1. Introduction
Computer vision is widely used in autopilot systems, unmanned aerial vehicles, intelligent manufacturing, augmented reality and other fields. In environments where human work is limited, computer vision can help with recognition and detection. As a type of computer vision technology, binocular vision uses binocular cameras to estimate depth based on stereo matching, and then obtains the three-dimensional information of the surrounding environment through the obtained depth information. It has high accuracy, a low cost and a small size and is suitable for complex environments. Binocular vision can be flexibly applied to intelligent robots, unmanned aerial vehicles and other equipment.
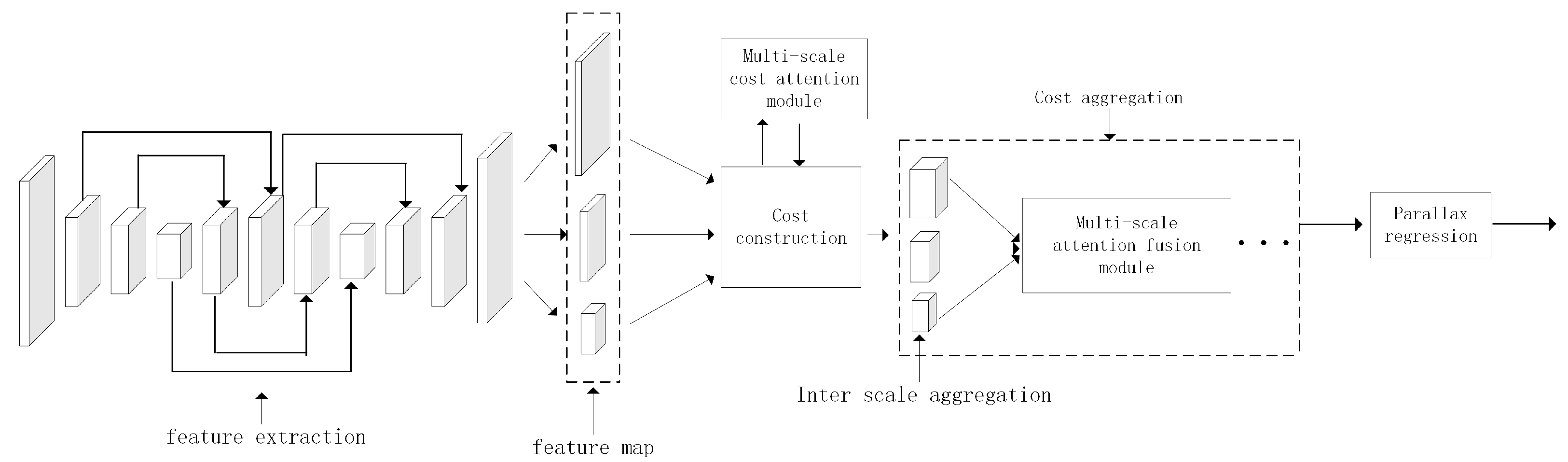
In recent years, compared to traditional methods, binocular stereo matching methods based on deep learning have seen great improvements in accuracy and speed. Among these methods, the single-scale method constructs a single cost volume based on the characteristics of a single-resolution image. This method processes a single cost volume and requires the use of 3D convolution in convolutional neural networks to improve its accuracy. However, the use of 3D convolution will increase the number of parameters in the model, resulting in reduced model speed. However, multi-scale methods, which fuse or process the images or cost volumes of different resolutions, can not only provide rich feature information for matching pixel points, but also be used in cost aggregation to improve the efficiency of matching costs. The multi-scale method combined with 2D convolution can obtain multi-scale information and aggregate the matching costs of multiple scales, achieving better results. Moreover, 2D convolution requires fewer parameters and has a small impact on model speed. However, using multi-scale methods to improve the robustness of the edges of objects and areas affected by illumination in real scenes, thus helping to better identify objects in subsequent 3D reconstruction tasks, remains a difficult problem to be solved by multi-scale methods. Therefore, investigations into multi-scale binocular stereo matching methods based on convolutional neural networks have high research value and significance. The research content and contributions of this article are as follows:
(1) Improvements have been made to the multi-scale model AANet+ [
1], and experiments have been conducted on Scene Flow datasets and other real scene datasets. The experimental results show that the proposed model significantly improves the disparity in robustness compared to the benchmark model.
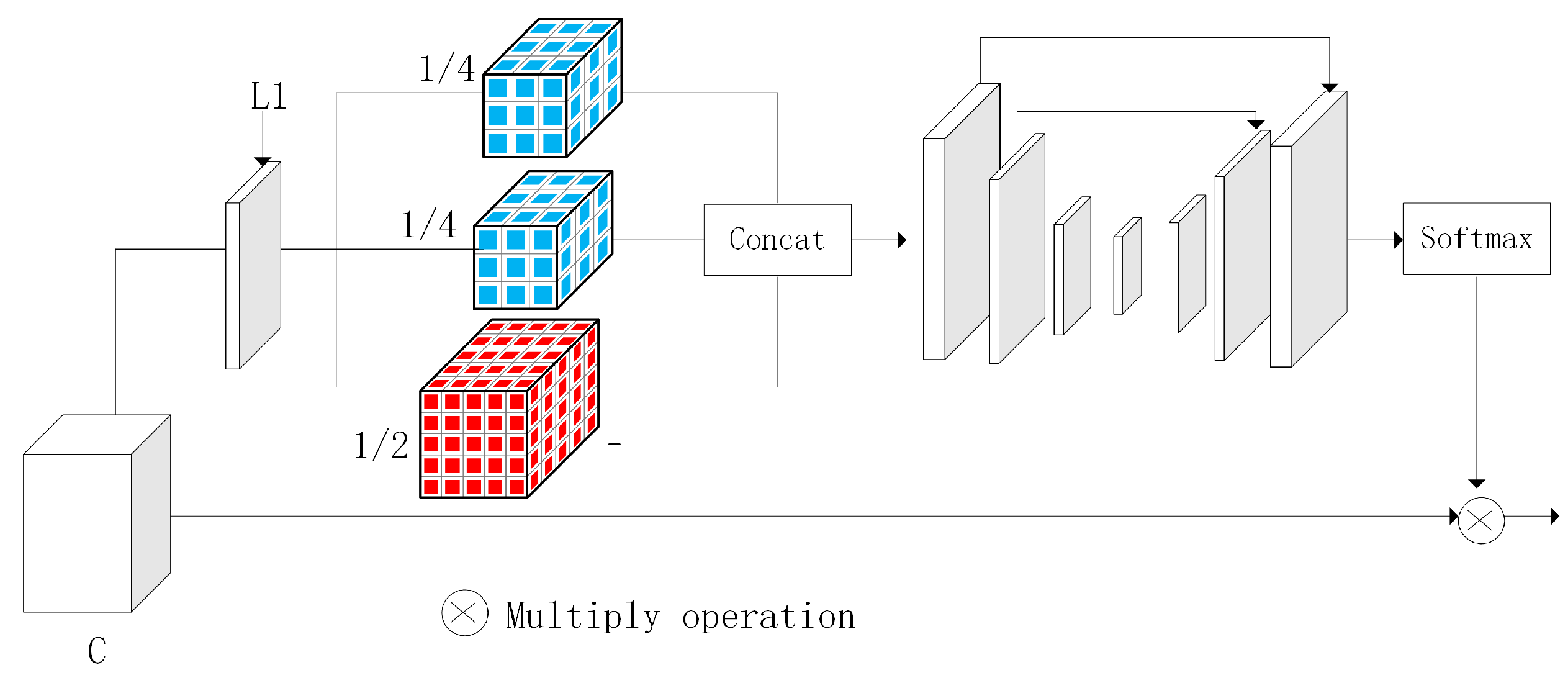
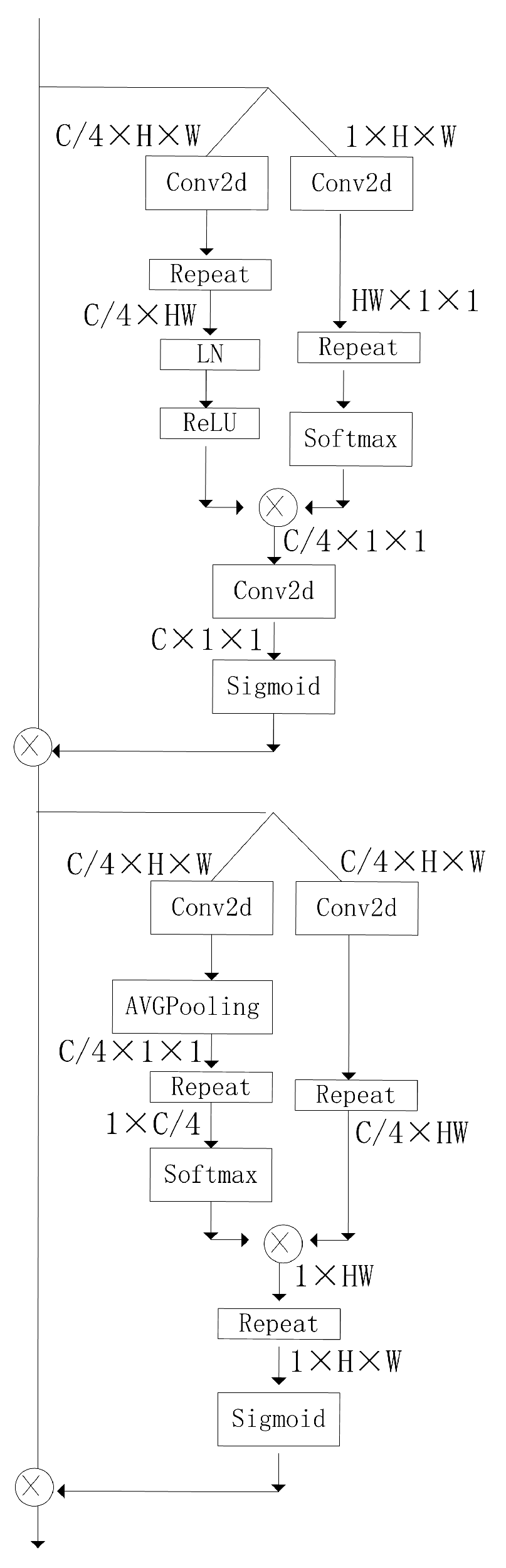
(2) Addressing the problem of low prediction disparity robustness in areas affected by light in real scenes in multi-scale stereo matching methods, a multi-scale cost attention module is added to suppress the redundant information and focus on areas affected by light.
(3) Addressing the problem of information loss caused by cross-scale fusion in multi-scale stereo-matching methods, an adaptive fusion structure is designed that utilizes a polarization self-attention mechanism to generate attention and fuse the attention with cost volumes to reduce information loss.
Based on the above, the research motivation in this article is mainly to reduce disparity errors in areas affected by light in disparity maps, and make contributions to subsequent 3D reconstruction tasks.
2. Related Works
Stereo-matching methods based on deep learning can be divided into single-scale stereo matching methods and multi-scale stereo matching methods according to the processing methods for different resolution cost volumes. Stereo matching based on multi-scale methods has been proven to improve the robustness of weakly or non-textured regions in disparity images. Inspired by traditional multi-scale stereo matching, Zhu et al. combined multi-scale methods with 3D convolution to obtain multi-scale features through multi-scale feature extraction and used cross-space pyramids to aggregate context information, improving the accuracy of multi-scale methods [
2]. Inspired by image segmentation algorithms, Alex et al. proposed GC-Net [
3], which uses a concatenation method to aggregate feature images obtained from feature extraction, concatenates left and right feature images to obtain cost volumes and uses a multi-scale method to aggregate cost volumes using 3D convolution to improve the accuracy of disparity maps. In order to effectively fuse multi-scale context information, Wu et al. proposed SSPCV-Net [
4], which uses a recursive method to upsample low-resolution cost volumes, utilizes a 3D aggregation module to extract the multi-level features of cost volumes, gradually completes the fusion of multi-scale cost volumes and finally obtains a more accurate disparity map through disparity regression.
Shen et al. proposed that in the downsampling stage of the cost volume aggregation module, the cost volumes of different scales are directly fused, reducing the number of 3D convolutions used and preserving the disparity information for the cost volumes of different scales [
5]. However, this method fails to adjust the disparity search range in a timely manner, and the generalization ability of the model needs to be improved. For this reason, Shen et al. proposed CFNet [
6], which uses a multi-scale cost volume fusion method to fuse the cost volumes of different scales as initial cost volumes, obtaining an initial disparity map and then using a cascade method to adjust the disparity search range for uncertainties in the initial disparity map. The resolution of the disparity map is thus gradually improved and refined. This method effectively integrates multi-scale information and improves the generalization ability of the model.
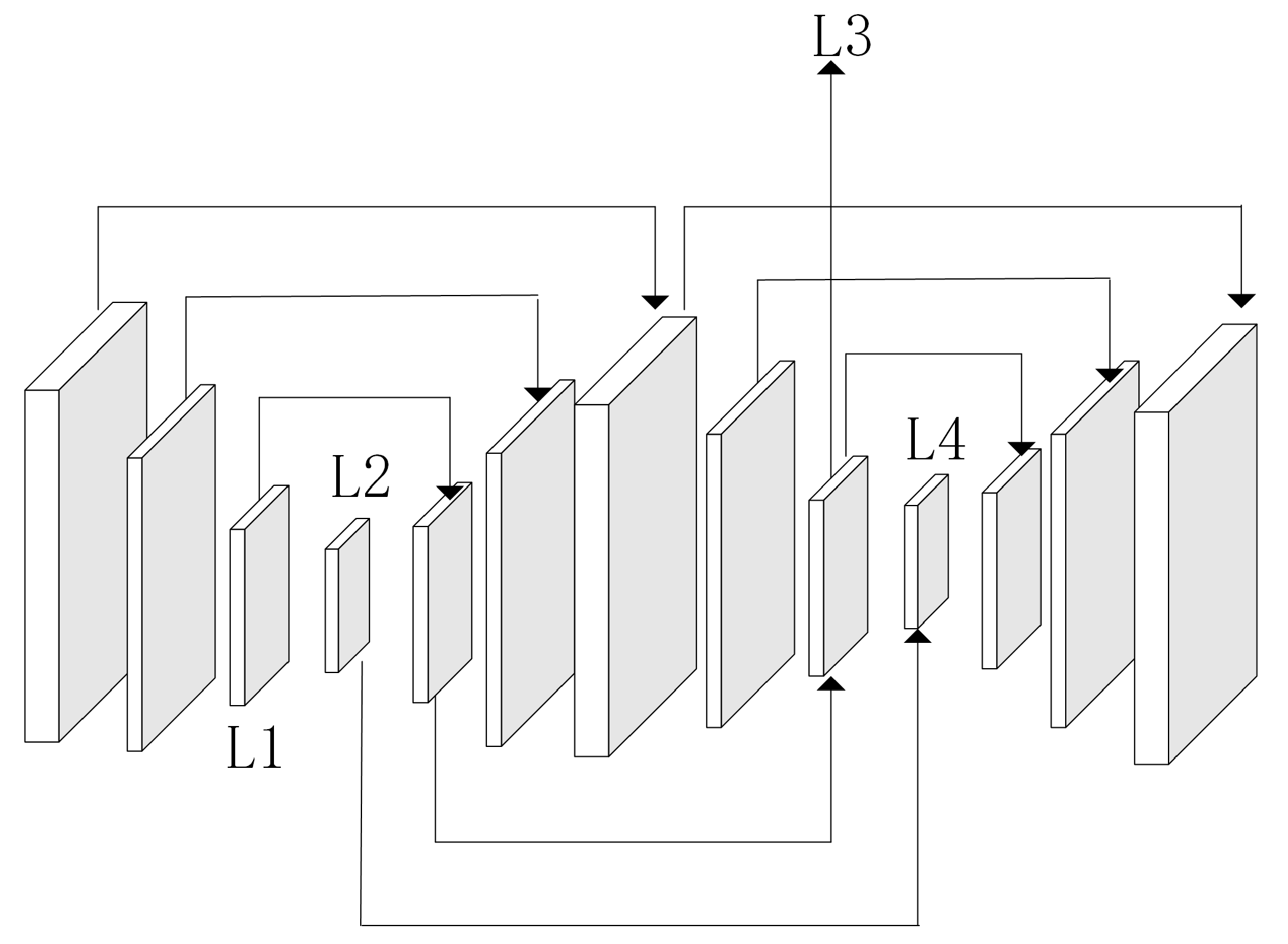
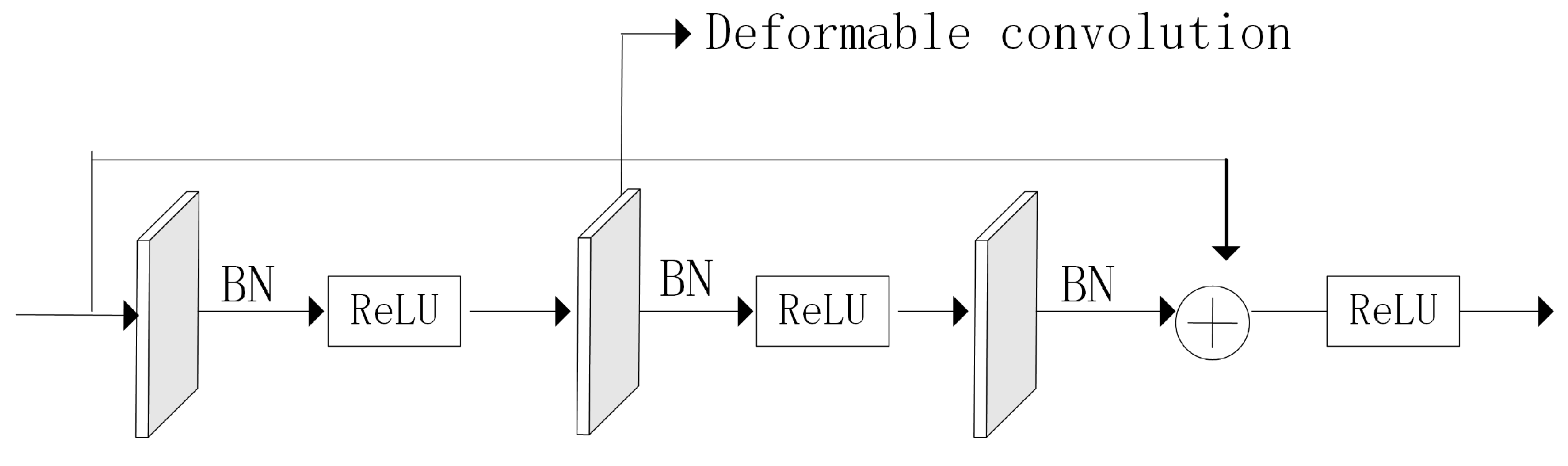
When the above multi-scale method is used in combination with 3D convolution, the model’s speed is slow due to the large number of parameters. In order to improve the prediction effect of the multi-scale method in weak and non-textured regions and to improve the speed of the model, Xu et al. proposed AANet [
1], in which 2D convolution is used to establish a stereo matching network, and a multi-scale method is used to aggregate cost volumes. Deformable convolution is added to the network to achieve an adaptive effect on the model. Two cost-aggregation modules are proposed: cross-scale cost aggregation and intra-scale cost aggregation. This method balances the speed and accuracy of the model well. Li [
7] and Jia [
8] proposed two model structures, respectively. Their common feature is the use of an hourglass structure composed of 2D convolutions to aggregate multi-scale cost volumes, thereby reducing computational complexity and balancing the accuracy and speed of the model. Syed et al. [
9] used multi-scale distortion features to estimate the disparity and minimize the disparity search range in the cost volume. They used a refined structure composed of 2D convolutions to process the disparity maps, reducing computational complexity while maintaining accuracy. Although the above network model achieves good balance between the accuracy and speed of stereo matching models, multi-scale information cannot be effectively fused, and its robustness is low in certain areas, such as object edge areas, foreground areas and occlusion areas.
In order to solve the problem of the high error match at the edges of multi-scale methods, Xue et al. used lightweight 2D and 3D multi-scale aggregation modules to aggregate low-resolution cost volumes and utilized multi-scale RGB image guidance for upsampling, improving the disparity robustness at the edges. However, the prediction effect on blocked areas and areas affected by lighting in the image is poor [
10]. Yang et al. designed RDNet [
11] to design a separate branch to learn edge information. Guided by edge information, RDNet improves the robustness of boundaries in disparity maps, and combines multi-scale methods to improve the accuracy of disparity maps. Jeon et al. [
12] combined a multi-scale fusion structure with a cross-scale fusion function, using a staggered cascade method to combine the cost volumes of different scales. Finally, an adaptive cost volume loss function was used to estimate the cost. This method improves the disparity accuracy of the edges. Zhang et al. [
13] proposed fusing low-level and high-level features to preserve image edge information, and designed a multi-scale cost aggregation module to extract rich global context information, reducing dependence on local information. Unlike HFMANet [
13], Li et al. [
14] designed a multi-channel group by group correlation method to construct cost volumes, and then used an adaptive cost aggregation method to regularize cost volumes from different scales through intermediate supervision. These two methods are helpful for disparity estimation in weak texture areas. Tao et al. [
15] designed a stereo matching network with confidence perception unimodal cascaded and fused pyramids, using confidence graphs to construct a unimodal cost distribution to narrow the disparity search range. Then, a cross-scale interactive aggregation module is designed to fully utilize multi-scale information. This method improves the disparity robustness of occluded areas in disparity maps. Most of the methods mentioned above focus on the low robustness of edges and weak texture areas. However, in real scenes, objects are easily affected by light and become difficult to estimate disparity. Therefore, this paper proposes a multi-scale cost attention and adaptive fusion structure, which alleviates the problem of low disparity robustness in illuminated areas in real-scene datasets using multi-scale methods. In the Scene Flow dataset, the method proposed in this article further reduces endpoint errors and improves disparity robustness in non-textured regions and small structures.
4. Experiments and Result
4.1. Datasets
Middlebury: The Middlebury [
29] dataset consists of four datasets, including data from 2001, 2003, 2005, 2006, 2014 and 2021. The latest dataset was proposed by Literature 66 and was captured by Middlebury College using a mobile device on a robotic arm. The latest dataset can be divided into 3000 × 2000 resolution, 1500 × 1000 resolution and 750 × 500 resolution.
Scene Flow: The Scene Flow dataset is a 3D composite dataset, subdivided into the FlyingThings3D dataset, Driving dataset and Monkaa dataset. The Scene Flow dataset has a total of over 30,000 pairs of training images, with a pixel size of 540 × 960, which contain abundant training samples and dense disparity maps. It has become a mainstream pre-training dataset in recent years.
KITTI: The KITTI dataset is a real road scene dataset collected by an international team through mobile vehicles using laser radar to obtain image depth information and convert it into disparity. Therefore, the disparity value obtained is relatively accurate. The dataset contains a total of over 300 pairs of images, including KITTI2012 and KITTI2015. The KITTI2012 and KITTI2015 datasets use 154 image pairs and 160 image pairs as training sets, respectively.
4.2. Experimental Setting
This experiment uses the Python framework, and the construction of the network environment and the training process in the experiment are run on the server configured as an NVIDIA Tesla T4 GPU. In this paper, four datasets are used for the experiment, namely Scene Flow, Middlebury, KITTI2015 and KITTI2012. For the Scene Flow dataset, this experiment was inspired by ACVNet and trained three times. First, the multi-scale adaptive cost attention was trained, and then the weight of the attention obtained from the training was frozen for the second training. The second training combined the multi-scale adaptive attention structure with the backbone network, and the obtained training parameters were saved. Finally, the weight obtained from the second training was trained with the final network and the final stereo matching network was obtained. The purpose of the three training sessions was to obtain a multi-scale cost attention with high accuracy and keep it intact, so that the model can improve its accuracy on ill-posed areas in the disparity map after applying the multi-scale cost attention, such as the areas affected by light and small areas.
In the Scene Flow dataset, the image is randomly cut to a 288 × 576 resolution, and a verification set size of 540 × 960 resolution is set with an initial learning rate of 0.001 and an epoch of 64 and optimized using the Adam optimizer
. After the 20th epoch, the learning rate is reduced to once every 10 epochs. For the KITTI2012 dataset, this experiment uses the pre-training model generated by the Scene Flow dataset for training and fine-tunes the model parameters. However, for the KITTI2015 and KITTI2012 datasets, the same strategy as that in [
1] is adopted for disparity prediction; that is, the true value of disparity is used as supervision to improve the accuracy of the model in this dataset. The maximum disparity is set to 192. In this paper, the model generalization experiment is carried out in the Middlebury dataset. The pre-training model in the Scene Flow dataset is used to test directly on the Middlebury dataset. The resolution of the image is one-quarter of the resolution.
4.3. Experimental Results Analysis
Ablation Study
In order to verify the effectiveness of the network modules mentioned in this paper, an ablation experiment was carried out on the Scene Flow dataset. The models’ designs were compared, and four schemes were used to evaluate the proposed model.
The first scheme is the training reference network, and the resulting endpoint error is 0.831. The percentage of difference outlier (D1) is 0.340, the proportion of pixels with a prediction error greater than 1PX is 0.0880, the proportion of pixels with a prediction error greater than 2PX is 0.0534 and the proportion of pixels with a prediction error greater than 3PX is 0.0405.
The second scheme is to train the network with multi-scale cost attention, and the resulting endpoint error is 0.776. The percentage of difference outlier (D1) is 0.304, the proportion of pixels with a prediction error greater than 1PX is 0.0918, the proportion of pixels with a prediction error greater than 2PX is 0.0509 and the proportion of pixels with a prediction error greater than 3PX is 0.0368. When the multi-scale cost attention is added separately, the key information in the cost volume is focused, and the redundant information is reduced, so all errors are greatly reduced.
The third scheme is to train the network model with multi-scale adaptive fusion, and the resulting endpoint error is 0.783. The percentage of a difference outlier (D1) is 0.332, the proportion of pixels with a prediction error greater than 1PX is 0.0908, the proportion of pixels with a prediction error greater than 2PX is 0.0516 and the proportion of pixels with a prediction error greater than 3PX is 0.0386. When the adaptive fusion module is added separately, it reduces the loss of price information in the cross-scale aggregation of the network model, so the error decreases.
The fourth scheme is the network proposed in this chapter, and the resulting endpoint error is 0.664. The percentage of difference outlier (D1) is 0.227, the proportion of pixels with a prediction error greater than 1PX is 0.0638, the proportion of pixels with a prediction error greater than 2PX is 0.0369 and the proportion of pixels with a prediction error greater than 3PX is 0.0271.
The results of the whole ablation experiment are shown in
Table 1, where D1 represents the pixel proportion of the first frame image prediction error, and 1PX, 2PX and 3PX represent the errors of the pixel points. The values of these four indicators are in the form of percentages. From the table, we can see that the network proposed in this paper has the lowest error in the ablation experiment.
4.4. Generalization Study
The visualization results are as follows:
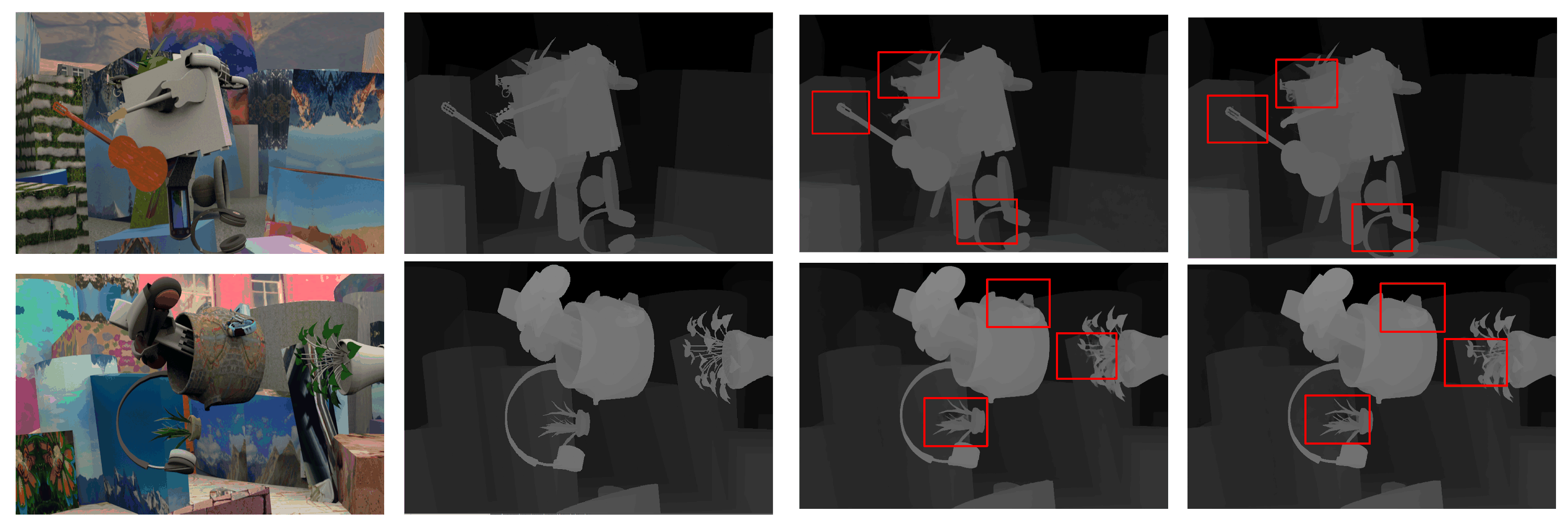
In
Figure 7, the first column is the original image, the second column is the predicted disparity map for AANet+ and the third column is the predicted disparity map for MCAFNet. As can be seen from the figure, MCAFNet has a low mismatch rate in non-textured areas such as chairs and human faces.
Addressing the generalization performance of the proposed model, a generalization experiment is carried out in the Middlebury [
29] dataset. For the generalization experiment, both the model in this paper and the benchmark network model adopt the pre-training model of the Scene Flow dataset, and the comparison index is the percentage of pixels with errors larger than 2 pixels (Bad2.0), that is, the error ratio is under 2 pixels. As shown in
Table 2, although the speed difference between the proposed network and the benchmark network model AANet+ is 0.05 s, the error matching rate of MCAFNet is 20% lower than AANet+.
4.5. Comparative Experiment
4.5.1. Comparative Experiments on the Scene Flow Dataset
For the Scene Flow dataset,
Table 3 reflects the quantitative evaluation results of this network and GC-Net, PSM-Net, AANet and AANet+. The evaluation indicators used in this paper are the end point error (EPE) and time. For the Scene Flow dataset, we can see from
Table 3 that the MCAFNet method proposed in this paper has better accuracy. Compared with AANet, the difference in speed of the network proposed in this paper is 0.15 s, and only 0.05 s compared with the reference network AANet+. Compared with other 3D convolution-based network models, namely PSM-Net and GC-Net, the speed of the network proposed in this paper is 48% and 76% higher, respectively. In terms of accuracy, the end point error of the network mentioned in this chapter is approximately 20% lower than that of AANet+. Compared with the PSNet and GCNet network models, the precision of the network proposed in this paper decreased by 39% and 73%, respectively.
On the Scene Flow dataset, the proposed network is visually compared with the reference network model AANet+. The visual comparison results are shown in
Figure 8. It can be seen from the red box in
Figure 8 that, compared with AANet+, MCAFNet’s predicted disparity map is closer to the true disparity map. Compared with the reference network, it improves the accuracy in the case of a small speed difference.
4.5.2. Comparative Experiments on the KITTI2012 Dataset
In this paper, the evaluation indicators provided by the KITTI dataset are used for comparison. The comparison indicators of the KITTI 2012 dataset are the non-occluded area error (Noc) of 2PX(pixel), 3PX (pixel) and 5PX (pixel) and all area errors (All). It can be seen from
Table 4 that, compared with AANet+, the error of MCAFNet in the non-occluded area on the KITTI2012 dataset is significantly reduced. Under the evaluation indicators of 2, 3 and 5 pixels in all areas, the error of the network mentioned in this paper is reduced by 0.35, 0.07 and 0.04, respectively, which proves that the prediction of disparity of the network mentioned is more accurate than that of the reference network. Compared with GCNet and ERSCNet, MCAFNet has a good performance in error matching rate in the comparison results of 3 pixels and 5 pixels. At 3 pixels, the Noc mis-matching rate decreases by 9.6% and 11%, respectively. With the exception of SegStereo [
31], iResNet-i2 [
32] and MSDCNet [
33], the network in this paper has the lowest Noc and All mismatch rates compared with the remaining network models.
The comparison results of this model with AA-Net+ and iResNet-i2 on the KITTI2012 dataset are shown in
Figure 9. The comparison results are provided by the KITTI dataset. In
Figure 9, the first line is the original map, the second line is the iResNet-i2-predicted disparity map and the third line is the AANet+-predicted disparity map. The fourth line is the GCNet-predicted disparity map. The fifth line is the AANet-predicted disparity map. The sixth line is the prediction disparity map of the network proposed in this paper. It can be seen from the red box mark in the error map that, compared to other multi-scale methods, our proposed model can better predict disparity in the illuminated area.
4.5.3. Comparative Experiments on the KITTI2015 Dataset
The comparison results of this model and AA-Net+ on the KITTI2015 dataset are shown in
Figure 10. The comparison results are provided by the KITTI dataset. In
Figure 10, the first line is the original map, the second is the predicted disparity map of AANet+. The third line is the error diagram of GCNet. The fourth line is the error map of AANet, and the fifth line is the error map of our proposed model network. From the red box mark in the figure, compared to other multi-scale methods, our proposed model can better predict disparity in the illuminated area.
The evaluation index provided by the KITTI2015 dataset is used for comparison. The comparison index of the KITTI2015 dataset is the proportion of predicted error pixels in the foreground area (D1 fg), background area (D1 bg) and all areas (D1 all) in the first frame of the image. It can be seen from
Table 5 that compared with BGNet [
34], FADNet [
35] and AA-Net+ in the KITTI2015 dataset, the network in this paper has a good performance in the false matching rate of the background area and all areas in the first frame of the image. Compared with the reference network AANet+, the false matching rate of all areas has decreased by 2.6%. Compared with PSMNet, the mismatch rate of all regions decreased by 4.3%. MCAFNet has the lowest error matching rate in the background area and all areas in the first frame of the image.
5. Conclusions
With the aim of addressing the problem of cost construction using 2D convolution, a multi-scale cost attention and adaptive fusion network based on AANet+ is proposed. The network inputs the initial cost volume obtained from cost construction into the multi-scale cost attention structure, and multiplies the obtained cost attention with the initial cost volume, reducing redundant information and improving the accuracy of the initial cost volume. The network improves the cross-scale aggregation in cost aggregation. It improves the addition to multi-scale attention fusion, adds an attention mechanism, enriches multi-scale cost information and improves the efficiency of cross-scale cost aggregation. Our experiments show that the end point error of the proposed network in the Scene Flow dataset is 39% and 73% lower than those of PSMNet and GC-Net, respectively. The end point error of our proposed network is 20% lower than AANet+, and the error matching rates in the KITTI2012 and KITTI2015 datasets are 1.60% and 2.22%, respectively. Compared with the reference network, the proposed network improves the robustness of the areas affected by light in real scenes.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}