new feature was tested in a developer instance of the app, it was, for the case study, not possible to quantify this effect. However, future work will investigate the effects of user experience on the classification performance of the users. This might lead to a new aggregation scheme across users, which may use MapSwipe experience as weights.
Further analysis should test extended possibilities for gamification of MapSwipe and how this affects user motivation. This might involve possibilities for the comparison of different users or rankings of users. We have provided such rankings on demand for a few organizations involved in larger MapSwipe campaigns. However, we were also confronted with the potential drawbacks of such rankings: these might stimulate low-quality classifications to speed up the swiping and to position one higher in the ranking.
Another aspect that requires further improvement is the user interface. The way that OSM buildings are displayed in the tiles is currently optimized for OSM building visibility. The cost is that the semi-transparent filled polygons tend to hide the underlying parts of the satellite imagery. Extensive testing with users will be needed to identify a compromise that allows both to see the satellite imagery and to easily grasp the existing building footprints. As MapSwipe is used in very different geographic settings, a solution needs to work for different terrain and land-cover settings. In densely populated urban areas, images with a higher resolution than that of zoom level 18 could be beneficial. However, this requires the availability of drone or aerial imagery, which is, so far, only available for selected areas.
In our study, we focused on the completeness of buildings. An interesting application might be a local assessment of machine learning predictions such as the Microsoft buildings footprint [
19]. The approach could, in principle, be extended also to other machine-learning-based feature predictions such as the Map With AI roads dataset by Facebook [
61]. We can think of many other OSM classes such as land-use features or streets where a similar completeness-task design could be developed. In the domain of land-use and land-cover, classification studies that underline the potential of crowd-sourcing approaches for better earth observation already exist [
62,
63]. Further studies are needed to fully comprehend which OSM classes perform well and which OSM classes are too complex. The use of MapSwipe to detect incompletely mapped regions at a small scale is limited to tasks that can be easily detected based on satellite imagery. It is not a silver bullet approach suitable for all types of OSM aspects, but it complements other approaches such as intrinsic and extrinsic data-quality assessments, incorporation of other Volunteered Geographic Information sources such as Twitter [
64] and awareness-raising campaigns for mapathons [
65].

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}