
MFSNet: Enhancing Semantic Segmentation of Urban Scenes with a Multi-Scale Feature Shuffle Network

Abstract
:1. Introduction
- To mitigate the issue of segmentation errors in urban scenes resulting from the presence of neighboring objects with similar features such as texture or color. We introduce a Pyramid Shuffle Module (PSM), which improving the multi-scale feature representations and segmentation robustness of the network by facilitating channel interaction among multi-scale features and highlighting discriminative features.
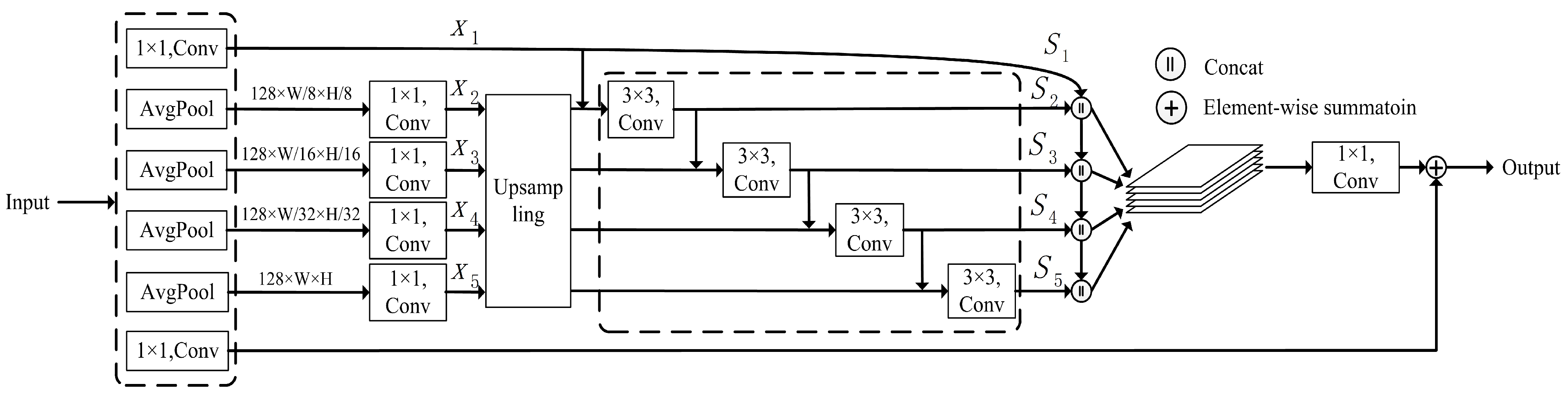
- To achieve precise segmentation of object boundaries. We proposed an efficient feature aggregation module (EFAM), serving as a branch for network multi-layer feature fusion in the network, to compensate for feature loss caused by pyramid pooling and to facilitate network backpropagation.
- Extensive experimental results on Pascal VOC 2012, Cityscapes, and Coco-Stuff datasets reveal that the proposed method exhibits a good generalization ability.
2. Methods
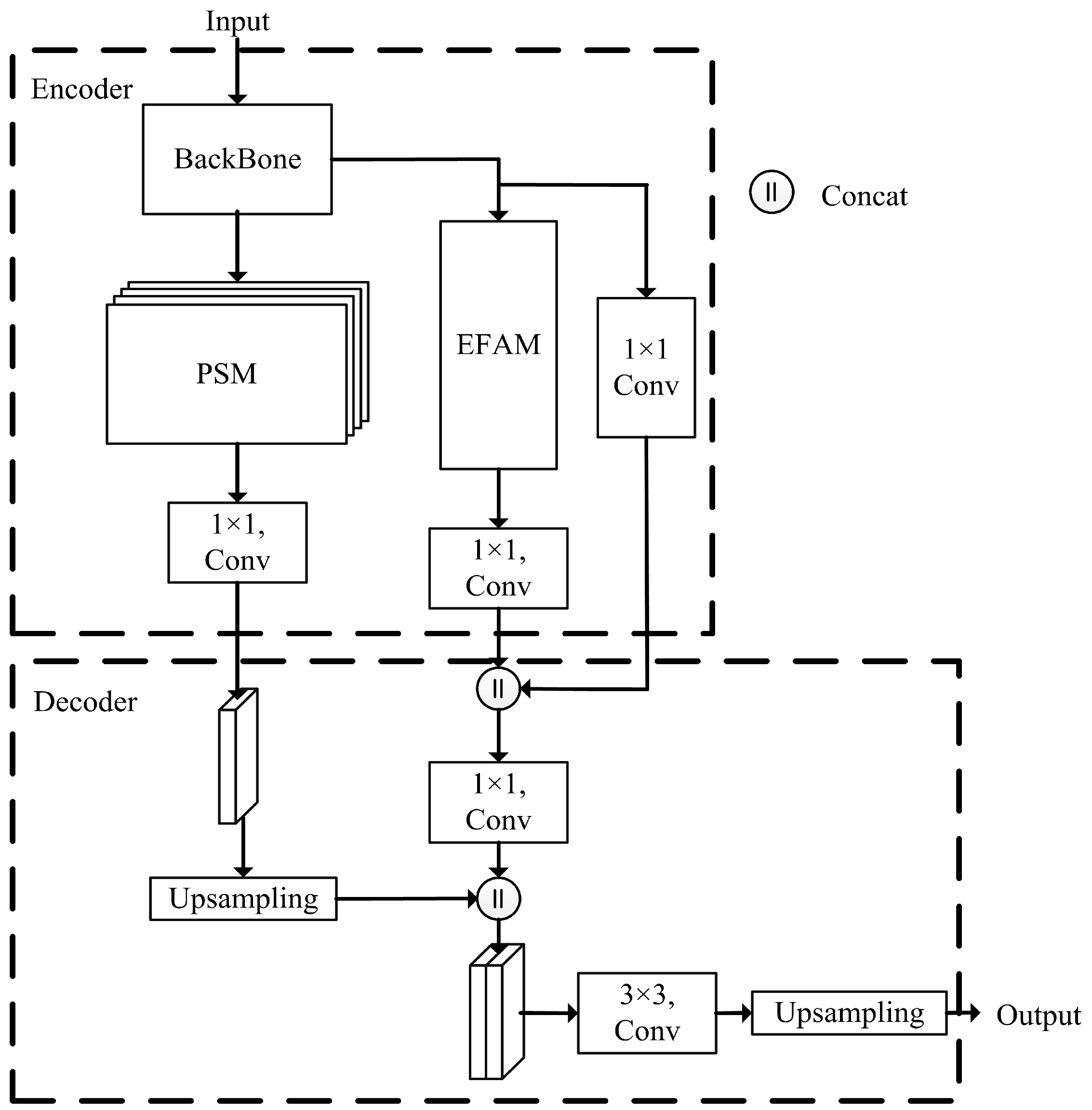
2.1. Overview
2.2. Pyramid Shuffle Model
2.3. Efficient Feature Aggregation Module
3. Experimental Results
3.1. Datasets
3.2. Train Setting
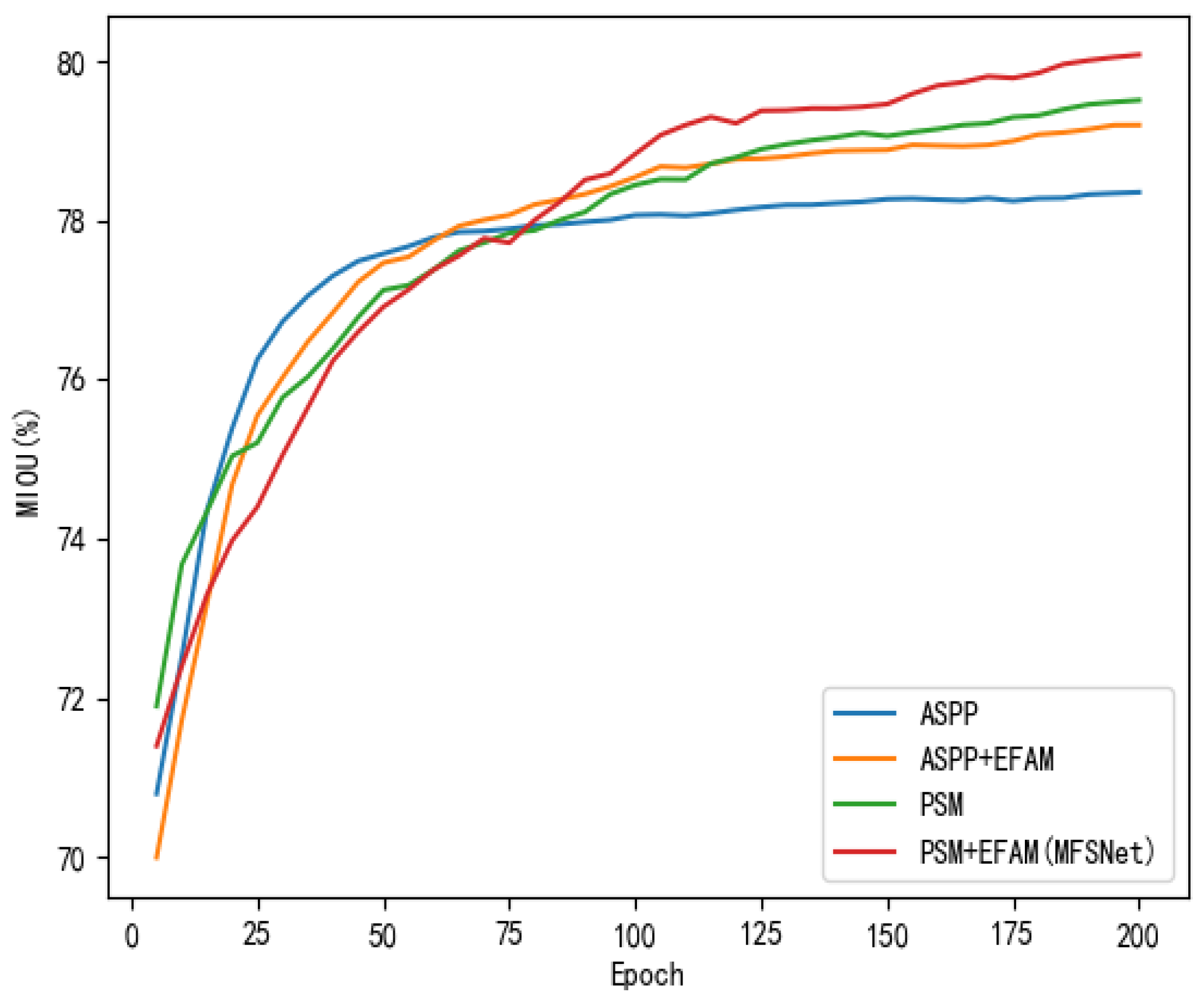
3.3. Ablation Study
3.4. Results on Pascal VOC 2012
3.5. Results on Cityscapes
3.6. Results on Coco-Stuff
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, M.; Chen, D.; Liu, S. Weakly supervised segmentation loss based on graph cuts and superpixel algorithm. Neural Process. Lett. 2022, 54, 2339–2362. [Google Scholar] [CrossRef]
- Sun, W.; Liu, Z.; Zhang, Y.; Zhong, Y.; Barnes, N. An Alternative to WSSS? An Empirical Study of the Segment Anything Model (SAM) on Weakly-Supervised Semantic Segmentation Problems. arXiv 2023, arXiv:2305.01586. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Fu, J.; Liu, J.; Wang, Y.; Zhou, J.; Wang, C.; Lu, H. Stacked deconvolutional network for semantic segmentation. IEEE Trans. Image Process. 2019. [Google Scholar] [CrossRef] [PubMed]
- Hou, L.; Vicente, T.F.Y.; Hoai, M.; Samaras, D. Large scale shadow annotation and detection using lazy annotation and stacked CNNs. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1337–1351. [Google Scholar] [CrossRef] [PubMed]
- He, J.; Deng, Z.; Qiao, Y. Dynamic multi-scale filters for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3562–3572. [Google Scholar]
- Bejar, H.H.; Guimaraes, S.J.F.; Miranda, P.A. Efficient hierarchical graph partitioning for image segmentation by optimum oriented cuts. Pattern Recognit. Lett. 2020, 131, 185–192. [Google Scholar] [CrossRef]
- Fan, M.; Lai, S.; Huang, J.; Wei, X.; Chai, Z.; Luo, J.; Wei, X. Rethinking bisenet for real-time semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9716–9725. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- He, H.; Chen, Y.; Li, M.; Chen, Q. ForkNet: Strong semantic feature representation and subregion supervision for accurate remote sensing change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2142–2153. [Google Scholar] [CrossRef]
- Zhu, L.; Ji, D.; Zhu, S.; Gan, W.; Wu, W.; Yan, J. Learning statistical texture for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12537–12546. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Yang, Z. Semantic segmentation method based on improved DeeplabV3+. In Proceedings of the International Conference on Cloud Computing, Performance Computing, and Deep Learning (CCPCDL 2023), Huzhou, China, 17–19 February 2023; pp. 32–37. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Ocnet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Zhang, C.; Jiang, W.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C. Transformer and CNN hybrid deep neural network for semantic segmentation of very-high-resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–20. [Google Scholar] [CrossRef]
- Cui, L.; Jing, X.; Wang, Y.; Huan, Y.; Xu, Y.; Zhang, Q. Improved Swin Transformer-Based Semantic Segmentation of Postearthquake Dense Buildings in Urban Areas Using Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 369–385. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhang, Q.-L.; Yang, Y.-B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. Ce-net: Context encoder network for 2d medical image segmentation. IEEE Trans. Med Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV 14. pp. 630–645. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Hariharan, B.; Arbeláez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic contours from inverse detectors. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 991–998. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Caesar, H.; Uijlings, J.; Ferrari, V. Coco-stuff: Thing and stuff classes in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1209–1218. [Google Scholar]
- Rashwan, A.; Du, X.; Yin, X.; Li, J. Dilated SpineNet for semantic segmentation. arXiv 2021, arXiv:2103.12270. [Google Scholar]
- Jin, Z.; Liu, B.; Chu, Q.; Yu, N. Isnet: Integrate image-level and semantic-level context for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7189–7198. [Google Scholar]
- Zhou, Z.; Lei, Y.; Zhang, B.; Liu, L.; Liu, Y. Zegclip: Towards adapting clip for zero-shot semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 11175–11185. [Google Scholar]
- Zhou, T.; Wang, W.; Konukoglu, E.; Van Gool, L. Rethinking semantic segmentation: A prototype view. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2582–2593. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7262–7272. [Google Scholar]
- Li, L.; Zhou, T.; Wang, W.; Li, J.; Yang, Y. Deep hierarchical semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1246–1257. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Chu, X.; Chen, L.; Chen, C.; Lu, X. Improving image restoration by revisiting global information aggregation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 53–71. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. Psanet: Point-wise spatial attention network for scene parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 267–283. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VI 16. pp. 173–190. [Google Scholar]
- Jo, S.; Yu, I.-J.; Kim, K. MARS: Model-agnostic Biased Object Removal without Additional Supervision for Weakly-Supervised Semantic Segmentation. arXiv 2023, arXiv:2304.09913. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. Pointrend: Image segmentation as rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9799–9808. [Google Scholar]
- He, J.; Deng, Z.; Zhou, L.; Wang, Y.; Qiao, Y. Adaptive pyramid context network for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7519–7528. [Google Scholar]
- Bai, S.; Koltun, V.; Kolter, J.Z. Multiscale deep equilibrium models. Adv. Neural Inf. Process. Syst. 2020, 33, 5238–5250. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Ertenli, C.U.; Akbas, E.; Cinbis, R.G. Streaming Multiscale Deep Equilibrium Models. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 189–205. [Google Scholar]
- Termritthikun, C.; Jamtsho, Y.; Ieamsaard, J.; Muneesawang, P.; Lee, I. EEEA-Net: An early exit evolutionary neural architecture search. Eng. Appl. Artif. Intell. 2021, 104, 104397. [Google Scholar] [CrossRef]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | BackBone | ASPP | PSM | Params. (M) | MIoU (%) | MAcc (%) |
|---|---|---|---|---|---|---|
| Non-EFAM | ResNet101 | √ | 59.3 | 78.4 | 87.2 | |
| Non-EFAM | ResNet101 | √ | 59.3 | 79.7 | 88.7 | |
| EFAM | ResNet101 | √ | 60.1 | 79.4 | 88.3 | |
| EFAM | ResNet101 | √ | 60.1 | 80.4 | 89.3 |
| Method | BackBone | Precision (M) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| Deeplabv3+ | ResNet101 | 86.5 | 86.6 | 86.5 |
| MFSNet | ResNet101 | 87.9 | 89.3 | 88.6 |
| BackBone | Post-Activation | Pre-Activation | MIoU (%) |
|---|---|---|---|
| ResNet50 | √ | 78.8 | |
| ResNet50 | √ | 78.9 | |
| ResNet101 | √ | 80.2 | |
| ResNet101 | √ | 80.4 |
| Method | Params. (M) | MIoU (%) |
|---|---|---|
| ASPP + CBAM [38] | 60.4 | 79.9 |
| ASPP + SE [18] | 60.4 | 79.8 |
| ASPP + ECA [39] | 60.1 | 79.9 |
| ASPP + SA [23] | 60.1 | 80.0 |
| PSM | 60.1 | 80.4 |
| Method | Backbone | Resolution | MIoU (%) | MAcc (%) |
|---|---|---|---|---|
| CCNet [41] | ResNet101 | 77.8 | 85.1 | |
| GCNet [17] | ResNet101 | 77.8 | 86.0 | |
| PSPNet [9] | ResNet101 | 78.5 | 87.0 | |
| PSANet [42] | ResNet101 | 77.7 | 85.0 | |
| DeepLabv3+ [12] | ResNet101 | 78.4 | 86.0 | |
| OCRNet [43] | HRNetV2p-W48 | 77.1 | 85.9 | |
| MARS [44] | ResNet101 | - | 77.7 | - |
| WASS-SAM [2] | ResNet101 | - | 77.2 | - |
| MFSNet (Ours) | ResNet50 | 78.9 | 87.8 | |
| MFSNet (Ours) | ResNet101 | 80.4 | 89.3 |
| Method | Backbone | Resolution | MIoU (%) | MAcc (%) |
|---|---|---|---|---|
| GCNet [17] | ResNet101 | 78.2 | 85.7 | |
| PSPNet [9] | ResNet101 | 78.3 | 85.3 | |
| DMNNet [6] | ResNet101 | 77.6 | 86.4 | |
| CCNet [41] | ResNet101 | 76.9 | 84.9 | |
| DeepLabv3+ [12] | ResNet101 | 79.0 | 87.0 | |
| PointRend [45] | ResNet101 | 78.3 | 85.7 | |
| APCNet [46] | ResNet101 | 77.9 | 87.1 | |
| PSANet [42] | ResNet101 | 78.4 | 87.4 | |
| Multiscale DEQ [47] | MDEQ-large | 77.8 | - | |
| UOIFT [7] | UOIFT | - | 78.0 | - |
| STDC [8] | STDC2 | 76.7 | 84.0 | |
| BiSeNetV2 [48] | BiSeNetV2 | 75.7 | 83.4 | |
| StreamDEQ [49] | MDEQ-iter8 | 78.2 | - | |
| EEA-NEt-C2 [50] | EEA-NEt-C2 | 76.8 | - | |
| MFSNet (Ours) | ResNet50 | 78.5 | 87.4 | |
| MFSNet (Ours) | ResNet101 | 79.4 | 88.3 |
| Class | DeepLabv3+ (%) | MFSNet (%) |
|---|---|---|
| Road | 98.5 | 98.2 |
| Sidewalk | 87.1 | 87.3 |
| Building | 92.8 | 93.2 |
| Wall | 51.3 | 51.6 |
| Fence | 62.4 | 63.2 |
| Pole | 66.5 | 69.1 |
| Traffic light | 70.6 | 73.1 |
| Traffic sign | 79.1 | 81.6 |
| Vegetation | 92.7 | 93.1 |
| Terrain | 64.1 | 64.5 |
| Sky | 95.0 | 94.2 |
| Person | 82.7 | 84.2 |
| Rider | 63.2 | 64.4 |
| Car | 95.7 | 95.9 |
| Truck | 86.1 | 83.2 |
| Bus | 89.1 | 89.6 |
| Train | 78.0 | 74.6 |
| Motorcycle | 68.9 | 69.1 |
| Bicycle | 78.1 | 79.5 |
| Method | Backbone | Resolution | MIoU (%) | MAcc (%) |
|---|---|---|---|---|
| PSPNet [9] | ResNet101 | 37.2 | 49.3 | |
| RefineNet [51] | ResNet101 | 33.6 | - | |
| DANet [52] | ResNet101 | 39.7 | - | |
| DeepLabv3 | ResNet101 | 37.3 | 49.3 | |
| DeepLabv3+ [12] | ResNet101 | 38.4 | 50.2 | |
| OCRNet [43] | ResNet101 | 39.5 | - | |
| MFSNet (Ours) | ResNet101 | 40.1 | 51.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, X.; Shu, C.; Jin, W.; Yu, Y.; Yang, S. MFSNet: Enhancing Semantic Segmentation of Urban Scenes with a Multi-Scale Feature Shuffle Network. Electronics 2024, 13, 12. https://doi.org/10.3390/electronics13010012
Qian X, Shu C, Jin W, Yu Y, Yang S. MFSNet: Enhancing Semantic Segmentation of Urban Scenes with a Multi-Scale Feature Shuffle Network. Electronics. 2024; 13(1):12. https://doi.org/10.3390/electronics13010012
Chicago/Turabian StyleQian, Xiaohong, Chente Shu, Wuyin Jin, Yunxiang Yu, and Shengying Yang. 2024. "MFSNet: Enhancing Semantic Segmentation of Urban Scenes with a Multi-Scale Feature Shuffle Network" Electronics 13, no. 1: 12. https://doi.org/10.3390/electronics13010012