
A Personalized Federated Learning Method Based on Clustering and Knowledge Distillation

Abstract
:1. Introduction
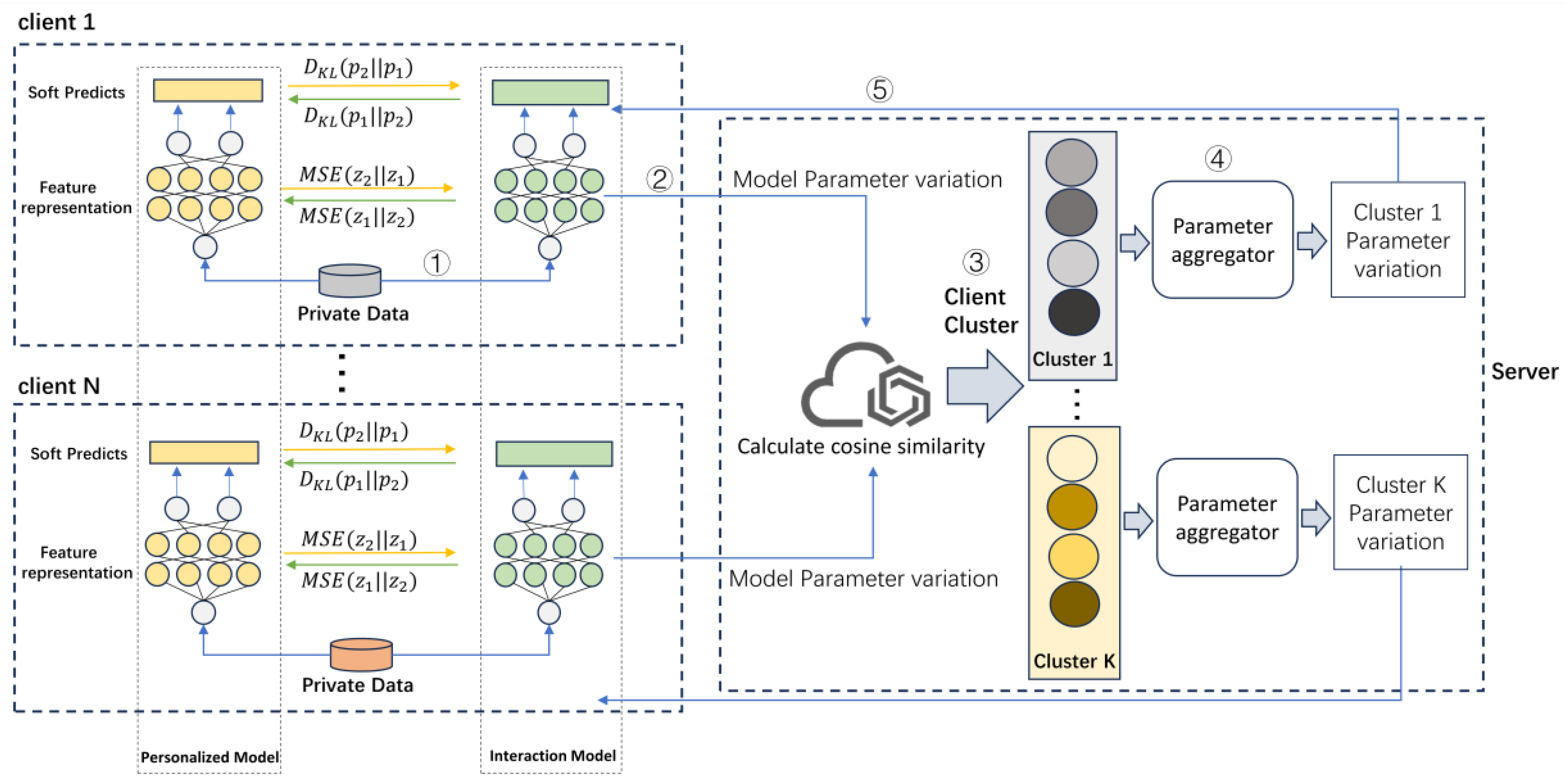
- To address the impact of data heterogeneity on model performance in federated learning, we propose a new personalized federated learning method, pFedCK, which establishes a dual-model structure on the client and combines two model mutual distillations based on the middle layer feature representation and the soft prediction of the model. It enables each client to have its own personalized model, and improves the accuracy of the model.
- Cluster partitioning of clients is realized by using the similarity of the amount of parameter variations in interaction models instead of the differences in data distribution. The interaction models of the clients with similar data distributions are enabled to learn together, thus reducing the impact of data heterogeneity on the distillation effect and further improving the accuracy of the personalized model in the Non-IID environment.
- The performance evaluation on three image datasets, MNIST, CIFAR10 and CIFAR100, shows that the method proposed in this paper has high accuracy compared to baseline algorithms.
2. Related Work
2.1. Clustered Federated Learning
2.2. Knowledge Distillation in Federated Learning
3. Personalized Federated Learning Method Based on Clustering and Knowledge Distillation
3.1. Federated Mutual Distillation
3.2. Clustering Based on Model Parameter Variations
3.3. The Process of pFedCK
| Algorithm 1. pFedCK |
| Input: clients, Set of clusters , : Loss function of interaction model, : Loss function of personalized model, initial interaction model , initial personalized model , : interaction model learning rate, : personalized model learning rate, number of iterations T |
| Output: |
| Server executes: 1: for each round =1, 2… do |
| 2: for each client in parallel do |
| 3: ClientUpdata() 4: end 5: for = 0, 1… do 6: for = 0, 1… do 7: 8: 9: end 10: end 11: for do 12: if and 13: K-Means () 14: 15: end 16: end 17: 18: for each cluster do 19: for do 20: 21: end 22: end 23: end ClientUpdata: 1: 2: for each epoch in parallel do 3: 4: 5: end 6: |
4. Experiments and Analysis
4.1. Datasets
4.2. Data Partition Setting
4.3. Parameter Settings
4.4. Baseline Algorithm
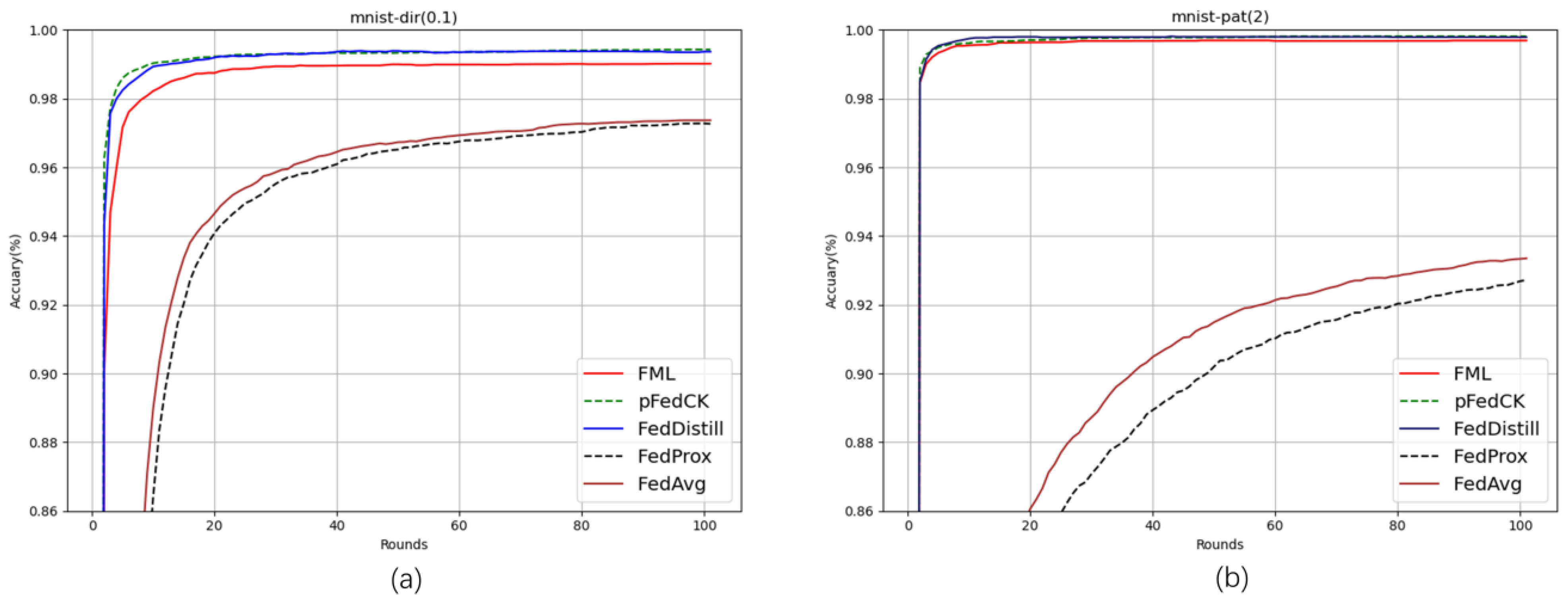
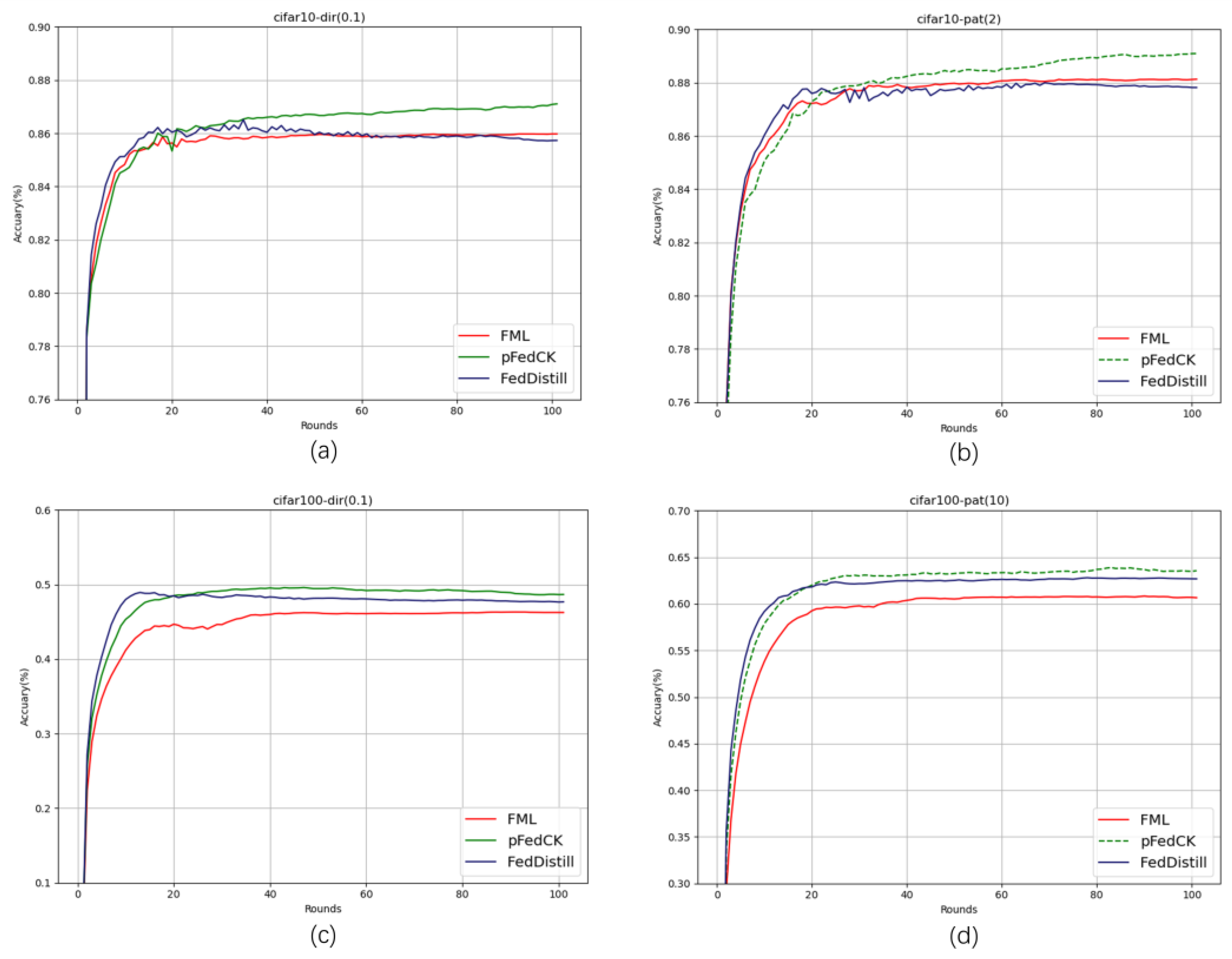
4.5. Results and Discussion
4.6. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics Conference, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. In Proceedings of the Machine Learning and Systems, Austin, TX, USA, 2–4 March 2020; Volume 2, pp. 429–450. [Google Scholar]
- Gao, L.; Fu, H.; Li, L.; Chen, Y.; Xu, M.; Xu, C. FedDC: Federated Learning with Non-IID Data via Local Drift Decoupling and Correction. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10102–10111. [Google Scholar]
- Collins, L.; Hassani, H.; Mokhtari, A.; Shakkottai, S. Exploiting Shared Representations for Personalized Federated Learning. arXiv 2021, arXiv:2102.07078. [Google Scholar]
- Deng, Y.; Kamani, M.; Mahdavi, M. Adaptive Personalized Federated Learning. arXiv 2020, arXiv:2003.13461. [Google Scholar]
- Tan, Y.; Long, G.; Liu, L.; Zhou, T.; Lu, Q.; Jiang, J.; Zhang, C. FedProto: Federated Prototype Learning across Heterogeneous Clients. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021. [Google Scholar]
- Zhang, M.; Sapra, K.; Fidler, S.; Yeung, S.; Álvarez, J.M. Personalized Federated Learning with First Order Model Optimization. arXiv 2020, arXiv:2012.08565. [Google Scholar]
- Shen, T.; Zhang, J.; Jia, X.; Zhang, F.; Huang, G.; Zhou, P.; Wu, F.; Wu, C. Federated Mutual Learning. arXiv 2020, arXiv:2006.16765. [Google Scholar]
- Sattler, F.; Müller, K.; Samek, W. Clustered Federated Learning: Model-Agnostic Distributed Multitask Optimization Under Privacy Constraints. IEEE Trans. Neural Netw. Learn. Syst. 2019, 32, 3710–3722. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, A.; Chung, J.; Yin, D.; Ramchandran, K. An Efficient Framework for Clustered Federated Learning. IEEE Trans. Inf. Theory 2020, 68, 8076–8091. [Google Scholar] [CrossRef]
- Jamali-Rad, H.; Abdizadeh, M.; Singh, A. Federated Learning With Taskonomy for Non-IID Data. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 8719–8730. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Guo, Y.; Chen, X. PFA: Privacy-preserving Federated Adaptation for Effective Model Personalization. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021. [Google Scholar]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Li, D.; Wang, J. FedMD: Heterogenous Federated Learning via Model Distillation. arXiv 2019, arXiv:1910.03581. [Google Scholar]
- Lin, T.; Kong, L.; Stich, S.U.; Jaggi, M. Ensemble Distillation for Robust Model Fusion in Federated Learning. arXiv 2020, arXiv:2006.07242. [Google Scholar]
- Zhu, Z.; Hong, J.; Zhou, J. Data-Free Knowledge Distillation for Heterogeneous Federated Learning. Proc. Mach. Learn. Res. 2021, 139, 12878–12889. [Google Scholar] [PubMed]
- Jeong, E.; Oh, S.; Kim, H.; Park, J.; Bennis, M.; Kim, S. Communication-Efficient On-Device Machine Learning: Federated Distillation and Augmentation under Non-IID Private Data. arXiv 2018, arXiv:1811.11479. [Google Scholar]
- Cho, Y.J.; Wang, J.; Chirvolu, T.; Joshi, G. Communication-Efficient and Model-Heterogeneous Personalized Federated Learning via Clustered Knowledge Transfer. IEEE J. Sel. Top. Signal Process. 2023, 17, 234–247. [Google Scholar] [CrossRef]
- Sun, S.; Cheng, Y.; Gan, Z.; Liu, J. Patient Knowledge Distillation for BERT Model Compression. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Zhang, J.; Hua, Y.; Wang, H.; Song, T.; Xue, Z.; Ma, R.; Guan, H. FedALA: Adaptive Local Aggregation for Personalized Federated Learning. arXiv 2022, arXiv:2212.01197. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Practical Heterogeneous | Pathological Heterogeneous | |||||
|---|---|---|---|---|---|---|
| Methods | MNIST | CIFAR10 | CIFAR100 | MNIST | CIFAR10 | CIFAR100 |
| FedAvg | 97.36 | 53.06 | 27.36 | 93.35 | 53.38 | 22.69 |
| FedProx | 97.27 | 52.37 | 26.92 | 92.71 | 52.66 | 22.42 |
| FedDistill | 99.36 | 85.73 | 47.66 | 99.78 | 87.81 | 62.68 |
| FML | 99.01 | 85.96 | 46.25 | 99.67 | 88.12 | 60.65 |
| pFedCK | 99.43 | 87.13 | 48.66 | 99.81 | 89.09 | 63.55 |
| Dataset | pFedCK-f | pFedCK-c | pFedCK |
|---|---|---|---|
| CIFAR10 | 88.95 | 88.89 | 89.09 |
| CIFAR100 | 61.77 | 63.23 | 63.55 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Shi, Y. A Personalized Federated Learning Method Based on Clustering and Knowledge Distillation. Electronics 2024, 13, 857. https://doi.org/10.3390/electronics13050857
Zhang J, Shi Y. A Personalized Federated Learning Method Based on Clustering and Knowledge Distillation. Electronics. 2024; 13(5):857. https://doi.org/10.3390/electronics13050857
Chicago/Turabian StyleZhang, Jianfei, and Yongqiang Shi. 2024. "A Personalized Federated Learning Method Based on Clustering and Knowledge Distillation" Electronics 13, no. 5: 857. https://doi.org/10.3390/electronics13050857