
Joint Optimization of Task Caching and Computation Offloading for Multiuser Multitasking in Mobile Edge Computing
Abstract
:1. Introduction
- A new framework is designed for task caching and computation offloading in dynamic MEC environments by handling large-scale user requests under resource constraints. The combined optimization challenge of offloading computations and caching tasks is framed as a mixed-integer non-linear programming (MINLP) issue to reduce the system’s average delay and power usage.
- A P-DDPG algorithm is suggested for the combined optimization challenge of task caching and computational offloading, aiming to identify the most effective strategies for caching and offloading. Integrating the priority experience replay (PER) system disrupts the link between training experiences and enhances the accessibility of the experience replay buffer, thus boosting both the efficiency of training and the consistency of outcomes.
2. Related Work
3. System Model and Problem Formulation
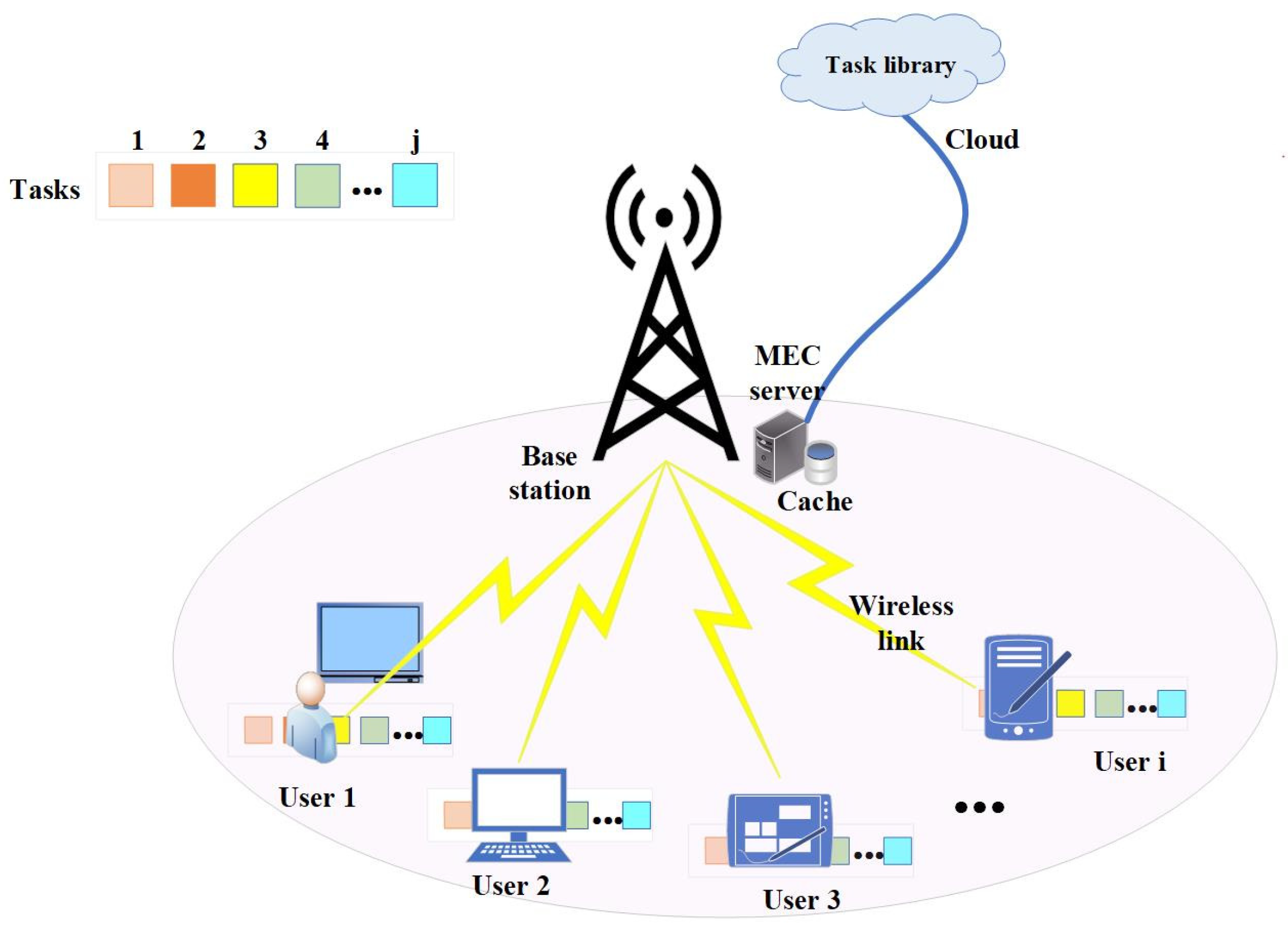
3.1. Network Model
3.2. Communication Model
3.3. Computation Model
- Local computation model;
- 2.
- MEC offloading model;
3.4. Caching Model
3.5. Problem Formulation
4. P-DDPG Algorithm
4.1. Formulation of the Problem with DRL
4.1.1. State Space
4.1.2. Action Space
4.1.3. Reward
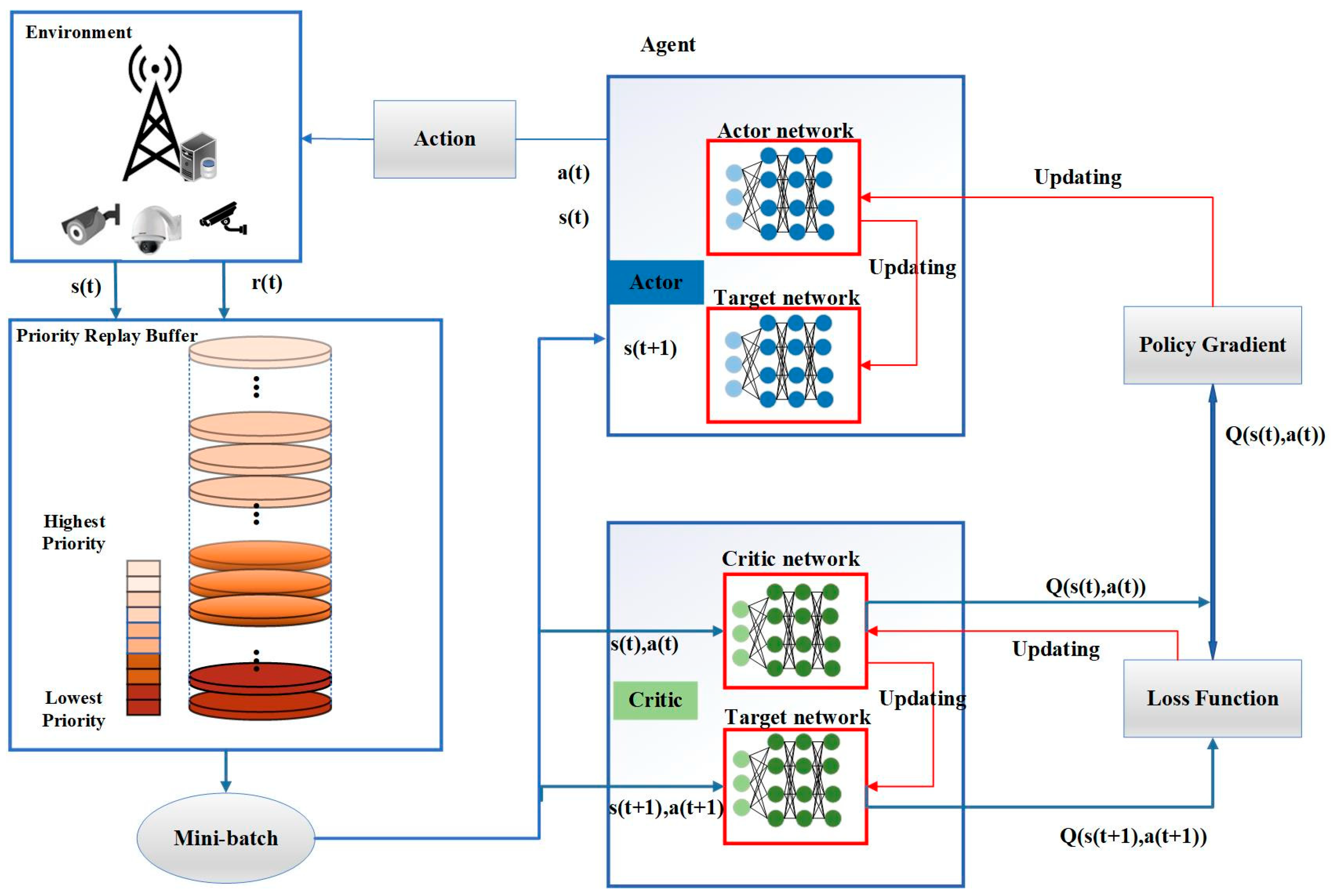
4.2. P-DDPG Algorithm Design
| Algorithm 1: P-DDPG algorithm |
| Initialize the priority experience playback buffer , the minimum batch size , the TD error sample size , the number of training times , the iteration time slot , and the weight control parameters and . Randomly initialize the weights and , discount factor , and update factor T of the main Q network and target Q network. Initialize the weight parameters , of the target network. 1: Initialize the main and target networks. 2: For do. 3: Randomly generate and receive initialized observation states . 4: Add random noise for action exploration. 5: For do. 6: The agent observes the state and selects actions according to the current strategy and noise . 7: Calculate the instant reward , and obtain the next immediate state after executing the action. 8: Based on the sampling probability in Equation (18), store and add it to the priority experience playback buffer . 9: Form a small batch I by sampling the most relevant experiences from the priority experience pool D. 10: Calculate the weight of the importance sample . 11: Calculate the target Q value . 12: Calculate the sampling probability of the TD error update experience from Equation (17). 13: Update the priority of the experience . 14: Update the of the critical network according to the loss function Equation (20). 15: Update the weights of the actor network parameters according to the strategy gradient strategy Equation (22). 16: Update the target network parameters according to Equations (23) and (24). 17: End for |
| 18: End for |
5. Performance Evaluation
5.1. Experimental Setup
- Local calculation (PCL): Each user doing the job performs it on the local CPU without offloading to the edge.
- Random cache and computation offload (RCAO): The ratio between the caching and the offloading of tasks to the computer is randomized for each time slot of the MEC server until the capacity of the cache is reached.
- DDQN: The selection and evaluation of actions are achieved through the use of different value functions, and tasks are cached and offloaded in an optimal ratio to achieve the lowest possible latency and power consumption.
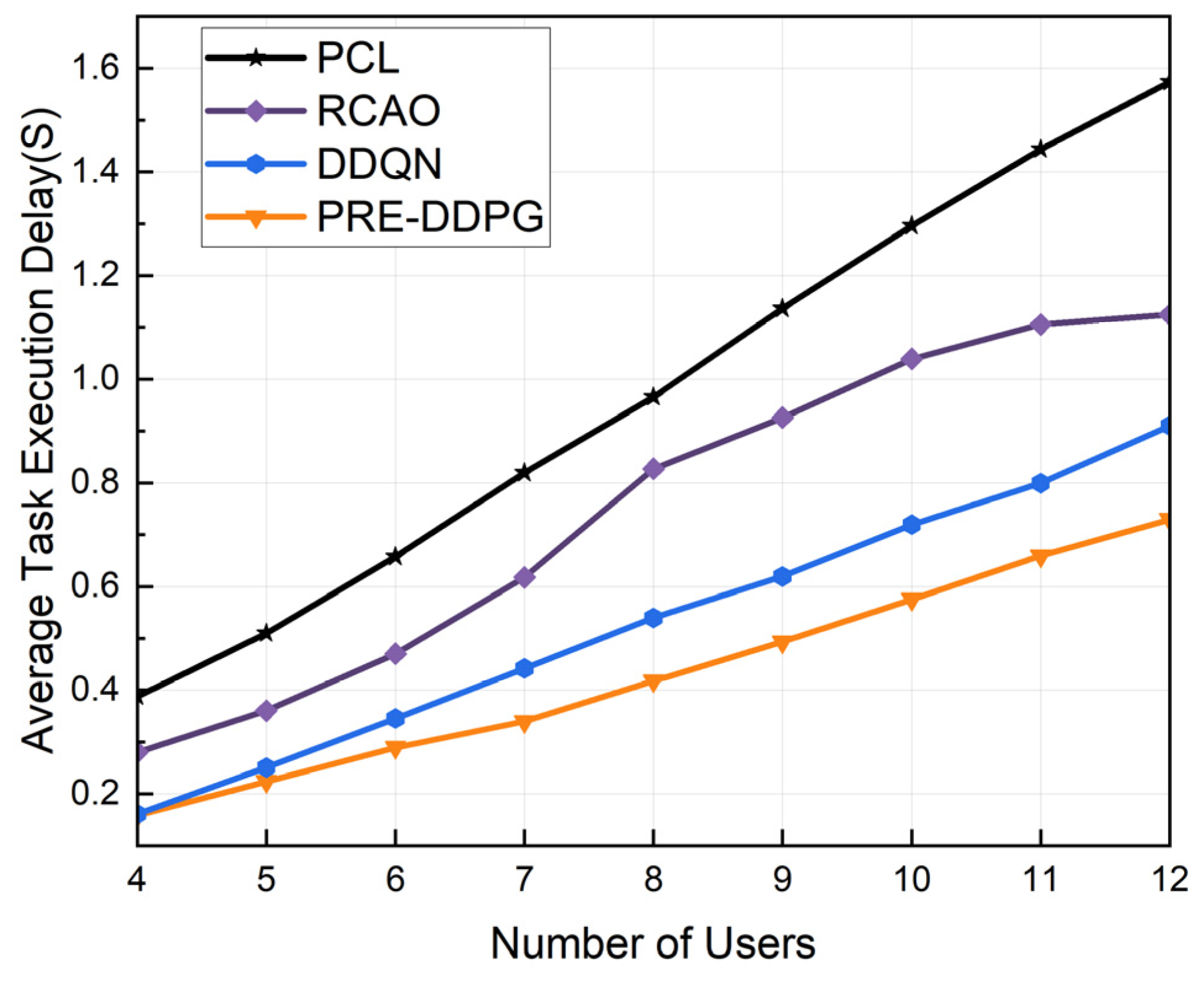
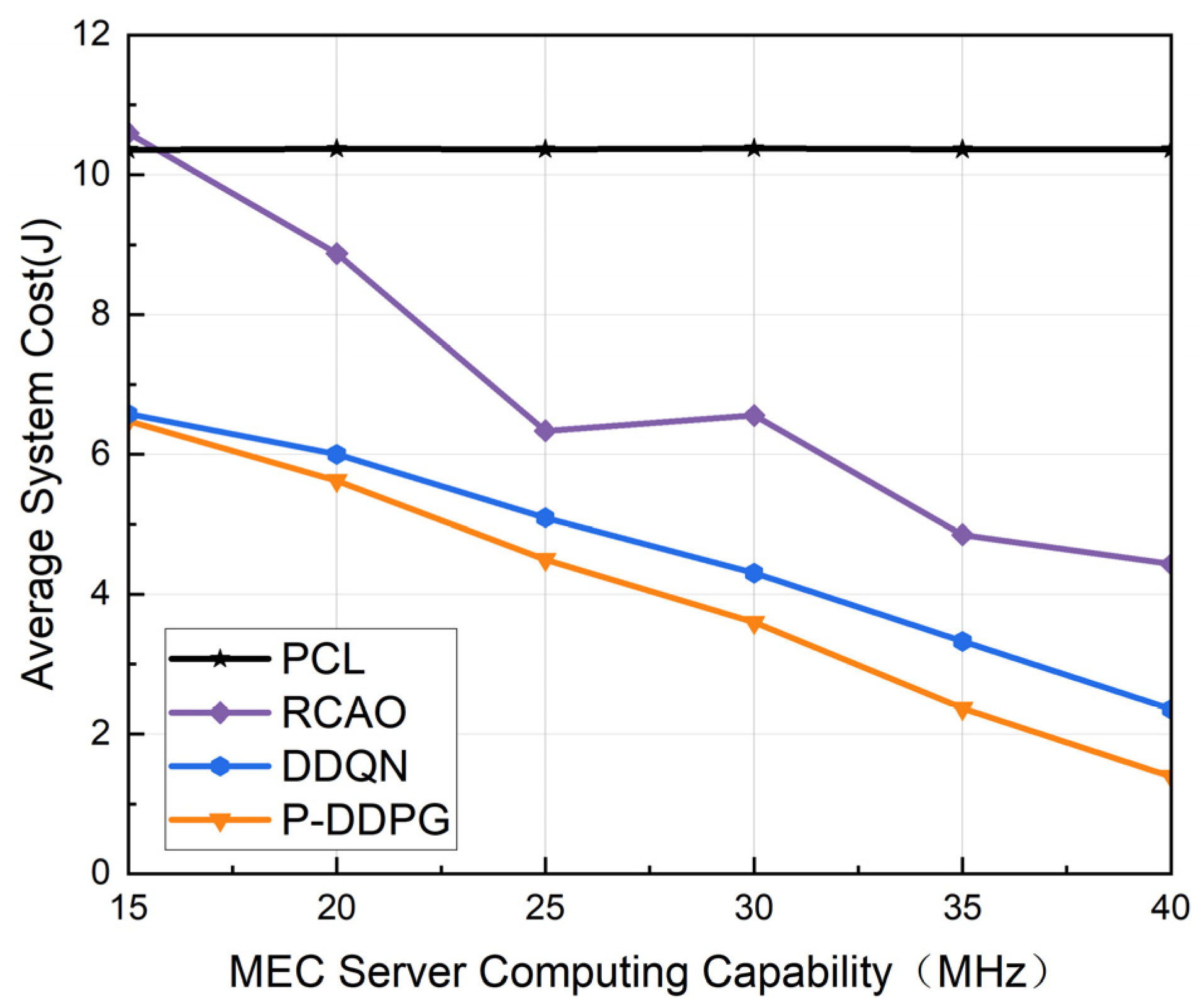
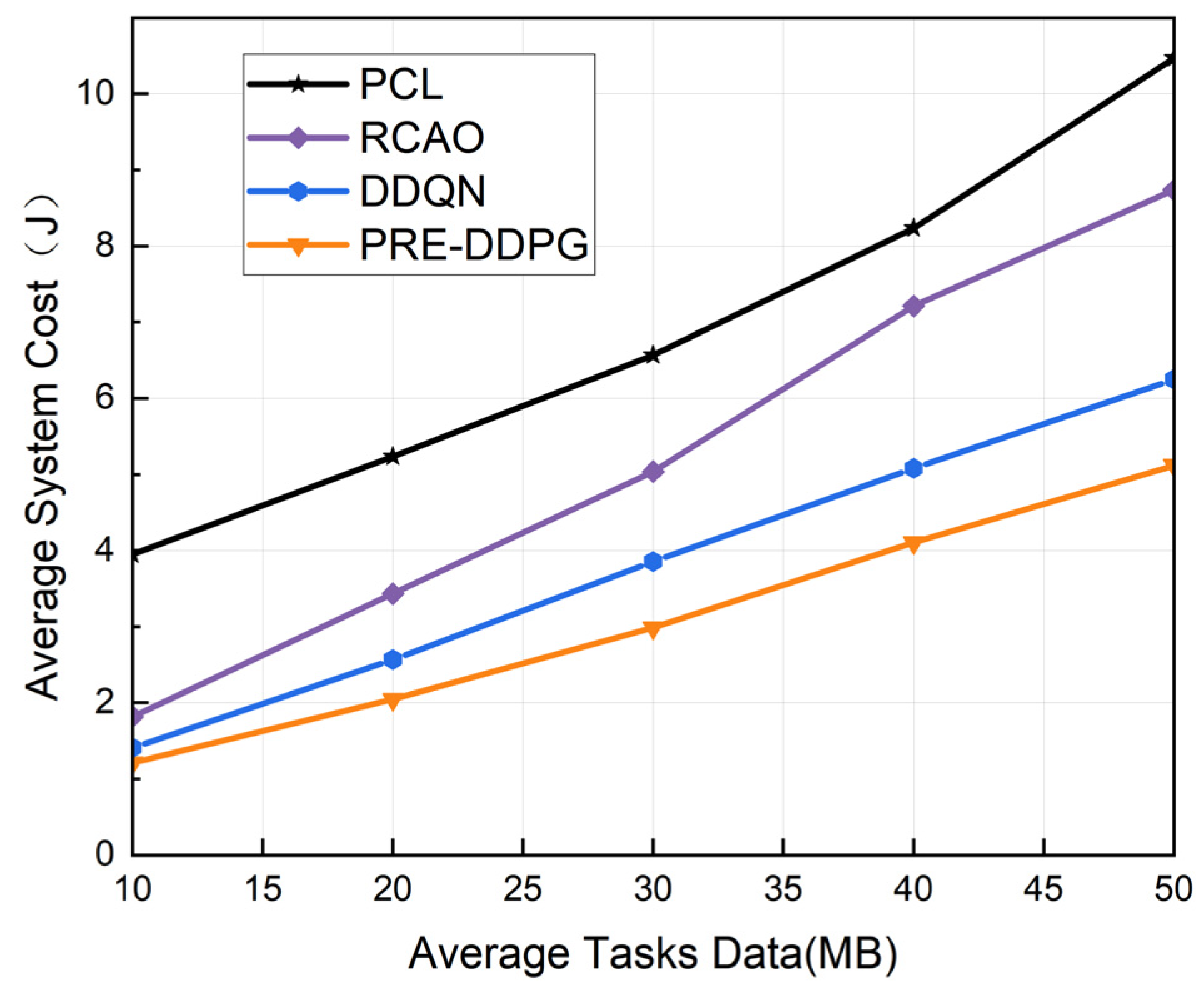
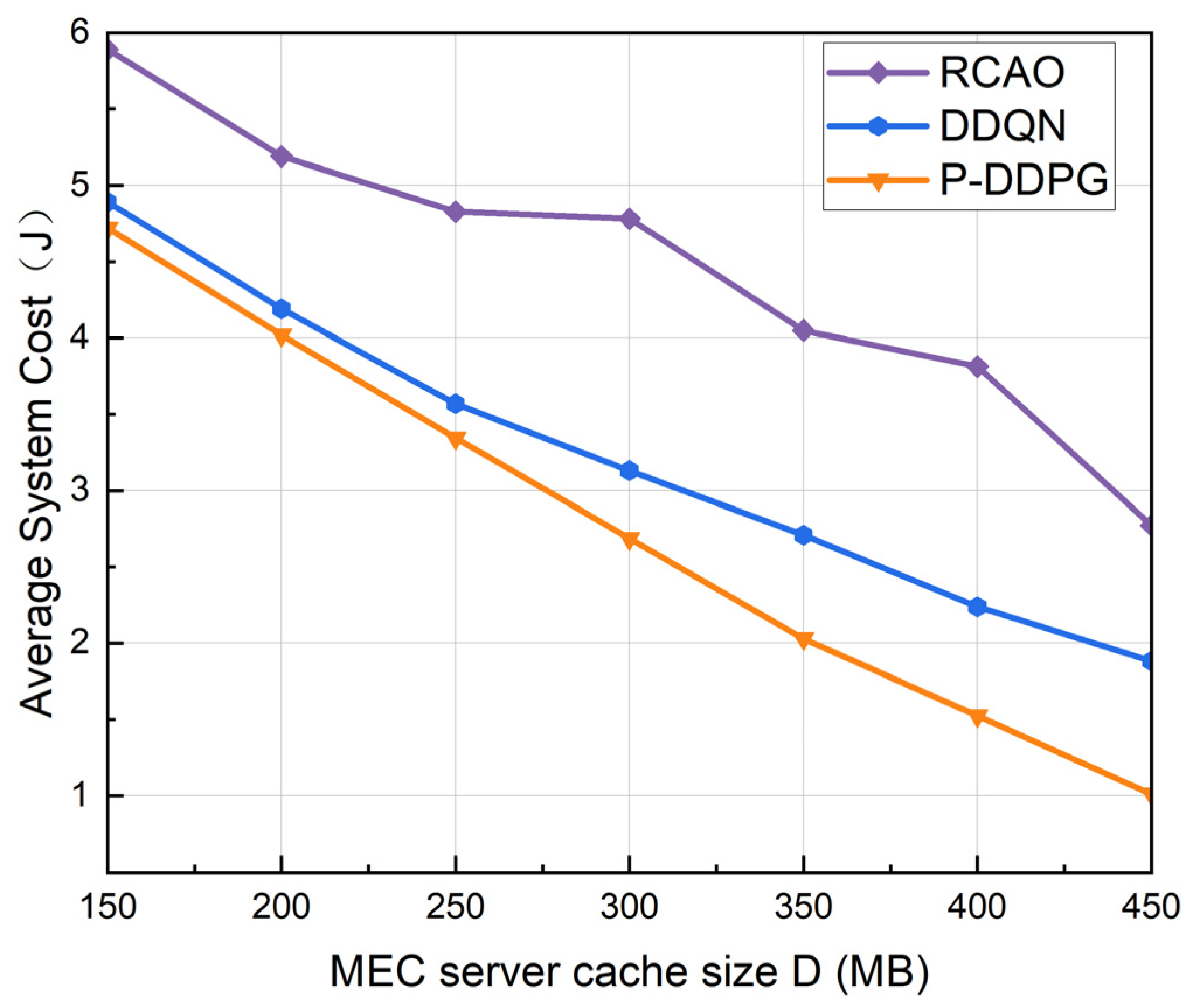
5.2. Experimental Results and Analysis
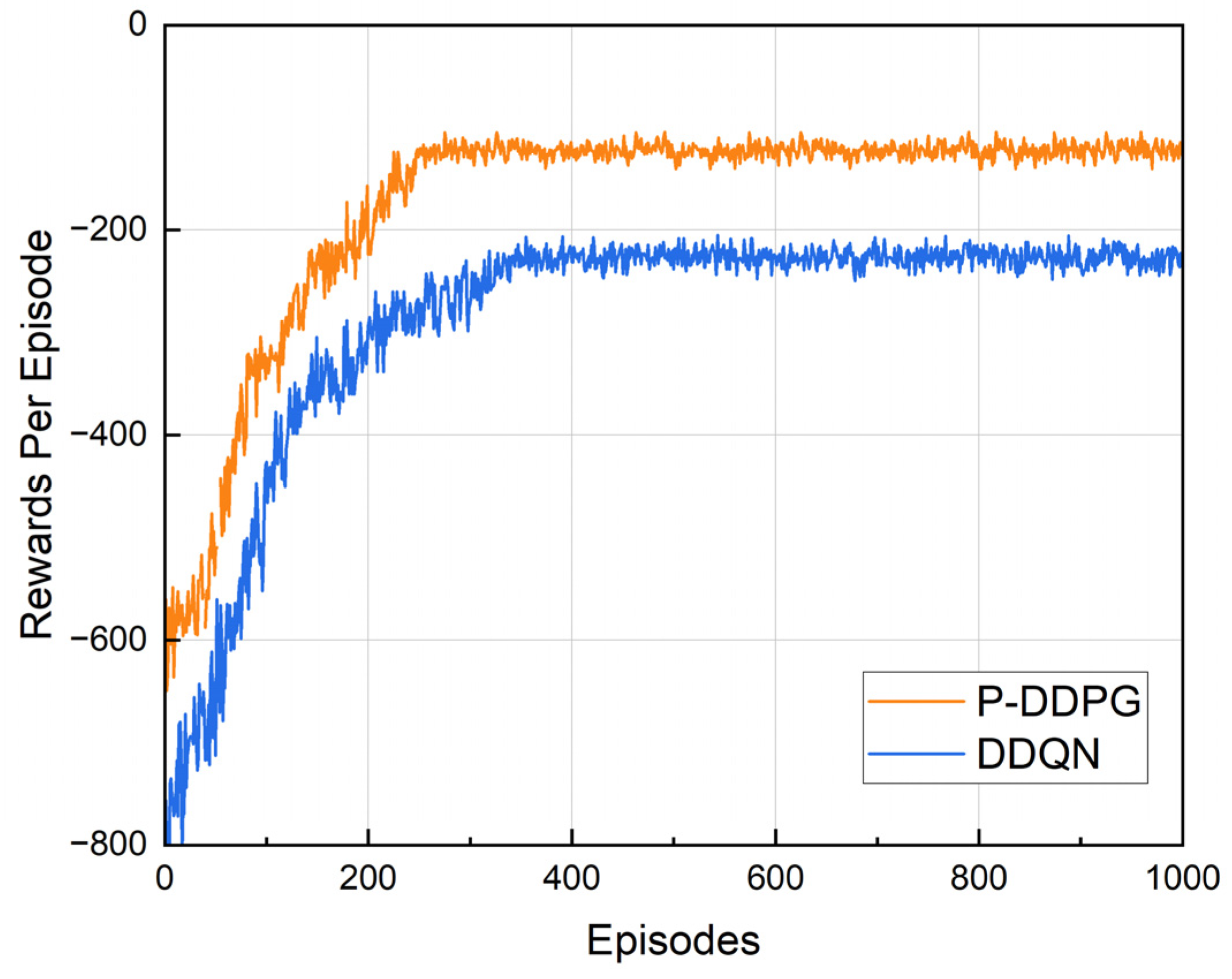
5.2.1. Convergence Performance
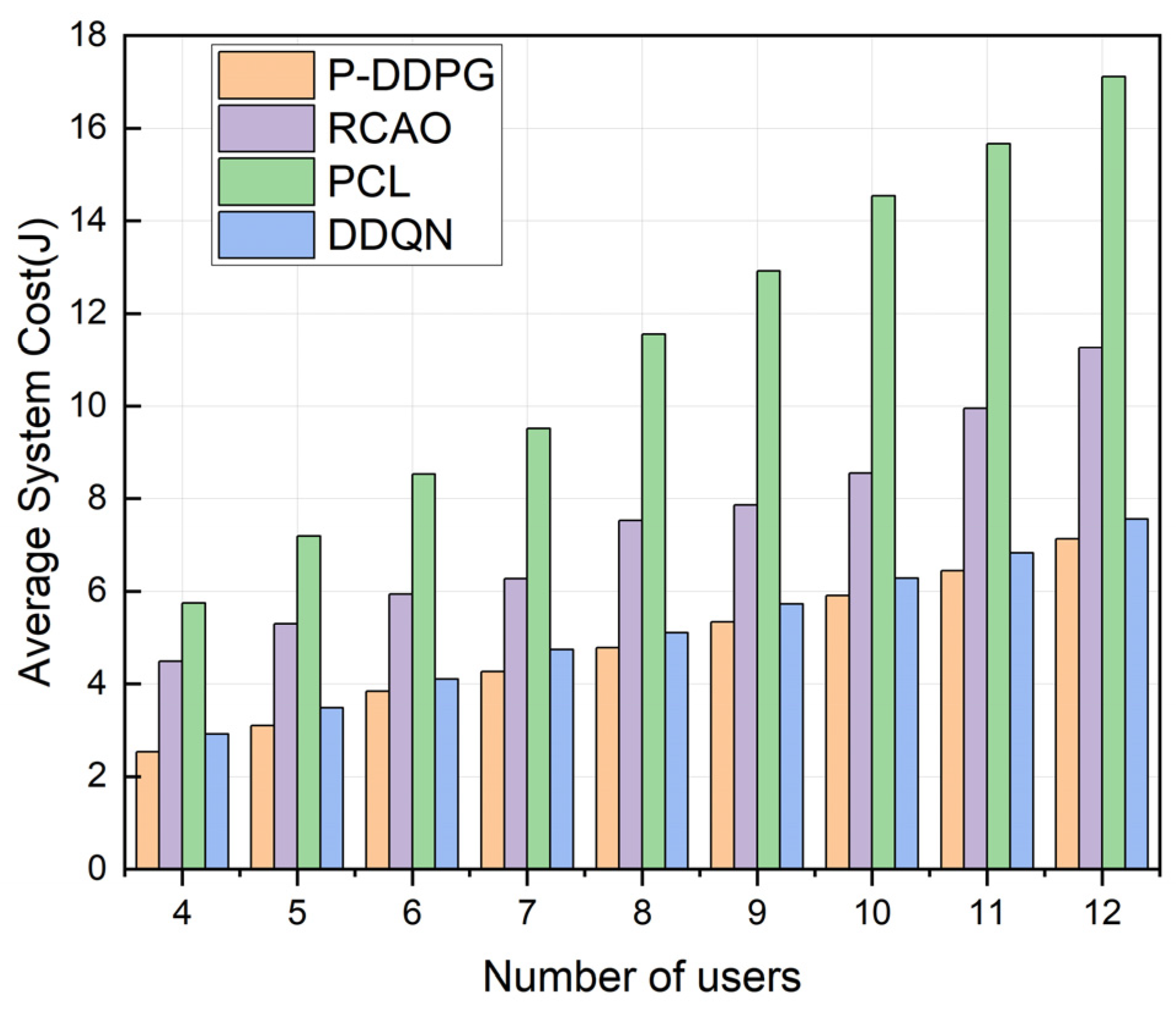
5.2.2. Performance Comparison
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Choi, Y.; Lim, Y. Edge Caching Based on Deep Reinforcement Learning in Vehicular Networks. In Proceedings of the 2022 IEEE 4th Eurasia Conference on IOT, Communication and Engineering (ECICE), Yunlin, Taiwan, 28–30 October 2022; pp. 57–59. [Google Scholar]
- Kiani, A.; Ansari, N. Edge Computing Aware NOMA for 5G Networks. IEEE Internet Things J. 2018, 5, 1299–1306. [Google Scholar] [CrossRef]
- Tran, T.X.; Pompili, D. Joint Task Offloading and Resource Allocation for Multi-Server Mobile-Edge Computing Networks. IEEE Trans. Veh. Technol. 2019, 68, 856–868. [Google Scholar] [CrossRef]
- Bi, S.; Huang, L.; Zhang, Y.J.A. Joint Optimization of Service Caching Placement and Computation Offloading in Mobile Edge Computing Systems. IEEE Trans. Wirel. Commun. 2020, 19, 4947–4963. [Google Scholar] [CrossRef]
- Wu, Z.; Yan, D. Deep reinforcement learning-based computation offloading for 5G vehicle-aware multi-access edge computing network. China Commun. 2021, 18, 26–41. [Google Scholar] [CrossRef]
- Khurshid, T.; Ahmed, W.; Rehan, M.; Ahmad, R.; Alam, M.M.; Radwan, A. A DRL Strategy for Optimal Resource Allocation Along With 3D Trajectory Dynamics in UAV-MEC Network. IEEE Access 2023, 11, 54664–54678. [Google Scholar] [CrossRef]
- Kong, X.; Duan, G.; Hou, M.; Shen, G.; Wang, H.; Yan, X.; Collotta, M. Deep Reinforcement Learning-Based Energy-Efficient Edge Computing for Internet of Vehicles. IEEE Trans. Ind. Inform. 2022, 18, 6308–6316. [Google Scholar] [CrossRef]
- Xu, Z.; Zhou, L.; Dai, H.; Liang, W.; Zhou, W.; Zhou, P.; Xu, W.; Wu, G. Energy-Aware Collaborative Service Caching in a 5G-Enabled MEC With Uncertain Payoffs. IEEE Trans. Commun. 2022, 70, 1058–1071. [Google Scholar] [CrossRef]
- Ren, J.; Yu, G.; He, Y.; Li, G.Y. Collaborative Cloud and Edge Computing for Latency Minimization. IEEE Trans. Veh. Technol. 2019, 68, 5031–5044. [Google Scholar] [CrossRef]
- Dai, H.; Wen, H.; Xing, H.; Ding, Z. Joint Cache Placement and NOMA-Based Task Offloading for Multi-User Mobile Edge Computing. In Proceedings of the 2023 IEEE 97th Vehicular Technology Conference (VTC2023-Spring), Florence, Italy, 20–23 June 2023; pp. 1–7. [Google Scholar]
- Chen, Z.; Zhou, Z.; Chen, C. Code Caching-Assisted Computation Offloading and Resource Allocation for Multi-User Mobile Edge Computing. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4517–4530. [Google Scholar] [CrossRef]
- Feng, H.; Guo, S.; Yang, L.; Yang, Y. Collaborative Data Caching and Computation Offloading for Multi-Service Mobile Edge Computing. IEEE Trans. Veh. Technol. 2021, 70, 9408–9422. [Google Scholar] [CrossRef]
- Tran, T.X.; Pompili, D. Adaptive Bitrate Video Caching and Processing in Mobile-Edge Computing Networks. IEEE Trans. Mob. Comput. 2019, 18, 1965–1978. [Google Scholar] [CrossRef]
- Shi, W.; Zhou, S.; Niu, Z.; Jiang, M.; Geng, L. Multiuser Co-Inference With Batch Processing Capable Edge Server. IEEE Trans. Wirel. Commun. 2023, 22, 286–300. [Google Scholar] [CrossRef]
- Chen, Z.; Yi, W.; Alam, A.S.; Nallanathan, A. Dynamic Task Software Caching-Assisted Computation Offloading for Multi-Access Edge Computing. IEEE Trans. Commun. 2022, 70, 6950–6965. [Google Scholar] [CrossRef]
- Cheng, M.; Li, J.; Nazarian, S. DRL-cloud: Deep reinforcement learning-based resource provisioning and task scheduling for cloud service providers. In Proceedings of the 2018 23rd Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju, Republic of Korea, 22–25 January 2018. [Google Scholar]
- Hazarika, B.; Singh, K.; Biswas, S.; Li, C.P. DRL-Based Resource Allocation for Computation Offloading in IoV Networks. IEEE Trans. Ind. Inform. 2022, 18, 8027–8038. [Google Scholar] [CrossRef]
- Li, S.; Li, B.; Zhao, W. Joint Optimization of Caching and Computation in Multi-Server NOMA-MEC System via Reinforcement Learning. IEEE Access 2020, 8, 112762–112771. [Google Scholar] [CrossRef]
- Zhu, A.; Guo, S.; Ma, M.; Feng, H.; Liu, B.; Su, X.; Guo, M.; Jiang, Q. Computation Offloading for Workflow in Mobile Edge Computing Based on Deep Q-Learning. In Proceedings of the 2019 28th Wireless and Optical Communications Conference (WOCC), Beijing, China, 9–10 May 2019; pp. 1–5. [Google Scholar]
- Liu, T.; Zhang, Y.; Zhu, Y.; Tong, W.; Yang, Y. Online Computation Offloading and Resource Scheduling in Mobile-Edge Computing. IEEE Internet Things J. 2021, 8, 6649–6664. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, G. Joint Service Caching, Resource Allocation and Computation Offloading in Three-Tier Cooperative Mobile Edge Computing System. IEEE Trans. Netw. Sci. Eng. 2023, 10, 3343–3353. [Google Scholar] [CrossRef]
- Tang, H.; Wu, H.; Qu, G.; Li, R. Double Deep Q-Network Based Dynamic Framing Offloading in Vehicular Edge Computing. IEEE Trans. Netw. Sci. Eng. 2023, 10, 1297–1310. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, Z.; Wu, Y.; Dong, M.; Leung, V.C.M. Energy Efficient Joint Computation Offloading and Service Caching for Mobile Edge Computing: A Deep Reinforcement Learning Approach. IEEE Trans. Green Commun. Netw. 2023, 7, 950–961. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, T.; Zhang, Z.; Zhou, H. A Game theory-based Computation Offloading Method in Cloud-Edge Computing Networks. In Proceedings of the 2021 International Conference on Computer Communications and Networks (ICCCN), Athens, Greece, 19–22 July 2021; pp. 1–6. [Google Scholar]
- Wu, Y.; Wang, Y.; Zhou, F.; Hu, R.Q. Computation Efficiency Maximization in OFDMA-Based Mobile Edge Computing Networks. IEEE Commun. Lett. 2020, 24, 159–163. [Google Scholar] [CrossRef]
- Fan, W.; Han, J.; Su, Y.; Liu, X.; Wu, F.; Tang, B.; Liu, Y. Joint Task Offloading and Service Caching for Multi-Access Edge Computing in WiFi-Cellular Heterogeneous Networks. IEEE Trans. Wirel. Commun. 2022, 21, 9653–9667. [Google Scholar] [CrossRef]
- Xue, J.; An, Y. Joint Task Offloading and Resource Allocation for Multi-Task Multi-Server NOMA-MEC Networks. IEEE Access 2021, 9, 16152–16163. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Nath, S.; Wu, J. Deep reinforcement learning for dynamic computation offloading and resource allocation in cache-assisted mobile edge computing systems. Intell. Converg. Netw. 2020, 1, 181–198. [Google Scholar] [CrossRef]
- Qiu, C.; Hu, Y.; Chen, Y.; Zeng, B. Deep Deterministic Policy Gradient (DDPG)-Based Energy Harvesting Wireless Communications. IEEE Internet Things J. 2019, 6, 8577–8588. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhouand, H.; Zhao, L.; Leung, V.C.M. Digital Twin Assisted Computation Offloading and Service Caching in Mobile Edge Computing. In Proceedings of the 2022 IEEE 42nd International Conference on Distributed Computing Systems (ICDCS), Bologna, Italy, 10–13 July 2022; pp. 1296–1297. [Google Scholar]
- Zhou, H.; Wang, Z.; Zheng, H.; He, S.; Dong, M. Cost Minimization-Oriented Computation Offloading and Service Caching in Mobile Cloud-Edge Computing: An A3C-Based Approach. IEEE Trans. Netw. Sci. Eng. 2023, 10, 1326–1338. [Google Scholar] [CrossRef]
- Wen, W.; Cui, Y.; Quek, T.Q.S.; Zheng, F.C.; Jin, S. Joint Optimal Software Caching, Computation Offloading and Communications Resource Allocation for Mobile Edge Computing. IEEE Trans. Veh. Technol. 2020, 69, 7879–7894. [Google Scholar] [CrossRef]
- Niu, J.; Zhang, S.; Chi, K.; Shen, G.; Gao, W. Deep learning for online computation offloading and resource allocation in NOMA. Comput. Netw. 2022, 216, 109238. [Google Scholar] [CrossRef]
- He, X.; Lu, H.; Du, M.; Mao, Y.; Wang, K. QoE-Based Task Offloading With Deep Reinforcement Learning in Edge-Enabled Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2252–2261. [Google Scholar] [CrossRef]
- Xue, Z.; Liu, C.; Liao, C.; Han, G.; Sheng, Z. Joint Service Caching and Computation Offloading Scheme Based on Deep Reinforcement Learning in Vehicular Edge Computing Systems. IEEE Trans. Veh. Technol. 2023, 72, 6709–6722. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| Number of users. | |
| Number of tasks. | |
| Upstream transmission rate of users. | |
| Transmission power of users. | |
| Total data upstream rate. | |
| Wireless transmission bandwidth. | |
| The number of CPU cycles per user time. | |
| The amount of data downloaded by tasks for offloading. | |
| CPU cycles needed for task execution. | |
| Task deadline. | |
| Task offloading decision. | |
| Caching decision of tasks. | |
| Total computing resources of MEC. | |
| Cache size of MEC. | |
| Background noise power. | |
| Energy coefficient of mobile devices. | |
| Channel gain. | |
| Weight of energy consumption. | |
| Weight of time consumption. | |
| Execution time of tasks offloaded locally. | |
| Execution time of tasks offloaded to MEC. | |
| Energy consumption of tasks offloaded locally. | |
| Energy consumption of tasks executed on MEC. | |
| Total energy consumption for task completion. | |
| Total delay for task completion. | |
| Total computing cost for task completion. |
| Parameter | Value |
|---|---|
| 5 | |
| 3 | |
| {0.8, 0.9, …, 1.5} GHz | |
| Cycles/bit | |
| (0,40) MB | |
| 30 GHz | |
| 20 MHz | |
| 200 m | |
| 100 mW | |
| −100 dBm | |
| 128 | |
| 0.0001 | |
| 0.001 | |
| 0.99 | |
| 0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, X.; Jia, Z.; Pang, X.; Zhao, S. Joint Optimization of Task Caching and Computation Offloading for Multiuser Multitasking in Mobile Edge Computing. Electronics 2024, 13, 389. https://doi.org/10.3390/electronics13020389
Zhu X, Jia Z, Pang X, Zhao S. Joint Optimization of Task Caching and Computation Offloading for Multiuser Multitasking in Mobile Edge Computing. Electronics. 2024; 13(2):389. https://doi.org/10.3390/electronics13020389
Chicago/Turabian StyleZhu, Xintong, Zongpu Jia, Xiaoyan Pang, and Shan Zhao. 2024. "Joint Optimization of Task Caching and Computation Offloading for Multiuser Multitasking in Mobile Edge Computing" Electronics 13, no. 2: 389. https://doi.org/10.3390/electronics13020389