
Reducing the Length of Dynamic and Relevant Slices by Pruning Boolean Expressions

Abstract
:1. Introduction
| Algorithm 1 Expert analysis of the file base.py from the Python library Pandas. |
| 868 def _format_data(self, name=None): … 883 n = len(self) 884 sep = ’,’ 885 max_seq_items = get_option(’display.max_seq_items’) or n … 894 is_truncated = n > max_seq_items … 938 if (is_truncated or 939 not (len(’,⎵’.join(head)) < display_width and 940 len(’,⎵’.join(tail)) < display_width)): 941 max_len = max(best_len(head), best_len(tail)) 942 head = [x.rjust(max_len) for x in head] 943 tail = [x.rjust(max_len) for x in tail] |
- A discussion of short-circuit evaluation for dynamic slicing.
- The introduction of pruned slicing.
- A proof-of-concept implementation of a dynamic, relevant, and pruned slicer for Python 3 programs.
- An empirical evaluation of dynamic and relevant slicing with short-circuit evaluation and pruned slicing on three small benchmarks.
- We extend our evaluation to relevant slicing and pruned relevant slicing. In particular, we compare dynamic and relevant slicing with respect to executability, correct results, slice length, and computation time.
- We extend our prototype slicer by implementing a relevant slicer.
2. Related Works
3. Background
3.1. Syntax of Boolean Expressions
- , where and are Boolean expressions;
- , where and are Boolean expressions;
- , where is a Boolean expression;
- ;
- ;
- Any expression that evaluates/casts to a Boolean value, e.g., ‘3 < 5’, ‘0’, ‘None’;
- A function/method call that returns a value interpretable as a Boolean.
3.2. Dynamic Slicing
- Instruction number X and execution number i: The instruction number X is the line number of the statement in the source code, and the execution number i is the position of the statement in the execution trace, i.e., means that statement X is the ith statement in the execution trace.
- Instruction type : The instruction type is either control (C) or assignment (A). Source code often comprises other types of statements (e.g., print(x)), but for the sake of simplicity, we restrict ourselves to these types.
- Set of referenced (or used) variables : comprises all variables that are referenced in statement . For example, for statement :a[i]=b, the used variables are . For function/method calls/definitions, is a variable vector to allow the matching of parameters.
- Set of defined variables : comprises all variables whose values are changed in statement . For example, for statement :a[i]=b, the set of defined variables is . For function/method calls/definitions, is a variable vector to allow the matching of parameters.
- Set of control dependencies : A statement is control-dependent on another statement (i.e., ) if is only executed when evaluates in a way that allows its execution, i.e., all statements in a loop body are control-dependent on the statement in the loop head, and all statements in the then and else branches are control-dependent on the if statement.
- 1
- a = x
- 2
- b = y
- 3
- c = z
- 4
- d = y
- 5
- if a < b or a < c or d < c:
- 6
- c = a
- 7
- if b > c:
- 8
- c = b
- 9
- d = c
| Algorithm 2: Simplified dynamic slicing algorithm. |
|
3.3. Short-Circuit Evaluation
| e | eval() | eval() | |
| true | ? | ||
| false | ? | ||
| true | ? | ||
| false | ? | ||
| ? | - | ||
| True | - | - | |
| False | - | - | |
| other | - | - |
- Base test case , where both sub-expressions of line 6 ( and ) evaluate to true.
- Base test case , where the second sub-expression evaluates to false.
- Short-circuit test case , where the first expression evaluates to false and thus the second expression is not evaluated.
3.4. Relevant Slicing
- 1
- def remove_extras(lst):
- 2
- l=[]
- 3
- for i in lst:
- 4
- checker=True
- 5
- for k in l:
- 6
- if k==i:
- 7
- checker=False
- 8
- if checker:
- 9
- l+=[i]
- 10
- return l
- The set of variables that could be (re)defined in any of the branches of the conditional in case of conditionals.
- The set of variables that would be (re)defined in the loop body in case of loops.
- for assignments (i.e., ).
| Algorithm 3: Relevant Slicing algorithm: Changes necessary for short-circuit evaluation are highlighted in blue; changes necessary for relevant slicing are highlighted in red. |
|
4. Pruned Slicing
| e | eval() | eval() | |
| true | true | ||
| true | false | ||
| false | ? | ||
| true | ? | ||
| false | true | ||
| false | false | ||
| ? | - | ||
| - | - | ||
| - | - | ||
| other | - | - |
| 222 if ( |
| 223 (not require_current_request or internal_url.host == _get_request_host()) |
| 224 and (not require_ssl or internal_url.scheme == “https”) |
| 225 and (not require_standard_port or internal_url.is_default_port()) |
| 226 and (allow_ip or not is_ip_address(str(internal_url.host))) |
| 227 ): |
| 228 return normalize_url(str(internal_url)) |
| 222 if ( |
| 223 (not require\_current\_request or internal\_url.host == \_get\_request\_host()) |
| 224 and (not require\_ssl or internal\_url.scheme == “https”) |
| 225 and (not require_standard_port or internal_url.is_default_port()) |
| 226 and (allow\_ip or not is\_ip\_address(str(internal\_url.host))) |
| 227 ): |
| 228 return normalize\_url(str(internal\_url)) |
5. Relation of the Different Slice Types
- 1
- def sort_age(lst):
- 2
- new_lst = []
- 3
- age = []
- 4
- for i in lst:
- 5
- age = age + [i[1],]
- 6
- while len(lst) != 0:
- 7
- for j in lst:
- 8
- if j[1] == max(age):
- 9
- lst.remove(j)
- 10
- age.remove(max(age))
- 11
- new_lst = new_lst + [j,]
- 12
- return new_lst
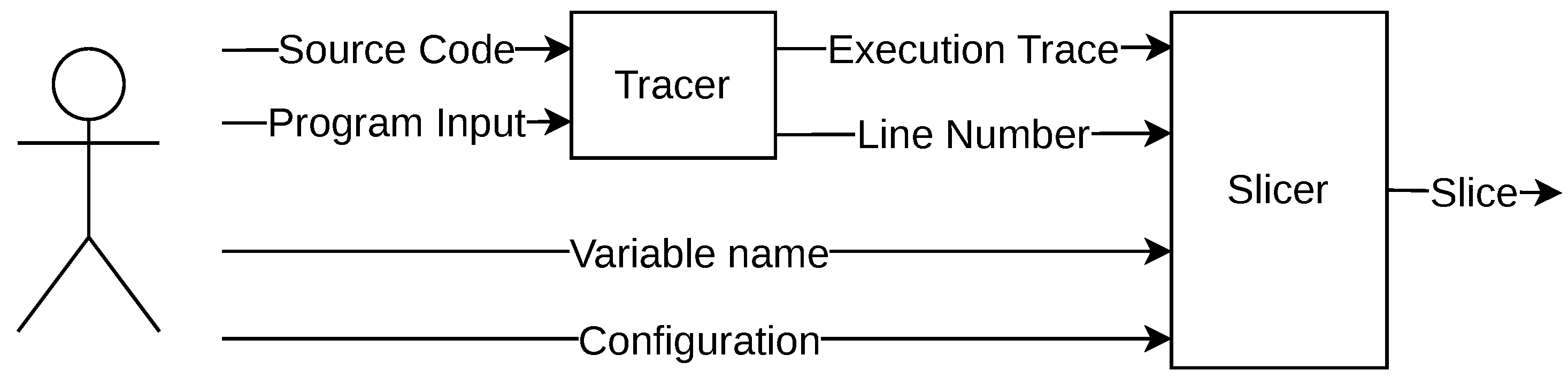
6. Prototype Implementation
6.1. Technical Details
6.2. Metamorphic Testing
- The original input program is executable.
- The augmentation of the original program is successful.
- Tracing of the program is successful.
- Slicer execution is successful.
- Code generation from the slice is successful.
- The execution results of the sliced program are equal to the execution results of the original program for the input and variable provided in the slicing criterion.
- The slices are shorter than or equal to the size of the set of executed statements (i.e., and ).
- The pruned slices are shorter than or equal to the size of their non-pruned counterparts (i.e., and ).
6.3. Limitations
6.4. Possible Improvements
7. Evaluation
7.1. Research Questions
- RQ1: What is the difference between dynamic and relevant slicing with respect to executability, correct results, and slice length? Dynamic slicing might result in slices that do not terminate or that compute different values for the variable of interest than the original program (see Section 3.4). Therefore, we analyze how often the program/test case combinations result in non-terminating dynamic slices or slices that compute the wrong result. While relevant slicing eliminates the majority of the problems with dynamic slicing, it comes with a tradeoff: relevant slices might contain more statements than dynamic slices. Thus, we analyze to what extent the size of the slices increases.
- RQ2: What reduction with respect to slice length can be achieved by pruning Boolean operations in dynamic and relevant slices? How many Boolean operators are pruned away? How frequently are Boolean operators used in real-world programs? We compare the average size of the dynamic and relevant slices to the size of the pruned versions to investigate the reduction that can be achieved. Since pruning not only helps reduce the slice length but also reduces the size of nested Boolean expressions, we additionally investigate how many Boolean operators are pruned away. Since the programs used in this evaluation are rather small, we investigate the frequency of Boolean operators in 40 open-source Python projects.
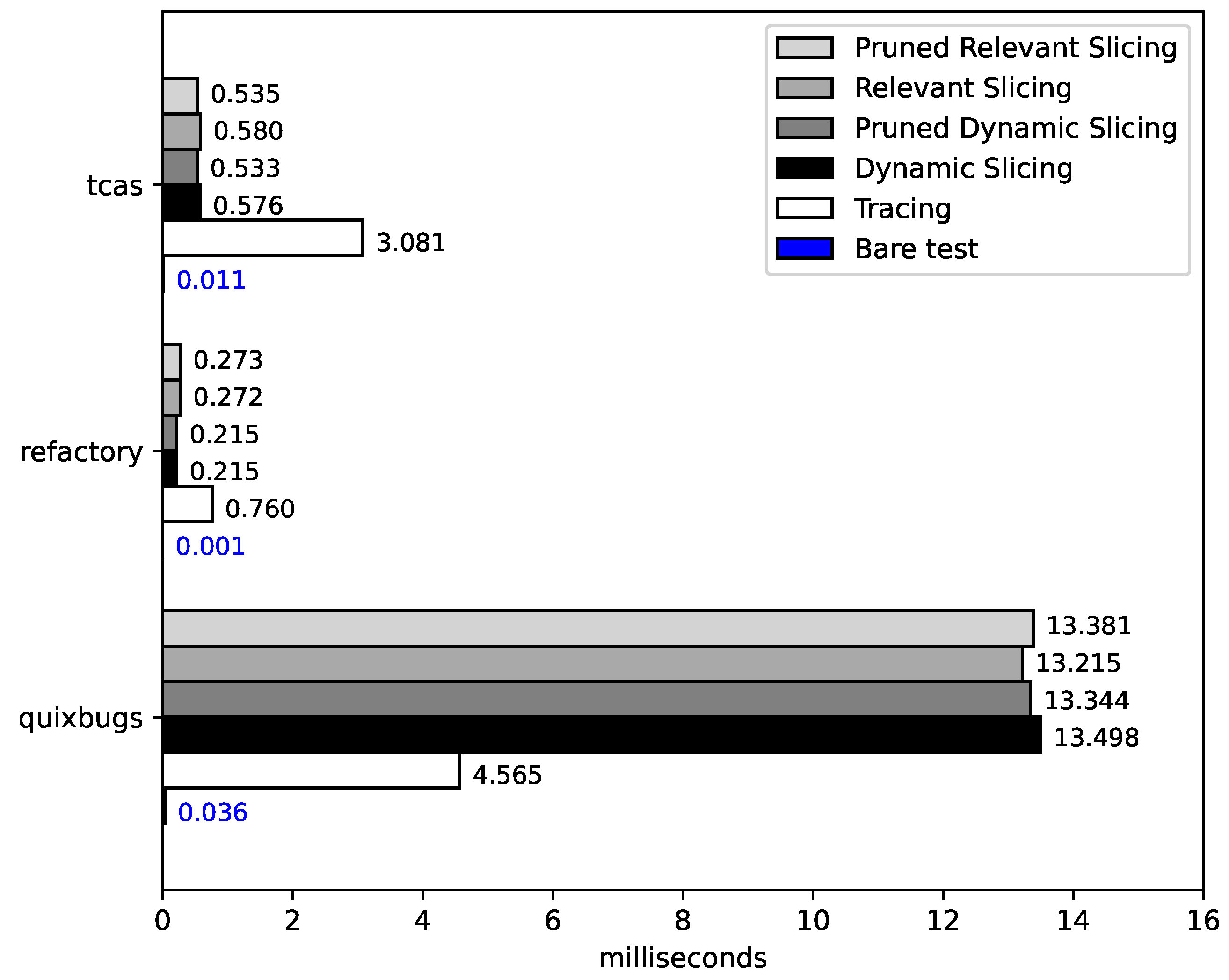
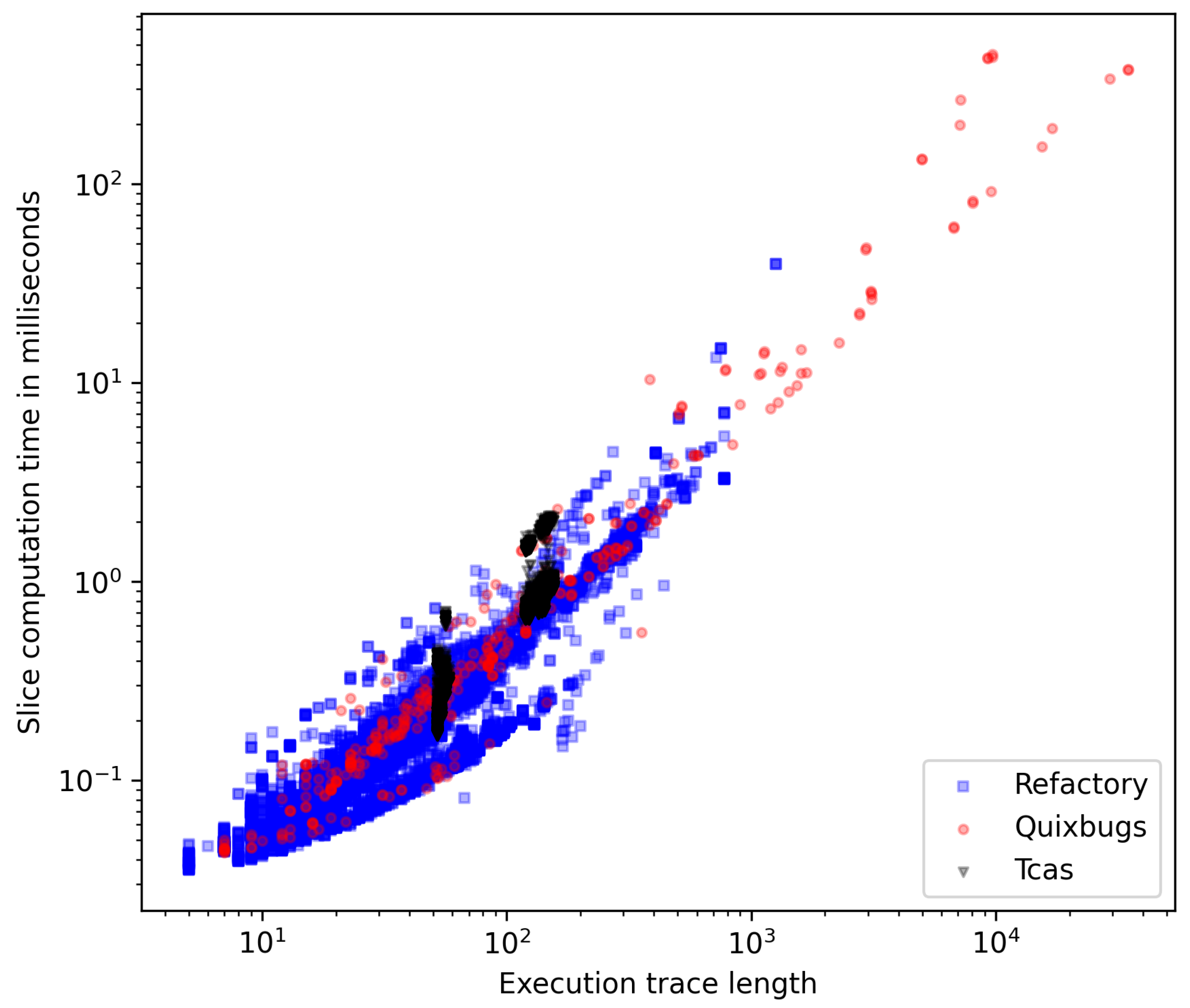
- RQ3: How much additional time is required for tracing and slicing compared to bare execution? What is the computation time overhead of relevant slicing compared to dynamic slicing? What is the computation time overhead of pruned slicing compared to dynamic and relevant slicing? Dynamic slicing requires that the execution of a program be traced. This comes with computation costs. Therefore, we analyze the time required for tracing and slicing and compare it with the bare execution time. Furthermore, we analyze whether relevant slicing and pruned slicing take longer than dynamic slicing.
7.2. Evaluation Metrics
7.3. Evaluation Environment and Evaluation Restrictions
7.4. Datasets
7.5. Results
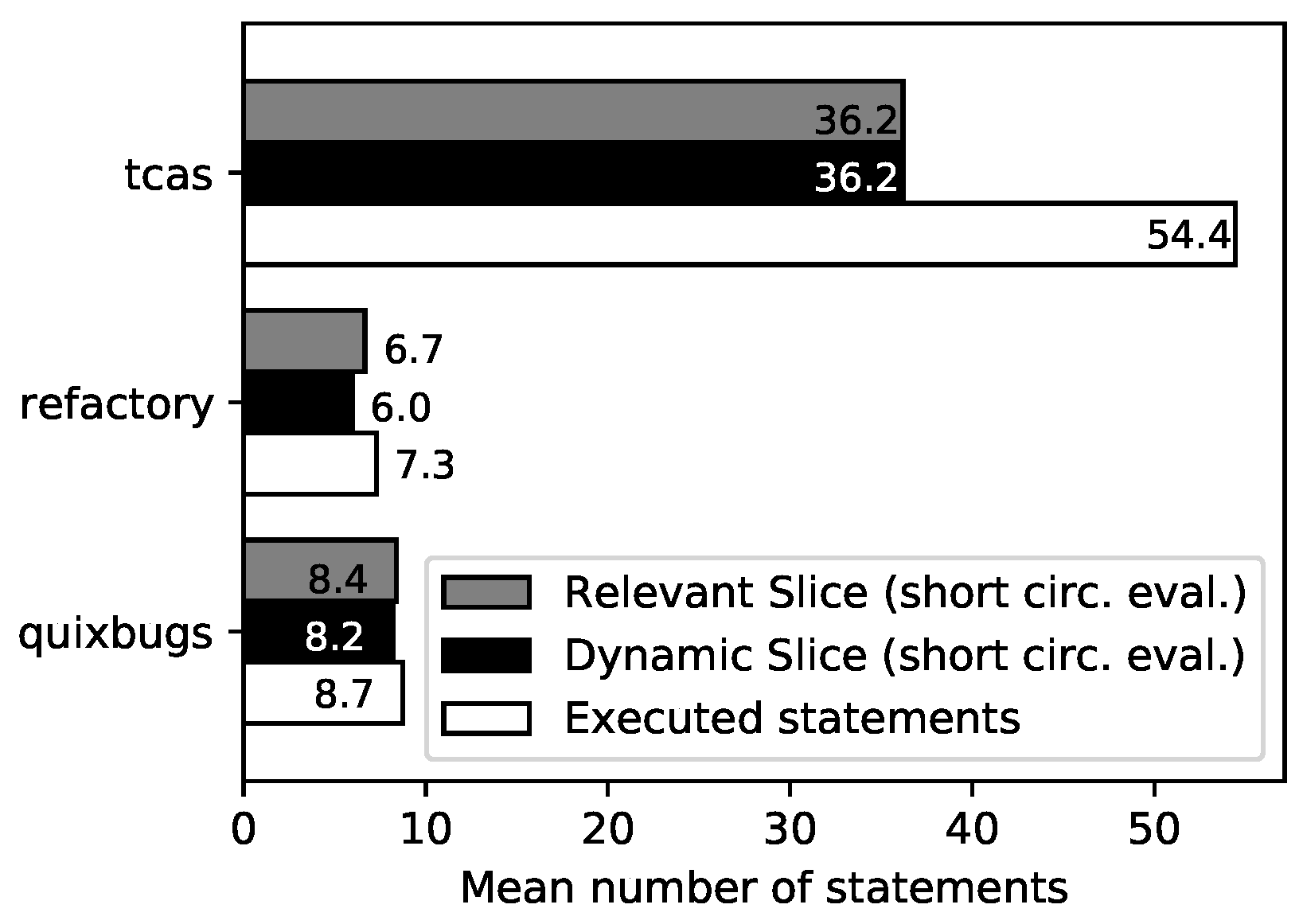
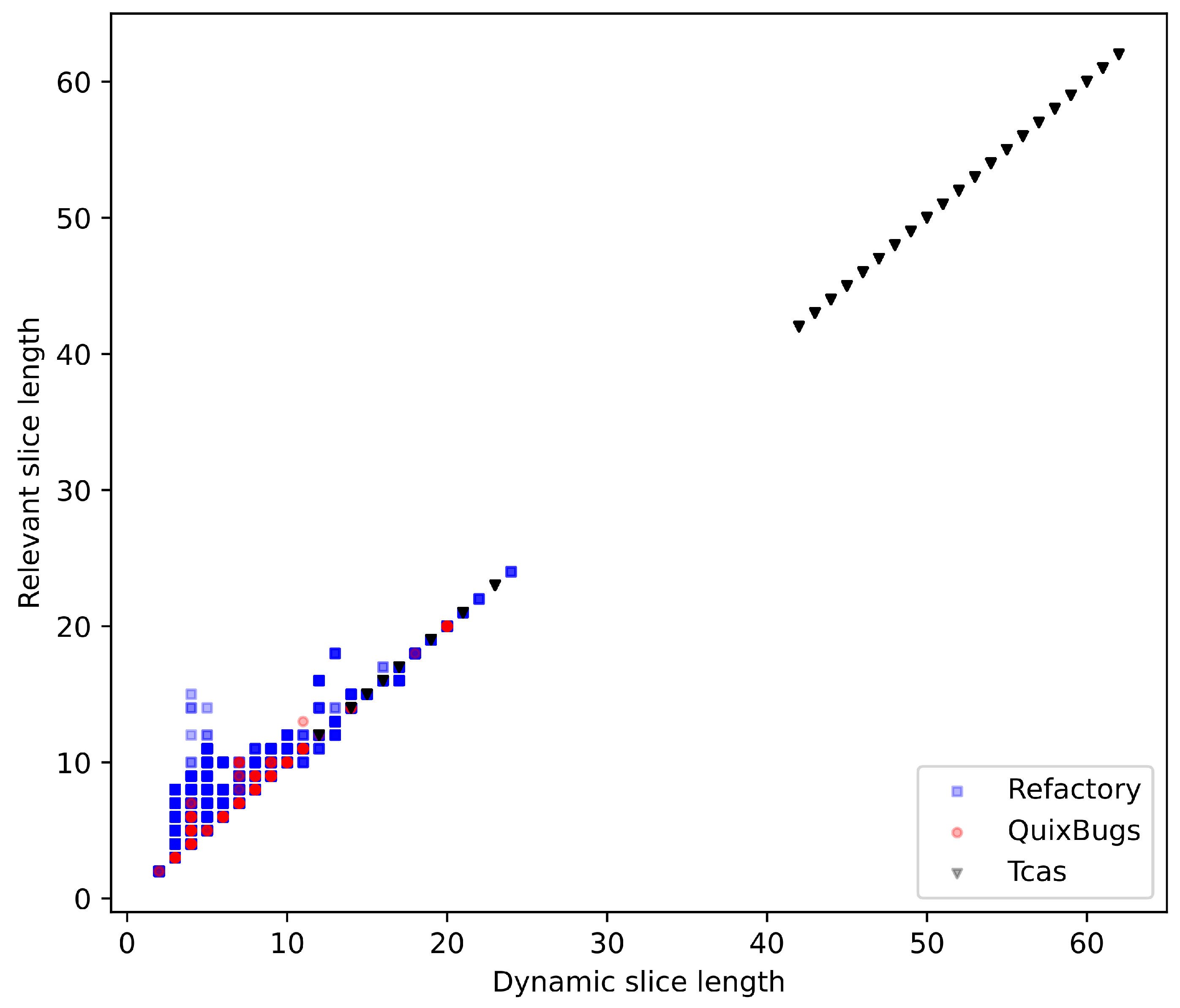
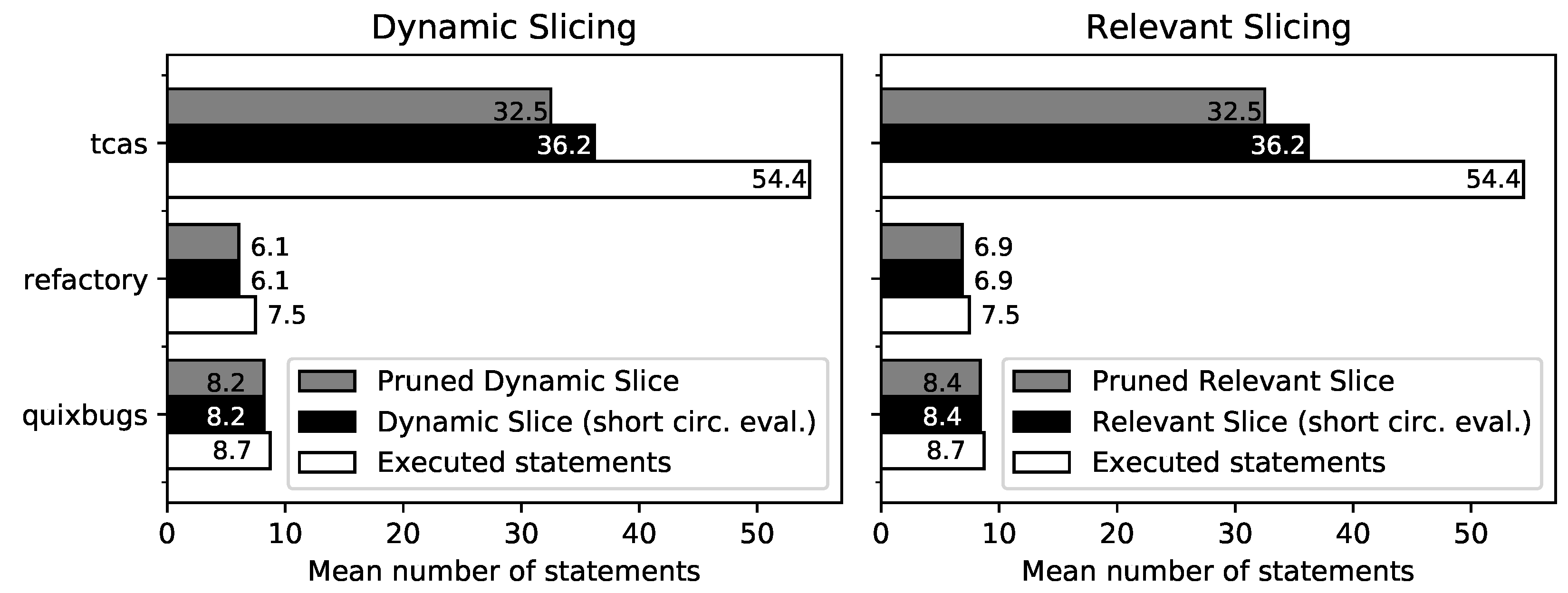
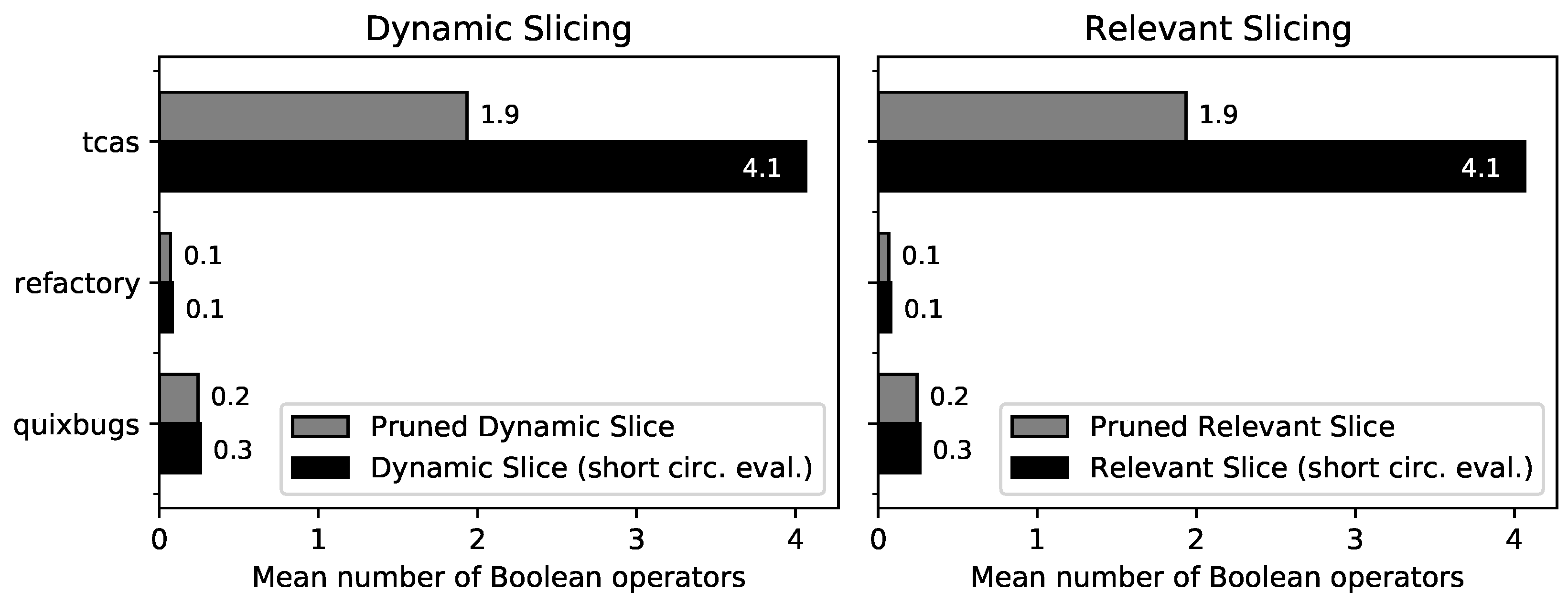
- The dynamic and relevant slices for TCAS are identical. This can be explained by the structure of TCAS: there are no loops, and the then and else branches of the conditionals change the same variable; therefore, relevant slicing has no impact.
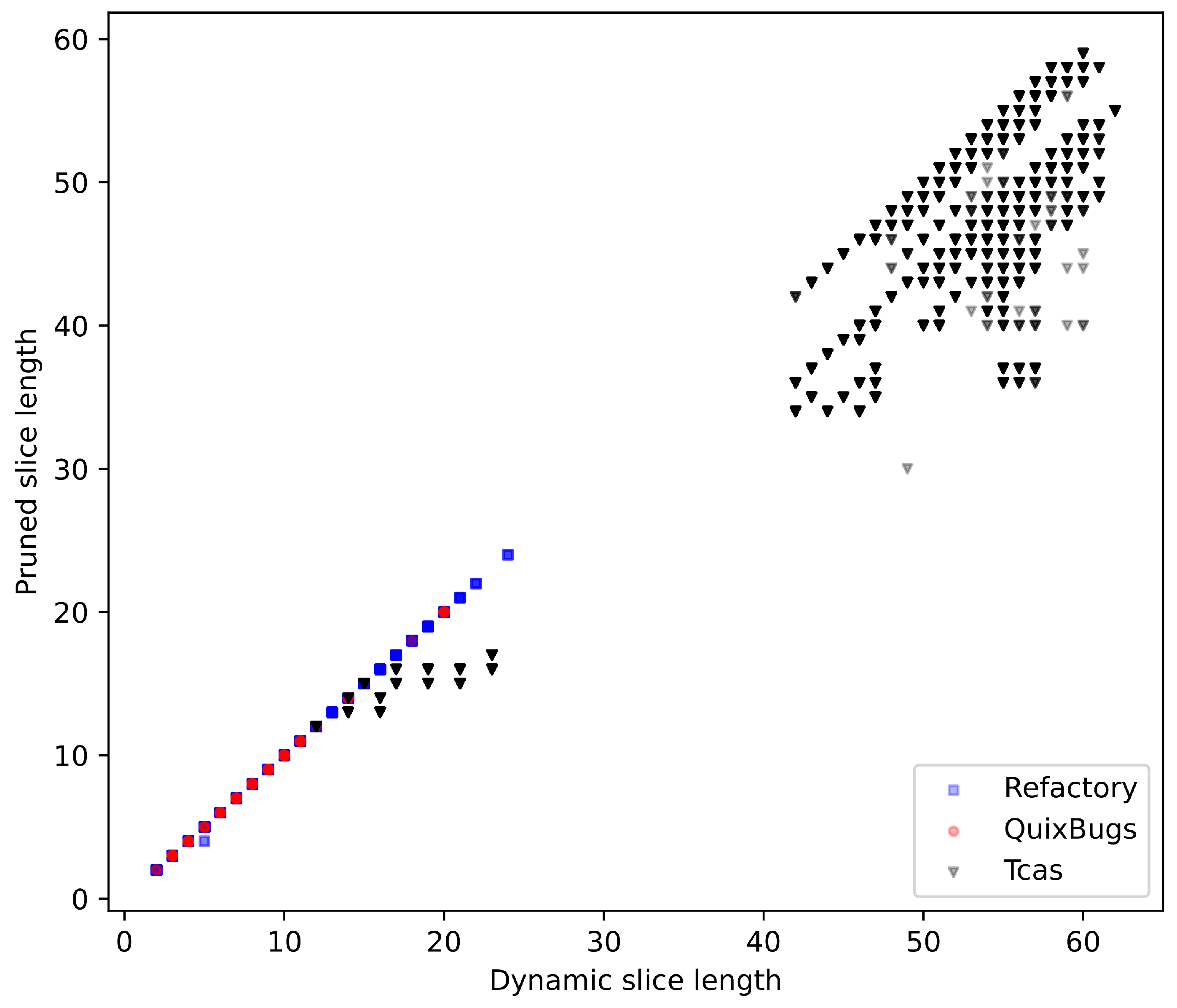
- For the Refactory dataset, relevant slicing eliminates the problem of non-terminating slices and reduces the number of slices where the sliced program computes a different result than the original program. However, the average size of the slice increases by 11.2%. For 65.9% of program/test case combinations, the relevant slice is identical to the dynamic slice; for 34.0%, the relevant slice is larger than the dynamic slice; and for 0.2%, it is smaller.
- For QuixBugs, the number of successfully sliced program/test case combinations stays the same, and the average slice size increases by 2.4%. For 87.7% of successfully sliced QuixBugs program/test case combinations, the relevant slice is identical to the dynamic slice, whereas for 12.3%, the size of the slice increases.
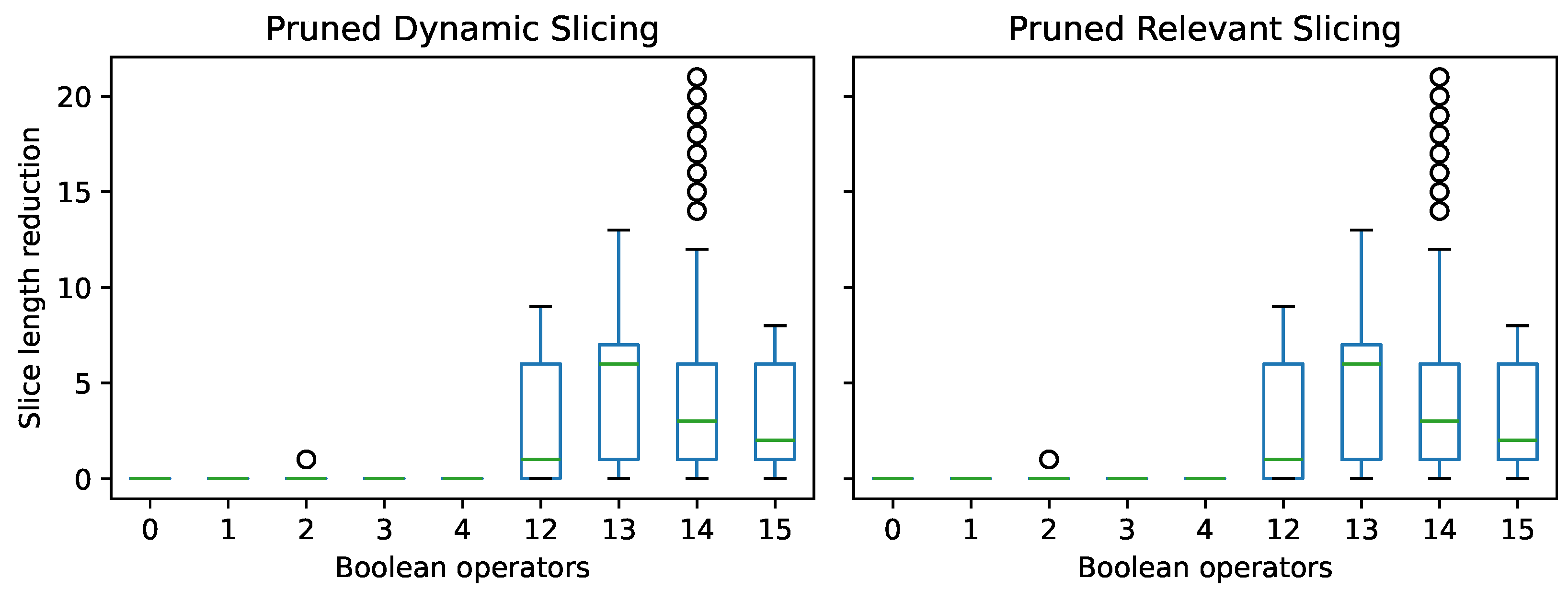
- Pruned slicing reduces the slice size for TCAS by 10.2%. There is no reduction for the Refactory dataset and QuixBugs because only a few Boolean operators are used.
- Pruning can decrease the size of the slice without ever increasing it.
- The more Boolean operators executed, the greater the achievable reduction through the use of pruned slicing.
- Pruned slicing can help reduce the number of Boolean sub-terms in the sliced program that need to be investigated by the developer.
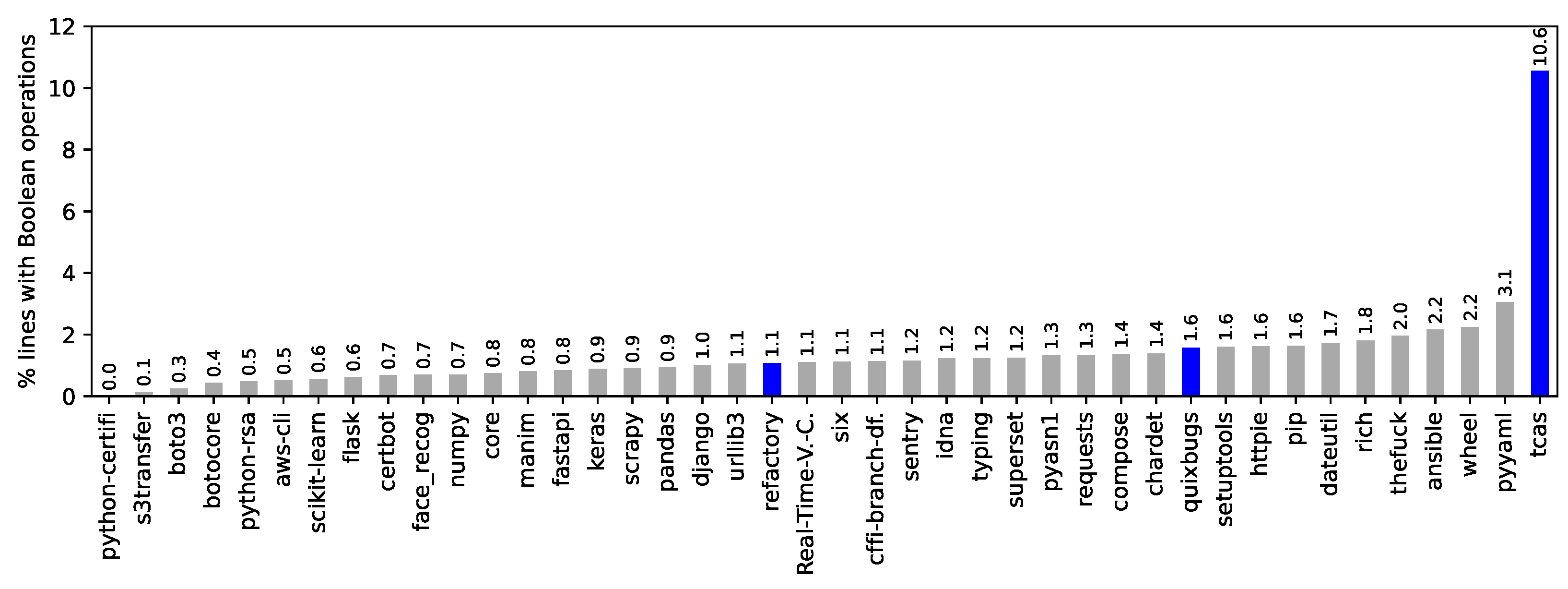
- The 40 investigated Python projects show a similar frequency of Boolean operators as the Refactory dataset and QuixBugs but are substantially bigger in terms of LOC.
- Tracing and slice computation takes orders of magnitude longer than the bare execution.
- The different slicing techniques have similar computation times.
- The time span required for slicing correlates with the length of the execution trace.
7.6. Threats to Validity
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Weiser, M. Program Slicing. IEEE Trans. Softw. Eng. 1984, SE-10, 352–357. [Google Scholar] [CrossRef]
- Soha, P.A.; Gergely, T.; Horváth, F.; Vancsics, B.; Beszédes, Á. A Case Against Coverage-Based Program Spectra. In Proceedings of the IEEE Conference on Software Testing, Verification and Validation (ICST), Porto de Galinhas, Brazil, 12–16 April 2023; IEEE: New York, NY, USA, 2023; pp. 13–24. [Google Scholar] [CrossRef]
- Beizer, B. Software Testing Techniques, 2nd ed.; ITP Media: Yas South Abu Dhabi, United Arab Emirates, 1990; p. 580. [Google Scholar]
- Hirsch, T.; Hofer, B. What we can learn from how programmers debug their code. In Proceedings of the 8th International Workshop on Software Engineering Research and Industrial Practice (SER-IP), Madrid, Spain, 4 June 2021; pp. 37–40. [Google Scholar] [CrossRef]
- Korel, B.; Laski, J. Dynamic program slicing. Inf. Process. Lett. 1988, 29, 155–163. [Google Scholar] [CrossRef]
- Agrawal, H.; Horgan, J.; Krauser, E.; London, S. Incremental regression testing. In Proceedings of the Conference on Software Maintenance, Montreal, QC, Canada, 27–30 September 1993; pp. 348–357. [Google Scholar] [CrossRef]
- Pandas. Base.py. Available online: https://github.com/pandas-dev/pandas/blob/a00154dcfe5057cb3fd86653172e74b6893e337d/pandas/core/indexes/base.py (accessed on 11 March 2024).
- Steindl, C. Program Slicing for Programming Languages. Ph.D. Thesis, Johannes Kepler University, Linz, Austria, 1999. [Google Scholar]
- Lin, D.; Chen, A.; Koppel, J.; Solar-Lezama, A. QuixBugs: A Multi-Lingual Program Repair Benchmark Set Based on the Quixey Challenge. In Proceedings of the ACM SIGPLAN International Conference on Systems, Programming, Languages, and Applications: Software for Humanity (SPLASH Companion), Vancouver, BC, Canada, 23–27 October 2017; pp. 55–56. [Google Scholar] [CrossRef]
- Hu, Y.; Ahmed, U.Z.; Mechtaev, S.; Leong, B.; Roychoudhury, A. Re-factoring based program repair applied to programming assignments. In Proceedings of the 34th International Conference on Automated Software Engineering (ASE), San Diego, CA, USA, 11–15 November 2019; pp. 388–398. [Google Scholar] [CrossRef]
- Hutchins, M.; Foster, H.; Goradia, T.; Ostrand, T. Experiments on the effectiveness of dataflow- and control-flow-based test adequacy criteria. In Proceedings of the 16th International Conference on Software Engineering (ICSE), Sorrento, Italy, 16–21 May 1994; pp. 191–200. [Google Scholar] [CrossRef]
- Hirsch, T.; Hofer, B. Pruning Boolean Expressions to Shorten Dynamic Slices. In Proceedings of the 22nd International Working Conference on Source Code Analysis and Manipulation (SCAM), Limassol, Cyprus, 3–4 October 2022; IEEE: New York, NY, USA, 2022; pp. 1–11. [Google Scholar] [CrossRef]
- Bergeretti, J.F.; Carré, B.A. Information-flow and data-flow analysis of while-programs. ACM Trans. Program. Lang. Syst. 1985, 7, 37–61. [Google Scholar] [CrossRef]
- Li, X.; Orso, A. More Accurate Dynamic Slicing for Better Supporting Software Debugging. In Proceedings of the 13th International Conference on Software Testing, Verification and Validation (ICST 2020), Porto, Portugal, 24–28 October 2020; pp. 28–38. [Google Scholar] [CrossRef]
- Agrawal, H.; Demillo, R.A.; Spafford, E.H. Efficient Debugging with Slicing and Backtracking; Technical Report; Purdue University: West Lafayette, IN, USA, 1990. [Google Scholar]
- Tip, F. A Survey of Program Slicing Techniques. J. Program. Lang. 1995, 3, 121–189. [Google Scholar]
- Silva, J. A vocabulary of program slicing-based techniques. ACM Comput. Surv. 2012, 44, 1–41. [Google Scholar] [CrossRef]
- Wong, W.E.; Gao, R.; Li, Y.; Abreu, R.; Wotawa, F. A Survey on Software Fault Localization. IEEE Trans. Softw. Eng. 2016, 42, 707–740. [Google Scholar] [CrossRef]
- Hammacher, C. Design and Implementation of an Efficient Dynamic Slicer for Java. Bachelor’s Thesis, University of Saarland, Saarbrucken, Germany, 2008. [Google Scholar]
- Ahmed, K.; Lis, M.; Rubin, J. Slicer4J: A dynamic slicer for Java. In Proceedings of the 29th ACM Joint Meeting European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), Athens, Greece, 23–28 August 2021; pp. 1570–1574. [Google Scholar] [CrossRef]
- Ahmed, K.; Lis, M.; Rubin, J. Mandoline: Dynamic Slicing of Android Applications with Trace-Based Alias Analysis. In Proceedings of the IEEE 14th International Conference on Software Testing, Verification and Validation (ICST 2021), Valencia, Spain, 4–13 April 2021; pp. 105–115. [Google Scholar] [CrossRef]
- Galindo, C.; Perez, S.; Silva, J. A Program Slicer for Java (Tool Paper). In Proceedings of the Software Engineering and Formal Methods, Berlin, Germany, 26–30 September 2022; pp. 146–151. [Google Scholar] [CrossRef]
- Galindo, C.; Pérez, S.; Silva, J. Program slicing of Java programs. J. Log. Algebr. Methods Program. 2023, 130, 100826. [Google Scholar] [CrossRef]
- Nguyen, H.V.; Kästner, C.; Nguyen, T.N. Cross-language program slicing for dynamic web applications. In Proceedings of the 10th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), Lisbon, Portugal, 5–9 September 2015; pp. 369–380. [Google Scholar] [CrossRef]
- Stiévenart, Q.; Binkley, D.W.; Roover, C.D. Static stack-preserving intra-procedural slicing of webassembly binaries. In Proceedings of the 44th International Conference on Software Engineering (ICSE ’22), Pittsburgh, PA, USA, 22–27 May 2022; pp. 2031–2042. [Google Scholar] [CrossRef]
- Galindo, C.; Pérez, S.; Silva, J. Exception-sensitive program slicing. J. Log. Algebr. Methods Program. 2023, 130, 100832. [Google Scholar] [CrossRef]
- Galindo, C.; Pérez, S.; Silva, J. Program Slicing Techniques with Support for Unconditional Jumps. In Proceedings of the 23rd International Conference on Formal Engineering Methods (ICFEM 2022), Madrid, Spain, 24–27 October 2022; pp. 123–139. [Google Scholar] [CrossRef]
- Nanda, M.G.; Ramesh, S. Interprocedural slicing of multithreaded programs with applications to Java. ACM Trans. Program. Lang. Syst. 2006, 28, 1088–1144. [Google Scholar] [CrossRef]
- Galindo, C.; Llorens, M.; Pérez, S.; Silva, J. Slicing Shared-Memory Concurrent Programs The Threaded System Dependence Graph Revisited. In Proceedings of the IEEE International Conference on Software Maintenance and Evolution (ICSME), Bogota, Colombia, 1–6 October 2023; pp. 73–83. [Google Scholar] [CrossRef]
- Ghosh, D.; Singh, J. A dynamic slicing-based approach for effective SBFL technique. Int. J. Comput. Sci. Eng. 2021, 24, 98–107. [Google Scholar] [CrossRef]
- Soremekun, E.; Kirschner, L.; Böhme, M.; Zeller, A. Locating Faults with Program Slicing: An Empirical Analysis. arXiv 2021, arXiv:2101.03008. [Google Scholar] [CrossRef]
- Messaoudi, S.; Shin, D.; Panichella, A.; Bianculli, D.; Briand, L.C. Log-Based Slicing for System-Level Test Cases. In Proceedings of the International Symposium on Software Testing and Analysis (ISSTA), Aarhus, Denmark, 12–16 July 2021; pp. 517–528. [Google Scholar]
- de Vos, M.; Pouwelse, J. ASTANA: Practical String Deobfuscation for Android Applications Using Program Slicing. arXiv 2021, arXiv:2104.02612. [Google Scholar]
- Wang, S.; Wang, X.; Sun, K.; Jajodia, S.; Wang, H.; Li, Q. GraphSPD: Graph-Based Security Patch Detection with Enriched Code Semantics. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–25 May 2023; pp. 2409–2426. [Google Scholar] [CrossRef]
- Zhang, Z.; Lei, Y.; Yan, M.; Mao, X.; Su, T.; Yu, Y. Influential Global and Local Contexts Guided Trace Representation for Fault Localization. ACM Trans. Softw. Eng. Methodol. 2022, 1, 27. [Google Scholar] [CrossRef]
- Home Assistant: Network.py. Available online: https://github.com/home-assistant/core/blob/1242456ff1fc8f70ff48503f91d6d54d9a46cfbc/homeassistant/helpers/network.py (accessed on 11 March 2024).
- Python Documentation: Abstract Syntax Tree. Available online: https://docs.python.org/3/library/ast.html (accessed on 11 March 2024).
- Segura, S.; Fraser, G.; Sanchez, A.B.; Ruiz-Cortes, A. A Survey on Metamorphic Testing. IEEE Trans. Softw. Eng. 2016, 42, 805–824. [Google Scholar] [CrossRef]
- Python Documentation: Timeit—Measure Execution Time of Small Code Snippets. Available online: https://docs.python.org/3/library/timeit.html (accessed on 11 March 2024).
- Majd, A.; Vahidi-Asl, M.; Khalilian, A.; Baraani-Dastjerdi, A.; Zamani, B. Code4Bench: A multidimensional benchmark of Codeforces data for different program analysis techniques. J. Comput. Lang. 2019, 53, 38–52. [Google Scholar] [CrossRef]
- Tomassi, D.A.; Dmeiri, N.; Wang, Y.; Bhowmick, A.; Liu, Y.C.; Devanbu, P.T.; Vasilescu, B.; Rubio-Gonzalez, C. BugSwarm: Mining and Continuously Growing a Dataset of Reproducible Failures and Fixes. In Proceedings of the International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 339–349. [Google Scholar] [CrossRef]
- Radu, A.; Nadi, S. A dataset of non-functional bugs. In Proceedings of the International Working Conference on Mining Software Repositories (MSR), Montreal, QC, Canada, 26–27 May 2019; pp. 399–403. [Google Scholar] [CrossRef]
- Reis, S.; Abreu, R. SECBENCH: A Database of Real Security Vulnerabilities. In Proceedings of the International Workshop on Secure Software Engineering in DevOps and Agile Development (SecSE), Oslo, Norway, 11–15 September 2017; pp. 70–85. [Google Scholar]
- Widyasari, R.; Sim, S.Q.; Lok, C.; Qi, H.; Phan, J.; Tay, Q.; Tan, C.; Wee, F.; Tan, J.E.; Yieh, Y.; et al. BugsInPy: A database of existing bugs in Python programs to enable controlled testing and debugging studies. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), New York, NY, USA, 8–13 November 2020; pp. 1556–1560. [Google Scholar] [CrossRef]
- PyPiStats: Most Downloaded PyPI Packages. Available online: https://pypistats.org/top (accessed on 1 June 2021).
- GitHub Topics: Python. Available online: https://github.com/topics/python?l=python&o=desc&s=stars (accessed on 1 June 2021).
- Sawilowsky, S.S. New Effect Size Rules of Thumb. J. Mod. Appl. Stat. Methods 2009, 8, 597–599. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Xi | T (Xi) | D (Xi) | U (Xi) | C (Xi) |
|---|---|---|---|---|
| A | {a} | {x} | { } | |
| A | {b} | {y} | { } | |
| A | {c} | {z} | { } | |
| A | {d} | {y} | { } | |
| C | { } | {a, b, c, d} | { } | |
| A | {c} | {a} | {5} | |
| C | { } | {b, c} | { } | |
| A | {d} | {c} | { } |
| Benchmark | TCAS | Refactory | QuixBugs |
|---|---|---|---|
| Base programs | 1 | 5 | 31 |
| LOC | 91–100 | 3–115 | 6–23 |
| Correct program versions | 1 | 1230 | 31 |
| Faulty program versions | 37 | 2795 | 31 |
| Test cases | 1545 | 4–17 | 3–14 |
| Avg. Num. Boolean expressions | 14.00 | 0.20 | 0.34 |
| Boolean operations | 12–15 | 0–4 | 0–2 |
| Benchmark | TCAS | Refactory | QuixBugs |
|---|---|---|---|
| Successfully executed and traced | 58,710 | 20,836 | 374 |
| Not executable | - | 3144 | 64 |
| Not supported | - | 1161 | 28 |
| Timeout during tracing | - | - | 18 |
| Benchmark | TCAS | Refactory | QuixBugs | |||
|---|---|---|---|---|---|---|
| Slice Type (D = Dynamic, R = Relevant) | D | R | D | R | D | R |
| Successfully sliced | 58,710 | 58,710 | 19,683 | 20,728 | 367 | 367 |
| Timeout executing the sliced program | - | - | 1044 | - | 6 | 6 |
| Other Exception | - | - | 76 | 83 | 1 | 1 |
| Sliced result differs from original | - | - | 33 | 25 | - | - |
| Benchmark | TCAS | Refactory | QuixBugs |
|---|---|---|---|
| Greater | - | 6678 | 45 |
| Equal | 58,710 | 12,955 | 322 |
| Smaller | - | 36 | - |
| TCAS | Refactory | QuixBugs | |
|---|---|---|---|
| Dynamic Slicing | |||
| Greater | - | - | - |
| Equal | 14,107 | 19,681 | 367 |
| Smaller | 44,603 | 2 | - |
| Relevant Slicing | |||
| Greater | - | - | - |
| Equal | 14,107 | 20,726 | 367 |
| Smaller | 44,603 | 2 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hirsch, T.; Hofer, B. Reducing the Length of Dynamic and Relevant Slices by Pruning Boolean Expressions. Electronics 2024, 13, 1146. https://doi.org/10.3390/electronics13061146
Hirsch T, Hofer B. Reducing the Length of Dynamic and Relevant Slices by Pruning Boolean Expressions. Electronics. 2024; 13(6):1146. https://doi.org/10.3390/electronics13061146
Chicago/Turabian StyleHirsch, Thomas, and Birgit Hofer. 2024. "Reducing the Length of Dynamic and Relevant Slices by Pruning Boolean Expressions" Electronics 13, no. 6: 1146. https://doi.org/10.3390/electronics13061146