

A Review of Trajectory Prediction Methods for the Vulnerable Road User

Abstract
:1. Introduction
- We summarize and synthesize recent Deep Learning strategies for enhancing trajectory prediction in autonomous driving, focusing on VRU safety. To the best of our knowledge, no comparable studies have delved into recent Deep Learning methods to this extent.
- We scrutinize various interaction models, revealing critical input features driving the success of prevalent prediction methods, and give an in-depth summary of possible output modes.
- We provide extensive insight into the efficacy of methods on various datasets, conduct a rigorous analysis of the results, and identify promising further research directions.
2. Fundamentals and Taxonomy
2.1. Problem Formulation
2.2. Classification Taxonomy and Method Selection
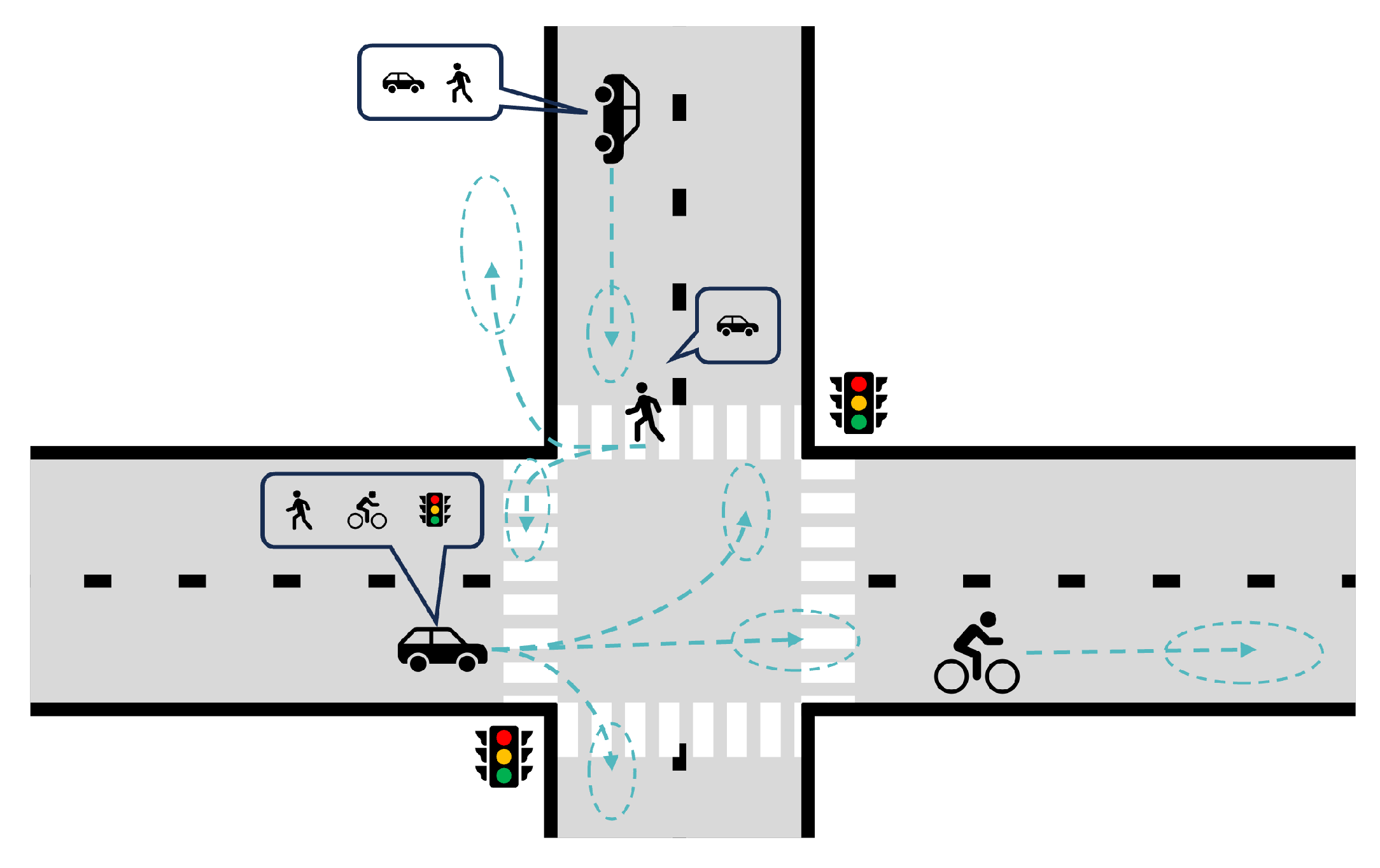
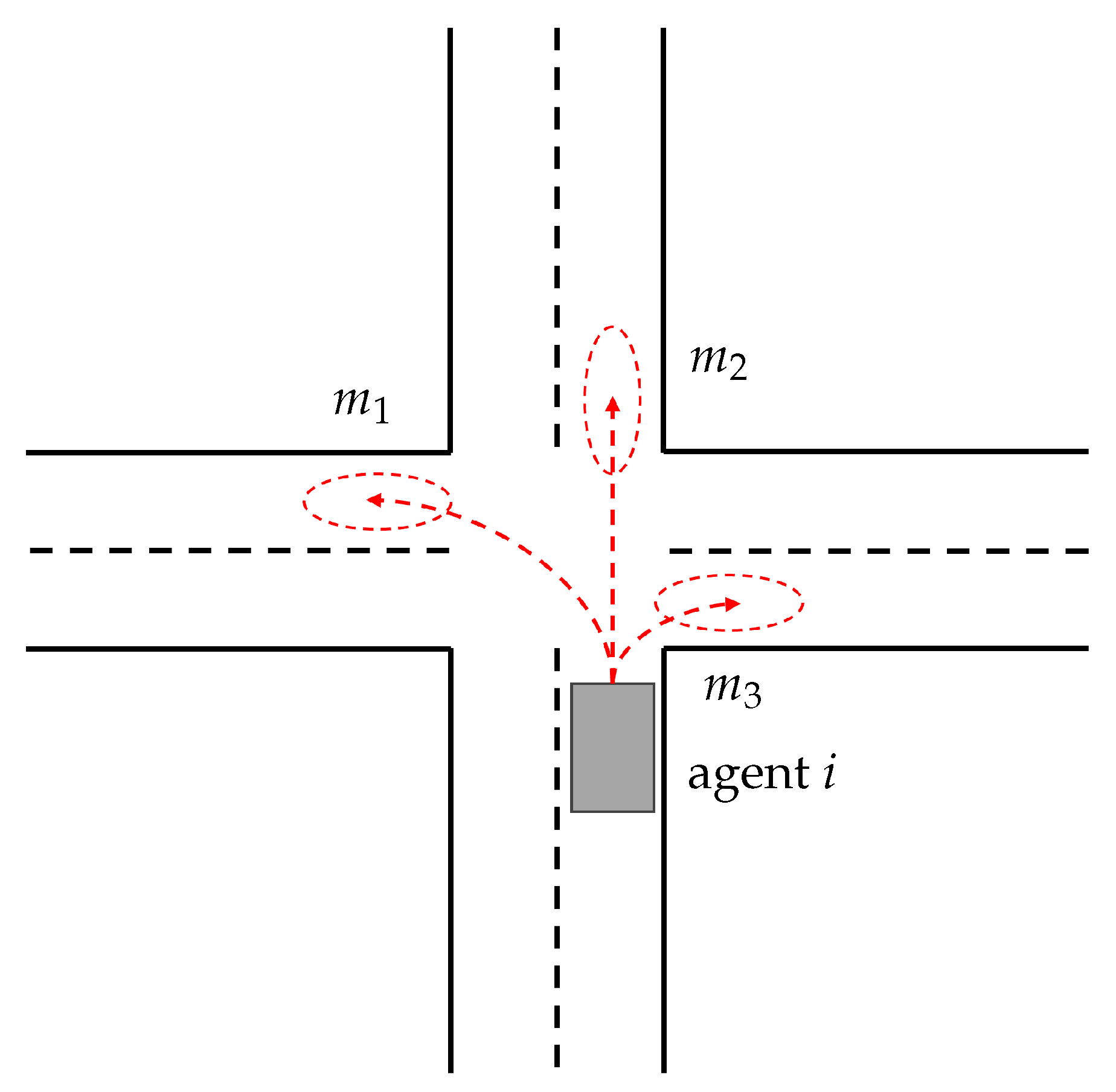
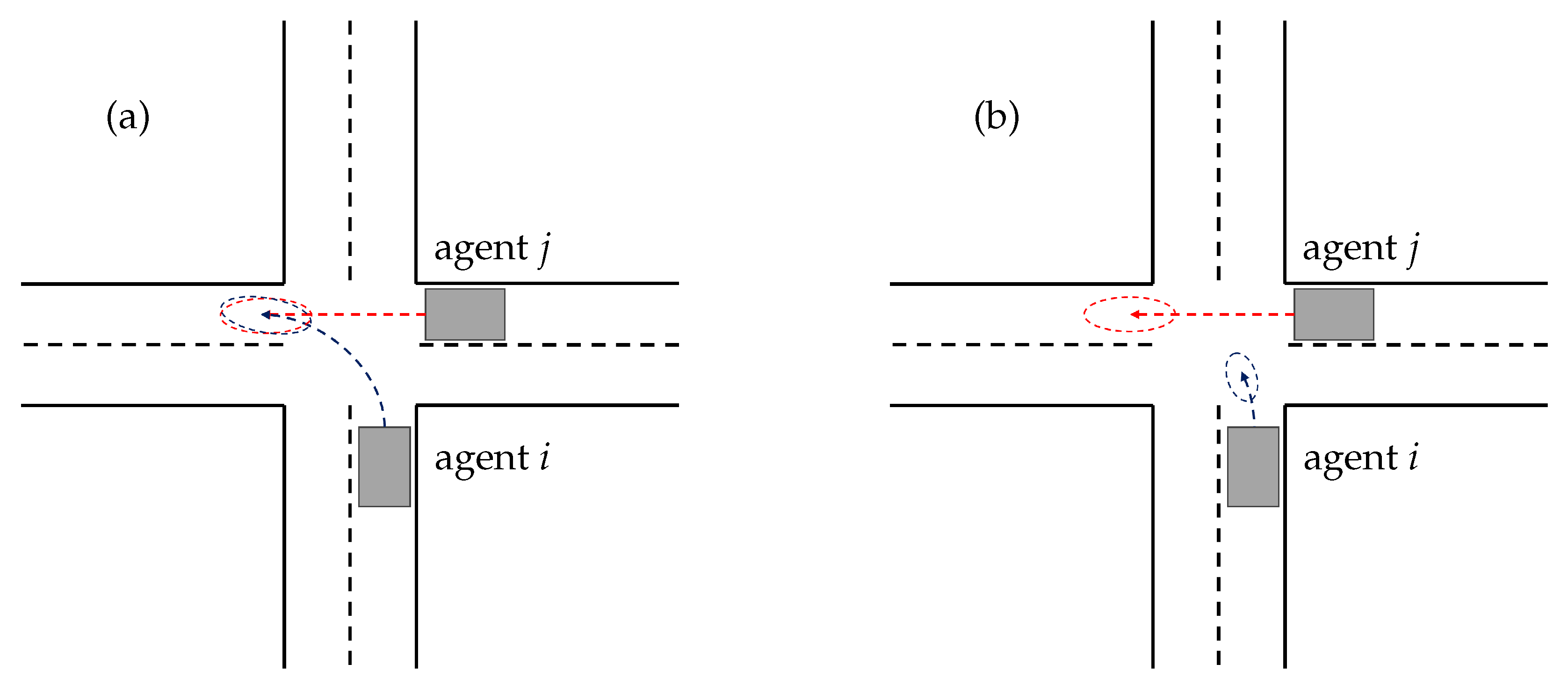
3. State and Context Representation
3.1. Possible Input Features
3.2. Scene Representation and Interaction Modeling
3.3. Output Representation
4. Neural Architectures
4.1. Diffusion-Based Methods
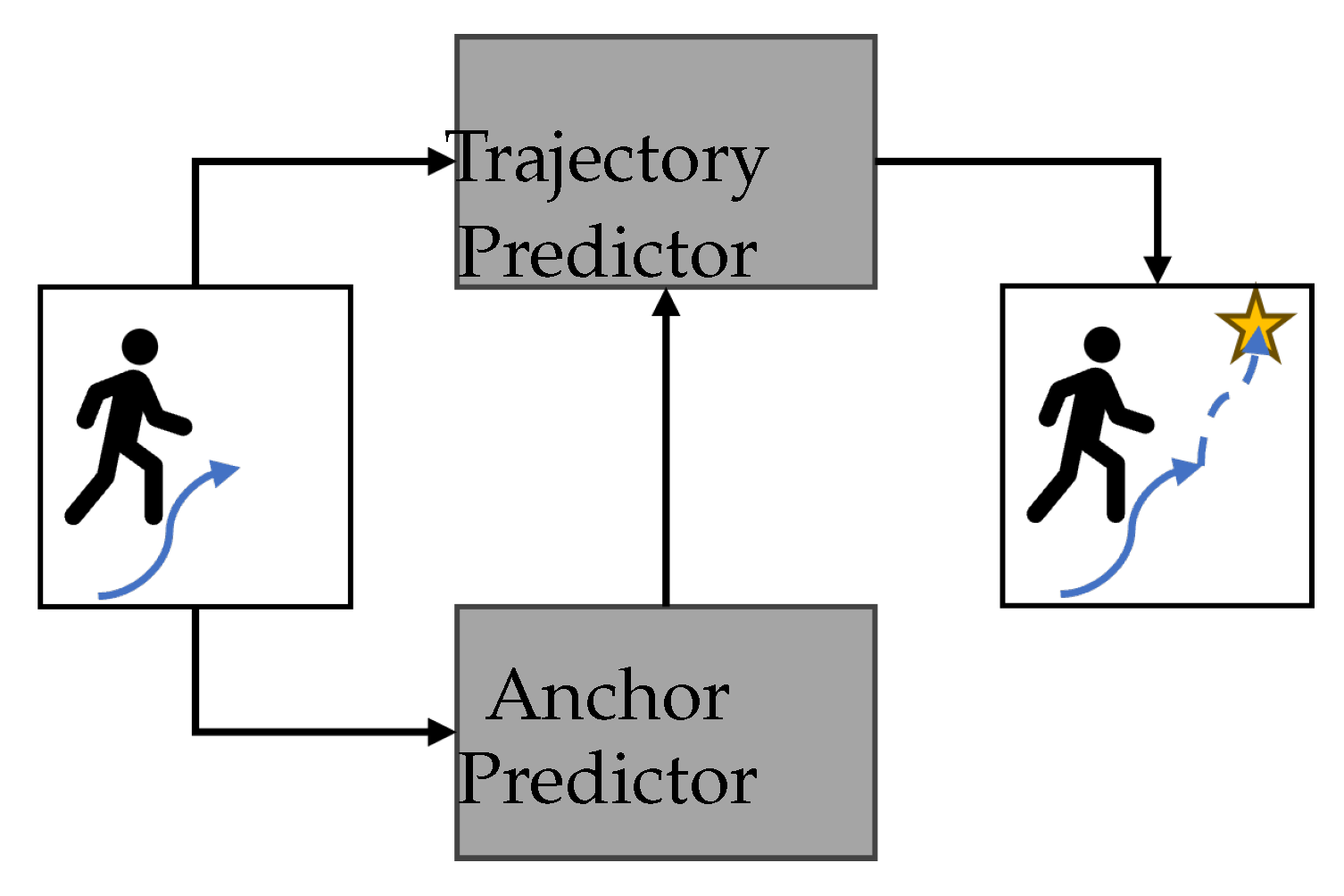
4.2. Anchor-Conditioned Methods
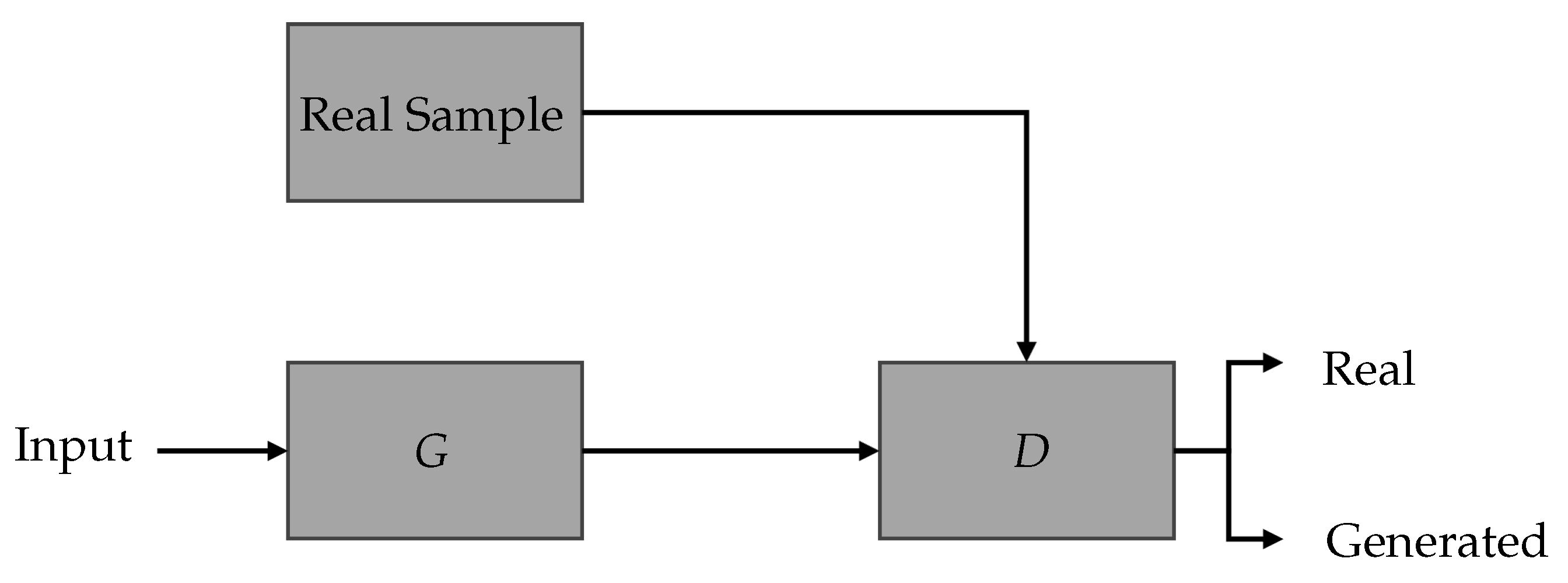
4.3. GAN-Based Methods
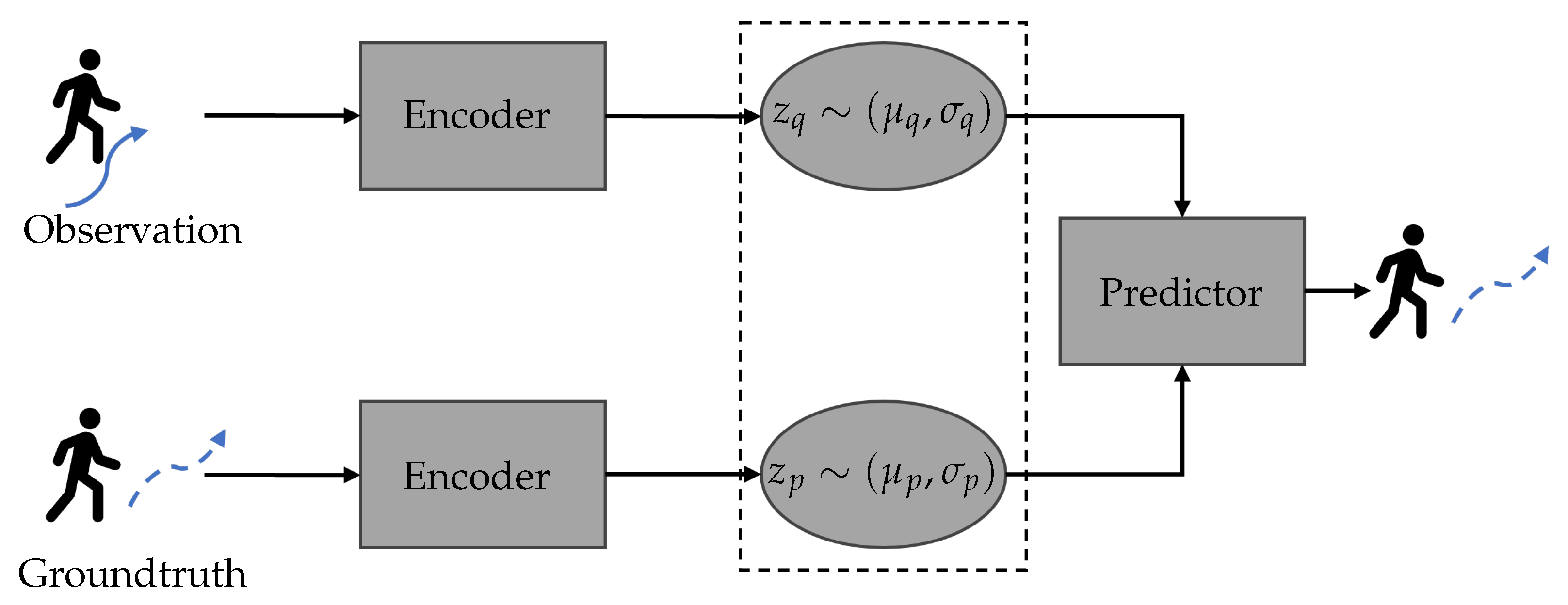
4.4. CVAE-Based Methods
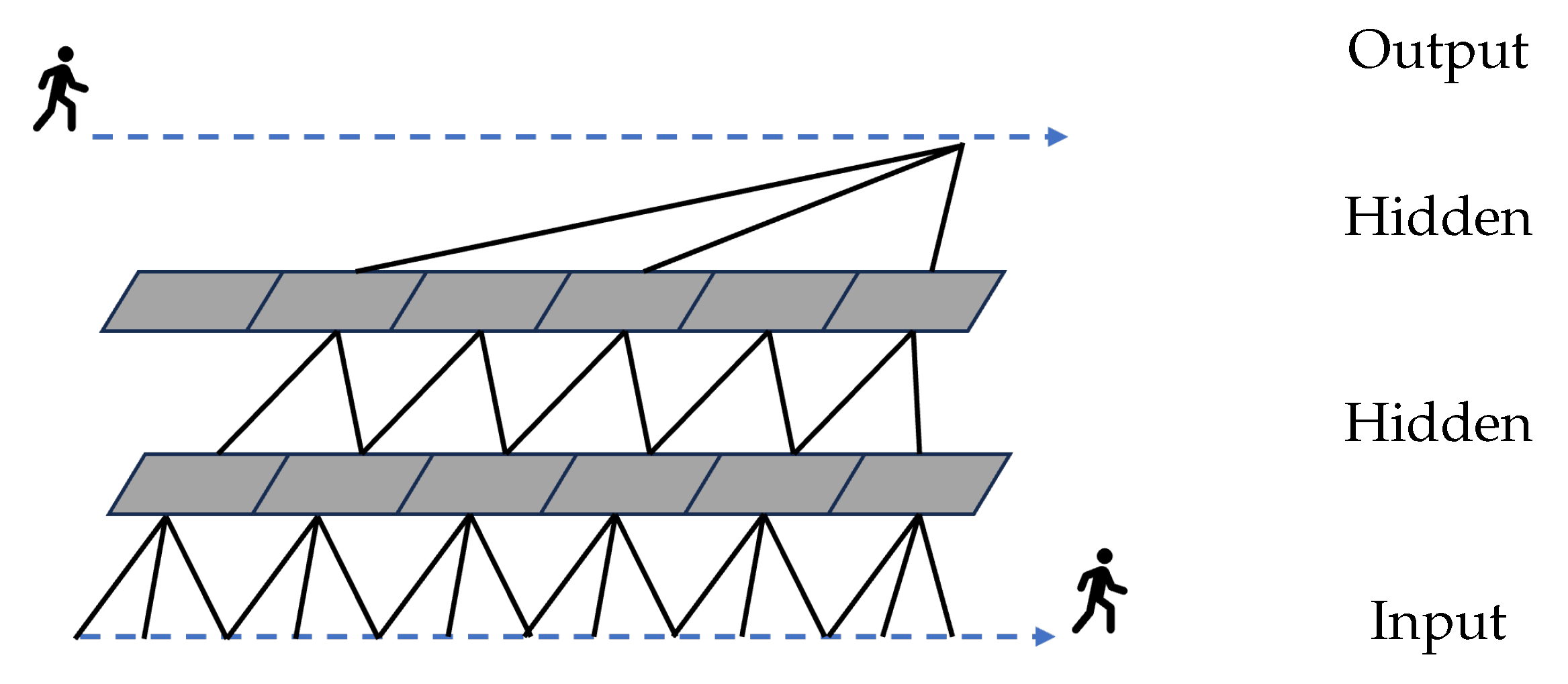
4.5. RNN-Based Methods
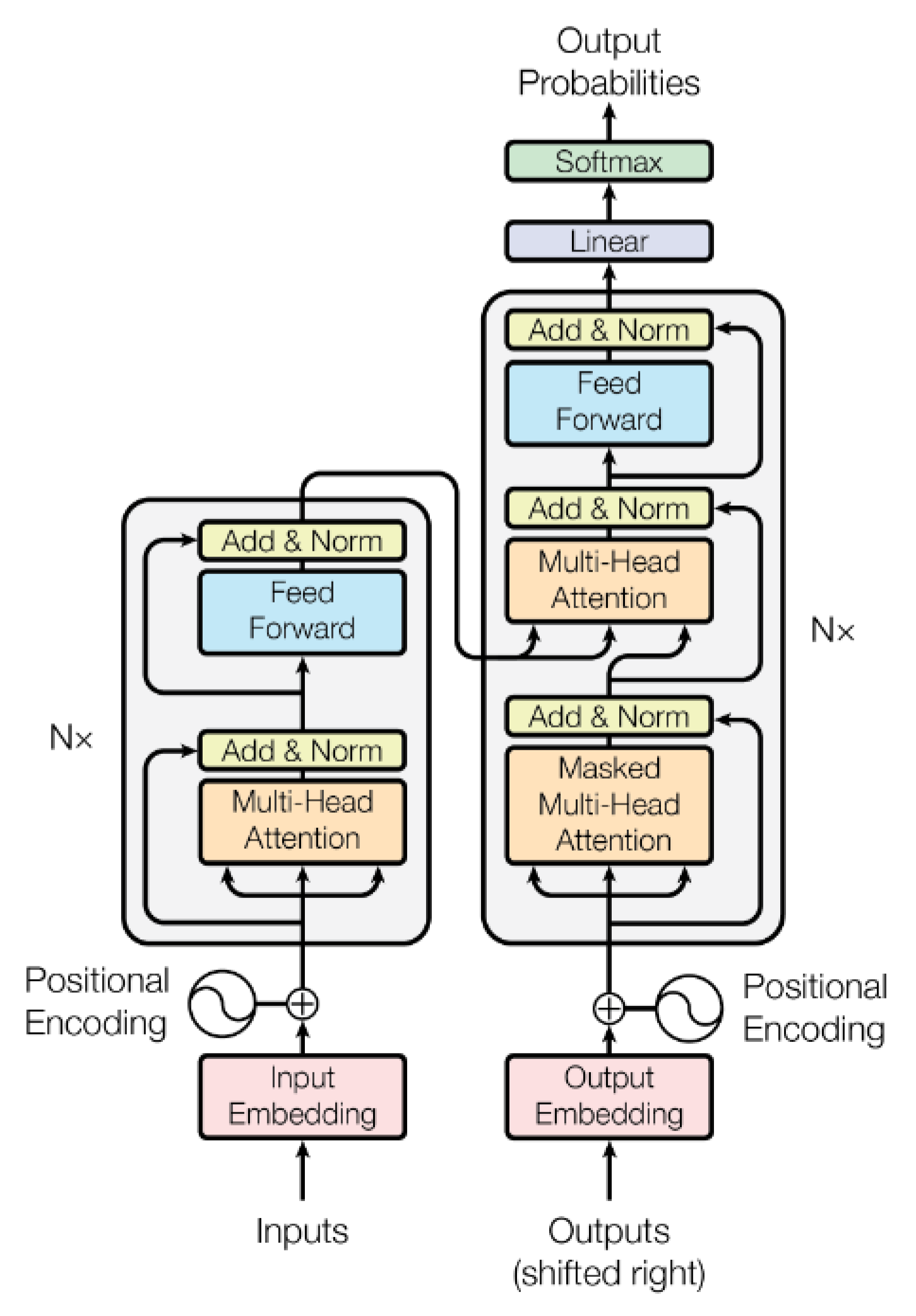
4.6. Transformer- and Attention-Based Methods
4.7. CNN-Based Methods
4.8. TCN-Based Methods
4.9. Graph-Based Methods
4.10. Set-Based Methods
4.11. Other Prediction Methods
5. Evaluation and Results
5.1. Datasets
5.2. Metrics
5.3. Summary of Reported Results
5.4. Discussion
5.5. Potential Research Directions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| GAN | Generative adversarial network |
| CVAE | Conditional variational autoencoder |
| CNN | Convolutional neural network |
| TCN | Temporal convolutional network |
| GNN | Graph neural network |
| LLM | Large Language Model |
| VRU | Vulnerable road user |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Method Class | Year | ||
|---|---|---|---|---|
| Observations [98] | Other | 2022 | 0.24 | 0.53 |
| Method | Method Class | Year | ||
|---|---|---|---|---|
| Spatial Transformer [72] | Transformer | 2022 | 18.51 | 35.84 |
| Method | Method Class | Year | @1 s | @3 s | @1 s | @3 s |
|---|---|---|---|---|---|---|
| PTP [123] | CVAE | 2021 | 0.471 | 1.319 | 0.763 | 2.299 |
References
- Zoox. Zoox Purpose-Built Robotaxi Is First in the World to Operate on Public Roads. 2023. Available online: https://zoox.com/wp-content/uploads/zoox-press-release-immediate-release.pdf (accessed on 9 October 2023).
- LLC, C. Human Ridehail Crash Rate Benchmark. 2023. Available online: https://getcruise.com/news/blog/2023/human-ridehail-crash-rate-benchmark/ (accessed on 9 October 2023).
- Lillo, L.D.; Gode, T.; Zhou, X.; Atzei, M.; Chen, R.; Victor, T. Comparative Safety Performance of Autonomous- and Human Drivers: A Real-World Case Study of the Waymo One Service. arXiv 2023, arXiv:2309.01206. [Google Scholar]
- Laumond, J.; Sekhavat, S.; Lamiraux, F. Lecture Notes in Control and Information Sciences 229; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Foundation, C.V. CVPR 2023 Open Access. 2023. Available online: https://openaccess.thecvf.com/CVPR2023?day=all (accessed on 24 October 2023).
- Foundation, C.V. ICCV 2023 Open Access. 2023. Available online: https://openaccess.thecvf.com/ICCV2023?day=all (accessed on 24 October 2023).
- Leon, F.; Gavrilescu, M. A review of tracking and trajectory prediction methods for autonomous driving. Mathematics 2021, 9, 660. [Google Scholar] [CrossRef]
- Liu, J.; Mao, X.; Fang, Y.; Zhu, D.; Meng, M.Q.H. A survey on deep-learning approaches for vehicle trajectory prediction in autonomous driving. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 6–9 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 978–985. [Google Scholar]
- Huang, Y.; Du, J.; Yang, Z.; Zhou, Z.; Zhang, L.; Chen, H. A survey on trajectory-prediction methods for autonomous driving. IEEE Trans. Intell. Veh. 2022, 7, 652–674. [Google Scholar] [CrossRef]
- Ridel, D.; Rehder, E.; Lauer, M.; Stiller, C.; Wolf, D. A literature review on the prediction of pedestrian behavior in urban scenarios. In Proceedings of the International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3105–3112. [Google Scholar]
- Rudenko, A.; Palmieri, L.; Herman, M.; Kitani, K.M.; Gavrila, D.M.; Arras, K.O. Human motion trajectory prediction: A survey. Int. J. Robot. Res. 2020, 39, 895–935. [Google Scholar] [CrossRef]
- Graves, A. Generating Sequences with Recurrent Neural Networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision. In Proceedings of the Computer Vision Conference (CVC), Online, 14–19 June 2020; pp. 128–144. [Google Scholar]
- Trenn, S. Multilayer Perceptrons: Approximation Order and Necessary Number of Hidden Units. IEEE Trans. Neural Netw. 2008, 19, 836–844. [Google Scholar] [CrossRef]
- Sun, Q.; Huang, X.; Gu, J.; Williams, B.C.; Zhao, H. M2I: From Factored Marginal Trajectory Prediction to Interactive Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6543–6552. [Google Scholar]
- Chen, Y.; Ivanovic, B.; Pavone, M. Scept: Scene-consistent, policy-based trajectory predictions for planning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17103–17112. [Google Scholar]
- Ngiam, J.; Caine, B.; Vasudevan, V.; Zhang, Z.; Chiang, H.T.L.; Ling, J.; Roelofs, R.; Bewley, A.; Liu, C.; Venugopal, A.; et al. Scene transformer: A unified architecture for predicting future trajectories of multiple agents. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 25–29 April 2022. [Google Scholar]
- Mao, W.; Xu, C.; Zhu, Q.; Chen, S.; Wang, Y. Leapfrog Diffusion Model for Stochastic Trajectory Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 5517–5526. [Google Scholar]
- Jiang, C.M.; Cornman, A.; Park, C.; Sapp, B.; Zhou, Y.; Anguelov, D. MotionDiffuser Controllable Multi-Agent Motion Prediction Using Diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 9644–9653. [Google Scholar]
- Gu, T.; Chen, G.; Li, J.; Lin, C.; Rao, Y.; Zhou, J.; Lu, J. Stochastic Trajectory Prediction via Motion Indeterminacy Diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17092–17101. [Google Scholar]
- Zhang, W.; Cheng, H.; Johora, F.T.; Sester, M. ForceFormer: Exploring Social Force and Transformer for Pedestrian Trajectory Prediction. arXiv 2023, arXiv:2302.07583. [Google Scholar]
- Wang, X.; Su, T.; Da, F.; Yang, X. ProphNet: Efficient Agent-Centric Motion Forecasting with Anchor-Informed Proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 21995–22003. [Google Scholar]
- Zhou, Z.; Wang, J.; Li, Y.H.; Huang, Y.K. Query-Centric Trajectory Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 17863–17873. [Google Scholar]
- Aydemir, G.; Akan, A.K.; Güney, F. ADAPT: Efficient Multi-Agent Trajectory Prediction with Adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 8295–8305. [Google Scholar]
- Dong, Y.; Wang, L.; Zhou, S.; Hua, G. Sparse Instance Conditioned Multimodal Trajectory Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 9763–9772. [Google Scholar]
- Chiara, L.F.; Coscia, P.; Das, S.; Calderara, S.; Cucchiara, R.; Ballan, L. Goal-Driven Self-Attentive Recurrent Networks for Trajectory Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, New Orleans, LA, USA, 18–24 June 2022; pp. 2518–2527. [Google Scholar]
- Li, D.; Zhang, Q.; Lu, S.; Pan, Y.; Zhao, D. Conditional Goal-oriented Trajectory Prediction for Interacting Vehicles with Vectorized Representation. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–13. [Google Scholar] [CrossRef]
- Mangalam, K.; An, Y.; Girase, H.; Malik, J. From Goals, Waypoints and Paths to Long Term Human Trajectory Forecasting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 15233–15242. [Google Scholar]
- Gu, J.; Sun, C.; Zhao, H. Densetnt: End-to-end trajectory prediction from dense goal sets. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 15303–15312. [Google Scholar]
- Dendorfer, P.; Osep, A.; Leal-Taixe, L. Goal-GAN: Multimodal Trajectory Prediction Based on Goal Position Estimation. In Proceedings of the Asian Conference on Computer Vision (ACCV), Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Mangalam, K.; Girase, H.; Agarwal, S.; Lee, K.H.; Adeli, E.; Malik, J.; Gaidon, A. It Is Not the Journey But the Destination Endpoint Conditioned Trajectory Prediction. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 759–776. [Google Scholar]
- Wang, Y.; Zhao, S.; Zhang, R.; Cheng, X.; Yang, L. Multi-Vehicle Collaborative Learning for Trajectory Prediction with Spatio-Temporal Tensor Fusion. IEEE Trans. Intell. Transp. Syst. 2022, 23, 236–248. [Google Scholar] [CrossRef]
- Li, Y.; Liang, R.; Wei, W.; Wang, W.; Zhou, J.; Li, X. Temporal pyramid network with spatial-temporal attention for pedestrian trajectory prediction. IEEE Trans. Netw. Sci. Eng. 2022, 9, 1006–1019. [Google Scholar] [CrossRef]
- Zhou, L.; Zhao, Y.; Yang, D.; Liu, J. GCHGAT: Pedestrian trajectory prediction using group constrained hierarchical graph attention networks. Appl. Intell. 2022, 52, 11434–11447. [Google Scholar] [CrossRef]
- Sadeghian, A.; Kosaraju, V.; Sadeghian, A.; Hirose, N.; Rezatofighi, S.H.; Savarese, S. SoPhie: An Attentive GAN for Predicting Paths Compliant to Social and Physical Constraints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1349–1358. [Google Scholar]
- Kosaraju, V.; Sadeghian, A.; Martín-Martín, R.; Reid, I.; Rezatofighi, S.H.; Savarese, S. Social-bigat: Multimodal trajectory forecasting using bicycle-gan and graph attention networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Gupta, A.; Johnson, J.; Fei-Fei, L.; Savarese, S.; Alahi, A. Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2255–2264. [Google Scholar]
- Zhu, W.; Liu, Y.; Zhang, M.; Yi, Y. Reciprocal Consistency Prediction Network for Multi-Step Human Trajectory Prediction. IEEE Trans. Intell. Transp. Syst. 2023, 24, 6042–6052. [Google Scholar] [CrossRef]
- Yang, C.; Pei, Z. Long-Short Term Spatio-Temporal Aggregation for Trajectory Prediction. IEEE Trans. Intell. Transp. Syst. 2023, 24, 4114–4126. [Google Scholar] [CrossRef]
- Zhou, H.; Ren, D.; Yang, X.; Fan, M.; Huang, H. CSR: Cascade Conditional Variational Auto Encoder with Socially-aware Regression for Pedestrian Trajectory Prediction. Pattern Recognit. 2023, 133, 109030. [Google Scholar] [CrossRef]
- Xu, Y.; Bazarjani, A.; Chi, H.-g.; Choi, C.; Fu, Y. Uncovering the Missing Pattern: Unified Framework Towards Trajectory Imputation and Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 9632–9643. [Google Scholar]
- Lee, M.; Sohn, S.S.; Moon, S.; Yoon, S.; Kapadia, M.; Pavlovic, V. MUSE-VAE: Multi-Scale VAE for Environment-Aware Long Term Trajectory Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2221–2230. [Google Scholar]
- Xie, C.; Li, Y.; Liang, R.; Dong, L.; Li, X. Synchronous Bi-Directional Pedestrian Trajectory Prediction with Error Compensation. In Proceedings of the Asian Conference on Computer Vision (ACCV), Macau, China, 4–8 December 2022; pp. 2796–2812. [Google Scholar]
- Miguel, M.A.D.; Armingol, J.M.; Garcia, F. Vehicles Trajectory Prediction Using Recurrent VAE Network. IEEE Access 2022, 10, 32742–32749. [Google Scholar] [CrossRef]
- Su, Z.; Huang, G.; Zhang, S.; Hua, W. Crossmodal Transformer Based Generative Framework for Pedestrian Trajectory Prediction. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 2337–2343. [Google Scholar]
- Halawa, M.; Hellwich, O.; Bideau, P. Action-based Contrastive Learning for Trajectory Prediction. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 143–159. [Google Scholar]
- Choi, D.; Min, K. Hierarchical Latent Structure for Multi-modal Vehicle Trajectory Forecasting. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 129–145. [Google Scholar]
- Yao, Y.; Atkins, E.; Johnson-Roberson, M.; Vasudevan, R.; Du, X. BiTraP: Bi-Directional Pedestrian Trajectory Prediction with Multi-Modal Goal Estimation. IEEE Robot. Autom. Lett. 2021, 6, 1463–1470. [Google Scholar] [CrossRef]
- Yuan, Y.; Weng, X.; Kitani, K.M. Agentformer: Agent-aware transformers for socio-temporal multi-agent forecasting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 9813–9823. [Google Scholar]
- Weng, X.; Wang, J.; Levine, S.; Kitani, K.; Rhinehart, N. Inverting the Pose Forecasting Pipeline with SPF2: Sequential Pointcloud Forecasting for Sequential Pose Forecasting. In Proceedings of the Proceedings of Machine Learning Research, PMLR, 10, Virtual, 8–10 September 2021; pp. 11–20. [Google Scholar]
- Salzmann, T.; Ivanovic, B.; Chakravarty, P.; Pavone, M. Trajectron++: Dynamically-Feasible Trajectory Forecasting with Heterogeneous Data. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer Science and Business Media Deutschland GmbH: Berlin/Heidelberg, Germany, 2020; pp. 683–700. [Google Scholar]
- Tang, L.; Yan, F.; Zou, B.; Li, W.; Lv, C.; Wang, K. Trajectory prediction for autonomous driving based on multiscale spatial-temporal graph. IET Intell. Transp. Syst. 2023, 17, 386–399. [Google Scholar] [CrossRef]
- Zhang, K.; Zhao, L.; Dong, C.; Wu, L.; Zheng, L. AI-TP: Attention-Based Interaction-Aware Trajectory Prediction for Autonomous Driving. IEEE Trans. Intell. Veh. 2023, 8, 73–83. [Google Scholar] [CrossRef]
- Kamenev, A.; Wang, L.; Bohan, O.B.; Kulkarni, I.; Kartal, B.; Molchanov, A.; Birchfield, S.; Nister, D.; Smolyanskiy, N. PredictionNet: Real-Time Joint Probabilistic Traffic Prediction for Planning, Control, and Simulation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 8936–8942. [Google Scholar]
- Sheng, Z.; Xu, Y.; Xue, S.; Li, D. Graph-Based Spatial-Temporal Convolutional Network for Vehicle Trajectory Prediction in Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2022, 23, 17654–17665. [Google Scholar] [CrossRef]
- Xu, D.; Shang, X.; Liu, Y.; Peng, H.; Li, H. Group Vehicle Trajectory Prediction with Global Spatio-Temporal Graph. IEEE Trans. Intell. Veh. 2022, 8, 1219–1229. [Google Scholar] [CrossRef]
- Mo, X.; Huang, Z.; Xing, Y.; Lv, C. Multi-agent trajectory prediction with heterogeneous edge-enhanced graph attention network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 9554–9567. [Google Scholar] [CrossRef]
- Zhang, W.; Chai, Q.; Zhang, Q.; Wu, C. Obstacle-transformer: A trajectory prediction network based on surrounding trajectories. IET Cyber-Syst. Robot. 2023, 5, e12066. [Google Scholar] [CrossRef]
- Liu, D.; Li, Q.; Li, S.; Kong, J.; Qi, M. Non-Autoregressive Sparse Transformer Networks for Pedestrian Trajectory Prediction. Appl. Sci. 2023, 13, 3296. [Google Scholar] [CrossRef]
- Wang, Z.; Guo, J.; Hu, Z.; Zhang, H.; Zhang, J.; Pu, J. Lane Transformer: A High-Efficiency Trajectory Prediction Model. IEEE Open J. Intell. Transp. Syst. 2023, 4, 2–13. [Google Scholar] [CrossRef]
- Chen, H.; Liu, Y.; Hu, C.; Zhang, X. Vulnerable Road User Trajectory Prediction for Autonomous Driving Using a Data-Driven Integrated Approach. IEEE Trans. Intell. Transp. Syst. 2023, 24, 7306–7317. [Google Scholar] [CrossRef]
- Nayakanti, N.; Al-Rfou, R.; Zhou, A.; Goel, K.; Refaat, K.S.; Sapp, B. Wayformer Motion Forecasting via Simple & Efficient Attention Networks. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 2980–2987. [Google Scholar]
- Gu, J.; Hu, C.; Zhang, T.; Chen, X.; Wang, Y.; Wang, Y.; Zhao, H.; University, T.; Zhi, S.Q. ViP3D: End-to-End Visual Trajectory Prediction via 3D Agent Queries. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 5496–5506. [Google Scholar]
- Choi, S.; Kim, J.; Yun, J.; Choi, J.W. R-Pred: Two-Stage Motion Prediction Via Tube-Query Attention-Based Trajectory Refinement. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 8525–8535. [Google Scholar]
- Zhu, Y.; Luan, D.; Shen, S. BiFF: Bi-level Future Fusion with Polyline-based Coordinate for Interactive Trajectory Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 8260–8271. [Google Scholar]
- Shi, L.; Wang, L.; Zhou, S.; Hua, G. Trajectory Unified Transformer for Pedestrian Trajectory Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 9675–9684. [Google Scholar]
- Duan, J.; Wang, L.; Long, C.; Zhou, S.; Zheng, F.; Shi, L.; Huan, G. Complementary Attention Gated Network for Pedestrian Trajectory Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 28 February–1 March 2022; pp. 542–550. [Google Scholar]
- Wang, J.; Ye, T.; Gu, Z.; Chen, J. LTP: Lane-based Trajectory Prediction for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17134–17142. [Google Scholar]
- Huang, Z.; Mo, X.; Lv, C. Multi-modal Motion Prediction with Transformer-based Neural Network for Autonomous Driving. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 2605–2611. [Google Scholar]
- Schmidt, J.; Jordan, J.; Gritschneder, F.; Dietmayer, K. CRAT-Pred: Vehicle Trajectory Prediction with Crystal Graph Convolutional Neural Networks and Multi-Head Self-Attention. In Proceedings of the International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 7799–7805. [Google Scholar]
- Tsao, L.W.; Wang, Y.K.; Lin, H.S.; Shuai, H.H.; Wong, L.K.; Cheng, W.H. Social-SSL: Self-supervised Cross-Sequence Representation Learning Based on Transformers for Multi-agent Trajectory Prediction. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 234–250. [Google Scholar]
- Li, L.; Pagnucco, M.; Song, Y. Graph-based spatial transformer with memory replay for multi-future pedestrian trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2231–2241. [Google Scholar]
- Zhou, Z.; Ye, L.; Wang, J.; Wu, K.; Lu, K. HiVT: Hierarchical Vector Transformer for Multi-Agent Motion Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8823–8833. [Google Scholar]
- Chen, X.; Zhang, H.; Zhao, F.; Cai, Y.; Wang, H.; Ye, Q. Vehicle Trajectory Prediction Based on Intention-Aware Non-Autoregressive Transformer with Multi-Attention Learning for Internet of Vehicles. IEEE Trans. Instrum. Meas. 2022, 71, 2513912. [Google Scholar] [CrossRef]
- Shi, S.; Jiang, L.; Dai, D.; Schiele, B. MTR-A: 1st Place Solution for 2022 Waymo Open Dataset Challenge–Motion Prediction. arXiv 2022, arXiv:2209.10033. [Google Scholar] [CrossRef]
- Sun, H.; Sun, F. Social-Transformer: Pedestrian Trajectory Prediction in Autonomous Driving Scenes. In Proceedings of the International Conference on Cognitive Systems and Signal Processing (ICCSIP), Suzhou, China, 20–21 November 2021; Springer Science and Business Media Deutschland GmbH: Berlin/Heidelberg, Germany, 2021; pp. 177–190. [Google Scholar]
- Wang, Y.; Pan, H.; Zhu, J.; Wu, Y.H.; Zhan, X.; Jiang, K.; Yang, D. BE-STI: Spatial-Temporal Integrated Network for Class-Agnostic Motion Prediction with Bidirectional Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17093–17102. [Google Scholar]
- Zamboni, S.; Kefato, Z.T.; Girdzijauskas, S.; Noren, C.; Col, L.D. Pedestrian trajectory prediction with convolutional neural networks. Pattern Recognit. 2022, 121, 108252. [Google Scholar] [CrossRef]
- Lv, P.; Wang, W.; Wang, Y.; Zhang, Y.; Xu, M.; Xu, C. SSAGCN: Social Soft Attention Graph Convolution Network for Pedestrian Trajectory Prediction. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–15. [Google Scholar] [CrossRef]
- Lian, J.; Ren, W.; Li, L.; Zhou, Y.; Zhou, B. PTP-STGCN: Pedestrian Trajectory Prediction Based on a Spatio-temporal Graph Convolutional Neural Network. Appl. Intell. 2023, 53, 2862–2878. [Google Scholar] [CrossRef]
- Sighencea, I.B.; Stanciu, R.I.; Caleanu, D.C. D-STGCN: Dynamic Pedestrian Trajectory Prediction UsingSpatio-Temporal Graph Convolutional Networks. Electronics 2023, 12, 611. [Google Scholar] [CrossRef]
- Lu, Y.; Wang, W.; Hu, X.; Xu, P.; Zhou, S.; Cai, M. Vehicle Trajectory Prediction in Connected Environments via Heterogeneous Context-Aware Graph Convolutional Networks. IEEE Trans. Intell. Transp. Syst. 2023, 24, 8452–8464. [Google Scholar] [CrossRef]
- Shi, L.; Wang, L.; Long, C.; Zhou, S.; Zhou, M.; Niu, Z.; Hua, G. SGCN: Sparse Graph Convolution Network for Pedestrian Trajectory Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8994–9003. [Google Scholar]
- Bae, I.; Jeon, H.G. Disentangled Multi-Relational Graph Convolutional Network for Pedestrian Trajectory Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 8–9 February 2021; pp. 911–919. [Google Scholar]
- Rowe, L.; Ethier, M.; Dykhne, E.H.; Czarnecki, K. FJMP: Factorized Joint Multi-Agent Motion Prediction over Learned Directed Acyclic Interaction Graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Pourkeshavarz, M.; Chen, C.; Ark, R.N.; Lab, H.; Toronto, C. Learn TAROT with MENTOR: A Meta-Learned Self-Supervised Approach for Trajectory Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 8384–8393. [Google Scholar]
- Xu, C.; Li, M.; Ni, Z.; Zhang, Y.; Chen, S. GroupNet: Multiscale Hypergraph Neural Networks for Trajectory Prediction with Relational Reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6498–6507. [Google Scholar]
- Schmidt, J.; Huissel, P.; Wiederer, J.; Jordan, J.; Belagiannis, V.; Dietmayer, K. RESET: Revisiting Trajectory Sets for Conditional Behavior Prediction. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Anchorage, AK, USA, 4–7 June 2023. [Google Scholar]
- Phan-Minh, T.; Grigore, E.C.; Boulton, F.A.; Beijbom, O.; Wolff, E.M. CoverNet: Multimodal Behavior Prediction using Trajectory Sets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14074–14083. [Google Scholar]
- Song, H.; Luan, D.; Ding, W.; Wang, M.Y.; Chen, Q. Learning to Predict Vehicle Trajectories with Model-based Planning. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022; pp. 1035–1045. [Google Scholar]
- Bhatt, N.P.; Khajepour, A.; Hashemi, E. MPC-PF: Socially and Spatially Aware Object Trajectory Prediction for Autonomous Driving Systems Using Potential Fields. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5351–6361. [Google Scholar] [CrossRef]
- Li, R.; Shi, H.; Fu, Z.; Wang, Z.; Lin, G. Weakly Supervised Class-Agnostic Motion Prediction for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 17599–17608. [Google Scholar]
- Chen, H.; Wang, J.; Shao, K.; Liu, F.; Hao, J.; Guan, C.; Chen, G.; Heng, P.A. Traj-MAE: Masked Autoencoders for Trajectory Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 8351–8362. [Google Scholar]
- Maeda, T.; Ukita, N. Fast Inference and Update of Probabilistic Density Estimation on Trajectory Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 9795–9805. [Google Scholar]
- Wang, J.; Li, X.; Sullivan, A.; Abbott, L.; Chen, S. PointMotionNet: Point-Wise Motion Learning for Large-Scale LiDAR Point Clouds Sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4419–4428. [Google Scholar]
- Guo, K.; Liu, W.; Pan, J. End-to-End Trajectory Distribution Prediction Based on Occupancy Grid Maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2242–2251. [Google Scholar]
- Zernetsch, S.; Reichert, H.; Kress, V.; Doll, K.; Sick, B. A Holistic View on Probabilistic Trajectory Forecasting—Case Study. Cyclist Intention Detection. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 4–9 June 2022; pp. 265–272. [Google Scholar]
- Monti, A.; Porrello, A.; Calderara, S.; Coscia, P.; Ballan, L.; Cucchiara, R. How Many Observations Are Enough? Knowledge Distillation for Trajectory Forecasting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6553–6562. [Google Scholar]
- Peri, N.; Luiten, J.; Li, M.; Ošep, A.; Leal-Taixé, L.; Ramanan, D. Forecasting From LiDAR via Future Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17202–17211. [Google Scholar]
- Agarwal, A.; Lalit, M.; Bansal, A.; Seeja, K. iSGAN: An Improved SGAN for Crowd Trajectory Prediction from Surveillance Videos. Procedia Comput. Sci. 2023, 218, 2319–2327. [Google Scholar] [CrossRef]
- Casas, S.; Sadat, A.; Urtasun, R. MP3: A Unified Model To Map, Perceive, Predict and Plan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14403–14412. [Google Scholar]
- Chen, H.; Liu, Y.; Zhao, B.; Hu, C.; Zhang, X. Vision-based Real-time Online Vulnerable Traffic Participants Trajectory Prediction for Autonomous Vehicle. IEEE Trans. Intell. Veh. 2023, 8, 2110–2122. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, H.; Zhao, F.; Hu, Y.; Tan, C.; Yang, J. Intention-Aware Vehicle Trajectory Prediction Based on Spatial-Temporal Dynamic Attention Network for Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19471–19483. [Google Scholar] [CrossRef]
- Huynh, M.; Alaghband, G. Online Adaptive Temporal Memory with Certainty Estimation for Human Trajectory Prediction. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 940–949. [Google Scholar]
- Kress, V.; Jeske, F.; Zernetsch, S.; Doll, K.; Sick, B. Pose and Semantic Map Based Probabilistic Forecast of Vulnerable Road Users Trajectories. IEEE Trans. Intell. Veh. 2022, 8, 2592–2603. [Google Scholar] [CrossRef]
- Lerner, A.; Chrysanthou, Y.; Lischinski, D. Crowds by Example. Comput. Graph. Forum 2007, 26, 655–664. [Google Scholar] [CrossRef]
- Pellegrini, S.; Ess, A.; Schindler, K.; Van Gool, L. You’ll Never Walk Alone: Modeling Social Behavior for Multi-target Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 261–268. [Google Scholar]
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning Social Etiquette: Human Trajectory Prediction in Crowded Scenes. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Wu, C.; Chen, Y.; Luo, J.; Su, C.C.; Dawane, A.; Hanzra, B.; Deng, Z.; Liu, B.; Wang, J.Z.; Kuo, C.-h. MEBOW: Monocular Estimation of Body Orientation in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3451–3461. [Google Scholar]
- Gao, J.; Sun, C.; Zhao, H.; Shen, Y.; Anguelov, D.; Li, C.; Schmid, C. VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11525–11533. [Google Scholar]
- Schmidt, J.; Jordan, J.; Gritschneder, F.; Monninger, T.; Dietmayer, K. Exploring Navigation Maps for Learning-Based Motion Prediction. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023. [Google Scholar]
- Liang, M.; Yang, B.; Hu, R.; Chen, Y.; Liao, R.; Feng, S.; Urtasun, R. Learning Lane Graph Representations for Motion Forecasting. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 541–556. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Bae, I.; Park, J.H.; Jeon, H.G. Non-Probability Sampling Network for Stochastic Human Trajectory Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6477–6487. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Croitoru, F.A.; Hondru, V.; Ionescu, R.T.; Shah, M. Diffusion Models in Vision: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10850–10869. [Google Scholar] [CrossRef]
- Liu, H.; Dai, Z.; So, D.; Le, Q.V. Pay Attention to MLPs. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, 6–14 December 2021; pp. 9204–9215. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Han, Y.; Huang, G.; Song, S.; Yang, L.; Wang, H.; Wang, Y. Dynamic Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2021, 44, 7436–7456. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph attention networks. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Weng, X.; Yuan, Y.; Kitani, K. PTP: Parallelized Tracking and Prediction with Graph Neural Networks and Diversity Sampling. IEEE Robot. Autom. Lett. 2021, 6, 4640–4647. [Google Scholar] [CrossRef]
- Makansi, O.; Cicek, Ö.; Marrakchi, Y.; Brox, T. On Exposing the Challenging Long Tail in Future Prediction of Traffic Actors. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 13147–13157. [Google Scholar]
- Liu, Y.; Yan, Q.; Alahi, A. Social NCE: Contrastive Learning of Socially-Aware Motion Representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 15118–15129. [Google Scholar]
- Wang, Y.; Guizilini, V.C.; Zhang, T.; Wang, Y.; Zhao, H.; Solomon, J. DETR3D: 3D Object Detection from Multi-View Images via 3D-to-2D Queries. In Proceedings of the Conference on Robot Learning, PMLR, Auckland, New Zealand, 14–18 December 2022; pp. 180–191. [Google Scholar]
- Liu, R.; Lehman, J.; Molino, P.; Petroski Such, F.; Frank, E.; Sergeev, A.; Yosinski, J. An intriguing failing of convolutional neural networks and the coordconv solution. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Thost, V.; Chen, J. Directed Acyclic Graph Neural Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar]
- Hu, Z.; Dong, Y.; Wang, K.; Sun, Y. Heterogeneous Graph Transformer. In Proceedings of the Web Conference, Taipei, Taiwan, 20–24 April 2020; pp. 2704–2710. [Google Scholar]
- Werling, M.; Ziegler, J.; Kammel, S.; Thrun, S. Optimal Trajectory Generation for Dynamic Street Scenarios in a Frenet Frame. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 3–7 May 2010; pp. 987–993. [Google Scholar]
- Jang, E.; Gu, S.; Poole, B. Categorical Reparameterization with Gumbel-Softmax. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Girgis, R.; Golemo, F.; Codevilla, F.; Weiss, M.; D’Souza, J.A.; Kahou, S.E.; Heide, F.; Pal, C. Latent Variable Sequential Set Transformers for Joint Multi-Agent Motion Prediction. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 25–29 April 2022. [Google Scholar]
- Wong, C.; Xia, B.; Hong, Z.; Peng, Q.; Yuan, W.; Cao, Q.; Yang, Y.; You, X. View Vertically: A Hierarchical Network for Trajectory Prediction via Fourier Spectrums. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 682–700. [Google Scholar]
- Ettinger, S.; Cheng, S.; Caine, B.; Liu, C.; Zhao, H.; Pradhan, S.; Chai, Y.; Sapp, B.; Qi, C.R.; Zhou, Y.; et al. Large Scale Interactive Motion Forecasting for Autonomous Driving: The Waymo Open Motion Dataset. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 9710–9719. [Google Scholar]
- Bock, J.; Krajewski, R.; Moers, T.; Runde, S.; Vater, L.; Eckstein, L. The inD Dataset: A Drone Dataset of Naturalistic Road User Trajectories at German Intersections. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1929–1934. [Google Scholar]
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3D Tracking and Forecasting with Rich Maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8748–8757. [Google Scholar]
- Wilson, B.; Qi, W.; Agarwal, T.; Lambert, J.; Singh, J.; Khandelwal, S.; Pan, B.; Kumar, R.; Hartnett, A.; Pontes, J.K.; et al. Argoverse 2: Next Generation Datasets for Self-driving Perception and Forecasting. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Benchmarks 2021), Virtual, 6–14 December 2021. [Google Scholar]
- Colyar, J.; Halkias, J. Interstate 80 Freeway Dataset. Online, 2006. U.S. Department of Transportation, Federal Highway Administration. Available online: https://www.fhwa.dot.gov/publications/research/operations/06137/index.cfm (accessed on 17 October 2023).
- Colyar, J.; Halkias, J. U.S. Highway 101 Dataset. Online, 2007. U.S. Department of Transportation, Federal Highway Administration. Available online: https://www.fhwa.dot.gov/publications/research/operations/07030/ (accessed on 18 October 2023).
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The Kitti Vision Benchmark Suite. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. (IJRR) 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Krajewski, R.; Bock, J.; Kloeker, L.; Eckstein, L. The highD Dataset: A Drone Dataset of Naturalistic Vehicle Trajectories on German Highways for Validation of Highly Automated Driving Systems. In Proceedings of the International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2118–2125. [Google Scholar]
- Liang, J.; Jiang, L.; Murphy, K.; Yu, T.; Hauptmann, A. The garden of forking paths: Towards multi-future trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10508–10518. [Google Scholar]
- Awad, G.; Butt, A.A.; Curtis, K.; Lee, Y.; Fiscus, J.; Godil, A.; Joy, D.; Delgado, A.; Smeaton, A.F.; Graham, Y.; et al. TRECVID 2018: Benchmarking Video Activity Detection, Video Captioning and Matching, Video Storytelling Linking and Video Search. In Proceedings of the TREC Video Retrieval Evaluation (TRECVID), Gaithersburg, MD, USA, 13–15 November 2018. [Google Scholar]
- Oh, S.; Hoogs, A.; Perera, A.; Cuntoor, N.; Chen, C.C.; Lee, J.T.; Mukherjee, S.; Aggarwal, J.; Lee, H.; Davis, L.; et al. A Large-scale Benchmark Dataset for Event Recognition in Surveillance Video. In Proceedings of the IEEE/CVF International Conferrence on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3153–3160. [Google Scholar]
- Zhan, W.; Sun, L.; Wang, D.; Shi, H.; Clausse, A.; Naumann, M.; Kümmerle, J.; Königshof, H.; Stiller, C.; de La Fortelle, A.; et al. Interaction Dataset: An International, Adversarial and Cooperative Motion Dataset in Interactive Driving Scenarios with Semantic Maps. arXiv 2019, arXiv:1910.03088. [Google Scholar]
- Ma, Y.; Zhu, X.; Zhang, S.; Yang, R.; Wang, W.; Manocha, D. TrafficPredict: Trajectory Prediction for Heterogeneous Traffic-Agents. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 6120–6127. [Google Scholar]
- Houston, J.; Zuidhof, G.; Bergamini, L.; Ye, Y.; Chen, L.; Jain, A.; Omari, S.; Iglovikov, V.; Ondruska, P. One Thousand and One Hours: Self-driving Motion Prediction Dataset. In Proceedings of the Conference on Robot Learning (CoRL), London, UK, 8–11 November 2021; pp. 409–418. [Google Scholar]
- Rasouli, A.; Kotseruba, I.; Tsotsos, J.K. Are They Going to Cross? A Benchmark Dataset and Baseline for Pedestrian Crosswalk Behavior. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 206–213. [Google Scholar]
- Rasouli, A.; Kotseruba, I.; Kunic, T.; Tsotsos, J.K. PIE: A Large-Scale Dataset and Models for Pedestrian Intention Estimation and Trajectory Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6262–6271. [Google Scholar]
- Katharopoulos, A.; Vyas, A.; Pappas, N.; Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. In Proceedings of the International Conference on Machine Learning (ICML), PMLR, Virtual, 13–18 July 2020; pp. 5156–5165. [Google Scholar]
- Hassani, A.; Walton, S.; Shah, N.; Abuduweili, A.; Li, J.; Shi, H. Escaping the big data paradigm with compact transformers. arXiv 2021, arXiv:2104.05704. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Goodfellow, I. Nips 2016 tutorial: Generative adversarial networks. arXiv 2016, arXiv:1701.00160. [Google Scholar]
- Lin, Y.; Li, H.; Althoff, M. Model Predictive Robustness of Signal Temporal Logic Predicates. IEEE Robot. Autom. Lett. 2023, 8, 8050–8057. [Google Scholar] [CrossRef]
- Salzmann, T.; Chiang, L.; Ryll, M.; Sadigh, D.; Parada, C.; Bewley, A. Human Scene Transformer. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023. [Google Scholar]
- Kooij, J.F.; Flohr, F.; Pool, E.A.; Gavrila, D.M. Context-Based Path Prediction for Targets with Switching Dynamics. Int. J. Comput. Vis. 2019, 127, 239–262. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Seff, A.; Cera, B.; Chen, D.; Ng, M.; Zhou, A.; Nayakanti, N.; Refaat, K.S.; Al-Rfou, R.; Sapp, B. MotionLM: Multi-Agent Motion Forecasting as Language Modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 8579–8590. [Google Scholar]
- Jiang, B.; Chen, X.; Liu, W.; Yu, J.; Yu, G.; Chen, T. MotionGPT: Human Motion as a Foreign Language. arXiv 2023, arXiv:2306.14795. [Google Scholar]









| Diffusion | Anchor | GAN | CVAE | RNN | Transformer | CNN | TCN | Graph | Set | Other |
|---|---|---|---|---|---|---|---|---|---|---|
| [18,19,20] | [21,22,23,24,25,26,27,28,29,30,31] | [32,33,34,35,36,37] | [16,38,39,40,41,42,43,44,45,46,47,48,49,50,51] | [52,53,54,55,56,57] | [17,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76] | [77,78] | [79,80,81,82,83,84] | [85,86,87] | [88,89,90] | [15,91,92,93,94,95,96,97,98,99] |
| Dataset | Year | Setting | Agent Type | Data | Sensors | Duration |
|---|---|---|---|---|---|---|
| ETH/UCY [106,107] | 2007/2009 | pedestrian zone, hotel lobby (Switzerland, Cyprus) | pedestrians | trajectories at 2.5 Hz | camera (surveillance) | 5 scenes |
| SDD 1 [108] | 2016 | university campus area | pedestrians, cyclists, cars, skateboarders, carts, buses | trajectories at 25 Hz | camera (drone) | 8 locations with 10,300 trajectories |
| inD 2 [136] | 2020 | urban intersections (Germany) | pedestrians, cyclists, cars, trucks, buses | trajectories at 25 Hz | camera (drone) | 10 h at 4 intersections with 13,599 trajectories |
| WOMD 3 [135] | 2021 | urban (USA) | pedestrians, cyclists, vehicles | trajectories at 10 Hz with bounding box and velocity, HD map | camera, LiDAR (vehicle) | 100,000 scenes of 20 s |
| Argoverse 1 [137] | 2019 | urban (USA) | vehicles | trajectories at 10 Hz, HD map | camera, LiDAR (vehicle) | 333,441 sequences of 5 s |
| Argoverse 2 [138] | 2021 | urban (USA) | pedestrians, cyclists, vehicles, busses, motorcyclists | trajectories at 10 Hz, HD map | camera, LiDAR (vehicle) | 324,000 sequences of 5 s |
| NGSIM 4 [139,140] | 2006/2007 | highway (USA) | vehicles | trajectories | camera (surveillance) | 45 min (US 101), 45 min (I-80) |
| nuScenes [141] | 2020 | urban (USA, Singapore) | pedestrians, cyclists, vehicles | trajectories, HD map | camera, LiDAR, radar (vehicle) | 1000 scenes of 20 s |
| KITTI [142,143] | 2012 | urban, highway (Germany) | pedestrians, cyclists, vehicles | images, point clouds | camera, LiDAR (vehicle) | 6 h |
| highD [144] | 2018 | highway (Germany) | vehicles | trajectories | camera (drone) | 16.5 h at 6 locations with 110,000 trajectories |
| Forking Paths [145] | 2020 | urban, pedestrian zones | pedestrians, vehicles | trajectories (multifuture) | simulation | 750 sequences of 15 s |
| VIRAT/ActEV [146,147] | 2018 | urban, pedestrian zones | pedestrians, vehicles | trajectories | camera (surveillance) | more than 29 h |
| Interaction [148] | 2019 | urban, highway (USA, China, Germany, Bulgaria) | pedestrians, vehicles | trajectories, HD map | camera (drone, surveillance) | 16.5 h |
| Apolloscape [149] | 2019 | urban (China) | pedestrians, cyclists, vehicles | trajectories, HD map | camera, LiDAR, radar (vehicle) | 1000 km trajectories |
| Lyft [150] | 2021 | urban (USA) | pedestrians, cyclists, vehicles | trajectories, HD map | camera, LiDAR (vehicle) | 1000 h |
| JAAD [151] | 2017 | urban (USA, Europe) | pedestrians | trajectories (annotations in images) | camera (vehicle) | 82,000 frames with 2200 pedestrian samples |
| PIE [152] | 2019 | urban (Canada) | pedestrians | trajectories (annotations in images) | camera (vehicle) | 6 h |
| Method | Method Class | Year | ||
|---|---|---|---|---|
| LED [18] | Diffusion | 2023 | 0.21 | 0.33 |
| MID [20] | Diffusion | 2022 | 0.21 | 0.38 |
| ForceFormer [21] | Anchor | 2023 | 0.19 | 0.30 |
| SICNet [25] | Anchor | 2023 | 0.19 | 0.33 |
| Goal-SAR [26] | Anchor | 2022 | 0.19 | 0.29 |
| Y-Net [28] | Anchor | 2021 | 0.18 | 0.27 |
| Goal-GAN [30] | Anchor | 2020 | 0.43 | 0.85 |
| PECNet [31] | Anchor | 2020 | 0.29 | 0.48 |
| TPNSTA [33] | GAN | 2022 | 0.37 | 0.71 |
| GCHGAT [34] | GAN | 2022 | 0.44 | 0.86 |
| SocialBiGAT [36] | GAN | 2019 | 0.48 | 1.00 |
| SoPhie [35] | GAN | 2019 | 0.54 | 1.15 |
| SocialGAN [37] | GAN | 2018 | 0.39 | 0.58 |
| RCPNet [38] | CVAE | 2023 | 0.33 | 0.58 |
| LSSTA [39] | CVAE | 2023 | 0.21 | 0.40 |
| CSR [40] | CVAE | 2023 | 0.14 | 0.23 |
| SBD [43] | CVAE | 2022 | 0.16 | 0.29 |
| ScePT [16] | CVAE | 2022 | 0.12 | 0.73 |
| AgentFormer [49] | CVAE | 2021 | 0.18 | 0.29 |
| BiTraP [48] | CVAE | 2021 | 0.18 | 0.35 |
| Trajectron++ [51] | CVAE | 2020 | 0.21 | 0.41 |
| Obstacle-Transformer [58] | Transformer | 2023 | 0.42 | 1.27 |
| NaST [59] | Transformer | 2023 | 0.24 | 0.50 |
| VRU-Traj-Pred [61] | Transformer | 2023 | 0.32 | 0.75 |
| TUTR [66] | Transformer | 2023 | 0.21 | 0.36 |
| Social-Transformer [76] | Transformer | 2022 | 0.51 | 0.53 |
| Social-SSL [71] | Transformer | 2022 | 0.44 | 0.85 |
| CAGN [67] | Transformer | 2022 | 0.25 | 0.43 |
| Ped-CNN [78] | CNN | 2022 | 0.44 | 0.91 |
| SSAGCN [79] | TCN | 2023 | 0.13 | 0.24 |
| PTP-STGCN [80] | TCN | 2023 | 0.42 | 0.68 |
| D-STGCN [81] | TCN | 2023 | 0.42 | 0.68 |
| SGCN [83] | TCN | 2021 | 0.37 | 0.65 |
| DMRGCN [84] | TCN | 2021 | 0.34 | 0.58 |
| GroupNet [87] | Graph | 2022 | 0.19 | 0.38 |
| FlowChain [94] | Other | 2023 | 0.29 | 0.52 |
| Observations [98] | Other | 2022 | 0.43 | 0.88 |
| V2-Net [134] | Other | 2022 | 0.18 | 0.28 |
| Method | Method Class | Year | ||
|---|---|---|---|---|
| LED [18] | Diffusion | 2023 | 8.48 | 11.66 |
| MID [20] | Diffusion | 2022 | 7.61 | 14.30 |
| SICNet [25] | Anchor | 2023 | 8.44 | 13.65 |
| Goal-SAR [26] | Anchor | 2022 | 7.75 | 11.83 |
| Y-Net [28] | Anchor | 2021 | 7.85 | 11.85 |
| Goal-GAN [30] | Anchor | 2020 | 12.20 | 22.10 |
| PECNet [31] | Anchor | 2020 | 9.96 | 15.88 |
| SoPhie [35] | GAN | 2019 | 16.27 | 29.38 |
| RCPNet [38] | CVAE | 2023 | 8.18 | 13.83 |
| CSR [40] | CVAE | 2023 | 4.87 | 6.32 |
| SBD [43] | CVAE | 2022 | 7.78 | 11.97 |
| Muse-VAE [42] | CVAE | 2022 | 6.36 | 11.10 |
| TUTR [66] | Transformer | 2023 | 7.76 | 12.69 |
| Social-SSL [71] | Transformer | 2022 | 6.63 | 12.23 |
| SSAGCN [79] | TCN | 2023 | 10.36 | 11.80 |
| D-STGCN [81] | TCN | 2023 | 15.18 | 25.50 |
| GroupNet [87] | Graph | 2022 | 9.65 | 15.34 |
| FlowChain [94] | Other | 2023 | 9.93 | 17.17 |
| End-to-End [96] | Other | 2022 | 8.60 | 13.90 |
| V2-Net [134] | Other | 2022 | 7.12 | 11.39 |
| Method | Method Class | Year | ||
|---|---|---|---|---|
| Goal-SAR [26] | Anchor | 2022 | 0.31 1 | 0.54 1 |
| End-to-End [96] | Other | 2022 | 13.09 2 | 19.39 2 |
| Method | Method Class | Year | |||||
|---|---|---|---|---|---|---|---|
| MotionDiffuser 4 [19] | Diffusion | 2023 | 0.86 | 1.95 | 0.43 | - | 0.20 |
| CGTP [27] | Anchor | 2022 | 2.371 | 5.395 | 0.559 | 0.169 | 0.180 |
| DenseTNT [29] | Anchor | 2021 | 1.039 | 1.551 | 0.178 | - | 0.3281 |
| MTR-A 1 [75] | Transformer | 2022 | 0.564 | 1.134 | 0.116 | - | 0.449 |
| Scene Transformer 2 [17] | Transformer | 2022 | 1.17/0.60/1.17 | 2.48/1.25/2.43 | 0.19/0.12/0.22 | - | 0.27/0.23/0.20 |
| Wayformer [62] | Transformer | 2023 | 0.545 | 1.128 | 0.123 | 0.127 | 0.419 |
| BiFF 2 [65] | Transformer | 2023 | - | 3.71/2.73/4.29 | 0.47/0.56/0.69 | - | 0.12/0.05/0.03 |
| BE-STI 3 [77] | CNN | 2022 | 0.0244/0.2850/1.594 | - | - | - | - |
| MPC-PF [91] | Other | 2023 | 1.0102 | 1.652 | - | - | 0.3105 |
| M2I [15] | Other | 2022 | 1.46 | 2.43 | 0.12 | - | 0.41 |
| Weakly 3 [92] | Other | 2023 | 0.0219/0.3385/1.6576 | - | - | - | - |
| Method | Method Class | Year | |||
|---|---|---|---|---|---|
| ProphNet [22] | Anchor | 2023 | 0.7726 | 1.1442 | 0.1121 |
| QCNet [23] | Anchor | 2023 | 0.73 | 1.07 | 0.11 |
| ADAPT [24] | Anchor | 2023 | 0.79 | 1.17 | - |
| CGTP [27] | Anchor | 2022 | 0.753 | 1.6140 | 0.3369 |
| DenseTNT [29] | Anchor | 2021 | 0.93 | 1.45 | 0.107 |
| Hierarchical [47] | CVAE | 2022 | 0.65 | 1.24 | - |
| Wayformer [62] | Transformer | 2023 | 0.7675 | 1.1615 | 0.11186 |
| R-Pred [64] | Transformer | 2023 | 0.76 | 1.12 | 0.116 |
| Lane Transformer [60] | Transformer | 2023 | 0.86 | 1.31 | 0.15 |
| Scene Transformer [17] | Transformer | 2022 | 0.80 | 1.23 | 0.13 |
| Multimodal Transformer [69] | Transformer | 2022 | 0.8372 | 1.2905 | 0.1429 |
| CRAT [70] | Transformer | 2022 | 1.06 | 1.90 | 0.26 |
| HiVT [73] | Transformer | 2022 | 0.77 | 1.1693 | 0.1267 |
| LTP [68] | Transformer | 2022 | 0.83 | 1.29 | - |
| MENTOR [86] | Graph | 2023 | 0.79 | 1.21 | 0.1301 |
| PRIME [90] | Set | 2022 | 1.22 | 1.56 | 0.115 |
| Traj-MAE [93] | Other | 2023 | 0.81 | 1.25 | 0.137 |
| PointMotionNet [95] | Other | 2022 | - | - | - |
| Method | Method Class | Year | |||
|---|---|---|---|---|---|
| ProphNet [22] | Anchor | 2023 | 0.68 | 1.33 | 0.18 |
| QCNet [23] | Anchor | 2023 | 0.62 | 1.19 | 0.14 |
| RESET [88] | Set | 2023 | 1.26 | 2.28 | 0.3127 |
| FJMP [85] | Graph | 2023 | 0.812 | 1.963 | 0.337 |
| Method | Method Class | Year | @1 s | @2 s | @3 s | @4 s | @5 s |
|---|---|---|---|---|---|---|---|
| Collab 1 [32] | GAN | 2022 | 0.60 | 1.24 | 1.95 | 2.78 | 3.72 |
| iNATran 2 [74] | Transformer | 2022 | 0.39 | 0.96 | 1.61 | 2.42 | 3.43 |
| Multiscale 1 [52] | RNN | 2023 | 0.37 | 0.93 | 1.48 | 2.04 | 2.67 |
| AI-TP 1 [53] | RNN | 2023 | 0.47 | 1.05 | 1.53 | 1.93 | 2.31 |
| GSTCN 1 [55] | RNN | 2022 | 0.42 | 0.81 | 1.29 | 1.97 | 2.95 |
| Global 1 [56] | RNN | 2022 | 0.323 | 0.815 | 1.404 | 2.143 | 2.965 |
| HEAT 3 [57] | RNN | 2022 | 0.68 | 0.92 | 1.15 | 1.45 | 2.05 |
| Method | Method Class | Year | ||
|---|---|---|---|---|
| Muse-VAE [42] | CVAE | 2022 | 1.09 | 2.10 |
| ScePT 1,5 [16] | CVAE | 2022 | - | 0.4/0.8/1.36/2.14 |
| Hierarchical [47] | CVAE | 2022 | 1.04 | 2.15 |
| PTP 2 [123] | CVAE | 2021 | 0.378/-/1.017/- | 0.490/-/1.527/- |
| AgentFormer [49] | CVAE | 2021 | 1.31 | 2.48 |
| Trajectron++ 1 [51] | CVAE | 2020 | - | 0.07/0.45/1.14/2.20 |
| ViP3D 3,6 [63] | Transformer | 2023 | 2.03 | 2.90 |
| R-Pred [64] | Transformer | 2023 | 0.94 | 1.50 |
| BE-STI 2,4 [77] | CNN | 2022 | 0.0220/0.2115/0.7511 | - |
| CoverNet [89] | Set | 2020 | 1.48 | 9.26 4 |
| Weakly 2,4 [92] | Other | 2023 | 0.0243/0.3316/1.6422 | - |
| Method | Method Class | Year | @1 s | @2 s | @3 s | @4 s | @5 s |
|---|---|---|---|---|---|---|---|
| Recurrent VAE 1 [44] | CVAE | 2022 | 0.3/0.09 | 0.52/0.18 | 0.68/0.20 | 0.98/0.28 | 1.33/0.36 |
| Multiscale [52] | RNN | 2023 | 0.20 | 0.39 | 0.549 | 0.90 | 1.49 |
| iNATran [74] | Transformer | 2022 | 0.04 | 0.05 | 0.21 | 0.54 | 1.10 |
| Method | Method Class | Year | ||
|---|---|---|---|---|
| ADAPT 1 [24] | Anchor | 2023 | 0.16 | 0.34 |
| PredictionNet [54] | RNN | 2022 | 0.518 | 1.228 |
| HEAT [57] | RNN | 2022 | 0.19 | 0.66 |
| HCAGCN [82] | TCN | 2022 | 0.187 | 0.58 |
| FJMP 1 [85] | Graph | 2023 | 0.194 | 0.630 |
| Method | Method Class | Year | |
|---|---|---|---|
| ABC+ [46] | CVAE | 2022 | 40/89/189 |
| BiTraP [48] | CVAE | 2021 | 38/94/222 |
| Method | Method Class | Year | |
|---|---|---|---|
| ABC+ [46] | CVAE | 2022 | 16/38/187 |
| BiTraP [48] | CVAE | 2021 | 23/48/102 |
| Method | Method Class | Year | ||
|---|---|---|---|---|
| Multiscale [52] | RNN | 2023 | 1.1546 | 2.1281 |
| AI-TP [53] | RNN | 2023 | 1.1559 | 2.1324 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schuetz, E.; Flohr, F.B. A Review of Trajectory Prediction Methods for the Vulnerable Road User. Robotics 2024, 13, 1. https://doi.org/10.3390/robotics13010001
Schuetz E, Flohr FB. A Review of Trajectory Prediction Methods for the Vulnerable Road User. Robotics. 2024; 13(1):1. https://doi.org/10.3390/robotics13010001
Chicago/Turabian StyleSchuetz, Erik, and Fabian B. Flohr. 2024. "A Review of Trajectory Prediction Methods for the Vulnerable Road User" Robotics 13, no. 1: 1. https://doi.org/10.3390/robotics13010001