
A Tracking-Based Two-Stage Framework for Spatio-Temporal Action Detection

 ,
,
Abstract
:1. Introduction
- We propose a tracking-based two-stage spatio-temporal action detection framework aimed at achieving better action detection.
- We extend action localization to action tracking by utilizing a simple and robust tracker and propose a track-aware feature aggregation module with an algorithm.
- Experiments on AVA demonstrate that the performance of TrAD excels compared to localization-based state of the art while reducing overall computation significantly.
2. Related Work
2.1. Spatio-Temporal Action Detection
2.2. Object Detection
2.3. Multi-Object Tracking
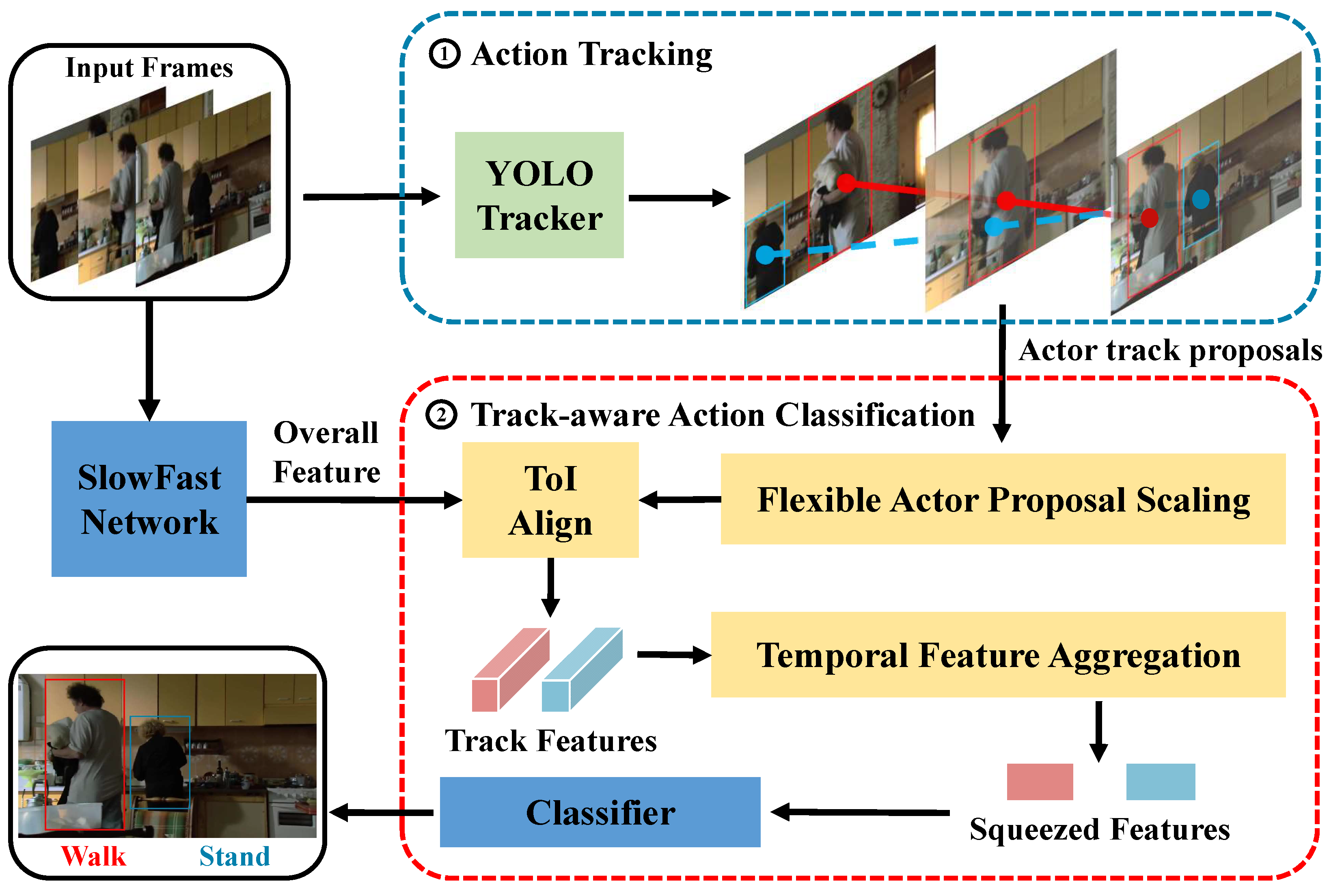
3. Methods
3.1. Overview
3.2. Action Tracking
3.3. Track-Aware Action Classification
| Algorithm 1 Flexible Actor Proposal Scaling (FAPS) |
|
4. Results
- RQ1. Compared to two-stage methods, does our method achieve better detection with less computation?
- RQ2. Does tracking improve spatio-temporal action detection?
- RQ3. Does the FAPS algorithm affect the spatio-temporal action detection?
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Metrics
4.1.3. Implementation Details
4.2. Comparisons with State-of-the-Art Methods
4.3. Impact of the Action Tracking
4.4. Impact of Different Proposal Strategies
4.5. Qualitative Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Notation | Meaning |
| V | Video sequence |
| The YOLO object detector | |
| Actor tracks sets | |
| Actor proposals | |
| Thresholds for track diverting | |
| Bounding box ratio clusters | |
| Center values of the bounding box ratio clusters | |
| Boundary points | |
| Bounding box ratio | |
| T | Temporal length of a video clip |
| H | Height of a feature map |
| W | Width of a feature map |
References
- Gkioxari, G.; Malik, J. Finding action tubes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 759–768. [Google Scholar] [CrossRef]
- Li, Y.; Chen, L.; He, R.; Wang, Z.; Wu, G.; Wang, L. MultiSports: A Multi-Person Video Dataset of Spatio-Temporally Localized Sports Actions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; IEEE: Washington, DC, USA, 2021; pp. 13516–13525. [Google Scholar] [CrossRef]
- Dave, I.R.; Scheffer, Z.; Kumar, A.; Shiraz, S.; Rawat, Y.S.; Shah, M. GabriellaV2: Towards better generalization in surveillance videos for Action Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops, WACV—Workshops, Waikoloa, HI, USA, 4–8 January 2022; IEEE: Washington, DC, USA, 2022; pp. 122–132. [Google Scholar] [CrossRef]
- Sun, B.; Wu, Y.; Zhao, K.; He, J.; Yu, L.; Yan, H.; Luo, A. Student Class Behavior Dataset: A video dataset for recognizing, detecting, and captioning students’ behaviors in classroom scenes. Neural Comput. Appl. 2021, 33, 8335–8354. [Google Scholar] [CrossRef]
- Girshick, R.B. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Washington, DC, USA, 2019; pp. 6201–6210. [Google Scholar] [CrossRef]
- Girdhar, R.; Carreira, J.; Doersch, C.; Zisserman, A. A Better Baseline for AVA. CoRR 2018, abs/1807.10066. Available online: http://xxx.lanl.gov/abs/1807.10066 (accessed on 30 March 2022).
- Bertasius, G.; Wang, H.; Torresani, L. Is Space-Time Attention All You Need for Video Understanding? In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, 18–24 July 2021; Volume 139, pp. 813–824. [Google Scholar]
- Li, Y.; Wu, C.Y.; Fan, H.; Mangalam, K.; Xiong, B.; Malik, J.; Feichtenhofer, C. MViTv2: Improved multiscale vision transformers for classification and detection. In Proceedings of the CVPR, New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Li, K.; Wang, Y.; Peng, G.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. UniFormer: Unified Transformer for Efficient Spatial-Temporal Representation Learning. In Proceedings of the International Conference on Learning Representations, virtual, 25–29 April 2022. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. CoRR 2012, abs/1212.0402. Available online: http://xxx.lanl.gov/abs/1212.0402 (accessed on 12 April 2022).
- Gu, C.; Sun, C.; Ross, D.A.; Vondrick, C.; Pantofaru, C.; Li, Y.; Vijayanarasimhan, S.; Toderici, G.; Ricco, S.; Sukthankar, R.; et al. AVA: A Video Dataset of Spatio-Temporally Localized Atomic Visual Actions. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; Computer Vision Foundation/IEEE Computer Society: Washington, DC, USA, 2018; pp. 6047–6056. [Google Scholar] [CrossRef]
- Jhuang, H.; Gall, J.; Zuffi, S.; Schmid, C.; Black, M.J. Towards understanding action recognition. In Proceedings of the International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 3192–3199. [Google Scholar]
- Pan, J.; Chen, S.; Shou, M.Z.; Liu, Y.; Shao, J.; Li, H. Actor-context-actor relation network for spatio-temporal action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 464–474. [Google Scholar]
- Sun, C.; Shrivastava, A.; Vondrick, C.; Murphy, K.; Sukthankar, R.; Schmid, C. Actor-Centric Relation Network. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part XI; Lecture Notes in Computer Science. Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11215, pp. 335–351. [Google Scholar] [CrossRef]
- Tang, J.; Xia, J.; Mu, X.; Pang, B.; Lu, C. Asynchronous interaction aggregation for action detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 71–87. [Google Scholar]
- Zhang, Y.; Tokmakov, P.; Hebert, M.; Schmid, C. A structured model for action detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9975–9984. [Google Scholar]
- Wu, C.Y.; Feichtenhofer, C.; Fan, H.; He, K.; Krahenbuhl, P.; Girshick, R. Long-term feature banks for detailed video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 284–293. [Google Scholar]
- Köpüklü, O.; Wei, X.; Rigoll, G. You only watch once: A unified cnn architecture for real-time spatiotemporal action localization. arXiv 2019, arXiv:1911.06644. [Google Scholar]
- Chen, S.; Sun, P.; Xie, E.; Ge, C.; Wu, J.; Ma, L.; Shen, J.; Luo, P. Watch Only Once: An End-to-End Video Action Detection Framework. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; IEEE: Washington, DC, USA, 2021; pp. 8158–8167. [Google Scholar] [CrossRef]
- Sui, L.; Zhang, C.; Gu, L.; Han, F. A Simple and Efficient Pipeline to Build an End-to-End Spatial-Temporal Action Detector. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2023, Waikoloa, HI, USA, 2–7 January 2023; IEEE: Washington, DC, USA, 2023; pp. 5988–5997. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.N.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection With Learnable Proposals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; Computer Vision Foundation/IEEE: Washington, DC, USA, 2021; pp. 14454–14463. [Google Scholar] [CrossRef]
- Wang, C.; Bochkovskiy, A.; Liao, H.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. CoRR 2022, abs/2207.02696. Available online: http://xxx.lanl.gov/abs/2207.02696 (accessed on 8 May 2022).
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision-ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I; Lecture Notes in Computer Science. Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12346, pp. 213–229. [Google Scholar] [CrossRef]
- Marvasti-Zadeh, S.M.; Cheng, L.; Ghanei-Yakhdan, H.; Kasaei, S. Deep Learning for Visual Tracking: A Comprehensive Survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 3943–3968. [Google Scholar] [CrossRef]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Washington, DC, USA, 2017; pp. 3645–3649. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXII. Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–21. [Google Scholar]
- Wu, J.; Kuang, Z.; Wang, L.; Zhang, W.; Wu, G. Context-Aware RCNN: A Baseline for Action Detection in Videos. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXV; Lecture Notes in Computer Science. Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12370, pp. 440–456. [Google Scholar] [CrossRef]
- Singh, G.; Choutas, V.; Saha, S.; Yu, F.; Gool, L.V. Spatio-Temporal Action Detection Under Large Motion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2023, Waikoloa, HI, USA, 2–7 January 2023; IEEE: Washington, DC, USA, 2023; pp. 5998–6007. [Google Scholar] [CrossRef]
- Chen, C.; Han, D.; Shen, X. CLVIN: Complete language-vision interaction network for visual question answering. Knowl.-Based Syst. 2023, 275, 110706. [Google Scholar] [CrossRef]
- Chen, C.; Han, D.; Chang, C.C. MPCCT: Multimodal vision-language learning paradigm with context-based compact Transformer. Pattern Recognit. 2024, 147, 110084. [Google Scholar] [CrossRef]
- Han, D.; Zhou, H.; Weng, T.H.; Wu, Z.; Han, B.; Li, K.C.; Pathan, A.S.K. LMCA: A lightweight anomaly network traffic detection model integrating adjusted mobilenet and coordinate attention mechanism for IoT. Telecommun. Syst. 2023, 84, 549–564. [Google Scholar] [CrossRef]
- Shi, S.; Han, D.; Cui, M. A multimodal hybrid parallel network intrusion detection model. Connect. Sci. 2023, 35, 2227780. [Google Scholar] [CrossRef]
- Wang, H.; Han, D.; Cui, M.; Chen, C. NAS-YOLOX: A SAR ship detection using neural architecture search and multi-scale attention. Connect. Sci. 2023, 35, 1–32. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.B.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 5987–5995. [Google Scholar] [CrossRef]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Kuhn, H.W. The Hungarian Method for the Assignment Problem. In 50 Years of Integer Programming 1958–2008—From the Early Years to the State-of-the-Art; Jünger, M., Liebling, T.M., Naddef, D., Nemhauser, G.L., Pulleyblank, W.R., Reinelt, G., Rinaldi, G., Wolsey, L.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 29–47. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. Conference Track Proceedings. [Google Scholar]
- Weinzaepfel, P.; Harchaoui, Z.; Schmid, C. Learning to Track for Spatio-Temporal Action Localization. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 3164–3172. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | T | mAP | GFLOPs |
|---|---|---|---|---|
| AVA Baseline [14] | I3D-VGG | 14.5 | N/A | |
| ACRN [17] | S3D-G | - | 17.4 | 81.4 + 406.5 |
| LFB [20] | R50-I3D-NL | 25.8 | N/A | |
| CA-RCNN [32] | SFR50-NL | 28.0 | N/A | |
| SlowOnly [8] | R50 | 19.7 | 42.8 + 406.5 | |
| SlowFast [8] | R50 | 25.2 | 97.5 + 406.5 | |
| ACAR [16] | SFR101 | 30.0 | 137.5 + 406.5 | |
| TrAD | SFR50 | 29.7 | 99.7 + 109.7 | |
| TrAD w.o. TAC | SFR50 | 28.1 | 97.5 + 109.7 | |
| SlowOnly [8] | R101 | 24.8 | 117.1 + 406.5 | |
| SlowFast [8] | R101 | 29.3 | 147.3 + 406.5 | |
| YOWO [21] | SFR50 | 17.1 | 139.3 | |
| WOO [22] | SFR50 | 25.2 | 141.6 |
| Method | mAP | GFLOPs |
|---|---|---|
| SlowFast | 25.2 | 97.5 + 406.5 |
| SlowFast w. DeepSort | 27.3 | 97.5 + 90.7 |
| SlowFast w. Bytetrack | 28.7 | 97.5 + 109.7 |
| TrAD | 29.7 | 99.5 + 109.7 |
| TrAD w.o. AT | 26.3 | 99.5 + 106.4 |
| Method | FAPS | mAP | ||
|---|---|---|---|---|
| SlowOnly | ✓ | Fixed | Fixed | 20.4 |
| ✗ | - | - | 19.7 | |
| TrAD | ✓ | Fixed | Fixed | 29.7 |
| ✓ | Random | Random | 27.1 | |
| ✗ | - | - | 28.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, J.; Yang, Y.; Liu, R.; Chen, L.; Fei, H.; Hu, C.; Shi, R.; Zou, Y. A Tracking-Based Two-Stage Framework for Spatio-Temporal Action Detection. Electronics 2024, 13, 479. https://doi.org/10.3390/electronics13030479
Luo J, Yang Y, Liu R, Chen L, Fei H, Hu C, Shi R, Zou Y. A Tracking-Based Two-Stage Framework for Spatio-Temporal Action Detection. Electronics. 2024; 13(3):479. https://doi.org/10.3390/electronics13030479
Chicago/Turabian StyleLuo, Jing, Yulin Yang, Rongkai Liu, Li Chen, Hongxiao Fei, Chao Hu, Ronghua Shi, and You Zou. 2024. "A Tracking-Based Two-Stage Framework for Spatio-Temporal Action Detection" Electronics 13, no. 3: 479. https://doi.org/10.3390/electronics13030479