
Generalization Performance of Quantum Metric Learning Classifiers

Abstract
:1. Introduction
2. Materials and Methods
2.1. Quantum Metric Learning Expressed as a Kernel-Based Quantum Model
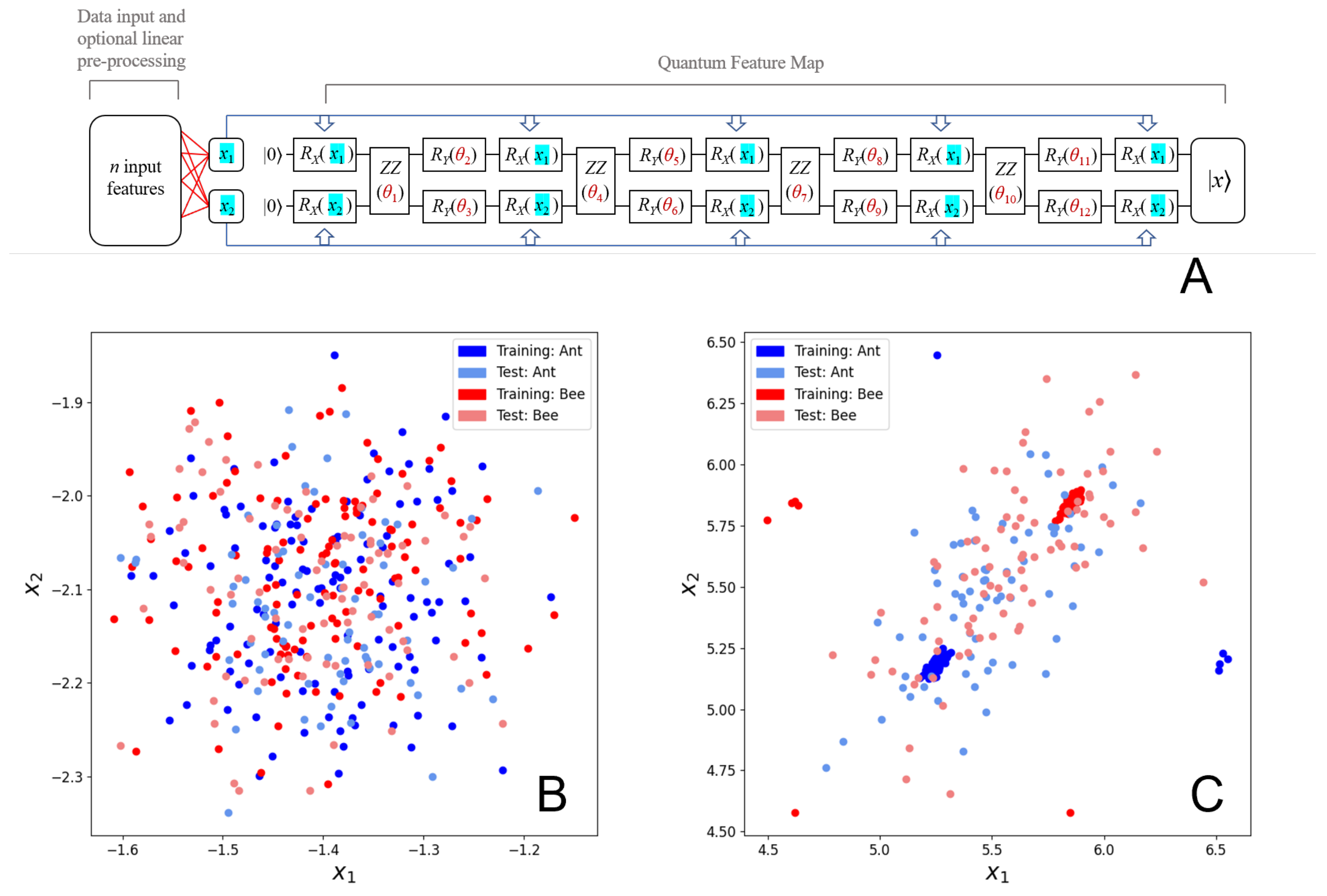
2.2. The Quantum Metric Learning Embedding Circuit
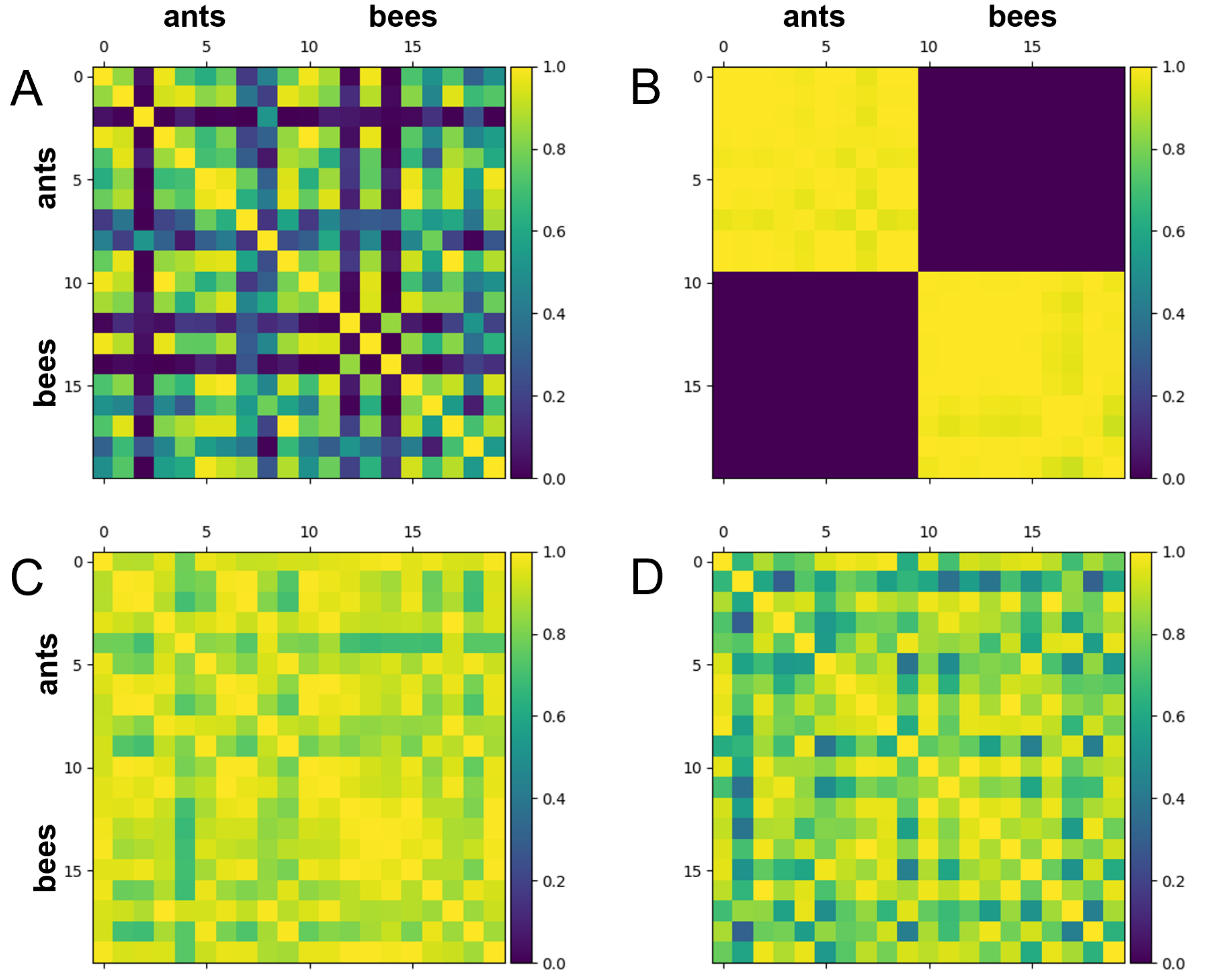
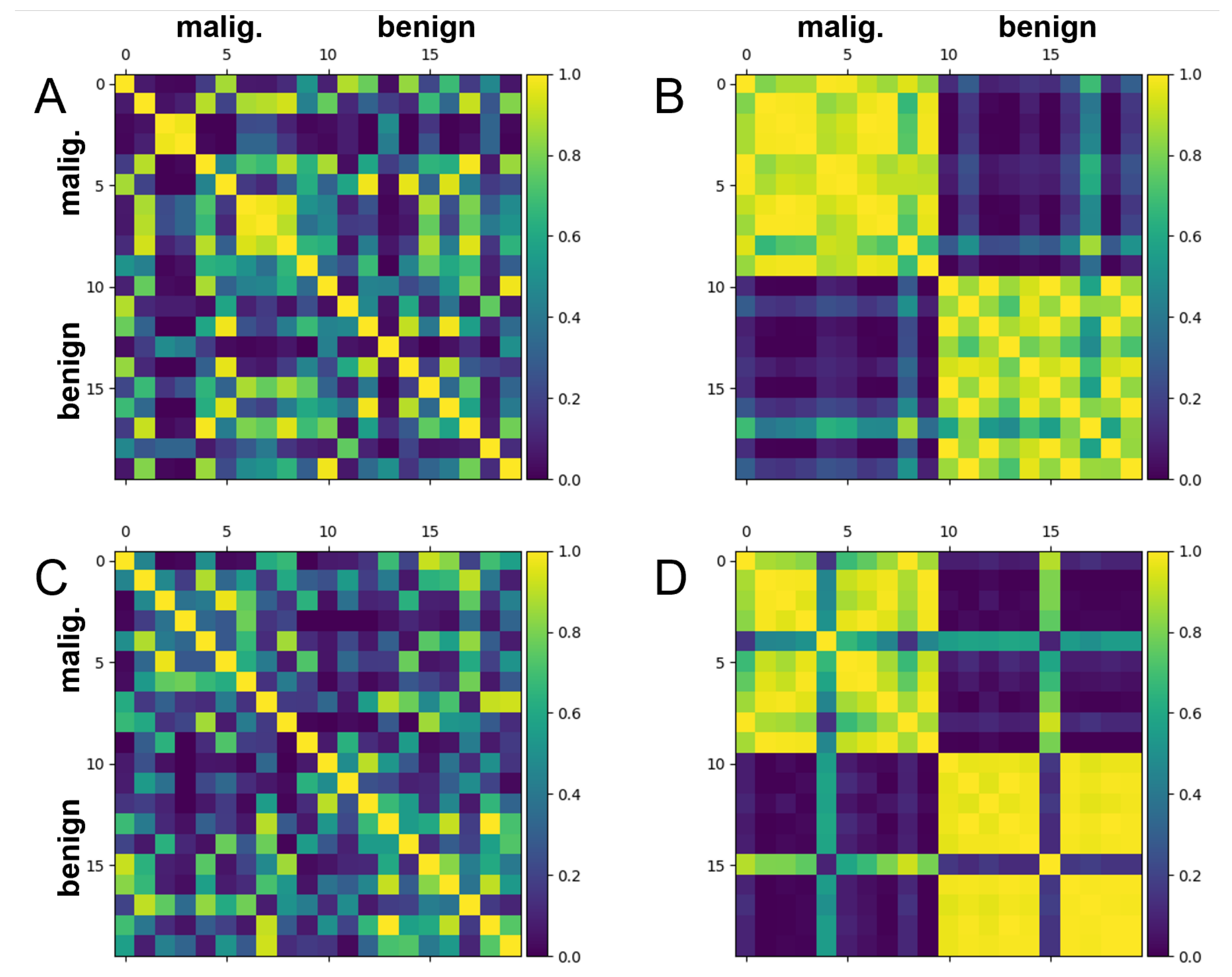
2.3. Training the Quantum Metric Learning Models
2.4. ImageNet Hymenoptera Dataset
2.4.1. Training QML Models with Feature Extraction Using ResNet-18
2.4.2. Training QML Models with Feature Extraction Using ResNet-18 Followed by PCA
2.4.3. Training QML Models with Feature Extraction Using PCA
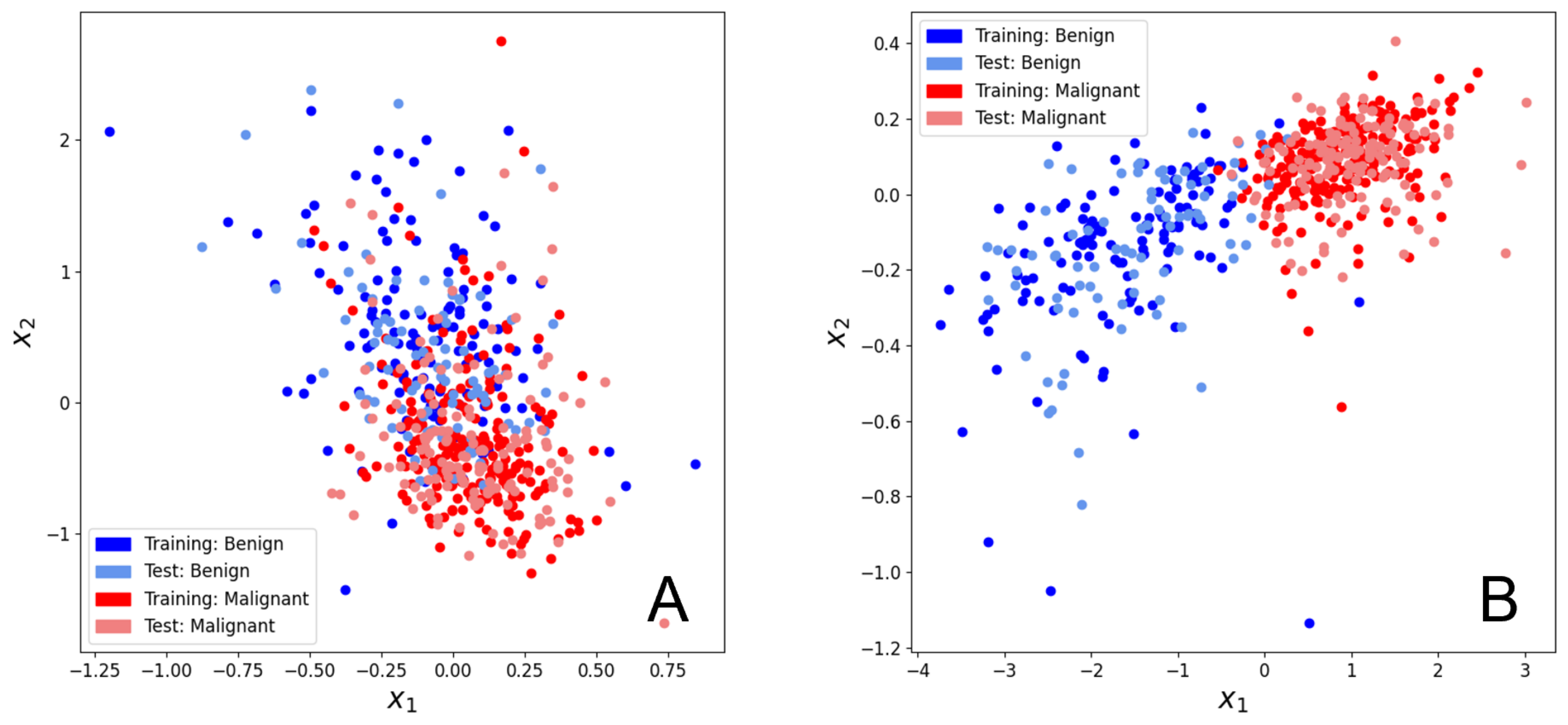
2.5. UCI ML Breast Cancer Wisconsin (Diagnostic) Dataset
2.5.1. Training QML Models Using All Input Features
2.5.2. Training QML Models with Feature Extraction Using PCA
2.6. Assessing Quantum Metric Learning Model Performance
3. Results
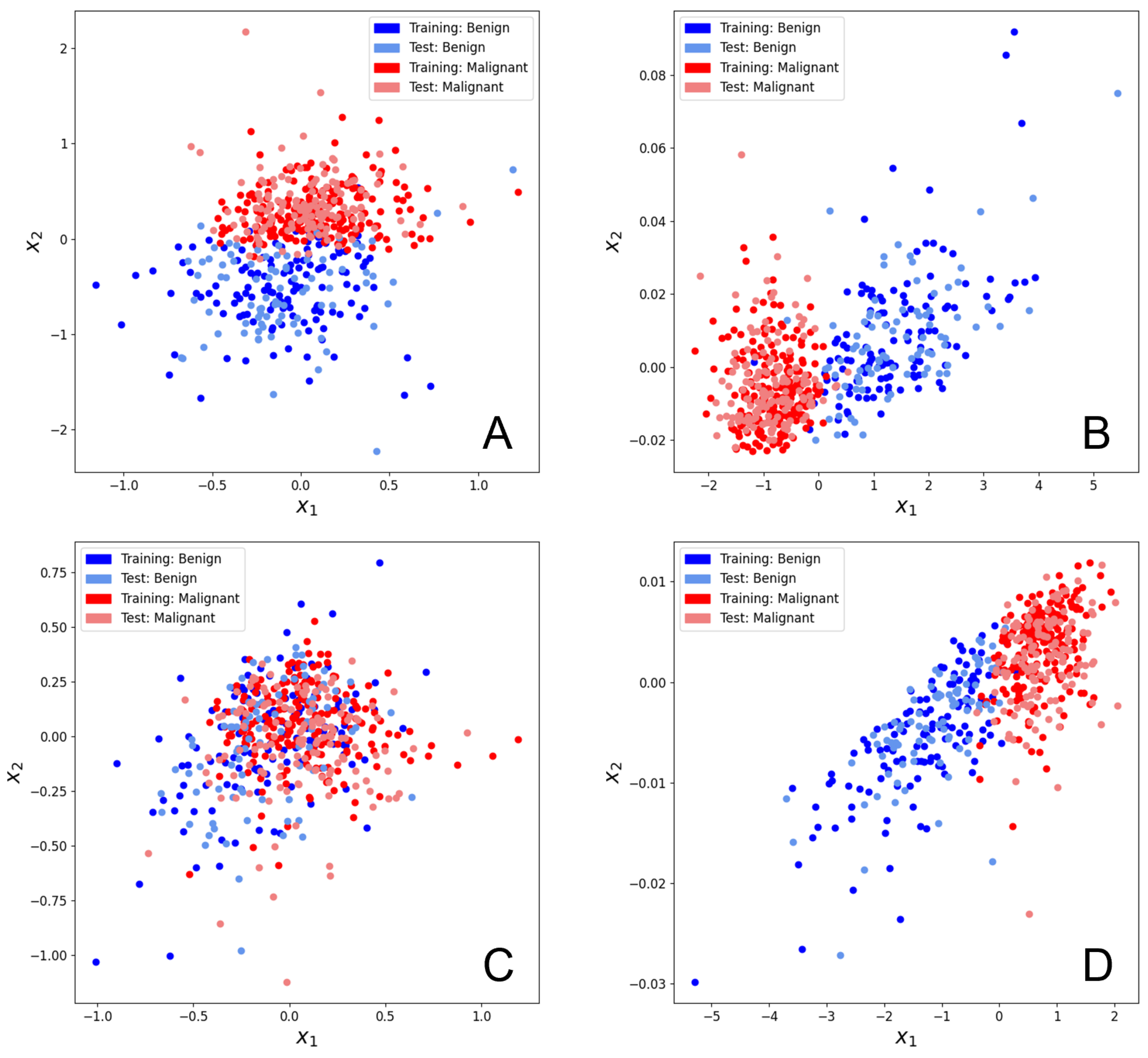
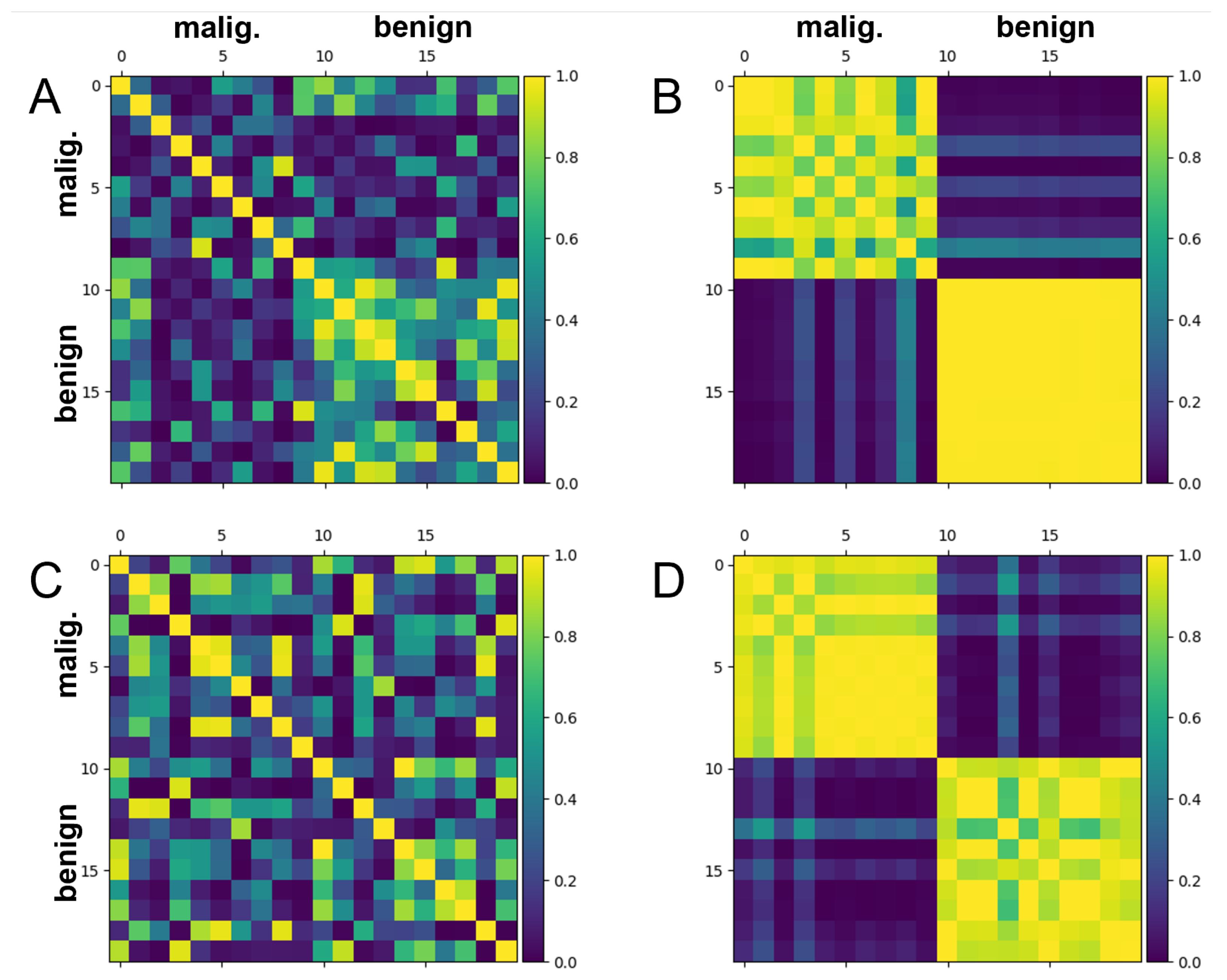
3.1. Hymenoptera Dataset
3.2. Breast Cancer Dataset
4. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| QML | quantum metric learning |
| PC | principal component |
| PCA | principal component analysis |
| KNN | k-nearest neighbor |
References
- Preskill, J. The Physics of Quantum Information. arXiv 2022, arXiv:2208.08064. [Google Scholar]
- Cao, Y.; Romero, J.; Olson, J.P.; Degroote, M.; Johnson, P.D.; Kieferová, M.; Kivlichan, I.D.; Menke, T.; Peropadre, B.; Sawaya, N.P.D.; et al. Quantum Chemistry in the Age of Quantum Computing. Chem. Rev. 2019, 119, 10856–10915. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grover, L.K. A Fast Quantum Mechanical Algorithm for Database Search. In Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing; Association for Computing Machinery, New York, NY, USA, 3–5 May 1996; STOC ’96. pp. 212–219. [Google Scholar]
- Shor, P. Algorithms for quantum computation: Discrete logarithms and factoring. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science, Santa Fe, New Mexico, 20–22 November 1994; pp. 124–134. [Google Scholar]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum machine learning. Nature 2017, 549, 195–202. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spagnolo, N.; Vitelli, C.; Sansoni, L.; Maiorino, E.; Mataloni, P.; Sciarrino, F.; Brod, D.J.; Galvão, E.F.; Crespi, A.; Ramponi, R.; et al. General Rules for Bosonic Bunching in Multimode Interferometers. Phys. Rev. Lett. 2013, 111, 130503. [Google Scholar] [CrossRef] [PubMed]
- Amin, M.H.; Andriyash, E.; Rolfe, J.; Kulchytskyy, B.; Melko, R. Quantum Boltzmann Machine. Phys. Rev. X 2018, 8, 021050. [Google Scholar] [CrossRef] [Green Version]
- Kieferová, M.; Wiebe, N. Tomography and generative training with quantum Boltzmann machines. Phys. Rev. A 2017, 96, 062327. [Google Scholar] [CrossRef] [Green Version]
- Wiebe, N.; Braun, D.; Lloyd, S. Quantum Algorithm for Data Fitting. Phys. Rev. Lett. 2012, 109, 050505. [Google Scholar] [CrossRef] [Green Version]
- Lloyd, S.; Mohseni, M.; Rebentrost, P. Quantum principal component analysis. Nat. Phys. 2014, 10, 631–633. [Google Scholar] [CrossRef] [Green Version]
- Wiebe, N.; Kapoor, A.; Svore, K.M. Quantum Deep Learning. arXiv 2014, arXiv:1412.3489. [Google Scholar] [CrossRef]
- Dunjko, V.; Taylor, J.M.; Briegel, H.J. Quantum-Enhanced Machine Learning. Phys. Rev. Lett. 2016, 117, 130501. [Google Scholar] [CrossRef] [Green Version]
- Kapoor, A.; Wiebe, N.; Svore, K. Quantum perceptron models. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3999–4007. [Google Scholar]
- Low, G.H.; Yoder, T.J.; Chuang, I.L. Quantum inference on Bayesian networks. Phys. Rev. A 2014, 89, 062315. [Google Scholar] [CrossRef]
- Wiebe, N.; Granade, C. Can small quantum systems learn? arXiv 2015, arXiv:1512.03145. [Google Scholar] [CrossRef]
- Giovannetti, V.; Lloyd, S.; Maccone, L. Quantum Random Access Memory. Phys. Rev. Lett. 2008, 100, 160501. [Google Scholar] [CrossRef] [Green Version]
- Rebentrost, P.; Mohseni, M.; Lloyd, S. Quantum Support Vector Machine for Big Data Classification. Phys. Rev. Lett. 2014, 113, 130503. [Google Scholar] [CrossRef] [Green Version]
- Preskill, J. Quantum Computing in the NISQ era and beyond. Quantum 2018, 2, 79. [Google Scholar] [CrossRef]
- Schuld, M.; Fingerhuth, M.; Petruccione, F. Implementing a distance-based classifier with a quantum interference circuit. EPL (Europhys. Lett.) 2017, 119, 60002. [Google Scholar] [CrossRef] [Green Version]
- Havlícek, V.; Córcoles, A.D.; Temme, K.; Harrow, A.W.; Kandala, A.; Chow, J.M.; Gambetta, J.M. Supervised learning with quantum-enhanced feature spaces. Nature 2019, 567, 209–212. [Google Scholar] [CrossRef] [Green Version]
- Schuld, M.; Killoran, N. Quantum Machine Learning in Feature Hilbert Spaces. Phys. Rev. Lett. 2019, 122, 040504. [Google Scholar] [CrossRef] [Green Version]
- Schuld, M. Supervised quantum machine learning models are kernel methods. arXiv 2021, arXiv:2101.11020. [Google Scholar]
- Blank, C.; Park, D.K.; Rhee, J.K.K.; Petruccione, F. Quantum classifier with tailored quantum kernel. NPJ Quantum Inf. 2020, 6, 41. [Google Scholar] [CrossRef]
- Park, D.K.; Blank, C.; Petruccione, F. The theory of the quantum kernel-based binary classifier. Phys. Lett. 2020, 384, 126422. [Google Scholar] [CrossRef] [Green Version]
- Kathuria, K.; Ratan, A.; McConnell, M.; Bekiranov, S. Implementation of a Hamming distance–like genomic quantum classifier using inner products on ibmqx2 and ibmq_16_melbourne. Quantum Mach. Intell. 2020, 2, 7. [Google Scholar] [CrossRef]
- Lloyd, S.; Schuld, M.; Ijaz, A.; Izaac, J.; Killoran, N. Quantum embeddings for machine learning. arXiv 2022, arXiv:2001.03622. [Google Scholar]
- Thumwanit, N.; Lortaraprasert, C.; Yano, H.; Raymond, R. Trainable Discrete Feature Embeddings for Variational Quantum Classifier. arXiv 2021, arXiv:2106.09415. [Google Scholar]
- Suzuki, Y.; Yano, H.; Gao, Q.; Uno, S.; Tanaka, T.; Akiyama, M.; Yamamoto, N. Analysis and synthesis of feature map for kernel-based quantum classifier. Quantum Mach. Intell. 2019, 2, 9. [Google Scholar] [CrossRef]
- García, D.P.; Cruz-Benito, J.; García-Peñalvo, F.J. Systematic Literature Review: Quantum Machine Learning and its applications. arXiv 2022, arXiv:2201.04093. [Google Scholar]
- Hubregtsen, T.; Wierichs, D.; Gil-Fuster, E.; Derks, P.J.H.S.; Faehrmann, P.K.; Meyer, J.J. Training Quantum Embedding Kernels on Near-Term Quantum Computers. arXiv 2021, arXiv:2105.02276. [Google Scholar] [CrossRef]
- Wang, X.; Du, Y.; Luo, Y.; Tao, D. Towards understanding the power of quantum kernels in the NISQ era. Quantum 2021, 5, 531. [Google Scholar] [CrossRef]
- LaRose, R.; Coyle, B. Robust data encodings for quantum classifiers. Phys. Rev. 2020, 102, 032420. [Google Scholar] [CrossRef]
- Easom-Mccaldin, P.; Bouridane, A.; Belatreche, A.; Jiang, R. On Depth, Robustness and Performance Using the Data Re-Uploading Single-Qubit Classifier. IEEE Access 2021, 9, 65127–65139. [Google Scholar] [CrossRef]
- Canatar, A.; Peters, E.; Pehlevan, C.; Wild, S.M.; Shaydulin, R. Bandwidth Enables Generalization in Quantum Kernel Models. arXiv 2022, arXiv:2206.06686. [Google Scholar]
- Caro, M.C.; Huang, H.Y.; Cerezo, M.; Sharma, K.; Sornborger, A.; Cincio, L.; Coles, P.J. Generalization in quantum machine learning from few training data. Nat. Commun. 2022, 13, 4919. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2019. Available online: http://archive.ics.uci.edu/ml (accessed on 1 August 2022).
- Farhi, E.; Goldstone, J.; Gutmann, S. A Quantum Approximate Optimization Algorithm. arXiv 2014, arXiv:1411.4028. [Google Scholar]
- Mari, A.; Bromley, T.R.; Izaac, J.; Schuld, M.; Killoran, N. Transfer learning in hybrid classical-quantum neural networks. arXiv 2019, arXiv:1912.08278. [Google Scholar] [CrossRef]
- Bergholm, V.; Izaac, J.; Schuld, M.; Gogolin, C.; Ahmed, S.; Ajith, V.; Alam, M.S.; Alonso-Linaje, G.; AkashNarayanan, B.; Asadi, A.; et al. PennyLane: Automatic differentiation of hybrid quantum-classical computations. arXiv 2018, arXiv:1811.04968. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of Features | ResNet (y/n) | Training Cost | Test Cost | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| 512 | y | 0.0141 | 0.9931 | 0.6184 | 0.5663 | 0.5912 |
| 256 | y | 0.9944 | 0.9885 | 0.5326 | 0.5976 | 0.5632 |
| 256 | n | 0.9947 | 0.9859 | 0.4945 | 0.5488 | 0.5202 |
| 64 | y | 0.9756 | 0.9942 | 0.4891 | 0.5488 | 0.5172 |
| 64 | n | 0.9956 | 0.9928 | 0.4828 | 0.5122 | 0.4970 |
| 16 | y | 0.9926 | 0.9897 | 0.5000 | 0.5488 | 0.5233 |
| 16 | n | 0.9969 | 0.9892 | 0.4831 | 0.5244 | 0.5029 |
| 4 | y | 0.9909 | 0.9911 | 0.4545 | 0.4878 | 0.4706 |
| 4 | n | 0.9959 | 0.9947 | 0.4783 | 0.5366 | 0.5057 |
| 2 | y | 0.9700 | 0.9928 | 0.4545 | 0.4878 | 0.4706 |
| 2 | n | 0.9954 | 0.9965 | 0.4316 | 0.5000 | 0.4633 |
| No. of Features | Training Cost | Test Cost | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| 30 | 0.1727 | 0.3623 | 0.9032 | 0.9790 | 0.9396 |
| 30 | 0.1465 | 0.3751 | 0.9091 | 0.9790 | 0.9428 |
| 16 | 0.2692 | 0.3023 | 0.9338 | 0.9860 | 0.9592 |
| 8 | 0.2757 | 0.2903 | 0.9226 | 1.0000 | 0.9597 |
| 4 | 0.2569 | 0.3440 | 0.9156 | 0.9860 | 0.9495 |
| 2 | 0.3953 | 0.3817 | 0.8981 | 0.9860 | 0.9400 |
| No. of Features | Training Cost | Test Cost | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| 30 | 0.2026 | 0.2791 | 0.9205 | 0.9720 | 0.9456 |
| 30 | 0.1750 | 0.2899 | 0.9211 | 0.9790 | 0.9492 |
| 16 | 0.2201 | 0.3101 | 0.9281 | 0.9930 | 0.9595 |
| 8 | 0.2497 | 0.2646 | 0.9655 | 0.9790 | 0.9722 |
| 4 | 0.2885 | 0.2913 | 0.9467 | 0.9930 | 0.9693 |
| 2 | 0.3450 | 0.3306 | 0.9517 | 0.9650 | 0.9583 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Bekiranov, S. Generalization Performance of Quantum Metric Learning Classifiers. Biomolecules 2022, 12, 1576. https://doi.org/10.3390/biom12111576
Kim J, Bekiranov S. Generalization Performance of Quantum Metric Learning Classifiers. Biomolecules. 2022; 12(11):1576. https://doi.org/10.3390/biom12111576
Chicago/Turabian StyleKim, Jonathan, and Stefan Bekiranov. 2022. "Generalization Performance of Quantum Metric Learning Classifiers" Biomolecules 12, no. 11: 1576. https://doi.org/10.3390/biom12111576