
Harnessing Causal Structure Alignment for Enhanced Cross-Domain Named Entity Recognition

Abstract
:1. Introduction
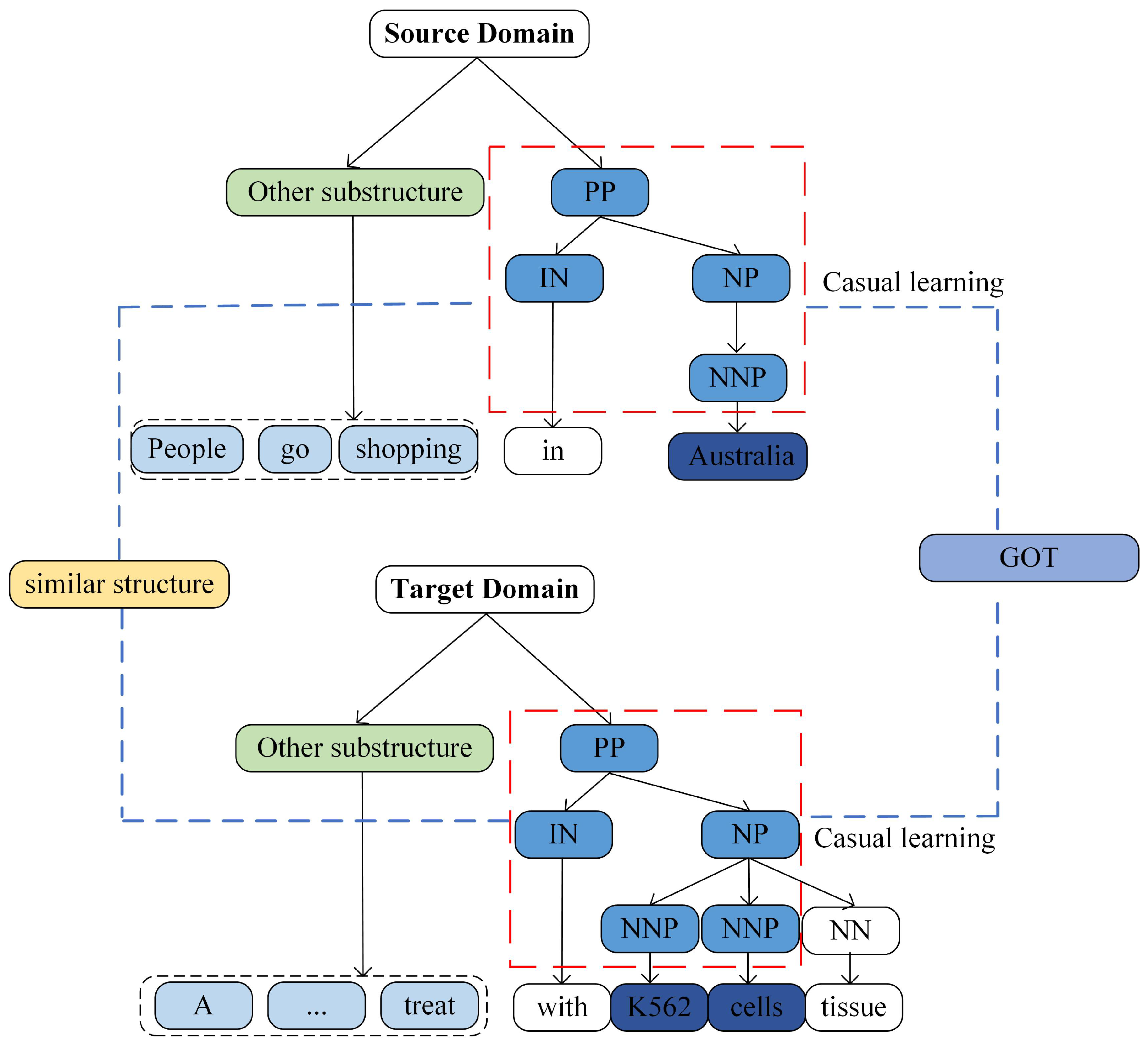
- This paper proposes a novel method that utilizes causally invariant knowledge between features to improve cross-domain named entity recognition (CD-NER). By leveraging the stability of causally invariant knowledge across domains, this method aids in the effective transfer of knowledge across different data environments.
- The proposed cross-domain named entity recognition model with causal structure alignment incorporates a causal alignment module in the embedding layer to build a causal feature graph by identifying causal relationships between features. Through alignment metrics via graph optimal transport (GOT), it obtains causal invariant knowledge, mitigating the negative transfer effects between domains. Additionally, Gated Attention Units (GAUs) are used in the hidden layer to enhance the utilization of causally invariant knowledge, thereby extracting more efficient feature representations in the target domain
- The proposed method and modeling approach are validated through rigorous experiments conducted on a variety of data sources, including five English datasets and a proprietary cross-domain NER dataset. The experimental results confirm the effectiveness of including causal invariant information within features, demonstrating its significant role in facilitating knowledge transfer for cross-domain named entity recognition.
2. Related Work
2.1. Cross-Domain Named Entity Recognition
2.2. Few-Shot Named Entity Recognition
2.3. Causal Invariant Learning
3. Methodology
3.1. Model Architecture
3.2. Causal Alignment Module
3.2.1. Causal Feature Graph
3.2.2. Causal Structural Alignment
3.3. Feature Fusion Module
3.4. Optimization Goals
4. Experiments
4.1. Datasets and Settings
4.2. Evaluation Protocols
4.3. Baseline Models
4.4. Result Analysis
4.5. Ablation Study
- Removal of the causal graph construction task loss .
- Omission of , which is crucial for the graph matching task.
- Absence of both and , to assess their combined effect.
- Exclusion of the gate mechanism in .
- Simultaneous elimination of , , and the gate mechanism in .
4.6. Performance with Different Data
4.7. Hyperparameter Discussion
- is designed to control the uncertainty distribution within the causal feature graph. This is achieved by adjusting , the loss associated with the causal graph construction task. By tuning , we effectively manage how the model accounts for uncertainty in the causal relationships it identifies and represents.
- , on the other hand, is pivotal in aligning causally invariant knowledge within the causal features. It does this by adjusting , which is instrumental in the graph matching task, ensuring that the causally relevant features are accurately aligned across different domains.
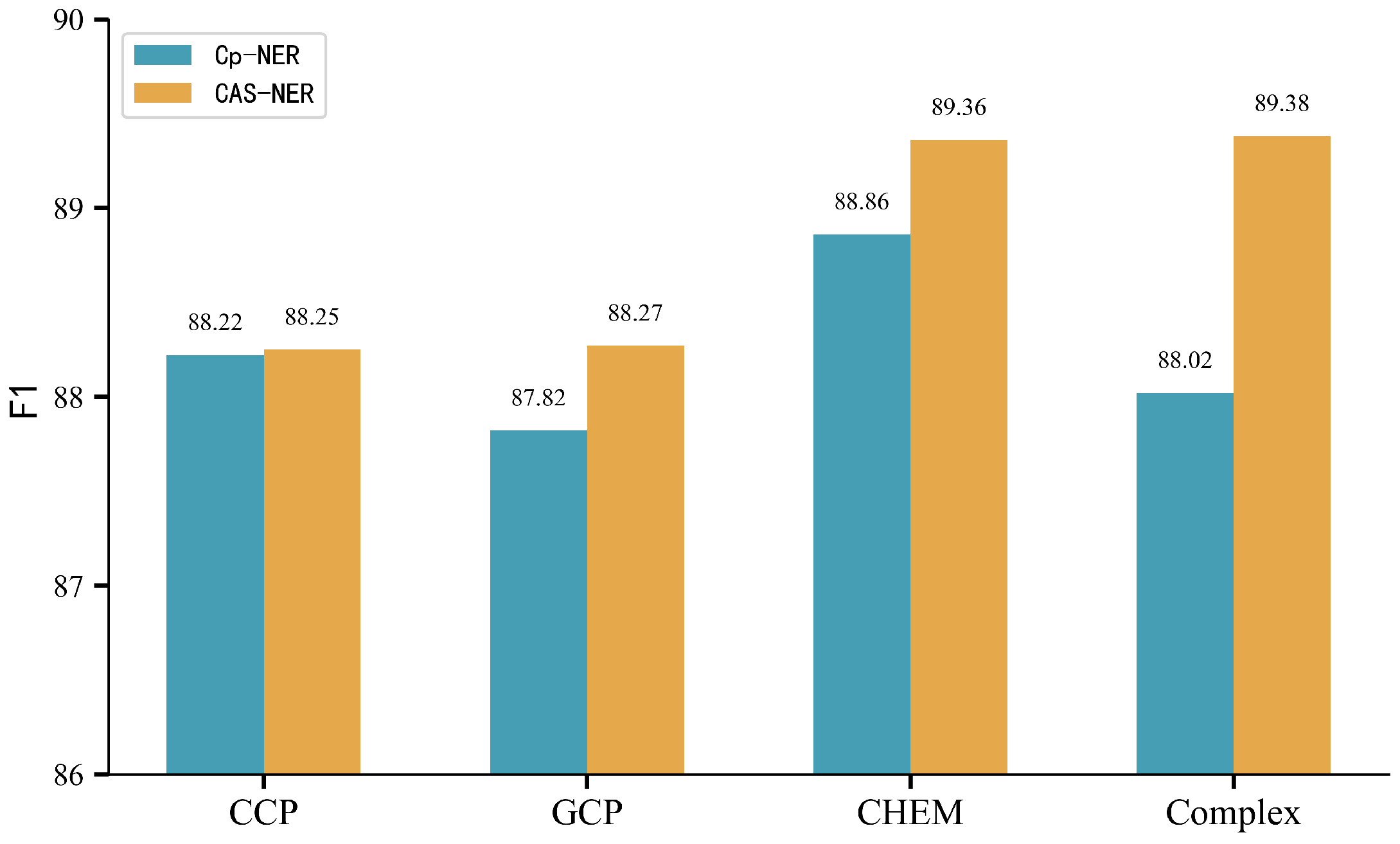
4.8. Fine-Grained Analysis
4.9. Case Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ehrmann, M.; Hamdi, A.; Pontes, E.L. Named entity recognition and classification in historical documents: A survey. ACM Comput. Surv. 2023, 56, 1–47. [Google Scholar] [CrossRef]
- Ahmad, P.N.; Shah, A.M.; Lee, K. A Review on Electronic Health Record Text-Mining for Biomedical Name Entity Recognition in Healthcare Domain. Healthcare 2023, 11, 1268. [Google Scholar] [CrossRef]
- Tsai, C.-M. Stylometric Fake News Detection Based on Natural Language Processing Using Named Entity Recognition: In-Domain and Cross-Domain Analysis. Electronics 2023, 12, 3676. [Google Scholar] [CrossRef]
- Liu, Z.; Xu, Y.; Yu, T. Crossner: Evaluating cross-domain named entity recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 13452–13460. [Google Scholar]
- Chen, J.; Zhang, Y. Multi-cell compositional LSTM for NER domain adaptation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5906–5917. [Google Scholar]
- Tan, Z.; Chen, Y.; Liang, Z. Named Entity Recognition for Few-Shot Power Dispatch Based on Multi-Task. Electronics 2023, 12, 3476. [Google Scholar] [CrossRef]
- Liu, Z.; Winata, G.I.; Xu, P. Coach: A Coarse-to-Fine Approach for Cross-domain Slot Filling. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 19–25. [Google Scholar]
- Hu, J.; Zhao, H.; Guo, D.; Wan, X.; Chang, T. A label-aware autoregressive framework for cross-domain NER. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2022, Seattle, WA, USA, 10–15 July 2022; pp. 2222–2232. [Google Scholar]
- Zheng, J.; Chen, H.; Ma, Q. Cross-domain named entity recognition via graph matching. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 2670–2680. [Google Scholar]
- Chen, X.; Li, L.; Fei, Q.; Zhang, N.; Tan, C.; Jiang, Y.; Chen, H. One Model for All Domains: Collaborative Domain-Prefix Tuning for Cross-Domain NER. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence (JCAL-23), Macao, China, 19–25 August 2023; Volume 2301, p. 10410. [Google Scholar]
- Chevalley, M.; Bunne, C.; Krause, A.; Bauer, S. Invariant causal mechanisms through distribution matching. arXiv 2022, arXiv:2206.11646. [Google Scholar]
- Chen, Y.; Zhang, Y.; Bian, Y.; Yang, H.; Ma, K.; Xie, B.; Liu, T.; Han, B.; Cheng, J. Learning causally invariant representations for out-of-distribution generalization on graphs. Adv. Neural Inf. Process. Syst. 2022, 35, 22131–22148. [Google Scholar]
- Arjovsky, M.; Bottou, L.; Gulrajani, I.; Lopez-Paz, D. Invariant Risk Minimization. arXiv 2019, arXiv:1907.02893. [Google Scholar]
- Fritzler, A.; Logacheva, V.; Kretov, M. Few-shot classification in named entity recognition task. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; pp. 993–1000. [Google Scholar]
- Tong, M.; Wang, S.; Xu, B.; Cao, Y.; Liu, M.; Hou, L.; Li, J. Learning from Miscellaneous Other-Class Words for Few-Shot Named Entity Recognition; Association for Computational Linguistics (ACL): Cedarville, OH, USA, 2021; pp. 6236–6247. [Google Scholar]
- Cui, L.; Wu, Y.; Liu, J.; Yang, S.; Zhang, Y. Template-Based Named Entity Recognition Using BART. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 1835–1845. [Google Scholar]
- Ma, R.; Zhou, X.; Gui, T.; Tan, Y.; Li, L.; Zhang, Q. Template-free Prompt Tuning for Few-shot NER. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 10–15 July 2022; Volume 2109, p. 13532. [Google Scholar]
- Lu, W.; Wang, J.; Li, H.; Chen, Y.; Xie, X. Domain-invariant Feature Exploration for Domain Generalization. Trans. Mach. Learn. Res. 2022, 2835–8856. [Google Scholar]
- Li, X.; Li, B.; Jin, X.; Lan, C.; Chen, Z. Learning Distortion Invariant Representation for Image Restoration from A Causality Perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1714–1724. [Google Scholar]
- Rojas-Carulla, M.; Schölkopf, B.; Turner, R.; Peters, J. Invariant models for causal transfer learning. J. Mach. Learn. Res. 2018, 19, 1309–1342. [Google Scholar]
- Yang, S.; Yu, K.; Cao, F.; Liu, L.; Wang, H.; Li, J. Learning causal representations for robust domain adaptation. IEEE Trans. Knowl. Data Eng. 2021, 35, 2750–2764. [Google Scholar] [CrossRef]
- Kocaoglu, M.; Snyder, C.; Dimakis, A.G.; Vishwanath, S. CausalGAN: Learning Causal Implicit Generative Models with Adversarial Training. Int. Conf. Learn. Represent. 2018, 1709, 02023. [Google Scholar]
- Wei, D.; Gao, T.; Yu, Y. DAGs with No Fears: A closer look at continuous optimization for learning Bayesian networks. Adv. Neural Inf. Process. Syst. 2020, 33, 3895–3906. [Google Scholar]
- Zheng, X.; Aragam, B.; Ravikumar, P.K.; Xing, E.P. Dags with no tears: Continuous optimization for structure learning. Adv. Neural Inf. Process. Syst. 2018, 31, 9472–9483. [Google Scholar]
- Zhai, P.; Yang, Y.; Zhang, C. Causality-based CTR prediction using graph neural networks. Inf. Process. Manag. 2023, 60, 103137. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- Ng, I.; Zhu, S.; Chen, Z.; Fang, Z. A Graph Autoencoder Approach to Causal Structure Learning. arXiv 2019, arXiv:1911.07420. [Google Scholar]
- Chen, L.; Gan, Z.; Cheng, Y.; Li, L.; Carin, L.; Liu, J. Graph optimal transport for cross-domain alignment. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1542–1553. [Google Scholar]
- Van Lint, J.H.; Wilson, R.M. A Course in Combinatorics; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Mou, L.; Men, R.; Li, G.; Xu, Y.; Zhang, L.; Yan, R.; Jin, Z. Natural Language Inference by Tree-Based Convolution and Heuristic Matching. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 130–136. [Google Scholar]
- Nédellec, C.; Bossy, R.; Kim, J.D.; Kim, J.J.; Ohta, T.; Pyysalo, S.; Zweigenbaum, P. Overview of BioNLP shared task 2013. In Proceedings of the BioNLP Shared Task 2013 Workshop, Sophia, Bulgaria, 9 August 2013; pp. 1–7. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.P.; Chanan, G.; Chintala, S.P. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | Size | Train | Dev | Test |
|---|---|---|---|---|
| PC | Sentence Entity | 2.5 K 7.9 K | 0.6 K 1.2 K | 1.7 K 5.3 K |
| CG | Sentence Entity | 3.0 K 10.8 K | 0.8 K 1.6 K | 1.9 K 6.9 K |
| Pol. | Sentence Entity | 0.2 K 1.3 K | 0.5 k 3.4 k | 0.6 k 4.2 k |
| Sci. | Sentence Entity | 0.2 K 1.0 K | 0.4 k 2.5 k | 0.5 k 3.0 k |
| Mus. | Sentence Entity | 0.1 K 0.6 K | 0.3 k 2.6 k | 0.4 k 3.3 k |
| Lit. | Sentence Entity | 0.1 K 0.5 K | 0.4 k 2.1 k | 0.4 k 2.2 k |
| AI | Sentence Entity | 0.1 K 0.5 K | 0.3 k 1.5 k | 0.4 k 1.8 k |
| Parameter | Value |
|---|---|
| Hidden variable | 768 |
| Batch size | 8 |
| Epoch | 50 |
| Dropout | 0.5 |
| Learning rate | |
| Optimizer | SGD |
| Method | Pol. | Sci. | Mus. | Lit. | AI | PC | CG |
|---|---|---|---|---|---|---|---|
| Coach | 61.50 | 52.09 | 51.66 | 48.25 | 45.15 | - | - |
| BERT-tag | 68.71 | 64.97 | 68.30 | 63.63 | 58.88 | - | - |
| LSTM | 70.56 | 66.42 | 70.52 | 66.96 | 58.28 | 86.26 | 80.74 |
| LST-NER | 70.44 | 66.83 | 72.08 | 67.12 | 60.32 | 87.14 * | 82.48 * |
| Cp-ner | 73.41 | 74.65 | 78.08 | 70.84 | 64.53 | 88.48 * | 84.53 * |
| Ours | 73.58 | 72.12 | 78.53 | 69.42 | 64.58 | 88.82 | 85.45 |
| Sample | k = 20 | k = 50 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | Pol. | Sci. | Mus. | Lit. | AI | Pol. | Sci. | Mus. | Lit. | AI |
| Coach | 46.15 | 48.71 | 43.37 | 41.64 | 41.55 | 60.97 | 52.03 | 51.56 | 48.73 | 51.15 |
| Bert-tag | 61.01 | 60.34 | 64.73 | 61.79 | 53.78 | 66.13 | 63.93 | 68.41 | 63.44 | 58.93 |
| LSTM | 59.58 | 60.55 | 67.12 | 63.92 | 55.39 | 68.21 | 65.78 | 70.47 | 66.85 | 58.67 |
| Tem-NER | 63.39 | 62.64 | 62.00 | 61.84 | 56.34 | 65.23 | 62.84 | 64.57 | 64.49 | 56.58 |
| LST-NER | 64.06 | 64.03 | 68.83 | 64.94 | 57.78 | 68.51 | 66.48 | 72.04 | 66.73 | 60.69 |
| Ours | 65.14 | 66.27 | 70.12 | 65.83 | 58.15 | 69.32 | 68.21 | 73.26 | 67.32 | 61.02 |
| T | Low Resources | High Resources | ||
|---|---|---|---|---|
| Datasets | Politics | Music | PC | CG |
| Ours | 69.32 | 73.26 | 88.82 | 85.45 |
| w/o | 68.80 | 72.13 | 87.82 | 83.95 |
| w/o | 68.65 | 71.10 | 86.55 | 83.68 |
| w/o | 68.12 | 72.56 | 86.84 | 84.77 |
| w/o + | 67.78 | 70.89 | 85.16 | 83.13 |
| w/o + + | 68.12 | 69.13 | 85.02 | 82.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Cao, M.; Yang, G.; Liu, J.; Liu, Y.; Wang, H. Harnessing Causal Structure Alignment for Enhanced Cross-Domain Named Entity Recognition. Electronics 2024, 13, 67. https://doi.org/10.3390/electronics13010067
Liu X, Cao M, Yang G, Liu J, Liu Y, Wang H. Harnessing Causal Structure Alignment for Enhanced Cross-Domain Named Entity Recognition. Electronics. 2024; 13(1):67. https://doi.org/10.3390/electronics13010067
Chicago/Turabian StyleLiu, Xiaoming, Mengyuan Cao, Guan Yang, Jie Liu, Yang Liu, and Hang Wang. 2024. "Harnessing Causal Structure Alignment for Enhanced Cross-Domain Named Entity Recognition" Electronics 13, no. 1: 67. https://doi.org/10.3390/electronics13010067