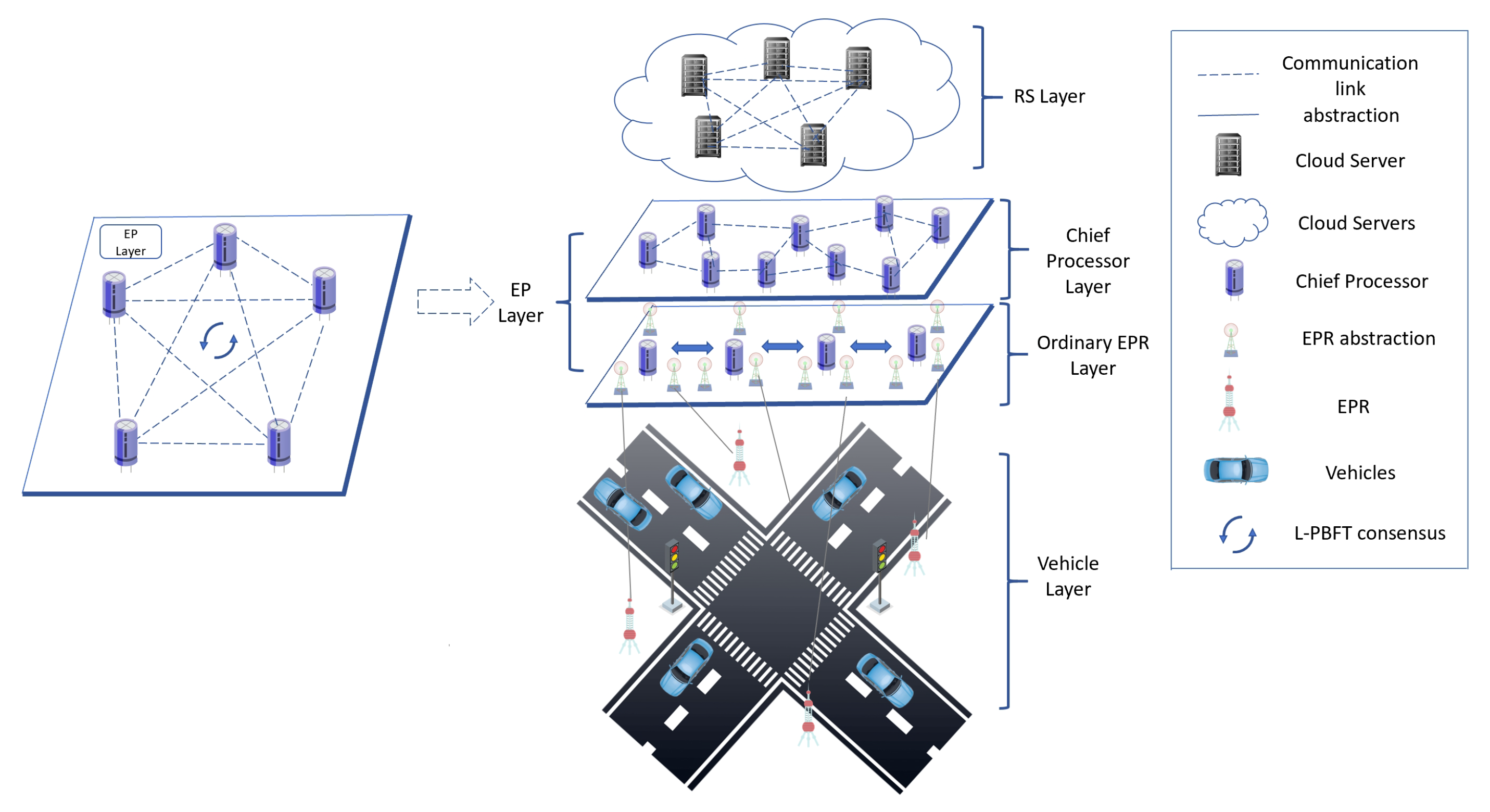
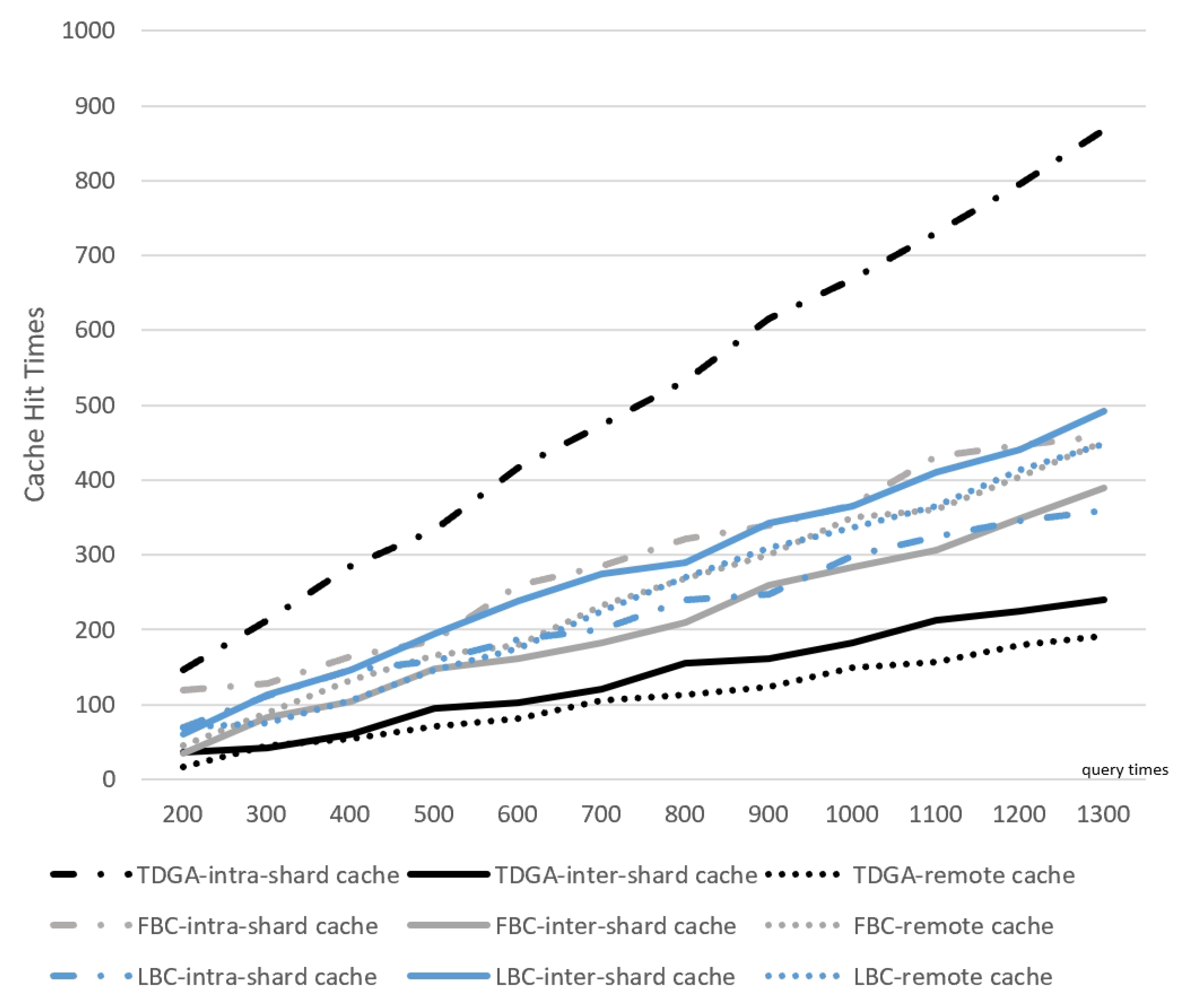
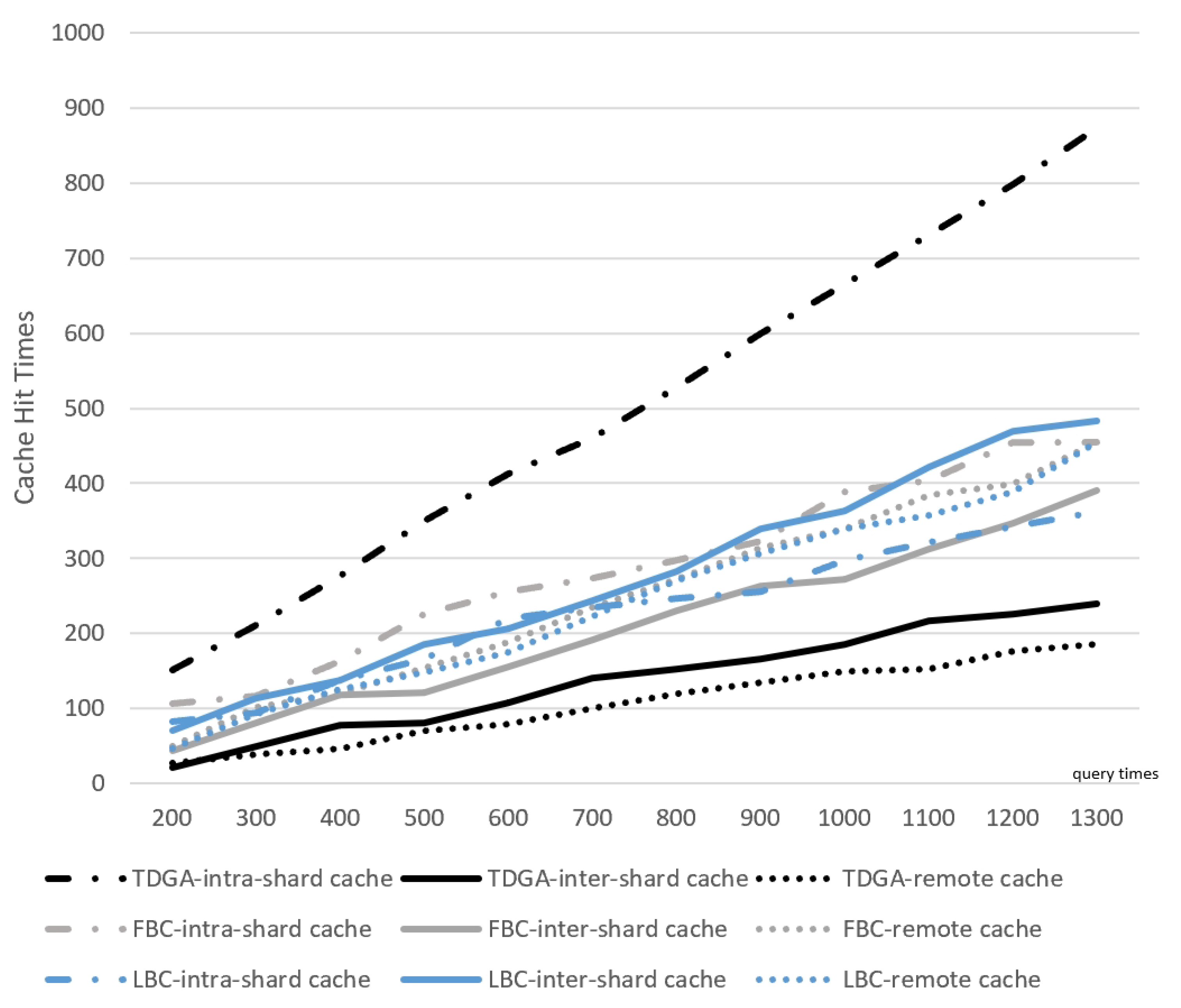
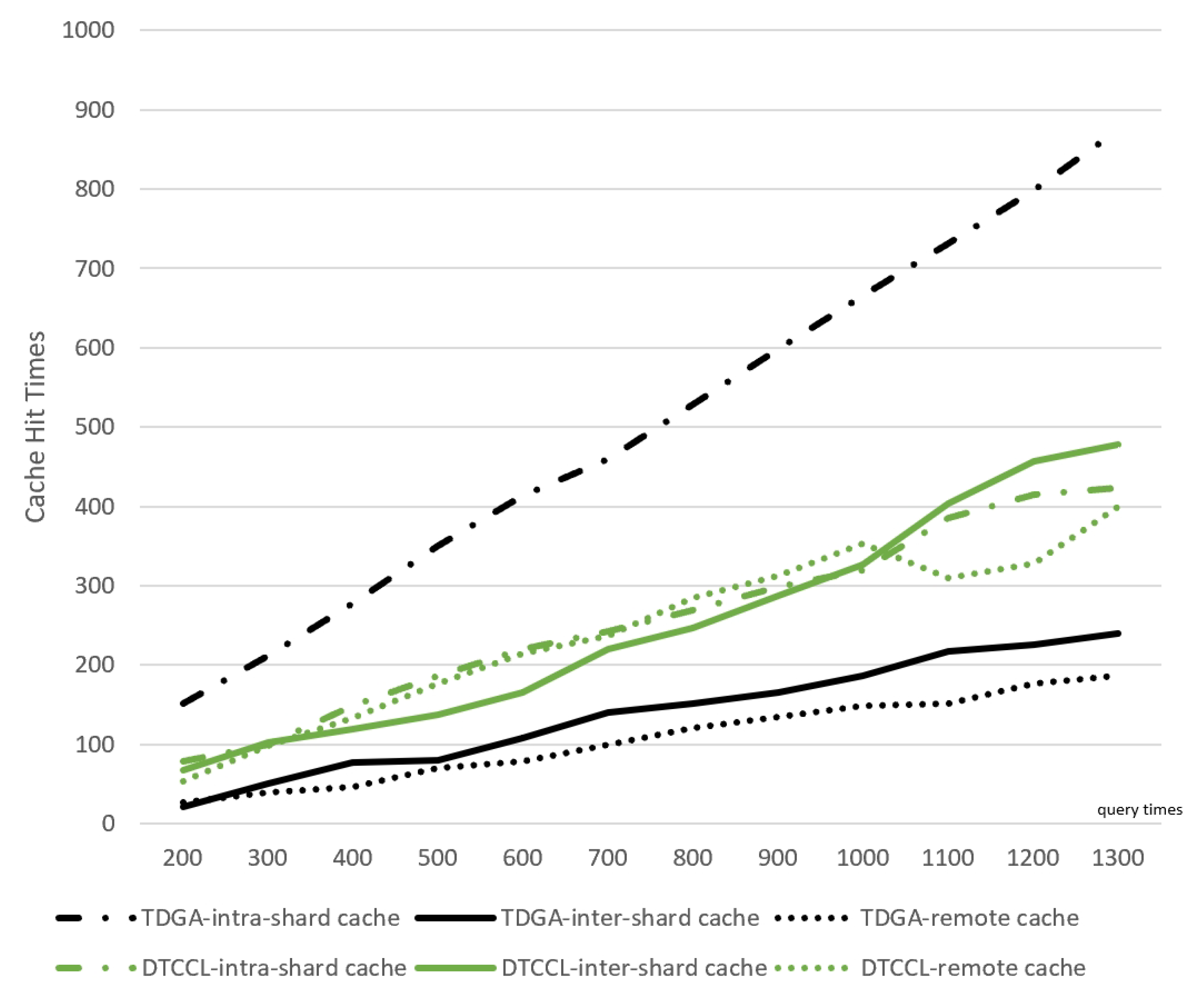
Traditional approaches commonly utilize a central server to cache the blockchain. We propose a Content Sharding mechanism to allow nodes within one group to cache similar blocks and nodes between various groups to cooperatively store the whole blockchain. The ES Layer provides services to vehicles in the form of cooperative search. This pattern can reduce the complexity of the central server to a certain extent, and at the same time improve the response speed of EPRs and balance the network load.
4.1. Group Caching and Data Access Costs
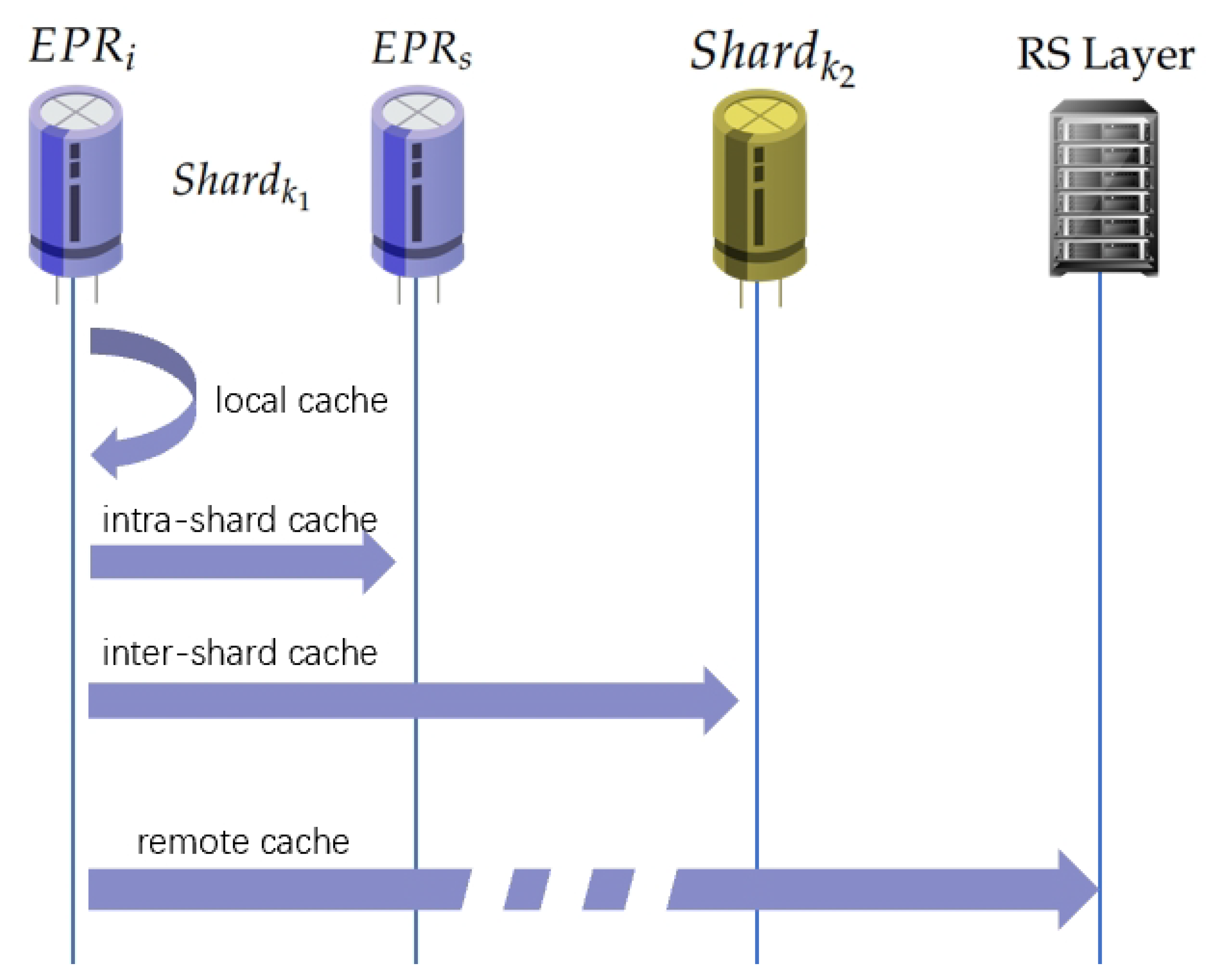
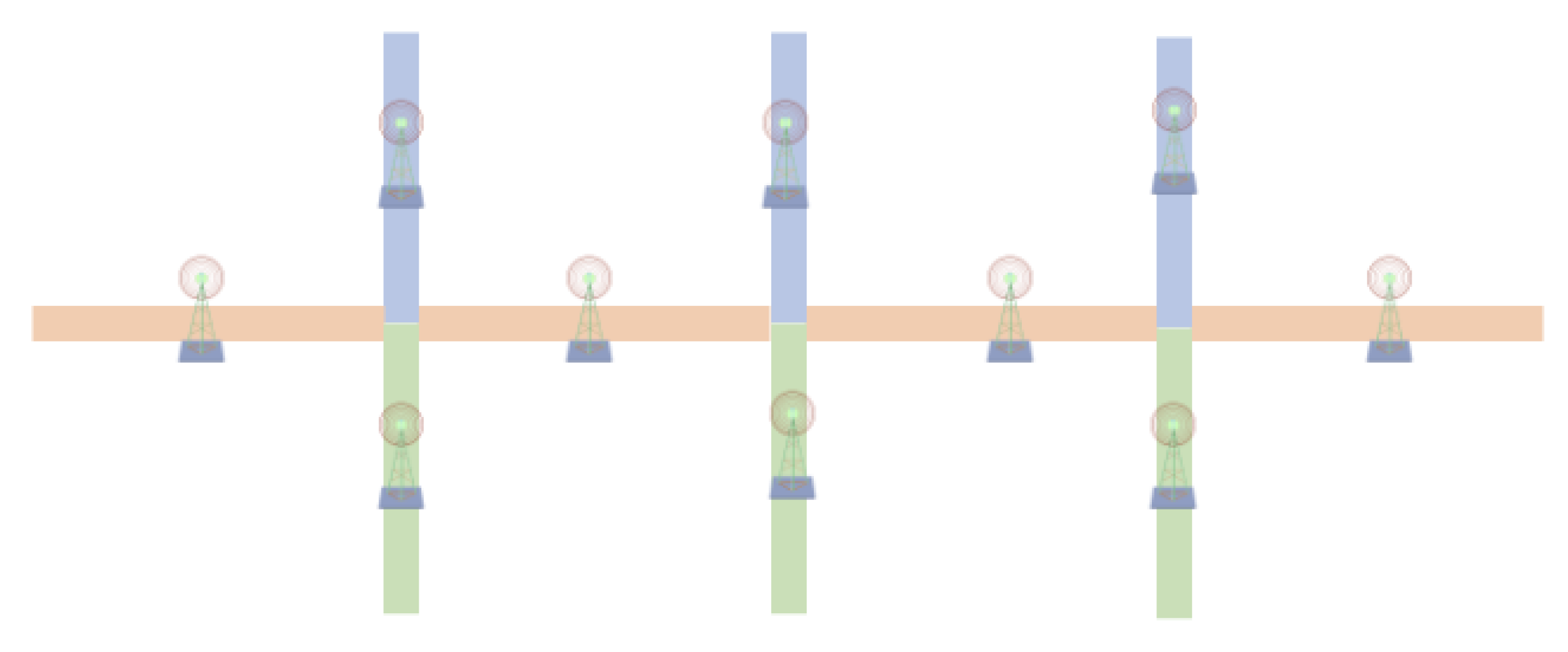
Since the blocks are scattered on different EPRs, the block storage of one EPR may not always be able to fully cover its incoming block query requests. Therefore, EPRs need to cooperate with each other to provide complete services. Different search paths for different cache locations of the blocks are shown in
Figure 2. The cost of a node accessing its own storage list is different from the cost of a node forwarding a query through a network request. In order to be able to better describe the above process, we define the cost function for a single data access request, a single EPR in (
10):
where
is a block with sequence number
j and
, where
J is the total number of blocks. Then, the blocks caching in
can be denoted as
.
stands for request with sequence number
r and
, where R is the total number of requests.
is the index of EPR being requested, where
. In
,
is one of the neighbors of
, which caches
.
There exist five search paths for various cache locations. and stand for the cost of search local and neighbor cache; stands for the cost of the forward request to another ; stands for the cost of the offered help from remote storage. and represent the transmission cost on short links between in the same and long links between and .
Since the TDVS algorithm takes into account the topology, there exists . Hence, the cost of a single request grows larger as the block cache location becomes farther.
4.2. Content Sharding
In the context of network data caching, whether a block is stored on a EPR depends on how often the block is accessed and how much it costs to query or forward. This process requires continuous learning and revision of the system. So, we employ the Traffic-Data-based Genetic Algorithm (TDGA) to solve the block cache location problem. The GA simulates the process of block caching as the evolution of a population. In the temporal dimension, the population keeps reproducing to adapt to the data access patterns; in the spatial dimension, the individuals within the population interact and collaborate with each other, exploring to find an excellent evolutionary direction. Scholars have already been using Genetic Algorithms (GAs) to solve caching problems. For example, Ref. [
32] introduces a self-tuning cache replacement policy based on which the future request of a cache block is forecast based on its access pattern. The proposed policy constantly balances among the potential attributes of the object in the cache memory: recency, frequency, size, and time. However, Ref. [
32] focuses on the traditional cache policy rather than the blockchain field. The TDGA combines the GA and blockchain concept tightly to realize an effective block caching strategy. The pseudocode of the GA is Algorithm 3.
We use
to stand for a set of cached blocks in
. Thus, an individual of the GA is denoted as (
11), where
and M is the population size:
The fitness of this individual is (
12):
Thus, the population and its fitness set can be represented as (
13):
| Algorithm 3 Pseudocode for GA. |
- Input:
population size M, mutation possibility , crossover possibility , convergence threshold , maximum iterations , total number of blocks J - Output:
best individual - 1:
current timer t ← 0 - 2:
← random generate M individuals - 3:
- 4:
, 0 - 5:
for
do - 6:
← FC() - 7:
- 8:
end for - 9:
while t do - 10:
, ← RWS(, ) - 11:
for and from 1 to M with step = 2 do - 12:
and from - 13:
= random float - 14:
= random float - 15:
if then - 16:
, ← CO(, ) - 17:
else if then - 18:
← MU(, J) - 19:
← MU(, J) - 20:
end if - 21:
- 22:
- 23:
end for - 24:
- 25:
for do - 26:
← FC() - 27:
- 28:
end for - 29:
with = - 30:
with = - 31:
if then - 32:
if then - 33:
BREAK - 34:
end if - 35:
- 36:
- 37:
end if - 38:
t ← t + 1 - 39:
end while - 40:
return
|
In Algorithm 3, Roulette Wheel Selection (RWS) is one of the selection methods and follows the definition in [
33]. The probability of an individual being selected is proportional to the size of its fitness. The Fitness Calculation (FC) function refers to (
12).
The Crossover (CO) function follows the rule of two-point crossover in [
34], shown in Algorithm 4. There are some well-known crossover operators, such as single point, two point, k point, uniform, and so on. As concluded in [
34], these methods both have pros and cons. Single-point crossover is easy to implement, but it lacks diversity. Two-point crossover has a similar effect, but it is applicable on small subsets. Uniform crossover has better recombination potential but still lacks diversity. Other crossover solutions have redundancy issues and premature convergence.
Based on real tests, we apply two-point crossover in our design. There are two reasons:
Two-point crossover has lower complexity and cost. Considering the previously mentioned node shard mechanism, the entities that are actually involved in the genetic algorithm are drastically reduced after partitioning. In other words, the size of in the cache reallocation is reduced from I (total number of EPRs) to K (total number of shards), where K ≪ I. Thus, two-point crossover with lower complexity and operating cost is well suited to the model of this paper.
Two-point crossover makes sense in the context of the real world. The chromosome designed in this paper is a list of blocks cached by all shards. The cached list is actually equivalent to a single gene. The crossing of two individuals can be considered as exchanging a useful cache with each other. Thus, two-point crossover makes physical sense.
| Algorithm 4 Pseudocode for CO. |
- Input:
two individual and - Output:
two individual after crossover and - 1:
= random integer - 2:
= random integer - 3:
if
then - 4:
switch and - 5:
end if - 6:
switch in and in - 7:
← after switch - 8:
← after switch - 9:
return ,
|
There are also many types of mutation operations. Based on the best combination of operations mentioned in [
34], we choose to use the value displacement mutation to fit the two-point crossover above, shown in Algorithm 5.
| Algorithm 5 Pseudocode for MU. |
- Input:
an individual , total number of blocks J - Output:
an individual after mutation - 1:
= random integer - 2:
= random integer - 3:
= random integer - 4:
changes the block in with position into - 5:
← after change - 6:
return
|
In the area of selecting ratios of crossover and mutation, recent scholars have used different parameters. Ref. [
35] tests the crossover rate from 0.1 to 0.9 and finds out that the best crossover rates are 0.5 and 0.6. Ref. [
36] sets the mutation rate to be 0.25. Ref. [
37] sets the crossover rate = 0.7 and mutation rate = 0.01 to 0.04. Ref. [
38] suggests that the general value of the crossover probability is 0.4 to 0.99, and the range of mutation probability is 0.0001 to 0.1. Ref. [
39] sets the crossover rate = 0.8 and mutation rate = 0.01. Ref. [
40] sets the crossover rate = 0.5 and mutation rate = 0.01. Ref. [
41] sets the crossover rate = 0.7 and mutation rate = 0.3.
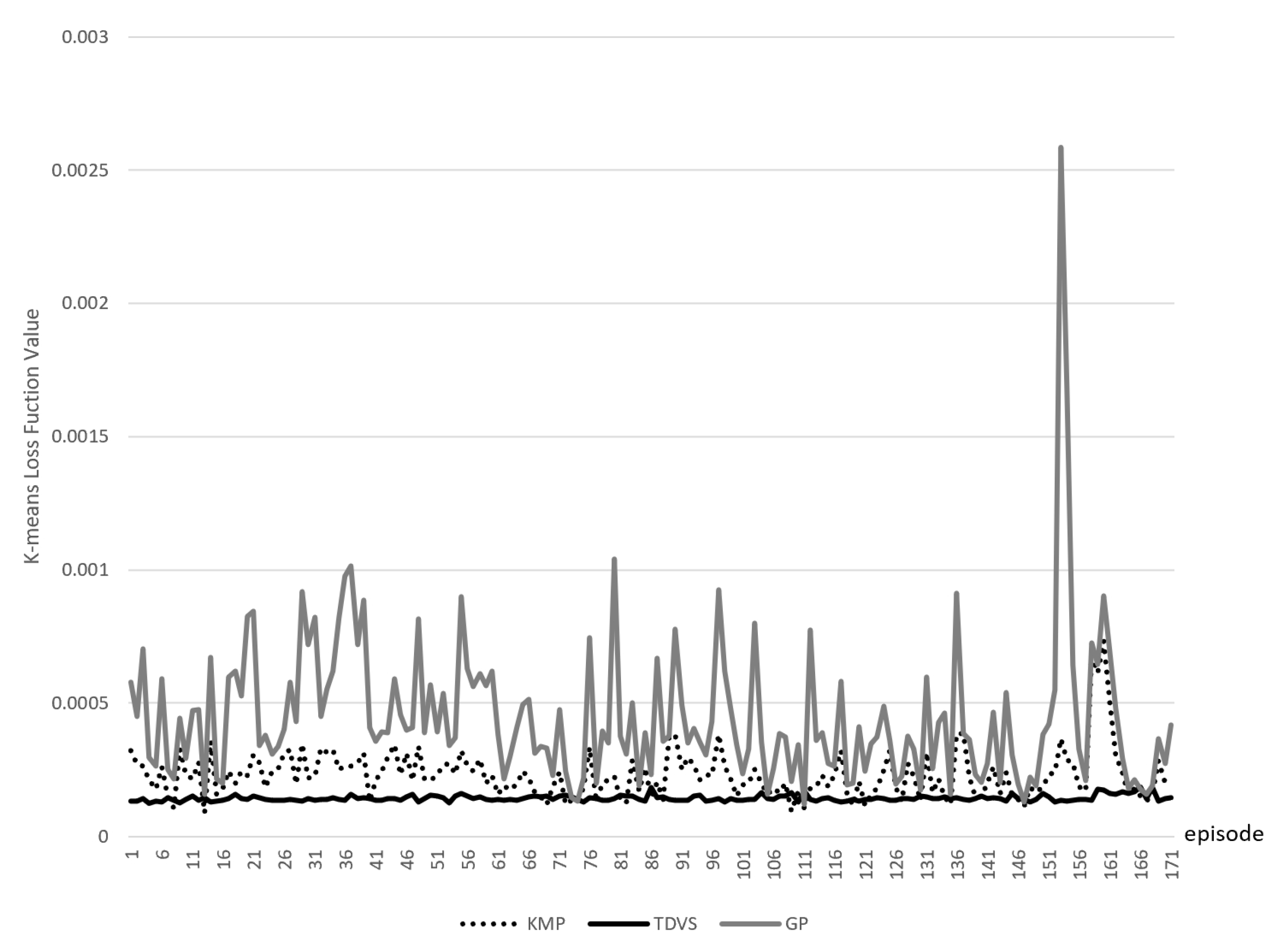
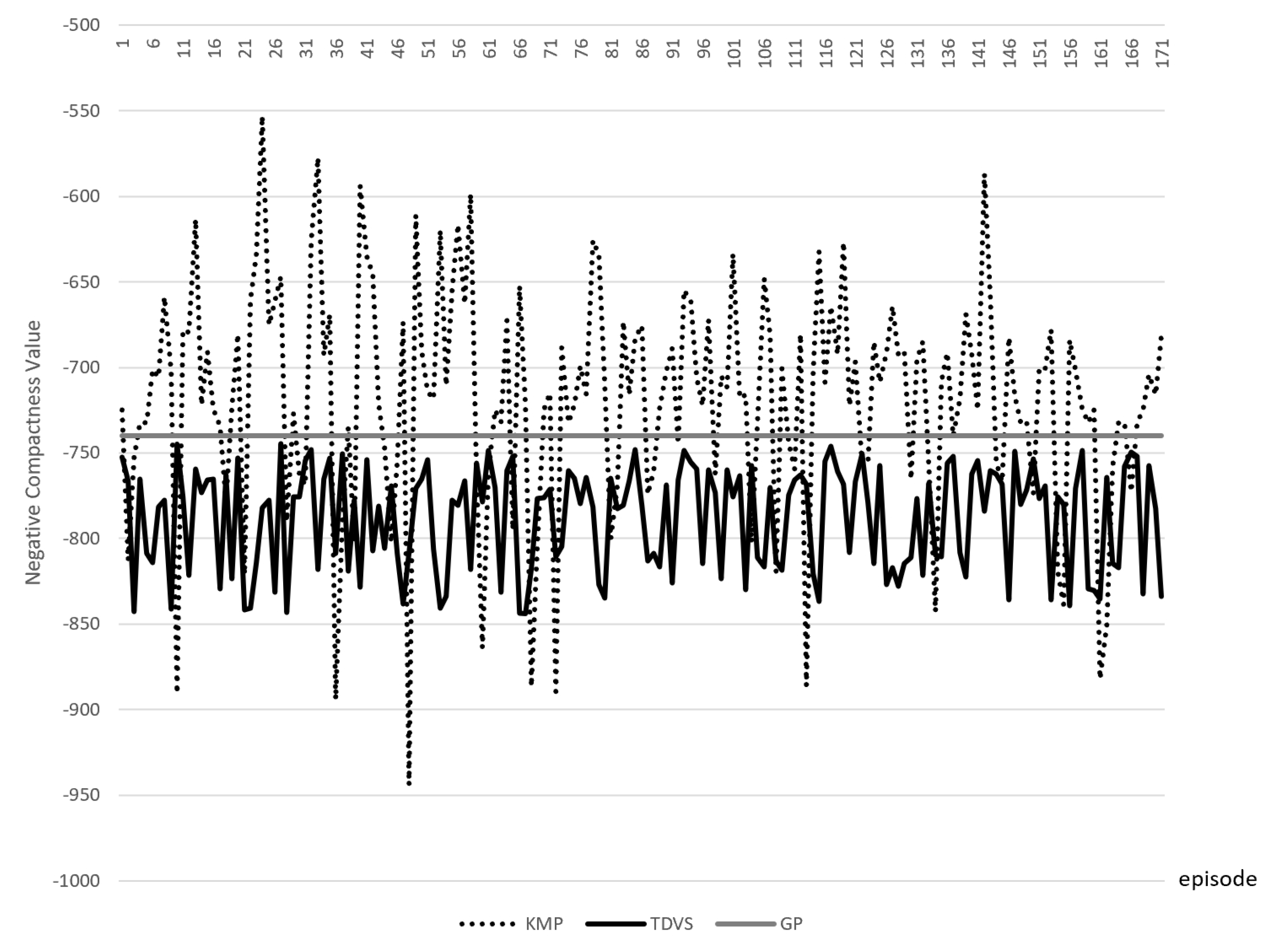
In the actual optimization, we find out that the combination of the crossover rate = 0.4 and mutation rate = 0.5 can achieve a more stable and high fitness value. The crossover rate seems to be smaller while the mutation rate seems to be larger than the settings described above. Such a choice is based on considerations of both scale and the experimental results. On the one hand, the crossover part of a chromosome is
of the individual size, which is a relatively large proportion in the case of a smaller value of
K. for better management. This leads to a smaller crossover probability. Moreover, the number of digits involved in the mutation operation is less compared to the number of digits in the whole chromosome (
). This leads to a larger mutation probability. On the other hand, based on actual tests and attempts, larger crossover rates and smaller mutation rates lead to high-fitness individual oscillations and difficulty in convergence. Ref. [
42] proposes that crossover appears to be more efficient than the mutation in larger population sizes, and the mutation is more efficient in small populations. Taking into account that cache allocation should be highly real time, the population size needs to be scaled down to a smaller range. So under the condition of a small population, the combination of a higher mutation probability and lower crossover probability can obtain better experimental results indeed also in accordance with the theoretical description.
In our design, the crossover and mutation strategies are dichotomous in each iteration. Although most genetic algorithms are used with both of these two, we have observed in real-world tests that using both operations leads to a faster increase in the fitness of the population but inevitably leads to oscillations at the high points as time goes by. Ref. [
32] also suggests that crossover and mutation strategies do not work for every chromosome. Ref. [
43] makes the same choices: pairs of the permutations are randomly selected, and a crossover operation is conducted between those pairs. Each newly obtained offspring then undergoes either another crossover or a mutation operator. Ref. [
44] mentions that only some of the offspring can participate in the mutation. Ref. [
45] uses a mutation probability to control for the dichotomy between crossover and mutation operations. Therefore, it is a feasible solution to set the crossover and mutation operations to be alternative for each individual.
We train the population by simulating a set of regular requests such as the fixed frequency of blocks being accessed on the EP Layer. The output contains the block lists of each shard.
With sufficient computing resources, the RS Layer integrates the data reported by the lower layer and undertakes GA. The CPs of each shard broadcast the block list issued by the RS Layer to other ordinary nodes within the same shard. One block list is shared within the shard and is the most compatible with the data features of the assigned shard.
Furthermore, EPRs within the same shard will filter the blocks suitable for their service pattern. The filtering principle is based on the relevance degree introduced in the next section.
4.3. Relevance Degree of Blocks on EPRs
EPRs aim to select the blocks that are most valuable to them. Therefore, we define a measurement of the storage priority between a block and a EPR. The Relevance Degree (RD) can influence whether the block can stay or not. Firstly, the presentation of the pattern of the block content and the node being accessed needs to be numerically settled.Then, the relevance between these two is assessed.
Due to the variety of types of on-board applications, the structure and content of data may vary greatly from application to application. However, the way of describing the data of different applications is more likely to have textual descriptions or textual remarks. Therefore, in order to be compatible with the data uploaded and downloaded in the network, we exploit some values relating to keywords to describe a segment of data. Details of the numerical depiction of a segment of data are below.
Firstly, some professional lexical tools or manual methods can be applied to produce a list of words that appear in certain IoV data. Since this part is beyond our scope, it will not be introduced later. We mainly focus on the depiction of a segment of data after structuring and its subsequent evolution. Referring to the implementation of the Term Frequency-Inverse Document Frequency (TF-IDF) method [
46],
and
are denoted as the quantitative expression of history requests of
and the content analysis expression of block
.
V is the total number of keywords:
The Kullback–Leibler (KL) divergence in [
47] and Jensen–Shannon (JS) divergence in [
48] are both used for a measurement of how one probability distribution is different from a second. JS divergence has relatively small numerical fluctuations and is symmetrical. Thus, the Relevance Degree between
and
is denoted as (
16):
EPRs picks the top several blocks closest to them and then add them to the local cache.
4.4. Complexity Analysis
The space complexity (
) of the GA relates to the number of individuals (
M) and the individual capacity (
). The individual capacity relates to the total number of EPRs (
I) and the total number of blocks contained in a single EPR (
). The space complexity of the GA algorithm is given in the following formula:
The time complexity (
) of the GA relates to the number of iterations (
) and the number of individuals
M:
Parallelization Process
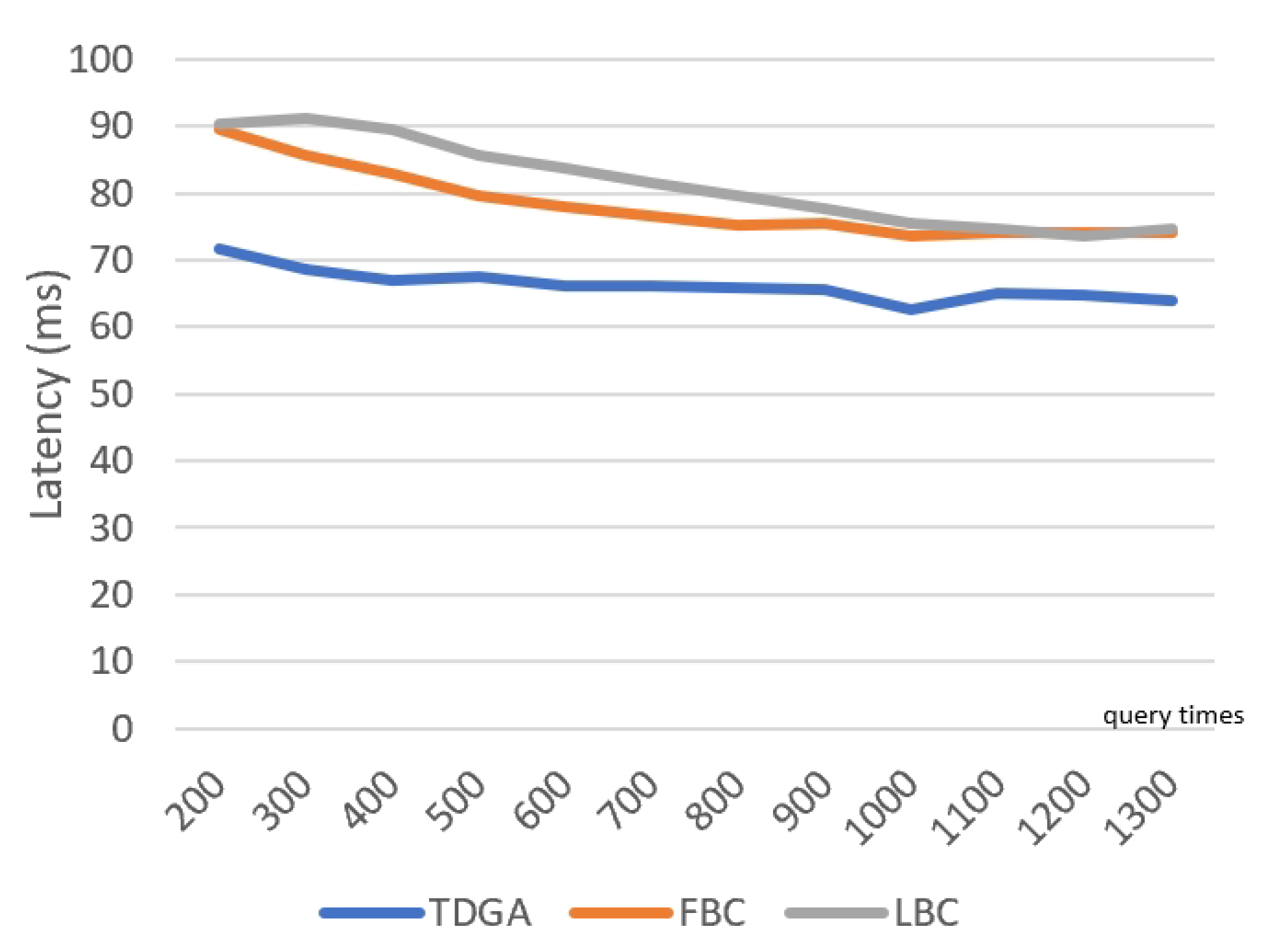
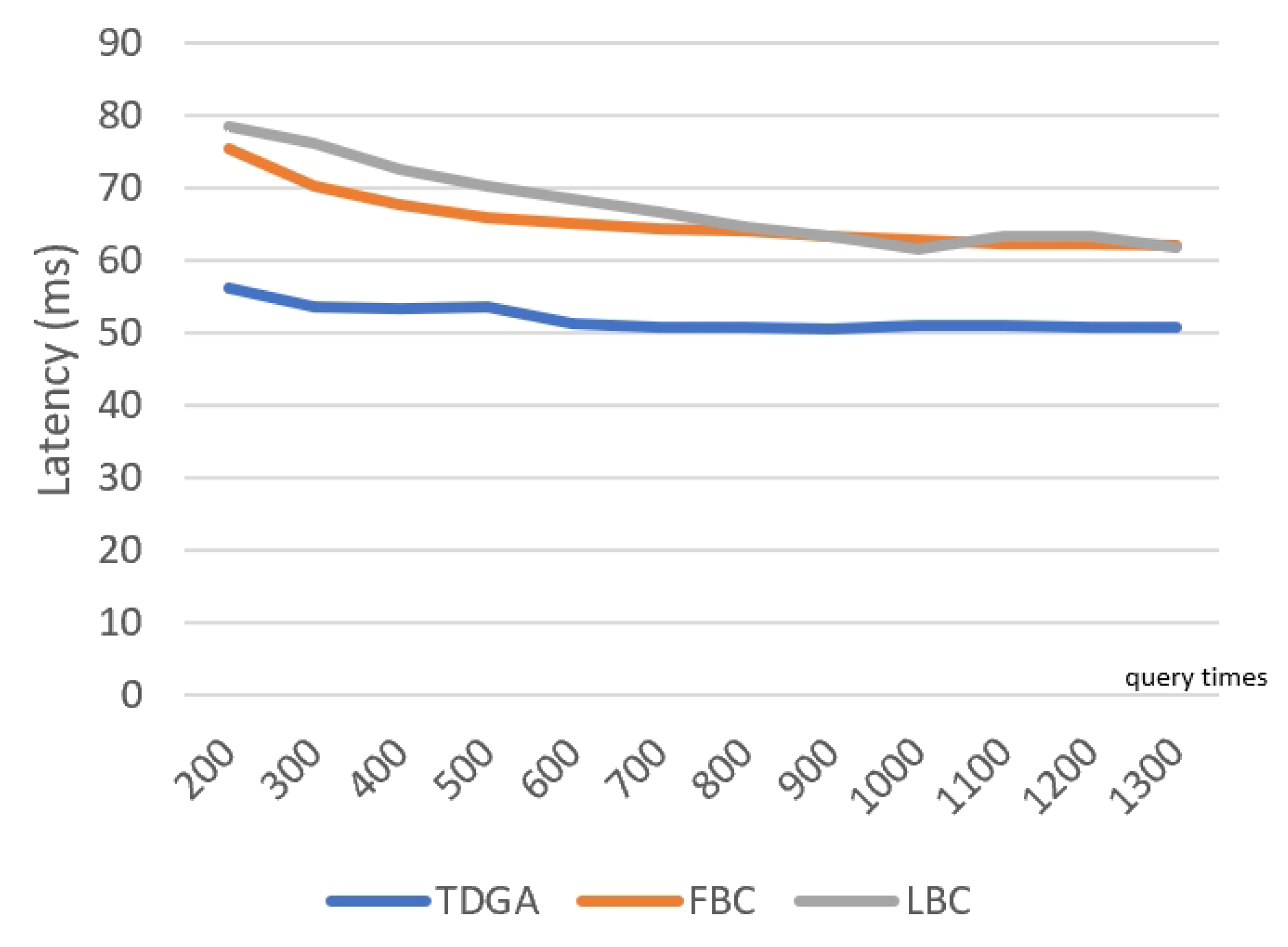
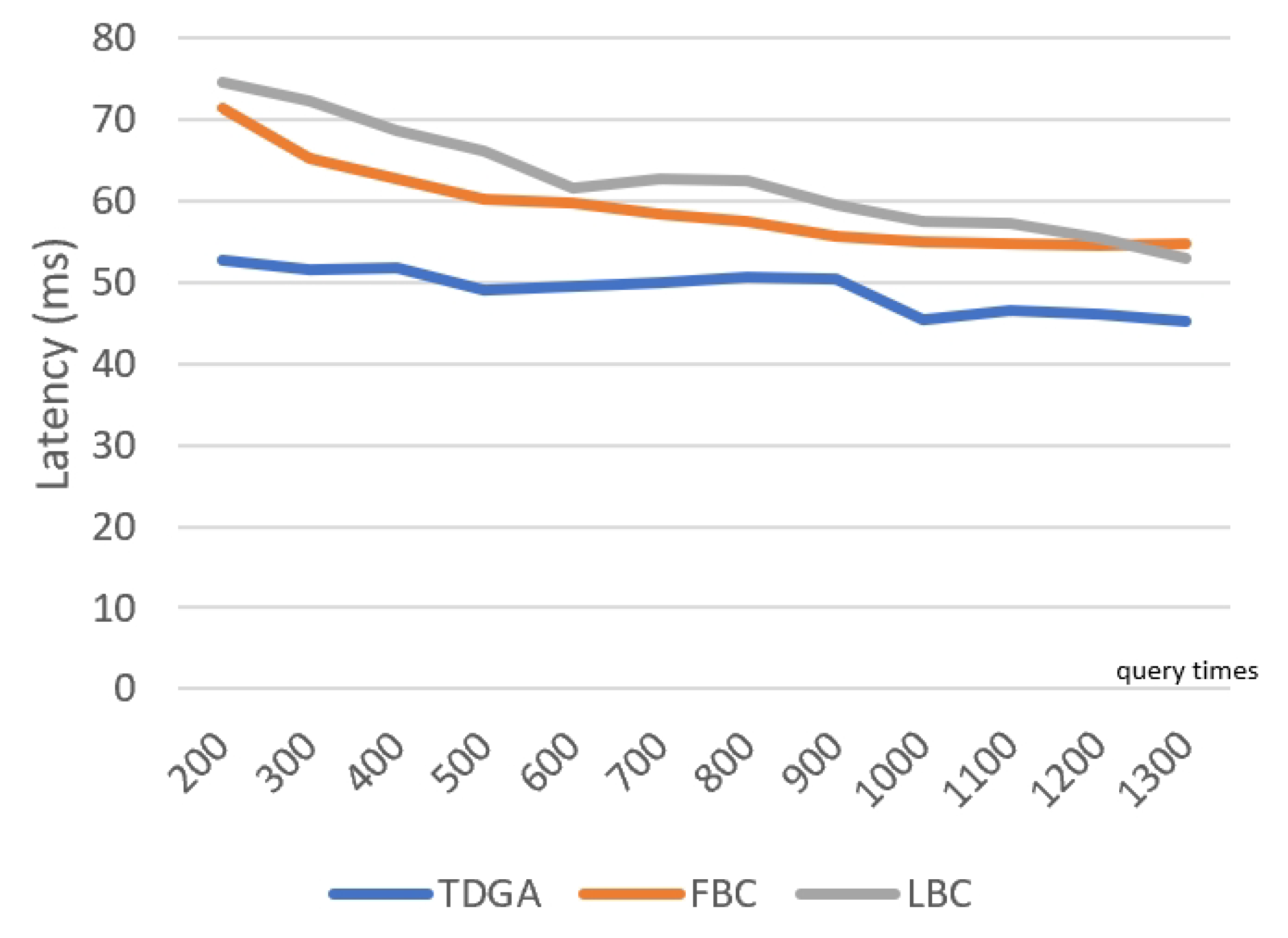
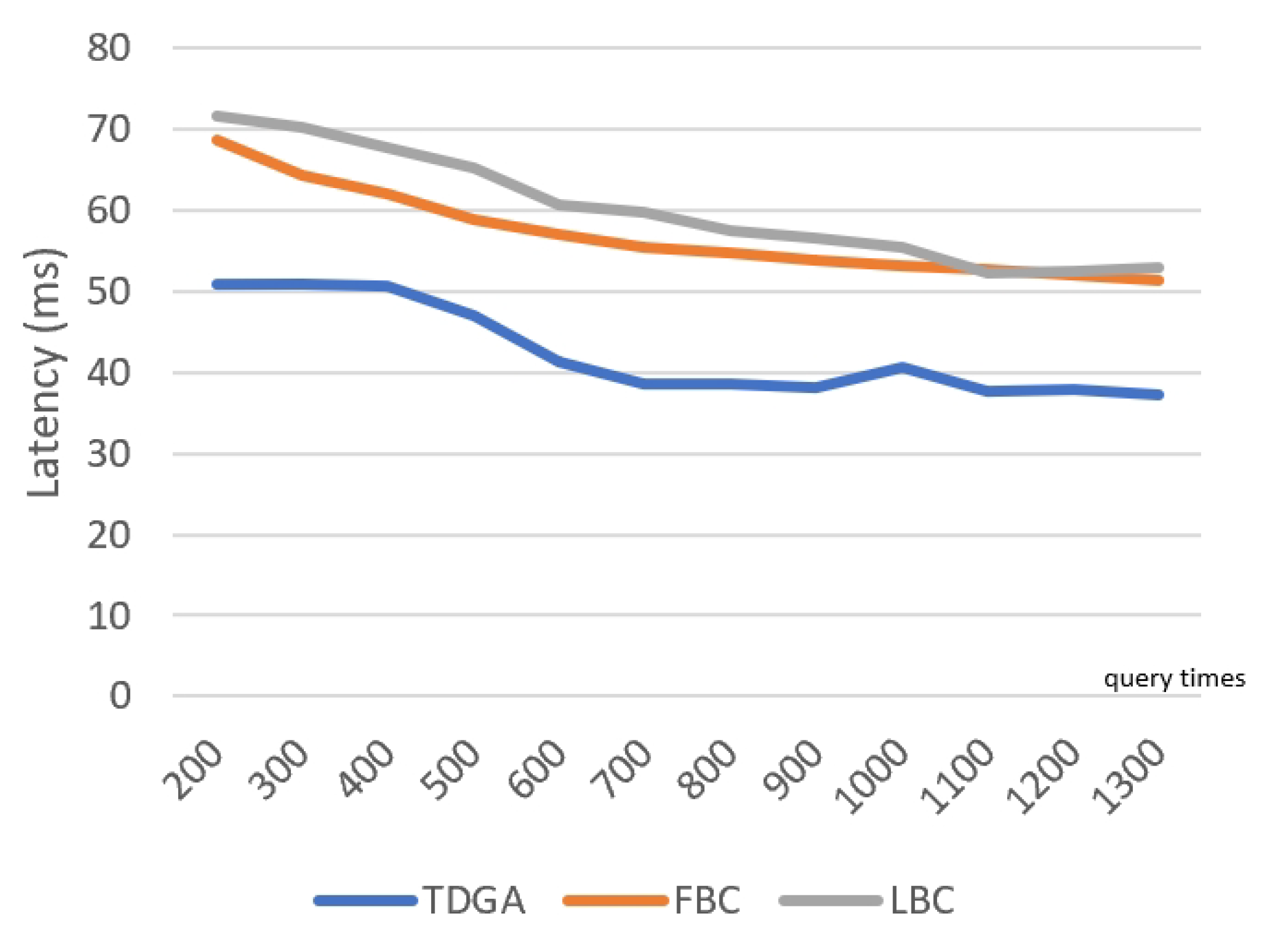
The TDGA searches for the global optimal solution as much as possible by using a large number of individuals and generations. Therefore, the number of iterations and the number of individuals M need to be large enough. For a single node to run the above algorithm, the time complexity and space complexity are indeed high.
However, the crossover and mutation operations designed in this paper involve at most two neighboring individuals. Moreover, these two neighboring individuals can be determined immediately after the start of each iteration. Therefore, the crossover and mutation operations at each round of iteration can be processed in parallel.
It is a reasonable assumption that all EPRs participate in the algorithm computation. For each computation node, the number of individuals to be processed per iteration is
, where
I represents the total number of EPRs. Each computation node can perform the crossover, mutation and updating of fitness on each set of individuals. Finally, the
I computation results are aggregated to the main process, and the new population is derived using the RWS mentioned above in [
33]. For a single computation node, the space and time complexities are reduced to
and
below:
There are some recommendations of the chosen
M in the literature. Ref. [
49] believes that population size = 20 is enough. Ref. [
35] tests the population size from 20 to 200 and generation size from 200 to 500. The results show that a higher number of generations with a smaller population size performs better. And the best combination is a population size of 50 and generation size of 100. Refs. [
39,
40,
50] set the population size to be 100. Ref. [
42] refers that a population size of less than about 1000 chromosomes has positive effects. Ref. [
51] conducts a series of experiments to prove that for functions with a large number of dimensions, a size of 800 individuals with a number of generations equal to 1000 seems to be the most favorable. Thus,
M can be set to about 300, practically (between 20 and 1000).
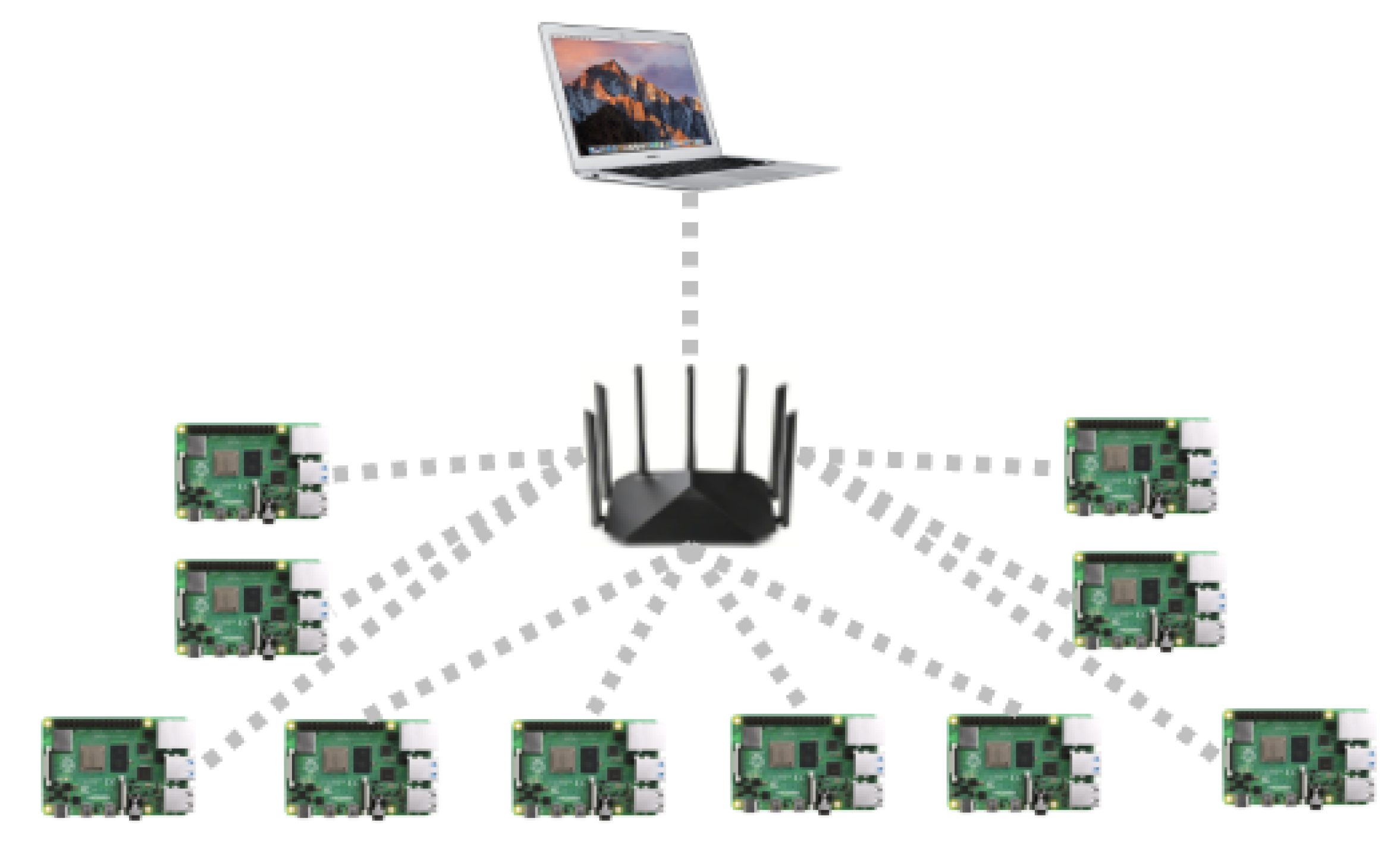
At the time of writing this paper, the total number of Bitcoin blocks is between 800,000 and 900,000. Thus, a 900,000-bit array can be used to store the block list within one node. Therefore, is set to be 900,000 bits.
Referring to (
19),
MB, which is far less than the memory of the fourth-generation Raspberry Pi (8GB) deployed in the next experiment section.
The total number of EPRs has the same order of magnitude as
M, which causes
in (
20) to be a small constant compared to
. As for the chosen generation number
, we were not able to find a unified standard figure. Refs. [
36,
39,
50] set the generation size to be 100. Ref. [
37] sets the value to be 200. Refs. [
40,
41] set it to be 1000. Moreover, in the next section, we also find that the highest fitness holds up at about 1000 generations. As a result,
can be set to 1000 in general, which is also affordable for Raspberry Pi (8 GB) deployed in the next experiment section.
The process of the TDGA has a short time interval, or can be triggered at regular intervals or under other suitable conditions. If the frequency of data updated is high under the current road conditions, then the task of data analysis is frequently added to the schedule of the RS Layer with high priority, which in turn leads to real-time changes in the block storage of the EPRs to meet the rapidly changing road environment. As mentioned earlier, the resource of the RS Layer is much better than the other two lower layers. Therefore, under the impetus of the rapidly updated and generated data, the increasing pressure of the other two lower layers is mainly manifested in communication. Pressure on the RS Layer is obviously greater than that of the other two layers, which will not reflect on the response speed of IoV services. In summary, the complexity of the TDGA can endure the rapid road information changes under the above algorithms.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}