Use of Large and Diverse Datasets for 1H NMR Serum Metabolic Profiling of Early Lactation Dairy Cows

 ,
,  ,
,
Abstract
:1. Introduction
2. Results
2.1. Dataset
2.2. 1H NMR Spectroscopy of Serum Samples
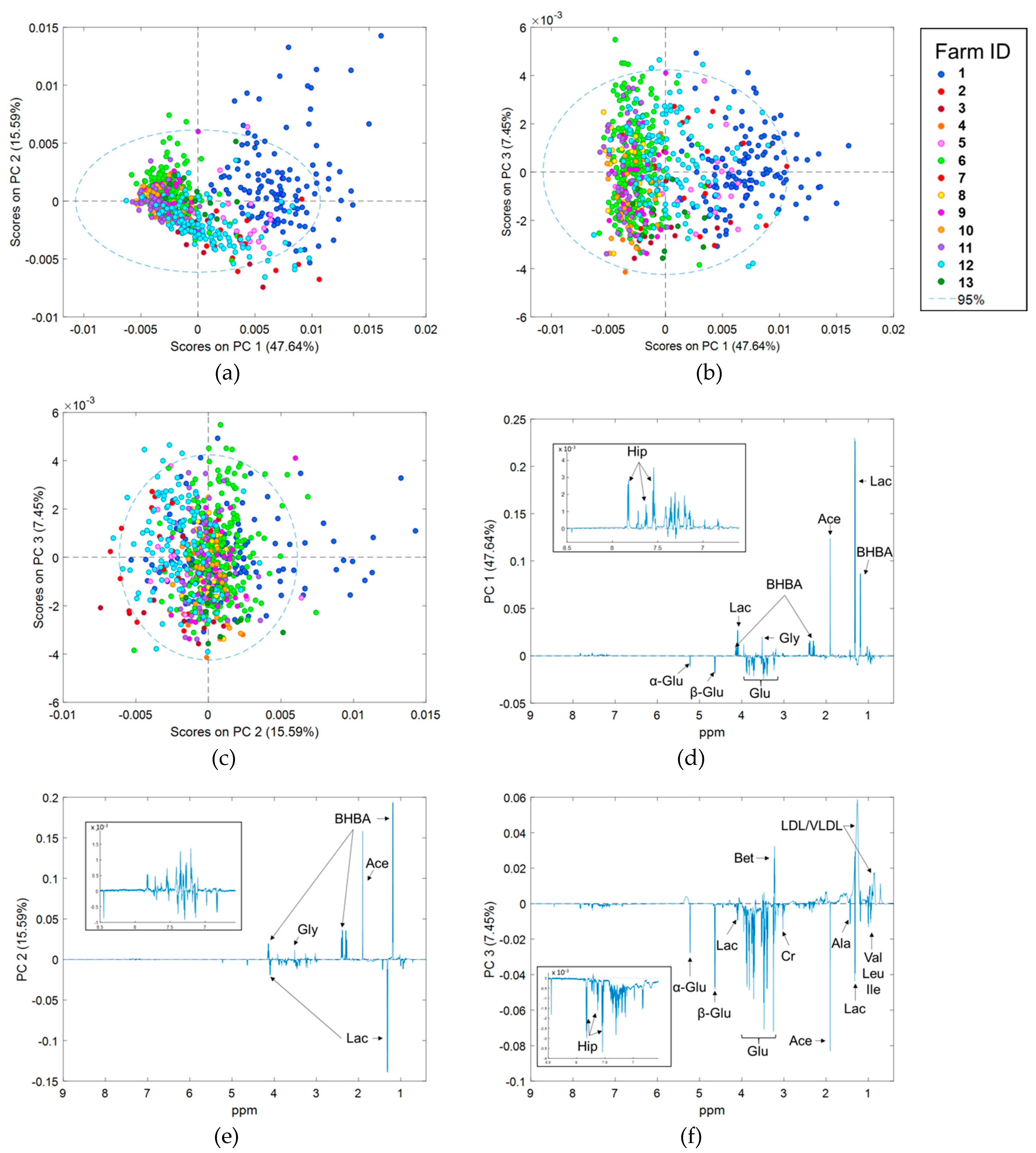
2.3. Preliminary Data Analysis Using Principal Component Analysis
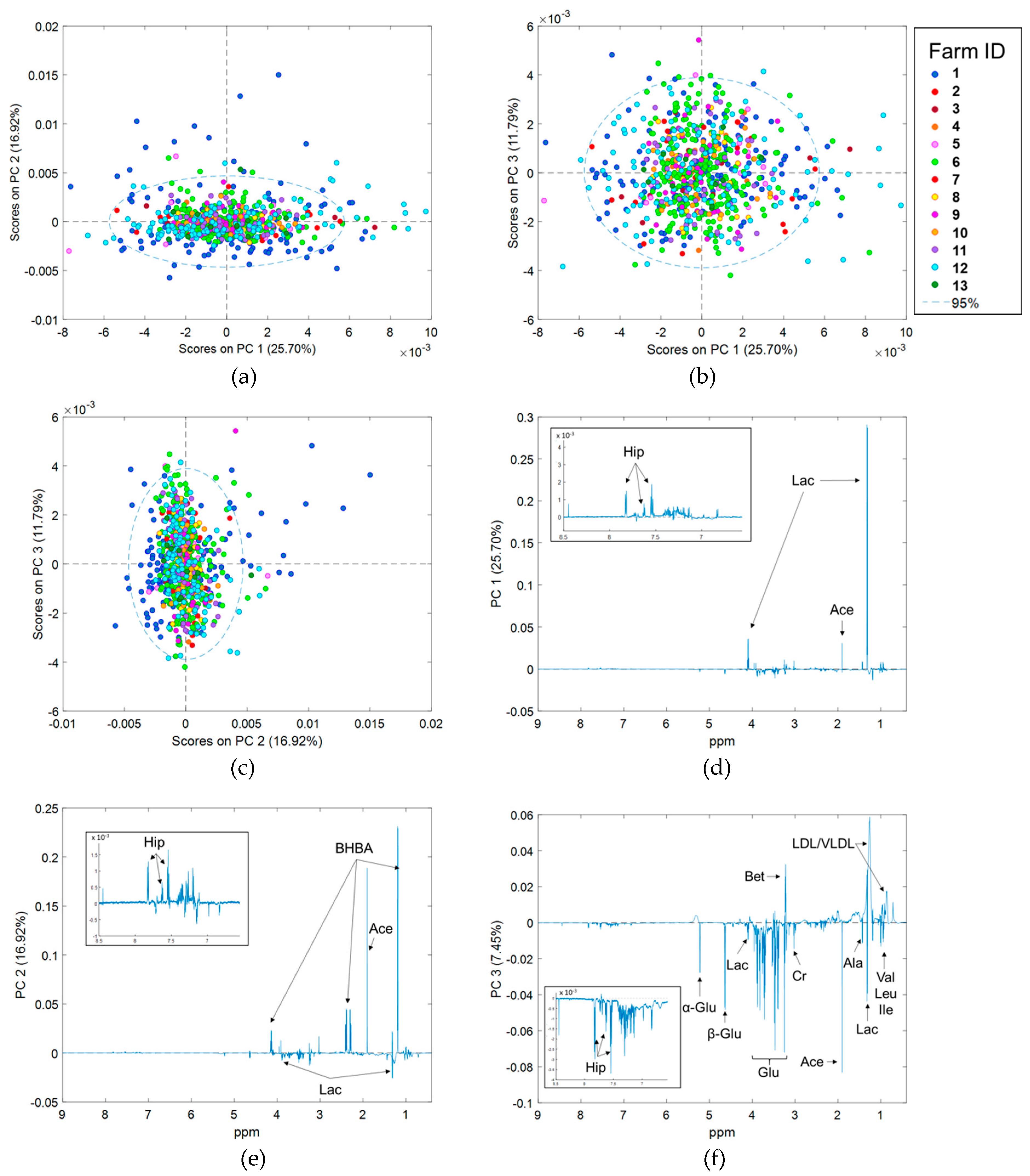
2.4. Principal Component Analysis of Spectra Corrected for Fixed Effects
2.5. Effect of Stage of Lactation, Parity, and Herd Effects on 1H NMR Spectra
2.6. Robustness of 1H NMR Predictions of Serum BHBA
2.7. Influence of Fixed Effects on Interpretation of 1H NMR Metabolomic Data
3. Discussion
3.1. Differences in 1H NMR Spectra Between Herds
3.2. Effect of Lactation Stage and Parity on Serum Metabolome
3.3. Accuracy of OPLS Models for Predicting Serum BHBA Concentration
3.4. Impact of Fixed Effects on the Interpretation of Metabolomic Data for Biomarker and Metabotype Discovery
4. Materials and Methods
4.1. Sample Collection
4.2. Reference BHBA Measurements
4.3. Chemicals
4.4. Sample Preparation for NMR Spectroscopy
4.5. 1H NMR Data Acquisition
4.6. 1H NMR Spectral Processing & Multivariate Statistical Analysis
4.7. Correction of 1H NMR Spectra for the Effects of Systematic Environemtal and Physiological Effects
4.8. Quantifying the Effect of Stage of Lactation, Parity and Herd on 1H NMR Spectra
4.9. The Relationships between 1H NMR Spectra and Existing Energy Balance Biomarker Concentrations
4.9.1. Robustness of OPLS Models to Predict External Phenotypes Using Uncorrected Data
4.9.2. Influence of Fixed Effects on Interpretation of 1H NMR Metabolomic Data
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wishart, D.S. Metabolomics: Applications to food science and nutrition research. Trends Food Sci. Technol. 2008, 19, 482–493. [Google Scholar] [CrossRef]
- Drackley, J.K. Biology of dairy cows during the transition period: The final frontier? J. Dairy Sci. 1999, 82, 2259–2273. [Google Scholar] [CrossRef]
- Grummer, R.R. Impact of changes in organic nutrient metabolism on feeding the transition dairy cow. J. Anim. Sci. 1995, 73, 2820–2833. [Google Scholar] [CrossRef]
- LeBlanc, S.J.; Lissemore, K.D.; Kelton, D.F.; Duffield, T.F.; Leslie, K.E. Major advances in disease prevention in dairy cattle. J. Dairy Sci. 2006, 89, 1267–1279. [Google Scholar] [CrossRef] [Green Version]
- Houle, D.; Govindaraju, D.; Omholt, S. Phenomics: The next challenge. Nat. Rev. Gen. 2010, 11, 855–866. [Google Scholar] [CrossRef]
- Daetwyler, H.D.; Xiang, R.; Yuan, Z.; Bolormaa, S.; Vander Jagt, C.J.; Hayes, B.J.; van der Werf, J.H.J.; Pryce, J.E.; Chamberlain, A.J.; Macleod, I.M.; et al. Integration of functional genomics and phenomics into genomic prediction raises its accuracy in sheep and dairy cattle. In Proceedings of the Association for the Advancement of Animal Breeding and Genetics, Armidale, NSW, Australia, 27 October–1 November 2019; pp. 11–14. [Google Scholar]
- Xiang, R.; Berg, I.V.D.; Macleod, I.M.; Hayes, B.J.; Prowse-Wilkins, C.P.; Wang, M.; Bolormaa, S.; Liu, Z.; Rochfort, S.J.; Reich, C.M.; et al. Quantifying the contribution of sequence variants with regulatory and evolutionary significance to 34 bovine complex traits. Proc. Natl. Acad. Sci. USA 2019, 116, 19398–19408. [Google Scholar] [CrossRef] [Green Version]
- Sun, L.W.; Zhang, H.Y.; Wu, L.; Shu, S.; Xia, C.; Xu, C.; Zheng, J.S. 1H-Nuclear magnetic resonance-based plasma metabolic profiling of dairy cows with clinical and subclinical ketosis. J. Dairy Sci. 2014, 97, 1552–1562. [Google Scholar] [CrossRef]
- Zhang, G.; Dervishi, E.; Dunn, S.; Mandal, R.; Liu, P.; Han, B.; Wishart, D.; Ametaj, B. Metabotyping reveals distinct metabolic alterations in ketotic cows and identifies early predictive serum biomarkers for the risk of disease. Metabolomics 2017, 13, 1–15. [Google Scholar] [CrossRef]
- Sun, Y.; Xu, C.; Li, C.; Cheng, X.; Xu, C.; Wu, L.; Zhang, H. Characterization of the serum metabolic profile of dairy cows with milk fever using (1)H-NMR spectroscopy. Vet. Quart. 2014, 34, 1–18. [Google Scholar] [CrossRef]
- Basoglu, A.; Baspinar, N.; Tenori, L.; Licari, C.; Gulersoy, E. Nuclear magnetic resonance (NMR)-based metabolome profile evaluation in dairy cows with and without displaced abomasum. Vet. Quart. 2020, 40, 1–15. [Google Scholar] [CrossRef]
- Hailemariam, D.; Mandal, R.; Saleem, F.; Dunn, S.M.; Wishart, D.S.; Ametaj, B.N. Identification of predictive biomarkers of disease state in transition dairy cows. J. Dairy Sci. 2014, 97, 2680–2693. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goldansaz, S.A.; Guo, A.C.; Sajed, T.; Steele, M.A.; Plastow, G.S.; Wishart, D.S. Livestock metabolomics and the livestock metabolome: A systematic review. PLoS ONE 2017, 12, e0177675. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sacco, D.; Brescia, M.A.; Sgaramella, A.; Casiello, G.; Buccolieri, A.; Ogrinc, N.; Sacco, A. Discrimination between southern Italy and foreign milk samples using spectroscopic and analytical data. Food Chem. 2009, 114, 1559–1563. [Google Scholar] [CrossRef]
- Tenori, L.; Santucci, C.; Meoni, G.; Morrocchi, V.; Matteucci, G.; Luchinat, C. NMR metabolomic fingerprinting distinguishes milk from different farms. Food Res. Int. 2018, 113, 131–139. [Google Scholar] [CrossRef]
- Sundekilde, U.K.; Frederiksen, P.D.; Clausen, M.R.; Larsen, L.B.; Bertram, H.C. Relationship between the metabolite profile and technological properties of bovine milk from two dairy breeds elucidated by NMR-based metabolomics. J. Agric. Food Chem. 2011, 59, 7360–7367. [Google Scholar] [CrossRef]
- Ilves, A.; Harzia, H.; Ling, K.; Ots, M.; Soomets, U.; Kilk, K. Alterations in milk and blood metabolomes during the first months of lactation in dairy cows. J. Dairy Sci. 2012, 95, 5788–5797. [Google Scholar] [CrossRef]
- Maher, A.D.; Hayes, B.; Cocks, B.; Marett, L.; Wales, W.J.; Rochfort, S.J. Latent biochemical relationships in the blood-milk metabolic axis of dairy cows revealed by statistical integration of 1H NMR spectroscopic data. J. Proteome Res. 2013, 12, 1428. [Google Scholar] [CrossRef]
- Mrode, R.A. Linear Models for the Prediction of Animal Breeding Values, 3rd ed.; CABI: Wallingford, UK, 2014. [Google Scholar]
- Wanichthanarak, K.; Jeamsripong, S.; Pornputtapong, N.; Khoomrung, S. Accounting for biological variation with linear mixed-effects modelling improves the quality of clinical metabolomics data. Comput. Struct. Biotechnol. J. 2019, 17, 611–618. [Google Scholar] [CrossRef]
- Laine, A.; Bastin, C.; Grelet, C.; Hammami, H.; Colinet, F.G.; Dale, L.M.; Gillon, A.; Vandenplas, J.; Dehareng, F.; Gengler, N. Assessing the effect of pregnancy stage on milk composition of dairy cows using mid-infrared spectra. J. Dairy Sci. 2017, 100, 2863–2876. [Google Scholar] [CrossRef] [Green Version]
- Oetzel, G.R. Monitoring and testing dairy herds for metabolic disease. Vet. Clin. North Am. Food Anim. Pr. 2004, 20, 651–674. [Google Scholar] [CrossRef]
- Ospina, P.A.; Nydam, D.V.; Stokol, T.; Overton, T.R. Associations of elevated nonesterified fatty acids and β-hydroxybutyrate concentrations with early lactation reproductive performance and milk production in transition dairy cattle in the northeastern United States. J. Dairy Sci. 2010, 93, 1596–1603. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lean, I.; Westwood, C.T.; Playford, M.C. Livestock disease threats associated with intensification of pastoral dairy farming. N. Z. Vet. J. 2008, 56, 261–269. [Google Scholar] [CrossRef] [PubMed]
- Schwaiger, T.; Beauchemin, K.A.; Penner, G.B. Duration of time that beef cattle are fed a high-grain diet affects the recovery from a bout of ruminal acidosis: Short-chain fatty acid and lactate absorption, saliva production, and blood metabolites. J. Anim. Sci. 2013, 91, 5743–5753. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Dong, G.; Wang, Z.; Wang, J.; Zhang, Z.; Liu, J. Rumen and plasma metabolomics profiling by UHPLC-QTOF/MS revealed metabolic alterations associated with a high-corn diet in beef steers. PLoS ONE 2018, 13, e0208031. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Martins, A.F.; Zhao, P.; Tieu, M.; Esteban-Gómez, D.; McCandless, G.T.; Platas-Iglesias, C.; Sherry, A.D. Enantiomeric recognition of d- and l-lactate by CEST with the aid of a paramagnetic shift reagent. J. Am. Chem. Soc. 2017, 139, 17431–17437. [Google Scholar] [CrossRef] [PubMed]
- Lees, H.J.; Swann, J.R.; Wilson, I.D.; Nicholson, J.K.; Holmes, E. Hippurate: The natural history of a mammalian–microbial cometabolite. J. Proteome Res. 2013, 12, 1527–1546. [Google Scholar] [CrossRef] [PubMed]
- Carpio, A.; Bonilla-Valverde, D.; Arce, C.; Rodríguez-Estévez, V.; Sánchez-Rodríguez, M.; Arce, L.; Valcárcel, M. Evaluation of hippuric acid content in goat milk as a marker of feeding regimen. J. Dairy Sci. 2013, 96, 5426–5434. [Google Scholar] [CrossRef] [Green Version]
- Pallister, T.; Jackson, M.A.; Martin, T.C.; Zierer, J.; Jennings, A.; Mohney, R.P.; MacGregor, A.; Steves, C.J.; Cassidy, A.; Spector, T.D.; et al. Hippurate as a metabolomic marker of gut microbiome diversity: Modulation by diet and relationship to metabolic syndrome. Sci. Rep. 2017, 7, 13670. [Google Scholar] [CrossRef] [Green Version]
- Liao, Y.; Hu, R.; Wang, Z.; Peng, Q.; Dong, X.; Zhang, X.; Zou, H.; Pu, Q.; Xue, B.; Wang, L. Metabolomics profiling of serum and urine in three beef cattle breeds revealed different levels of tolerance to heat stress. J. Agric. Food Chem. 2018, 66, 6926–6935. [Google Scholar] [CrossRef]
- Yin, P.; Lehmann, R.; Xu, G. Effects of pre-analytical processes on blood samples used in metabolomics studies. Anal. Bioanal. Chem. 2015, 407, 4879–4892. [Google Scholar] [CrossRef] [Green Version]
- Beckonert, O.; Keun, H.C.; Ebbels, T.M.; Bundy, J.; Holmes, E.; Lindon, J.C.; Nicholson, J.K. Metabolic profiling, metabolomic and metabonomic procedures for NMR spectroscopy of urine, plasma, serum and tissue extracts. Nat. Protoc. 2007, 2, 2692–2703. [Google Scholar] [CrossRef] [PubMed]
- Emwas, A.-H.; Luchinat, C.; Turano, P.; Tenori, L.; Roy, R.; Salek, R.M.; Ryan, D.; Merzaban, J.S.; Kaddurah-Daouk, R.; Zeri, A.C.; et al. Standardizing the experimental conditions for using urine in NMR-based metabolomic studies with a particular focus on diagnostic studies: A review. Metabolomics 2015, 11, 872–894. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jobard, E.; Trédan, O.; Postoly, D.; André, F.; Martin, A.-L.; Elena-Herrmann, B.; Boyault, S. A systematic evaluation of blood serum and plasma pre-analytics for metabolomics cohort studies. Int. J. Mol. Sci. 2016, 17, 2035. [Google Scholar] [CrossRef] [Green Version]
- Klein, M.S.; Almstetter, M.F.; Schlamberger, G.; Nürnberger, N.; Dettmer, K.; Oefner, P.J.; Meyer, H.H.D.; Wiedemann, S.; Gronwald, W. Nuclear magnetic resonance and mass spectrometry-based milk metabolomics in dairy cows during early and late lactation. J. Dairy Sci. 2010, 93, 1539–1550. [Google Scholar] [CrossRef] [PubMed]
- Cozzi, G.; Ravarotto, L.; Gottardo, F.; Stefani, A.L.; Contiero, B.; Moro, L.; Brscic, M.; Dalvit, P. Short communication: Reference values for blood parameters in holstein dairy cows: Effects of parity, stage of lactation, and season of production. J. Dairy Sci. 2011, 94, 3895–3901. [Google Scholar] [CrossRef] [PubMed]
- Luke, T.D.W.; Rochfort, S.; Wales, W.J.; Bonfatti, V.; Marett, L.; Pryce, J.E. Metabolic profiling of early-lactation dairy cows using milk mid-infrared spectra. J. Dairy Sci. 2019, 102, 1747–1760. [Google Scholar] [CrossRef] [Green Version]
- Morales Pineyrua, J.T.; Farina, S.R.; Mendoza, A. Effects of parity on productive, reproductive, metabolic and hormonal responses of Holstein cows. Anim. Reprod. Sci. 2018, 191, 9–21. [Google Scholar] [CrossRef]
- Davies, A.; Fearn, T. Back to basics: Calibration statistics. Spectrosc. Eur. 2006, 18, 31–32. [Google Scholar]
- Posma, J.M.; Garcia-Perez, I.; Ebbels, T.M.D.; Lindon, J.C.; Stamler, J.; Elliott, P.; Holmes, E.; Nicholson, J.K. Optimized phenotypic biomarker discovery and confounder elimination via covariate-adjusted projection to latent structures from metabolic spectroscopy data. J. Proteome Res. 2018, 17, 1586–1595. [Google Scholar] [CrossRef] [Green Version]
- Lean, I.J.; Farver, T.B.; Troutt, H.F.; Bruss, M.L.; Galland, J.C.; Baldwin, R.L.; Holmberg, C.A.; Weaver, L.D. Time series cross-correlation analysis of postparturient relationships among serum metabolites and yield variables in Holstein cows. J. Dairy Sci. 1992, 75, 1891–1900. [Google Scholar] [CrossRef]
- Aschenbach, J.R.; Kristensen, N.B.; Donkin, S.S.; Hammon, H.M.; Penner, G.B. Gluconeogenesis in dairy cows: The secret of making sweet milk from sour dough. IUBMB Life 2010, 62, 869–877. [Google Scholar] [CrossRef] [PubMed]
- Drackley, J.K.; Overton, T.R.; Douglas, G.N. Adaptations of glucose and long-chain fatty acid metabolism in liver of dairy cows during the periparturient period. J. Dairy Sci. 2001, 84, E100–E112. [Google Scholar] [CrossRef]
- Van den Berg, R.A.; Hoefsloot, H.C.J.; Westerhuis, J.A.; Smilde, A.K.; van der Werf, M.J. Centering, scaling, and transformations: Improving the biological information content of metabolomics data. BMC Genom. 2006, 7, 142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Emwas, A.-H.; Saccenti, E.; Gao, X.; McKay, R.; Santos, V.; Roy, R.; Wishart, D. Recommended strategies for spectral processing and post-processing of 1D 1 H-NMR data of biofluids with a particular focus on urine. Off. J. Metab. Soc. 2018, 14, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Fontanesi, L. Metabolomics and livestock genomics: Insights into a phenotyping frontier and its applications in animal breeding. Anim. Front. 2016, 6, 73–79. [Google Scholar] [CrossRef] [Green Version]
- Boichard, D.; Brochard, M. New phenotypes for new breeding goals in dairy cattle. Anim. Int. J. Anim. Biosci. 2012, 6, 544–550. [Google Scholar] [CrossRef] [Green Version]
- Egger-Danner, C.; Cole, J.B.; Pryce, J.E.; Gengler, N.; Heringstad, B.; Bradley, A.; Stock, K.F. Invited review: Overview of new traits and phenotyping strategies in dairy cattle with a focus on functional traits. Anim. Int. J. Anim. Biosci. 2015, 9, 191–207. [Google Scholar] [CrossRef] [Green Version]
- De Haas, Y.; Pryce, J.E.; Calus, M.P.; Wall, E.; Berry, D.P.; Lovendahl, P.; Krattenmacher, N.; Miglior, F.; Weigel, K.; Spurlock, D.; et al. Genomic prediction of dry matter intake in dairy cattle from an international data set consisting of research herds in Europe, North America, and Australasia. J. Dairy Sci. 2015, 98, 6522–6534. [Google Scholar] [CrossRef]
- McMurray, C.H.; Blanchflower, W.J.; Rice, D.A. Automated kinetic method for D-3-hydroxybutyrate in plasma or serum. Clin. Chem. 1984, 30, 421–425. [Google Scholar] [CrossRef]
- Gowda, N.G.A.; Raftery, D. Quantitating metabolites in protein precipitated serum using NMR spectroscopy. Anal. Chem. 2014, 86, 5433–5440. [Google Scholar] [CrossRef]
- Viant, M.R. Improved methods for the acquisition and interpretation of NMR metabolomic data. Biochem. Biophys. Res. Commun. 2003, 310, 943–948. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, N.-P.V.; Carstensen, J.M.; Smedsgaard, J. Aligning of single and multiple wavelength chromatographic profiles for chemometric data analysis using correlation optimised warping. J. Chromatogr. 1998, 805, 17–35. [Google Scholar] [CrossRef]
- Eigenvector. PLS Toolbox, R2017b; Eigenvector Research Inc.: Manson, WA, USA, 2017. [Google Scholar]
- Team, R.C. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]
- Wei, T.; Simko, V. R Package “Corrplot”: Visualization of a Correlation Matrix, (Version 0.84). Available online: https://github.com/taiyun/corrplot (accessed on 29 April 2020).
- Gilmour, A.R.; Gogel, B.J.; Cullis, B.R.; Thompson, R. ASReml User Guide Release 4.1 Functional Specification, 4.1; HP1 1ES; VSN International Ltd.: Hemel Hempstead, UK, 2015; p. 67. [Google Scholar]
- Smilde, A.; Jansen, J.; Hoefsloot, H.; Lamers, R.-J.; van Der Greef, J.; Timmerman, M. ANOVA-simultaneous component analysis (ASCA): A new tool for analyzing designed metabolomics data. Bioinformatics 2005, 21, 3043–3048. [Google Scholar] [CrossRef]
- Chong, I.-G.; Jun, C.-H. Performance of some variable selection methods when multicollinearity is present. Chemom. Intellig. Lab. Syst. 2005, 78, 103–112. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Farm | N | Location | Parity | DIM | BHBA |
|---|---|---|---|---|---|
| 1 | 129 | Sth Gipp 1 | 2.9 (1.1) | 19.4 (7.2) | 1.25 (0.69) |
| 2 | 11 | Sth Gipp | 2.6 (1.2) | 20.4 (8.1) | 0.34 (0.12) |
| 3 | 12 | W Gipp 2 | 2.6 (1.4) | 22.8 (5.7) | 0.33 (0.10) |
| 4 | 11 | W Gipp | 3.1 (1.2) | 17.9 (10.2) | 0.54 (0.15) |
| 5 | 18 | MID 3 | 2.9 (1.1) | 22.6 (5.1) | 0.61 (0.25) |
| 6 | 248 | W Gipp | 2.1 (1.0) | 16.7 (6.0) | 0.55 (0.21) |
| 7 | 9 | GV 4 | 2.6 (1.0) | 13.9 (6.7) | 0.53 (0.27) |
| 8 | 24 | MID | 2.4 (1.2) | 17.7 (8.2) | 0.38 (0.09) |
| 9 | 33 | Sth Gipp | 2.5 (1.2) | 18.3 (7.2) | 0.55 (0.33) |
| 10 | 27 | Sth Gipp | 1.8 (1.1) | 13.1 (7.7) | 0.50 (0.14) |
| 11 | 50 | Tas 5 | 2.6 (1.3) | 18.6 (7.3) | 0.42 (0.17) |
| 12 | 123 | MID | 2.8 (1.2) | 15.8 (8.6) | 0.38 (0.15) |
| 13 | 12 | Tas | 2.7 (0.8) | 16.0 (7.6) | 0.58 (0.22) |
| ALL | 707 | - | 2.5 (1.2) | 17.4 (7.3) | 0.63 (0.46) |
| PC1 (47.64%) | PC2 (15.59%) | PC3 (7.45%) | ||||||
|---|---|---|---|---|---|---|---|---|
| Fixed Effect | F-con | P Value | F-con | P Value | F-con | P Value | ||
| WIM | 2.66 | 0.047 | 5.42 | 0.001 | 2.14 | 0.094 | ||
| Parity | 2.78 | 0.041 | 20.39 | <0.001 | 15.19 | <0.001 | ||
| Herd | 158.29 | <0.001 | 26.78 | <0.001 | 6.66 | <0.001 | ||
| Calibration | Cross Validation | External Validation | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Validation Farm | P | LV | N | R2 | RMSE | R2 | RMSE | N | R2 | RMSE | ||
| - | <0.05 | 3 | 707 | 0.95 | 0.10 | 0.95 | 0.10 | - | - | - | ||
| 1 | <0.05 | 5 | 578 | 0.87 | 0.08 | 0.85 | 0.08 | 129 | 0.96 | 0.18 | ||
| 2 | <0.05 | 3 | 696 | 0.95 | 0.10 | 0.95 | 0.10 | 11 | 0.59 | 0.10 | ||
| 3 | <0.05 | 4 | 695 | 0.96 | 0.09 | 0.96 | 0.10 | 12 | 0.78 | 0.06 | ||
| 4 | <0.05 | 3 | 696 | 0.95 | 0.10 | 0.95 | 0.10 | 11 | 0.93 | 0.09 | ||
| 5 | <0.05 | 3 | 689 | 0.96 | 0.10 | 0.95 | 0.10 | 18 | 0.99 | 0.09 | ||
| 6 | <0.05 | 3 | 459 | 0.96 | 0.11 | 0.96 | 0.11 | 248 | 0.87 | 0.10 | ||
| 7 | <0.05 | 3 | 698 | 0.95 | 0.10 | 0.95 | 0.10 | 9 | 0.98 | 0.05 | ||
| 8 | <0.05 | 3 | 683 | 0.95 | 0.10 | 0.95 | 0.10 | 24 | 0.30 | 0.07 | ||
| 9 | <0.05 | 3 | 674 | 0.95 | 0.10 | 0.95 | 0.10 | 33 | 0.95 | 0.11 | ||
| 10 | <0.05 | 3 | 680 | 0.95 | 0.10 | 0.95 | 0.10 | 27 | 0.85 | 0.09 | ||
| 11 | <0.05 | 3 | 657 | 0.95 | 0.10 | 0.95 | 0.10 | 50 | 0.82 | 0.08 | ||
| 12 | <0.05 | 3 | 584 | 0.97 | 0.09 | 0.96 | 0.09 | 123 | 0.52 | 0.12 | ||
| 13 | <0.05 | 3 | 695 | 0.95 | 0.10 | 0.95 | 0.10 | 12 | 0.98 | 0.05 | ||
| Dataset | N | LVs | P Value 1 | R2C | RMSEC | R2CV | RMSECV |
|---|---|---|---|---|---|---|---|
| Farm 1 Uncorrected | 129 | 4 | <0.001 | 0.98 | 0.10 | 0.97 | 0.12 |
| All Data Uncorrected | 707 | 4 | <0.001 | 0.96 | 0.09 | 0.96 | 0.10 |
| All Data Corrected for Herd | 707 | 4 | <0.001 | 0.93 | 0.09 | 0.93 | 0.09 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luke, T.D.W.; Pryce, J.E.; Elkins, A.C.; J. Wales, W.; Rochfort, S.J. Use of Large and Diverse Datasets for 1H NMR Serum Metabolic Profiling of Early Lactation Dairy Cows. Metabolites 2020, 10, 180. https://doi.org/10.3390/metabo10050180
Luke TDW, Pryce JE, Elkins AC, J. Wales W, Rochfort SJ. Use of Large and Diverse Datasets for 1H NMR Serum Metabolic Profiling of Early Lactation Dairy Cows. Metabolites. 2020; 10(5):180. https://doi.org/10.3390/metabo10050180
Chicago/Turabian StyleLuke, Timothy D. W., Jennie E. Pryce, Aaron C. Elkins, William J. Wales, and Simone J. Rochfort. 2020. "Use of Large and Diverse Datasets for 1H NMR Serum Metabolic Profiling of Early Lactation Dairy Cows" Metabolites 10, no. 5: 180. https://doi.org/10.3390/metabo10050180