1. Introduction
Individuals are susceptible to falls due to instability in their lower extremities and limited joint mobility during daily activities [
1]. The likelihood and severity of falls are particularly high in individuals over the age of 65, with 30–40% experiencing at least one fall per year. These falls can result in fractures or other long-term health issues, which can cause significant physical and psychological injury [
2,
3,
4]. Injuries sustained by older adults from falls depend not only on the injuries incurred but also on the time interval between the onset of the fall and the receipt of help and treatment. Medical research has shown that timely assistance or treatment after a fall can reduce the risk of sequelae from later falls as well as accidental death [
5]. Providing timely assistance and treatment services for elderly individuals who live alone and have fallen at home is of significant social and practical importance. This ensures the safety and security of the elderly.
Currently, there are several methods for detecting human posture [
6] which can also recognize and detect falls. Wearable technology development can integrate sensors, wireless communication, and other technologies into wearable devices. These devices support various interaction methods, such as gesture and eye movement, to capture human body movement and posture information. They use multi-information data fusion to achieve the detection of human falls, resulting in high detection accuracy and real-time detection [
7,
8,
9,
10]. However, older people may forget to wear them after charging, which hinders prolonged detection due to the need for frequent recharging. Placing sensor nodes in a specific area to monitor changes in the human body’s center of gravity, movement trajectory, and position can provide valuable information about the body’s posture and overall situation [
11,
12,
13,
14]. However, deployment costs are high, and external environmental limitations and interference can be a challenge.
The utilization of cameras or other imaging devices for real-time acquisition of image information in a monitoring area, coupled with the application of deep learning techniques to analyze the acquired image data and determine human body movement postures, represents a current research focus [
15,
16]. Deep learning methods for analysis can be broadly categorized into two directions: two-stage and one-stage [
17]. Prominent examples of two-stage algorithms include R-CNN, Mask R-CNN [
18], R-FCN [
19], and Faster R-CNN [
20]. These approaches offer advantages such as high detection rates and low memory usage [
21,
22]. On the other hand, one-stage algorithms like the YOLO series [
23,
24,
25] and the SSD series perform candidate frame generation and classification in a single step. By dividing images into grids, these algorithms directly predict target categories and anchor frames on the images before obtaining final results through filtering and post-processing. Due to their lower computational requirements, one-stage algorithms are more suitable for real-time detection projects. Furthermore, recent advancements in the YOLO series have significantly improved target detection accuracy, establishing the one-stage algorithm as the mainstream choice for practical applications. Therefore, this paper selects YOLOv8 as its foundation to enhance fall detection in complex scenes.
The YOLOv8 model represents the latest advancement in the YOLO series, incorporating novel enhancements derived from YOLOv5 to optimize performance and flexibility, thereby rendering it more suitable for diverse target detection tasks. Comprising three key components—the backbone, neck network, and detection head—this model leverages the C2f module within its backbone network to effectively merge the C3 and ELAH structures, facilitating superior feature transfer and enhancing information utilization efficiency. Notably, the YOLOv8 detection head adopts a decoupled head approach by eliminating the objectness branch while retaining only classification and regression branches. This simplification significantly streamlines the model architecture. Additionally, an Anchor Free strategy is employed which eliminates reliance on predefined anchors; instead enabling adaptive learning of object size and position. Consequently, these advancements contribute to improved accuracy and robustness in object detection.
Lijuan Zhang et al. proposed DCF-YOLOv8, which leverages DenseBlock to enhance the C2f module and mitigate the influence of environmental factors [
26]. Haitong Lou et al. introduced DC-YOLOv8, employing deeper networks for the precise detection of small targets [
27]. Gui Xiangquan et al. incorporated the DepthSepConv lightweight convolution module into YOLOv8-L, integrated the BiFormer attention mechanism, and expanded the small target detection layer to achieve efficient detection of small targets [
28]. Cao Yiqi et al., in EFD-YOLO, substituted EfficientRep as a backbone network and introduced the FocalNeXt focus module to address occlusion issues to some extent while enhancing detection accuracy [
29].
To address the issue of low detection accuracy of the YOLOv8 algorithm in complex environments with target deformation, large changes in target scale, and occlusion, this paper proposes the ESD-YOLO model based on the YOLO algorithm. The model incorporates dynamic convolution, a dynamic detection head, and an exponential moving average to enhance the accuracy and robustness of fall detection in complex scenarios. This paper presents research on improving the YOLOv8 backbone network’s ability to capture target details and cope with target deformations. The proposed C2Dv3 module was incorporated into the network for this purpose. Additionally, the feature extraction ability of the detection model was improved by replacing the original detection head in the Neck section with the DyHead module. The proposed EASlideloss loss function aims to improve the model’s ability to handle hard sample problems. ESD-YOLO performed better in dim and blurred environments, with informative pictures, large-scale transformations, and occlusions, improving the accuracy and robustness of the fall detection model.
2. Materials and Methods
2.1. Overall Structure of ESD-YOLO Network
This paper proposed ESD-YOLO, a high-precision fall detection model for complex scenarios. It effectively addressed the problem of low detection accuracy caused by fall target deformation, occlusion, and high environmental overlap.
Figure 1 shows the overall structural model of ESD-YOLO.
The ESD-YOLO model combined the C2f module in the YOLOv8 backbone with the DCNv3 module. The dynamic convolutional layer replaced the convolutional layer in the Bottleneck in C2f, enhancing the backbone network’s ability to extract pose information of a falling character in a complex scene. The DyHead module was incorporated into the Neck section to consolidate multiple attention operations, resulting in improved performance of ESD-YOLO in complex fall detection scenarios. Additionally, EASlideloss, a slide loss function based on exponential moving average, was proposed to replace the original loss function of YOLOv8. This function dynamically balances the model’s attention to hard samples, thereby enhancing the model’s accuracy and stability.
2.2. C2Dv3 Module Design
Detecting falls in complex environments and a wide variety of poses presents a significant challenge. The C2f module in YOLOv8, which integrates low-level feature maps with high-level feature maps, encounters difficulties in recognizing falls under these circumstances. The C2f module may not effectively capture the intricate details of falling targets due to variations in human body postures, resulting in substantial changes in target size and shape. Moreover, the module is limited to sensing features within a fixed range and lacks the adaptability to adjust the sampling position of the convolution kernel dynamically, making it arduous to capture crucial information about falling targets comprehensively. Consequently, this led to decreased accuracy for target localization in complex environments and increased the likelihood of false detections.
To address the limitations of the C2f module in detecting falls with significant variations in scale and high environmental similarity, we introduced DCNv3 during the feature extraction stage. DCNv3 effectively captures comprehensive information surrounding the fall target within the sensory field and adapts to diverse sizes and shapes by dynamically adjusting convolution kernel shapes and positions [
30]. The deformable convolution operation in DCNv3 employs a learnable offset to govern the shape of each convolution kernel, thereby facilitating adaptive adjustment of the convolution operation based on diverse image regions and enhancing its perceptual capability. This enhancement enables a more precise capture of fall target details and features, thereby improving both the accuracy and robustness of our fall detection model. Consequently, it led to enhanced precision in detecting fall targets and increased reliability of the model even in complex scenarios.
The DCNv3 model enables adaptive modification of the convolution kernel shape based on the target content in the image. This flexible mapping enhances the coverage of the detected target appearance and captures a more comprehensive range of useful feature information [
30]. Equation (1) represents the expression for DCNv3.
Equation (1) defines as the number of groups, as the projection weights shared within each group, and as the normalized modulation factor of the Kth sampling point of the Gth group. DCNv3 exhibits superior adaptability to large-scale visual models compared to its counterparts in the same series, while also possessing stronger feature representation and a more stable training process.
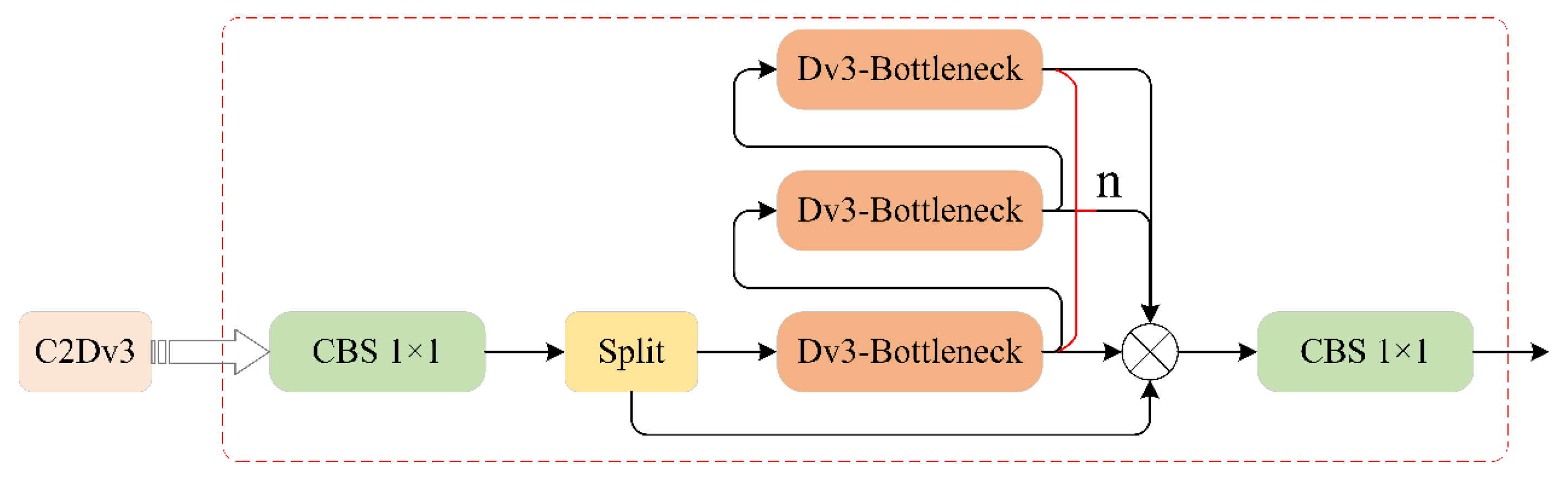
DCNv3 has negligible impact on the number of parameters or computational complexity of the model. However, excessive utilization of deformable convolutional layers can significantly increase computation time in practical applications. To ensure optimal performance without compromising functionality, only the standard convolutional layers within the Bottleneck of the C2f module in the backbone network were substituted with DCNv3 deformable convolutional layers, forming a compliant bottleneck module (Dv3_Bottleneck), as depicted in
Figure 2.
As illustrated in
Figure 3, the C2f module has been reconstructed using Dv3_Bottleneck, which comprises of convolution layer, separation layer, and Dv3_Bottleneck. The incorporation of C2Dv3 into the backbone network enhances its ability to capture crucial target features, thereby elevating target detection performance.
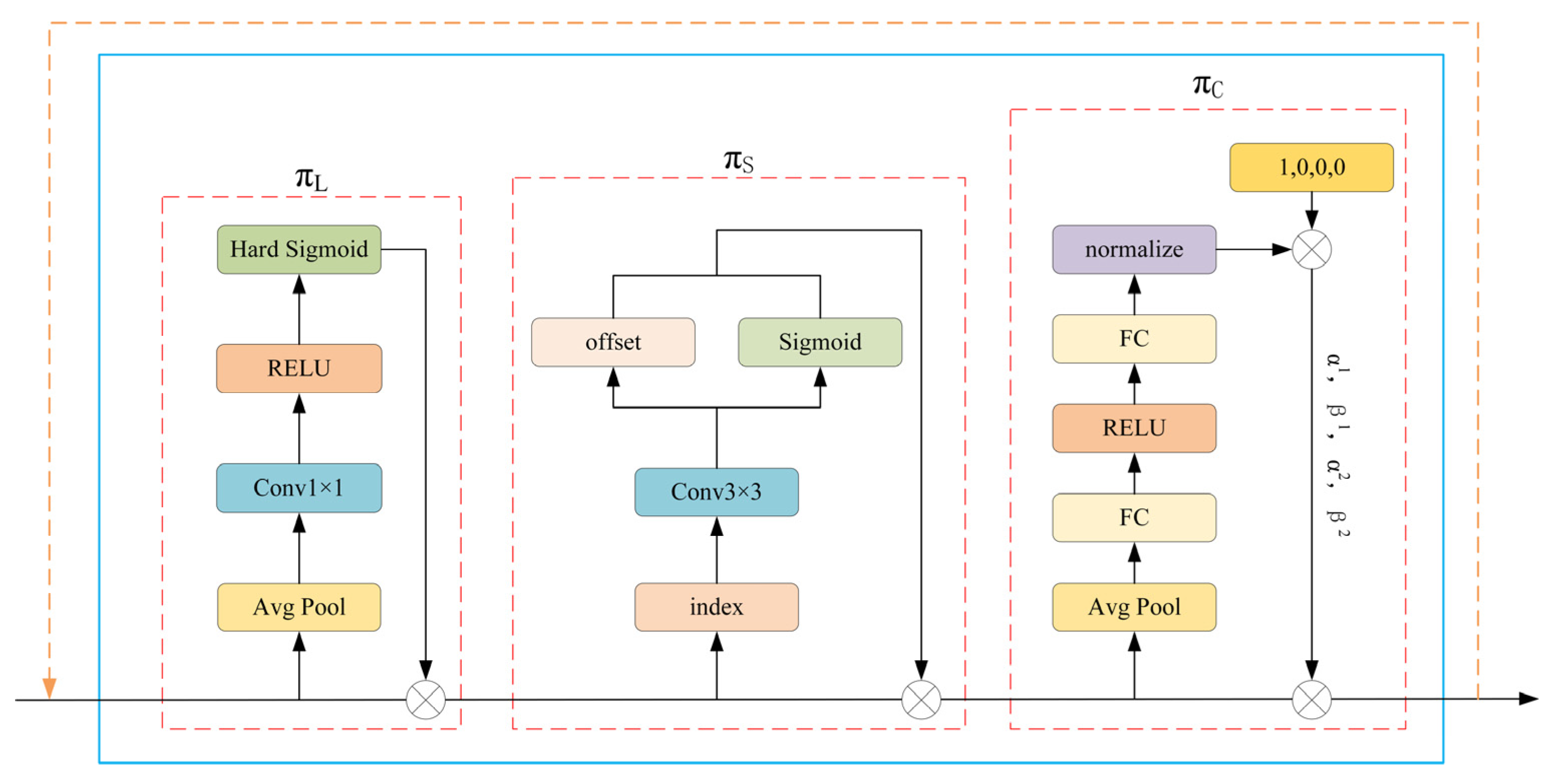
2.3. DyHead Module
To better integrate the diversity of feature scales resulting from variations in falling target scale and capture the inherent spatial relationships across different scales and shapes, this study replaced the original detection head of YOLOv8 with a dynamic detection head called DyHead (Dynamic Head). DyHead incorporates scale-aware attention, spatial-aware attention, and task-aware attention simultaneously [
31]. It employs a dynamic receptive field design that adaptively adjusts the convolution kernel size based on the size of the falling target. The DyHead model possesses the capability to integrate multiple attention mechanisms, thereby enabling the fusion of diverse information and mitigating the adverse effects caused by occlusion. This ensures effective detection of targets with varying scales and shapes while enhancing overall detection capability and optimizing computational efficiency. The calculation formula is presented in Equation (2).
The attention function is represented by the symbol
, and the feature tensor F is a three-dimensional tensor with dimensions of
. Here,
represents the level of the feature map,
represents the width-height product of the feature map, and
represents the number of channels in the feature map. The scale-aware attention module
, space-aware attention module
, and task-aware attention module
are, respectively, applied to each dimension of
,
, and
.
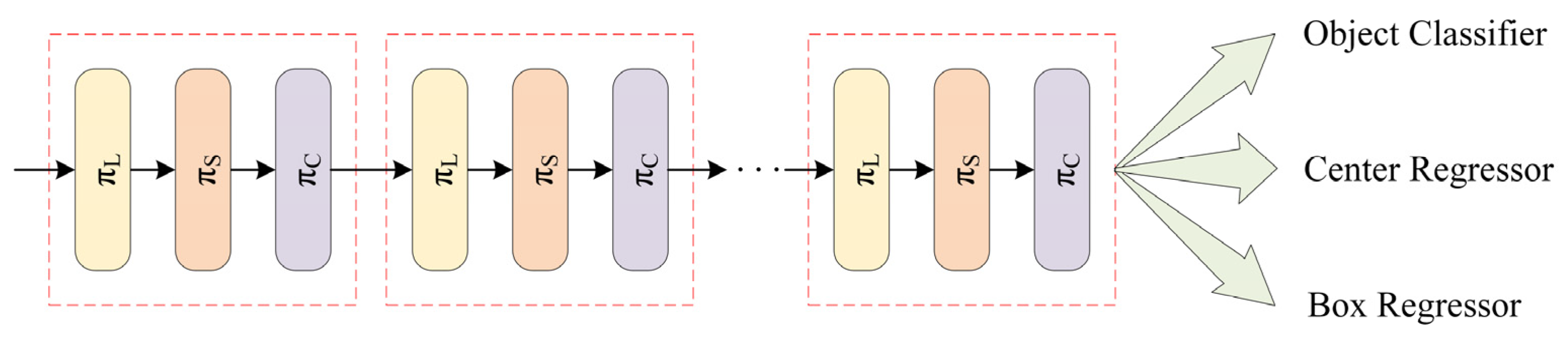
Figure 4 illustrates the structure of a single DyHead block.
The computational processes for each of the three attention modules are represented as follows:
In Equation (3), the linear function
is approximated using a 1 × 1 convolution operation. Herein,
serves as an activation function for this approximation process. Before introducing
as representing the number of sparse sampling positions in Equation (4), we explain that these positions enable focusing on discriminant locations through determining movable position
based on self-learning spatial displacement
. Moreover, we introduce
, denoting a self-learning importance scalar at position
which can be learned from input features at middle level
. Subsequently defined in Equation (5),
refers to the feature slice of channel C while
represents a superfunction employed for learning control activation threshold values. Sequentially applying these three attention mechanisms allows them to be stacked multiple times to form DyHead blocks, as depicted in
Figure 5.
2.4. Loss Function EASlideloss Design
The elderly population is more susceptible to falls in complex environments, and the fall detection model encounters challenges such as obscured fall objects, low ambient lighting, high environmental overlap, and diverse fall postures. These data present hard samples with a lower number of fall instances compared to non-fall instances, resulting in an imbalanced dataset. Without an appropriate loss function, the performance of the fall detection model in the target category is compromised, thereby affecting its accuracy and reliability in practical applications. YOLOv8′s original BCEwithloss (BCE) loss function solely focuses on accurate label prediction without addressing sample balancing when tackling the sample imbalance issue. Consequently, the model prioritizes non-fall instances over effectively identifying falling actions. To address this limitation, Slideloss incorporates a sliding window mechanism that adaptively learns threshold parameter μ for positive and negative samples. By assigning higher weights near μ, it amplifies relative loss for hard-classified samples while emphasizing misclassified ones [
32]. The implementation principle is illustrated by Equation (6).
The proposed EASlideloss in this paper is based on Slideloss, which integrates the exponential moving average (EMA) with the original Slideloss. By applying the exponential moving average method to weigh the value of the time series, we aim to mitigate the impact of sudden changes in adaptive threshold on loss and enhance both the accuracy and reliability of our model. Additionally, we gradually reduce the weight assigned to difficult samples, thereby diminishing the model’s attention towards them and preventing excessive interference caused by these challenging instances throughout the training process. The implementation principle is illustrated in Equations (7)–(9).
In Equation (7), the attenuation factor 0 < < 1 represents the weight distribution control for historical and latest data when calculating the average value, where denotes the attenuation coefficient. The variable represents the current training round, while is a hyperparameter. In Equation (8), signifies the previous time’s average index value, and represents the current time’s data.
2.5. Model Evaluation Metrics
The evaluation metrics employed in this study to assess the performance of the fall detection model include Precision (P), Recall (R), and Average Precision (AP). AP quantifies the detector’s performance within each category, while the mean average precision (mAP) is obtained by averaging these AP values. mAP serves as a pivotal metric for evaluating the overall accuracy of object detection models and a reliable indicator of their performance.
4. Conclusions
The present study introduces ESD-YOLO, a high-precision algorithm for human fall detection in complex scenes. In comparison to the YOLOv8s model, it exhibits enhanced capabilities in addressing challenges encountered during fall tasks, including large target scale transformations, crowded environments with multiple individuals, and high levels of environmental fusion and occlusion. The main contributions of this paper can be summarized as follows:
The C2Dv3 module is proposed to redesign the backbone network of YOLOv8s, enhancing its feature extraction ability and enabling it to better capture details of falling human bodies and process complex features of falling targets.
DyHead replaces the original detection head of YOLOv8s, allowing the model to focus on potential position relationship features of falling targets in different scales and shapes in spatial positions.
EASlideloss loss function replaces the original BCE loss function of YOLOv8s, improving accuracy while ensuring stability by focusing on difficult fall samples and gradually reducing attention to them.
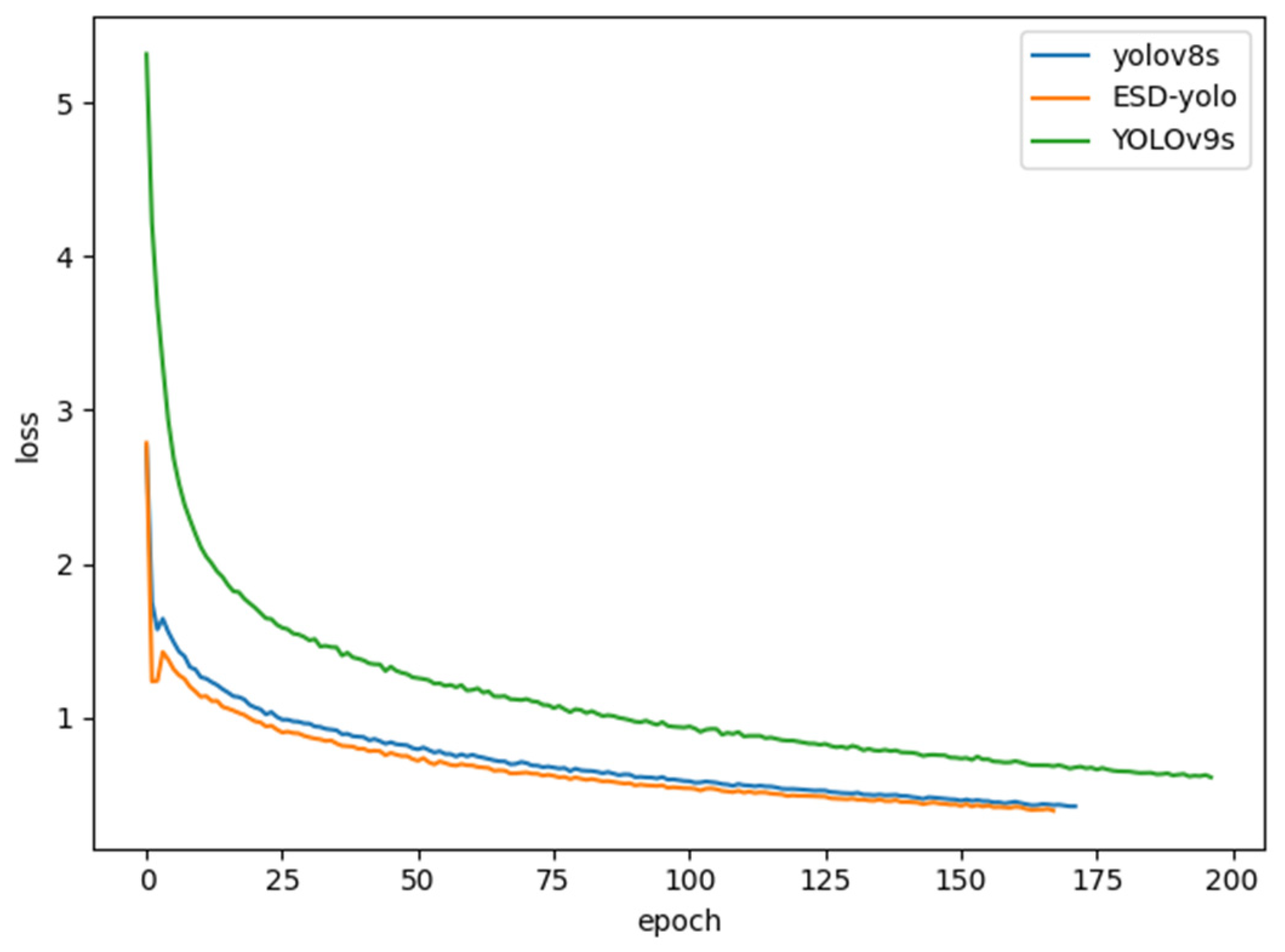
The experimental results on the self-constructed dataset demonstrate that ESD-YOLO achieves an accuracy of 84.2%, a recall of 82.5%, a mAP0.5 of 88.7%, and a mAP0.5:0.95 of 62.5%. In comparison with the original YOLOv8s model, ESD-YOLO exhibits improvements in accuracy, recall, mAP0.5, and mAP0.5:0.95 by 1.9%, 4.1%, 4.3%, and 2.8%, respectively. The comprehensive fall detection experiments validate that ESD-YOLO possesses an efficient architecture and superior detection accuracy, thereby meeting the real-time fall detection requirements effectively. Furthermore, when compared to existing fall detection models, ESD-YOLO offers enhanced detection accuracy for various complex fall scenarios. In summary, ESD-YOLO enhances the accuracy of human fall detection and enables real-time identification and alerting of falls. It facilitates timely detection of elderly individuals experiencing falls and transmits alarm information to their caregivers through various communication channels, thereby enabling prompt intervention. Future research directions should focus on reducing model parameters to facilitate its deployment on mobile devices, making it applicable in real-world scenarios.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}