




Explanatory Factors of Daily Mobility Patterns in Suburban Areas: Applications and Taxonomy of Two Metropolitan Corridors in Madrid Region

Abstract
:1. Introduction
- Firstly, an extensive literature review of previous studies is firstly carried out to identify the characteristics that may have an influence on urban mobility. Then, a set of agreed indicators to measure these characteristics is proposed;
- Secondly, correlation analyses are performed between the indicators and in the context of suburban zones in Madrid. These analyses serve to examine the relations between urban transport patterns and other conditions such as socioeconomic characteristics or urban form;
- Finally, a cluster analysis is applied, using geolocated data compiled in the set of indicators. Through this exploratory technique, a taxonomy is created to classify the types of zones we may find in the suburbs of big cities, which are different in terms of geographical location and urban and social conditions.
2. Materials and Methods
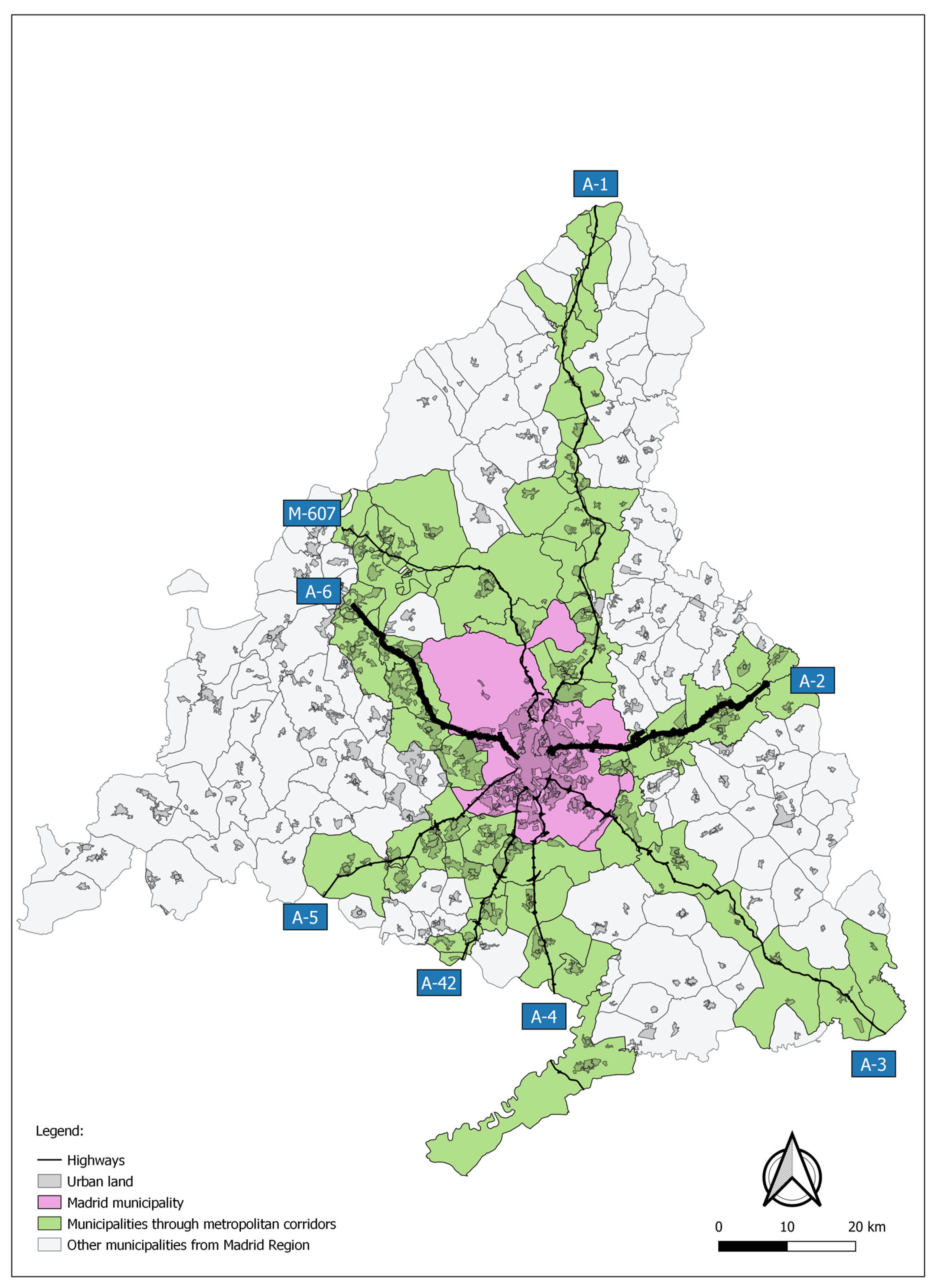
2.1. Case Study: Two Metropolitan Corridors in Madrid
2.2. Indicators to Characterize Urban Mobility in the Case Study
2.2.1. Literature Review: Concepts and Variables Surrounding Urban Mobility
- (a) Handy [28] carries out a review of different approaches trying to understand the relation between urban form and travel behavior. She remarks on the importance of providing alternatives to using a car through urban design, especially in new developments. Walking is promoted if residential areas are provided with facilities such as shops, schools, or health centers. Public transport may be an option if there is a competitive offer of services. In this regard, it is especially relevant to consider the connections by train;
- (b) Kockelman [29] also focuses on the influence of variables related to urban form on residential mobility. She analyzes the case of the San Francisco Bay Area, finding that a balanced land use mix and accessibility levels could be more relevant than other variables usually used to predict travel behavior. Nevertheless, demographic and socioeconomic variables should never be neglected;
- (c) Giuliano and Narayan [30] explore the relationship between land-use characteristics and individual mobility. They make a comparison between the US and Great Britain using travel diary data. According to this research, differences in daily trips and miles traveled are mainly explained by household income and urban density;
- (d) Zang [31] uses data from a travel survey in Boston to analyze how spatial accessibility may explain non-work travel choices. Apart from accessibility, many other explanatory variables are included in this research (see Table 2). Special importance is attached to household characteristics such as size, composition, and proximity to facilities such as schools or leisure areas;
- (e) Giuliano and Dargay [32] extend the study carried out in [c]. Results show that apart from income and density, other variables related to demography, population size, or car ownership and costs are also explanatory factors for urban mobility;
- (f) The analysis presented by Limtanakool et al. [33] shows how socioeconomic factors, land use characteristics, and travel time affect mode choice. The authors employ data from the 1998 Netherlands National Travel Survey in the analysis, and also emphasize the importance of trip purposes when choosing the transport mode;
- (g) Kang et al. [34] investigate how mobility patterns are affected by compactness and urban size. This research is quite different from previous ones. On the one hand, the authors only consider two variables, carrying out a very thorough analysis of both. On the other hand, mobility phone data instead of household survey data are used to characterize travel patterns. The study includes eight cities in Northeast China;
- (h) Klinger and Lanzendorf [35] apply regression models to analyze the determinants of modal choices in the context of three German cities. They focus on the variables related to urban form, socioeconomics, and transport infrastructure and offer. Data are extracted from a survey specifically conducted for the research;
- (i) Bel and Rosell [36] use a household travel survey to analyze the factors influencing the greenhouse gas emissions of individuals on their daily trips. The variables analyzed are mainly related to personal characteristics (e.g., occupation, age, gender, educational level, or income). The case study is the metropolitan area of Barcelona, and the mapped results show the importance of the geographical situation in relation to the city center;
- (j) Marcinczak and Bartosiewicz [37] determine the relations between commuting patterns and urban form in Poland. This study focuses on the effect of spatial structure on daily trips made for work. Conclusions are critical with the trends towards suburbanization, but the analysis only considers jobs’ locations;
- (k) Reul et al. [38] quantify the effects of potential influencing factors on urban transportation in the future through an innovative approach. The results are based on an activity-based transport demand model, developed for a synthetic city. The authors analyze different scenarios to investigate urban transportation against the backdrop of mode availability, urban structure, or an aging population;
- (l) Cerin et al. [39] focus on a cross-cutting topic, which is becoming increasingly significant: synergies between transport and health. They analyze how local urban design features may encourage walking. To that end, data from specific surveys carried out in 14 cities around the world are combined with objective measures of the built environment. The results, presented at the neighborhood level, show that the main factors predicting walking share are: the density, the number of intersections and the public transport connectivity.
- Concerning the variables, some of them are more focused on urban form or land use attributes (e.g., (a) [28], (g) [34], and (l) [39]). Others are more focused on socioeconomic and personal characteristics (e.g., (i) [36]). Additionally, there are more broad studies trying to include a range of socioeconomic and land use variables (e.g., (d) [31] and (e) [32]).
- As for the formal contexts, there is a wide variation. There are approaches that analyze only one city or metropolitan area (e.g., (b) [29], (d) [31], and (i) [36]), while others include in their analysis various cities or adopt a national or even international approach (e.g., (c) [30], (e) [32], (f) [33], (h) [35], and (j) [37]). In reference to the case studies, the most innovative approach is based on the analysis of a synthetic city through an activity-based transport model (k) [38].
2.2.2. Data Availability and Indicators
- (A) Household Mobility Survey (HMS) for the Madrid Region [48]. This is the most important source of information that has served to structure and organize by zones all the data gathered. It provides transport variables such as modal share;
- (B) Open Data from Madrid Transport Authority [49]. This database contains information regarding Public Transport (PT) offer and infrastructure. The data are provided in Geographical Information Systems format. The information is provided for each PT stop and line; therefore, the data must be aggregated to obtain the indicators per transport zone;
- (C) Geographic Information from the Spanish Ministry of Transport and Urban Agenda [50]. The information available here is very wide and diverse and covers the national territory. Of special interest in this case is the information on soil classification, urbanized surface, and population. Data are presented as homogeneous areas considering their land use characteristics. Therefore, some transformations—generally aggregations—are needed to obtain the indicators for different territorial divisions;
- (D) Territorial Information System from the Statistic Institute in Madrid Region [51]. It includes cartography and a street map with detailed information for each street. This data source is very useful to calculate distances, or to obtain information on activities and the supply of services existing in different zones of the Region. However, it is necessary to simplify the figures to calculate the indicators per transport zone. For example, the number of activities is provided per street and must be aggregated. While the estimation of distances to the city center is based on the centroids of the zones;
- (E) Spanish Statistical Institute [52]. Statistics on population, demography, and socioeconomic characteristics of residents per zone can be found in this data source. Some figures in this source are obtained at the municipal level, and therefore certain disaggregation is needed to obtain the indicators.
2.3. Correlation Analysis for Explaining Urban Mobility
- xi = values of the x-variable in a sample.
- = mean of the values of the x-variable.
- yi = values of the y-variable in a sample.
- = mean of the values of the y-variable.
2.4. Cluster Analysis to Classify Transport Zones According to Mobility Patterns
- Normalize selected indicators using Z-scores formulation;
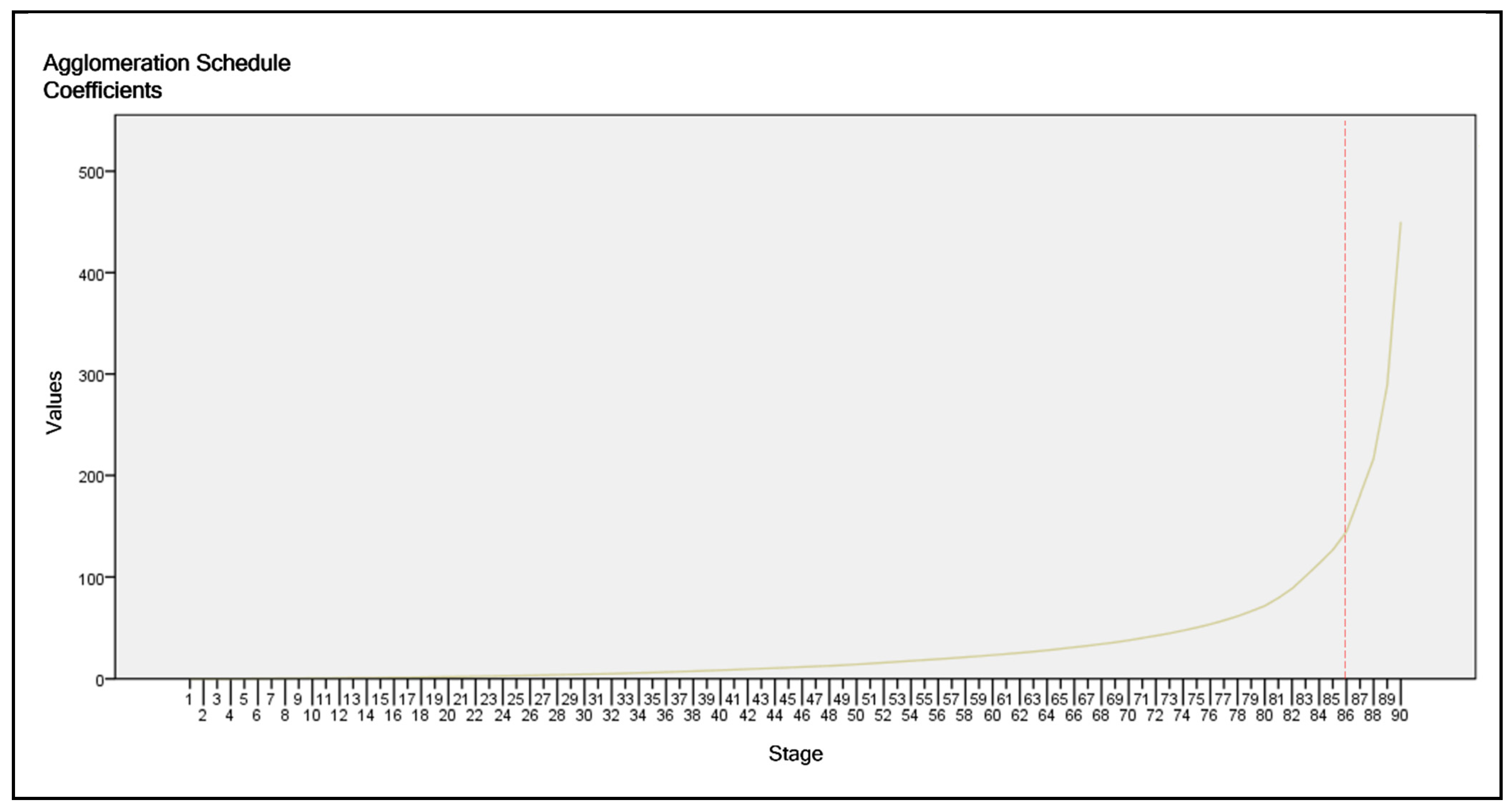
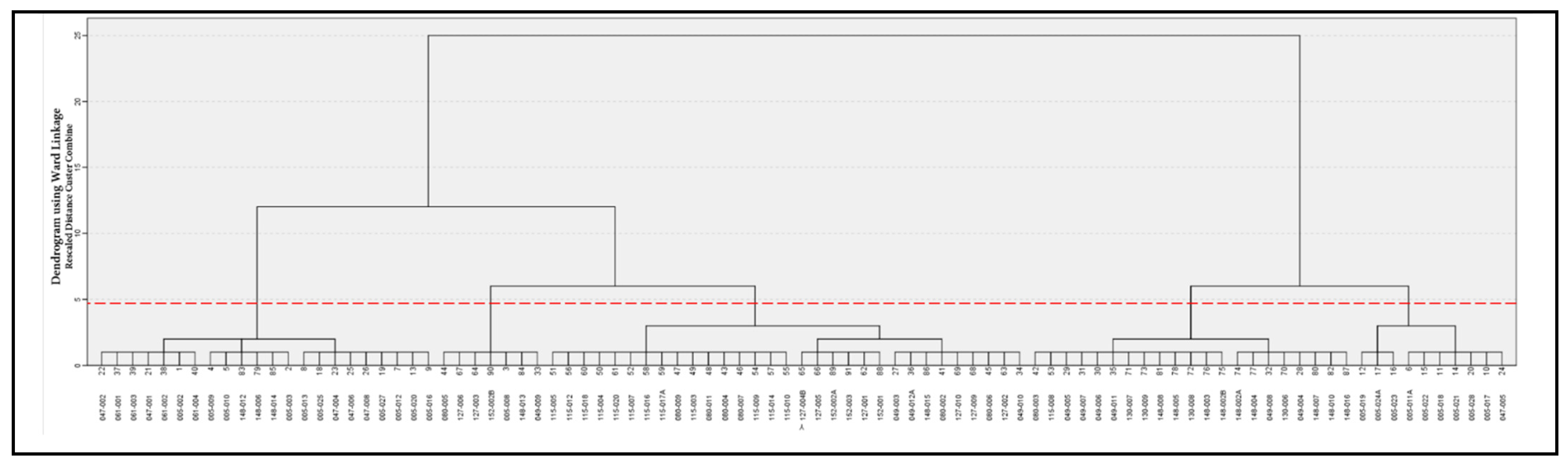
- Set the appropriate number of clusters through a hierarchical method: the Ward method with squared Euclidean distance measurement. The number of clusters is set according to the agglomeration schedule and the dendrogram;
- Use the non-hierarchical method k-means to test the stability of the resulting clusters. The number of clusters is defined in stage 2 and the iterations are started from centroids obtained with the Ward method;
- Test the validity of the obtained solution. On the one hand, by comparing the solutions obtained by the two cluster methods used; on the other hand, through the ANOVA analysis, which shows if the classification variables selected contribute to the cluster classification.
3. Results
3.1. Explanatory Variables for Urban Mobility Patterns
- Regarding the demographic distribution, the existence of children and elders are both relevant variables shaping mobility in contrary directions. In those zones with a higher percentage of the population over 65, the transport patterns are more sustainable. The use and availability of cars are substantially lower, the walking share is higher, and the trips are shorter. The rate of children has a stronger and opposite effect, especially on the car share and walking share. Those zones with a higher percentage of the population under 14 are very car-dependent and are characterized by few walking trips. As for the working-age population or women rates, no significant relations can be demonstrated with transport variables, at least at the zone level.
- Concerning the socioeconomic concept, results attach great importance to income levels as explanatory variables. In this suburban context, wealthier families live in zones where the car share is particularly higher, while the walking share is particularly lower (absolute coefficient values > 0.7). These high-income zones are also characterized by car availability and long distances traveled. The positive correlation between income and the public transport share may be surprising. This is because the wealthiest zones are located not very far from the city center and have good quality radial connections by public transport (e.g., many zones in the A-6 corridor are connected with Madrid City by a Bus–HOV lane).
- Density and diversity play the most important role in shaping mobility. The number of inhabitants per urban surface is the variable with the biggest influence on transport variables. Correlation coefficients demonstrate that in low-density settlements, the motorization rate and especially the use of cars is higher. By contrast, people living in more compact urban areas make shorter trips and walk more. As for diversity, those areas with a broader offer of activities and services show more sustainable travel patterns: less dependence on cars, more trips on foot, and shorter distances. The public transport share is the only transport variable that is not well explained by any of these density or diversity-related variables.
- Regarding the accessibility to public transport, those urban areas close to a train station (800 m buffer) present higher PT use. However, the effect is moderate. As for the number of PT stops, it has a very high effect on car share but the effect on PT use is not significant. In this metropolitan context, the public transport share is found to be an indicator with little variation (ranging from 10 to 20%) compared to the car (from 30 to 70%) or walking shares (from 20 to 60%). This makes it difficult to find strong correlations with the rest of the variables.
- Finally, the distance to the city—the center of the Madrid Municipality—is a very interesting explanatory factor. It is the variable with the highest impact on the public transport share, even if the effect is not very strong (Pearson coefficient < 0.5). As would be expected, people living closer to the city center make more trips by public transport. However, living far from the city center does not necessarily imply having less sustainable transport patterns. In fact, distant zones present higher walking shares and lower motorization rates. Precisely due to the distance, many of these zones work as isolated areas, being self-sufficient for many functions.
3.2. Transport Zones Classification
- Cluster 1: Self-sufficient dense zones, with an aging population and far from the city center. This cluster is composed of the zones with the highest urban density (268 Inhab./ha). Most of them are historical centers, with few children (12% on average) and many elders (22%). These zones are functional urban centers far away from Madrid city (30 km) and well provided for by services and activities, which are viable thanks to the urban density. They present the highest walking shares (57% of the trips on foot) and the lowest use of cars.
- Cluster 2: Middle-class dense zones in the East, closer to the city center. These zones are also very dense and well provided for. They are in the A-2 corridor, relatively close to the Madrid city center (16 km on average). The income is higher than zones in Cluster 1 but low compared to other zones in this sample, especially those located in the A-6 corridor. Nearly half of the trips are made on foot. Due to their high walking shares and their proximity to Madrid, people living in those zones make the shortest trips in this sample (4 km).
- Cluster 3: Middle-class zones with low density and far from the city center. The zones in this cluster are very far from Madrid city (30 km). Despite the distance, they do not work as self-sufficient centers due to their lack of activities and services and their lower density compared to equally distant zones in Cluster 1 (55 Inhab./ha). More than half of their trips are made by car.
- Cluster 4: Zones with upper-class families with children that are very car-dependent. Zones characterized by a young population, showing the highest percentage of children (24%). Families living in these areas are wealthy and very car-dependent (0.74 cars per inhabitant and 67% of trips by car). Few activities are offered in these areas and residents have the longest trips (11 km on average).
- Cluster 5: Wealthiest zones with very low density and few local activities. This cluster is composed of the most dispersed zones (34 Inhab./ha). Households with the highest incomes live in these zones (77,664 € per year), which are located mainly in the A-6 corridor. Most trips are made by car (67%), and very few on foot. As for public transport use, it is high compared to the rest of the clusters (18% of the trips). This is probably due to the proximity to Madrid city and the relatively good connections by PT with the city center.
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Cluster Combined | Coefficients | Stage | Cluster Combined | Coefficients | ||
|---|---|---|---|---|---|---|---|
| Cluster 1 | Cluster 2 | Cluster 1 | Cluster 2 | ||||
| 1 | 22 | 37 | 0.020 | 46 | 19 | 23 | 110.624 |
| 2 | 14 | 20 | 0.057 | 47 | 27 | 86 | 120.179 |
| 3 | 51 | 56 | 0.106 | 48 | 28 | 32 | 120.777 |
| 4 | 22 | 39 | 0.171 | 49 | 42 | 53 | 130.473 |
| 5 | 89 | 91 | 0.237 | 50 | 41 | 45 | 140.220 |
| 6 | 54 | 57 | 0.311 | 51 | 29 | 30 | 150.028 |
| 7 | 71 | 73 | 0.387 | 52 | 3 | 84 | 150.894 |
| 8 | 1 | 40 | 0.464 | 53 | 6 | 11 | 160.759 |
| 9 | 80 | 82 | 0.554 | 54 | 21 | 38 | 170.629 |
| 10 | 41 | 69 | 0.647 | 55 | 50 | 52 | 180.498 |
| 11 | 44 | 67 | 0.752 | 56 | 7 | 9 | 190.391 |
| 12 | 50 | 61 | 0.857 | 57 | 80 | 87 | 200.312 |
| 13 | 64 | 90 | 0.963 | 58 | 4 | 83 | 210.274 |
| 14 | 65 | 66 | 10.072 | 59 | 43 | 54 | 220.289 |
| 15 | 79 | 85 | 10.190 | 60 | 10 | 24 | 230.308 |
| 16 | 62 | 88 | 10.321 | 61 | 62 | 65 | 240.379 |
| 17 | 23 | 25 | 10.461 | 62 | 1 | 21 | 250.518 |
| 18 | 4 | 5 | 10.644 | 63 | 2 | 79 | 260.723 |
| 19 | 12 | 17 | 10.836 | 64 | 29 | 42 | 280.044 |
| 20 | 29 | 31 | 20.038 | 65 | 6 | 10 | 290.505 |
| 21 | 30 | 35 | 20.243 | 66 | 44 | 64 | 310.035 |
| 22 | 41 | 68 | 20.458 | 67 | 7 | 19 | 320.566 |
| 23 | 52 | 58 | 20.675 | 68 | 71 | 72 | 340.205 |
| 24 | 10 | 14 | 20.900 | 69 | 34 | 41 | 350.865 |
| 25 | 23 | 26 | 30.130 | 70 | 50 | 51 | 370.882 |
| 26 | 62 | 89 | 30.361 | 71 | 28 | 80 | 400.093 |
| 27 | 27 | 36 | 30.627 | 72 | 3 | 33 | 420.367 |
| 28 | 72 | 76 | 30.899 | 73 | 7 | 8 | 440.738 |
| 29 | 47 | 49 | 40.172 | 74 | 2 | 4 | 470.463 |
| 30 | 21 | 22 | 40.445 | 75 | 29 | 71 | 500.409 |
| 31 | 6 | 15 | 40.728 | 76 | 43 | 47 | 530.596 |
| 32 | 8 | 18 | 50.054 | 77 | 28 | 74 | 570.408 |
| 33 | 43 | 46 | 50.419 | 78 | 3 | 44 | 610.487 |
| 34 | 52 | 59 | 50.787 | 79 | 43 | 50 | 660.433 |
| 35 | 51 | 60 | 60.174 | 80 | 27 | 34 | 710.675 |
| 36 | 45 | 63 | 60.590 | 81 | 28 | 29 | 790.495 |
| 37 | 47 | 48 | 70.024 | 82 | 1 | 2 | 880.504 |
| 38 | 74 | 77 | 70.467 | 83 | 27 | 62 | 1000.828 |
| 39 | 71 | 81 | 70.948 | 84 | 1 | 7 | 1130.406 |
| 40 | 7 | 13 | 80.442 | 85 | 6 | 12 | 1260.576 |
| 41 | 54 | 55 | 80.947 | 86 * | 27 | 43 | 1440.536 |
| 42 | 71 | 78 | 90.470 | 87 | 3 | 27 | 1800.351 |
| 43 | 72 | 75 | 100.000 | 88 | 6 | 28 | 2160.710 |
| 44 | 12 | 16 | 100.537 | 89 | 1 | 3 | 2890.013 |
| 45 | 32 | 70 | 110.076 | 90 | 1 | 6 | 4500.000 |


| Cluster | Error | F | Sig. | |||
|---|---|---|---|---|---|---|
| Mean Square | df | Mean Square | df | |||
| ZScore_Pop. < 14 (%) | 150.036 | 4 | 0.347 | 86 | 430.307 | 0.000 |
| ZScore_Net household income (€/year) | 170.935 | 4 | 0.212 | 86 | 840.461 | 0.000 |
| ZScore_Urban density (hab/m2) | 160.365 | 4 | 0.285 | 86 | 570.345 | 0.000 |
| ZScore_ PT stops (No./ha) | 130.688 | 4 | 0.410 | 86 | 330.398 | 0.000 |
| ZScore_Distance city center (km) | 150.626 | 4 | 0.320 | 86 | 480.874 | 0.000 |
References
- Bettencourt, L.M.A.; Lobo, J.; Helbing, D.; Kühnert, C.; West, G.B. Growth, innovation, scaling, and the pace of life in cities. Proc. Natl. Acad. Sci. USA 2007, 104, 7301–7306. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nieuwenhuijsen, M.J. Urban and transport planning, environmental exposures and health-new concepts, methods and tools to improve health in cities. Environ. Health 2016, 15, 161–171. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Newman, P.; Kenworthy, J. Sustainability and Cities: Overcoming Automobile Dependence; Island Press: Washington, DC, USA, 1999. [Google Scholar]
- Alonso, A.; Monzón, A.; Cascajo, R. Comparative analysis of passenger transport sustainability in European cities. Ecol. Indic. 2015, 48, 578–592. [Google Scholar] [CrossRef] [Green Version]
- Nieuwenhuijsen, M.J. Urban and transport planning pathways to carbon neutral, liveable and healthy cities; A review of the current evidence. Environ. Int. 2020, 140, 105661. [Google Scholar] [CrossRef]
- Goldman, T.; Gorham, R. Sustainable urban transport: Four innovative directions. Technol. Soc. 2006, 28, 261–273. [Google Scholar] [CrossRef]
- Attard, M.; Shiftan, Y. Sustainable Urban Transport, 1st ed.; Emerald Group Publishing Limited: Bingley, UK, 2015. [Google Scholar]
- Gallo, M.; Marinelli, M. Sustainable mobility: A review of possible actions and policies. Sustainability 2020, 12, 7499. [Google Scholar] [CrossRef]
- Banister, D. The sustainable mobility paradigm. Transp. Policy 2008, 15, 73–80. [Google Scholar] [CrossRef]
- European Commission. Green Paper—Towards a New Culture for Urban Mobility; COM (2007) 0551 Final; European Commission: Brussels, Belgium, 2007. [Google Scholar]
- European Commission. Action Plan on Urban Mobility; COM (2009) 490 Final; European Commission: Brussels, Belgium, 2009. [Google Scholar]
- European Commission. Together towards Competitive and Resource-Efficient Urban Mobility; COM (2013) 0913 Final; European Commission: Brussels, Belgium, 2013. [Google Scholar]
- Mozos-Blanco, M.Á.; Pozo-Menéndez, E.; Arce-Ruiz, R.; Baucells-Aletà, N. The way to sustainable mobility. A comparative analysis of sustainable mobility plans in Spain. Transp. Policy 2018, 72, 45–54. [Google Scholar] [CrossRef]
- Kiba-Janiak, M.; Witkowski, J. Sustainable Urban Mobility Plans: How Do They Work? Sustainability 2019, 11, 4605. [Google Scholar] [CrossRef] [Green Version]
- De Falco, S.; Angelidou, M.; Addie, J.P.D. From the “smart city” to the “smart metropolis”? Building resilience in the urban periphery. Eur. Urban Reg. Stud. 2018, 26, 205–223. [Google Scholar] [CrossRef]
- Camagni, R.; Gibelli, M.C.; Rigamonti, P. Urban mobility and urban form: The social and environmental costs of different patterns of urban expansion. Ecol. Econ. 2002, 40, 199–216. [Google Scholar] [CrossRef]
- Bassolas, A.; Barbosa-Filho, H.; Dickinson, B.; Dotiwalla, X.; Eastham, P.; Gallotti, R.; Ghoshal, G.; Gipson, B.; Hazarie, S.A.; Kautz, H.; et al. Hierarchical organization of urban mobility and its connection with city livability. Nat. Commun. 2019, 10, 4817. [Google Scholar] [CrossRef] [Green Version]
- McKenzie, G. Urban mobility in the sharing economy: A spatiotemporal comparison of shared mobility services. Comput. Environ. Urban Syst. 2020, 79, 101418. [Google Scholar] [CrossRef]
- Alonso, A.; Monzón, A.; Cascajo, R. Measuring Negative Synergies of Urban Sprawl and Economic Crisis over Public Transport Efficiency. Int. Reg. Sci. Rev. 2017, 41, 540–576. [Google Scholar] [CrossRef] [Green Version]
- Oskarbski, J.; Birr, K.; Zarski, K.; Coelho, M.; Fernandes, P.; Zbieta Macioszek, E. Bicycle Traffic Model for Sustainable Urban Mobility Planning. Energies 2021, 14, 5970. [Google Scholar] [CrossRef]
- Bratzel, S. Conditions of success in sustainable urban transport policyPolicy change in “relatively successful” European cities. Transp. Rev. 2010, 19, 177–190. [Google Scholar] [CrossRef]
- Puhe, M.; Schippl, J. User Perceptions and Attitudes on Sustainable Urban Transport among Young Adults: Findings from Copenhagen, Budapest and Karlsruhe. J. Environ. Policy Plan. 2014, 16, 337–357. [Google Scholar] [CrossRef]
- Magdolen, M.; von Behren, S.; Burger, L.; Chlond, B. Mobility Styles and Car Ownership—Potentials for a Sustainable Urban Transport. Sustainability 2021, 13, 2968. [Google Scholar] [CrossRef]
- Acheampong, R.A.; Cugurullo, F.; Gueriau, M.; Dusparic, I. Can autonomous vehicles enable sustainable mobility in future cities? Insights and policy challenges from user preferences over different urban transport options. Cities 2021, 112, 103134. [Google Scholar] [CrossRef]
- Geneletti, D.; La Rosa, D.; Spyra, M.; Cortinovis, C. A review of approaches and challenges for sustainable planning in urban peripheries. Landsc. Urban Plan. 2017, 165, 231–243. [Google Scholar] [CrossRef]
- Harig, O.; Burghardt, D.; Hecht, R. A Supervised Approach to Delineate Built-Up Areas for Monitoring and Analysis of Settlements. Int. J. Geo-Inf. 2016, 5, 137. [Google Scholar] [CrossRef] [Green Version]
- Litýnski, P. The Intensity of Urban Sprawl in Poland. Int. J. Geo-Inf. 2021, 10, 95. [Google Scholar] [CrossRef]
- Handy, S. Methodologies for exploring the link between urban form and travel behavior. Transp. Res. Part D Transp. Environ. 1996, 1, 151–165. [Google Scholar] [CrossRef]
- Kockelman, K.M. Travel Behavior as Function of Accessibility, Land Use Mixing, and Land Use Balance: Evidence from San Francisco Bay Area. Transp. Res. Rec. J. Transp. Res. Board 1997, 1607, 116–125. [Google Scholar] [CrossRef]
- Giuliano, G.; Narayan, D. Another Look at Travel Patterns and Urban Form: The US and Great Britain. Urban Stud. 2003, 40, 2295–2312. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M. Exploring the relationship between urban form and nonwork travel through time use analysis. Landsc. Urban Plan. 2005, 73, 244–261. [Google Scholar] [CrossRef]
- Giuliano, G.; Dargay, J. Car ownership, travel and land use: A comparison of the US and Great Britain. Transp. Res. Part A Policy Pract. 2006, 40, 106–124. [Google Scholar] [CrossRef]
- Limtanakool, N.; Dijst, M.; Schwanen, T. The influence of socioeconomic characteristics, land use and travel time considerations on mode choice for medium- and longer-distance trips. J. Transp. Geogr. 2006, 14, 327–341. [Google Scholar] [CrossRef]
- Kang, C.; Ma, X.; Tong, D.; Liu, Y. Intra-urban human mobility patterns: An urban morphology perspective. Phys. A Stat. Mech. Its Appl. 2012, 391, 1702–1717. [Google Scholar] [CrossRef]
- Klinger, T.; Lanzendorf, M. Moving between mobility cultures: What affects the travel behavior of new residents? Transportation 2016, 43, 243–271. [Google Scholar] [CrossRef]
- Bel, G.; Rosell, J. The impact of socioeconomic characteristics on CO2 emissions associated with urban mobility: Inequality across individuals. Energy Econ. 2017, 64, 251–261. [Google Scholar] [CrossRef]
- Marcińczak, S.; Bartosiewicz, B. Commuting patterns and urban form: Evidence from Poland. J. Transp. Geogr. 2018, 70, 31–39. [Google Scholar] [CrossRef]
- Reul, J.; Grube, T.; Stolten, D. Urban transportation at an inflection point: An analysis of potential influencing factors. Transp. Res. Part D Transp. Environ. 2021, 92, 102733. [Google Scholar] [CrossRef]
- Cerin, E.; Sallis, J.F.; Salvo, D.; Hinckson, E.; Conway, T.L.; Owen, N.; van Dyck, D.; Lowe, M.; Higgs, C.; Moudon, A.V.; et al. Determining thresholds for spatial urban design and transport features that support walking to create healthy and sustainable cities: Findings from the IPEN Adult study. Lancet Glob. Health 2022, 10, e895–e906. [Google Scholar] [CrossRef]
- Jiménez-Espada, M.; Naranjo, J.M.V.; García, F.M.M. Identification of Mobility Patterns in Rural Areas of Low Demographic Density through Stated Preference Surveys. Appl. Sci. 2022, 12, 10034. [Google Scholar] [CrossRef]
- U-MOVE. Smart Strategies for Urban Sustainable Mobility. Available online: http://umove.transyt-projects.es/ (accessed on 18 October 2022).
- Romero, C.; Monzón, A.; Alonso, A.; Julio, R. Potential demand for bus commuting trips in metropolitan corridors through the use of real-time information tools. Int. J. Sustain. Transp. 2021, 16, 314–325. [Google Scholar] [CrossRef]
- Schafer, A.; Victor, D.G. The future mobility of the world population. Transp. Res. Part A Policy Pract. 2000, 34, 171–205. [Google Scholar] [CrossRef]
- Tyrinopoulos, Y.; Antoniou, C. Factors affecting modal choice in urban mobility. Eur. Transp. Res. Rev. 2013, 5, 27–39. [Google Scholar] [CrossRef] [Green Version]
- Cavoli, C. Accelerating sustainable mobility and land-use transitions in rapidly growing cities: Identifying common patterns and enabling factors. J. Transp. Geogr. 2021, 94, 103093. [Google Scholar] [CrossRef]
- Deloitte; IPD. Encuesta de Movilidad de la Comunidad de Madrid 2018; Consorcio Regional de Transportes de Madrid: Madrid, Spain, 2018. [Google Scholar]
- Nicolas, J.P.; Pochet, P.; Poimboeuf, H. Towards sustainable mobility indicators: Application to the Lyons conurbation. Transp. Policy 2003, 10, 197–208. [Google Scholar] [CrossRef]
- Consorcio de Transportes de Madrid. Available online: https://www.crtm.es/conocenos/planificacion-estudios-y-proyectos/encuesta-domiciliaria/edm2018.aspx (accessed on 18 October 2022).
- Consorcio de Transportes de Madrid. Datos Abiertos. Available online: https://data-crtm.opendata.arcgis.com/ (accessed on 18 October 2022).
- Ministerio de Transportes, Movilidad y Agenda Urbana. Centro de Descargas. Organismo Autónomo Centro Nacional de Información Geográfica. Available online: https://centrodedescargas.cnig.es/CentroDescargas/ (accessed on 18 October 2022).
- Nomecalles. Instituto de Estadística de la Comunidad de Madrid. Available online: https://www.madrid.org/nomecalles/DescargaBDTCorte.icm (accessed on 18 October 2022).
- INE. Instituto de Estadística Nacional. Available online: https://www.ine.es/ (accessed on 18 October 2022).
- May, A.D.; Page, M.; Hull, A. Developing a set of decision-support tools for sustainable urban transport in the UK. Transp. Policy 2008, 15, 328–340. [Google Scholar] [CrossRef]
- Haghshenas, H.; Vaziri, M. Urban sustainable transportation indicators for global comparison. Ecol. Indic. 2012, 15, 115–121. [Google Scholar] [CrossRef]
- Huck, S. Reading Statistics and Research; Pearson: Boston, MA, USA, 2000. [Google Scholar]
- Field, A. Discovering Statistics Using IBM SPSS Statistics, 3rd ed.; SAGE: Thousand Oaks, CA, USA, 2013. [Google Scholar]
- Rousseau, R.; Egghe, L.; Guns, R. Becoming Metric-Wise: A Bibliometric Guide for Researchers; Chandos Publishing: Cambridge, UK, 2018. [Google Scholar]
- Boslaugh, S. Statistics in a Nutshell, 2nd ed.; O’RELLY: Sebastopol, CA, USA, 2013. [Google Scholar]
- Bonett, D.G.; Wright, T.A. Sample size requirements for estimating Pearson, Kendall and Spearman correlations. Psychometrika 2000, 65, 23–28. [Google Scholar] [CrossRef]
- Nardo, M.; Saisana, M.; Saltelli, A.; Tarantola, S.; Hoffman, H.; Giovannini, E. Handbook on Constructing Composite Indicators: Methodology and User Guide; OECD: Paris, France, 2005. [Google Scholar]
- Milligan, G.W.; Cooper, M.C. An examination of procedures for determining the number of clusters in a data set. Psychometrika 1985, 50, 159–179. [Google Scholar] [CrossRef]
- Hair, J.F.; Black, W.C.; Babin, B.J.; Anderson, R.E. Multivariate Data Analysis, 7th ed.; Pearson: Boston, MA, USA, 2009. [Google Scholar]
- Miralles-Guasch, C.; Melo, M.M.; Marquet, O. A gender analysis of everyday mobility in urban and rural territories: From challenges to sustainability. Gend. Place Cult. 2015, 23, 398–417. [Google Scholar] [CrossRef]
- Carpio-Pinedo, J.; Benito-Moreno, M.; Lamíquiz-Daudén, P.J. Beyond land use mix, walkable trips. An approach based on parcel-level land use data and network analysis. J. Maps 2021, 17, 23–30. [Google Scholar] [CrossRef]
- Mavoa, S.; Witten, K.; McCreanor, T.; O’Sullivan, D. GIS based destination accessibility via public transit and walking in Auckland, New Zealand. J. Transp. Geogr. 2012, 20, 15–22. [Google Scholar] [CrossRef]
- Ford, A.C.; Barr, S.L.; Dawson, R.J.; James, P. Transport Accessibility Analysis Using GIS: Assessing Sustainable Transport in London. Int. J. Geo-Inf. 2015, 4, 124–149. [Google Scholar] [CrossRef]



| Corridor | Population * (1000 Inhabitants) | Average Gross Income * (1000 € per Inhabitant Per Year) | Daily Traffic * (1000 Cars Per Day) |
|---|---|---|---|
| A-1 | 250 | 50 | 90 |
| A-2 * | 600 | 30 | 135 |
| A-3 | 200 | 30 | 85 |
| A-4 | 550 | 25 | 125 |
| A-42 | 750 | 25 | 110 |
| A-5 | 750 | 30 | 90 |
| A-6 * | 550 | 55 | 140 |
| M-607 | 300 | 45 | 80 |
| Determinants of Urban Mobility | References (Literature Review) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Key Concepts | Variables | (a) | (b) | (c) | (d) | (e) | (f) | (g) | (h) | (i) | (j) | (k) | (l) | |
| Socioeconomic and personal characteristics | Demographic distribution | -Children -Elders -Working-age people -Gender | X | X | X | X | X | X | ||||||
| Socio-economic features | -Household income -Household size -Educational level | X | X | X | X | X | X | |||||||
| Land-use attributes and urban form | Density and diversity | -Inhabitants per hectare -Land use -Activities (e.g., schools, health centers, shops) | X | X | X | X | X | X | X | X | ||||
| Accessibility | -Existence of railway station -PT services -Configuration of streets (e.g., no. of intersections) | X | X | X | X | X | X | X | X | |||||
| Geographical situation | -Distance to the city center | X | X | X | X | |||||||||
| Urban size and form | -Population in the municipality -Shape index | X | X | X | X | X | X | |||||||
| Urban transport patterns | Car availability and modal choices | -Modal share (car/PT/bike/walking) -Car availability | X | X | X | X | X | X | X | X | X | |||
| Trip characteristics | -Travel distance -Time and timetables -Trip purposes | X | X | X | X | X | X | X | X | |||||
| Variables from Literature Review | Selected * and Calculated Indicators Per Transport Zone (Units) | Reference Year and Comments | Databases (X) Data Available (✓) Data Used | ||||
|---|---|---|---|---|---|---|---|
| [A] | [B] | [C] | [D] | [E] | |||
| -Children -Elders -Working-age people -Gender | -Population under 14 (%) -Population over 65 (%) -Working age population (%) -Women (%) | Year 2018. Data on [E] are more complete and solid as it comes from electoral roll and not from a statistical sample | X | ✓ | |||
| -Household income -Household size -Educational level | -Net household income (€/year) | Year 2018 | X | ✓ | |||
| -Inhabitants per hectare -Land use -Activities (e.g., schools, health centers, shops) | -Urban density (Inhabitants/ha) | Year 2021. This indicator requires information on soil classification (urban areas), available in [C], and population, available in [E]. Information on these sources is provided up to date (reference year 2021) | ✓ | ✓ | |||
| -Aggregated activities (No./ha) | Year 2021. Information on aggregated activities (i.e., schools, health centers, and commerce) is available in [D] and provided up to date (reference year 2021) | ✓ | |||||
| -Existence of railway station -PT services | -Population near a train station <800 m (%) -PT stops (No./ha) | Year 2021. Data for public transport offer are available in [B] and values of population and buffers are provided by [C] | ✓ | ✓ | |||
| -Distance to the city center | -Distance to the city center (km) | Year 2021. Average distances to the city center are calculated through [D] | ✓ | ||||
| -Population in the municipality -Shape index | - | Since transport zones are smaller than municipalities (Figure 2), these indicators are not appropriate to the context | X | X | |||
| - Modal share (Car/PT/ Bike/Walking) -Car availability | -Car share (%) -PT share (%) -Walking share (%) -Car availability (no. vehicles per Inhabitant) | Year 2018 | ✓ | ||||
| -Travel distance -Time and timetables -Trip purposes | -Average travel distance (km) | Year 2018. Information on time and timetables or trip purposes is also available in [A], but data are provided in categorical formats, not easily transformed into numerical variables (therefore discarded) | ✓ | ||||
| Kolmogorov–Smirnov | Shapiro–Wilk | |||||
|---|---|---|---|---|---|---|
| Statistic | df | Sig. (>0.05) | Statistic | df | Sig. (>0.05) | |
| Car share (%) | 0.120 | 91 | 0.002 | 0.954 | 91 | 0.003 |
| PT share (%) * | 0.084 | 91 | 0.122 | 0.980 | 91 | 0.183 |
| Walking share (%) | 0.108 | 91 | 0.010 | 0.950 | 91 | 0.002 |
| Car Availability (no. vehicles per inhabitant) * | 0.065 | 91 | 0.200 | 0.987 | 91 | 0.533 |
| Average travel distance (km) | 0.269 | 91 | 0.000 | 0.426 | 91 | 0.000 |
| Transport Variables | ||||||
|---|---|---|---|---|---|---|
| Normal Variables | Non-Normal Variables | |||||
| Key Concepts | Explanatory Variables | PT Share | Car Availability | Car Share | Walking Share | Average Travel Distance |
| Demographic distribution | Population under 14 (%) | −0.080 | 0.378 ** | 0.659 ** | −0.633 ** | 0.439 ** |
| Population over 65 (%) | 0.166 | −0.348 ** | −0.553 ** | 0.484 ** | −0.333 ** | |
| Working age population (%) | −0.183 | 0.135 | 0.188 | −0.126 | 0.130 | |
| Women (%) | 0.064 | 0.011 | −0.059 | 0.029 | 0.105 | |
| Socio-economic features | Net household income (€/year) | 0.354 ** | 0.523 ** | 0.705 ** | −0.737 ** | 0.495 ** |
| Density and diversity | Urban density (Inhabitants/ha) | −0.069 | −0.613 ** | −0.812 ** | 0.799 ** | −0.582 ** |
| Aggregated activities (No./ha) | −0.059 | −0.487 ** | −0.735 ** | 0.702 ** | −0.533 ** | |
| Accessibility | Population near a train station <800 m (%) | 0.244 * | −0.078 | −0.160 | 0.080 | 0.002 |
| PT stops (No./ha) | 0.009 | −0.517 ** | −0.753 ** | 0.715 ** | −0.506 ** | |
| Geographical situation | Distance to the city center (km) | −0.384 ** | −0.296 ** | −0.174 | 0.269 ** | 0.205 |
| (Pearson coefficient) | (Spearman rho) | |||||
| Indicators | Cluster 1 (n = 10) | Cluster 2 (n = 24) | Cluster 3 (n = 21) | Cluster 4 (n = 9) | Cluster 5 (n = 27) |
|---|---|---|---|---|---|
| Self-Sufficient Dense Zones, with Aging Population and Far from City Center | Middle-Class Dense Zones in the East, Closer to City Center | Middle-Class Zones with Low Density and Far from City Center | Upper-Class Families with Children and Very Car-Dependent | Wealthiest Zones with Very Low Density and Few Local Activities | |
| Population under 14 (%) | 12 | 13 | 16 | 24 | 16 |
| Population over 65 (%) | 22 | 19 | 14 | 8 | 17 |
| Working age population (%) | 65 | 68 | 70 | 67 | 67 |
| Women (%) | 52 | 51 | 51 | 51 | 52 |
| Net household income (€/year) | 32,081 | 37,265 | 41,964 | 60,054 | 77,664 |
| Urban density (Inhab./ha) | 268 | 175 | 55 | 39 | 34 |
| Aggregated activities (no./ha) | 13.8 | 11.4 | 6.2 | 4.3 | 3.4 |
| Population near a train station <800 m (%) | 39.1 | 21.7 | 17.6 | 27.8 | 15.4 |
| PT stops (no./ha) | 75 | 39 | 18 | 12 | 16 |
| Distance to the city center (km) | 30.1 | 16.4 | 30.4 | 19.9 | 14.7 |
| Car share (%) | 28 | 37 | 51 | 67 | 62 |
| PT share (%) | 14 | 14 | 13 | 12 | 18 |
| Walking share (%) | 57 | 48 | 35 | 20 | 18 |
| Car availability (no. vehicles per inhabitant) | 0.54 | 0.64 | 0.68 | 0.74 | 0.73 |
| Average travel distance (km) | 7 | 4 | 6 | 11 | 6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alonso, A.; Monzón, A.; Aguiar, I.; Ramírez-Saiz, A. Explanatory Factors of Daily Mobility Patterns in Suburban Areas: Applications and Taxonomy of Two Metropolitan Corridors in Madrid Region. ISPRS Int. J. Geo-Inf. 2023, 12, 16. https://doi.org/10.3390/ijgi12010016
Alonso A, Monzón A, Aguiar I, Ramírez-Saiz A. Explanatory Factors of Daily Mobility Patterns in Suburban Areas: Applications and Taxonomy of Two Metropolitan Corridors in Madrid Region. ISPRS International Journal of Geo-Information. 2023; 12(1):16. https://doi.org/10.3390/ijgi12010016
Chicago/Turabian StyleAlonso, Andrea, Andrés Monzón, Iago Aguiar, and Alba Ramírez-Saiz. 2023. "Explanatory Factors of Daily Mobility Patterns in Suburban Areas: Applications and Taxonomy of Two Metropolitan Corridors in Madrid Region" ISPRS International Journal of Geo-Information 12, no. 1: 16. https://doi.org/10.3390/ijgi12010016