
Estimation of Travel Cost between Geographic Coordinates Using Artificial Neural Network: Potential Application in Vehicle Routing Problems

Abstract
:1. Introduction
2. Literature Review
2.1. Euclidean Distance and Road Distance
2.2. Routing Engines
2.3. Travel Cost Estimation
3. Artificial Neural Network Model
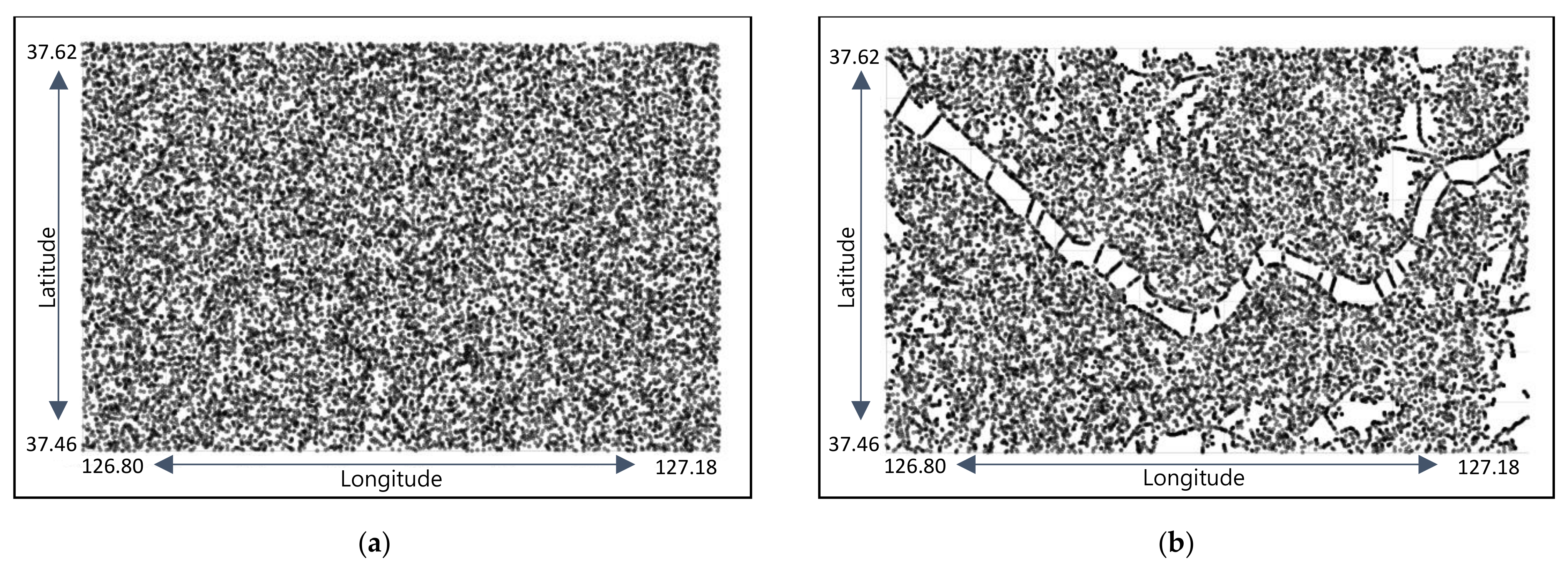
3.1. Training and Test Data
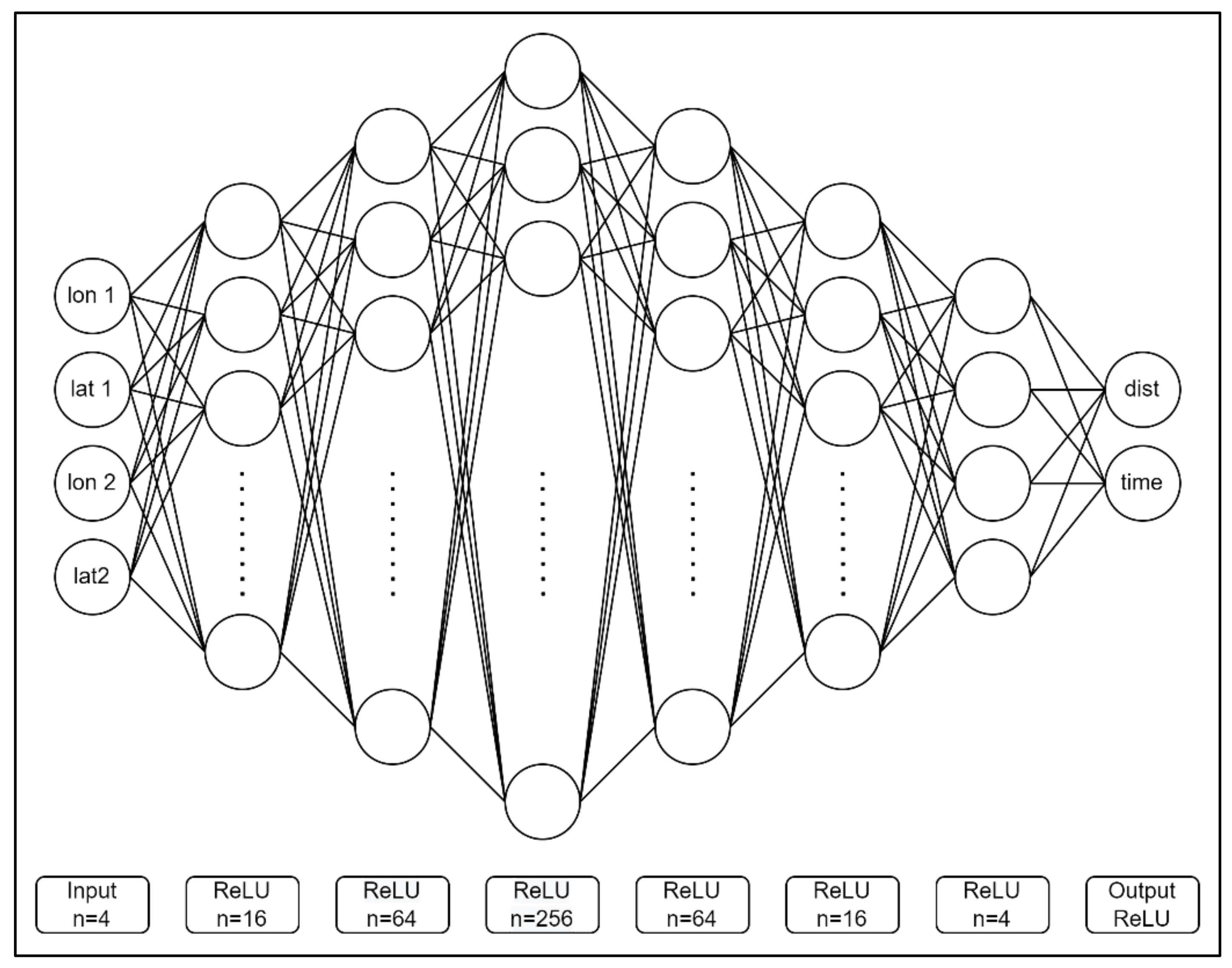
3.2. Model Construction and Train Parameters
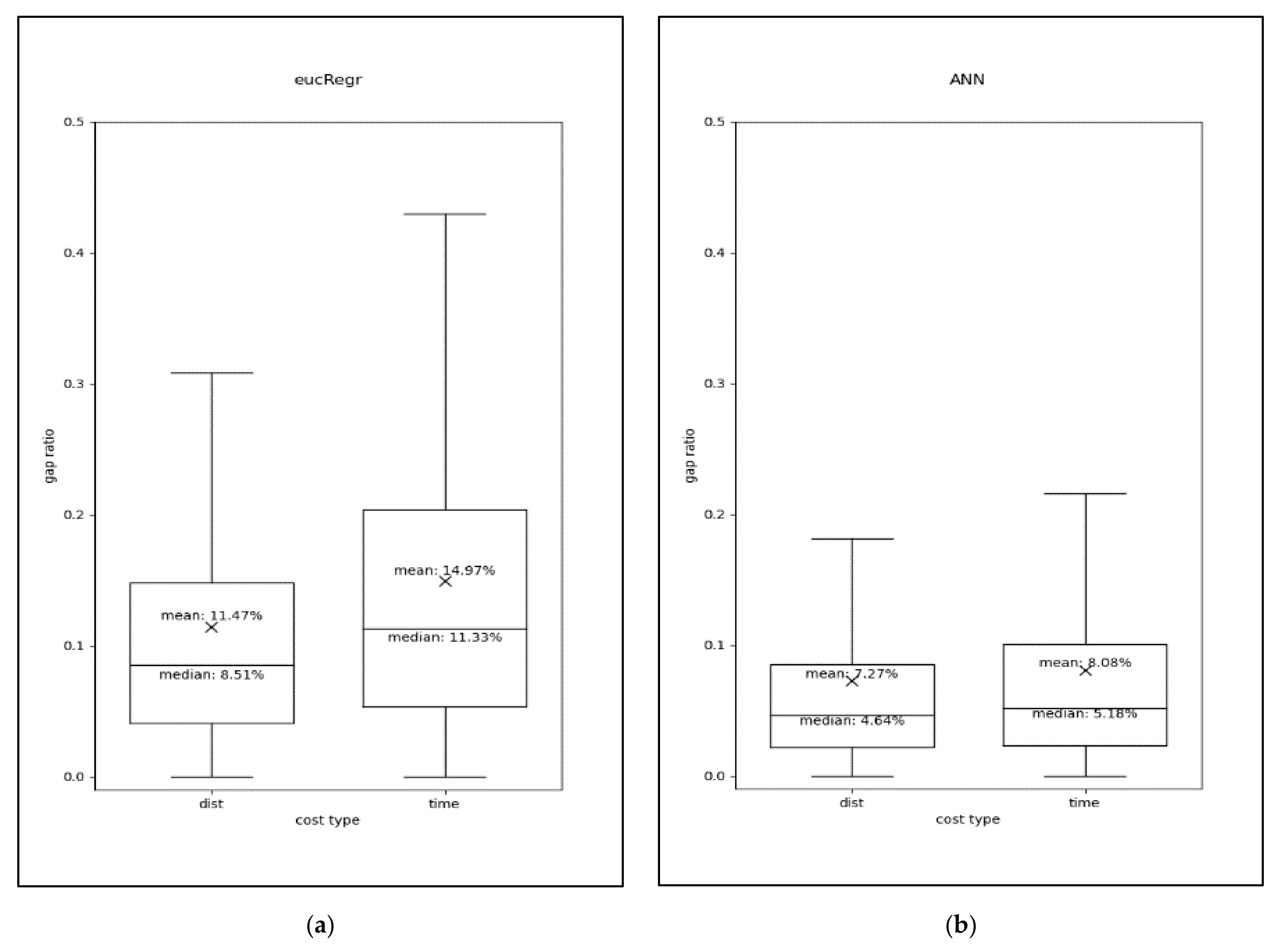
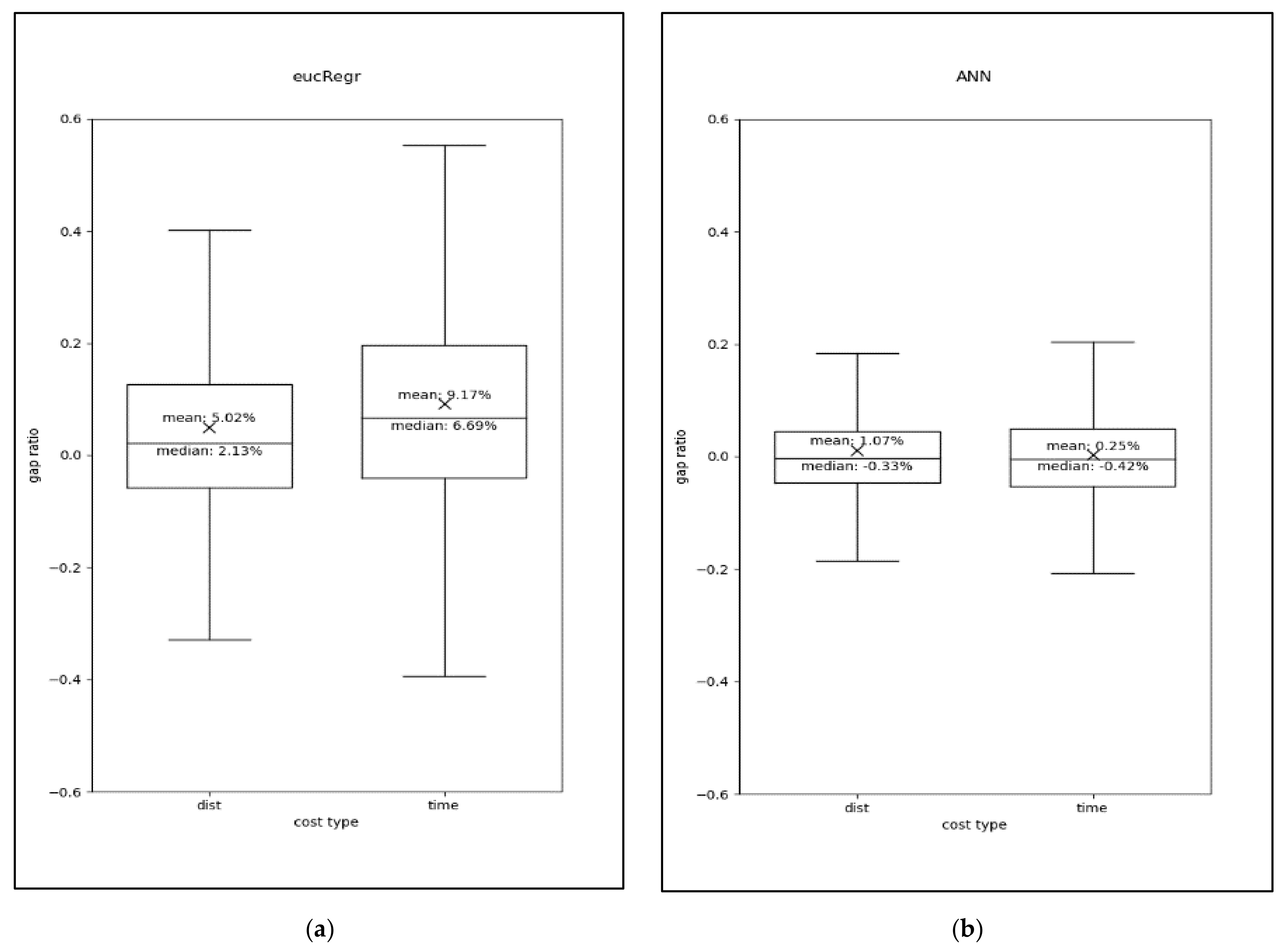
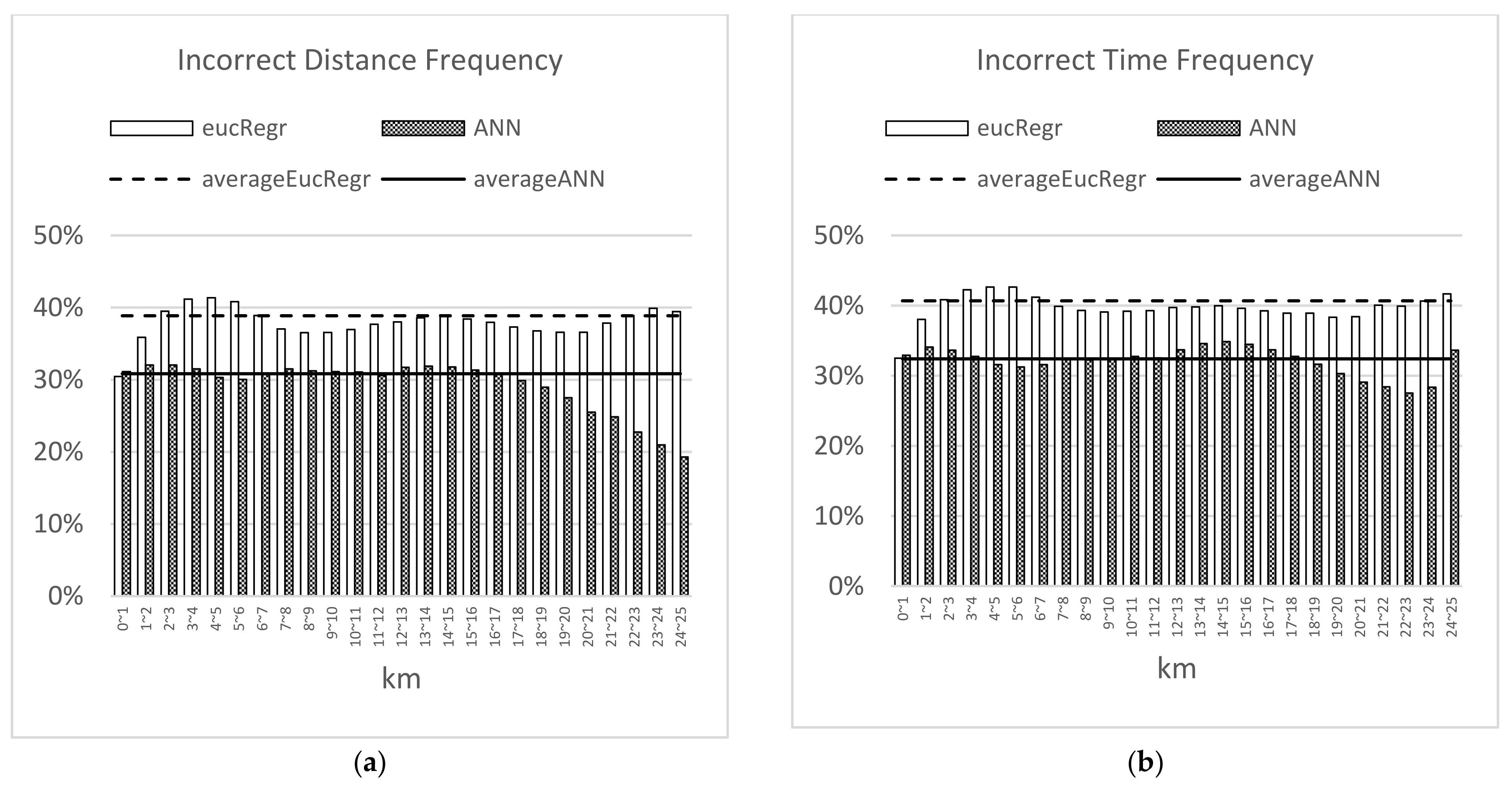
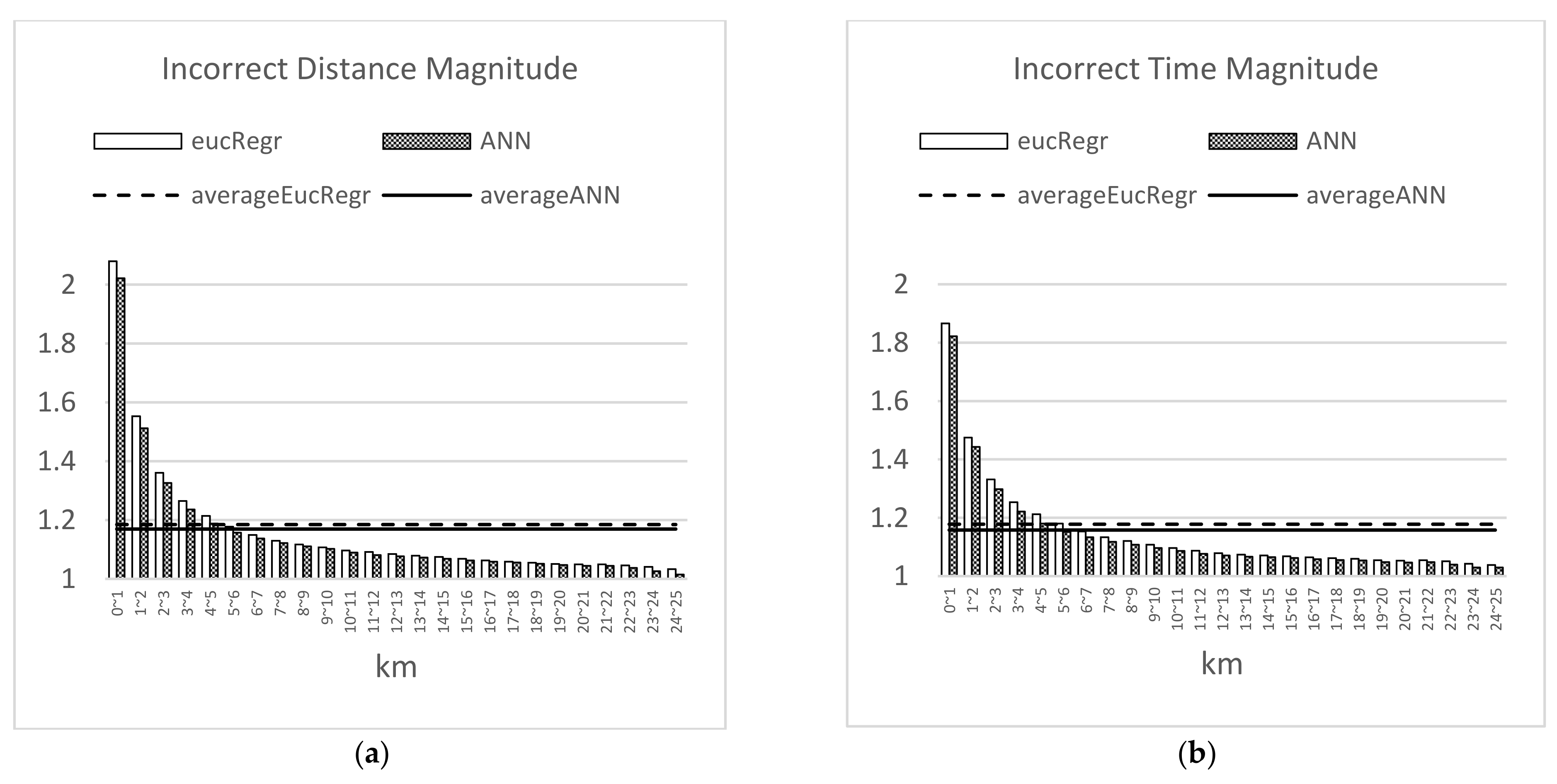
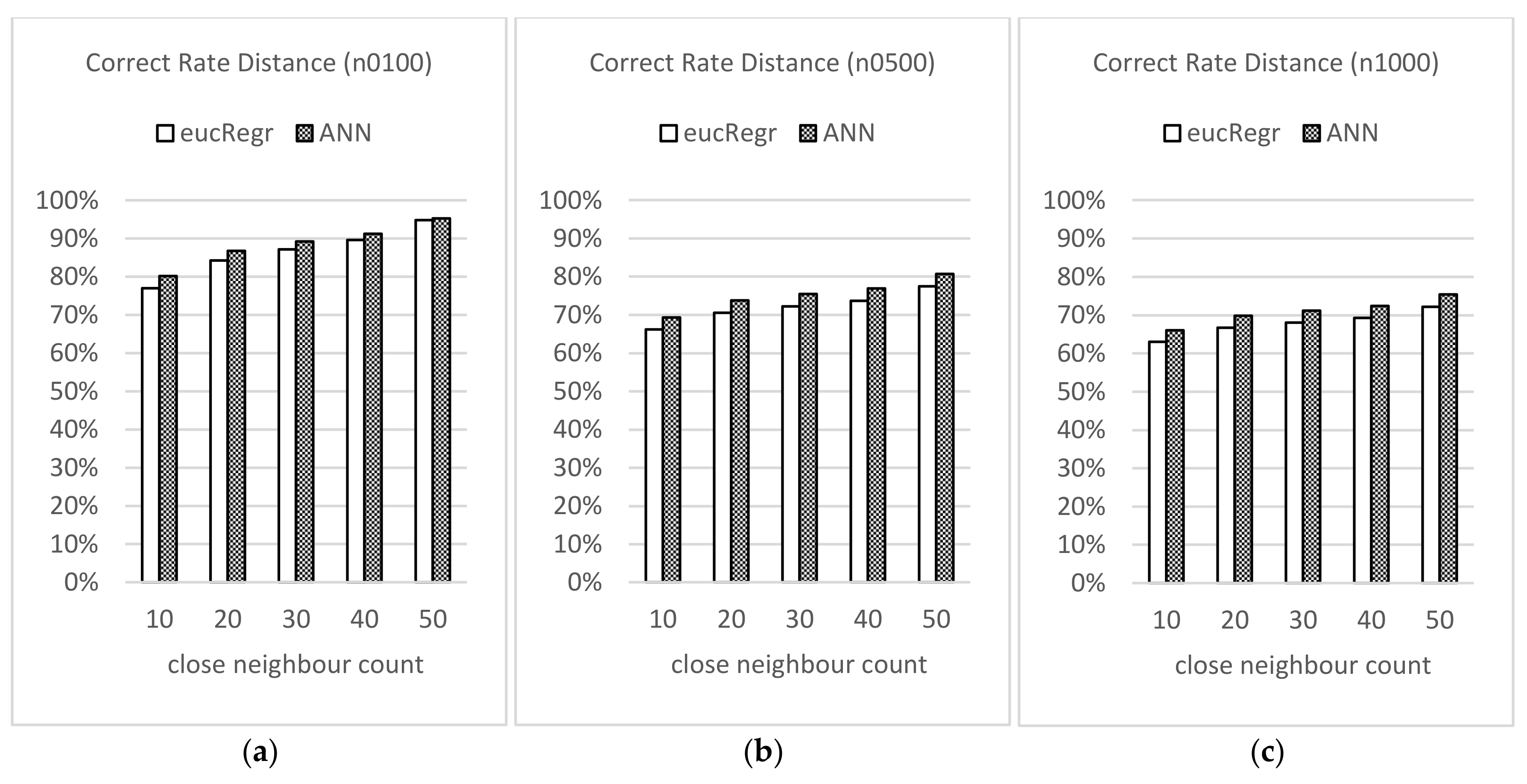
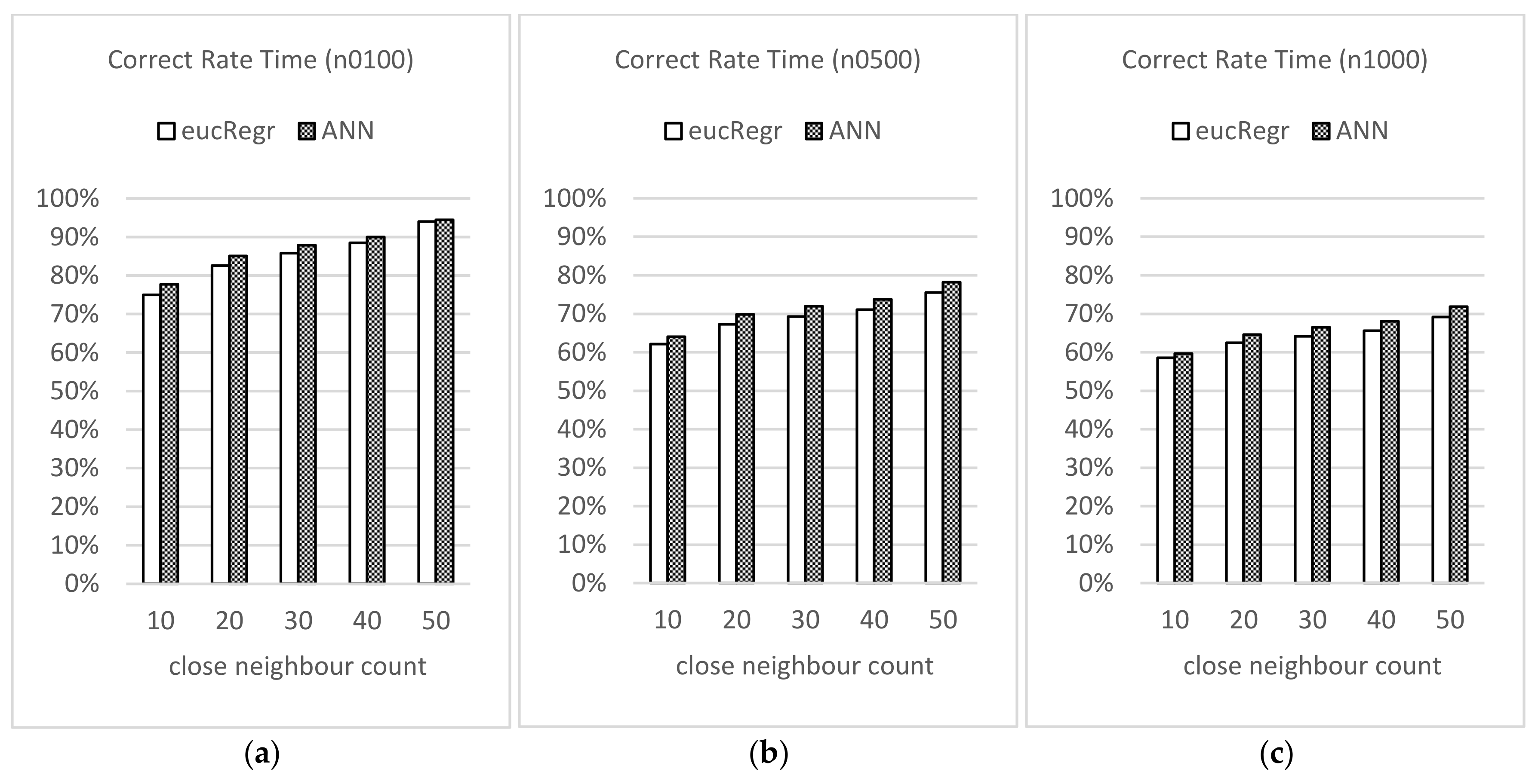
3.3. Estimation Performance of the Model
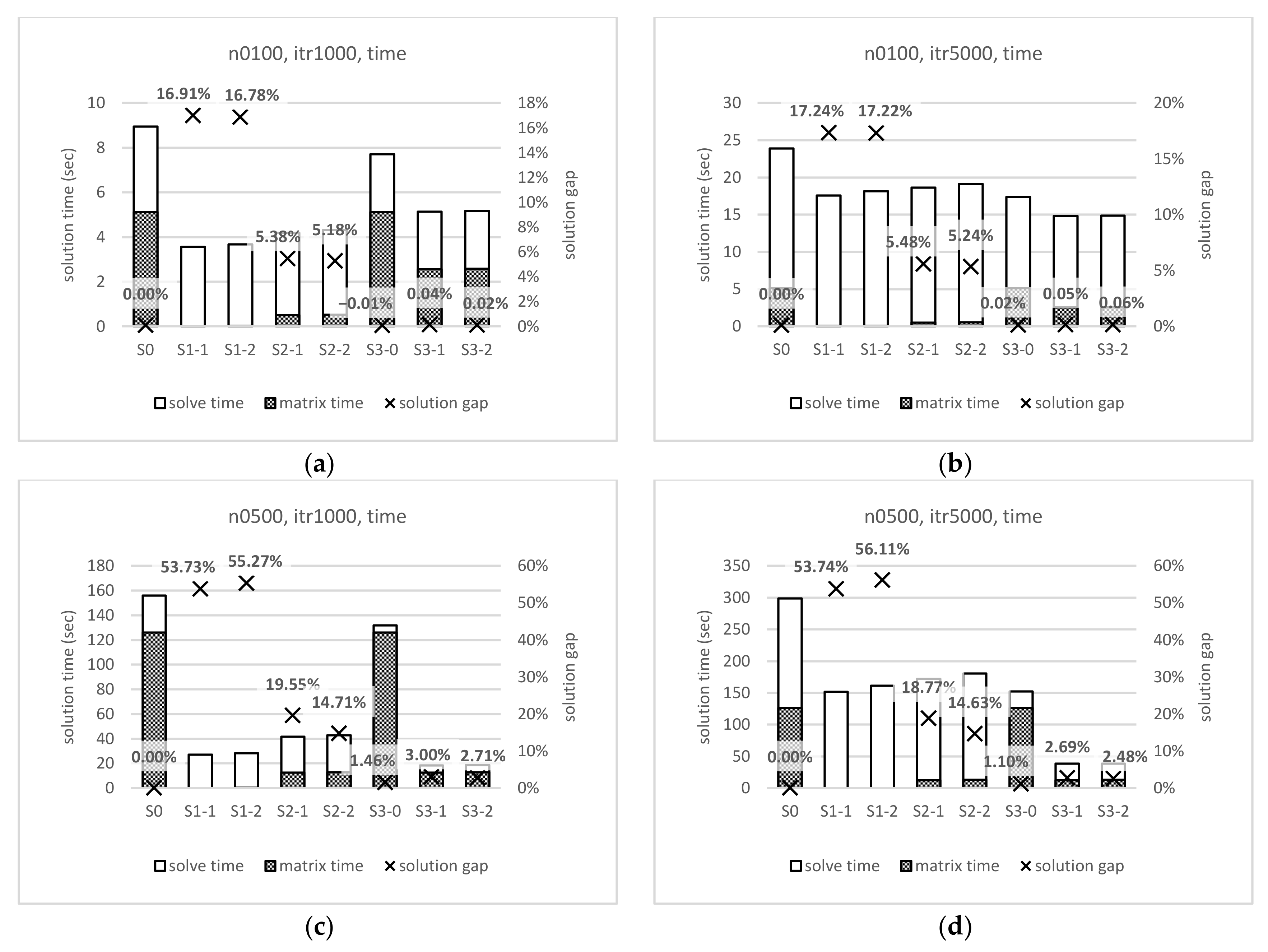
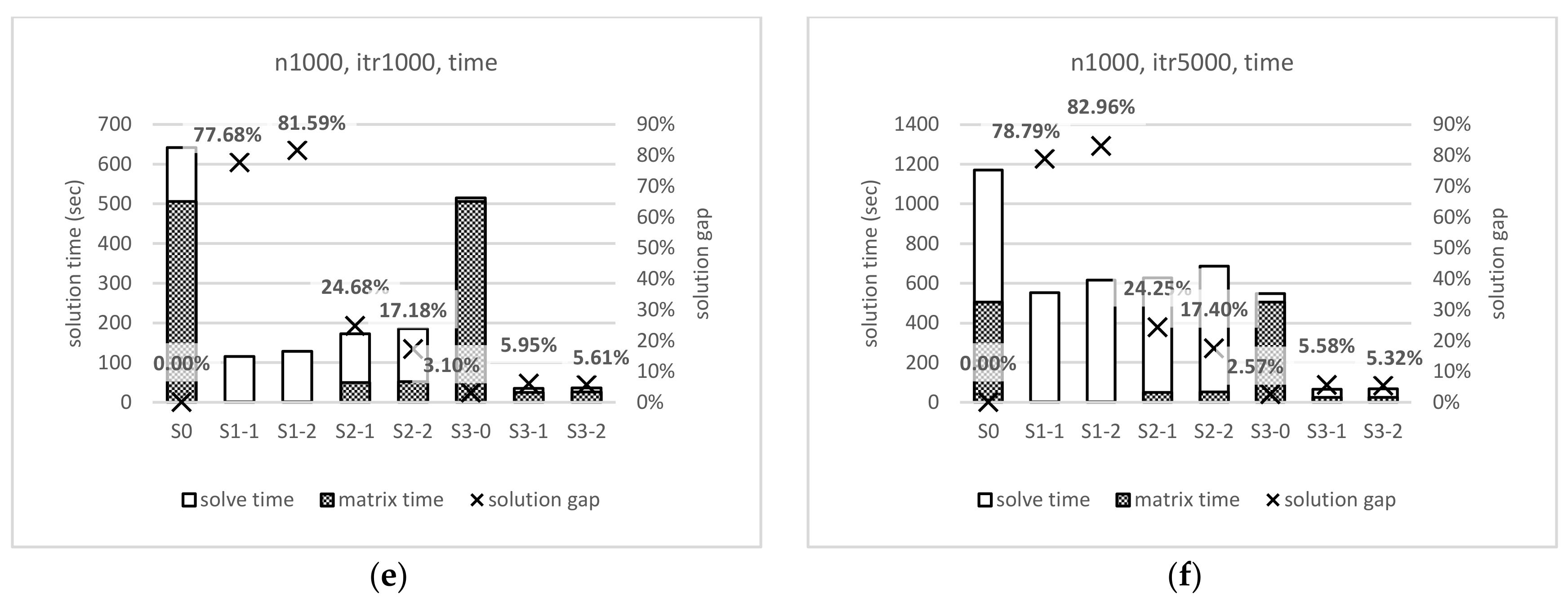
4. Potential Application in Vehicle Routing Problems
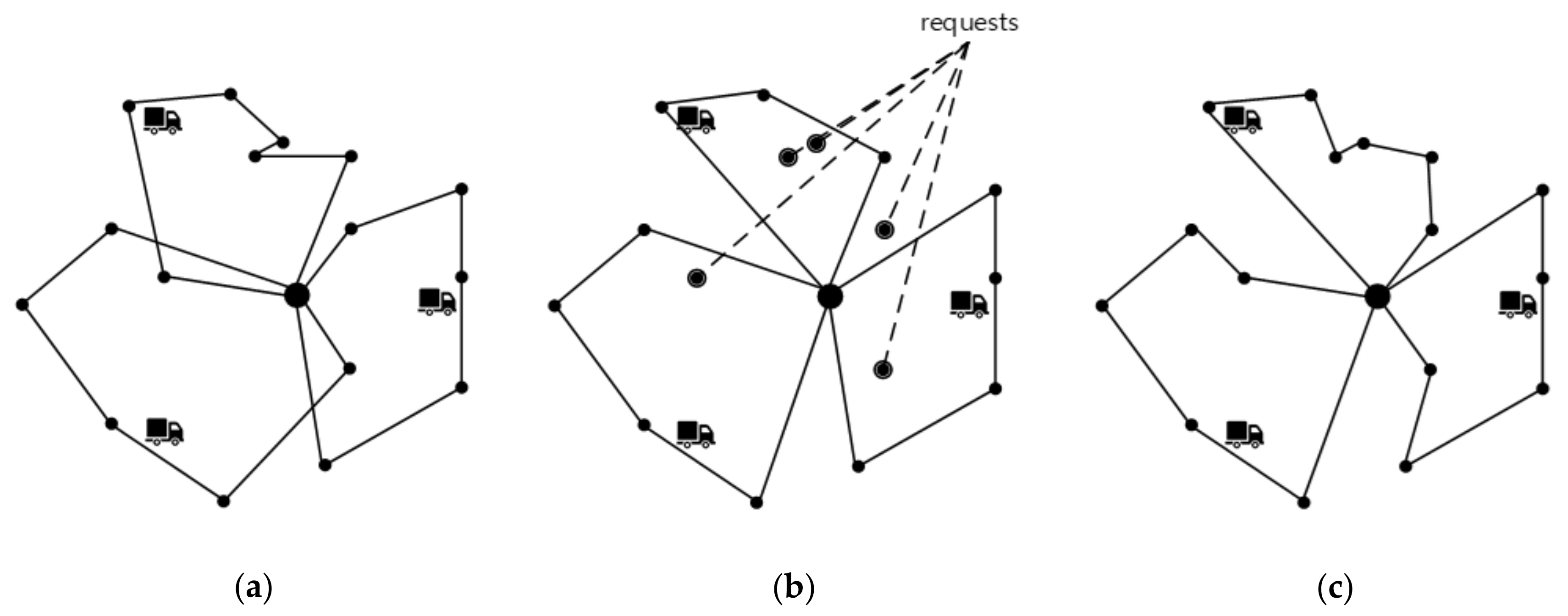
4.1. Scenario Design
4.2. Instance Creation and Solution Method
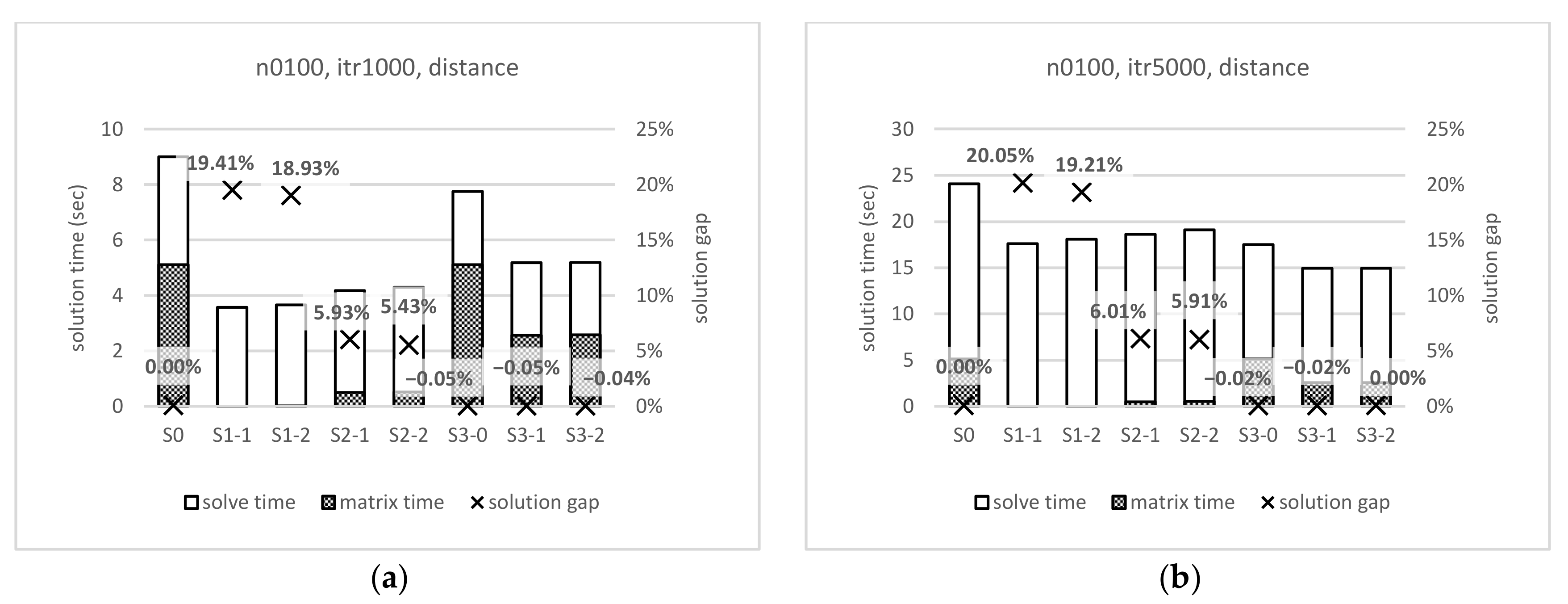
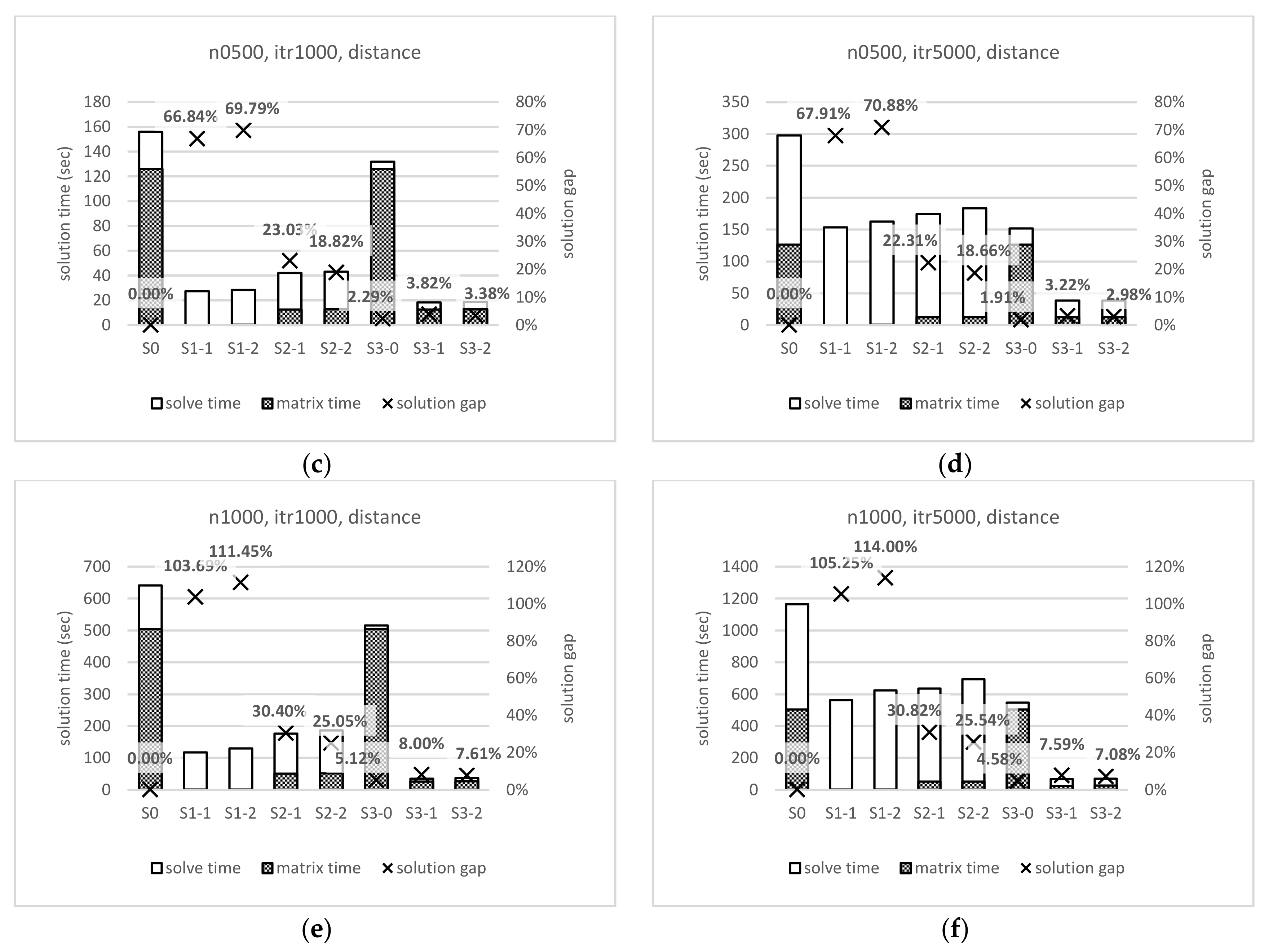
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Toth, P.; Vigo, D. The Vehicle Routing Problem; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2002; ISBN 0-89871-498-2. [Google Scholar]
- Laporte, G.; Nobert, Y. Exact Algorithms for the Vehicle Routing Problem. North-Holl. Math. Stud. 1987, 132, 147–184. [Google Scholar] [CrossRef]
- Gower, J.C. Properties of Euclidean and non-Euclidean distance. Linear Algebra Appl. 1985, 67, 81–97. [Google Scholar] [CrossRef]
- Smet, G. De OptaPlanner-Vehicle Routing with Real Road Distances. Available online: https://www.optaplanner.org/blog/2014/09/02/VehicleRoutingWithRealRoadDistances.html (accessed on 9 June 2022).
- Boyacı, B.; Dang, T.H.; Letchford, A.N. Vehicle routing on road networks: How good is Euclidean approximation? Comput. Oper. Res. 2021, 129, 105197. [Google Scholar] [CrossRef]
- Lee, K.; Chae, J. A proposal and analysis of new realistic sets of benchmark instances for vehicle routing problems with asymmetric costs. Appl. Sci. 2021, 11, 4790. [Google Scholar] [CrossRef]
- Google Maps Distance Matrix API. Available online: https://developers.google.com/maps/documentation/distance-matrix/overview (accessed on 9 June 2022).
- GraphHopper. GraphHopper Routing Engine. Available online: https://github.com/graphhopper (accessed on 9 June 2022).
- OpenStreetMap. Setting Up a Local Copy of the OpenStreetMap Database. Available online: https://wiki.openstreetmap.org/wiki/Setting_up_a_local_copy_of_the_OpenStreetMap_database,_kept_up_to_date_with_minutely_diffs (accessed on 9 June 2022).
- Ballou, R.H.; Rahardja, H.; Sakai, N. Selected country circuity factors for road travel distance estimation. Transp. Res. Part A Policy Pract. 2002, 36, 843–848. [Google Scholar] [CrossRef]
- Gonçalves, D.N.S.; Gonçalves, C.D.M.; De Assis, T.F.; Silva, M.A. Da Analysis of the difference between the euclidean distance and the actual road distance in Brazil. Transp. Res. Procedia 2014, 3, 876–885. [Google Scholar] [CrossRef]
- Phibbs, C.S.; Luft, H.S. Correlation of the travel time on roads versus stright line distance. Med. Care Res. Rev. 1995, 52, 532–542. [Google Scholar] [CrossRef]
- SK Telecom TMAP API. Available online: https://openapi.sk.com/API/detail?svcSeq=4#pay (accessed on 11 June 2020).
- Naver Cloud Plaform Maps Application Services-NAVER Cloud Platform. Available online: https://www.fin-ncloud.com/product/applicationService/maps (accessed on 11 June 2022).
- OSRM. Open Source Routing Machine: High Performance Routing Engine Run on OpenStreetMap Data. Available online: https://github.com/Project-OSRM/osrm-backend (accessed on 10 June 2022).
- Valhalla Valhalla: Open Source Routing Engine for OpenStreetMap. Available online: https://github.com/valhalla/valhalla (accessed on 11 June 2022).
- Openrouteservice The Open Source Route Planner Api. Available online: https://github.com/GIScience/openrouteservice (accessed on 11 June 2022).
- Lin, H.-E.; Zito, R.; Taylor, M.A.P. A review of travel-time prediction in transport and logistics. Proc. East. Asia Soc. Transp. Stud. 2005, 5, 1433–1448. [Google Scholar]
- Bai, M.; Lin, Y.; Ma, M.; Wang, P. Travel-Time Prediction Methods: A Review; Springer International Publishing: Midtown Manhattan, NY, USA, 2018; Volume 11344, ISBN 9783030057541. [Google Scholar]
- Deshmukh, P.S. Travel Time Prediction using Neural Networks: A Literature Review. In Proceedings of the 2018 International Conference on Information, Communication, Engineering and Technology (ICICET), Pune, India, 29–31 August 2018; pp. 6–10. [Google Scholar] [CrossRef]
- Jiang, G.; Zhang, R. Travel-time prediction for urban arterial road: A case on China. In IVEC2001, Proceedings of the IEEE International Vehicle Electronics Conference 2001. IVEC 2001 (Cat. No.01EX522), Tottori, Japan, 25–28 September 2001; IEEE: Piscataway, NJ, USA, 2001; pp. 255–260. [Google Scholar] [CrossRef]
- Zheng, F.; Van Zuylen, H. Urban link travel time estimation based on sparse probe vehicle data. Transp. Res. Part C Emerg. Technol. 2013, 31, 145–157. [Google Scholar] [CrossRef]
- Gurmu, Z.K.; Fan, W.D. Artificial neural network travel time prediction model for buses using only GPS data. J. Public Transp. 2014, 17, 45–65. [Google Scholar] [CrossRef]
- Wu, N.; Wang, J.; Zhao, W.X.; Jin, Y. Learning to effectively estimate the travel time for fastest route recommendation. Int. Conf. Inf. Knowl. Manag. Proc. 2019, 1923–1932. [Google Scholar] [CrossRef]
- Das, S.; Kalava, R.N.; Kumar, K.K.; Kandregula, A.; Suhaas, K.; Bhattacharya, S.; Ganguly, N. Map Enhanced Route Travel Time Prediction using Deep Neural Networks. arXiv 2019, arXiv:1911.02623. [Google Scholar] [CrossRef]
- Wang, Q.; Xu, C.; Zhang, W.; Li, J. GraphTTE: Travel time estimation based on attention-spatiotemporal graphs. IEEE Signal Process. Lett. 2021, 28, 239–243. [Google Scholar] [CrossRef]
- Jin, G.; Yan, H.; Li, F.; Huang, J.; Li, Y. Spatio-Temporal Dual Graph Neural Networks for Travel Time Estimation. arXiv 2021, arXiv:2105.13591. [Google Scholar] [CrossRef]
- Ma, J.; Chan, J.; Rajasegarar, S.; Leckie, C. Multi-attention graph neural networks for city-wide bus travel time estimation using limited data. Expert Syst. Appl. 2022, 202, 117057. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. Proc. Mach. Learn. Res. 2015, 37, 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21 June 2010; pp. 807–814. [Google Scholar]
- Agarap, A.F. Deep Learning using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Arnold, F.; Gendreau, M.; Sörensen, K. Efficiently solving very large-scale routing problems. Comput. Oper. Res. 2019, 107, 32–42. [Google Scholar] [CrossRef]
- Shaw, P. Using constraint programming and local search methods to solve vehicle routing problems. Lect. Notes Comput. Sci. 1998, 1520, 417–431. [Google Scholar] [CrossRef]
- Lee, K. Solving Capacitated Vehicle Routing Problems Using a Parallel Large Neighborhood Search Algorithm. Master’s Thesis, Korea Aerospace University, Gyeonggi, Republic of Korea, 2020. [Google Scholar]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Tang, J.; Liu, F.; Zou, Y.; Zhang, W.; Wang, Y. An Improved Fuzzy Neural Network for Traffic Speed Prediction Considering Periodic Characteristic. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2340–2350. [Google Scholar] [CrossRef]
- Yao, B.; Chen, C.; Cao, Q.; Jin, L.; Zhang, M.; Zhu, H.; Yu, B. Short-Term Traffic Speed Prediction for an Urban Corridor. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 154–169. [Google Scholar] [CrossRef]
- Lee, K.; Chae, J. Five Million Rows of Distance (meter) and Time (second) of Traveling between Two Geographical Coordinates; Mendeley Data; V1. [dataset]. Unpublished work. 2023. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Number | X (Input) | Y (Output) | ||||
|---|---|---|---|---|---|---|
| Longitude 1 | Latitude 1 | Longitude 2 | Latitude 2 | Distance (m) | Time (s) | |
| 1 | 126.9808 | 37.6141 | 127.1293 | 37.5760 | 17,511 | 1097 |
| 2 | 126.8230 | 37.5060 | 127.0829 | 37.5098 | 26,943 | 1400 |
| 3 | 127.0719 | 37.5136 | 126.9036 | 37.4888 | 17,235 | 1069 |
| … | … | … | … | … | … | … |
| Scenarios | Matrix Type | Cost Type | Details | |
|---|---|---|---|---|
| S0 (Base) | Full OSM matrix for VRP | Distance | - | |
| Time | ||||
| S1 | S1-1 | Full EucDist matrix for VRP | Distance | |
| Time | ||||
| S1-2 | Full ANN matrix for VRP | Distance | ||
| Time | ||||
| S2 | S2-1 | Full EucDist matrix for VRP and partial OSM matrices for TSPs | Distance | After running VRP, run TSP for each vehicle |
| Time | ||||
| S2-2 | Full ANN Matrix for VRP and partial OSM matrices for TSPs | Distance | ||
| Time | ||||
| S3 | S3-0 | Partial OSM matrix for VRP | Distance | 50 closest neighbors based on OSM |
| Time | ||||
| S3-1 | Partial OSM matrix for VRP | Distance | 50 closest neighbors based on EucDist | |
| Time | ||||
| S3-2 | Partial OSM matrix for VRP | Distance | 50 closest neighbors based on ANN | |
| Time | ||||
| Cost Type | Problem Size | LNS Iteration | Scenario | Mean Gap from S0 | Variance | Degree of Freedom | t-Statistics | t) |
|---|---|---|---|---|---|---|---|---|
| Distance | 100 | 1000 | S2-1 | 0.059340 | 0.000447 | 593 | 3.032024 | 0.002535 (<0.01) |
| S2-2 | 0.054336 | 0.000370 | ||||||
| 5000 | S2-1 | 0.060147 | 0.000366 | 595 | 0.687932 | 0.491764 (>0.05) | ||
| S2-2 | 0.059109 | 0.000316 | ||||||
| 500 | 1000 | S2-1 | 0.230325 | 0.001727 | 575 | 13.60022 | 1.01 × 10−36 (<0.001) | |
| S2-2 | 0.188196 | 0.001151 | ||||||
| 5000 | S2-1 | 0.223133 | 0.001536 | 594 | 11.89121 | 2.12 × 10−29 (<0.001) | ||
| S2-2 | 0.186558 | 0.001302 | ||||||
| 1000 | 1000 | S2-1 | 0.303998 | 0.003369 | 544 | 12.95487 | 1.21 × 10−33 (<0.001) | |
| S2-2 | 0.250463 | 0.001754 | ||||||
| 5000 | S2-1 | 0.308150 | 0.003582 | 543 | 12.40323 | 2.8 × 10−31 (<0.001) | ||
| S2-2 | 0.255393 | 0.001846 | ||||||
| Time | 100 | 1000 | S2-1 | 0.053796 | 0.000306 | 598 | 1.411387 | 0.158651 (>0.05) |
| S2-2 | 0.051796 | 0.000296 | ||||||
| 5000 | S2-1 | 0.054809 | 0.000275 | 597 | 1.81339 | 0.070274 (>0.05) | ||
| S2-2 | 0.052409 | 0.000251 | ||||||
| 500 | 1000 | S2-1 | 0.195454 | 0.001088 | 582 | 19.36356 | 7.51 × 10−65 (<0.001) | |
| S2-2 | 0.147109 | 0.000782 | ||||||
| 5000 | S2-1 | 0.187688 | 0.001239 | 535 | 16.68161 | 1.3 × 10−50 (<0.001) | ||
| S2-2 | 0.146321 | 0.000606 | ||||||
| 1000 | 1000 | S2-1 | 0.246780 | 0.002444 | 460 | 23.11096 | 5.35 × 10−79 (<0.001) | |
| S2-2 | 0.171819 | 0.000712 | ||||||
| 5000 | S2-1 | 0.242476 | 0.002457 | 454 | 21.17282 | 1.03 × 10−69 (<0.001) | ||
| S2-2 | 0.173965 | 0.000685 |
| Cost Type | Problem Size | LNS Iteration | Scenario | Mean Gap from S0 | Variance | Degree of Freedom | t-Statistics | t) |
|---|---|---|---|---|---|---|---|---|
| Distance | 100 | 1000 | S3-1 | −0.00051 | 5.43 × 10−5 | 593 | −0.27505 | 0.78337 (>0.05) |
| S3-2 | −0.00035 | 4.52 × 10−5 | ||||||
| 5000 | S3-1 | −0.00020 | 1.64 × 10−5 | 597 | −0.70038 | 0.483964 (>0.05) | ||
| S3-2 | 2.61 × 10−5 | 1.50 × 10−5 | ||||||
| 500 | 1000 | S3-1 | 0.038191 | 0.000367 | 590 | 2.96851 | 0.003114 (<0.01) | |
| S3-2 | 0.033792 | 0.000292 | ||||||
| 5000 | S3-1 | 0.032218 | 0.000228 | 596 | 1.988923 | 0.047166 (<0.05) | ||
| S3-2 | 0.029834 | 0.000203 | ||||||
| 1000 | 1000 | S3-1 | 0.080004 | 0.000563 | 597 | 2.073294 | 0.038573 (<0.05) | |
| S3-2 | 0.076061 | 0.000522 | ||||||
| 5000 | S3-1 | 0.075898 | 0.000481 | 594 | 2.977116 | 0.003028 (<0.01) | ||
| S3-2 | 0.070769 | 0.000409 | ||||||
| Time | 100 | 1000 | S3-1 | 0.000427 | 3.21 × 10−5 | 598 | 0.579254 | 0.562636 (>0.05) |
| S3-2 | 0.000161 | 3.12 × 10−5 | ||||||
| 5000 | S3-1 | 0.000478 | 1.03 × 10−5 | 597 | −0.31144 | 0.755578 (>0.05) | ||
| S3-2 | 0.000561 | 1.11 × 10−5 | ||||||
| 500 | 1000 | S3-1 | 0.030004 | 0.000177 | 597 | 2.757916 | 0.005995 (<0.01) | |
| S3-2 | 0.027065 | 0.000164 | ||||||
| 5000 | S3-1 | 0.026874 | 0.000128 | 598 | 2.263893 | 0.023938 (<0.05) | ||
| S3-2 | 0.024801 | 0.000123 | ||||||
| 1000 | 1000 | S3-1 | 0.059465 | 0.000304 | 596 | 2.464255 | 0.014011 (<0.05) | |
| S3-2 | 0.056052 | 0.000271 | ||||||
| 5000 | S3-1 | 0.055786 | 0.000218 | 598 | 2.154696 | 0.031584 (<0.05) | ||
| S3-2 | 0.053207 | 0.000212 |
| Time | Matrix Size | OSM | EucDist | ANN | |
|---|---|---|---|---|---|
| Matrix creation | 100 | 5.12 s | <0.01 s | <0.01 s | |
| 500 | 126.12 s | ||||
| 1000 | 505.13 s | ||||
| 100 | 0.52 s | ||||
| 500 | 12.79 s | ||||
| 1000 | 51.18 s | ||||
| 100 | 2.57 s | ||||
| 500 | 12.80 s | ||||
| 1000 | 25.9 s | ||||
| Problem-solving | 100 | 2.72 s | |||
| 500 | 28.46 s | ||||
| 1000 | 127.51 s | ||||
| 100 | 3.69 s | ||||
| 500 | 29.81 s | ||||
| 1000 | 130.17 s | ||||
| 100 | 2.62 s | ||||
| 500 | 5.70 s | ||||
| 1000 | 9.82 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.; Chae, J. Estimation of Travel Cost between Geographic Coordinates Using Artificial Neural Network: Potential Application in Vehicle Routing Problems. ISPRS Int. J. Geo-Inf. 2023, 12, 57. https://doi.org/10.3390/ijgi12020057
Lee K, Chae J. Estimation of Travel Cost between Geographic Coordinates Using Artificial Neural Network: Potential Application in Vehicle Routing Problems. ISPRS International Journal of Geo-Information. 2023; 12(2):57. https://doi.org/10.3390/ijgi12020057
Chicago/Turabian StyleLee, Keyju, and Junjae Chae. 2023. "Estimation of Travel Cost between Geographic Coordinates Using Artificial Neural Network: Potential Application in Vehicle Routing Problems" ISPRS International Journal of Geo-Information 12, no. 2: 57. https://doi.org/10.3390/ijgi12020057