1. Introduction
Recommender systems have become increasingly important in various areas, such as music, movies, books, online shopping, news, points of interest (POIs), and e-learning materials, due to the growth of e-commerce and the increase in data volume [
1,
2]. While most B2C online services are equipped with diverse recommender system algorithms, B2B online services have received comparatively less attention from researchers, despite the growth of e-commerce in both sectors. Understanding differences between B2B and B2C is imperative for developing an appropriate approach to recommender systems for B2B. These differences include customers, transaction prices, product volumes, sales cycles, purchase decision processes, and trading relationships as highlighted by Saha et al. (2014) [
3]. B2B transactions target companies dealing with many high-priced products, with longer sales cycles and decision-making processes. This emphasizes the importance of trading relationships in B2B, while B2C tends to prioritize the product. Furthermore, B2B purchasing decisions are typically driven by planned and logical needs, unlike the impulse purchases often seen in B2C transactions. Thus, recommender systems for B2B require a different approach.
There are not many papers available on B2B recommender systems due to the confidentiality and non-disclosure of inter-company transaction data. In this paper, three papers related to B2B recommendation systems are identified. One paper proposes a framework for a B2B recommender system [
4], and another paper suggests a hybrid model and its applicability to B2B as a case study [
5]. However, unlike this paper, the first thesis focuses on a framework that recommends suppliers to buyers. In B2B, most buyers have specific requirements and order in a planned way [
3]. They need search engines rather than a recommender system since they know what they want. In the second paper, the model is based on collaborative filtering (CF), not utilizing side information. Side information refers to information other than the user’s interaction with the item, such as the user profile, item properties, item reviews, and the user’s social network [
2,
6]. If side information is used together, more diverse recommendations can be made than CF. Apart from these two papers, there is another B2B recommendation study similar to this one, which proposes a supplier-centric recommendation system [
7]. Nevertheless, its objective is to recommend the supplier’s products to client companies using a co-clustering technique. Furthermore, the difference from this research is that it relies solely on the past purchase network without utilizing side information to identify recommendation candidates.
This study intends to present two new perspectives on how recommender systems can be utilized in B2B. (1) Recommending buyers to sellers. The system aims to recommend buyers to sellers, contrary to the more conventional recommendation pair, which is items to buyers, and this is done as such for two reasons. Firstly, relationship plays a crucial part in B2B transaction. Secondly, recommending sellers to buyers could be less effective because buyers make a planned and rational transaction [
3]. Consequently, this manuscript focuses on the perspective of a company that sells products and recommends buyers unexpected by them to help discover customers (i.e., compared with the generic terms of recommender systems, users become suppliers, and items become buyers in this study). (2) Explainability must be guaranteed. In B2B, where the transaction amount is large and long term, it is not enough to recommend a company without explanation. For a recommender system to become a service in B2B, it needs to be able to explain what made the recommendations so that sales and marketing teams can also use the analysis.
Many algorithms have been developed to recommend products that meet the tastes of customers. CF is a popular method for recommendation systems, along with content-based, hybrid, and knowledge-based methods [
2]. However, CF methods perform poorly in sparse data due to their inability to model side information [
6]. To address this limitation, various recommendation systems have incorporated side information, including supervised learning (SL) and knowledge-based models. While SL models such as factorization machine [
8], neural factorization machine [
9], Wide&Deep [
10], and AutoInt [
11] are effective, they have limited capacity to explain recommendation outcomes. For instance, AutoInt is an SL model that identifies meaningful combination features through correlations between different feature fields [
11], yet it cannot reveal the individual characteristics of users. Thus, to provide more persuasive recommendations that take into account specific variable correlations for each user, this study utilizes the knowledge-based KGAT (knowledge graph attention network for recommendation) model [
6]. Other well-known knowledge-based models, such as CFKG [
12] and KGCN [
13], are considered, but the KGAT is selected as the primary model for this paper. The KGAT considers network information in its recommendations and employs a knowledge graph (KG), which is a heterogeneous graph capturing information about items and their attributes, to understand the mutual relations between entities [
2]. The KGAT possesses strengths in providing explainable and personalized recommendations.
This project not only proposes a new perspective on the B2B recommender system but also provides explainability for individual company recommendations through the attention mechanism from B2B transaction statements. Additionally, it suggests a performance improvement method through feature extraction and data preprocessing from B2B transaction data. This research offers new insights into the potential application of recommender systems in the B2B domain, enabling the analysis of big data transactions between companies. The main tasks of this study are summarized as follows: (1) proposing a new perspective on applying an explainable recommender system in B2B potential customer identification; (2) extracting features from B2B transaction statements that can be used in a knowledge graph; and (3) advancing keyword extraction techniques for trade items to improve modeling performance.
2. Theoretical Background
As data have become abundant, B2B has evolved to enable the recommendation of similar companies based on their purchase history. Unlike typical recommendation systems that recommend products to customers, this paper introduces a novel perspective in the B2B context by suggesting recommendations of potential customers to suppliers. This is because, in the B2B context, buyers are generally aware of the products they desire and make purchases under planned conditions, rendering product recommendations less essential [
3]. By recommending suitable potential customers to suppliers, these suppliers can identify future customers, and these potential customers can receive the desired products. This approach results in time savings for both parties. Furthermore, through data analysis utilizing deep neural networks, not only B2B experts but also non-experts can track recommendation outcomes to gain market insights. By analyzing a company’s transaction trends, it is possible to identify core transaction items and pinpoint popular products and potential areas for improvement.
In the context of B2B, characterized by substantial and crucial transactions, the looming potential for high risks underscores the necessity for robust recommendations to guide decision making. Thus, a recommendation algorithm capable of elucidating the rationale behind individual recommendations is essential. As a solution, the KGAT model is employed, which provides personalized and relevant recommendations by synergistically combining graph-based representation learning with the attention mechanism [
6]. The KGAT leverages the structured nature of a knowledge graph, encoding relationships between entities along with their attributes, such as transaction history, industry sector, and more. Through learning entity representations within the graph, the KGAT captures both the inherent characteristics of entities and the intricate interactions among them. This synergistic approach empowers the KGAT to deliver recommendations that are not only more accurate but also contextually aware. Upon comparing multiple recommendation models during this project, the KGAT provides a detailed rationale and demonstrates strong overall performance.
3. Related Work
3.1. B2B Recommender System
B2B recommendation systems have been the subject of several research papers. Among them, three papers have been selected for comparison. One paper introduces a framework for the system in B2B e-commerce [
4]. In contrast to this paper, the focus is on the system’s framework rather than the recommendation model itself. Additionally, while this paper focuses on recommending suppliers to buyers, it discusses the structure of recommending buyers to suppliers.
The second paper describes an item-based trust module, which is a variation of the collaborative filtering (CF) model [
5]. It calculates trust matrices for users and items and utilizes a hybrid prediction module to forecast user–item ratings. Unlike the current research, it constructs a B2B recommendation system using rating data from companies. Furthermore, this paper differs by not incorporating side information when retrieving candidate recommendations.
Finally, the third paper proposes a supplier-centric B2B recommendation system similar to the perspective of this research [
7]. However, its emphasis lies in recommending products that suppliers can offer to customers, rather than suggesting buyer companies. the third paper utilizes the co-clustering technique and relies on the past purchase history of customers to identify recommendation candidates. This research distinguishes itself from previous studies by aiming to provide a potential customer recommendation system in B2B using evidence-based approaches and incorporating side information within the model.
3.2. Recommendation Models
In this study, a comparative analysis is conducted among the KGAT, KGCN, AutoInt, and factorization machine (FM) models [
6,
8,
11,
13]. Among these models, the hypothesis is posited that the KGAT model would be particularly well-suited for the B2B dataset, and the empirical results validate this hypothesis.
The knowledge graph attention network (KGAT) is a deep learning recommender model that effectively utilizes interactions with a knowledge graph to generate personalized recommendations. The KGAT offers several advantages in recommendation tasks, including the ability to capture high-order connectivity and provide explanations for each company through the attention mechanism. The attention mechanism in the KGAT computes attention weights for entities and relations in the knowledge graph, allowing for a more precise modeling of their importance. Moreover, as the KGAT is built upon the architecture of graph convolution networks, it is well-equipped to deliver accurate predictions on the network structure present in the market transaction dataset.
Moving on to the KGCN model, this deep learning approach focuses on leveraging graph convolutional networks to capture and incorporate the structural information present in the knowledge graph. The KGCN aims to improve the recommendation performance by effectively utilizing the graph structure and its inherent relationships. The model exploits the power of graph convolutional layers to aggregate information from neighboring entities, enabling it to capture the complex interactions and dependencies within the B2B dataset. However, in contrast to attention mechanisms, it lacks the capacity to overtly elucidate rationales for individual recommendations.
AutoInt, on the other hand, is a model that combines deep learning with the attention mechanism to enhance recommendation accuracy. It employs self-attention mechanisms to capture the dependencies between different feature dimensions, enabling the model to effectively learn feature interactions and generate personalized recommendations. AutoInt offers the advantage of being able to capture both low-order and high-order feature interactions, which can be beneficial in the context of B2B recommendation systems, where complex relationships between features exist. Nevertheless, similar to the KGCN, it does not offer explicit explications for individual recommendation justifications.
Lastly, the FM model is a classic approach used in recommendation systems. It models feature interactions through factorization techniques, allowing it to capture both linear and non-linear relationships between features. FM is known for its efficiency and ability to handle sparse datasets, making it a popular choice in various recommendation scenarios. However, it exhibits limitations in modeling complex relationships and high-order interactions.
4. Overall Process of the KGAT Recommender System
The overall process of the KGAT model can be summarized in four parts: data preparation, collaborative knowledge graph (CKG) embedding layer, attention embedding propagation layers, prediction layer, and optimization. The following passages are a rephrased rendition of the content from the KGAT [
6].
The first step in building the KGAT model is to prepare the data, which involves creating a user–item bipartite graph and knowledge graph. These two graphs are then combined to form a hybrid structure called the collaborative knowledge graph (CKG).
Figure 1 illustrates an example of CKG. The user–item bipartite graph G1 represents the relationship between users
U and items
I, which is defined as
, where
if a link exists between them [
6]. In contrast to the typical B2C recommendation system data, this paper considers users as suppliers and items as buyers. The knowledge graph typically illustrates the relationship between item
I and its side information
e. KG
is represented as a set of triplets
, where head entity
h and tail entity
t can represent either an item or side information, and
r denotes the relationship between them [
6]. In the context of B2B data,
I represents buyers, while side information about them is represented as
e. Then, CKG is a unified graph that merges the user–item bipartite graph and KG. So, CKG is represented as
, where
is the union of
E and
U, and
includes the interaction relation [
6].
The second step is to create the collaborative knowledge graph (CKG) embedding layer, which involves learning low-dimensional representations of the nodes in CKG by utilizing graph-embedding techniques. This step helps to capture the interactions between users, items, and their side information in the low-dimensional space. In the KGAT, TransR is employed as the graph-embedding technique [
14]. TransR is a technique that uses distinct embedding spaces for entities and relations within a knowledge graph, taking into account their unique properties and characteristics. The embedding for
and
t is expressed as
and
. With the given triplet
, one of the objective functions is as follows:
Here,
, and
represents a broken tail that is obtained by randomly replacing one of the entities in a valid triplet [
6].
is the parameter matrix for relation
r. This matrix helps the model to incorporate the relation information into the learned representations.
is the sigmoid function. This sigmoid function compresses the input value to a range between 0 and 1. The function penalizes the model when the triplet in the knowledge graph is not true, with the degree of penalty being determined by a pairwise ranking loss in Equation (
1). The model adjusts its parameters to minimize this loss function, thereby enhancing the performance of the recommender system.
After applying TransR, the KGAT utilizes the attentive embedding propagation layers to recursively propagate the learned embeddings to other entities in the graph. The embeddings learned in the previous step are utilized to update the embeddings through the attentive propagation layer. This enables the KGAT to learn high-order relations and capture the complex structural information of KG [
6]. To consider the first-order connectivity of entity
h, it is computed by the linear combination of
:
where
is a triple neighbor set for entity
h. The KGAT applies the relational attention mechanism via implementing
.
represents the attention weights, indicating the importance propagated from
t to
h under the condition of relation
r. The expression of
is normalized using the softmax function:
is composed of
, and the detailed formula is as follows:
The tanh function is chosen as the nonlinear activation function, and the attention weights are assigned using the inner product method with learnable parameters
. Next, the entity representation
and its ego-network representations
are combined to create a new representation of entity
h [
6]. This is expressed as
, where the bi-interaction aggregator is utilized as
in this paper:
High-order propagation involves stacking propagation layers to create multiple stacks, where the lth steps can be expressed as .
In the prediction layer, the KGAT utilizes the layer-aggregation mechanism to concatenate the representations of each step into one vector. And then, the prediction of the matching score between a user and item is achieved via an inner product of their corresponding representations:
The final objective function of the KGAT comprises two loss functions. One of the loss functions is used to learn Equation (
1), while the other loss function is defined as follows:
Set
O contains triples
, where
belongs to the set of observed interactions between user
u and item
i, and
belongs to the set of unobserved interactions. The activation functions is the sigmoid function. The final objective function with L2 regularization is as follows:
Two loss functions are alternatively optimized during the training process. The loss function
, as expressed in Equation (
1), is used to optimize the structural embedding from KG. On the other hand,
is utilized to optimize the pairwise ranking from KG [
6].
7. Conclusions and Future Work
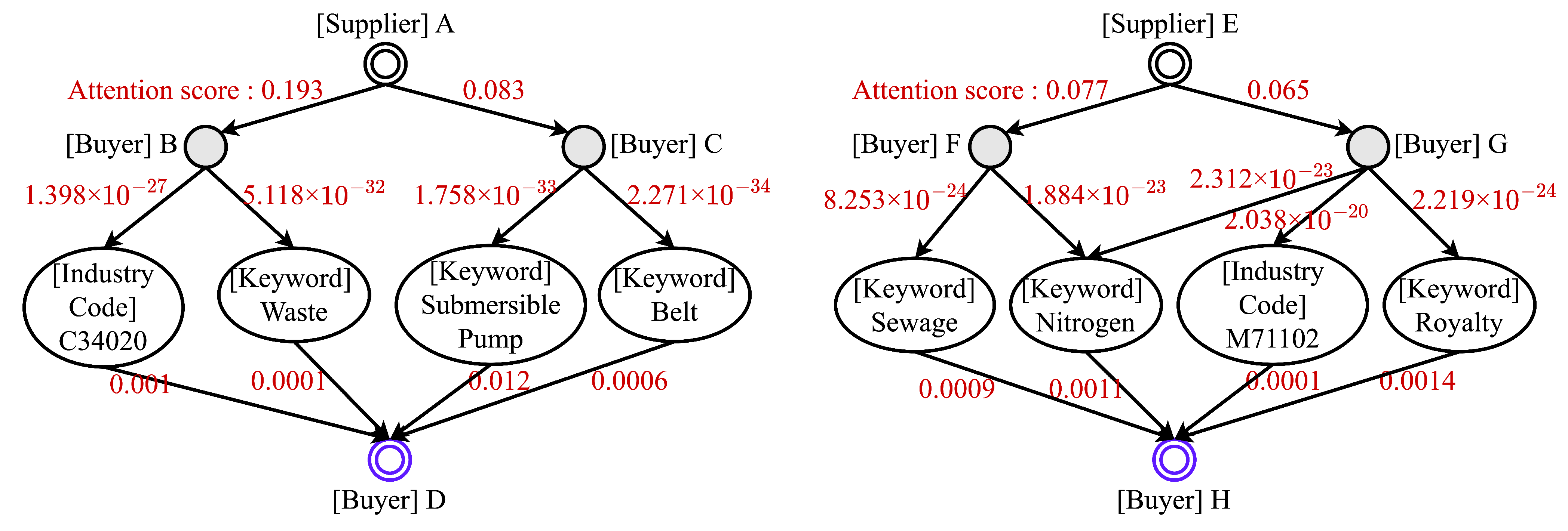
This work introduces a new framework for a B2B recommender system with the goal of identifying potential prospects in the B2B domain. Various recommendation algorithms are considered, and the KGAT is found to perform well. Additionally, a buyer’s knowledge graph is introduced, incorporating features, such as traded item names and industry codes of buyers and suppliers, for potential customer identification. A new word extraction process is also proposed to improve performance. Furthermore, the visualization of the attention mechanism provides insights into the reasons behind the recommendations, which can be valuable for marketing and sales teams. They can utilize the visualization to identify similar companies and understand buyer interests. This study represents a novel attempt to showcase the scalability of the recommender system in the B2B domain. It is anticipated that this research will assist B2B supply companies in identifying potential customers.
To further advance this study, there are several aspects that should be taken into consideration. Firstly, it is crucial to tackle the performance drop of the KGAT with increasing triples. Efficient graph learning and embedding strategies can play a vital role in optimizing performance. Moreover, to further extend the potential of the KGAT model, the incorporation of additional side information from users could be explored. For instance, integrating supplementary details, such as user interests, into the model can provide more sophisticated recommendations. Additionally, the efficiency of the KGAT model is substantially dependent on the quality and availability of the fundamental knowledge graph and data. Hence, focusing on improving data quality and reducing noise can significantly enhance performance. Considering these avenues of development, the KGAT model can evolve into a more effective and accurate B2B recommendation system.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}