
Robot Learning by Demonstration with Dynamic Parameterization of the Orientation: An Application to Agricultural Activities



Abstract
:1. Introduction
2. Materials and Methods
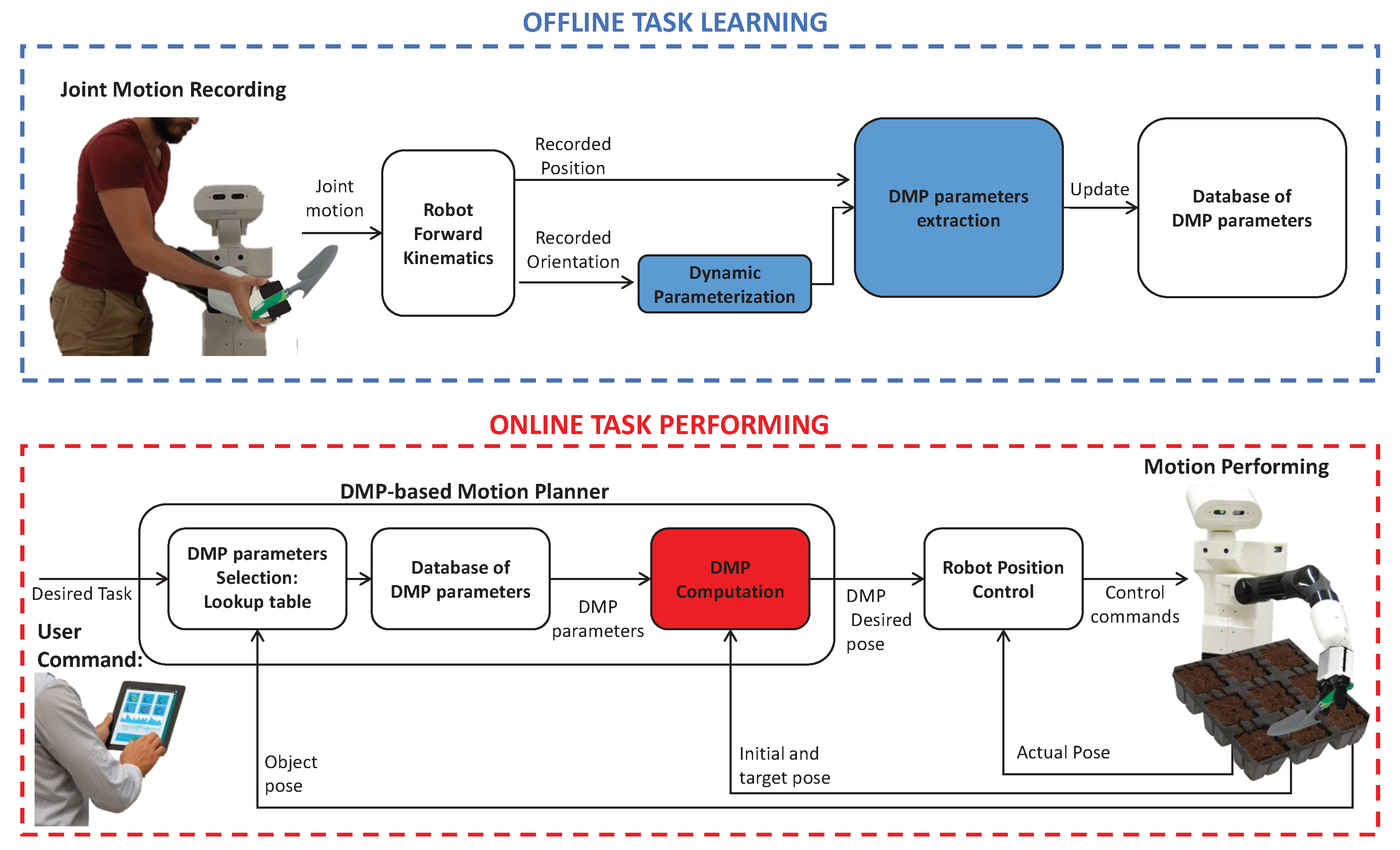
2.1. The Proposed DMP-Based Robot-Motion Planner with Dynamic Parameterization of the Orientation
2.1.1. DMP Computation for Orientation
2.1.2. DMP Parameters Extraction for Orientation
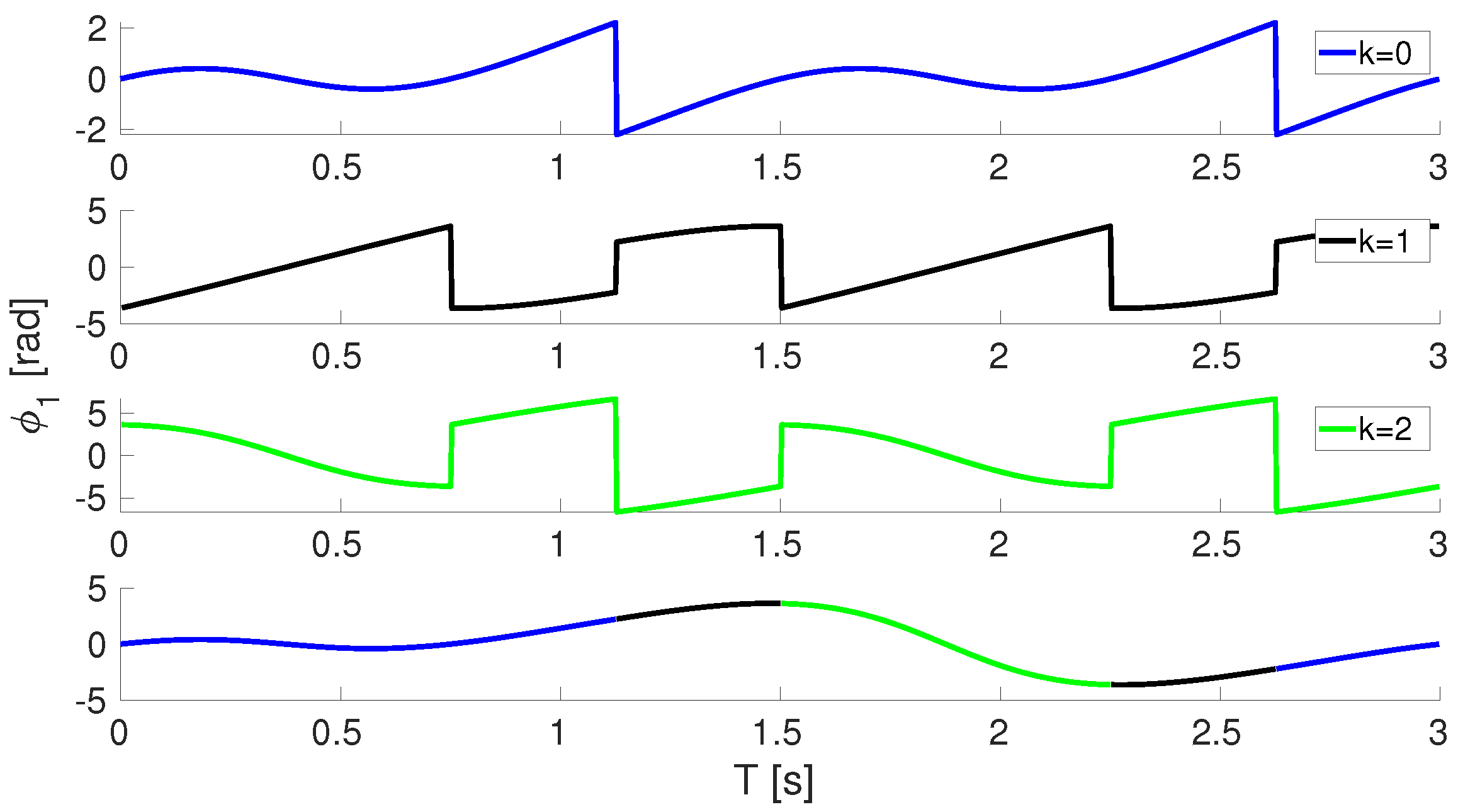
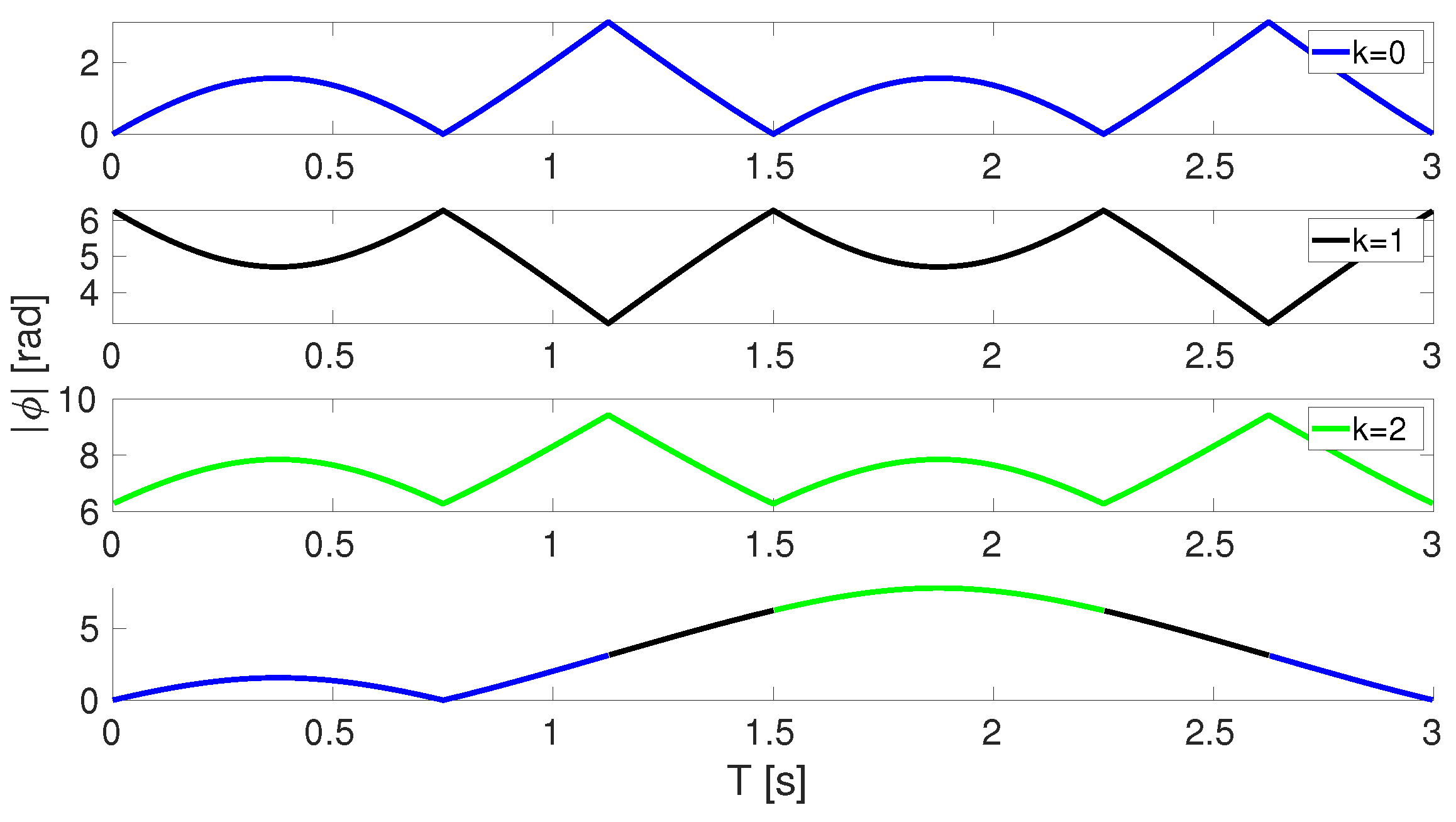
2.1.3. Dynamic Parameterization for Orientation
2.2. Application of the Proposed DMP-Based Motion Planner to Agricultural Robotics
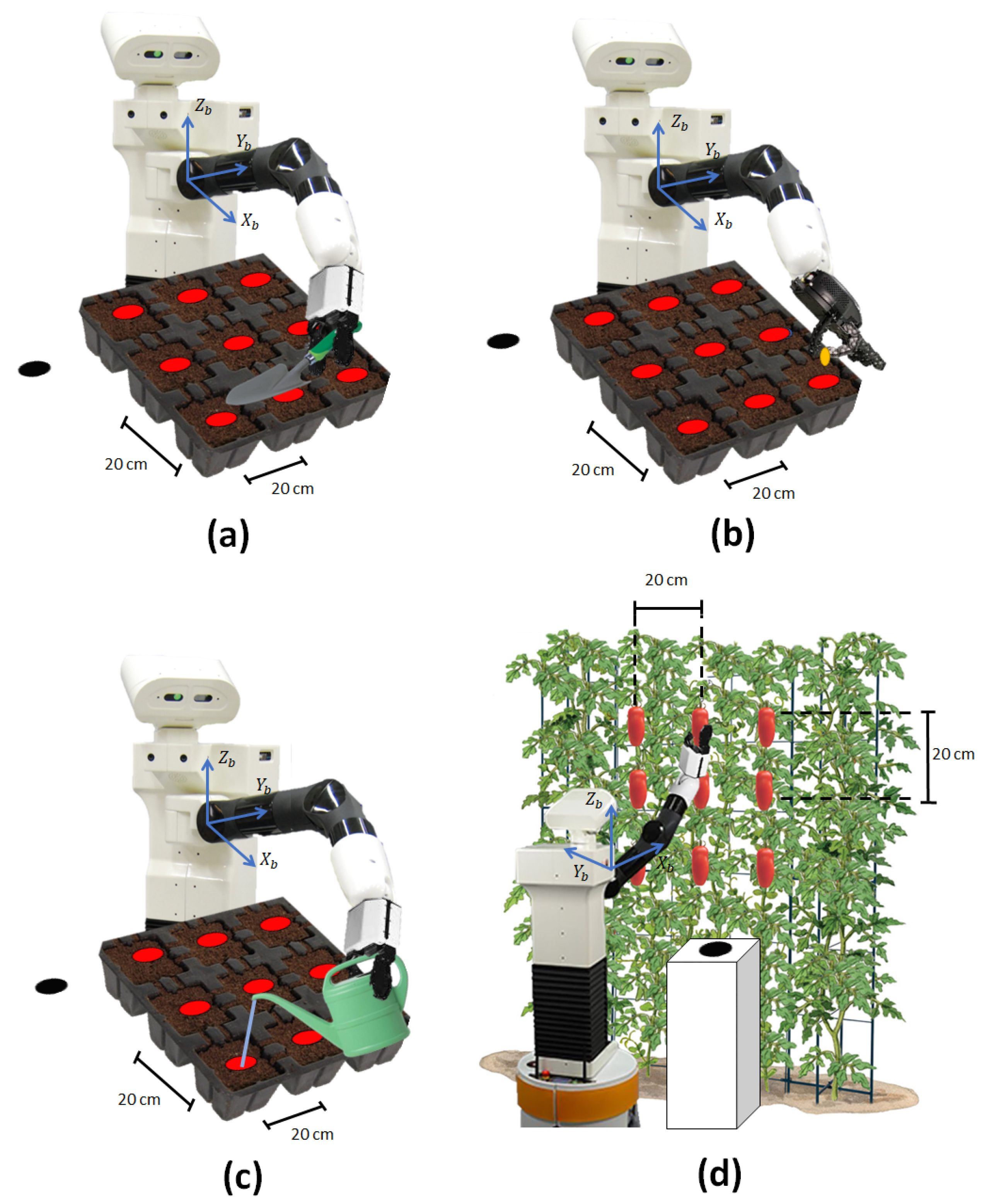
2.2.1. Experimental Robotic Platform
2.2.2. Experimental Protocol
Offline Task Learning
Online Task Performing
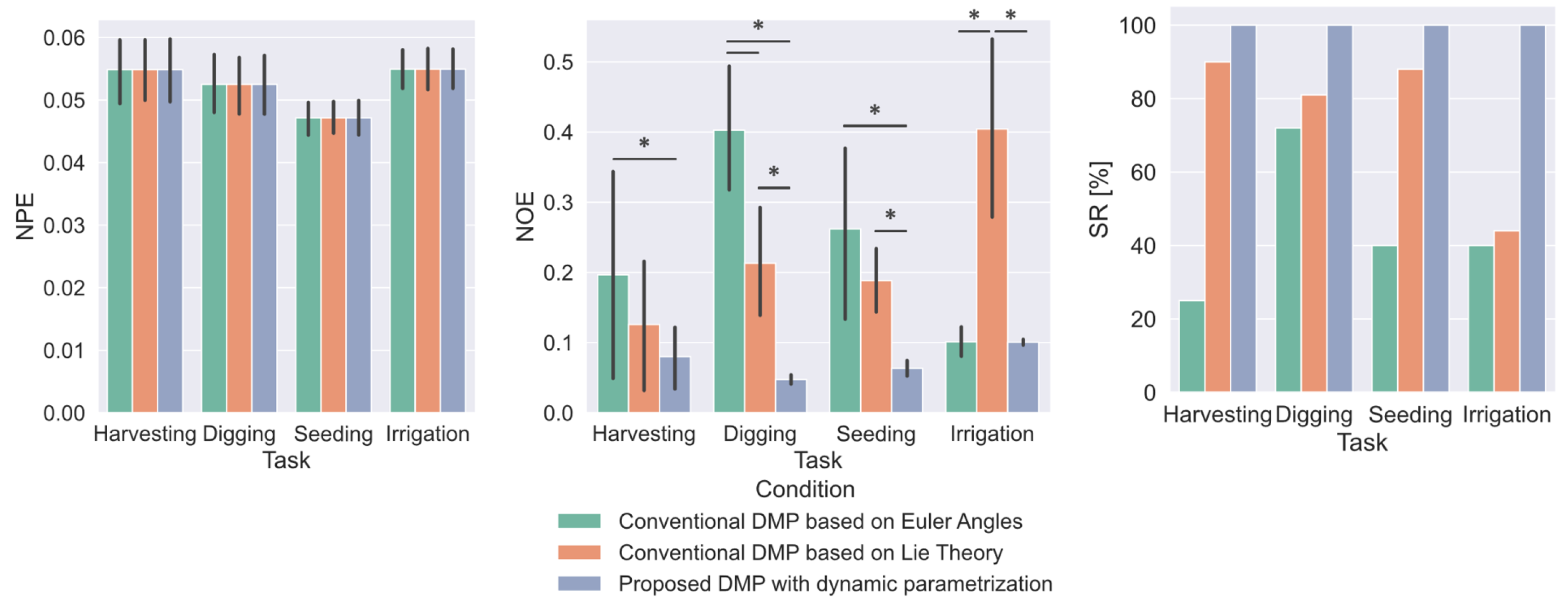
Performance Indices
- The NPE and the NOE assess the capability of the proposed approach to accurately replicate the demonstrated motions. They are normalized with respect to the overall displacement of the recorded motion and are computed as follows:where N is the number of collected samples; and are the position and orientation expressed in unit Quaternion of the computed DMP, respectively; and and are the recorded position and orientation at the i-th sample, respectively. The lower the NPE and NOE, the higher the trajectory reconstruction accuracy.
- The success rate in managing orientation discontinuity (SR-MOD) of the task execution is used to evaluate the capability of a given approach to accomplish the task and is evaluated aswhere is the number of trials successfully accomplished and is the number of all the performed trials. A task is considered successfully accomplished if no singularity or discontinuity issues occur.
Statistical Analysis
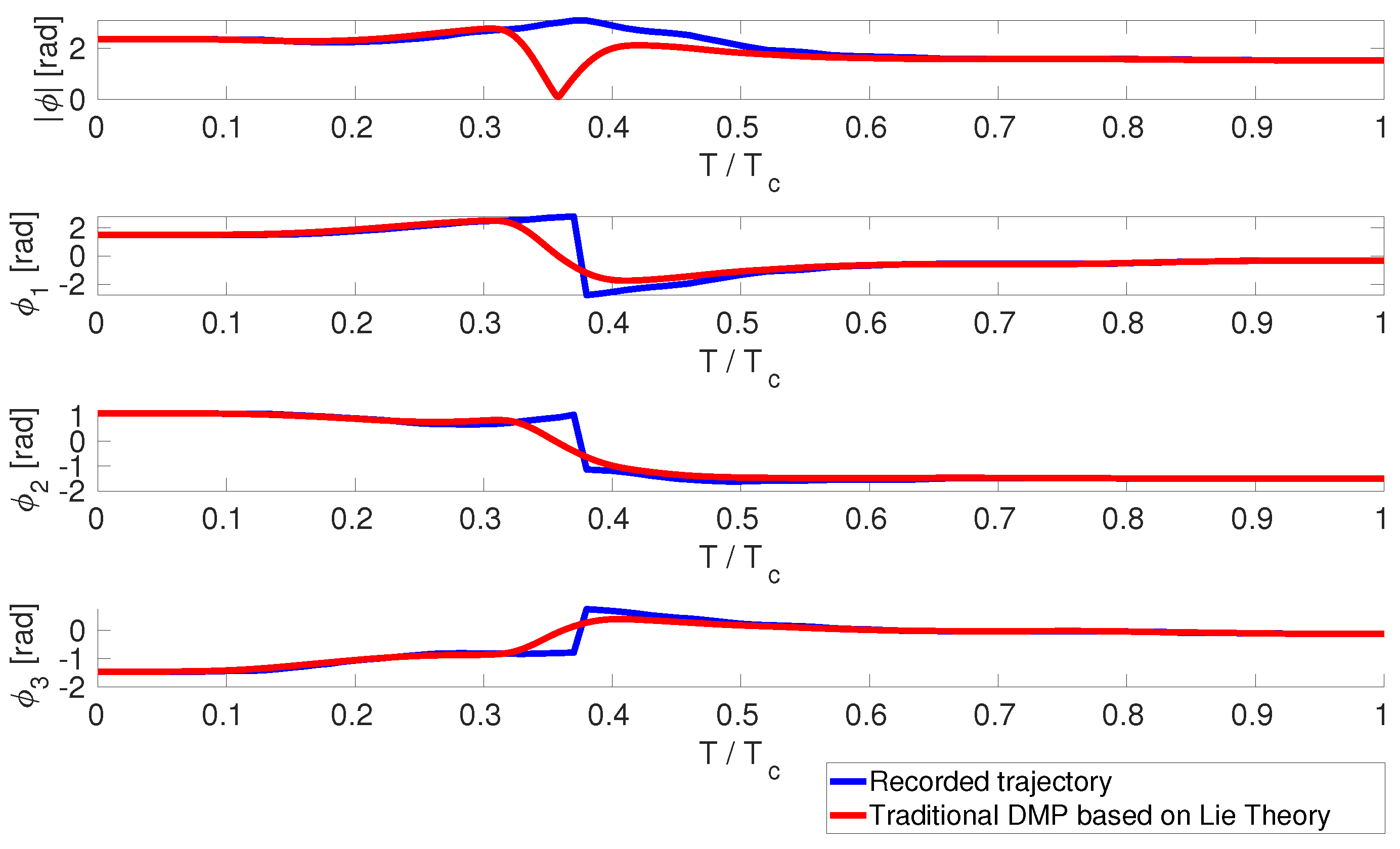
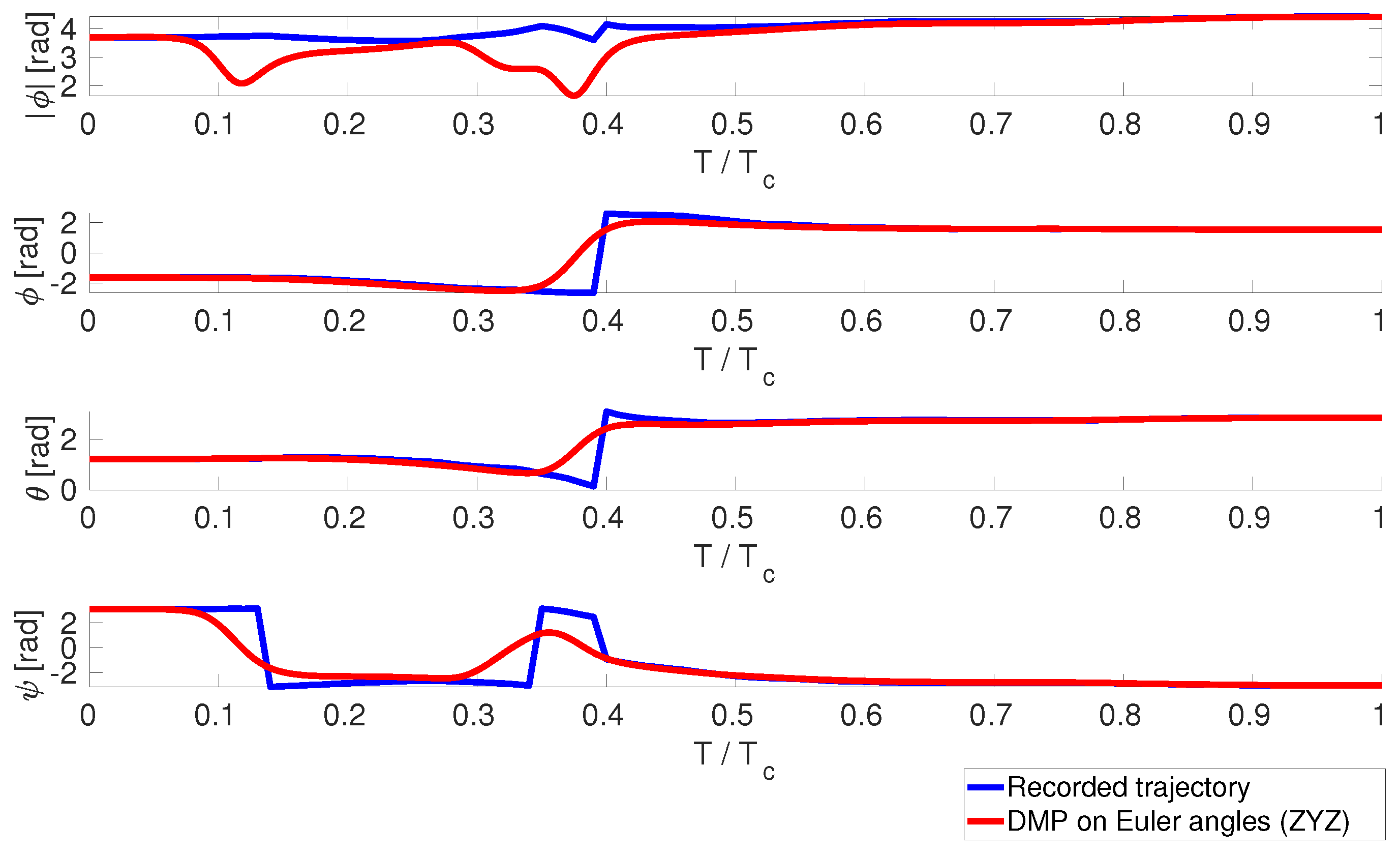
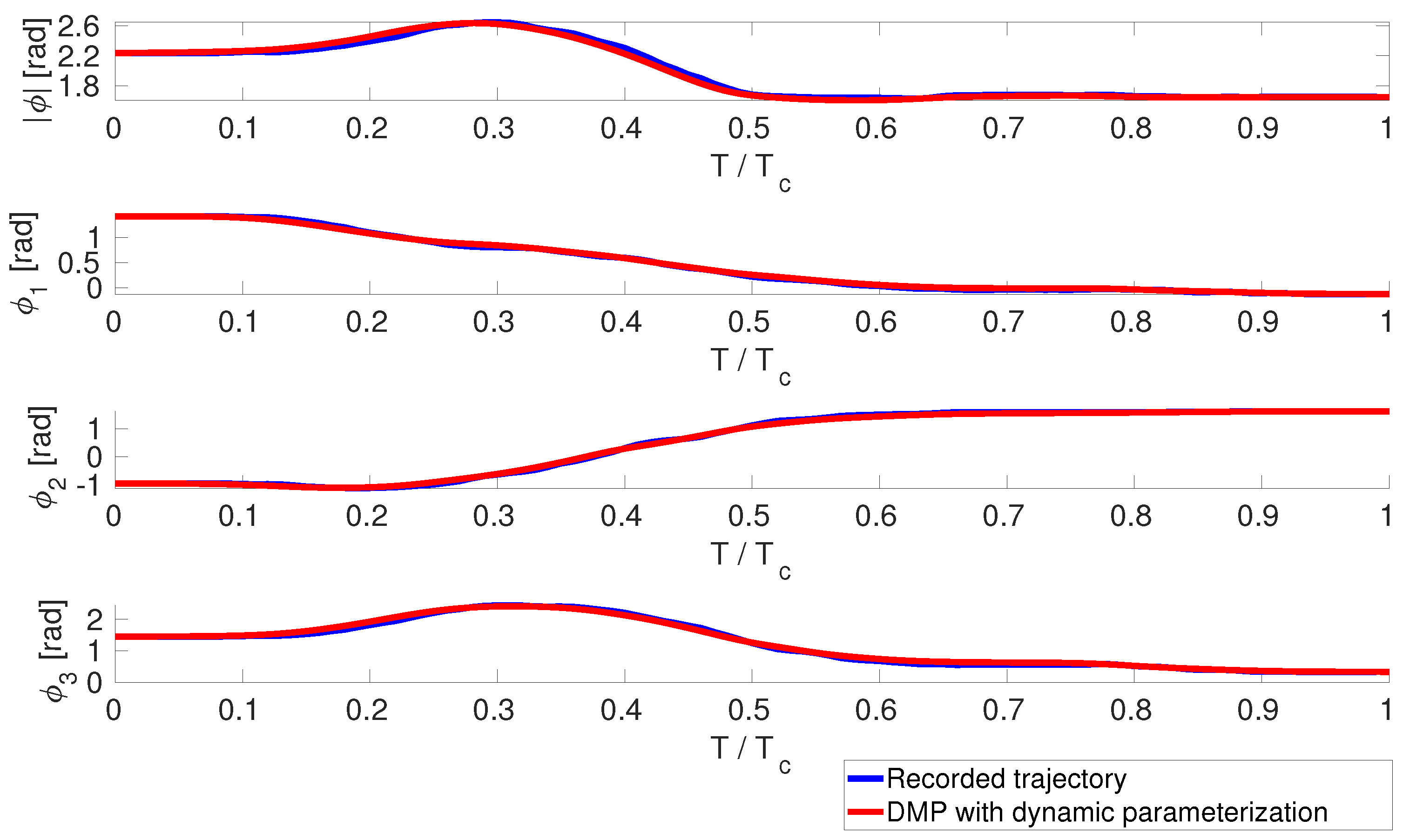
3. Results and Discussions
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Background on DMPs
Appendix A.1. DMP Computation
Appendix A.2. DMP Parameters Extraction
Appendix B. Background on Lie Groups
- The exponential map, which maps elements from the algebra m to the manifold M:
- The logarithm map, which maps elements from the manifold M to the algebra m:
Appendix B.1. Lie Algebra of SO(3)
Lie Algebra of S3
References
- Maja, M.M.; Ayano, S.F. The impact of population growth on natural resources and farmers’ capacity to adapt to climate change in low-income countries. Earth Syst. Environ. 2021, 5, 271–283. [Google Scholar] [CrossRef]
- Alexandra, R.; Péter, V.; Krisztina, D. Human resource aspect of agricultural economy–challenges of demographic change. APSTRACT Appl. Stud. Agribus. Commer. 2017, 11, 163–168. [Google Scholar]
- Bac, C.W.; Van Henten, E.J.; Hemming, J.; Edan, Y. Harvesting robots for high-value crops: State-of-the-art review and challenges ahead. J. Field Robot. 2014, 31, 888–911. [Google Scholar] [CrossRef]
- Adamides, G.; Edan, Y. Human–robot collaboration systems in agricultural tasks: A review and roadmap. Comput. Electron. Agric. 2023, 204, 107541. [Google Scholar] [CrossRef]
- Duffy, B.R. Anthropomorphism and the social robot. Robot. Auton. Syst. 2003, 42, 177–190. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Kayacan, E.; De Baedemaeker, J.; Saeys, W. Task and motion planning for apple harvesting robot. IFAC Proc. Vol. 2013, 46, 247–252. [Google Scholar] [CrossRef]
- Sucan, I.A.; Moll, M.; Kavraki, L.E. The open motion planning library. IEEE Robot. Autom. Mag. 2012, 19, 72–82. [Google Scholar] [CrossRef]
- Jaulin, L. Path planning using intervals and graphs. Reliab. Comput. 2001, 7, 1–15. [Google Scholar] [CrossRef]
- Jensen, M.A.F.; Bochtis, D.; Sørensen, C.G.; Blas, M.R.; Lykkegaard, K.L. In-field and inter-field path planning for agricultural transport units. Comput. Ind. Eng. 2012, 63, 1054–1061. [Google Scholar] [CrossRef]
- Zeng, J.; Ju, R.; Qin, L.; Hu, Y.; Yin, Q.; Hu, C. Navigation in unknown dynamic environments based on deep reinforcement learning. Sensors 2019, 19, 3837. [Google Scholar] [CrossRef]
- de Castro, G.G.; Berger, G.S.; Cantieri, A.; Teixeira, M.; Lima, J.; Pereira, A.I.; Pinto, M.F. Adaptive Path Planning for Fusing Rapidly Exploring Random Trees and Deep Reinforcement Learning in an Agriculture Dynamic Environment UAVs. Agriculture 2023, 13, 354. [Google Scholar] [CrossRef]
- Fang, Z.; Liang, X. Intelligent obstacle avoidance path planning method for picking manipulator combined with artificial potential field method. Ind. Robot. Int. J. Robot. Res. Appl. 2022, 49, 835–850. [Google Scholar] [CrossRef]
- Zhao, M.; Lv, X. Improved manipulator obstacle avoidance path planning based on potential field method. J. Robot. 2020, 2020, 1701943. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Kayacan, E.; De Baerdemaeker, J.; Saeys, W. Motion planning algorithm and its real-time implementation in apples harvesting robot. In Proceedings of the International Conference of Agricultural Engineering, Zurich, Switzerland, 6–10 July 2014. [Google Scholar]
- Liu, C.; Feng, Q.; Tang, Z.; Wang, X.; Geng, J.; Xu, L. Motion Planning of the Citrus-Picking Manipulator Based on the TO-RRT Algorithm. Agriculture 2022, 12, 581. [Google Scholar] [CrossRef]
- Chen, Y.; Fu, Y.; Zhang, B.; Fu, W.; Shen, C. Path planning of the fruit tree pruning manipulator based on improved RRT-Connect algorithm. Int. J. Agric. Biol. Eng. 2022, 15, 177–188. [Google Scholar] [CrossRef]
- Argall, B.D.; Chernova, S.; Veloso, M.; Browning, B. A survey of robot learning from demonstration. Robot. Auton. Syst. 2009, 57, 469–483. [Google Scholar] [CrossRef]
- Chen, J.R. Constructing task-level assembly strategies in robot programming by demonstration. Int. J. Robot. Res. 2005, 24, 1073–1085. [Google Scholar] [CrossRef]
- Billard, A.; Calinon, S.; Dillmann, R.; Schaal, S. Handbook of robotics chapter 59: Robot programming by demonstration. In Handbook of Robotics; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Si, W.; Wang, N.; Yang, C. A review on manipulation skill acquisition through teleoperation-based learning from demonstration. Cogn. Comput. Syst. 2021, 3, 1–16. [Google Scholar] [CrossRef]
- Lauretti, C.; Cordella, F.; Zollo, L. A hybrid joint/Cartesian DMP-based approach for obstacle avoidance of anthropomorphic assistive robots. Int. J. Soc. Robot. 2019, 11, 783–796. [Google Scholar] [CrossRef]
- Ijspeert, A.J.; Nakanishi, J.; Hoffmann, H.; Pastor, P.; Schaal, S. Dynamical movement primitives: Learning attractor models for motor behaviors. Neural Comput. 2013, 25, 328–373. [Google Scholar] [CrossRef]
- Lauretti, C.; Cordella, F.; Guglielmelli, E.; Zollo, L. Learning by Demonstration for planning activities of daily living in rehabilitation and assistive robotics. IEEE Robot. Autom. Lett. 2017, 2, 1375–1382. [Google Scholar] [CrossRef]
- Saveriano, M.; Abu-Dakka, F.J.; Kramberger, A.; Peternel, L. Dynamic movement primitives in robotics: A tutorial survey. arXiv 2021, arXiv:2102.03861. [Google Scholar] [CrossRef]
- Schaal, S.; Atkeson, C.G. Constructive incremental learning from only local information. Neural Comput. 1998, 10, 2047–2084. [Google Scholar] [CrossRef] [PubMed]
- Tamantini, C.; Cordella, F.; Lauretti, C.; Zollo, L. The WGD—A Dataset of Assembly Line Working Gestures for Ergonomic Analysis and Work-Related Injuries Prevention. Sensors 2021, 21, 7600. [Google Scholar] [CrossRef] [PubMed]
- Siciliano, B.; Sciavicco, L.; Villani, L.; Oriolo, G. Robotics–Modelling, Planning and Control; Advanced Textbooks in Control and Signal Processing Series; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Magermans, D.; Chadwick, E.; Veeger, H.; Van Der Helm, F. Requirements for upper extremity motions during activities of daily living. Clin. Biomech. 2005, 20, 591–599. [Google Scholar] [CrossRef] [PubMed]
- Benos, L.; Tsaopoulos, D.; Bochtis, D. A review on ergonomics in agriculture. Part I: Manual operations. Appl. Sci. 2020, 10, 1905. [Google Scholar] [CrossRef]
- Evans, D.J. On the representatation of orientation space. Mol. Phys. 1977, 34, 317–325. [Google Scholar] [CrossRef]
- Ude, A.; Nemec, B.; Petrić, T.; Morimoto, J. Orientation in cartesian space dynamic movement primitives. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2997–3004. [Google Scholar]
- La Hera, P.; Morales, D.O.; Mendoza-Trejo, O. A study case of Dynamic Motion Primitives as a motion planning method to automate the work of forestry cranes. Comput. Electron. Agric. 2021, 183, 106037. [Google Scholar] [CrossRef]
- Motokura, K.; Takahashi, M.; Ewerton, M.; Peters, J. Plucking motions for tea harvesting robots using probabilistic movement primitives. IEEE Robot. Autom. Lett. 2020, 5, 3275–3282. [Google Scholar] [CrossRef]
- Chevalley, C. Theory of Lie Groups; Courier Dover Publications: Mineola, NY, USA, 2018. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task 1: Digging | |
|---|---|
| Subtask 1-1 | Tool reaching |
| Subtask 1-2 | Digging |
| Subtask 1-3 | Soil placing into the bucket |
| Subtask 1-4 | Tool placing |
| Subtask 1-5 | Homing |
| Task 2: Seeding | |
| Subtask 2-1 | Seed reaching |
| Subtask 2-2 | Seed placing into the hall |
| Subtask 2-3 | Homing |
| Task 3: Irrigation | |
| Subtask 3-1 | Reaching the watering can |
| Subtask 3-2 | Irrigation |
| Subtask 3-3 | Watering can placing |
| Subtask 3-4 | Homing |
| Task 4: Harvesting | |
| Subtask 4-1 | Vegetable reaching |
| Subtask 4-2 | Vegetable detaching from the plant |
| Subtask 4-3 | Vegetable placing into the crate |
| Subtask 4-4 | Homing |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lauretti, C.; Tamantini, C.; Tomè, H.; Zollo, L. Robot Learning by Demonstration with Dynamic Parameterization of the Orientation: An Application to Agricultural Activities. Robotics 2023, 12, 166. https://doi.org/10.3390/robotics12060166
Lauretti C, Tamantini C, Tomè H, Zollo L. Robot Learning by Demonstration with Dynamic Parameterization of the Orientation: An Application to Agricultural Activities. Robotics. 2023; 12(6):166. https://doi.org/10.3390/robotics12060166
Chicago/Turabian StyleLauretti, Clemente, Christian Tamantini, Hilario Tomè, and Loredana Zollo. 2023. "Robot Learning by Demonstration with Dynamic Parameterization of the Orientation: An Application to Agricultural Activities" Robotics 12, no. 6: 166. https://doi.org/10.3390/robotics12060166