
A Reactive Deep Learning-Based Model for Quality Assessment in Airport Video Surveillance Systems
Abstract
:1. Introduction
1.1. Related Works
1.1.1. Image Quality Assessment
1.1.2. Video Anomaly Detection
- A.
- Video jitter detection
- B.
- Surveillance video occlusion
2. Materials and Methods
2.1. Data Acquisition
2.2. Proposed Method
2.2.1. The Proposed 3D CNN for Anomaly Detection
2.2.2. The Proposed 2D CNN for Quality Assessment
3. Results and Discussion
3.1. Evaluation Metrics
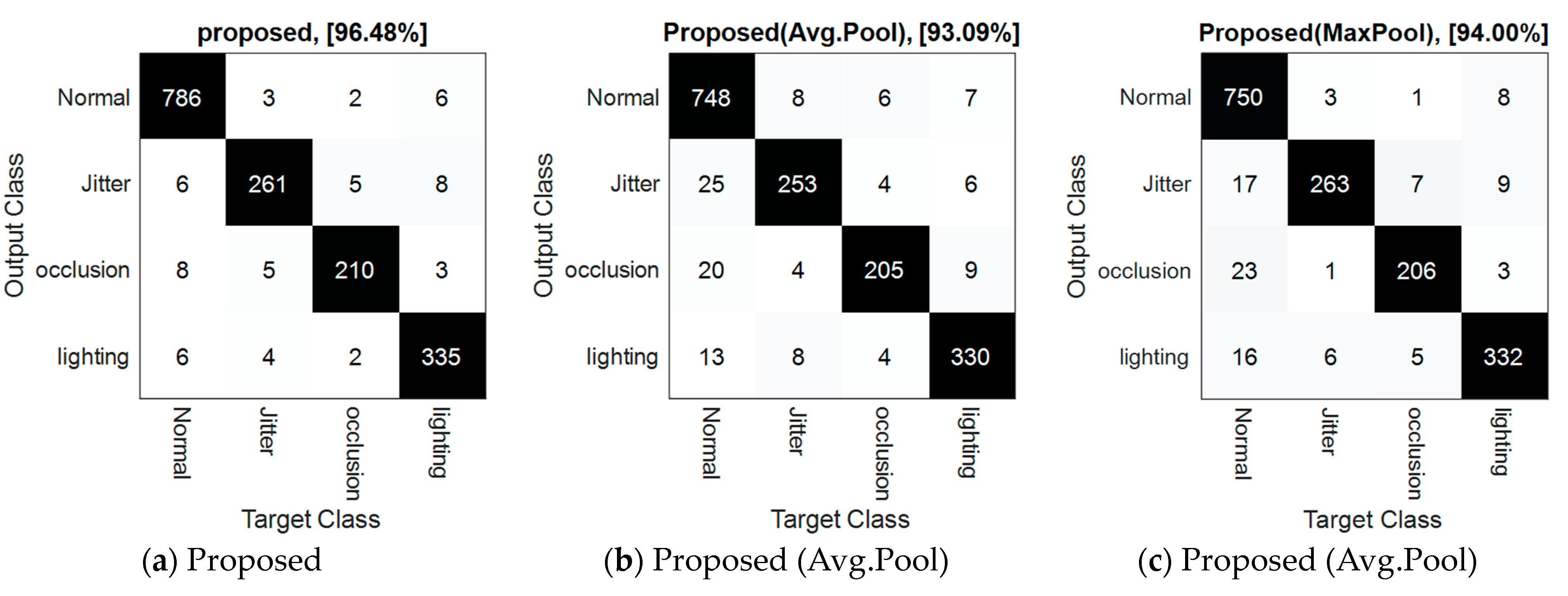
3.2. Performance of the Proposed Method in Anomaly Detection
- Proposed (Avg. Pooling): In this configuration, all pooling layers in the 3D CNN model used in the proposed method were of the average pooling type.
- Proposed (Max Pooling): In this configuration, all pooling layers in the 3D CNN model used in the proposed method were of the max pooling type.
- Two-dimensional CNN: In this configuration, the anomaly detection is performed using the 2D CNN model only. It should be noted that in this case, the learning model is fed with one frame each time.
3.3. Performance of the Proposed Method in Quality Assessment
- -
- Proposed (3D + 2D CNNs): In this case, according to the procedure presented in Section 3, quality assessment is performed based on the combination of 3D CNN and 2D CNN features.
- -
- Proposed (2D CNN Only): In this case, only the 2D CNN model is used to assessment of video quality. In other words, the features extracted by 3D CNN are ignored in the proposed model. The purpose of comparing the proposed method with this state is to evaluate the effectiveness of the proposed hybrid strategy.
3.4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lyu, Z.; Luo, J. A surveillance video real-time object detection system based on edge-cloud cooperation in airport apron. Appl. Sci. 2022, 12, 10128. [Google Scholar] [CrossRef]
- Balasundaram, A.; Dilip, G.; Manickam, M.; Sivaraman, A.K.; Gurunathan, K.; Dhanalakshmi, R.; Ashokkumar, S. Abnormality identification in video surveillance system using DCT. Intell. Autom. Soft Comput. 2021, 32, 693–704. [Google Scholar] [CrossRef]
- Thai, P.; Alam, S.; Lilith, N.; Nguyen, B.T. A computer vision framework using convolutional neural networks for airport-airside surveillance. Transp. Res. Part C Emerg. Technol. 2022, 137, 103590. [Google Scholar] [CrossRef]
- Zhang, X.; Shu, C.; Li, S.; Wu, C.; Liu, Z. AGVS: A New Change Detection Dataset for Airport Ground Video Surveillance. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20588–20600. [Google Scholar] [CrossRef]
- Zhang, X.; Qiao, Y. A video surveillance network for airport ground moving targets. In Proceedings of the Mobile Networks and Management: 10th EAI International Conference, MONAMI 2020, Chiba, Japan, 10–12 November 2020; Proceedings 10. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 229–237. [Google Scholar]
- Chen, P.; Li, L.; Wu, J.; Dong, W.; Shi, G. Contrastive self-supervised pre-training for video quality assessment. IEEE Trans. Image Process. 2021, 31, 458–471. [Google Scholar] [CrossRef]
- Dost, S.; Saud, F.; Shabbir, M.; Khan, M.G.; Shahid, M.; Lovstrom, B. Reduced reference image and video quality assessments: Review of methods. EURASIP J. Image Video Process. 2022, 2022, 1–31. [Google Scholar] [CrossRef]
- Kumar, C.; Singh, S. Security standards for real time video surveillance and moving object tracking challenges, limitations, and future: A case study. Multimedia Tools Appl. 2023, 1–32. [Google Scholar] [CrossRef]
- Pareek, P.; Thakkar, A. A survey on video-based human action recognition: Recent updates, datasets, challenges, and applications. Artif. Intell. Rev. 2021, 54, 2259–2322. [Google Scholar] [CrossRef]
- Streijl, R.C.; Winkler, S.; Hands, D.S. Mean opinion score (MOS) revisited: Methods and applications, limitations and alternatives. Multimedia Syst. 2016, 22, 213–227. [Google Scholar] [CrossRef]
- Barman, N.; Zadtootaghaj, S.; Schmidt, S.; Martini, M.G.; Möller, S. An objective and subjective quality assessment study of passive gaming video streaming. Int. J. Netw. Manag. 2020, 30, e2054. [Google Scholar] [CrossRef]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Q. Information content weighting for perceptual image quality assessment. IEEE Trans. Image Process. 2010, 20, 1185–1198. [Google Scholar] [CrossRef] [PubMed]
- Maalouf, A.; Larabi, M.C. CYCLOP: A stereo color image quality assessment metric. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 1161–1164. [Google Scholar]
- Omari, M.; Abdelouahed, A.A.; Hassouni, M.E.; Cherif, H. Improving Reduced Reference Image Quality Assessment Methods By Using Color Information. Int. J. Comput. Inf. Syst. Ind. Manag. Appl. (IJCISIM) 2018, 10, 183–196. [Google Scholar]
- Gupta, P.; Moorthy, A.K.; Soundararajan, R.; Bovik, A.C. Generalized Gaussian scale mixtures: A model for wavelet coefficients of natural images. Signal Process. Image Commun. 2018, 66, 87–94. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Yan, Q.; Gong, D.; Zhang, Y. Two-stream convolutional networks for blind image quality assessment. IEEE Trans. Image Process. 2018, 28, 2200–2211. [Google Scholar] [CrossRef] [PubMed]
- Kang, L.; Ye, P.; Li, Y.; Doermann, D. Convolutional neural networks for no-reference image quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2014; pp. 1733–1740. [Google Scholar]
- Gu, K.; Zhai, G.; Yang, X.; Zhang, W. Deep learning network for blind image quality assessment. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; IEEE: New York City, NY, USA; pp. 511–515. [Google Scholar]
- Liu, X.; Van De Weijer, J.; Bagdanov, A.D. Rankiqa: Learning from rankings for no-reference image quality assessment. In Proceedings of the IEEE International Conference on Computer Vision, Macao, China, 4–8 December 2017; pp. 1040–1049. [Google Scholar]
- Zhang, W.; Ma, K.; Yan, J.; Deng, D.; Wang, Z. Blind image quality assessment using a deep bilinear convolutional neural network. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 36–47. [Google Scholar] [CrossRef]
- Liu, J.; Zhou, W.; Li, X.; Xu, J.; Chen, Z. LIQA: Lifelong blind image quality assessment. IEEE Trans. Multimedia 2022, 25, 5358–5373. [Google Scholar] [CrossRef]
- Lim, A.; Ramesh, B.; Yang, Y.; Xiang, C.; Gao, Z.; Lin, F. Real-time optical flow-based video stabilization for unmanned aerial vehicles. J. Real-Time Image Process. 2019, 16, 1975–1985. [Google Scholar] [CrossRef]
- Zhang, W.; Shi, X.; Jin, T.; Chen, S.; Xu, Y.; Sun, W.; Xue, Y.; Yu, Z. A moving object detection algorithm of jitter video. In Proceedings of the 2019 4th Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Nagoya, Japan, 13–15 July 2019; IEEE: New York City, NY, USA; pp. 63–67. [Google Scholar]
- Lejmi, W.; Khalifa, A.B.; Mahjoub, M.A. Challenges and methods of violence detection in surveillance video: A survey. In Proceedings of the Computer Analysis of Images and Patterns: 18th International Conference, CAIP 2019, Salerno, Italy, 3–5 September 2019; Proceedings, Part II 18. Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 62–73. [Google Scholar]
- Zhu, H.; Wei, H.; Li, B.; Yuan, X.; Kehtarnavaz, N. A review of video object detection: Datasets, metrics and methods. Appl. Sci. 2020, 10, 7834. [Google Scholar] [CrossRef]
- Ning, C.; Menglu, L.; Hao, Y.; Xueping, S.; Yunhong, L. Survey of pedestrian detection with occlusion. Complex Intell. Syst. 2021, 7, 577–587. [Google Scholar] [CrossRef]
- Li, F.; Li, X.; Liu, Q.; Li, Z. Occlusion handling and multi-scale pedestrian detection based on deep learning: A review. IEEE Access 2022, 10, 19937–19957. [Google Scholar] [CrossRef]
- Ansari, M.A.; Singh, D.K. Human detection techniques for real time surveillance: A comprehensive survey. Multimedia Tools Appl. 2021, 80, 8759–8808. [Google Scholar] [CrossRef]
- Wu, C.; Shao, S.; Tunc, C.; Satam, P.; Hariri, S. An explainable and efficient deep learning framework for video anomaly detection. Clust. Comput. 2021, 25, 2715–2737. [Google Scholar] [CrossRef] [PubMed]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Crnjanski, J.; Krstić, M.; Totovic, A.R.; Pleros, N.; Gvozdić, D. Adaptive sigmoid-like and PReLU activation functions for all-optical perceptron. Opt. Lett. 2021, 46, 2003–2006. [Google Scholar] [CrossRef]
- Tong, Z.; Tanaka, G. Hybrid pooling for enhancement of generalization ability in deep convolutional neural networks. Neurocomputing 2019, 333, 76–85. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | 2D CNN Setting | 3D CNN Setting |
|---|---|---|
| Input | 1080 × 1920 × 3 | 338 × 600 × 10 × 3 |
| Convolution1 ([Dims], [N filters]) | [30 × 30], [32] | [32 × 32 × 5], [16] |
| Hybrid Pooling1 | 2 × 2 | 2 × 2 × 2 |
| Convolution2 ([Dims], [N filters]) | [10 × 10], [48] | [16 × 16 × 3], [48] |
| Hybrid Pooling2 | 2 × 2 | 2 × 2 × 2 |
| Convolution3 ([Dims], [N filters]) | [8 × 8], [64] | [8 × 8 × 2], [128] |
| Hybrid Pooling3 | 2 × 2 | 2 × 2 × 2 |
| Fully Connected 1 | 400 | 300 |
| Method | Accuracy | F-Measure | Recall | Precision |
|---|---|---|---|---|
| Proposed | 96.4848 | 95.6734 | 96.0460 | 95.3241 |
| Proposed (AvgPool) | 93.0909 | 92.0620 | 93.2088 | 91.0522 |
| Proposed (MaxPool) | 94 | 93.1615 | 94.4428 | 92.0419 |
| 2D CNN | 89.3333 | 87.909 | 89.1707 | 86.8763 |
| ResNet50 | 91.3333 | 89.8329 | 90.9986 | 88.8237 |
| VGG-16 | 90.5455 | 88.7227 | 89.7765 | 87.7941 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Pan, Y.; Fan, Y. A Reactive Deep Learning-Based Model for Quality Assessment in Airport Video Surveillance Systems. Electronics 2024, 13, 749. https://doi.org/10.3390/electronics13040749
Liu W, Pan Y, Fan Y. A Reactive Deep Learning-Based Model for Quality Assessment in Airport Video Surveillance Systems. Electronics. 2024; 13(4):749. https://doi.org/10.3390/electronics13040749
Chicago/Turabian StyleLiu, Wanting, Ya Pan, and Yong Fan. 2024. "A Reactive Deep Learning-Based Model for Quality Assessment in Airport Video Surveillance Systems" Electronics 13, no. 4: 749. https://doi.org/10.3390/electronics13040749