
A Novel Distributed Adaptive Controller for Multi-Agent Systems with Double-Integrator Dynamics: A Hedging-Based Approach

Abstract
:1. Introduction
- (1)
- Designing a novel distributed adaptive control algorithm and a novel hedging-based reference model for multi-agent systems with double-integrator dynamics that uses position and velocities in the control law, which highly increases transient performance since it yields a faster update and enlarges the feasible actuator bandwidth set that increases the overall system performance and robustness.
- (2)
- Provides the first result for distributed adaptive control with double-integrator type multi-agent systems to deal with uncertainty, unknown control effectiveness, and actuator dynamics altogether. The proposed controller also yields a faster response, and hence, better performance while providing a level of robustness due to not needing a distributed signal integration. To show these advantages, we compare our performance results with the control algorithm developed in [31] in Section 4 of this paper.
- (3)
- Utilizing a compact form for both system dynamics and controller for all agents for investigating stability via Lyapunov Stability Theory and Linear Matrix Inequalities. This compact form enables extending controller design and stability analysis for systems with even higher than second-order dynamics (which can include acceleration, jerk, etc.) without any changes in Lyapunov-based stability analysis. For detailed information on this item, please see Remark 3 in Section 3.
- (4)
- Avoiding one of the assumptions that current high-order multi-agent distributed adaptive control literature is required for the boundedness of the reference model (see, for example, Assumption 3.1. of [31]).
2. Notation and Mathematical Preliminaries
3. Main Results
3.1. Proposed Control Design
3.2. Proposed Distributed Control
3.3. Theoretical Results
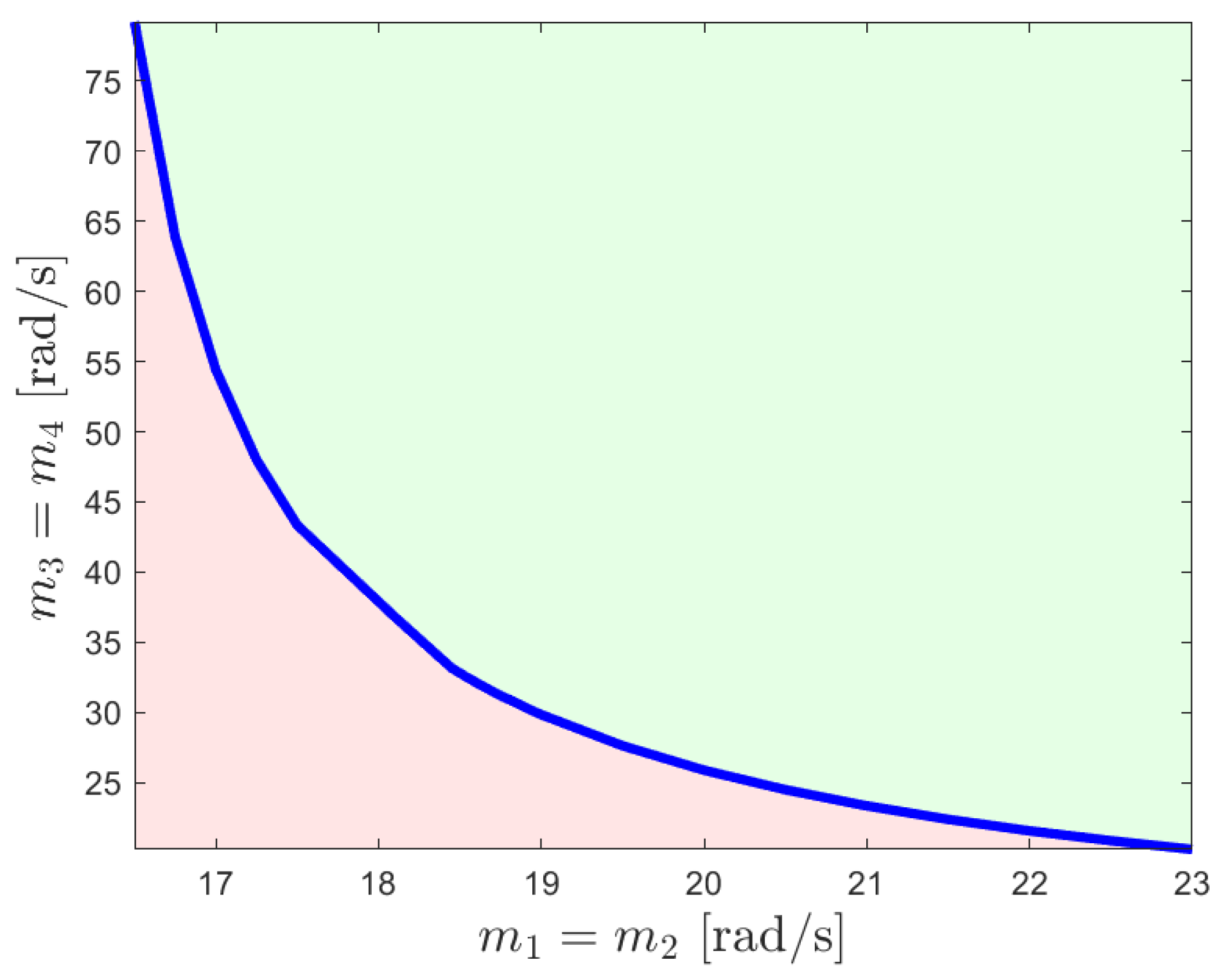
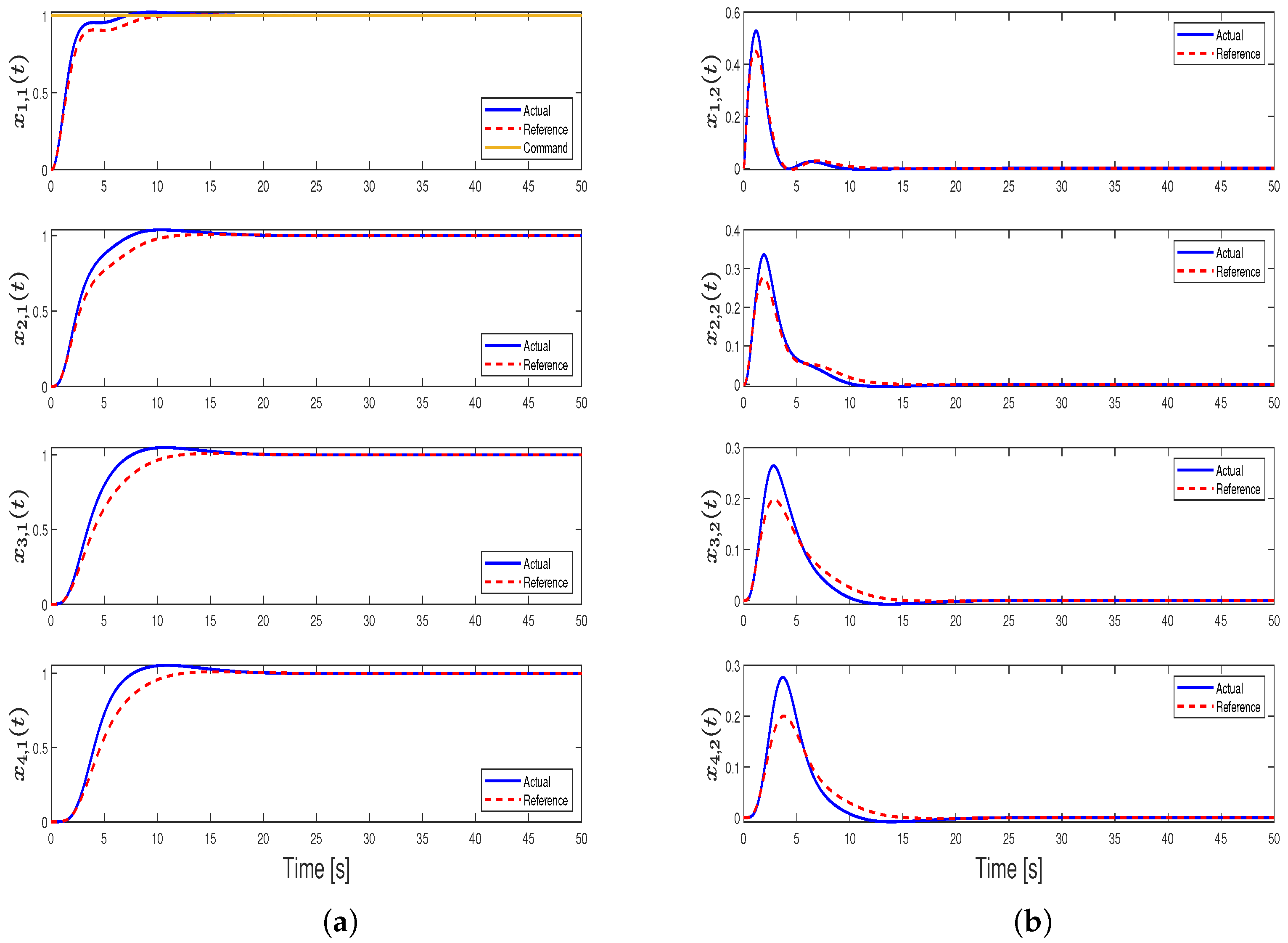
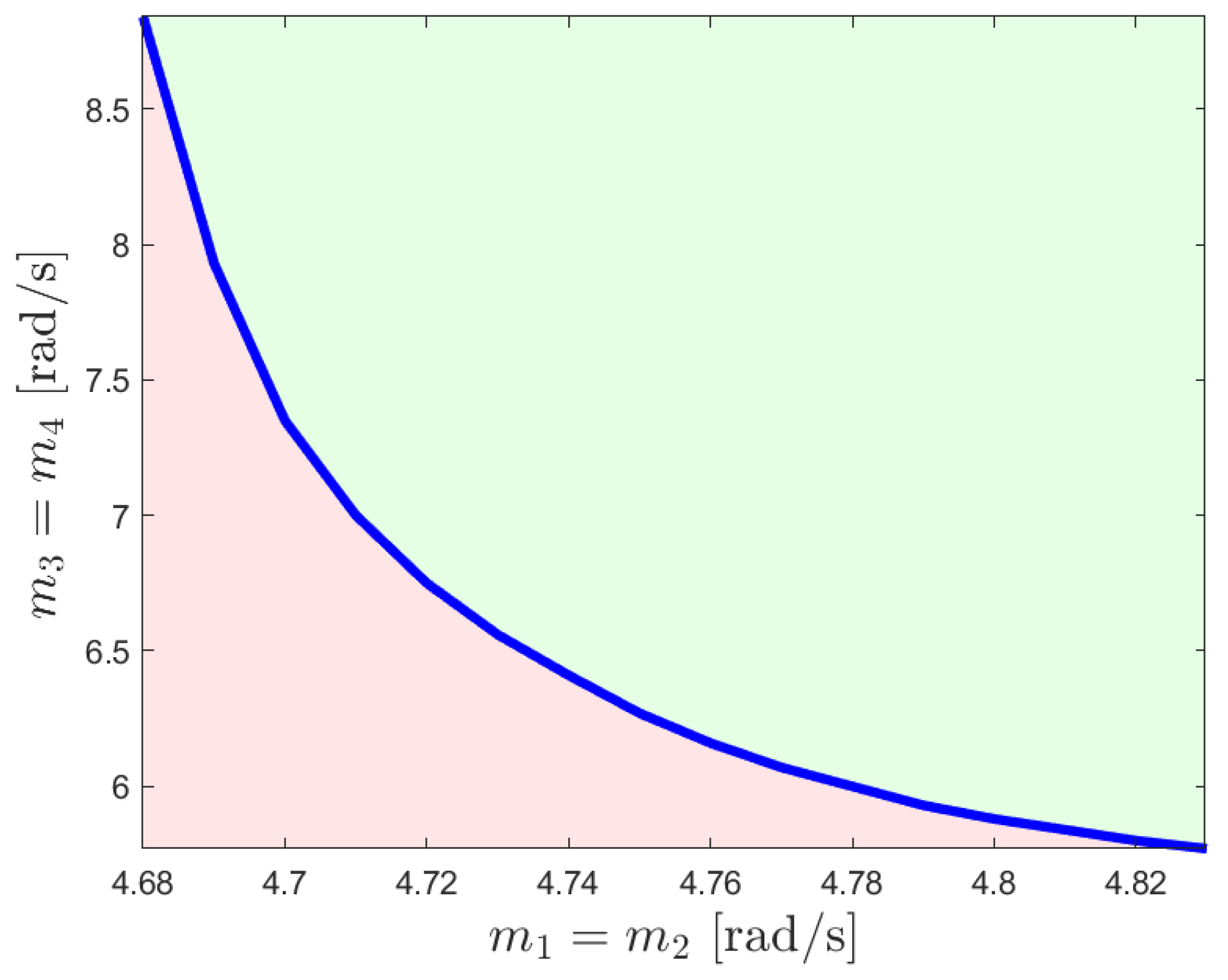
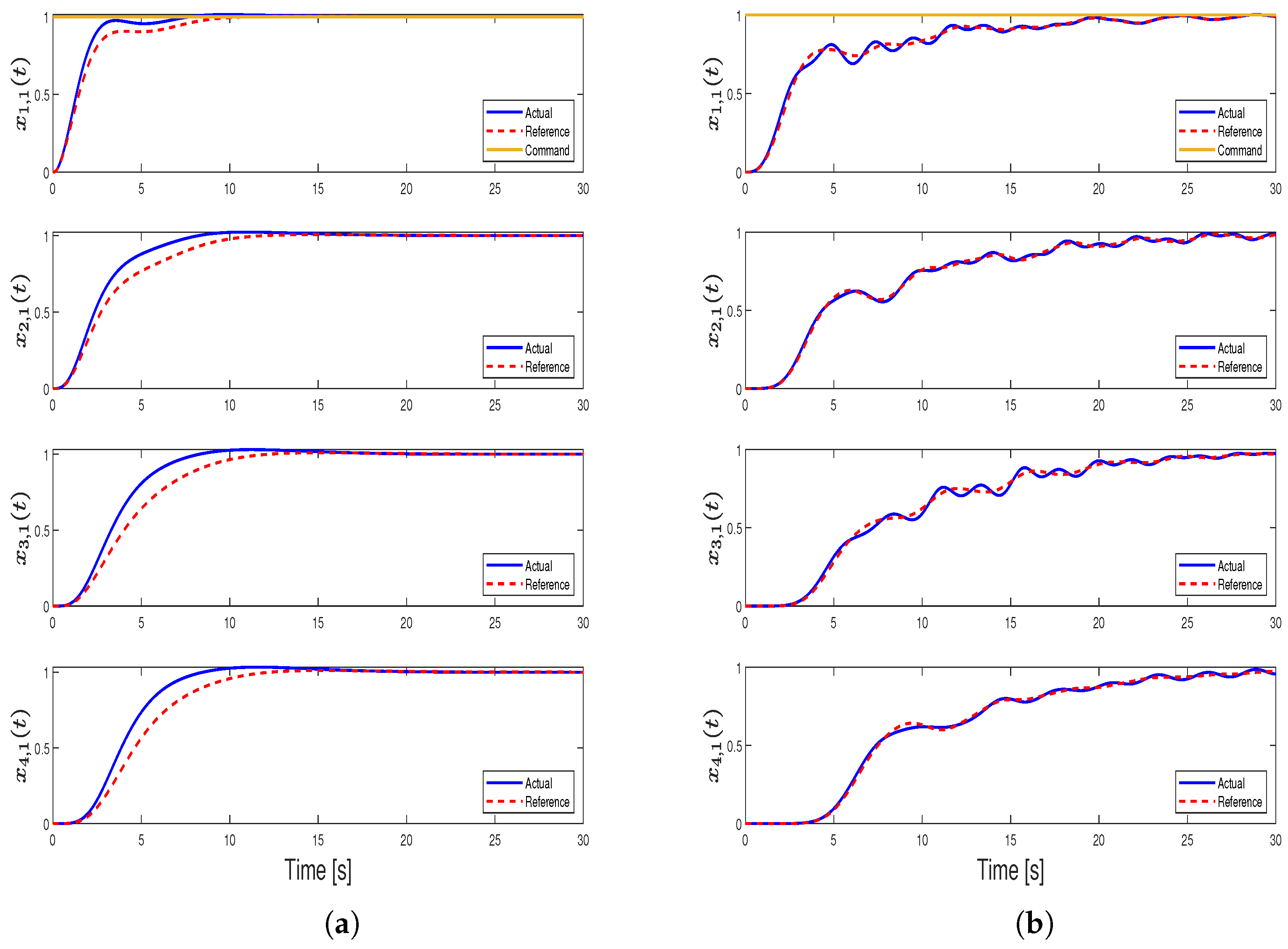
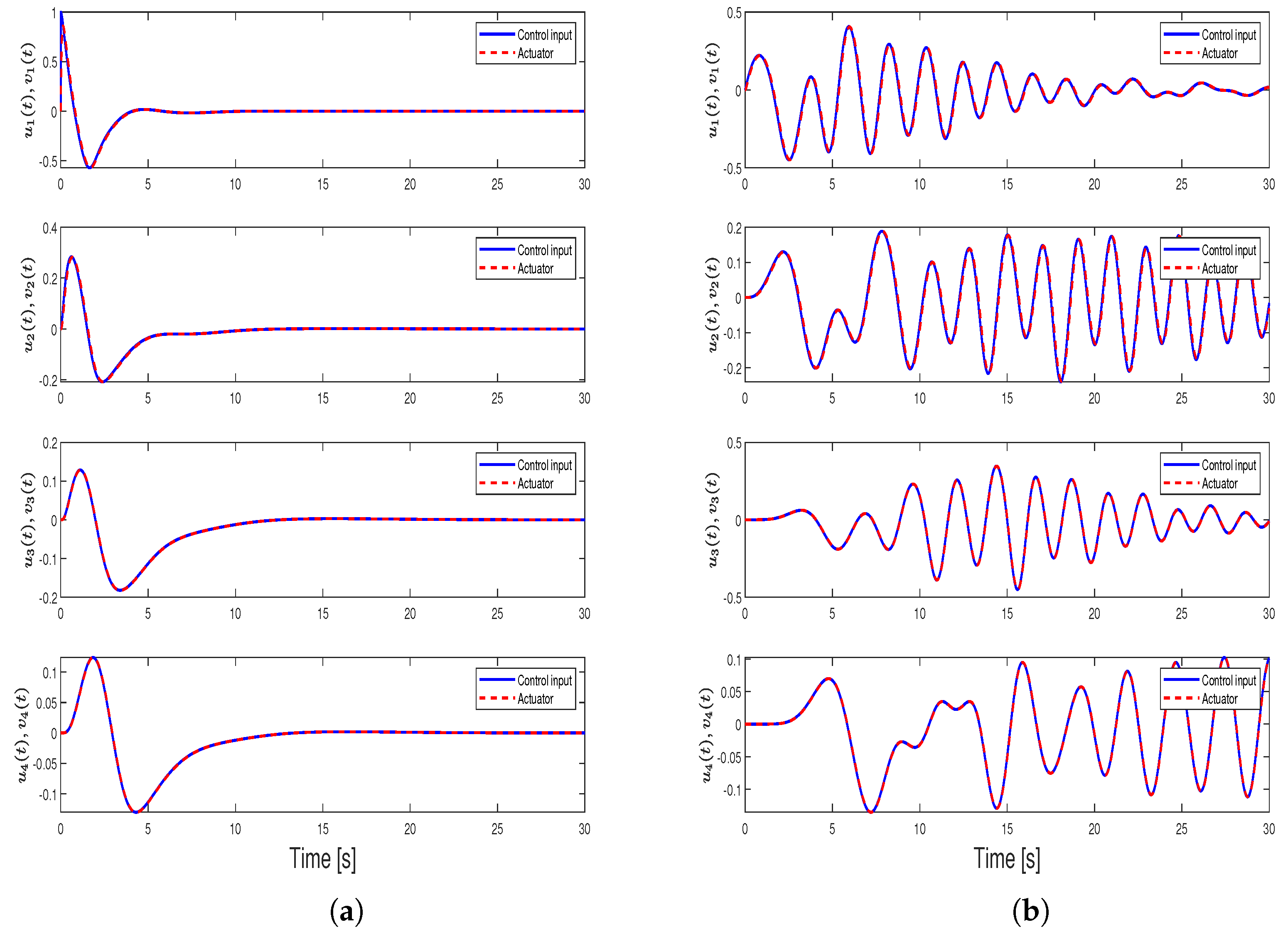
4. Illustrative Numerical Example

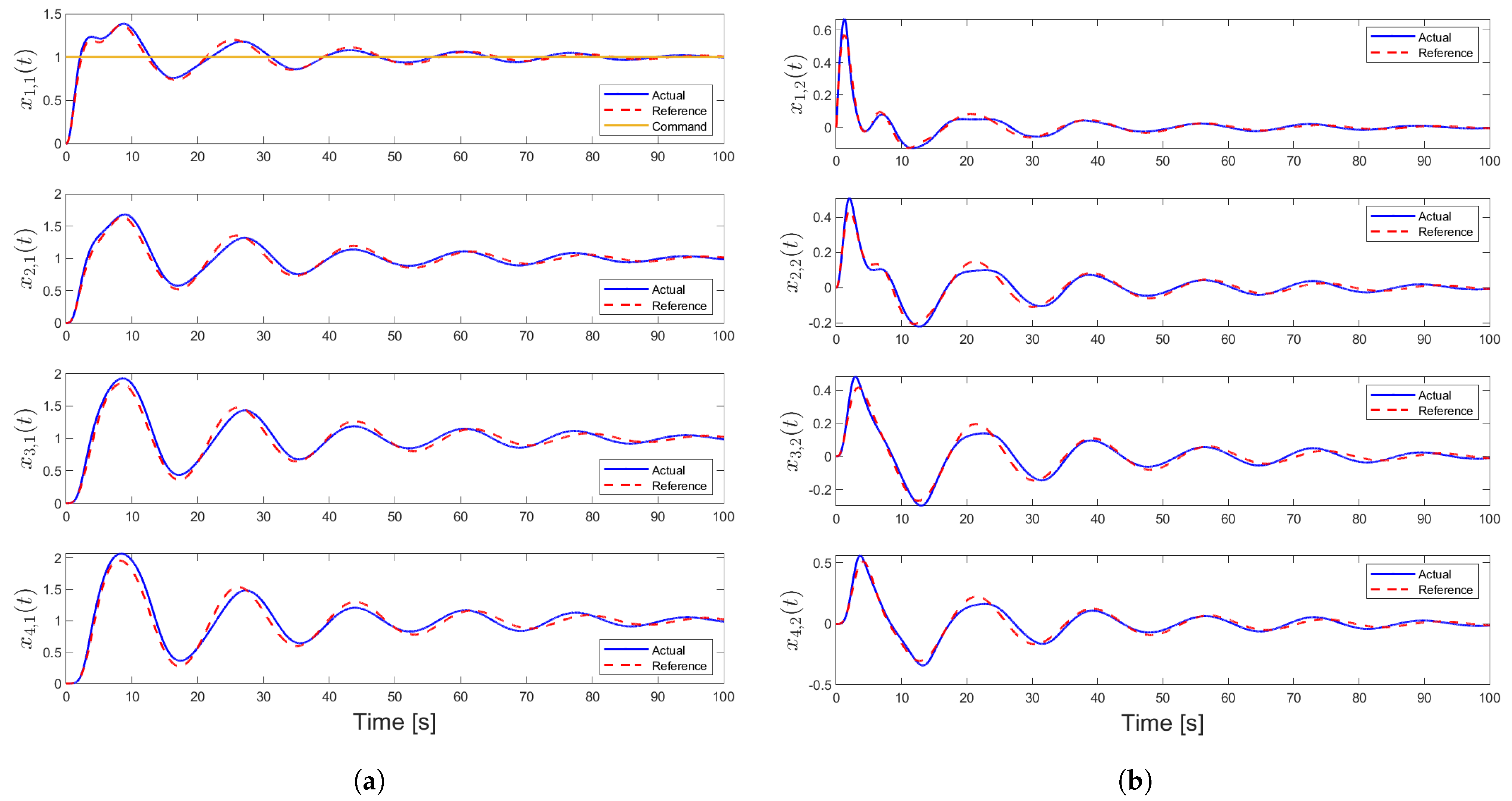
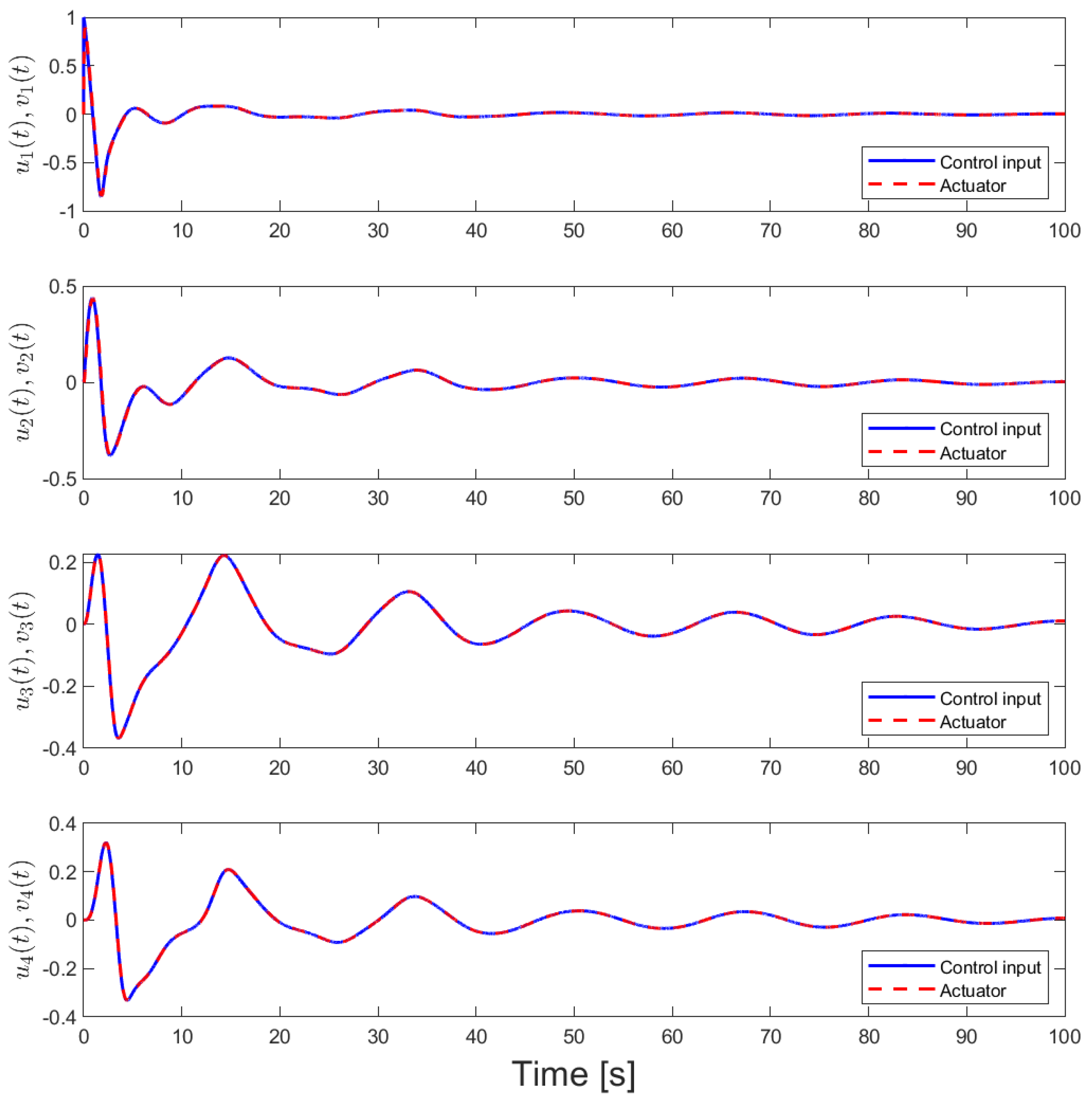
4.1. Case 1—Position Consensus (Motivational Example)
4.2. Case 2—Position and Velocity Consensus
4.3. Case 3—Position Consensus and Damping
4.4. Case 4—Position, Velocity Consensus, and Damping (Main Result)
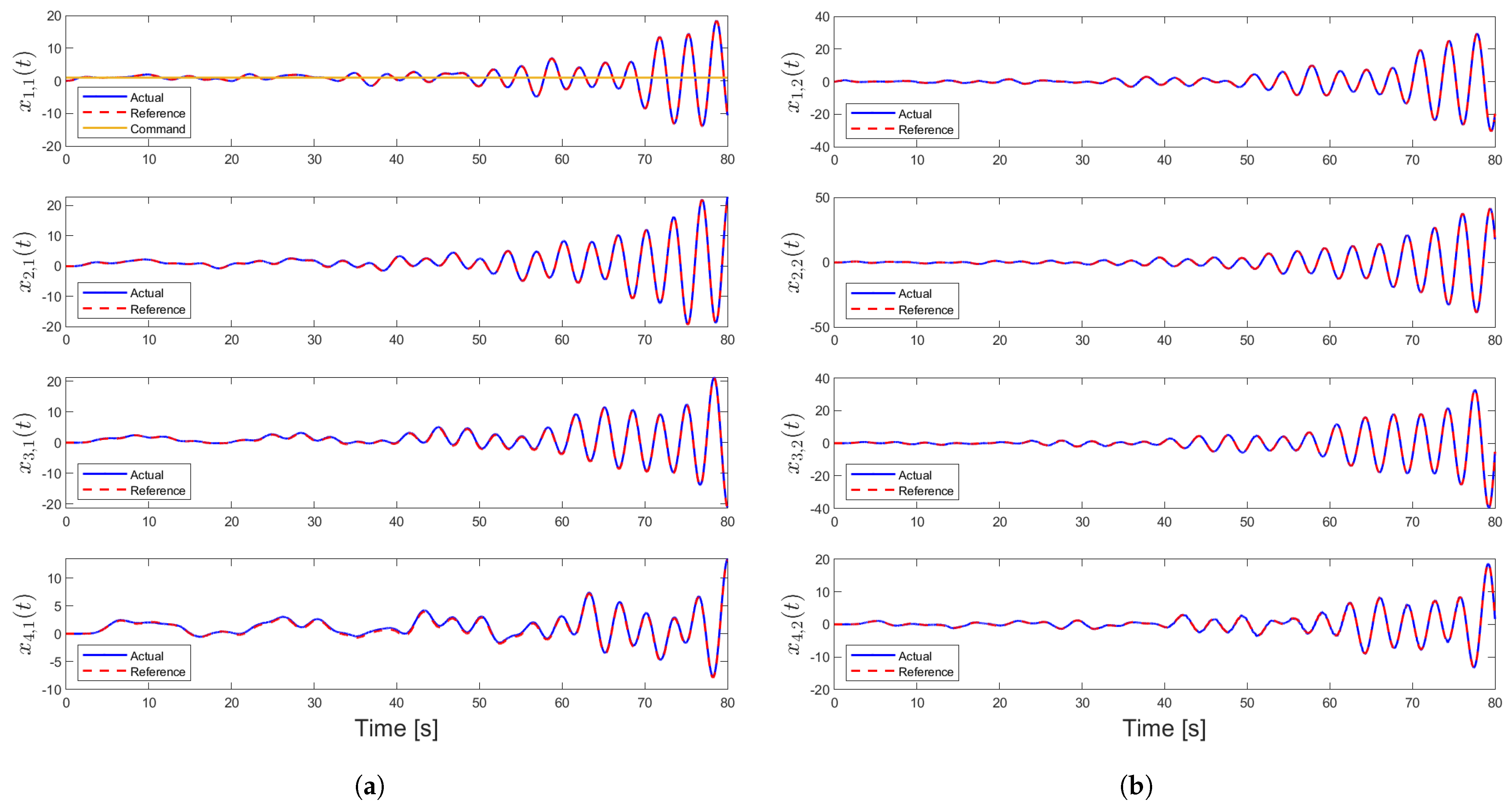
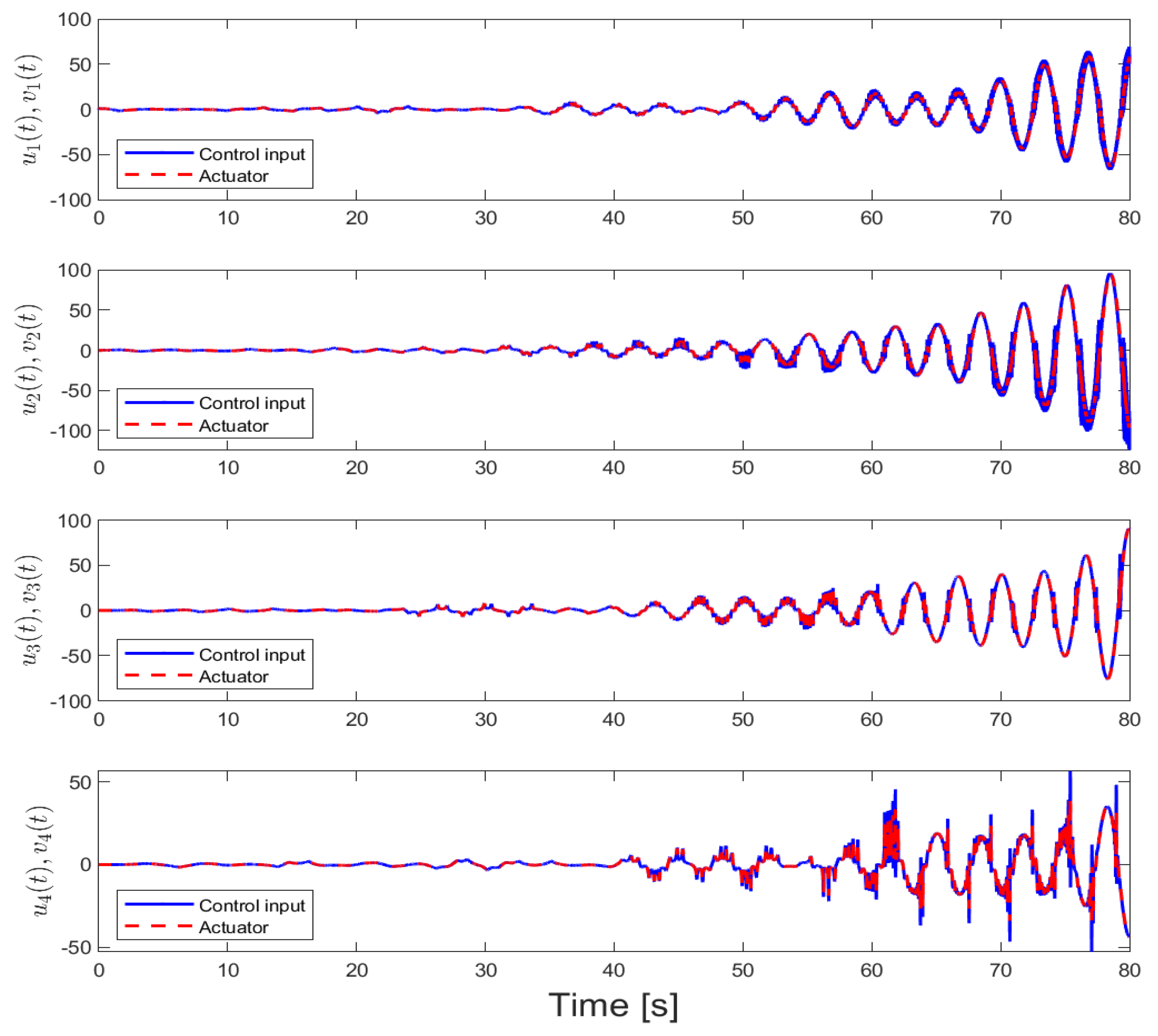
4.5. Case 5—Comparison with the Results in [31]
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lewis, F.L.; Zhang, H.; Hengster-Movric, K.; Das, A. Cooperative Control of Multi-Agent Systems: Optimal and Adaptive Design Approaches; Springer Science & Business Media: London, UK, 2013. [Google Scholar]
- Olfati-Saber, R.; Fax, J.A.; Murray, R.M. Consensus and cooperation in networked multi-agent systems. Proc. IEEE 2007, 95, 215–233. [Google Scholar] [CrossRef]
- Shamma, J. Cooperative Control of Distributed Multi-Agent Systems; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Bullo, F.; Cortéz, J.; Martinéz, S. Distributed Control of Robotic Networks; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Mesbahi, M.; Egerstedt, M. Graph Theoretic Methods in Multiagent Networks; Princeton University Press: Princeton, NJ, USA, 2010. [Google Scholar]
- Cao, Y.; Yu, W.; Ren, W.; Chen, G. An overview of recent progress in the study of distributed multi-agent coordination. IEEE Trans. Ind. Inform. 2012, 9, 427–438. [Google Scholar] [CrossRef]
- Rossi, F.; Bandyopadhyay, S.; Wolf, M.T.; Pavone, M. Multi-Agent Algorithms for Collective Behavior: A structural and application-focused atlas. arXiv 2021, arXiv:2103.11067. [Google Scholar]
- Saber, R.O.; Murray, R.M. Consensus protocols for networks of dynamic agents. In Proceedings of the 2003 American Control Conference, Denver, CO, USA, 4–6 June 2003; pp. 951–956. [Google Scholar]
- Blondel, V.D.; Hendrickx, J.M.; Olshevsky, A.; Tsitsiklis, J.N. Convergence in multiagent coordination, consensus, and flocking. In Proceedings of the 44th IEEE Conference on Decision and Control, Seville, Spain, 15 December 2005; pp. 2996–3000. [Google Scholar]
- Hong, Y.; Hu, J.; Gao, L. Tracking control for multi-agent consensus with an active leader and variable topology. Automatica 2006, 42, 1177–1182. [Google Scholar] [CrossRef]
- Ren, W.; Sorensen, N. Distributed coordination architecture for multi-robot formation control. Robot. Auton. Syst. 2008, 56, 324–333. [Google Scholar] [CrossRef]
- Ren, W.; Atkins, E. Distributed multi-vehicle coordinated control via local information exchange. Int. J. Robust Nonlinear Control IFAC-Affil. J. 2007, 17, 1002–1033. [Google Scholar] [CrossRef]
- Ren, W. Consensus strategies for cooperative control of vehicle formations. IET Control Theory Appl. 2007, 1, 505–512. [Google Scholar] [CrossRef]
- Ren, W. On Consensus Algorithms for Double-Integrator Dynamics. IEEE Trans. Autom. Control 2008, 53, 1503–1509. [Google Scholar] [CrossRef]
- Abdessameud, A.; Tayebi, A. On consensus algorithms for double-integrator dynamics without velocity measurements and with input constraints. Syst. Control Lett. 2010, 59, 812–821. [Google Scholar] [CrossRef]
- Egerstedt, M.; Hu, X. Formation constrained multi-agent control. IEEE Trans. Robot. Autom. 2001, 17, 947–951. [Google Scholar] [CrossRef]
- Jadbabaie, A.; Lin, J.; Morse, A.S. Coordination of groups of mobile autonomous agents using nearest neighbor rules. IEEE Trans. Autom. Control 2003, 48, 988–1001. [Google Scholar] [CrossRef]
- Dimarogonas, D.V.; Egerstedt, M.; Kyriakopoulos, K.J. A leader-based containment control strategy for multiple unicycles. In Proceedings of the 45th IEEE Conference on Decision and Control, San Diego, CA, USA, 13–15 December 2006; pp. 5968–5973. [Google Scholar]
- Dimarogonas, D.V.; Kyriakopoulos, K.J. A connection between formation control and flocking behavior in nonholonomic multiagent systems. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation, ICRA 2006, Orlando, FL, USA, 15–19 May 2006; pp. 940–945. [Google Scholar]
- Talebi, S.P.; Werner, S.; Huang, Y.F.; Gupta, V. Distributed Algebraic Riccati Equations in Multi-Agent Systems. In Proceedings of the 2022 European Control Conference (ECC), London, UK, 12–15 July 2022; pp. 1810–1817. [Google Scholar]
- Fattahi, S.; Fazelnia, G.; Lavaei, J.; Arcak, M. Transformation of optimal centralized controllers into near-globally optimal static distributed controllers. IEEE Trans. Autom. Control 2018, 64, 66–80. [Google Scholar] [CrossRef]
- Das, A.; Lewis, F.L. Distributed adaptive control for synchronization of unknown nonlinear networked systems. Automatica 2010, 46, 2014–2021. [Google Scholar] [CrossRef]
- Yucelen, T.; Johnson, E.N. Control of multivehicle systems in the presence of uncertain dynamics. Int. J. Control 2013, 86, 1540–1553. [Google Scholar] [CrossRef]
- Wang, W.; Wen, C.; Huang, J. Distributed adaptive asymptotically consensus tracking control of nonlinear multi-agent systems with unknown parameters and uncertain disturbances. Automatica 2017, 77, 133–142. [Google Scholar] [CrossRef]
- Sarsilmaz, S.B.; Yucelen, T. A Distributed Adaptive Control Approach for Heterogeneous Uncertain Multiagent Systems. In Proceedings of the 2018 AIAA Guidance, Navigation, and Control Conference, Kissimmee, FL, USA, 8–12 January 2018. [Google Scholar]
- Dogan, K.M.; Gruenwald, B.C.; Yucelen, T.; Muse, J.A.; Butcher, E.A. Distributed adaptive control of networked multiagent systems with heterogeneous actuator dynamics. In Proceedings of the 2017 American Control Conference (ACC), Seattle, WA, USA, 24–26 May 2017. [Google Scholar]
- Kurttisi, A.; Aly, I.A.; Dogan, K.M. Coordination of Uncertain Multiagent Systems with Non-Identical Actuation Capacities. In Proceedings of the 2022 IEEE 61st Conference on Decision and Control (CDC), Cancun, Mexico, 6–9 December 2022; pp. 3947–3952. [Google Scholar]
- Sarioglu, E.; Kurttisi, A.; Dogan, K.M. Experimental Results on Composing Cooperative Behaviors in Networked Mobile Robots in the Presence of Unknown Control Effectiveness. In Proceedings of the AIAA SCITECH 2023 Forum, National Harbor, MD, USA, 23–27 January 2023; pp. 5–8. [Google Scholar]
- Mirzaei, M.J.; Ghaemi, S.; Badamchizadeh, M.A.; Baradarannia, M. Adaptive super-twisting control for leader-following consensus of second-order multi-agent systems based on time-varying gains. ISA Trans. 2023, 140, 144–156. [Google Scholar] [CrossRef]
- Dogan, K.M.; Yucelen, T.; Muse, J.A. Stability Verification for Uncertain Multiagent Systems in the Presence of Heterogeneous Coupled and Actuator Dynamics. In Proceedings of the AIAA Scitech 2021 Forum, Virtual Event, 11–15 & 19–21 January 2021. [Google Scholar]
- Dogan, K.M.; Gruenwald, B.C.; Yucelen, T.; Muse, J.A.; Butcher, E.A. Distributed adaptive control and stability verification for linear multiagent systems with heterogeneous actuator dynamics and system uncertainties. Int. J. Control 2019, 92, 2620–2638. [Google Scholar] [CrossRef]
- Godsil, C.; Royle, G. Algebraic Graph Theory; Springer: New York, NY, USA, 2001. [Google Scholar]
- Khalil, H.K. Adaptive output feedback control of nonlinear systems represented by input-output models. IEEE Trans. Autom. Control 1996, 41, 177–188. [Google Scholar] [CrossRef]
- Lavretsky, E.; Wise, K.A. Robust Adaptive Control. In Robust and Adaptive Control; Springer: London, UK, 2013; pp. 317–353. [Google Scholar]
- Boyd, S.; El Ghaoui, L.; Feron, E.; Balakrishnan, V. Linear Matrix Inequalities in System and Control Theory; SIAM: Philadelphia, PA, USA, 1994. [Google Scholar]
- Khalil, H.K. Nonlinear Systems; Prentice Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Löfberg, J. YALMIP: A Toolbox for Modeling and Optimization in MATLAB. In Proceedings of the 2004 IEEE International Conference on Robotics and Automation (IEEE Cat. No. 04CH37508), New Orleans, LA, USA, 26 April–1 May 2004. [Google Scholar]
- Mosek ApS. The MOSEK Optimization Toolbox for MATLAB Manual; Version 9.3; Mosek ApS: Copenhagen, Denmark, 2022. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set of negative definite real numbers. | |
| Set of positive definite real numbers. | |
| Set of real numbers. | |
| Set of real column vectors. | |
| Set of positive definite real matrices. | |
| Set of nonnegative definite real matrices. | |
| Set of diagonal matrices. | |
| Set of positive definite diagonal matrices. | |
| Transpose of a matrix. | |
| Inverse of a matrix. | |
| identity matrix. | |
| zero vector. | |
| vector with all entries are 1. | |
| Proj | Projection operator. |
| diag(·) | Diagonalized vector. |
| ≜ | Equality from the definition. |
| ith column operator. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kurttisi, A.; Dogan, K.M.; Gruenwald, B.C. A Novel Distributed Adaptive Controller for Multi-Agent Systems with Double-Integrator Dynamics: A Hedging-Based Approach. Electronics 2024, 13, 1142. https://doi.org/10.3390/electronics13061142
Kurttisi A, Dogan KM, Gruenwald BC. A Novel Distributed Adaptive Controller for Multi-Agent Systems with Double-Integrator Dynamics: A Hedging-Based Approach. Electronics. 2024; 13(6):1142. https://doi.org/10.3390/electronics13061142
Chicago/Turabian StyleKurttisi, Atahan, Kadriye Merve Dogan, and Benjamin Charles Gruenwald. 2024. "A Novel Distributed Adaptive Controller for Multi-Agent Systems with Double-Integrator Dynamics: A Hedging-Based Approach" Electronics 13, no. 6: 1142. https://doi.org/10.3390/electronics13061142