
Crowd Density Estimation and Mapping Method Based on Surveillance Video and GIS
Abstract
:1. Introduction
2. Related Work
2.1. Crowd Density Estimation
2.2. Semantic Segmentation
2.3. Integration of Video and GIS
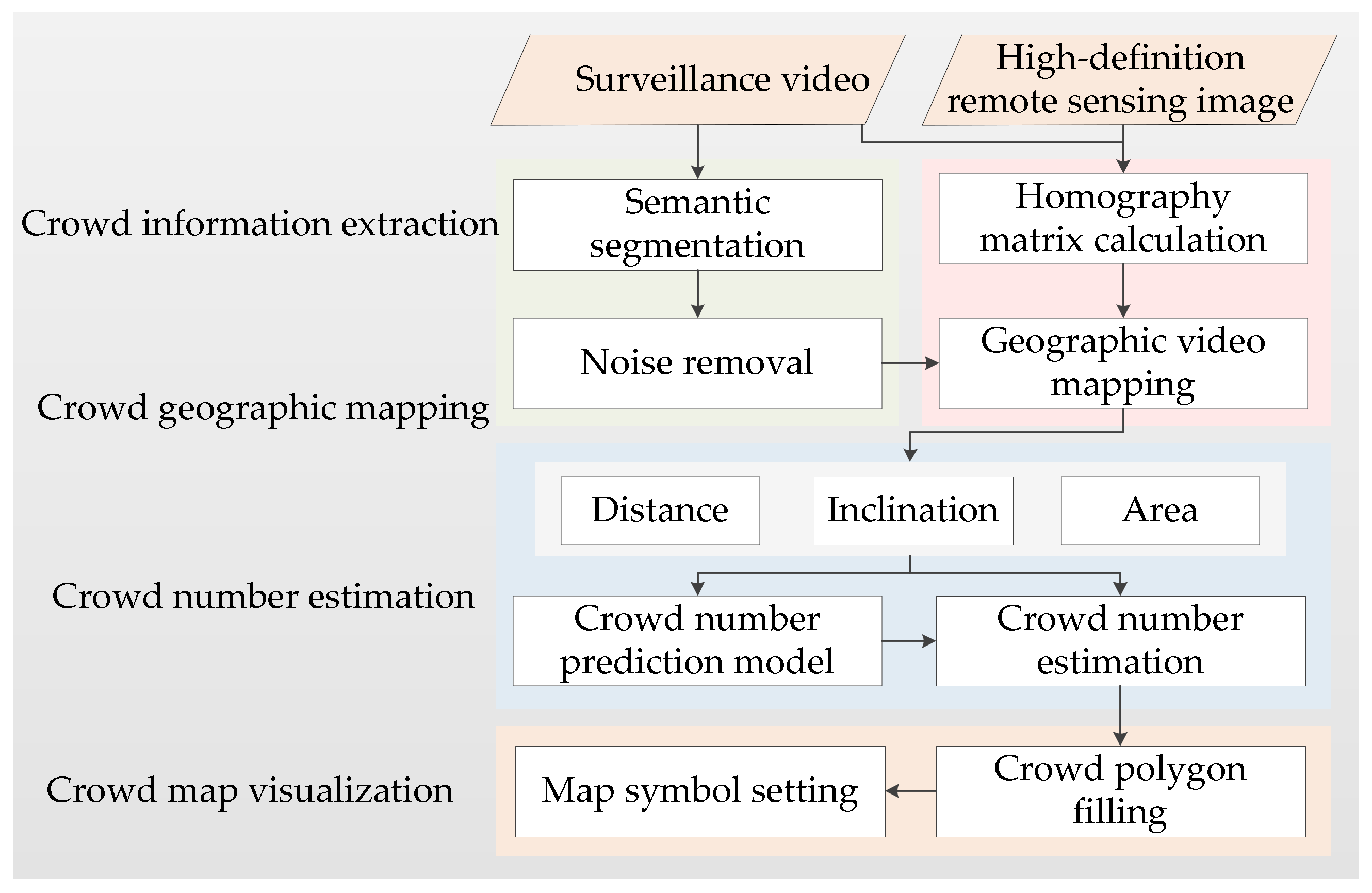
3. Methodology
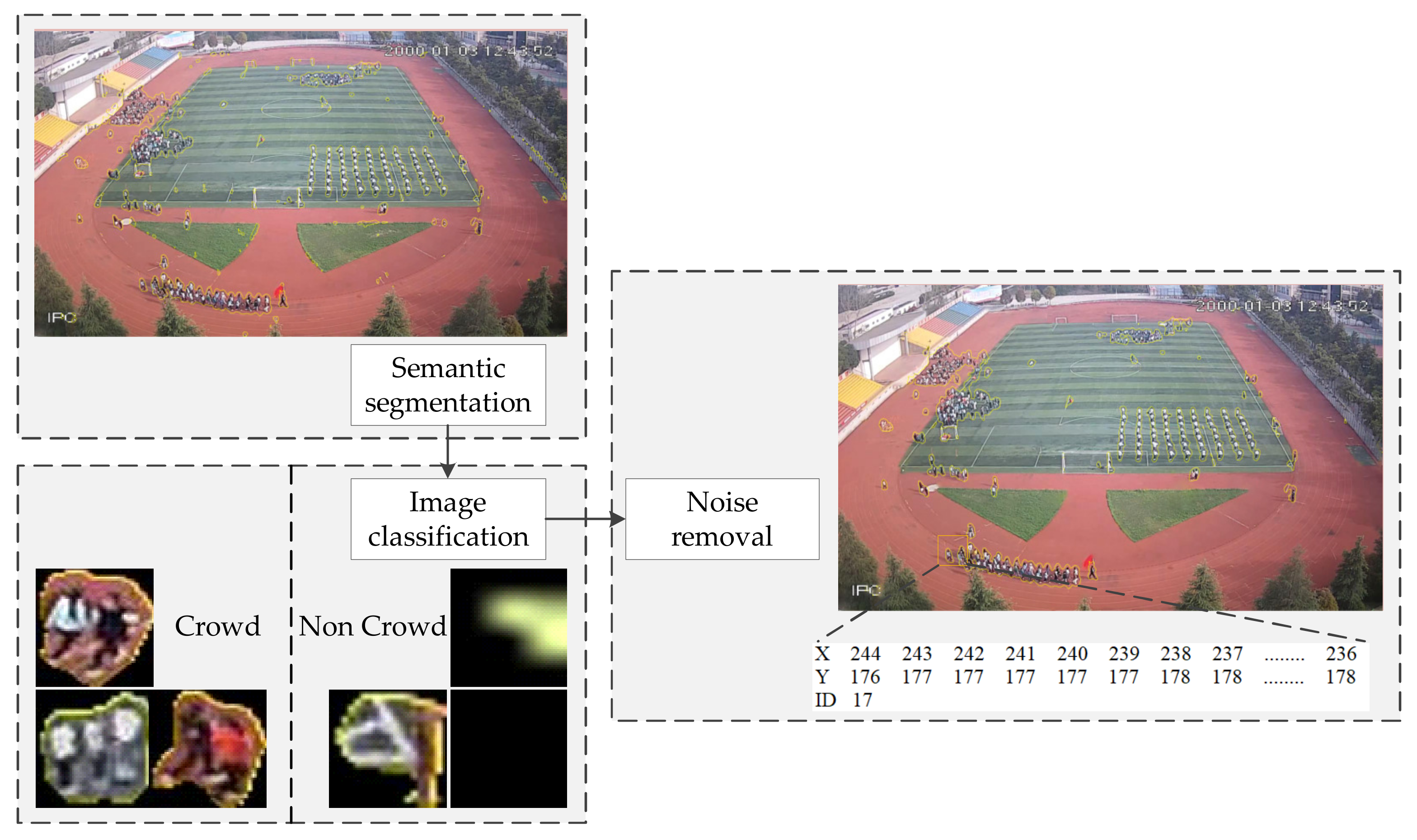
3.1. Crowd Information Extraction
3.1.1. Semantic Segmentation
3.1.2. Noise Removal
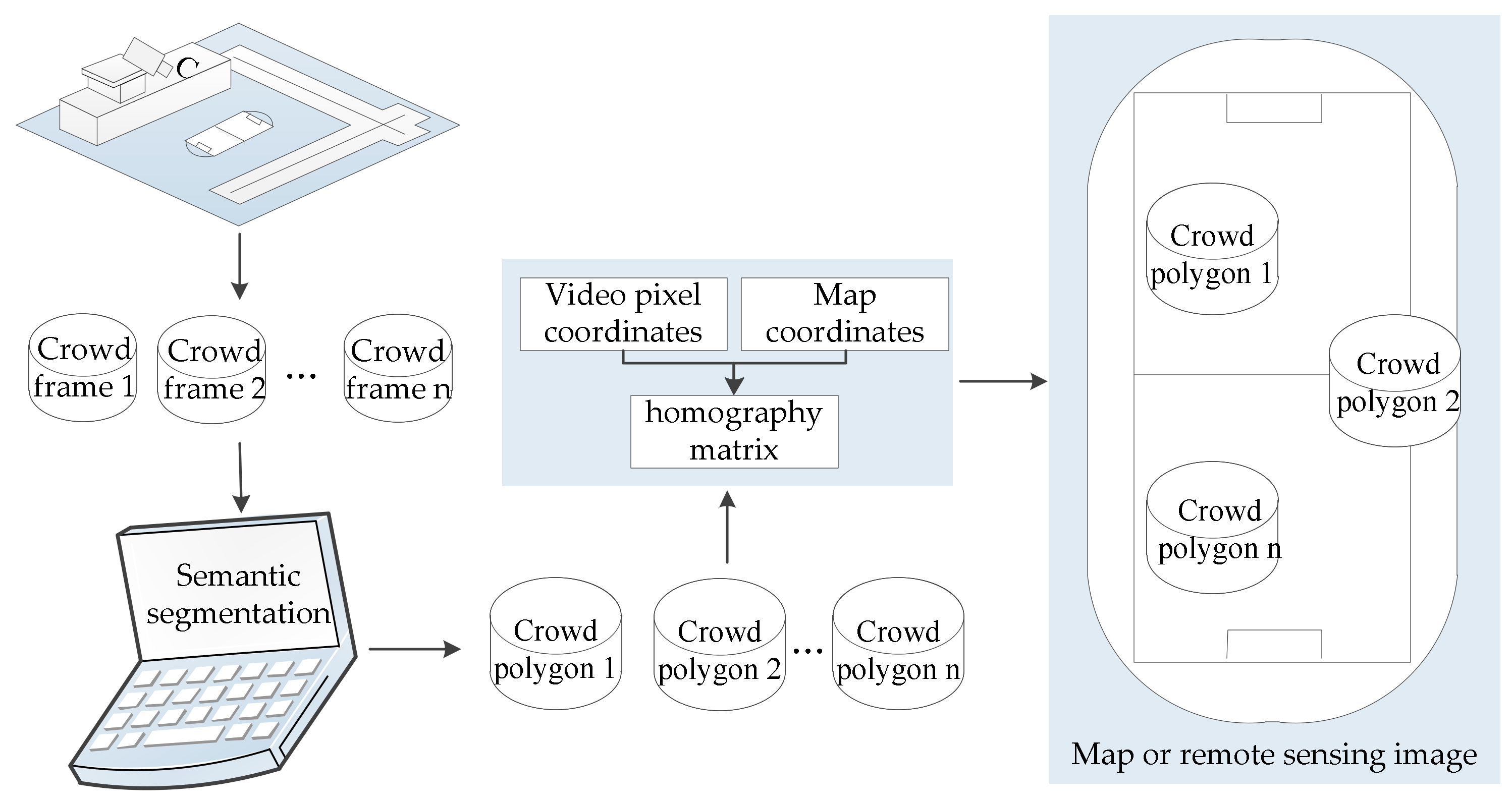
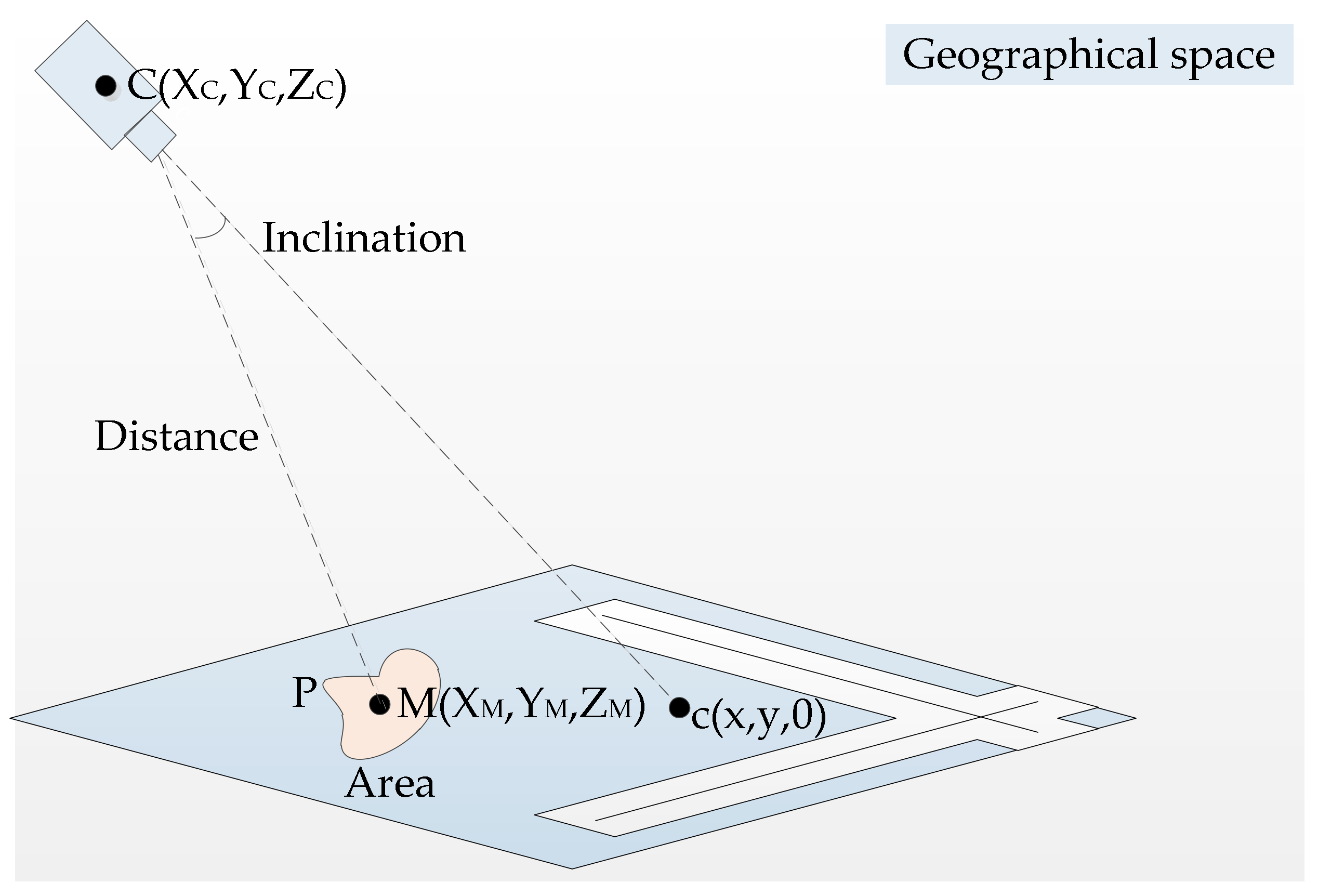
3.2. Crowd Geographic Mapping
3.2.1. Homography Matrix Calculation
3.2.2. Geographic Video Mapping
3.3. Crowd Number Estimation
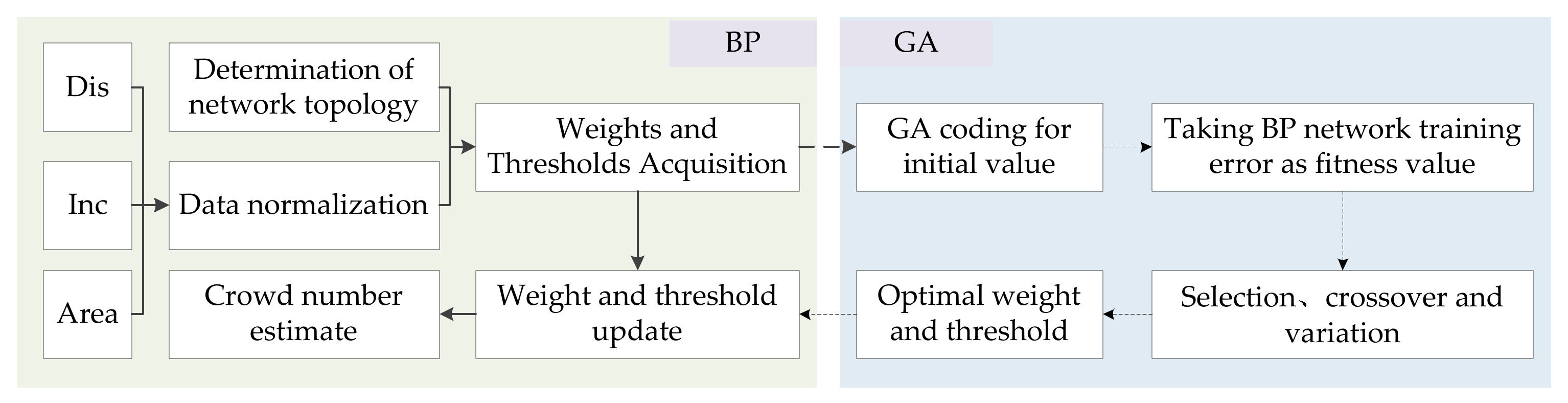
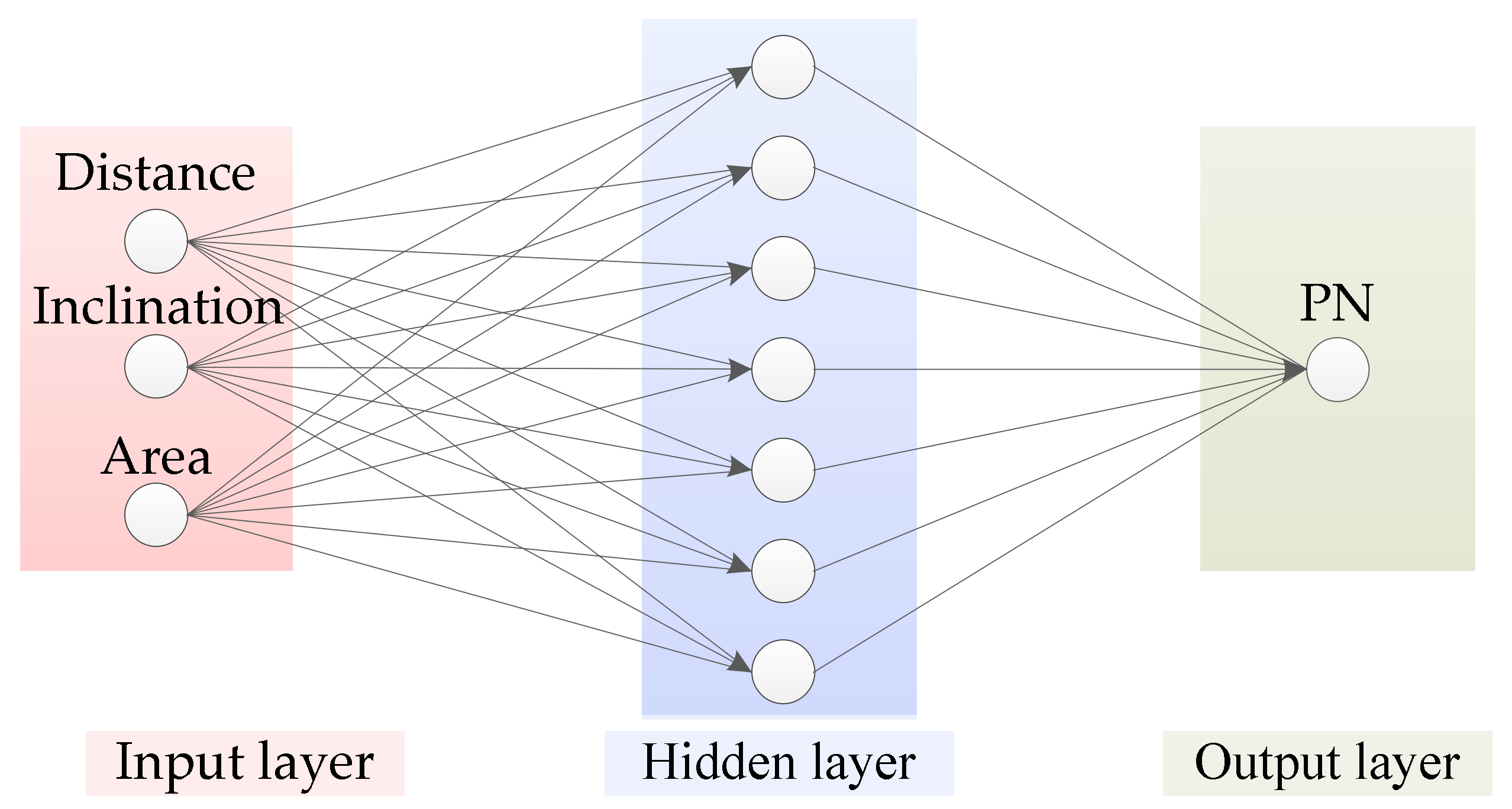
3.3.1. Crowd Number Prediction Model
3.3.2. Model Factor Calculation and Prediction
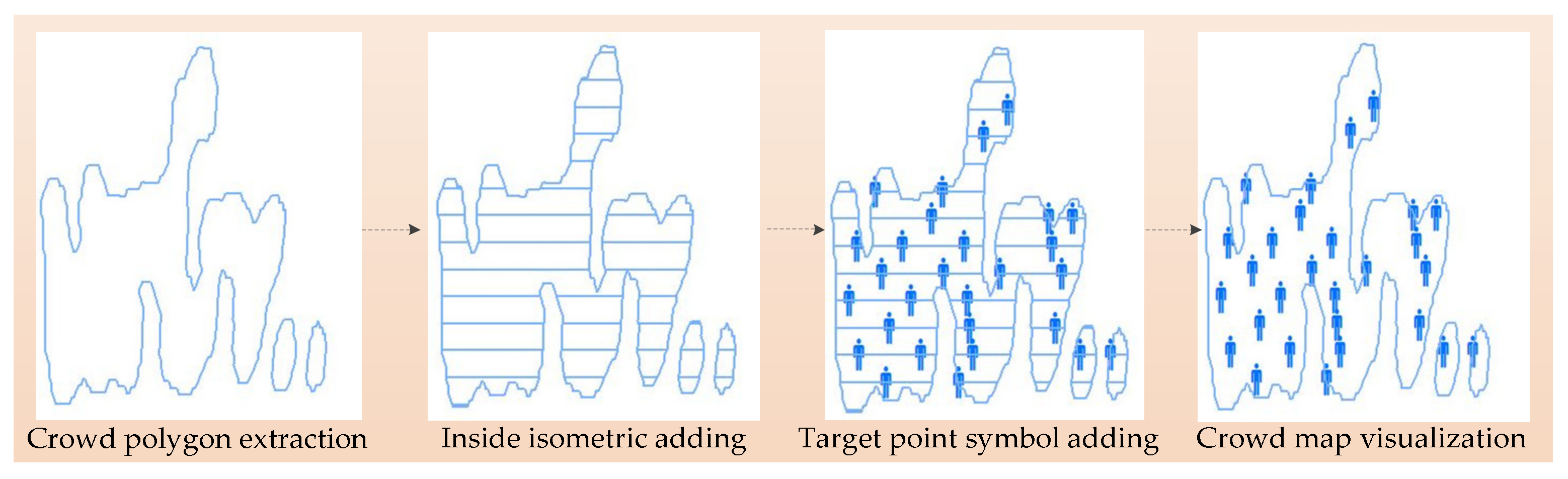
3.4. Crowd Map Visualization
4. Experiments and Results
4.1. Experimental Environment and Data
4.2. Experimental Analysis
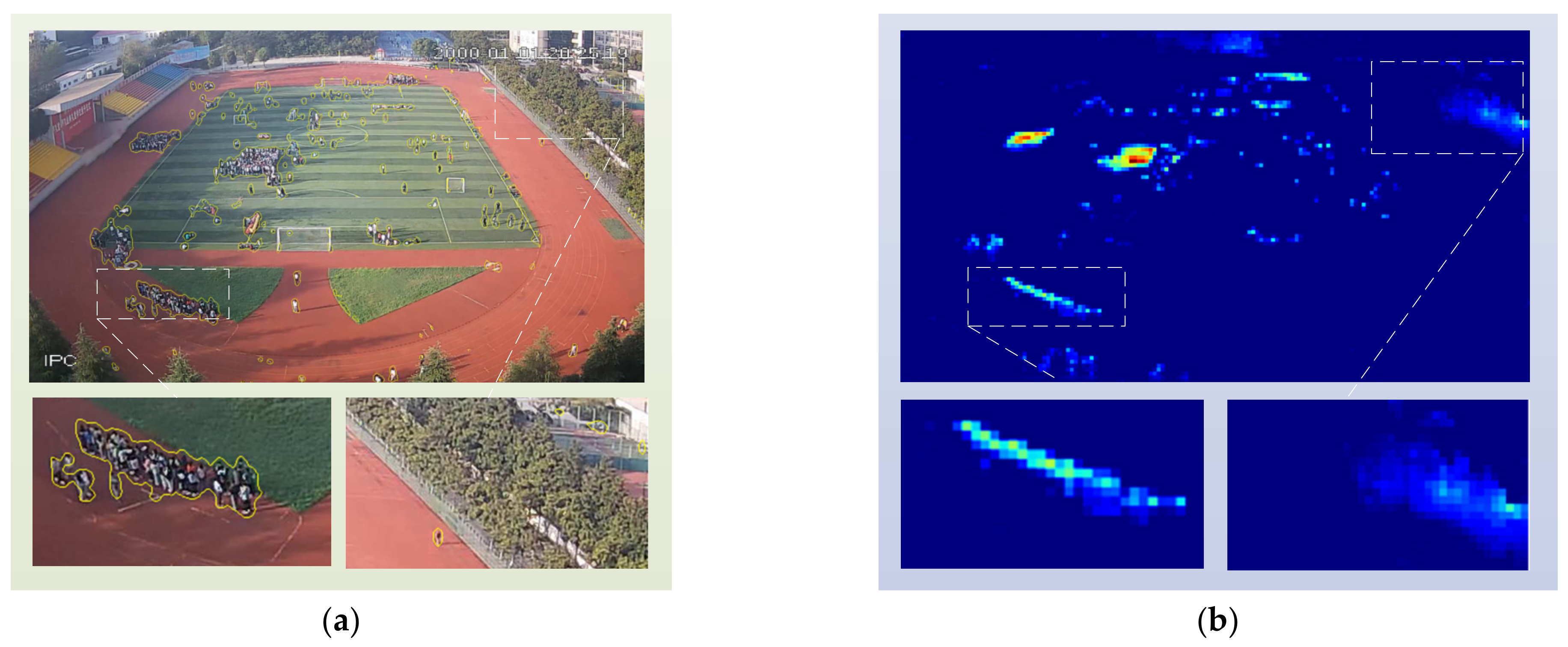
4.2.1. Crowd Extraction and Geographic Mapping
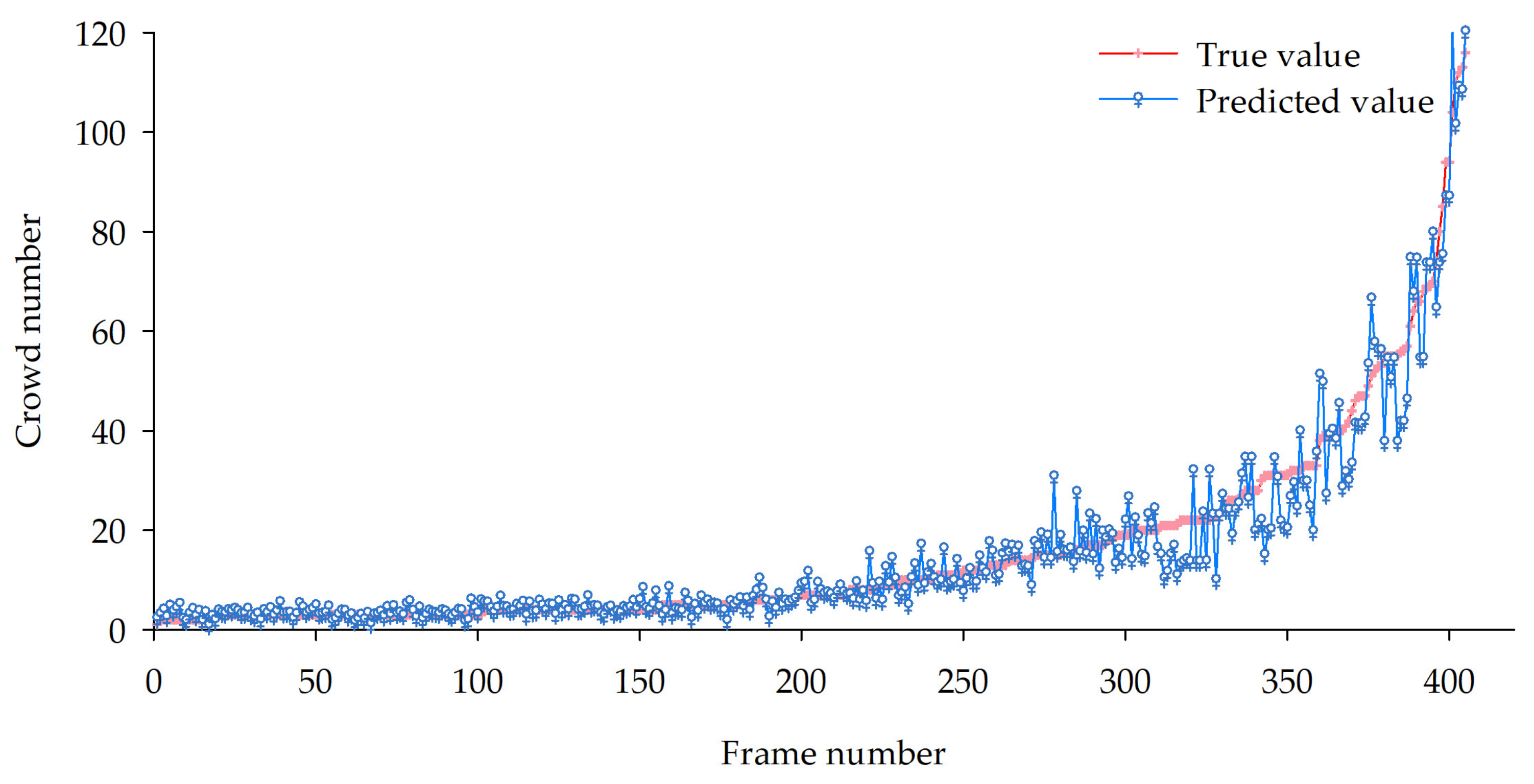
4.2.2. Crowd Number Estimation
4.2.3. Crowd Map Visualization
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Milosavljevic, A.; Dimitrijevic, A.; Rancic, D. GIS-augmented video surveillance. Int. J. Geogr. Inf. Sci. 2010, 24, 1415–1433. [Google Scholar] [CrossRef]
- Wang, T.; Qiao, M.N.; Deng, Y.J.; Zhou, Y.; Wang, H.; Lyu, Q.; Snoussi, H. Abnormal event detection based on analysis of movement information of video sequence. Optik 2018, 152, 50–60. [Google Scholar] [CrossRef]
- Xiong, Q.H.; Zhou, S.J.; Chen, Q.S. Abnormal driving behavior detection based on kernelization-sparse representation in video surveillance. Multimed. Tools Appl. 2022, 81, 4585–4601. [Google Scholar] [CrossRef]
- Hsueh, Y.L.; Lie, W.N.; Guo, G.Y. Human behavior recognition from multiview videos. Inf. Sci. 2020, 517, 275–296. [Google Scholar] [CrossRef]
- Zhang, Y.G.; Wang, J.; Yang, X. Real-time vehicle detection and tracking in video based on faster R-CNN. J. Phys. Conf. Ser. 2017, 887, 14–16. [Google Scholar] [CrossRef]
- Zhang, C.; Li, H.S.; Wang, X.; Yang, X.K. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 833–841. [Google Scholar] [CrossRef]
- Sengar, S.S.; Mukhopadhyay, S. Moving object detection based on frame difference and W4. SIViP 2017, 11, 1357–1364. [Google Scholar] [CrossRef]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source multi-scale counting in extremely dense crowd images. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2547–2554. [Google Scholar] [CrossRef]
- Chan, A.B.; Vasconcelos, N. Bayesian Poisson regression for crowd counting. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 545–551. [Google Scholar] [CrossRef]
- Paragios, N.; Ramesh, V. A MRF-based approach for real-time subway monitoring. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001. [Google Scholar] [CrossRef]
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar] [CrossRef]
- McDonald, G.C. Ridge regression. WIREs Comp. Stats. 2009, 1, 93–100. [Google Scholar] [CrossRef]
- Zhang, W.H.; Liu, C. Research on human abnormal behavior detection based on deep learning. In Proceedings of the 2020 International Conference on Virtual Reality and Intelligent Systems (ICVRIS), Zhangjiajie, China, 18–19 July 2020; pp. 973–978. [Google Scholar] [CrossRef]
- Bai, H.Y.; Mao, J.G.; Chan, S.-H.G. A survey on deep learning-based single image crowd counting: Network design, loss function and supervisory signal. Neurocomputing 2022, 508, 1–18. [Google Scholar] [CrossRef]
- Zhao, Y.C.; Chen, B. WiCount: A deep learning approach for crowd counting using WiFi signals. In Proceedings of the 2017 IEEE International Symposium on Parallel and Distributed Processing with Applications and 2017 IEEE International Conference on Ubiquitous Computing and Communications (ISPA/IUCC), Guangzhou, China, 12–15 December 2017; pp. 967–974. [Google Scholar] [CrossRef]
- Liu, Y.B.; Jia, R.S.; Liu, Q.M.; Zhang, X.L.; Sun, H.M. Crowd counting method based on the self-attention residual network. Appl. Intell. 2021, 51, 427–440. [Google Scholar] [CrossRef]
- Pissinou, N.; Radev, I.; Makki, K. Spatio-temporal modeling in video and multimedia geographic information systems. GeoInformatica 2001, 5, 375–409. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Lin, S.F.; Chen, J.Y.; Chao, H.X. Estimation of number of people in crowded scenes using perspective transformation. IEEE Trans. Syst. Man Cybern. A Syst. Humans 2001, 31, 645–654. [Google Scholar] [CrossRef]
- Wu, B.; Nevatia, R. Detection and tracking of multiple, partially occluded humans by bayesian combination of edgelet based part detectors. Int. J. Comput. Vis. 2007, 75, 247–266. [Google Scholar] [CrossRef]
- Cho, S.Y.; Chow, T.W.S.; Leung, C.T. A neural-based crowd estimation by hybrid global learning algorithm. IEEE Trans. Syst. Man Cybern. B Cybern. 1999, 29, 535–541. [Google Scholar] [CrossRef]
- Wang, Y.; Zou, Y. Fast visual object counting via example-based density estimation. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3653–3657. [Google Scholar] [CrossRef]
- Pham, V.Q.; Kozakaya, T.; Yamaguchi, O.; Okada, R. Count Forest: Co-voting uncertain number of targets using random forest for crowd density estimation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3253–3261. [Google Scholar] [CrossRef]
- Saleh, S.A.M.; Suandi, S.A.; Ibrahim, H. Recent survey on crowd density estimation and counting for visual surveillance. Eng. Appl. Artif. Intell. 2015, 41, 103–114. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.Y.; Lin, W.; Yuan, Y. Learning from synthetic data for crowd counting in the wild. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8198–8207. [Google Scholar] [CrossRef]
- Yu, C.Y.; Xu, Y.; Gou, L.S.; Nan, Z.F. Crowd counting based on single-column deep spatiotemporal convolutional neural network. Laser Optoelectron. Prog. 2021, 58, 143–151. [Google Scholar] [CrossRef]
- Boominathan, L.; Kruthiventi, S.S.S.; Babu, R.V. CrowdNet: A deep convolutional network for dense crowd counting. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 640–644. [Google Scholar] [CrossRef]
- Zhang, Y.Y.; Zhou, D.S.; Chen, S.Q.; Gao, S.H.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Patel, V.M. Generating high-quality crowd density maps using contextual pyramid CNNs. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1879–1888. [Google Scholar] [CrossRef]
- Cao, X.K.; Wang, Z.P.; Zhao, Y.Y.; Su, F. Scale aggregation network for accurate and efficient crowd counting. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar] [CrossRef]
- Li, Y.H.; Zhang, X.F.; Chen, D.M. CSRnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar] [CrossRef]
- Zhang, L.; Shi, M.J.; Chen, Q.B. Crowd counting via Scale-Adaptive Convolutional Neural Network. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1113–1121. [Google Scholar] [CrossRef]
- Yu, H.S.; Yang, Z.G.; Tan, L.; Wang, Y.N.; Sun, W.; Sun, M.G.; Tang, Y.D. Methods and datasets on semantic segmentation: A review. Neurocomputing 2018, 304, 82–103. [Google Scholar] [CrossRef]
- Csurka, G.; Perronnin, F. An efficient approach to semantic segmentation. Int. J. Comput. Vis. 2011, 95, 198–212. [Google Scholar] [CrossRef]
- Guo, Y.M.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Zhao, H.S.; Shi, J.P.; Qi, X.J.; Wang, X.G.; Jia, J.Y. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for scene segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.K.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar] [CrossRef]
- Sultani, W.; Chen, C.; Shah, M. Real-World anomaly detection in surveillance videos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar] [CrossRef]
- Day, Y.F.; Dagtas, S.; Iino, M.; Khokhar, A.; Ghafoor, A. Spatio-temporal modeling of video data for on-line object-oriented query processing. In Proceedings of the International Conference on Multimedia Computing and Systems, Washington, DC, USA, 15–18 May 1995; pp. 98–105. [Google Scholar] [CrossRef]
- Wu, C.; Zhu, Q.; Zhang, Y.T.; Du, Z.Q.; Zhou, Y.; Xie, X.; He, F. An adaptive organization method of GeoVideo data for spatio-temporal association analysis. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2015, 2, 29. [Google Scholar] [CrossRef]
- Lewis, P.; Fotheringham, S.; Winstanley, A. Spatial video and GIS. Int. J. Geogr. Inf. Sci. 2011, 25, 697–716. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. Computer Vision and Pattern Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Smeulders, A.W.M.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1442–1468. [Google Scholar] [CrossRef] [Green Version]
- Ross, D.A.; Lim, J.; Lin, R.S.; Yang, M.H. Incremental learning for robust visual tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar] [CrossRef]
- Lawin, F.J.; Danelljan, M.; Tosteberg, P.; Bhat, G.; Khan, F.S.; Felsberg, M. Deep projective 3D semantic segmentation. In Proceedings of the Computer Analysis of Images and Patterns, Ystad, Sweden, 22–24 August 2017; pp. 95–107. [Google Scholar] [CrossRef]
- Hamin, S.; Kichun, J.; Jieun, C.; Youngrok, S.; Chansoo, K.; Kwangjin, H. A training dataset for semantic segmentation of urban point cloud map for intelligent vehicles. ISPRS J. Photogramm. Remote Sens. 2022, 187, 159–170. [Google Scholar] [CrossRef]
- Leow, W.K.; Chiang, C.C.; Hung, Y.P. Localization and mapping of surveillance cameras in city map. In Proceedings of the 16th International Conference on Multimedia 2008, Vancouver, BC, Canada, 26–31 October 2008; pp. 369–378. [Google Scholar] [CrossRef]
- Joo, I.H.; Hwang, T.H.; Choi, K.H. Generation of video metadata supporting video-GIS integration. ICIP 2004, 3, 1695–1698. [Google Scholar]
- Zhang, X.G.; Shi, X.Y.; Luo, X.Y.; Sun, Y.P.; Zhou, Y.D. Real-Time web map construction based on multiple cameras and GIS. ISPRS Int. J. Geo-Inf. 2021, 10, 803. [Google Scholar] [CrossRef]
- Hsu, S.; Samarasekera, S.; Kumar, R.; Sawhney, H.S. Pose estimation, model refinement, and enhanced visualization using video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head, SC, USA, 15 June 2000; pp. 488–495. [Google Scholar] [CrossRef]
- Xie, Y.J.; Wang, M.Z.; Liu, X.J.; Wu, Y.G. Intergration of GIS and moving objects in surveillance video. ISPRS Int. J. Geo-Inf. 2017, 6, 94. [Google Scholar] [CrossRef]
- Dai, H.H.; Hu, B.; Cui, Q.; Zou, Z.Q. VideoGIS data retrieval based on multi-feature fusion. In Proceedings of the 2017 12th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Nanjing, China, 24–26 November 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Chrysler, A.; Gunarso, R.; Puteri, T.; Warnars, H.L.H.S. A literature review of crowd-counting system on convolutional neural network. IOP Conf. Ser. Earth Environ. Sci. 2021, 729, 012029. [Google Scholar] [CrossRef]
- Li, B.; Huang, H.B.; Zhang, A.; Liu, P.W.; Liu, C. Approaches on crowd counting and density estimation: A review. Pattern Anal. Applic. 2021, 24, 853–874. [Google Scholar] [CrossRef]
- Ma, H.; Arslan Ay, S.; Zimmermann, R.; Kim, S.H. Large-scale geo-tagged video indexing and queries. Geoinformatica 2014, 18, 671–697. [Google Scholar] [CrossRef]
- Fu, H.; Fu, B.H.; Shi, P.H. An improved segmentation method for automatic mapping of cone karst from remote sensing data based on DeepLabV3+ model. Remote Sens. 2021, 13, 441. [Google Scholar] [CrossRef]
- Hassanzadeh, T.; Essam, D.; Sarker, R. EvoDCNN: An evolutionary deep convolutional neural network for image classification. Neurocomputing 2022, 488, 271–283. [Google Scholar] [CrossRef]
- Sankaranarayanan, K.; Davis, J.W. A fast linear registration framework for multi-camera GIS coordination. In Proceedings of the 2008 IEEE Fifth International Conference on Advanced Video and Signal Based Surveillance, Santa Fe, NM, USA, 1–3 September 2008; pp. 245–251. [Google Scholar] [CrossRef]
- Collins, R.T.; Lipton, A.J.; Fujiyoshi, H.; Kanade, T. Algorithms for cooperative multi-sensor surveillance. Proc. IEEE Inst. Electr. Electron. Eng. 2001, 89, 1456–1477. [Google Scholar] [CrossRef]
- Yue, C.W.; Li, N.T.; Hai, L.W. Inflation forecast based on BP neural network model. Adv. Mater. Res. 2014, 3326, 5536–5539. [Google Scholar] [CrossRef]
- Qiu, W.D.; Wen, G.J.; Liu, H.J. A Back-Propagation neural network model based on genetic algorithm for prediction of build-up rate in drilling process. Arab. J. Sci. Eng. 2022, 47, 11089–11099. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.Y.; Lin, W.; Li, X.L. NWPU-Crowd: A largescale benchmark for crowd counting and localization. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2141–2149. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | MAE | RMSE |
|---|---|---|
| SFCN+ | 126.9 | 128.6 |
| CDEM-M | 37.0 | 43.5 |
| Frame | SFCN+ | CDEM-M |
|---|---|---|
 True value: 505 |  Predicted value: 312 |  Predicted value: 537 |
 True value: 348 |  Predicted value: 242 |  Predicted value: 324 |
 True value: 685 |  Predicted value: 362 |  Predicted value: 716 |
 True value: 130 |  Predicted value: 57 |  Predicted value: 157 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Sun, Y.; Li, Q.; Li, X.; Shi, X. Crowd Density Estimation and Mapping Method Based on Surveillance Video and GIS. ISPRS Int. J. Geo-Inf. 2023, 12, 56. https://doi.org/10.3390/ijgi12020056
Zhang X, Sun Y, Li Q, Li X, Shi X. Crowd Density Estimation and Mapping Method Based on Surveillance Video and GIS. ISPRS International Journal of Geo-Information. 2023; 12(2):56. https://doi.org/10.3390/ijgi12020056
Chicago/Turabian StyleZhang, Xingguo, Yinping Sun, Qize Li, Xiaodi Li, and Xinyu Shi. 2023. "Crowd Density Estimation and Mapping Method Based on Surveillance Video and GIS" ISPRS International Journal of Geo-Information 12, no. 2: 56. https://doi.org/10.3390/ijgi12020056