


Music Emotion Recognition Based on a Neural Network with an Inception-GRU Residual Structure
Abstract
:1. Introduction
2. Related Work
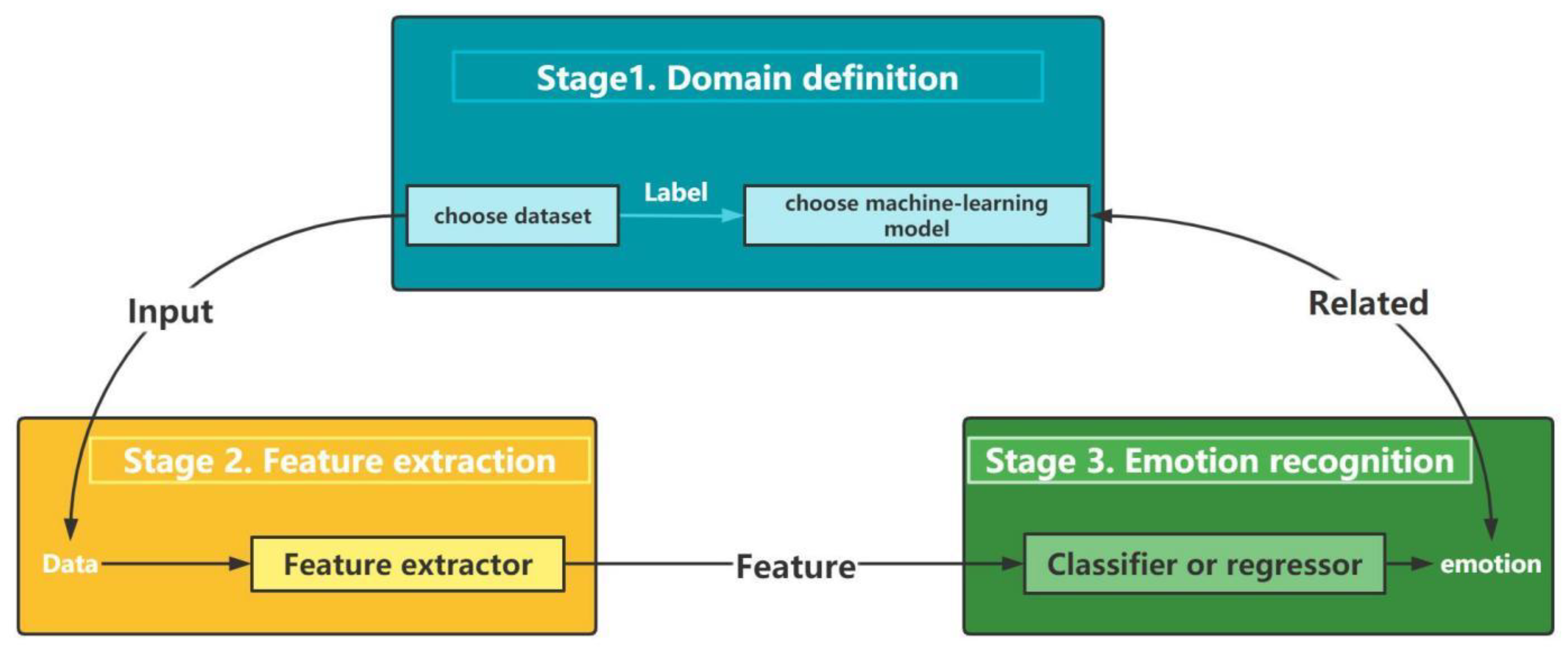
3. Methodology
3.1. Pre-Processing
- Cut the audio into 30-s clips.
- Perform STFT for the music clips to produce two-dimensional spectrograms.
- Use the logarithm of the resulting spectrogram to highlight features and feed more prominent factors into the neural network.
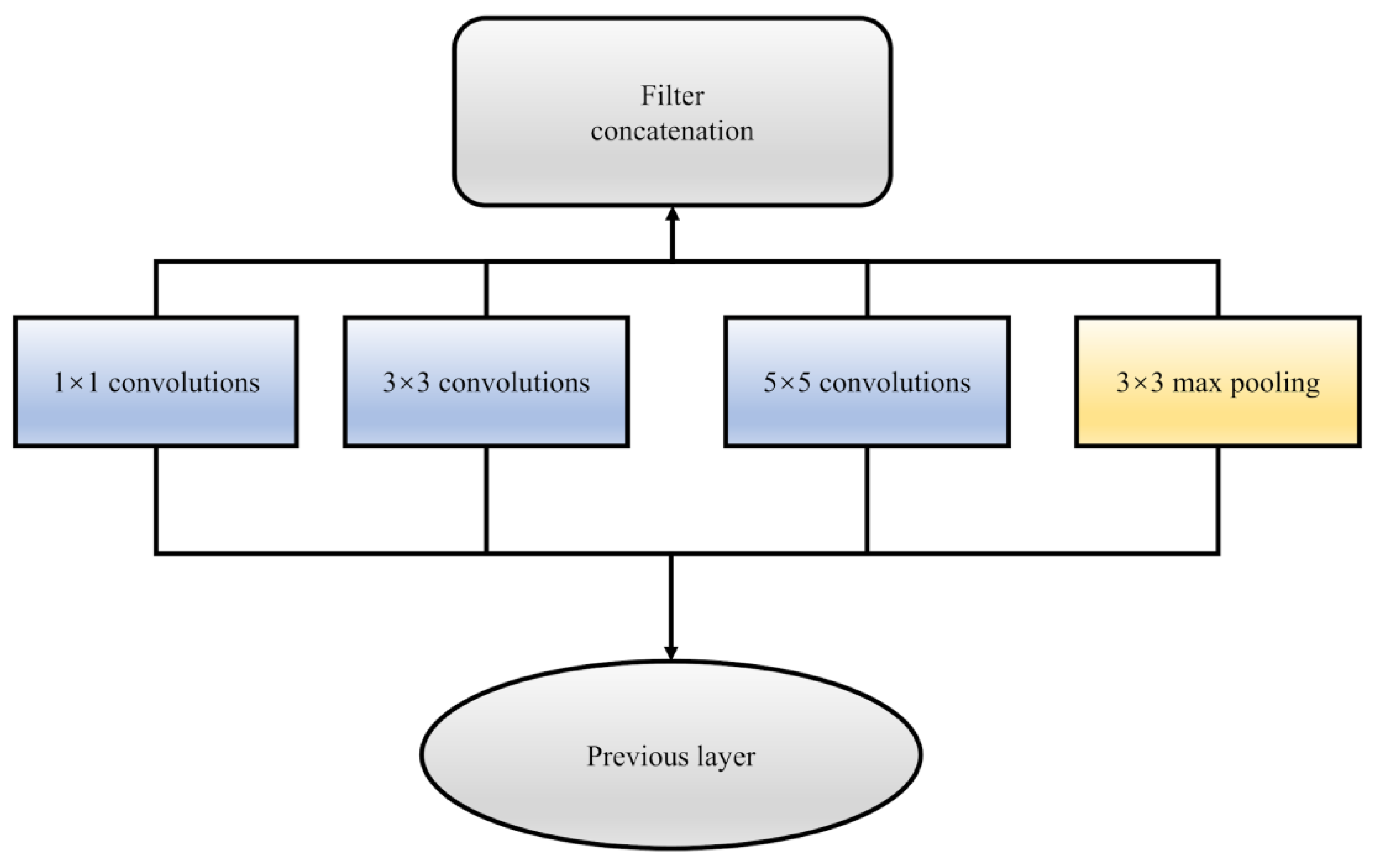
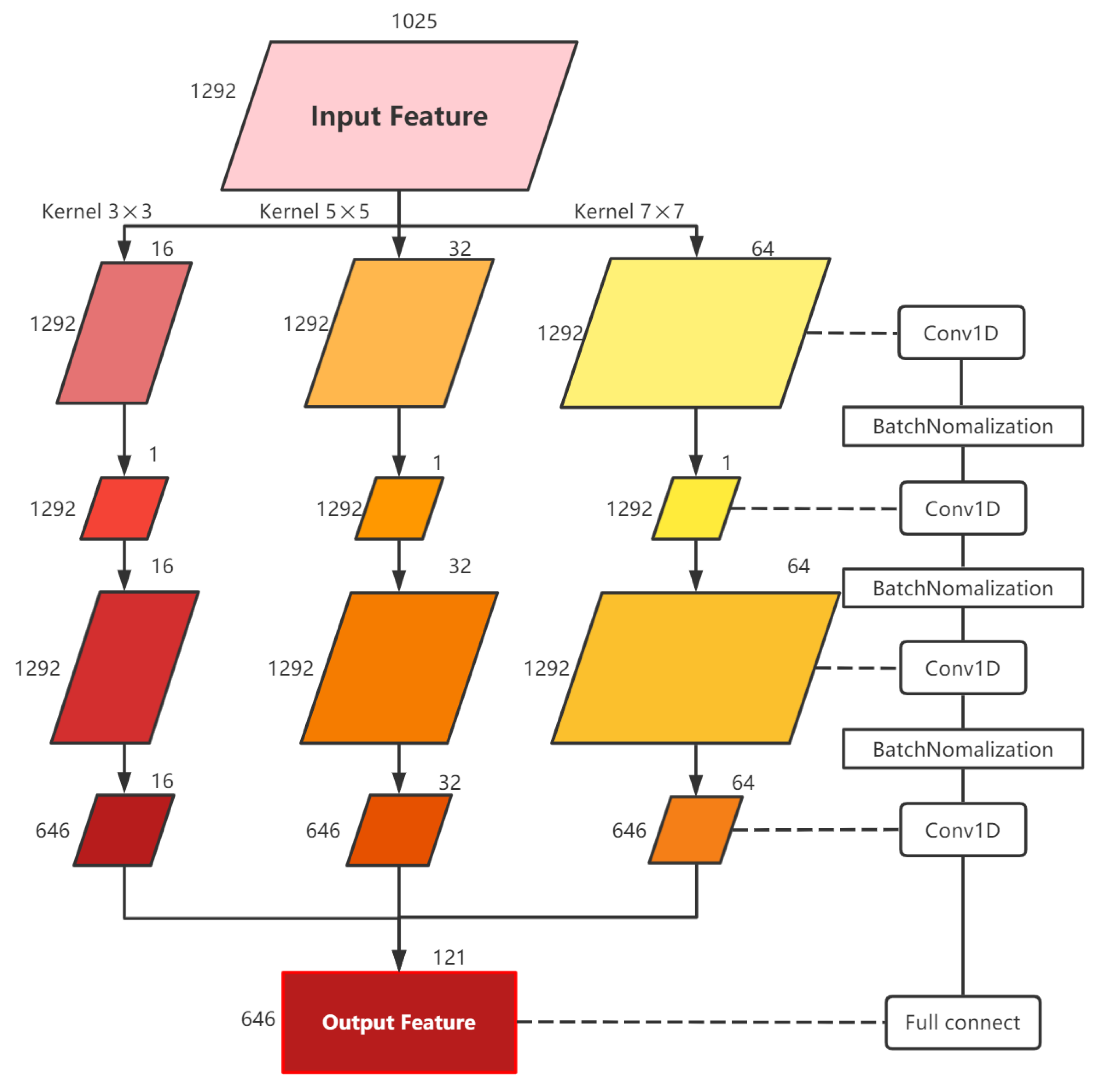
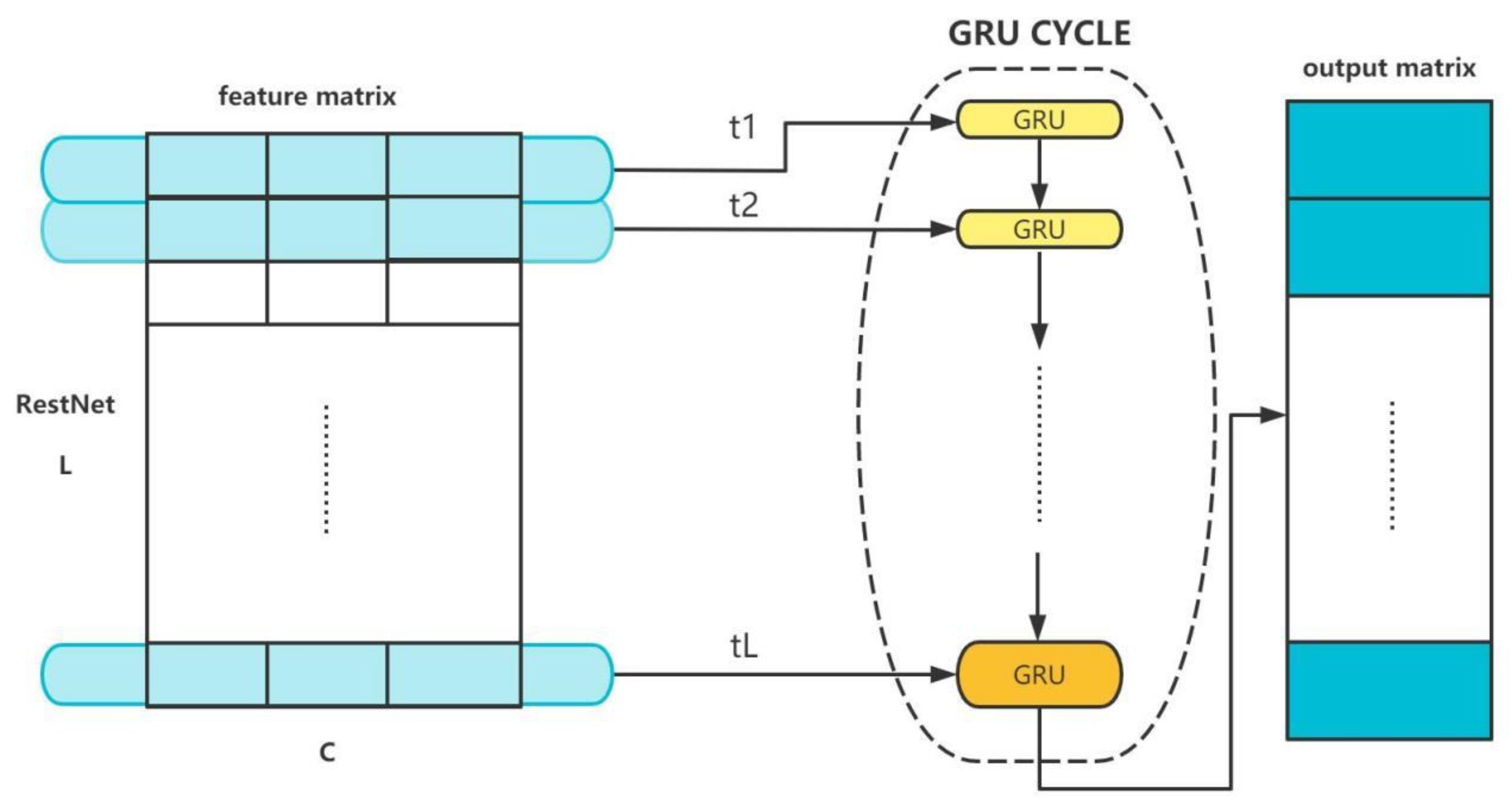
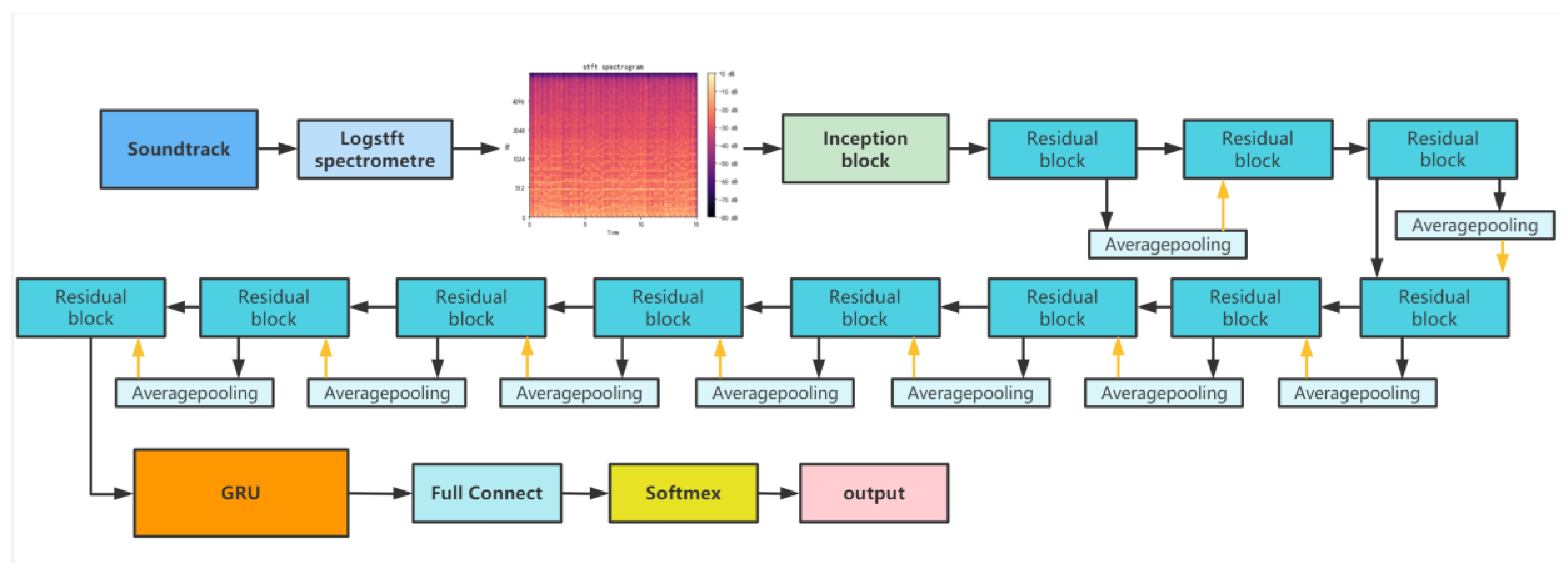
3.2. Network Structure
- obtain the mean of data in each training batch;
- obtain the variance of data in each training batch;
- normalize the batch of training data using the computed mean and variance to obtain a (0,1) normal distribution;
- conduct scale transformation and offset to obtain the distribution that best reflects the characteristics of the training samples.
- 1D CNN: it is suitable for processing time series signals of music;
- adjusted Inception structure: It gets adjusted based on InceptionV1;
- the feature expansion-compression-expansion steps can effectively preserve the main features while guaranteeing the mining of valid feature information;
- parallel use of multiple optimized Inception structures to achieve multiple expansion-compression-expansion paths in parallel and extend the diversity of features;
- 1D residual structure: It avoids gradient vanishing of the deep network;
- combination with GRU model: It is used to deal with time series music signals and retain valid features through gating.
4. Experiment Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- He, N.; Ferguson, S. Multi-view neural networks for raw audio-based music emotion recognition. In Proceedings of the 2020 IEEE International Symposium on Multimedia (ISM), Naples, Italy, 2–4 December 2020; pp. 168–172. [Google Scholar]
- Jeon, B.; Kim, C.; Kim, A.; Kim, D.; Park, J.; Ha, J. Music Emotion Recognition via End-to-End Multimodal Neural Networks. In Proceedings of the RecSys ’17 Poster Proceedings, Como, Italy, 27–31 August 2017. [Google Scholar]
- Huang, C.; Zhang, Q. Research on Music Emotion Recognition Model of Deep Learning Based on Musical Stage Effect. Sci. Program. 2021, 2021, 3807666. [Google Scholar] [CrossRef]
- Wu, Z. Research on Automatic Classification Method of Ethnic Music Emotion Based on Machine Learning. J. Math. 2022, 2022, 7554404. [Google Scholar] [CrossRef]
- Sun, M. Study on Antidepressant Emotion Regulation Based on Feedback Analysis of Music Therapy with Brain-Computer Interface. Comput. Math. Methods Med. 2022, 2022, 7200678. [Google Scholar] [CrossRef] [PubMed]
- Sanyal, S.; Banerjee, A.; Sengupta, R.; Ghosh, D. Chaotic Brain, Musical Mind-A Non-Linear eurocognitive Physics Based Study. J. Neurol. Neurosci. 2016, 7, 1–10. [Google Scholar] [CrossRef]
- Gharavian, D.; Bejani, M.; Sheikhan, M. Audio-visual emotion recognition using FCBF feature selection method and particle swarm optimization for fuzzy ARTMAP neural networks. Multimed. Tools Appl. 2017, 76, 2331–2352. [Google Scholar] [CrossRef]
- Han, B.J.; Rho, S.; Jun, S.; Hwang, E. Music emotion classification and context-based music recommendation. Multimed. Tools Appl. 2010, 47, 433–460. [Google Scholar] [CrossRef]
- Hassan, A.; Damper, R.; Niranjan, M. On acoustic emotion recognition: Compensating for covariate shift. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1458–1468. [Google Scholar] [CrossRef]
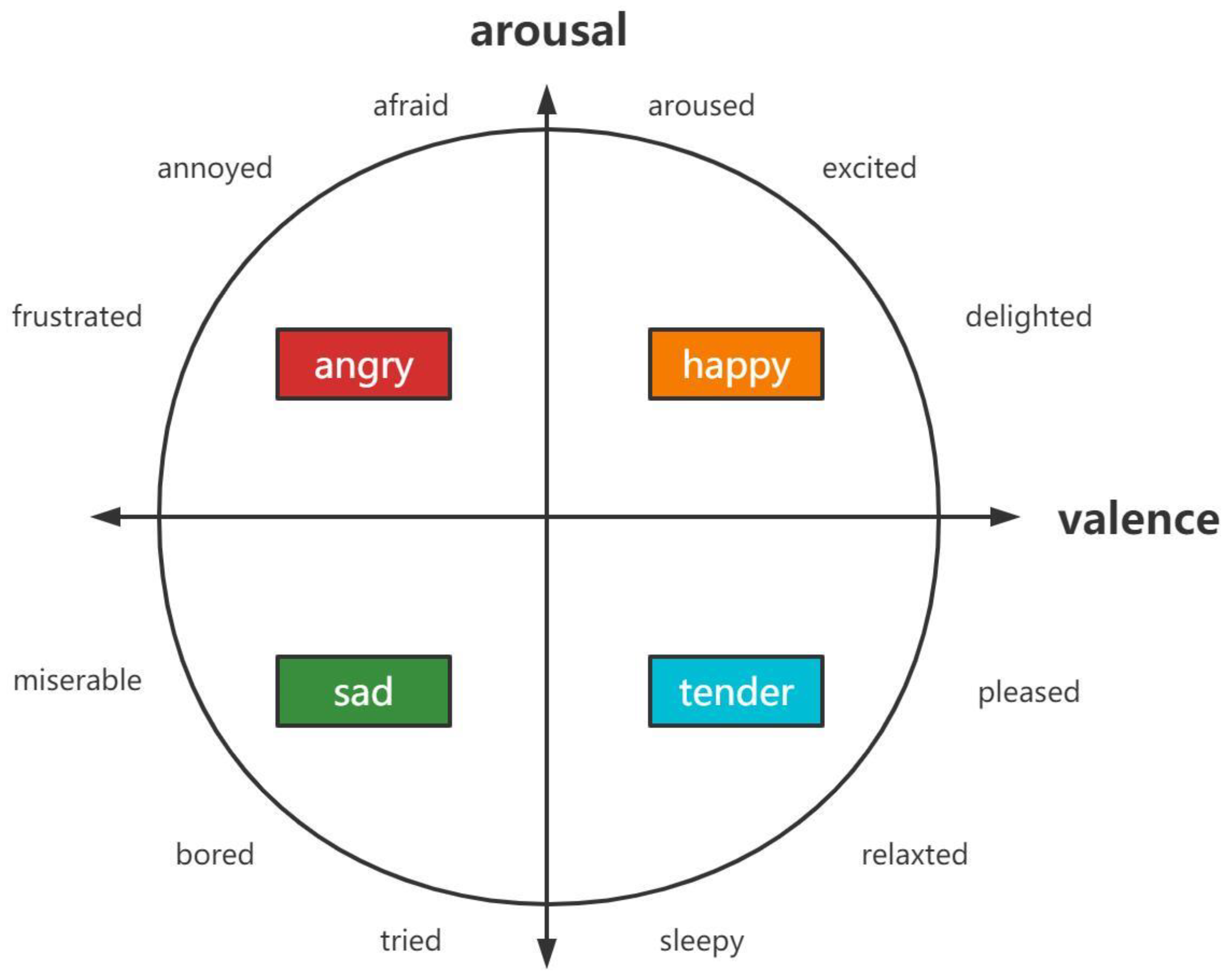
- Thayer, R.E. The Biopsychology of Mood and Arousal; Oxford University Press: Oxford, UK, 1990. [Google Scholar]
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161–1178. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Han, D.; Kong, Y.; Han, J.; Wang, G. A survey of music emotion recognition. Front. Comput. Sci. 2022, 16, 166335. [Google Scholar] [CrossRef]
- Koh, E.Y.; Cheuk, K.W.; Heung, K.Y.; Agres, K.R.; Herremans, D. MERP: A Music Dataset with Emotion Ratings and Raters’ Profile Information. Sensors 2023, 23, 382. [Google Scholar] [CrossRef] [PubMed]
- Gabrielsson, A.; Lindström, E. The influence of musical structure on emotional expression. In Music and Emotion: Theory and Research; Juslin, P.N., Sloboda, J.A., Eds.; Oxford University Press: Oxford, UK, 2001; pp. 223–248. [Google Scholar]
- Huang, Z.; Xue, W.; Mao, Q.; Zhan, Y. Unsupervised domain adaptation for speech emotion recognition using PCANet. Multimed. Tools Appl. 2017, 76, 6785–6799. [Google Scholar] [CrossRef]
- Lin, Y.C.; Yang, Y.H.; Chen, H.H. Exploiting online music tags for music emotion classification. ACM Trans. Multimed. Comput. Commun. Appl. 2011, 7, 26. [Google Scholar] [CrossRef]
- Albornoz, E.M.; Sánchez-Gutiérrez, M.; Martinez-Licona, F.; Rufiner, H.L.; Goddard, J. Spoken emotion recognition using deep learning. In Proceedings of the CIARP 2014: Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications, Puerto Vallarta, Mexico, 2–5 November 2014; pp. 104–111. [Google Scholar]
- Kılıç, B.; Aydın, S. Classification of Contrasting Discrete Emotional States Indicated by EEG Based Graph Theoretical Network Measures. Neuroinformatics 2022, 20, 863–877. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.H.; Lin, Y.C.; Su, Y.F.; Chen, H.H. A regression approach to music emotion recognition. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 448–457. [Google Scholar] [CrossRef]
- Han, B.J.; Rho, S.; Dannenberg, R.B.; Hwang, E. SMERS: Music Emotion Recognition Using Support Vector Regression. In Proceedings of the 10th International Society for Music Information Retrieval Conference (ISMIR 2009), Kobe, Japan, 26–30 October 2009; pp. 651–656. [Google Scholar]
- Koh, E.; Dubnov, S. Comparison and analysis of deep audio embeddings for music emotion recognition. arXiv 2021, arXiv:2104.06517. [Google Scholar]
- Eerola, T.; Vuoskoski, J.K. A comparison of the discrete and dimensional models of emotion in music. Psychol. Music 2011, 39, 18–49. [Google Scholar] [CrossRef] [Green Version]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; pp. 18–25. [Google Scholar]
- Chollet, F. Keras-team/Keras. Available online: https://github.com/fchollet/keras (accessed on 1 December 2022).
- Saari, P.; Eerola, T.; Lartillot, O. Generalizability and simplicity as criteria in feature selection: Application to mood classification in music. IEEE Trans. Audio Speech Lang. Process. 2010, 19, 1802–1812. [Google Scholar] [CrossRef]
- Chen, N.; Wang, S. High-Level Music Descriptor Extraction Algorithm Based on Combination of Multi-Channel CNNs and LSTM. In Proceedings of the 18th ISMIR Conference, Suzhou, China, 23–27 October 2017; pp. 509–514. [Google Scholar]
- Panda, R.; Malheiro, R.; Paiva, R.P. Musical texture and expressivity features for music emotion recognition. In Proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR 2018), Paris, France, 23–27 September 2018; pp. 383–391. [Google Scholar]
- Sarkar, R.; Choudhury, S.; Dutta, S.; Roy, A.; Saha, S.K. Recognition of emotion in music based on deep convolutional neural network. Multimed. Tools Appl. 2020, 79, 765–783. [Google Scholar] [CrossRef]
- Chaudhary, D.; Singh, N.P.; Singh, S. Development of music emotion classification system using convolution neural network. Int. J. Speech Technol. 2021, 24, 571–580. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Size | Filter_Number, Kernel Size | |
|---|---|---|---|
| Input | 1292, 1025 | - | |
| SE-Inception | Conv1D | [1292, 16] [1292, 32] [1292, 64] | [16,3] [32,5] [64,7] |
| BatchNormalization | [1292, 16] [1292, 32] [1292, 64] | - | |
| Conv1D | [1292, 1] [1292, 1] [1292, 1] | [1,3] [1,5] [1,7] | |
| Conv1D | [1292, 16] [1292, 32] [1292, 64] | [16,3] [32, 5] [64,7] | |
| BatchNormalization | [1292, 16] [1292, 32] [1292, 64] | - | |
| AveragePooling1D | [646, 16] [646, 32] [646, 64] | [2] [2] [2] | |
| Concatenate | 646, 112 | - | |
| residual_1d_block × 2 | 646, 112 | [112,3] | |
| average_pooling1d | 323, 112 | [2] | |
| residual_1d_block × 2 | 323, 112 | [112,3] | |
| average_pooling1d | 161, 112 | [2] | |
| residual_1d_block × 2 | 161, 112 | [161, 3] | |
| average_pooling1d | 80, 112 | [2] | |
| residual_1d_block × 2 | 80, 112 | [80, 3] | |
| average_pooling1d | 40, 112 | [2] | |
| residual_1d_block | 40, 112 | [40, 3] | |
| average_pooling1d | 20, 112 | [2] | |
| residual_1d_block | 20, 112 | [20, 3] | |
| average_pooling1d | 10, 112 | [2] | |
| residual_1d_block | 10, 112 | [10, 3] | |
| average_pooling1d | 5, 112 | [2] | |
| residual_1d_block | 5, 112 | [5, 3] | |
| average_pooling1d | 2, 112 | [2] | |
| GUR | 8 | - | |
| Dense_softmax | 4 | - | |
| Class | Precision | Recall | F1-Score |
|---|---|---|---|
| Anger | 0.88 | 0.79 | 0.86 |
| Sad | 0.69 | 0.88 | 0.71 |
| Tender | 0.63 | 0.63 | 0.72 |
| Happy | 0.93 | 0.93 | 0.80 |
| Method | Accuracy | Param | FLOPs | Recall | F1-Score |
|---|---|---|---|---|---|
| SVM + ReliefF | 54.63% | - | - | ||
| VGG-16 | 56.45% | - | - | 72.69% | 76.4% |
| Inception-v3 | 68.12% | 14,992,068 | 85,681,045,528 | ||
| ResNet-18 | 74.35% | 2,487,978 | 1,230,683,852 | ||
| Sarkar et al. [29]. | 82.54% | 1,203,140 | 17,710,549,784 | 61.87% | 62.66% |
| Chaudhary et al. [30]. | 83.98% | 375,012 | 5,922,046,296 | 74.53% | 69.46% |
| Proposed approach | 84.23% | 79.63% | 77.36% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, X.; Chen, F.; Ban, J. Music Emotion Recognition Based on a Neural Network with an Inception-GRU Residual Structure. Electronics 2023, 12, 978. https://doi.org/10.3390/electronics12040978
Han X, Chen F, Ban J. Music Emotion Recognition Based on a Neural Network with an Inception-GRU Residual Structure. Electronics. 2023; 12(4):978. https://doi.org/10.3390/electronics12040978
Chicago/Turabian StyleHan, Xiao, Fuyang Chen, and Junrong Ban. 2023. "Music Emotion Recognition Based on a Neural Network with an Inception-GRU Residual Structure" Electronics 12, no. 4: 978. https://doi.org/10.3390/electronics12040978