1. Introduction
Deep learning, as a promising and practical technology, has been extensively adopted to enhance the performance of mobile crowdsensing systems (MCSs) [
1,
2,
3,
4]. For instance, in [
5], the authors utilize deep neural networks (DNNs) and employ graph convolutional reinforcement learning to achieve Aoi-minimal UAV crowdsensing. Similarly, in [
6], the DNN is utilized to implement a heterogeneous task allocation in MCSs, employing a modified approximate policy approach. Furthermore, in [
7], Xu et al. combine the concepts of the graph attention network and deep reinforcement learning to propose an intelligent task allocation scheme for MCSs. It is evident that well-trained DNN models can significantly enhance the performance of MCSs.
However, as the model complexity, data volume, and number of tasks grow, the cost of training an applicable model, particularly for deep neural networks (DNNs), also increases. For instance, training a model with 1.5 billion parameters, such as the BERT model on Wikipedia, can cost nearly
$1.6 million. Therefore, safeguarding the trained models from duplication, theft, or unauthorized reproduction by adversaries is necessary and crucial [
8,
9].
It is worth noting that, to enhance the provision of machine learning as a service (MLaaS), certain organizations or companies opt to offer open-source toolkits, remote services, or cloud platforms to the public. However, despite its potential for commercial profit, this approach exposes the trained DNN models (which are often trained at considerable cost) to the public, enabling adversaries to steal the models discreetly and conveniently. These potential risks can lead to substantial economic losses [
10,
11,
12] and even involve legal issues [
13,
14,
15,
16] related to copyright infringement for the model owners. Researchers have already highlighted that adversaries can stealthily and efficiently steal DNN models [
17,
18]. In cases where the adversary possesses greater knowledge about the model or when the model parameters are publicly available, two commonly employed white-box attacks are unauthorized finetuning and pruning [
19]. Furthermore, recent studies have shown that even under a black-box attack scenario [
17,
20], the core functionalities of a DNN model can still be extracted. Despite the adversary’s limited access to the exposed API, they can employ advanced model extraction approaches to reconstruct the underlying core functionality of the model. In conclusion, there has been a rapid growth in the threat to the copyright of DNN models, highlighting the urgent need for effective and practical countermeasures.
In recent years, numerous schemes have been proposed to protect model copyrights. DNN watermarking is a commonly employed scheme among these, known for its effectiveness in practical scenarios [
21,
22]. It utilizes the over-parameterization properties of DNNs to secretly embed a designed watermark (e.g., a signature or logo representing ownership information) into the model. Verifying the ownership of a suspected model can be easily accomplished by extracting potential embedded watermarks from the model [
23]. Consequently, DNN watermarking is considered a promising technique with significant advantages. However, these schemes still have some crucial drawbacks [
24]. Notably, the essential attribute of these schemes is their invasive nature, where the model content or training process is modified after watermark embedding. Recent studies have shown that such modifications can severely compromise the utility of DNN models or introduce additional vulnerabilities [
25,
26].
To overcome the limitations of invasive techniques such as watermarking, researchers have proposed DNN fingerprinting, which has garnered significant attention [
27,
28]. Fingerprinting is rooted in the uniqueness of a DNN model, which embodies its distinct characteristics. Specifically, a distinctive fingerprint is extracted from the owner model, serving as an identifier to differentiate it from other models. If the extracted fingerprint from a suspect model matches that of the owner model, the model owner can assert ownership based on this result. However, in real-world scenarios, relying solely on the fingerprint as a feature or metric for justifying model ownership is insufficiently persuasive. Nonetheless, DNN fingerprinting is also vulnerable to state-of-the-art model stealing attacks. In conclusion, the distinctive characteristics of a DNN model may be compromised or unavailable in various situations.
To address the limitations of DNN fingerprinting, researchers have turned their attention to assessing the similarity between distinct models [
29,
30,
31]. Traditional approaches employ direct calculations, such as the Euclidean distance [
29], Kullback–Leibler divergence, or Jensen–Shannon divergence [
31], to measure the dissimilarity between the contents of distinct models in parameter space or output space. This methodology is based on the premise that the similarity between two different models stems from the resemblance of their internal contents. However, this simplistic approach lacks persuasiveness and practicality. For example, computing the Euclidean distance in the parameter space of DNN models can result in significant computational expenses [
32]. If these costs are deemed acceptable, copyright verification becomes unnecessary. Moreover, there is a possibility that the two models exhibit substantial differences [
33] in parameter space despite sharing the same training dataset and initialization due to potential bugs in floating-point operations or stochasticity in the training process.
To enhance the assessment of similarity between distinct models, Chen et al. [
30] introduced a testing framework called DeepJudge. In their study, they evaluate the similarity of two distinct models using six metrics across three levels, which are based on the generated test cases. Their experiments provide evidence of DeepJudge’s effectiveness. Despite the promise of DeepJudge compared to traditional approaches, it assumes that the model owner grants unrestricted access to the architecture, parameters, and datasets, including training details in some cases. However, in real-world scenarios, ownership verification is typically conducted by a third party, and the model owner is reluctant to provide such access due to concerns about model privacy. Consequently, there is an urgent need for a method that can measure model similarity while maintaining model privacy. However, to the best of our knowledge, this problem has been largely overlooked.
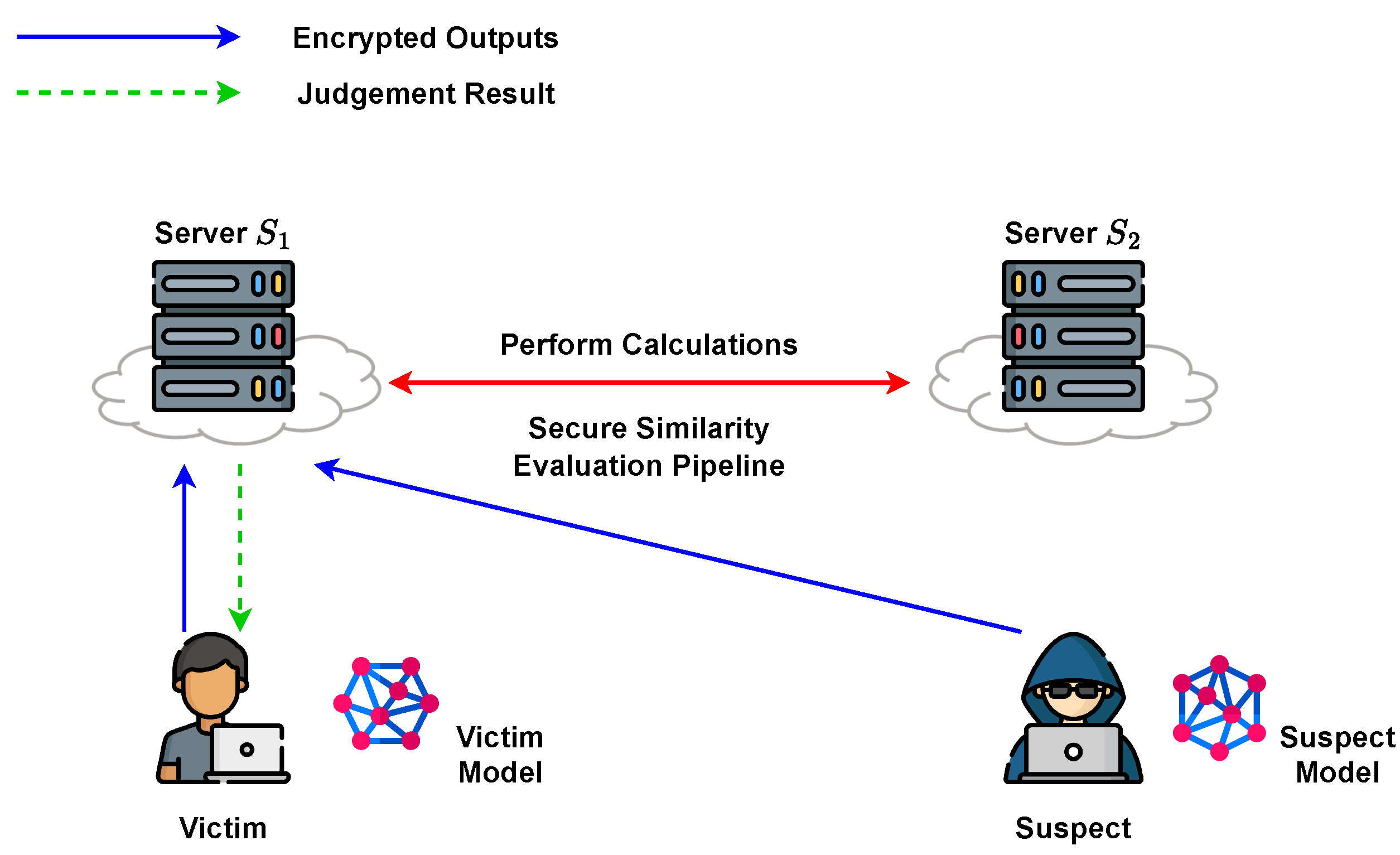
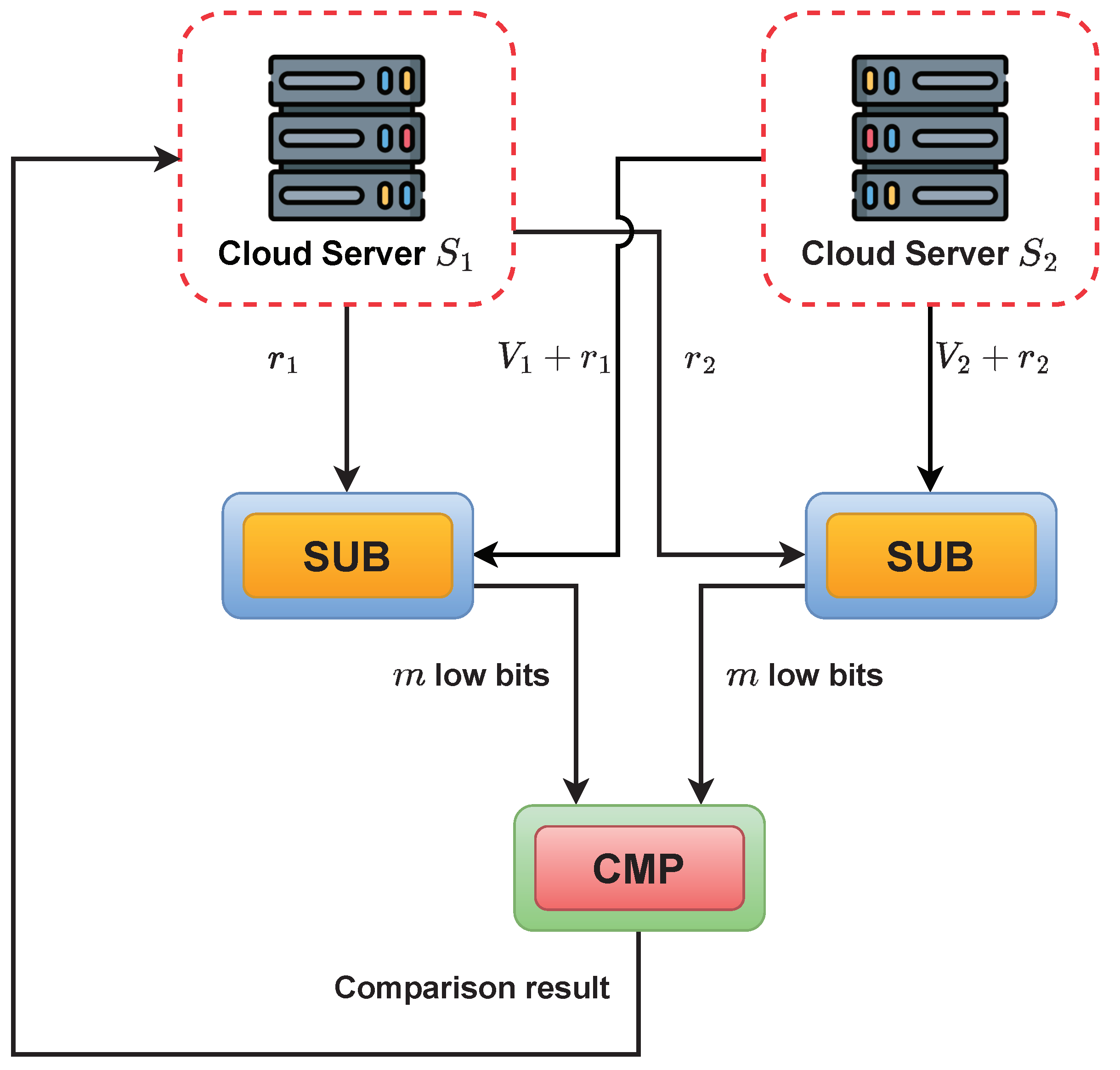
This paper focuses on evaluating the similarity between two distinct models in a privacy-preserving manner using cryptographic techniques. We propose a set of protocols based on the two-cloud model for conducting privacy-preserving model similarity evaluation. In these protocols, the model owner (referred to hereafter as the “victim”) and the party holding a suspect model (referred to hereafter as the “suspect”) transmit encrypted data to the cloud server. During the computation phase, the two non-colluding servers can evaluate the similarity using different metrics without accessing any sensitive information about the model data. Subsequently, the encrypted evaluation result is returned to the victim for further estimation purposes. In real-world scenarios, when two AI companies or organizations face a copyright infringement conflict, the details of their respective models are confidential due to commercial competition. Therefore, adopting these protocols encourages the entities to pursue judgment by the authorized third party while alleviating concerns about unintentional leakage of confidential model information.
In summary, our main contributions are:
We address a realistic and often overlooked problem: preserving privacy in model copyright verification. To the best of our knowledge, this paper is the first to discuss privacy preservation in this context.
We propose a set of protocols based on the two-cloud model that enables the evaluation of similarity between distinct models while safeguarding model privacy. Our protocols encompass multiple metrics at various levels, providing a comprehensive evaluation of model similarity.
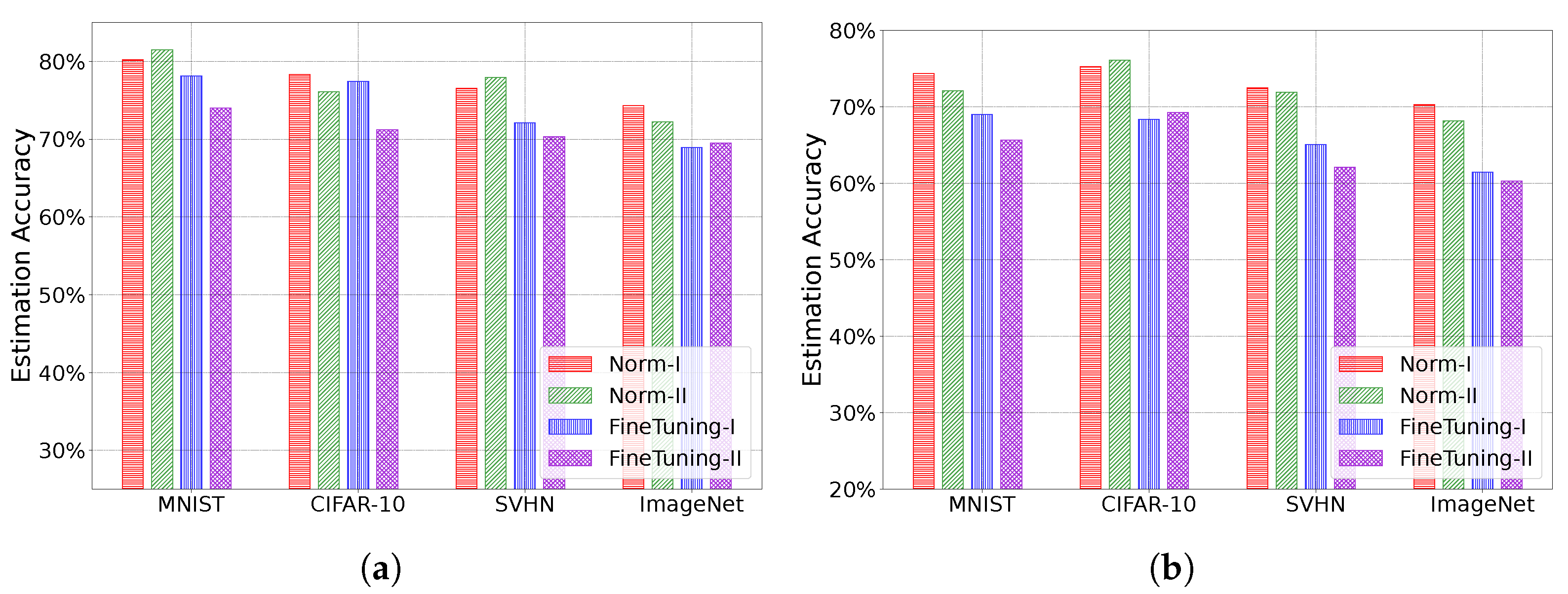
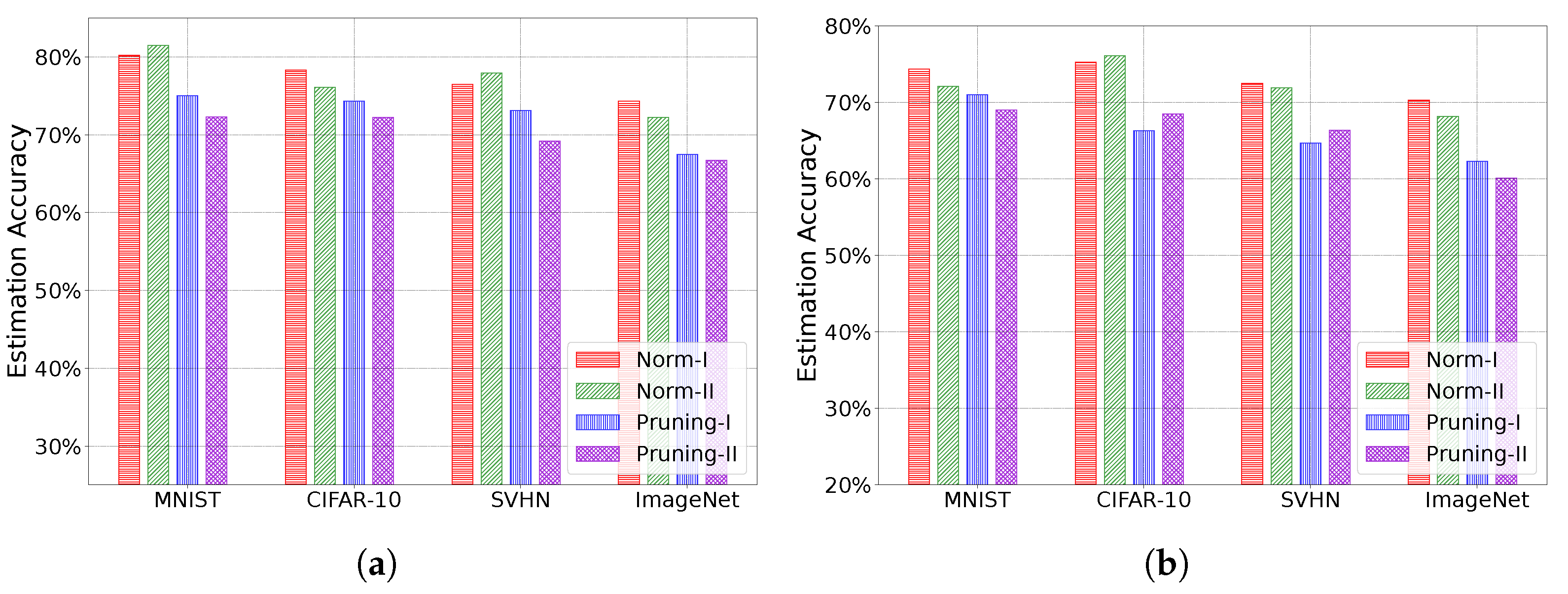
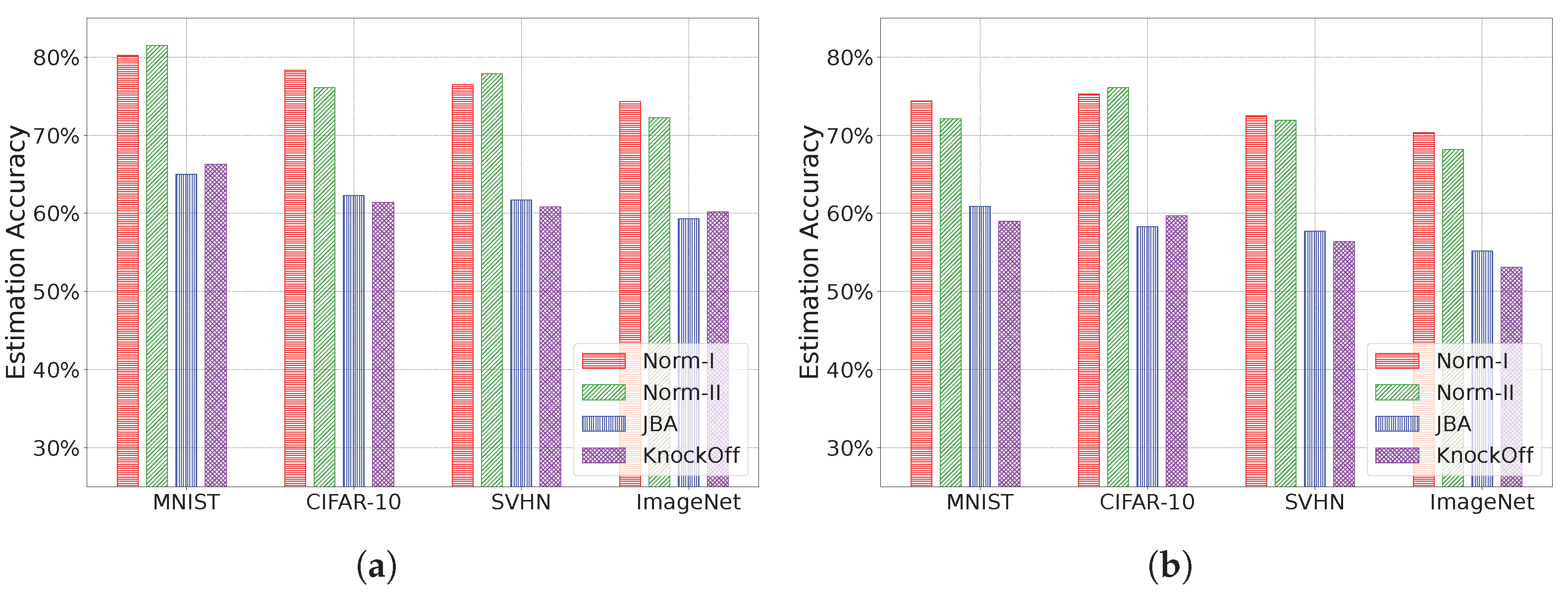
Through extensive experiments conducted on various real-world DNN models and datasets, we demonstrate the effectiveness of our protocols.
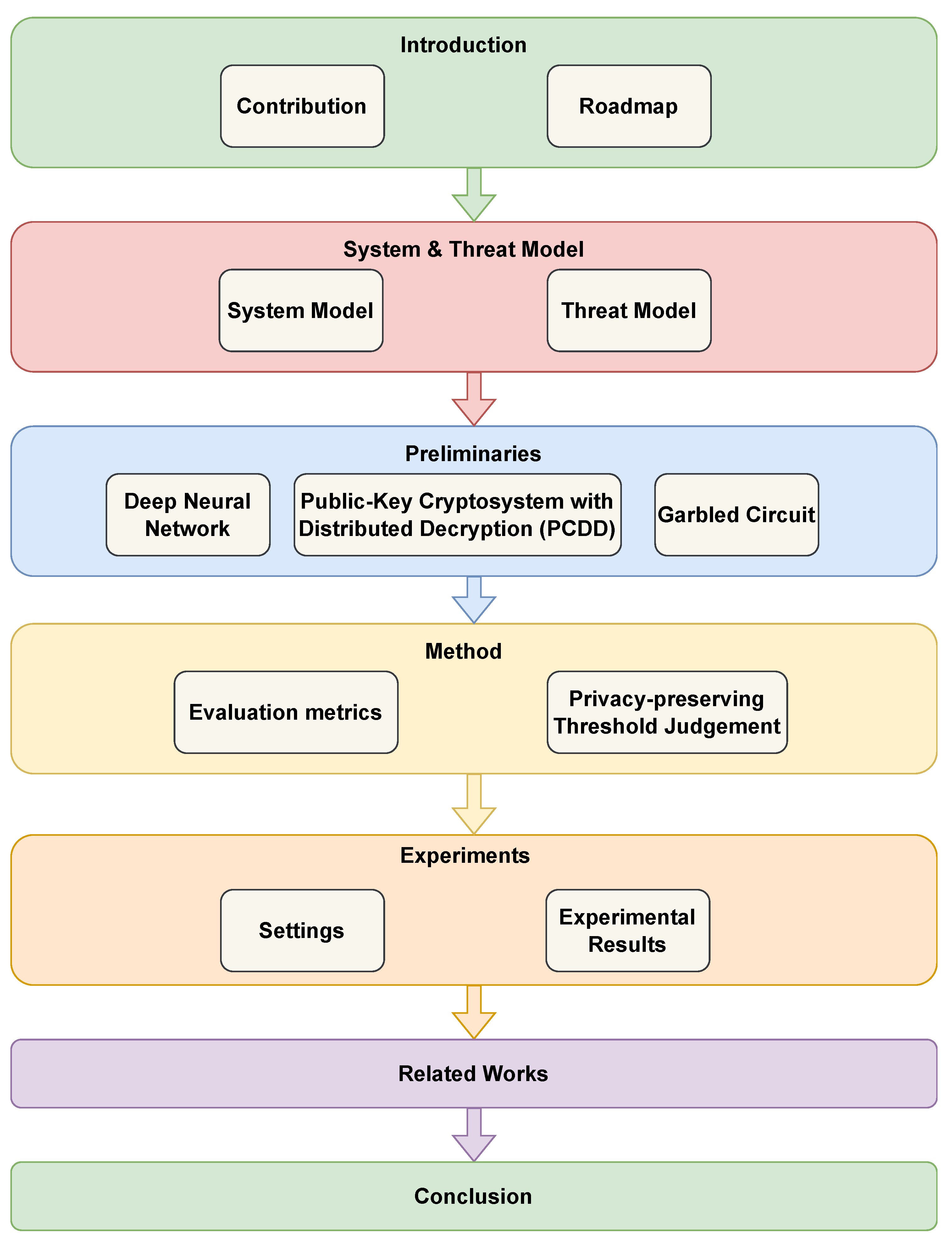
The structure of this paper is as follows:
Section 2 provides an introduction to the system and the threat model.
Section 3 presents the preliminaries, while
Section 4 describes the details of the proposed protocols. In
Section 5, we discuss the experimental results to demonstrate the effectiveness of the proposed protocols.
Section 6 highlights relevant works on model copyright. Finally, we conclude our work in
Section 7. The detailed roadmap is illustrated in
Figure 1.
6. Related Works
6.1. DNN Watermarking
Numerous watermarking technology solutions have been proposed to safeguard the copyright of DNN models. Similar to the techniques utilized in the traditional multimedia domain, existing DNN watermarking approaches comprise two primary steps. The initial step involves embedding, whereas the subsequent step entails verification. In the embedding step, the designated watermark, owned by the creator, is incorporated into the model during the training process. Regarding the verification step, DNN watermarking approaches can be primarily classified into two categories: white-box and black-box. Categorization is based on the level of knowledge accessible during the verification step.
In white-box watermarking, the availability of model information allows for the embedding of a pre-determined signature into the model’s parameter spaces using various methods, such as regularization terms. Thus, if the extracted watermark from a suspect model closely matches the owner’s signature, the copyright of that model can be readily justified. In contrast, black-box watermarking employs backdoor attack techniques due to the absence of model information. Specifically, the model owner trains the model with a trigger set to compel the model to categorize certain samples into a specific hidden class, acting as a backdoor. The watermark is also injected into the model upon completion of the training procedure. Thus, to verify the copyright of a suspect model, the owner simply needs to query the suspect model using samples from the trigger set and examine whether the predicted result corresponds to the predetermined hidden class.
Despite its effectiveness and simplicity, watermarking inevitably possesses significant drawbacks. In addition to its invasive nature, which interferes with the training process, the performance of watermarking is heavily reliant on the model’s ability to memorize. Essentially, watermarking aims to maximize the model’s retention of the watermark content, and the degree of memorization determines the robustness of the watermark against attacks. As indicated in numerous studies, watermarking proves effective in countering finetuning and pruning attacks but is susceptible to various model extraction attacks. One critical factor is that model extraction attacks aim to pilfer the model’s functionality rather than its entire contents, whereas most watermarks are often task-irrelevant. Despite the aforementioned disadvantages of watermarking, it remains the sole method for owners to embed their signature into their models, surpassing the capabilities of other techniques.
6.2. DNN Fingerprinting
In recent years, numerous researchers have focused on DNN fingerprinting techniques as an alternative method for verifying ownership. Similar to DNN watermarking, DNN fingerprinting involves two steps: fingerprint extraction and fingerprint verification. Importantly, fingerprinting is considered non-invasive, distinguishing it from watermarking schemes. Unlike watermarking, where intervention in the model training process is required to embed a watermark, fingerprinting techniques directly extract a distinctive feature or attribute from the model to act as a fingerprint. If the fingerprint of a suspect model matches that of the owner’s model, the owner can assert ownership of the suspect model.
For example, in [
28], the authors introduced IPGuard, a fingerprinting scheme. IPGuard characterizes the fingerprint by utilizing data points located near the classification boundary to capture the model’s boundary property. If a suspect model produces identical predictions for a majority of these points, IPGuard identifies it as an unauthorized copy of the owner’s victim model. Additionally, in [
27], a Conferrable Ensemble Method (CEM) is introduced to capture the overlap between the decision boundary or adversarial subspaces of the victim model and those of the suspect model. Specifically, this CEM generates conferrable adversarial examples, which are a specific type of transferable examples, to facilitate characterization. In [
27], the authors demonstrate the robustness of a CEM against common DNN removal attacks, such as finetuning, pruning, and extraction attacks. However, it is incapable of addressing certain adapted attacks, including adversarial learning.
In conclusion, as evidenced, the majority of fingerprinting schemes concentrate on establishing the “uniqueness” of a particular model. However, in practical scenarios, relying solely on or being limited to a specific metric is not practical. Consequently, relying solely on fingerprinting is insufficient to provide convincing evidence or support for verifying model ownership. A potentially promising approach to address this challenge is to combine various existing methods to create a comprehensive mechanism.
6.3. Model Similarity Evaluation
The evaluation of model similarity has emerged as a crucial metric used to assess performance in diverse scenarios, including Machine Unlearning [
32] and model copyright protection [
30]. Consequently, numerous researchers have dedicated their efforts to this area and proposed a range of schemes.
Wu et al. [
29] utilized the Euclidean distance as a measure of similarity between two distinct DNN models in the context of machine unlearning, based on the intuition that the parameter distance reflects their similarity. However, experiments conducted on ResNet by the authors of [
33] revealed that relying solely on the
-Norm to evaluate DNN model similarity is insufficiently accurate and practical. Specifically, various complex factors such as learning rate and floating-point operations can result in significantly different model parameter outcomes, even when the training datasets and initialization are identical. Additionally, for large DNN models with a substantial number of parameters, the computational costs become impractical in real-world applications [
32].
To address the mentioned limitations, Golarkar et al. [
31] employ the extensively used the Jensen–Shannon divergence, based on the Kullback–Leibler divergence, to assess the distance between two distinct DNN models in the parameter space. Similarly, in [
57], the authors utilize the Jensen–Shannon divergence to quantify the distance between probability distributions of two different DNN models. Another notable metric, known as activation distance, is employed in certain studies [
57,
58]. It represents the average
-Norm distance between probability distributions of two distinct models. Furthermore, to provide a comprehensive evaluation at a broader level, model similarity measurement employs layer-wise distance [
41]. This approach computes the distance between two models considering their parameters or the output of each layer.
Recently, Chen et al. [
30] introduced a framework known as DeepJudge. DeepJudge combines multiple metrics to provide a comprehensive evaluation of the similarity between two distinct DNN models. Specifically, the framework categorizes six distinct metrics into three main categories. When assessing the similarity between two different DNN models, DeepJudge initially calculates the distance value for each respective metric separately. Subsequently, it determines whether the suspect model exhibits sufficient similarity to the victim model within the specified metric, based on a predetermined threshold. Finally, a straightforward majority voting scheme is employed to determine whether the suspect model constitutes an illicit copy of the victim model. However, this necessitates the victim granting DeepJudge full access to their DNN model, including model parameters and architecture. Consequently, this approach is impractical in real-world scenarios where concerns about model data privacy have already arisen, as some model owners may be unwilling to provide DeepJudge with such privileges due to the potential risk of private model information leakage.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}