1. Introduction
Genetic factors have important biological functions and are closely related to diseases. Identifying the biological functions of genetic factors is useful in analyzing the complex mechanisms of diseases and helpful in disease prevention, diagnosis, and treatment. piRNAs are a kind of small non-coding RNA (sncRNA) discovered in 2006 that bind to the PIWI subfamily of the Argonaute protein. They are slightly longer than miRNAs by approximately 24–32 nucleotides. They lack clear secondary structures but have two sequence preferences (the 5′ end uridine or 10th adenosine) [
1,
2].
Based on their origins, piRNAs are divided into three categories: piRNAs derived from inter-gene regions, piRNAs derived from mRNA, and piRNAs derived from lncRNA. Given their different origins, piRNAs have a variety of functions. Early studies found that piRNAs can recognize and silence transposons, thereby maintaining the stability of the genome structure [
3]. As early as 2014, Gou et al. [
4] found that piRNAs guided the large-scale elimination of mRNAs at the later stage of spermatogenesis in mice; that was the first research to demonstrate that piRNAs regulate mRNAs. In 2015, Watanabe et al. [
5] discovered that piRNAs from transposons and pseudogenes mediate the degradation of large amounts of mRNA and lncRNA in mice. In 2019, Dai et al. [
6] revealed that piRNAs are widely involved in mRNA translational activation in sperm cells and conducted in-depth and systematic research on the molecular mechanisms of positive piRNA regulation in target gene translation. Recent research on a
C. elegans model showed that the regulatory range of piRNAs involves almost all mRNAs in germ cells [
7]. In summary, these breakthrough studies suggest that piRNA functions are important and diverse and that they mediate a highly complex RNA regulatory network.
Identifying piRNA functions is a fundamental and challenging problem. There are currently two existing recognition methods: biological experimental methods and computational methods. Many biological experimental techniques can be used to recognize piRNA functions, such as immunoprecipitation. However, experiments identifying piRNA functions are time-consuming, expensive, have only a minor flux, and require professional operators. With the establishment of piRNA-specific databases and the accumulation of piRNA-related functional data, it is possible to predict piRNA functional labels via computational methods [
8].
Much research has been conducted in identifying the functional labels of miRNAs and lncRNAs, but prediction algorithm research on piRNA functional labels is still in its infancy. The current study focuses on mRNA-related piRNA using a miRNA-like mechanism [
4,
9,
10], and lncRNA-related piRNA is disregarded. In 2017, Liu et al. [
11] proposed 2L-piRNA, the first piRNA function predictor. By extracting features such as pseudo-nucleotide components (PseKNC) and using SVM classifiers, the authors built a two-layer ensemble classifier. The first layer is used to identify whether a query RNA molecule is piRNA or non-piRNA with 86.1% accuracy. The second layer identifies whether a piRNA is involved in mRNA deadenylation with 77.6% accuracy. In 2018, Li et al. [
12] presented a 2L-piRNAPred algorithm based on features including nucleotide composition, positional specificity, physicochemical properties, and an F-value feature selection algorithm, achieving accuracies of 89% (first layer) and 84% (second layer). In 2019, Khan et al. proposed the first computational tool based on deep learning, 2L-piRNADNN [
13]. This method constructs a deep neural network based on feature vectors containing dinucleotide autocovariance and physicochemical properties, with accuracies of 91.81% (first layer) and 84.52% (second layer). In 2020, Zuo et al. [
14] proposed 2lpiRNAred using a sparse representation classifier (SRC) and a support vector machine with a radial basis function using Markov distance (SVMMDRBF). This study also proposed a new feature selection algorithm based on Luca fuzzy entropy and Gaussian membership function (LFE-GM), with accuracies of 88.72% (first layer) and 79.97% (second layer). Meanwhile, Khan et al. [
15] proposed a 2L-PseKNC algorithm based on PseKNC and deep neural networks. This algorithm uses principal component analysis (PCA) to select features and can achieve accuracies of 94.73% (first layer) and 85.21% (second layer). In summary, such studies only focus on mRNA-related piRNA recognition and their performance still needs to be improved.
In addition to the above studies, only a few prediction tools for piRNA target loci are available. Gou et al. [
4] were the first to identify the potential targeting sites of piRNAs within the three prime untranslated regions (3′ UTRs) of MIWI-associated mRNAs. In that study, miRanda [
16], a miRNA target prediction tool, was used. Based on the experimental data of Gou et al. [
17], pirnaPre was the first tool designed for piRNA target locus identification. It used mouse data and selected a combination of MIWI CLIP-seq-derived features and position-derived features to train an SVM classifier. A training area under the curve (AUC) of 0.87 was achieved, and 3781 mRNAs from 2587 protein-coding genes were predicted as potential piRNA targets. pirScan [
18,
19] is another tool for predicting piRNA target sites based on established targeting rules from
C. elegans and
C. briggsae data. Yang et al. [
20] developed the first deep learning method based on multi-head attention, identifying piRNA targeting sites on
C. elegans mRNAs and obtaining an AUC of 93.3% using an independent test set. However, these methods used experimentally validated data from specific species and cannot currently be extended to other organisms.
Recent studies have demonstrated that a piRNA can perform different functions in different times and spaces and can have multiple functional labels. For example, a piRNA can not only eliminate transposons during the ping-pong cycle but also mediate mRNA degradation in late cell stages [
21]. Thus, there is a need for a careful investigation and dissection of piRNA functions. In this study, we propose a novel method, MLPPF, designed for multi-label predictions of piRNA functions based on pretrained k-mer embedding, positional embedding, and an improved TextRNN model. First, a benchmark dataset was constructed by processing piRNA-function-annotated data and sequence data. Moreover, pretrained k-mer and positional embedding were applied to achieve biologically significant sequence representation. Finally, an end-to-end model that couples the discriminative power of representation with an improved textRNN was used to implement the piRNA functional label prediction task. Compared with the other three methods, MLPPF performed best and revealed the key factors of piRNA subsequences, thus demonstrating its effectiveness.
2. Materials and Methods
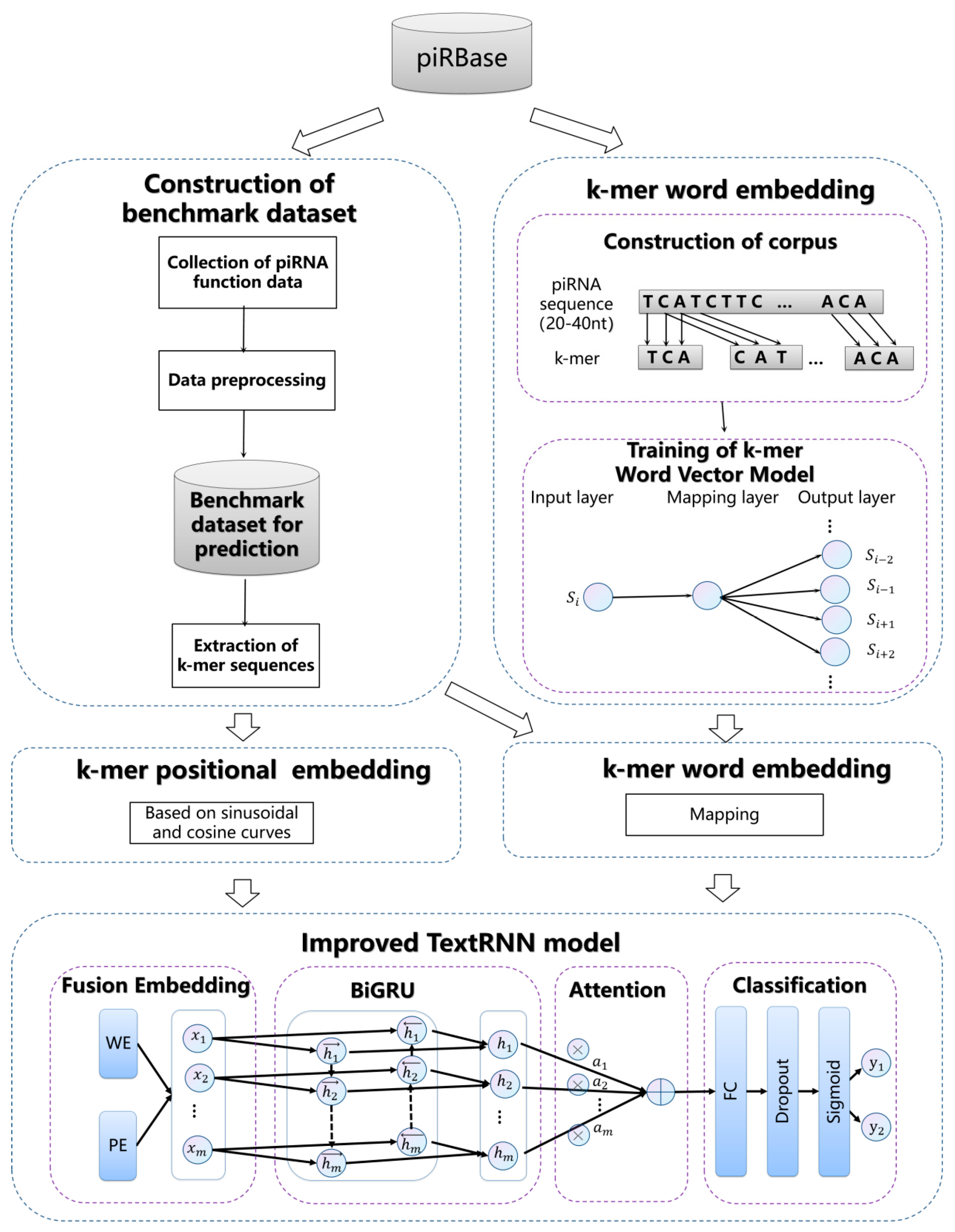
To identify the functional labels of piRNAs, our study builds a benchmark dataset, encodes a piRNA sequence with pretrained k-mer and positional embedding; and treats the piRNA function identification problem as an imbalanced multi-label learning issue by using an improved TextRNN model. The prediction process scheme is shown in
Figure 1 and is divided into 4 main steps. They are benchmark dataset construction, piRNA sequence encoding, TextRNN model construction, and performance evaluation, which are explained in detail below.
2.1. Datasets
According to the NONCODE and piRBase databases, Liu et al. [
11] constructed the first and most popular benchmark dataset for identifying mouse piRNA functional subsets in 2017, containing 1418 non-piRNA sequences; 709 piRNAs with the function of instructing target mRNA deadenylation; and 709 piRNAs without such a function. In 2020, they improved the dataset by increasing the contents of the three subsets to 798, 1257, and 2068, respectively. Although fruit fly species were added to this improved dataset, most studies still focus on mRNA-related piRNAs and ignore lncRNA-related piRNAs.
In our study, mRNA-related and lncRNA-related piRNAs were considered. The piRNA target data were downloaded in 2022 from piRBase (
http://bigdata.ibp.ac.cn/piRBase, accessed on 20 January 2022) and extracted from the published literature [
22]. After eliminating redundant data, 2628 non-duplicate piRNA sequences were obtained. In a piRNA target record, piRBase provides a piRBase name linked to detailed information concerning the piRNA, a target gene/transcript ID, a target site, and other relevant information. According to the interaction characteristics of piRNAs, piRNA sequences are marked with functional tags. We focused on two types of functional labels: mRNA-related piRNAs and lncRNA-related piRNAs. The functional labels for specific piRNAs are based on predicted and experimentally validated information about piRNA target sites. piRNA target mRNAs in mouse tissues were extracted from the published literature and used to experimentally verify piRNA target relationships. The prediction of potential piRNA target lncRNAs was performed the same way as piRNA target mRNA cleavage in mouse testes is predicted [
4,
9,
10].If the piRNA only targets an mRNA, the functional label of the piRNA is marked as [1, 0]. If the piRNA only targets a lncRNA, the functional label of the piRNA is marked as [0, 1]. If both piRNA-mRNA and piRNA-lncRNA interactions exist, the functional label of the piRNA is marked as [1, 1]. In the benchmark dataset, the distribution of functional piRNAs reveals that 1806 piRNAs are only related to mRNA, accounting for 68.7%. Additionally, 538 piRNAs are only related to lncRNA, accounting for 20.5%. Furthermore, 284 piRNAs are related to both mRNA and lncRNA, accounting for 10.8%.
2.2. Sequence Embedding
In our study, a fusion of k-mer word embedding and positional embedding was used to obtain a piRNA sequence representation with biological significance, resulting in high accuracy and reliability in the prediction.
2.2.1. k-mer Word Embedding
RNA sequences need to be encoded into a numeric vector before machine learning can take place. Most biological sequence analysis methods use one-hot encoding for their k-mer fragments. While such encoding is popular, it results in high sparsity and does not consider the biological significance of ribonucleic acids. It hardly reflects sequence similarities and differences.
Inspired by studies on natural language processing (NLP), we analogized a piRNA sequence to a sentence and its k-mer subsequence to a word. By using a word-embedding model, representations of piRNA sequences with biological significance were obtained.
Referenced to Zeng et al. [
23], a piRNA sequence, S, can be denoted as
where
is the
-th nucleotide,
, and
is the length of the piRNA sequence. The piRNA sequence is stored in a cDNA (complementary DNA) format.
We used a sliding window to extract
k-mer sequence fragments from a piRNA sequence
, as follows:
where
is the
-th k-mer subsequence,
is the width of the sliding window, and
is the number of k-mer subsequences in the piRNA sequence,
.
Word2vec [
24] is a word-embedding technique designed to represent standard words in a corpus as vectors with word semantics. This technique has improved multiple natural language processing tasks. The Skip-gram model is a useful example of a Word2vec model; it is used to obtain the embedding vectors of k-mers. piRNA sequences in the piRBase database serve as a corpus, and their k-mer sequence fragments, extracted by the sliding window, are used to pretrain vectors with biological meanings in an unsupervised manner. To maximize the probability of the target k-mer and the co-occurrence of the context sequence, the word vector
of the k-mer sequence fragment
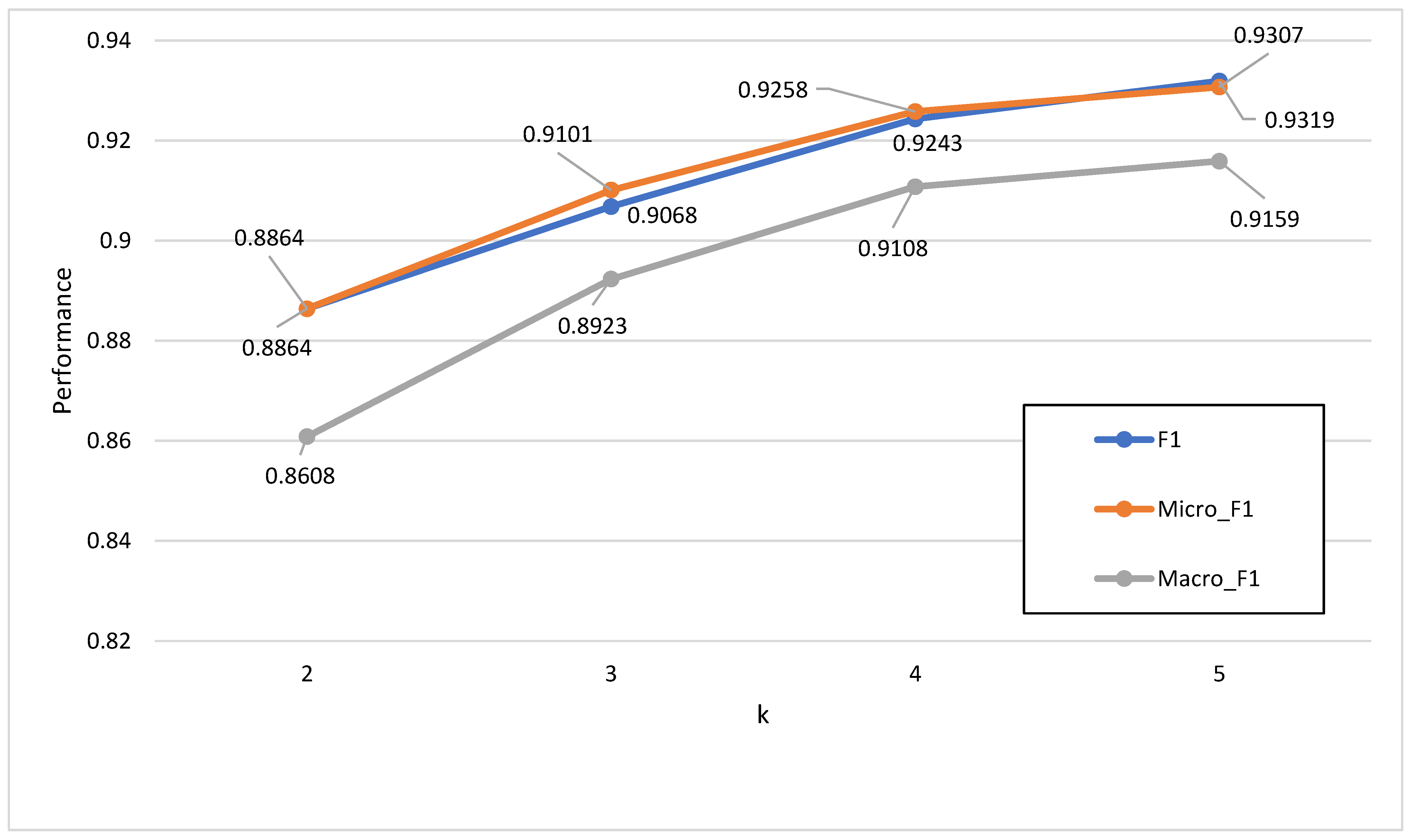
is obtained. The value of k ranged from 2 to 5 in our experiment, and the value selection is discussed in
Section 3.1.
The set of m-many k-mer sequence fragments
corresponding to the piRNA sequence
is transformed into a pretrained embedding representation, which is expressed as follows:
2.2.2. k-mer Positional Embedding
In natural language processing technology, positional vectors are used to represent the position information of words. To enhance our model in capturing the sequential characteristics of sequences, positional embedding (PE) was used to identify piRNA functional labels.
Since the binary representation of position vectors wastes substantial memory, positional embedding generated by sinusoidal and cosine curves of varying frequencies was applied in our study. The positional embedding of the
-th k-mer subsequence is a vector determined by both the k-mer position and the component position, calculated as follows:
where
represents the position of the k-mer subsequence in a piRNA, and
j represents the component position of the k-mer positional embedding vector. The range of
i is [1,
], the range of
j is [0,
], and
represents the dimension of the positional embedding.
and
denote the value at even and odd component positions in the positional embedding vector of the
-th k-mer subsequence, respectively. This positional embedding is based on sinusoidal and cosine curves and provides our model with the ability to model the position of a k-mer subsequence and the distance of every two k-mer subsequences.
2.3. Improved TextRNN Network
In NLP, the TextRNN model [
25] can capture the most important semantic information in a sentence and improve the performance of multi-label identification tasks. Hence, in our study, an improved TextRNN network was used to systematically recognize piRNA functional labels in four parts: a fusion-encoding layer, a sequence encoder, an attention layer, and a classification layer. The details of the above components are described in the following sections.
2.3.1. k-mer Encoding Layer
In the embedding layer, the final embedding matrix is an aggregate matrix
, which is accumulated by the k-mer word embedding matrix and the positional embedding matrix.
refers to the dimension of both positional embedding and the pretrained embedding representation. It is computed as follows:
2.3.2. Sequence Encoder
TextRNN [
25] is an RNN-based flexible neural network designed for text data processing. In multiple text tests, TextRNN has achieved good results. However, traditional RNNs are likely to face vanishing or exploding gradient problems. As a variant of recurrent neural networks, gated recurrent units (GRUs) [
25] can effectively address these problems. By simplifying the gating structure, GRUs become faster than Long Short-Term Memory (LSTM) and can better learn long-term dependencies. Therefore, a GRU can be successfully used to model sequence data in NLP, especially in sequence classification tasks and sequence annotation tasks. Typically, a GRU contains two gates, the update gate and the reset gate, which are used to determine the retention or disposal of information. The update gate
decides how much of the new input should be used to update the hidden state, while the reset gate
determines how much of the previous hidden state should be forgotten. The update gate
and reset gate
of the
-th hidden unit are computed by
where
is the sigmoid function,
is the vector of the current-position k-mer fragment, and
is the final hidden state of the previous position k-mer fragment. The weight matrices
,
,
, and
are learned, and
and
are biases.
The hidden state
and candidate hidden state
of the GRU are computed by
where
is the dot product,
and
are weight matrices, and
is a bias.
Bi-GRU is a structure-reinforcing GRU neural network and provides the output layer with complete contextual information about the input data at each moment. The input sequence propagates through both a forward GRU and a backward GRU and then concatenates the outputs of both. The calculation process of the final hidden state of the current k-mer fragment,
, is as follows:
where
and
are the forward and backward hidden states of the current k-mer fragment, respectively.
represents the forward hidden state of the previous position k-mer fragment.
represents the backward hidden state of the next position k-mer fragment. Finally, the output of the piRNA sequence encoder,
, is obtained by consolidating the encoding information from both directions of each k-mer fragment, where
h is the dimension of the final hidden state.
2.3.3. Attention Layer
Recent studies have shown that piRNAs degrade mRNAs and lncRNAs through a miRNA-like mechanism. This suggests that a specific sequence fragment at a specific position is required for piRNA functions. The model should selectively focus on specific k-mer piRNA fragments that have biological functions. An attention mechanism can enable neural networks to focus on a subset of their inputs, so an attention layer is used in our model.
The output of the sequence encoder serves as the input to this layer. As referenced by Yang et al. [
26], a k-mer-level context vector,
, can be introduced, and a normalized importance weights,
, can be calculated using a softmax function. To measure the importance of k-mer subsequences, the computation process is as follows:
where
is a trainable weight;
is a bias,
is the attention weight of the
-th k-mer; and
represents the new weighted representation of the piRNA, as calculated by the sum of element-wise multiplication between attention weights and the input data of that layer.
2.3.4. Classification Layer
We treated this piRNA function prediction task as a multi-label classification problem. We introduced a fully connected layer for linear transformation into the classification layer of the model, allowing each sample to have the possibility of multiple labels. To reduce the model’s dependence on specific neurons and improve generalization capabilities, we performed a dropout operation on the output of the fully connected layer. Finally, a sigmoid activation function was used to generate the predicted probability of the corresponding label for each sample, ensuring they are independent of each other.
2.4. Evaluation Methods
In our research, 10-fold cross-validation was used to evaluate the performance of the model. Samples were randomly divided into 10 folds. Each fold was used to validate the model, with the remaining data used to train it.
Evaluating the performance of multi-label classification differs from multi-class classification. In multi-class classification, each sample only belongs to one class, and the class labels are mutually exclusive. Predictions can be either entirely correct or incorrect. In multi-label classification, each sample can belong to multiple classes, and evaluating multi-label classification methods is like evaluating of information retrieval methods.
In the present study, the multi-label corpus C is the piRNA sequence set with functional labels, where each sample in this set is represented as , , and is the total number of samples in C. is a piRNA sample, is the true associated label set of , and is a label set obtained with the prediction method for represents the total number of labels.
To evaluate our piRNA function multi-label prediction method, two kinds of metrics were used. One is a sample-based metric, another is a label-based metric. Sample-based metrics include accuracy, precision, recall, F1 score, hamming loss, etc. To better highlight that our study falls within the domain of multi-label classification, we provide explanations for hamming loss, micro_F1, and macro_F1.
Hamming loss is used to estimate the incorrect classification ratio, indicating both the failure to predict correct labels and the prediction of incorrect labels. The lower the Hamming loss, the better the performance. The formula is as follows:
where
represents the symmetric difference between two sets.
Two label-based metrics are also applied, and they are as follows:
is the harmonic mean of
and
, calculated as follows:
where
represents the overall precision of all labels.
is the harmonic mean of among multi-label precision and recall and is calculated as follows:
where
represents the precision of the
-th label.
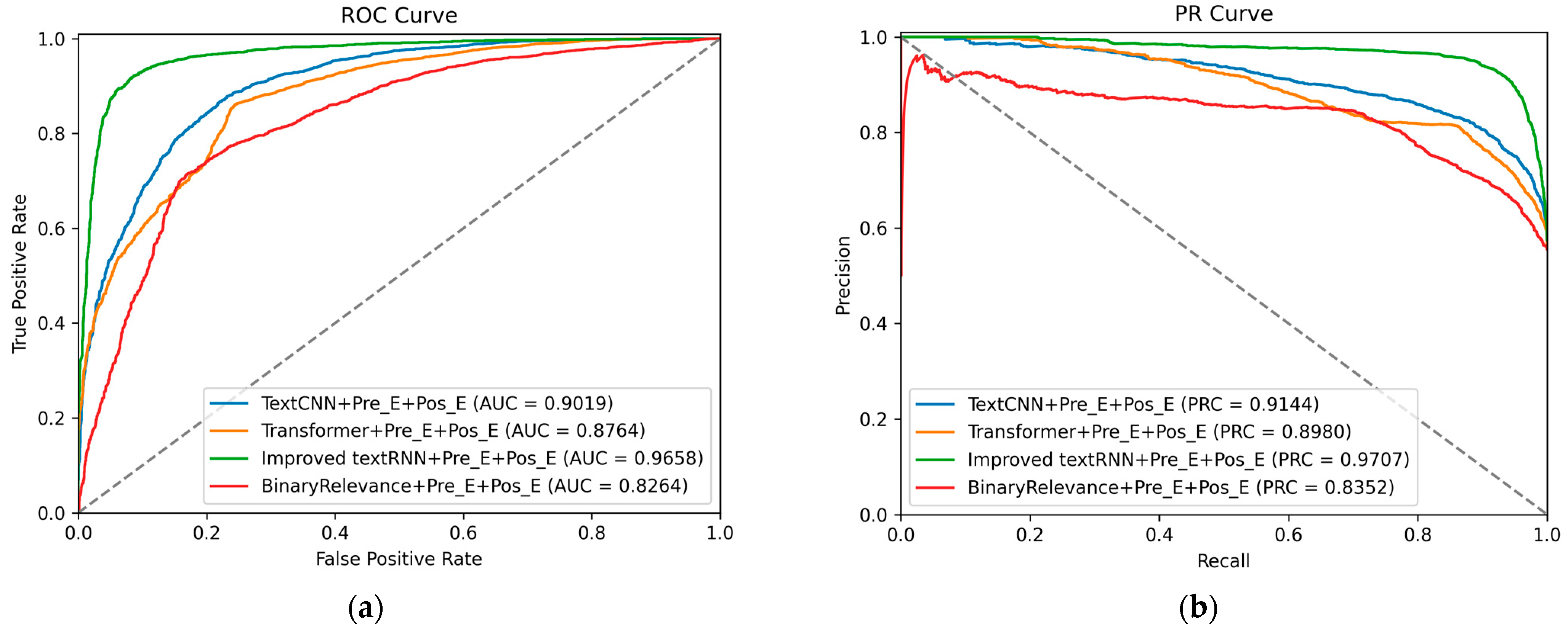
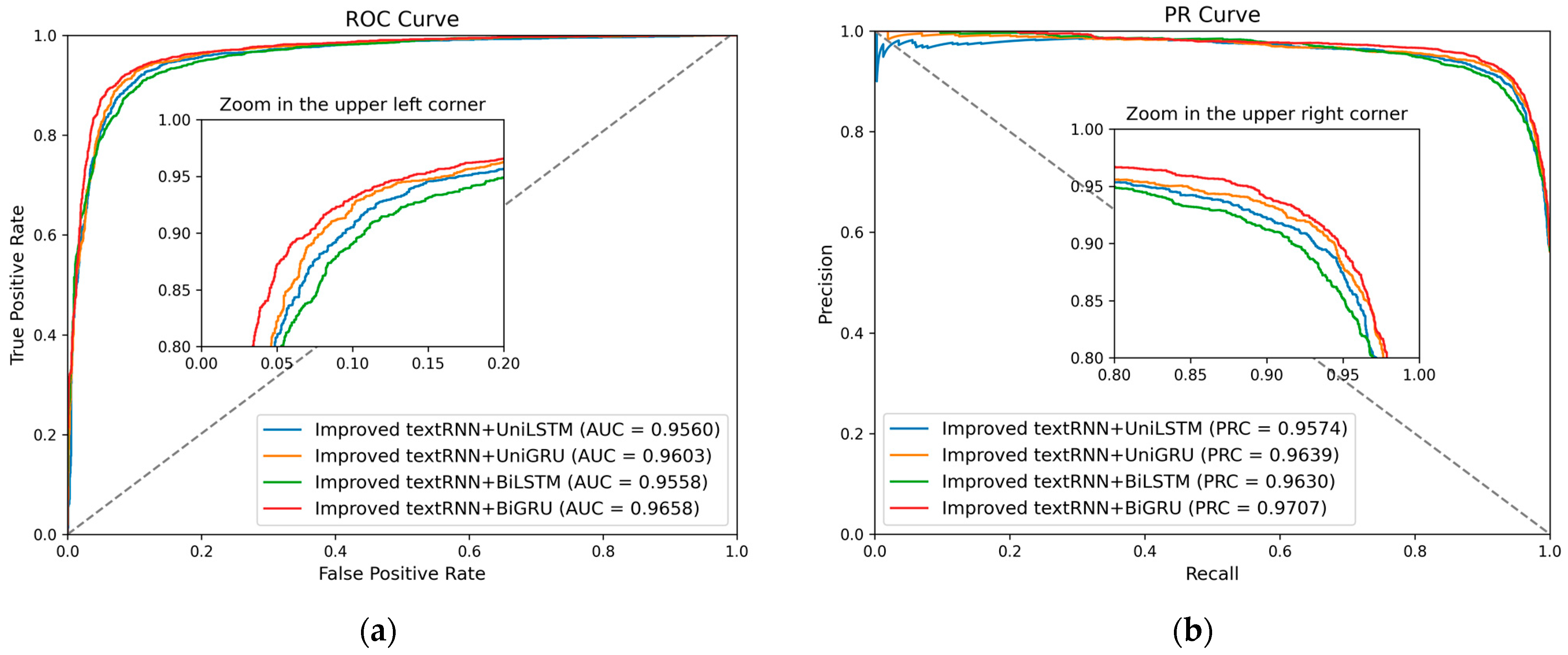
Apart from the above metrics, the receiver operating characteristic curve (ROC) and the precision–recall curve (PRC) are also used to evaluate the performance of methods.
4. Conclusions and Future Directions
Compared with the prediction results for miRNA and lncRNA functional labels, research related to piRNAs is still in an early phase. In this study, we developed a computational method for predicting functional labels for piRNAs based on pretrained k-mer embedding, positional embedding, and an improved TextRNN model. First, we collected piRNA functional label data and sequence data and then constructed a benchmark dataset via data processing. Moreover, pretrained k-mer and positional embedding were applied to obtain sequence representation with biological significance. Finally, an end-to-end model that couples the discriminative power of representation with the improved textRNN was used to implement the piRNA functional label prediction task. In conclusion, our model can characterize piRNA functional labels and could be beneficial to researchers investigating piRNA functions.
Bioinformatics investigations necessitate extensive data. In contrast to the abundant databases on miRNA-mRNA and miRNA-lncRNA, functional annotated data on piRNA remain limited. Our ongoing studies revolve around a dedicated focus on contemporary advancements in piRNA research and will improve our work in the following future directions:
Due to data limitations, we only focused on two types of functional labels for piRNA in this study. Existing studies have shown that piRNAs can not only degrade mRNA in a miRNA-like manner but also extensively activate mRNA translation. According to these biological facts, we will subdivide piRNA functional labels based on data accumulation. In addition, piRNA functions are diverse, as they can regulate various genetic factors such as transposable elements (TE). For these regulatory objects, we will expand the piRNA functional labels through data accumulation.
- 2.
Identification of functional sites
Based on the transcriptome data, we will identify the functional sites of piRNA and explore piRNAs as potential biomarkers and drug targets using a computational method. This method can characterize the functional sites of piRNAs, helping researchers infer the potential regulatory functions of piRNAs and their binding mechanisms with other genetic factors.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}