

A Methodology for Accelerating FPGA Fault Injection Campaign Using ICAP
 , ,
, ,  , and
, and 
Abstract
:1. Introduction
2. Related Work
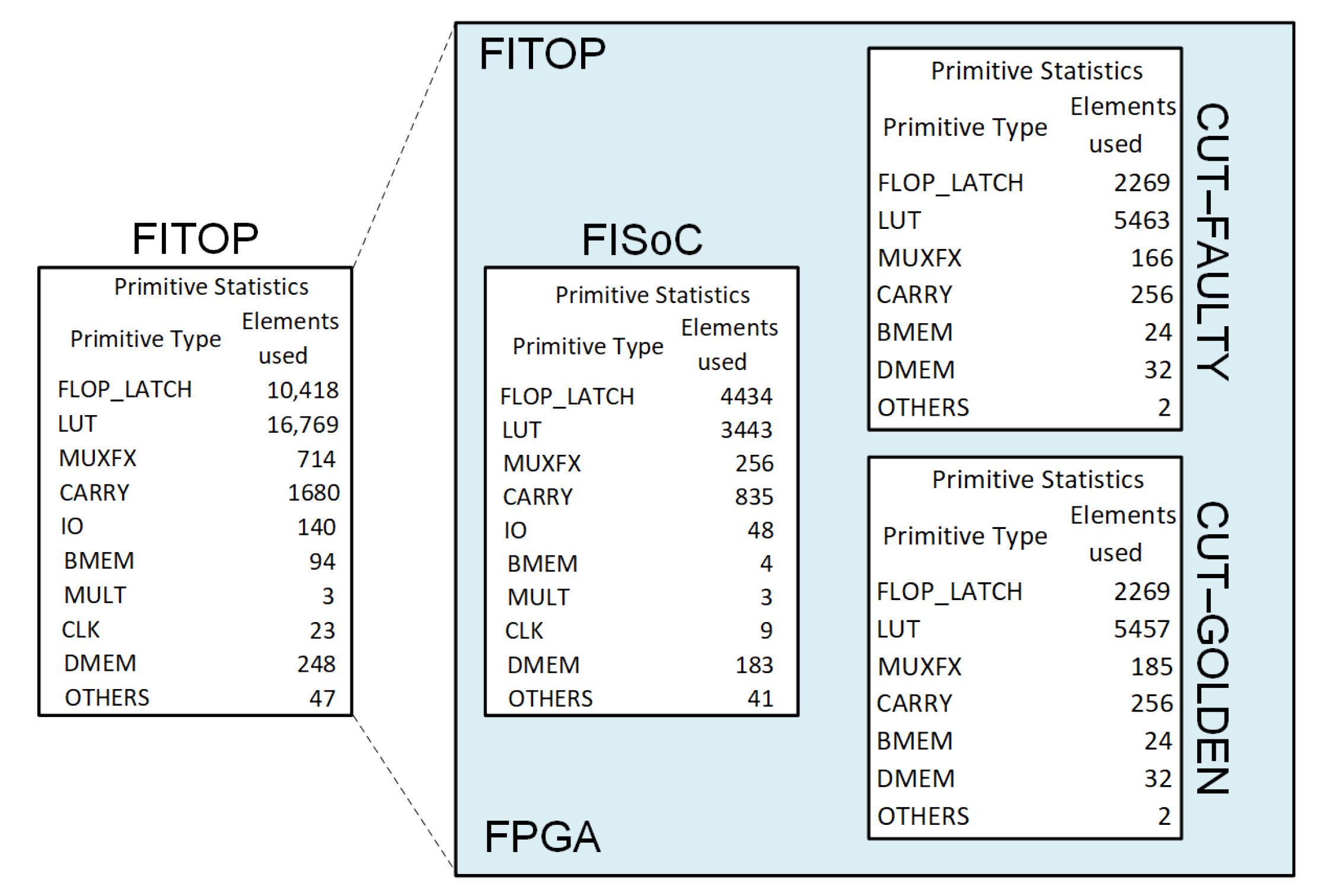
3. Case Study


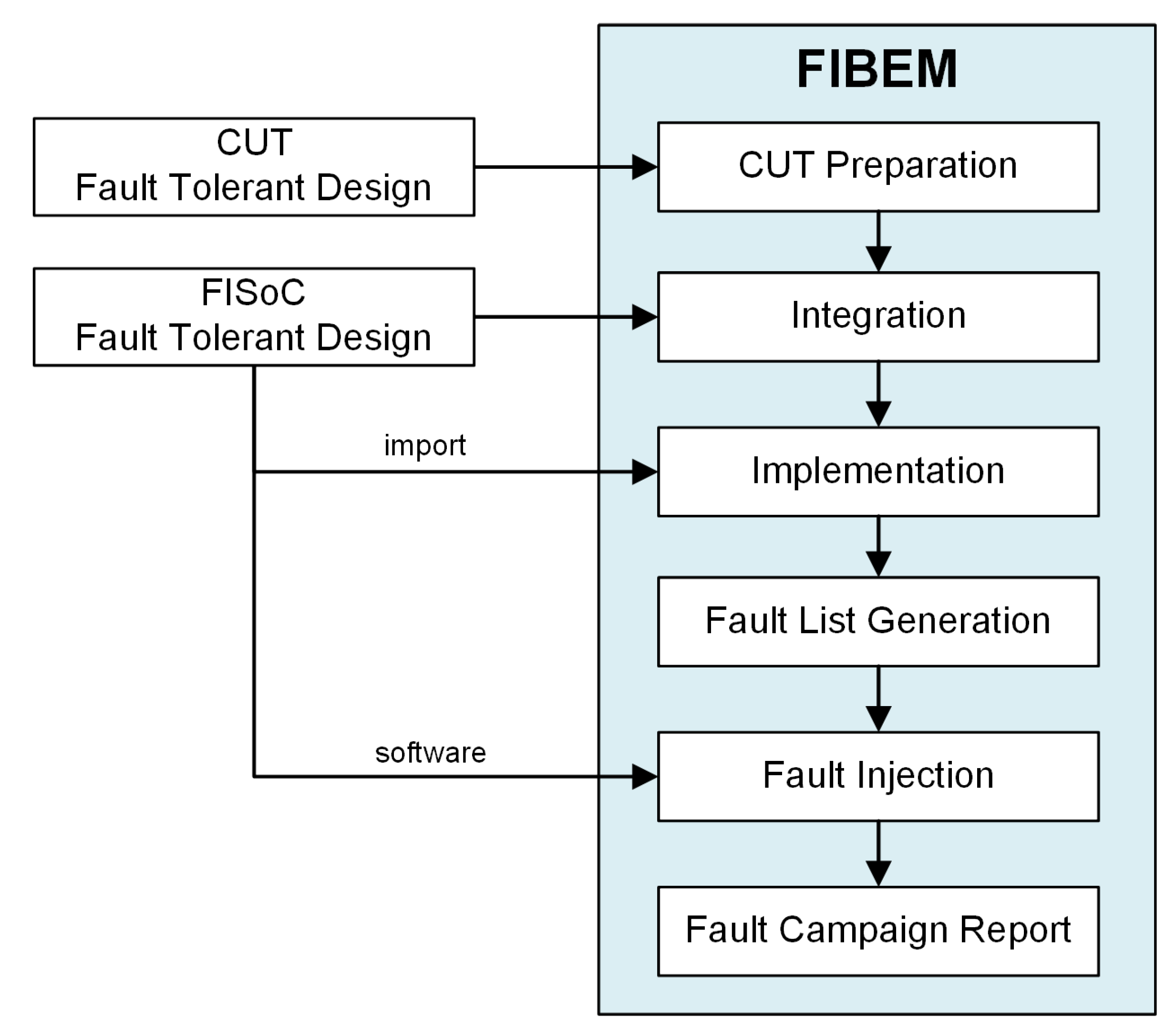
4. Proposed Fault Emulation Flow
4.1. CUT Prepare
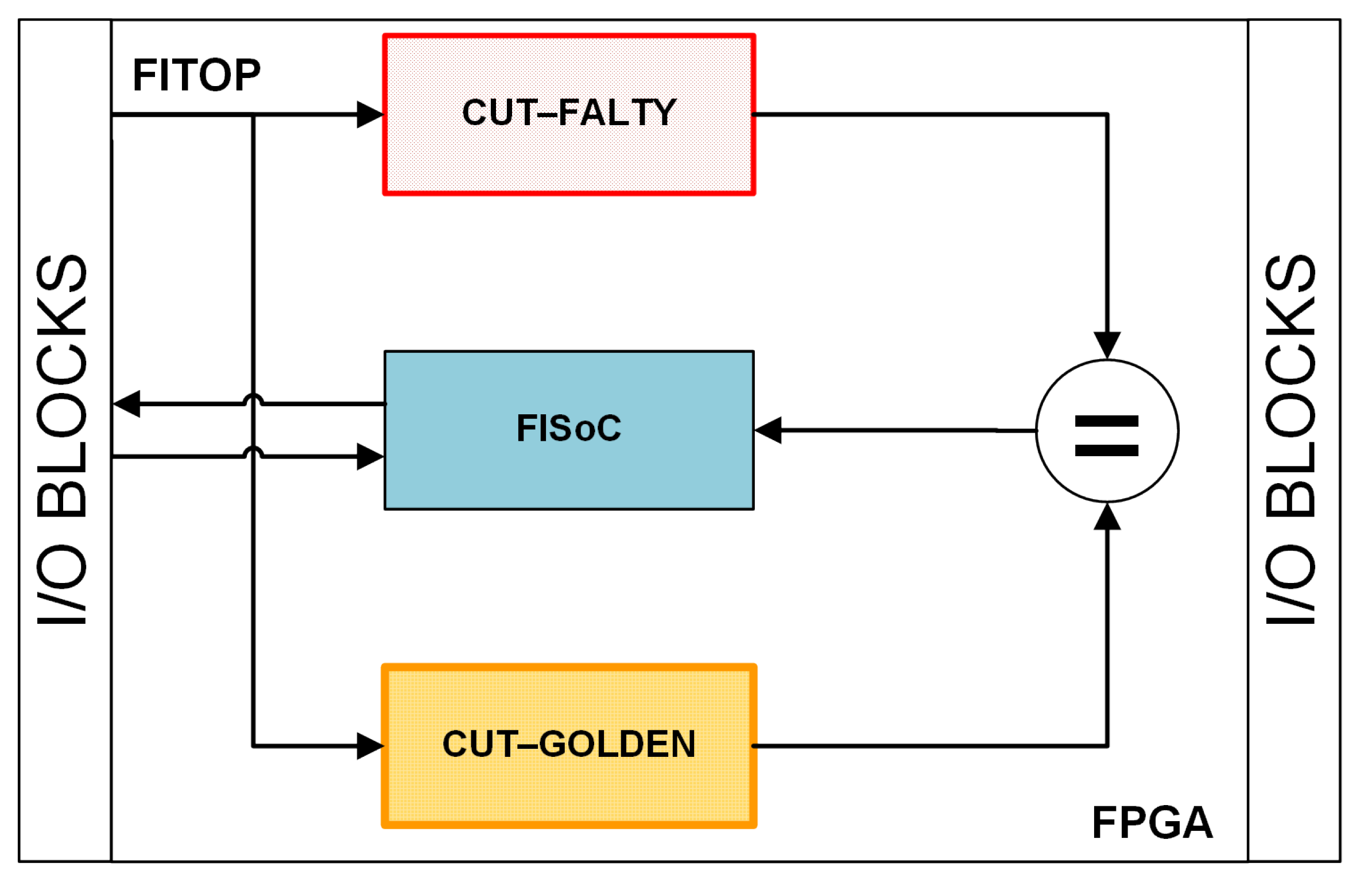
4.2. Integration
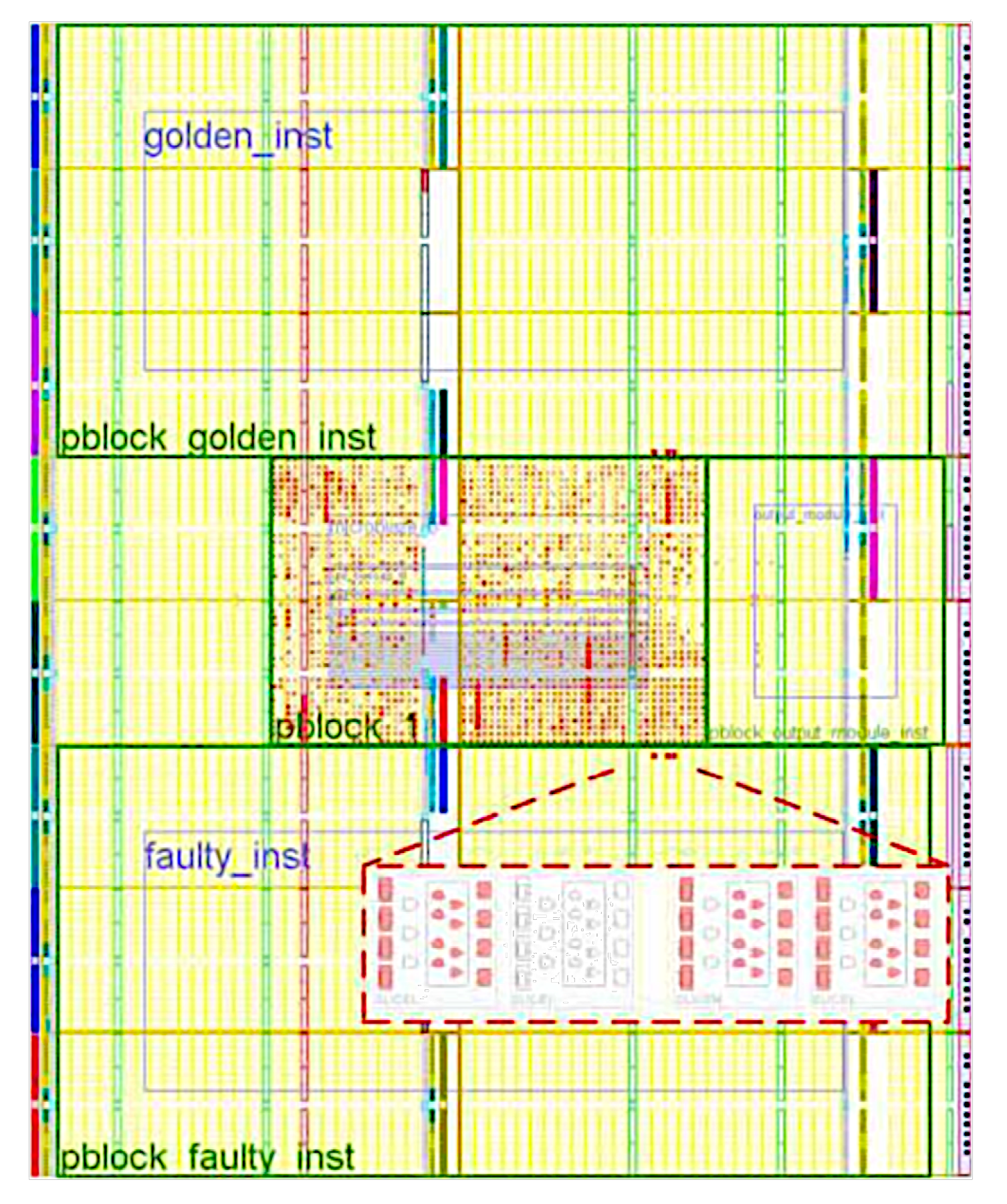
4.3. Implementation
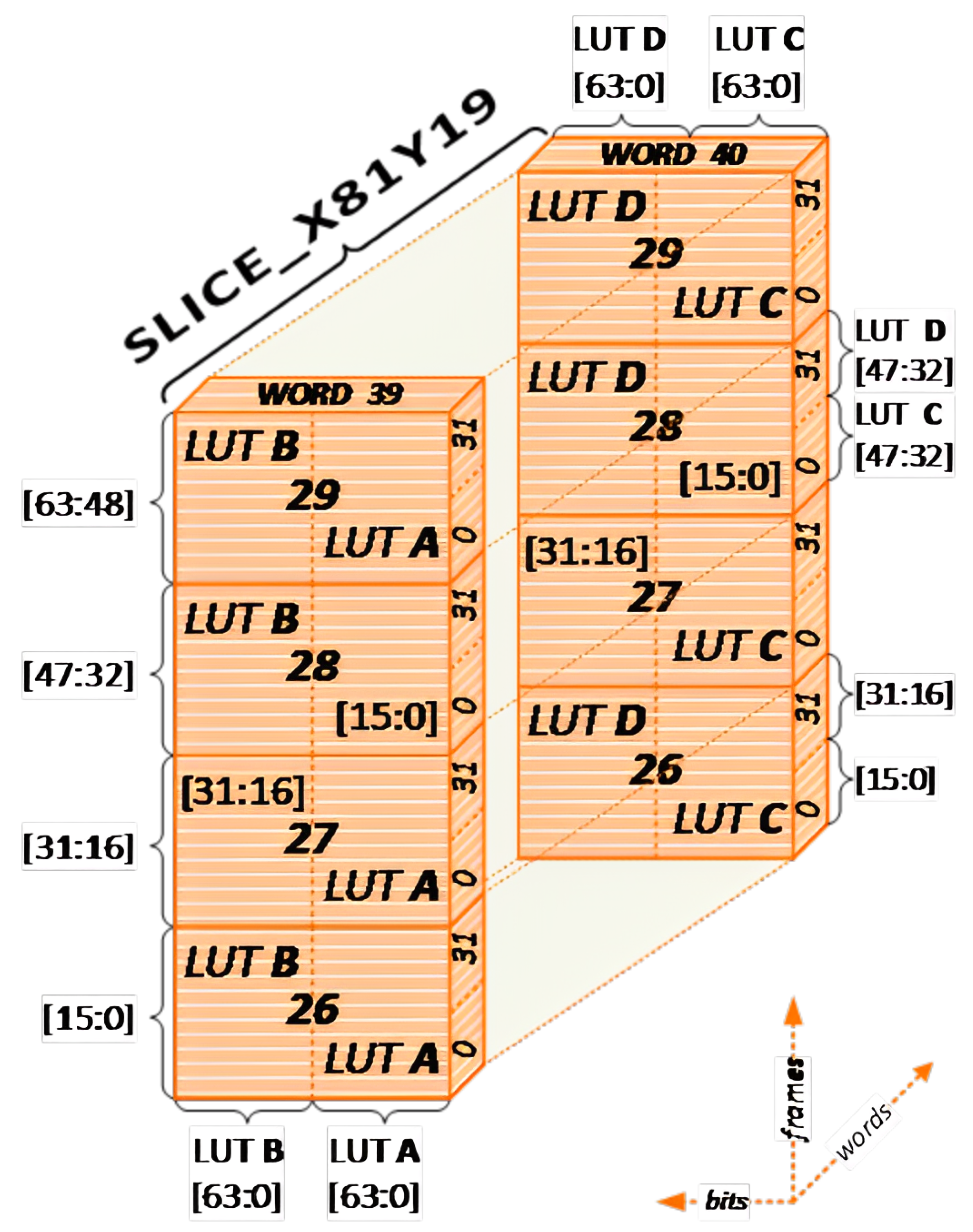
4.4. Fault List Generation
4.5. Fault Injection
4.6. Fault Coverage Report
4.7. Workflow
| Algorithm 1: Proposed Fault Emulation Flow. |
| Input: CUT, FISoC, comparator Output: Fault list Step 1: CUT Preparation; Remove interface-specific components from CUT; Instantiate CUT twice (GOLDEN and FAULTY) in FITOP; Step 2: Integration; Integrate CUT instances and FISoC in FITOP; Connect output ports of CUT instances to comparator; Add hardware to avoid metastability of asynchronous signals; Step 3: Implementation; Use PlanAhead tool to load netlists of FITOP modules; Constrain area for FAULTY instance of CUT; Generate netlist containing the entire hardware description; Step 4: Fault List Generation; Convert netlist to XDL using Xilinx application; Identify LUTs belonging to FAULTY instance in XDL file; Use XY coordinates to calculate frame addresses of FPGA configuration memory; Extract data needed for fault injection and send to FISoC; Step 5: Fault Injection; Use FISoC to reset CUT instances and comparator; Inject faults into FAULTY instance of CUT using frame addresses; Observe the response of CUT and record results; Step 6: Results Analysis; Analyze results of fault injection to evaluate fault tolerance techniques; |
5. Experimental Results
5.1. Case Study 1
5.2. Case Study 2
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Makowski, D. The Impact of Radiation on Electronic Devices with the Special Consideration of Neutron and Gamma Radiation Monitoring; Lodz University of Technology: Łódź, Poland, 2006; pp. 1–151. [Google Scholar]
- Reyneri, L.M.; Serrano-Cases, A.; Morilla, Y.; Cuenca-Asensi, S.; Martínez-Álvarez, A. A Compact Model to Evaluate the Effects of High Level C++ Code Hardening in Radiation Environments. Electronics 2019, 8, 653. [Google Scholar] [CrossRef]
- Wang, T.; Wan, X.; Jin, H.; Li, H.; Sun, Y.; Liang, R.; Xu, J.; Zheng, L. Optimization of the Cell Structure for Radiation-Hardened Power MOSFETs. Electronics 2019, 8, 598. [Google Scholar] [CrossRef]
- Díez-Acereda, V.; L. Khemchandani, S.; del Pino, J.; Mateos-Angulo, S. RHBD Techniques to Mitigate SEU and SET in CMOS Frequency Synthesizers. Electronics 2019, 8, 690. [Google Scholar] [CrossRef]
- Viel, F.; Silva, L.A.; Valderi Leithardt, R.Q.; Zeferino, C.A. Internet of Things: Concepts, Architectures and Technologies. In Proceedings of the 2018 13th IEEE International Conference on Industry Applications (INDUSCON), Sao Paulo, Brazil, 12–14 November 2018; pp. 909–916. [Google Scholar] [CrossRef]
- Shukla, S.; Ray, K.C. Design and ASIC Implementation of a Reconfigurable Fault-Tolerant ALU for Space Applications. In Proceedings of the 2019 IEEE International Symposium on Smart Electronic Systems (iSES) (Formerly iNiS), Rourkela, India, 16–18 December 2019; pp. 156–159. [Google Scholar] [CrossRef]
- Simevski, A.; Schrape, O.; Benito, C.; Krstic, M.; Andjelkovic, M. PISA: Power-robust Multiprocessor Design for Space Applications. In Proceedings of the 2020 IEEE 26th International Symposium on On-Line Testing and Robust System Design (IOLTS), Napoli, Italy, 13–15 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Kameda, T.; Nagata, A.; Kimura, Y.; Imai, R.; Shrestha, P.; Kimura, K.; Yasuda, A.; Watanabe, H. Space Environment Evaluation and Low-Earth-Orbit Demonstration of a Communication Component with a Commercial Transceiver Integrated Circuit. Aerospace 2022, 9, 280. [Google Scholar] [CrossRef]
- Paiva, D.; Duarte, J.M.; Lima, R.; Carvalho, M.; Mattiello-Francisco, F.; Madeira, H. Fault injection platform for affordable verification and validation of CubeSats software. In Proceedings of the 2021 10th Latin-American Symposium on Dependable Computing (LADC), Florianópolis, Brazil, 22–26 November 2021; pp. 1–11. [Google Scholar] [CrossRef]
- Pitchaimani, B.; Sridharan, M. A novel emulation method to assess the effects of cosmic radiation for avionics SoC using the GA based fault injection hardware. Sādhanā 2022, 47, 1–6. [Google Scholar] [CrossRef]
- Eslami, M.; Ghavami, B.; Raji, M.; Mahani, A. A survey on fault injection methods of digital integrated circuits. Integration 2020, 71, 154–163. [Google Scholar] [CrossRef]
- de Oliveira, A.B.; Tambara, L.A.; Benevenuti, F.; Benites, L.A.C.; Added, N.; Aguiar, V.A.P.; Medina, N.H.; Silveira, M.A.G.; Kastensmidt, F.L. Evaluating Soft Core RISC-V Processor in SRAM-Based FPGA Under Radiation Effects. IEEE Trans. Nucl. Sci. 2020, 67, 1503–1510. [Google Scholar] [CrossRef]
- Braga, G.; Benevenuti, F.; Gonçalves, M.M.; Hernandez, H.G.; Hübner, M.; Brandalero, M.; Kastensmidt, F.; Azambuja, J.R. Evaluating softcore GPU in SRAM-based FPGA under radiation-induced effects. Microelectron. Reliab. 2021, 126, 114348, In Proceedings of ESREF 2021, 32nd European Symposium on Reliability of Electron Devices, Failure Physics and Analysis, Virtually, 4–8 October 2021. [Google Scholar] [CrossRef]
- Ding, Q.; Luo, R.; Wang, H.; Yang, H.; Xie, Y. Modeling the Impact of Process Variation on Critical Charge Distribution. In Proceedings of the 2006 IEEE International SOC Conference, Austin, TX, USA, 24–27 September 2006; Volume 2, pp. 243–246. [Google Scholar] [CrossRef]
- Mogollon, J.M.; Guzman-Miranda, H.; Napoles, J.; Aguirre, M.A. Metrics for the Measurement of the Quality of Stimuli in Radiation Testing Using Fast Hardware Emulation. IEEE Trans. Nucl. Sci. 2013, 60, 2456–2460. [Google Scholar] [CrossRef]
- Dodd, P.; Massengill, L. Basic mechanisms and modeling of single-event upset in digital microelectronics. IEEE Trans. Nucl. Sci. 2003, 50, 583–602. [Google Scholar] [CrossRef]
- Lesea, A.; Drimer, S.; Fabula, J.; Carmichael, C.; Alfke, P. The Rosetta Experiment: Atmospheric Soft Error Rate Testing in Fiffering Technology FPGAs. IEEE Trans. Device Mater. Reliab. 2005, 5, 317–328. [Google Scholar] [CrossRef]
- Bocquillon, A.; Foucard, G.; Miller, F.; Buard, N.; Leveugle, R.; Daniel, C.; Rakers, S.; Carriere, T.; Pouget, V.; Velazco, R. Highlights of laser testing capabilities regarding the understanding of SEE in SRAM based FPGAs. In Proceedings of the 2007 9th European Conference on Radiation and Its Effects on Components and Systems, Deauville, France, 10–14 September 2007; pp. 1–6. [Google Scholar] [CrossRef]
- Padmapriya, K.; Varaprasad, B. Improving Test Coverage of Hi-Reliability ASIC Designs with Test Point Insertion for Space Applications. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 10–12 September 2020; pp. 1099–1103. [Google Scholar] [CrossRef]
- Ziade, H.; Ayoubi, R.; Velazco, R. A Survey on Fault Injection Techniques. Int. Arab. J. Inf. Technol. 2004, 1, 171–186. [Google Scholar] [CrossRef]
- da Silva, A.; Sanchez, S. LEON3 ViP: A Virtual Platform with Fault Injection Capabilities. In Proceedings of the 2010 13th Euromicro Conference on Digital System Design: Architectures, Methods and Tools, Lille, France, 1–3 September 2010; pp. 813–816. [Google Scholar] [CrossRef]
- Jenn, E.; Arlat, J.; Rimen, M.; Ohlsson, J.; Karlsson, J. Fault injection into VHDL models: The MEFISTO tool. In Proceedings of the IEEE 24th International Symposium on Fault- Tolerant Computing, Austin, TX, USA, 15–17 June 1994; Volume 2, pp. 66–75. [Google Scholar] [CrossRef]
- Lopez-Ongil, C.; Garcia-Valderas, M.; Portela-Garcia, M.; Entrena, L. Autonomous Fault Emulation: A New FPGA-Based Acceleration System for Hardness Evaluation. IEEE Trans. Nucl. Sci. 2007, 54, 252–261. [Google Scholar] [CrossRef]
- Entrena, L.; Garcia-Valderas, M.; Fernandez-Cardenal, R.; Lindoso, A.; Portela, M.; Lopez-Ongil, C. Soft Error Sensitivity Evaluation of Microprocessors by Multilevel Emulation-Based Fault Injection. IEEE Trans. Comput. 2010, 61, 313–322. [Google Scholar] [CrossRef]
- Vanhauwaert, P.; Leveugle, R.; Roche, P. Reduced Instrumentation and Optimized Fault Injection Control for Dependability Analysis. In Proceedings of the 2006 IFIP International Conference on Very Large Scale Integration, Nice, France, 16–18 October 2006; pp. 391–396. [Google Scholar] [CrossRef]
- Alderighi, M.; Casini, F.; D’Angelo, S.; Mancini, M.; Codinachs, D.M.; Pastore, S.; Poivey, C.; Sechi, G.R.; Weigand, G.S.R. Experimental validation of fault injection analyses by the FLIPPER tool. In Proceedings of the 2009 European Conference on Radiation and Its Effects on Components and Systems, Brugge, Belgium, 14–18 September 2009; Volume 57, pp. 544–548. [Google Scholar] [CrossRef]
- Alderighi, M.; Casini, F.; D’Angelo, S.; Pastore, S.; Sechi, G.; Weigand, R. Evaluation of Single Event Upset Mitigation Schemes for SRAM based FPGAs using the FLIPPER Fault Injection Platform. In Proceedings of the 22nd IEEE International Symposium on Defect and Fault-Tolerance in VLSI Systems (DFT 2007), Rome, Italy, 26–28 September 2007; pp. 105–113. [Google Scholar] [CrossRef]
- Aguirre, M.; Tombs, J.; Muñoz, F.; Baena, V.; Torralba, A.; Fernández-León, A.; Tortosa, F.; González-Gutiérrez, D. An FPGA Based Bardware Emulator for the Insertion and Analysis of Single Event Upsets in VLSI Designs. Radiation Effects on Components and Systems Workshop (RADECS). 2004, pp. 1–5. Available online: https://www.tib.eu/en/search/id/BLCP%3ACN058079892/A-FPGA-based-hardware-emulator-for-the-insertion/ (accessed on 25 December 2022).
- Dutton, B.; Ali, M.; Sunwoo, J.; Stroud, C. Embedded Processor Based Fault Injection and SEU Emulation for FPGAs. In Proceedings of the International Conference on Embedded Systems and Applications, Las Vegas, NV, USA, 14 July 2009; pp. 183–189. [Google Scholar]
- Serrano, F.; Alaminos, V.; Clemente, J.; Mecha, H.; Liu, S. NESSY: Una plataforma de inyección de errores para una FPGA Virtex-5. JCRA. 2012. Available online: https://jornadassarteco.org (accessed on 25 December 2022).
- Chapman, K. SEU Strategies for Virtex-5 Devices; Xilinx Inc.: San Jose, CA, USA, 2010; Volume 2.0, pp. 1–16. [Google Scholar]
- Ferlini, F.; Seman, L.O.; Bezerra, E.A. Enabling ISO 26262 Compliance with Accelerated Diagnostic Coverage Assessment. Electronics 2020, 9, 732. [Google Scholar] [CrossRef]
- Leipnitz, M.T.; Geferson, L.; Nazar, G.L. A fault injection platform for fpga-based communication systems. In Proceedings of the 2016 IEEE 7th Latin American Symposium on Circuits & Systems (LASCAS), Florianopolis, Brazil, 28 February–2 March 2016; pp. 59–62. [Google Scholar]
- Zhang, R.; Xiao, L.; Li, J.; Cao, X.; Qi, C.; Li, J.; Wang, M. A fast fault injection platform of multiple SEUs for SRAM-based FPGAs. Microelectron. Reliab. 2018, 82, 147–152. [Google Scholar] [CrossRef]
- Xie, Y.; Chen, H.; Xie, Y.Z.; Mao, C.A.; Li, B.Y. An automated FPGA-based fault injection platform for granularly-pipelined fault tolerant CORDIC. In Proceedings of the 2018 International Conference on Field-Programmable Technology (FPT), Naha, Japan, 10–14 December 2018; pp. 370–373. [Google Scholar]
- Wilson, A.E.; Wirthlin, M. Fault Injection of TMR Open Source RISC-V Processors using Dynamic Partial Reconfiguration on SRAM-based FPGAs. In Proceedings of the 2021 IEEE Space Computing Conference (SCC), Laurel, MD, USA, 23–27 August 2021; pp. 1–8. [Google Scholar]
- Zhang, Y.; Chen, L.; Wang, S.; Zhou, J.; Tian, C.; Feng, H. Research on agile FPGA fault injection system. In Proceedings of the 2021 International Conference on Microelectronics (ICM), New Cairo City, Egypt, 19–22 December 2021; pp. 57–61. [Google Scholar]
- Yang, W.; Li, Y.; He, C. Fault injection and failure analysis on Xilinx 16 nm FinFET Ultrascale+ MPSoC. Nucl. Eng. Technol. 2022, 54, 2031–2036. [Google Scholar] [CrossRef]
- Feng, H.; Li, W.; Chen, L.; Wang, S.; Zhou, J.; Tian, C.; Zhang, Y. Precise Fault Injection and Fault Location System for SRAM-based FPGAs. In Proceedings of the 2022 IEEE 10th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 17–19 June 2022; Volume 10, pp. 2371–2376. [Google Scholar]
- Xilinx. Virtex-5 FPGA Configuration User Guide; Xilinx Inc.: San Jose, CA, USA, 2012; Volume 3.11, pp. 1–166. [Google Scholar]
- Xilinx. Virtex-5 FPGA User Guide; Xilinx Inc.: San Jose, CA, USA, 2012; Volume 5.4, pp. 1–385. [Google Scholar]
- Carmichael, C. Application Note: Virtex Series Triple Module Redundancy Design Techniques for Virtex FPGAs TMR in FPGAs; Xilinx Inc.: San Jose, CA, USA, 2006; Volume 1.0.1, pp. 1–37. [Google Scholar]
- Ferlini, F.; da Silva, F.A.; Bezerra, E.A.; Lettnin, D.V. Non-intrusive fault tolerance in soft processors through circuit duplication. In Proceedings of the LATW ’12: Proceedings of the 2012 13th Latin American Test Workshop, Washington, DC, USA, 10–13 April 2012; pp. 1–6. [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Method | Pros | Cons |
|---|---|---|---|
| [1] | Physical injection (particle radiation or laser beam) | Realistic results | Expensive, requires specific equipment |
| [17] | Physical injection (particle radiation or laser beam) | Realistic results | Expensive, requires specific equipment |
| [18] | Physical injection (particle radiation or laser beam) | Realistic results | Expensive, requires specific equipment |
| [20] | Physical injection (pin forcing) | Limited to IC boundaries, requires a prototype | |
| [21] | Simulation-based injection (SystemC transaction level model) | Early analysis | High computing resources, long execution time |
| [22] | Simulation-based injection (VHDL model) | High computing resources, long execution time | |
| [23] | Emulation-based injection (autonomous technique) | Reduced execution time | Intrusive approach |
| [24] | Emulation-based injection (autonomous technique) | Reduced execution time | Intrusive approach |
| [25] | Emulation-based injection (autonomous technique) | Reduced execution time | Intrusive approach |
| [26] | Emulation-based injection (partial reconfiguration) | Non-intrusive approach | Limited to Xilinx FPGAs |
| [15] | Emulation-based injection (partial reconfiguration) | Non-intrusive approach | Limited to Xilinx FPGAs |
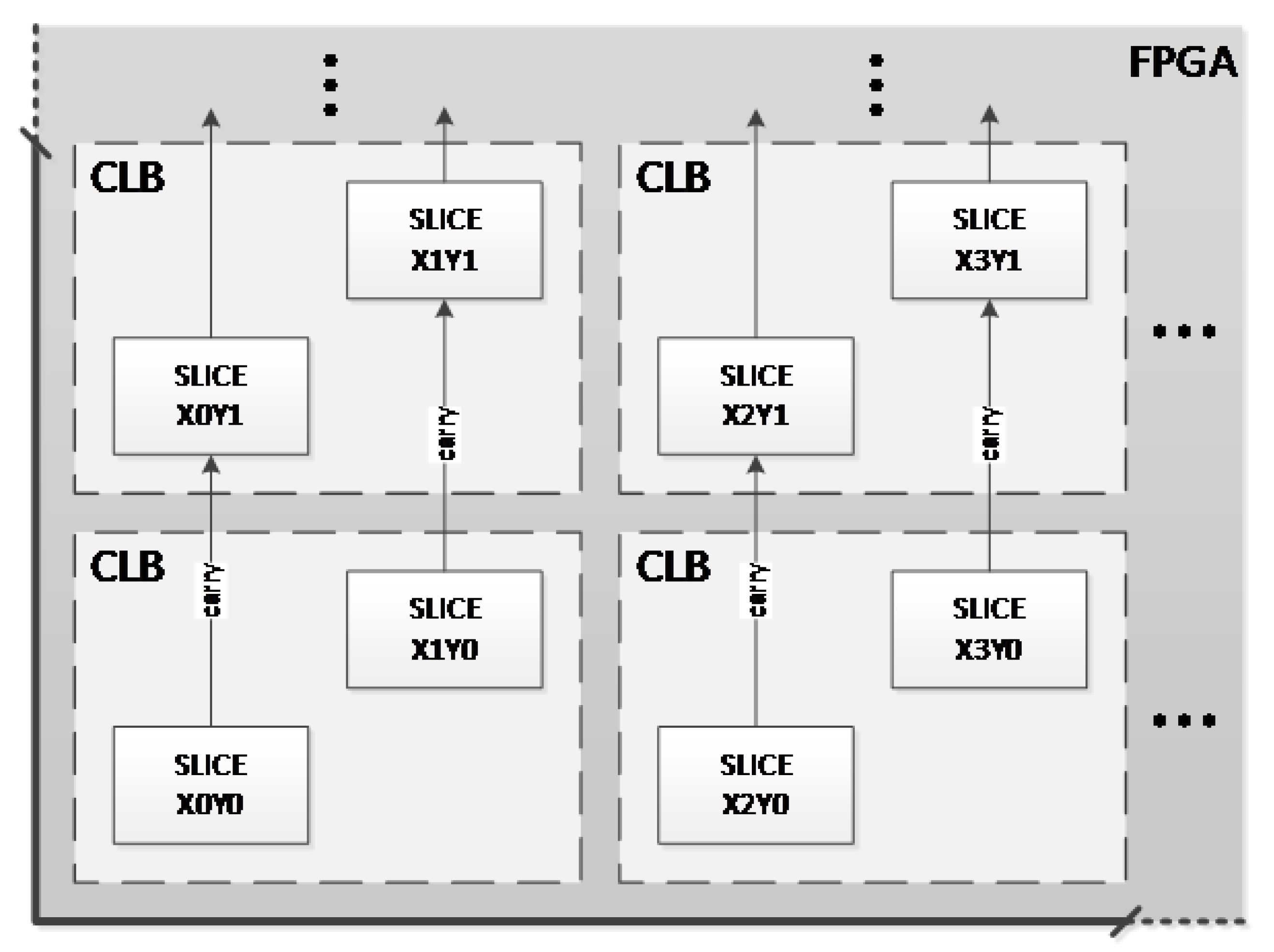
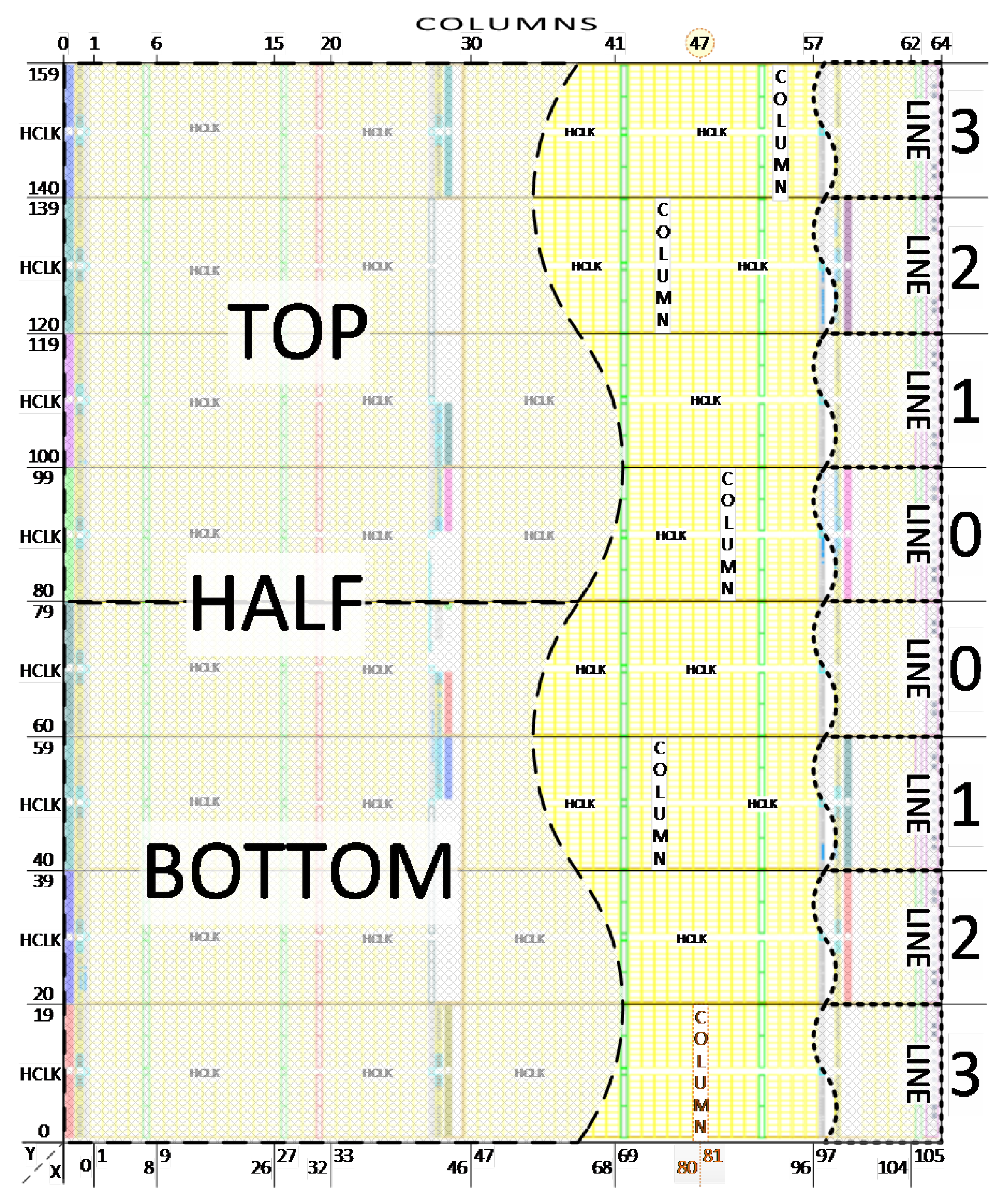
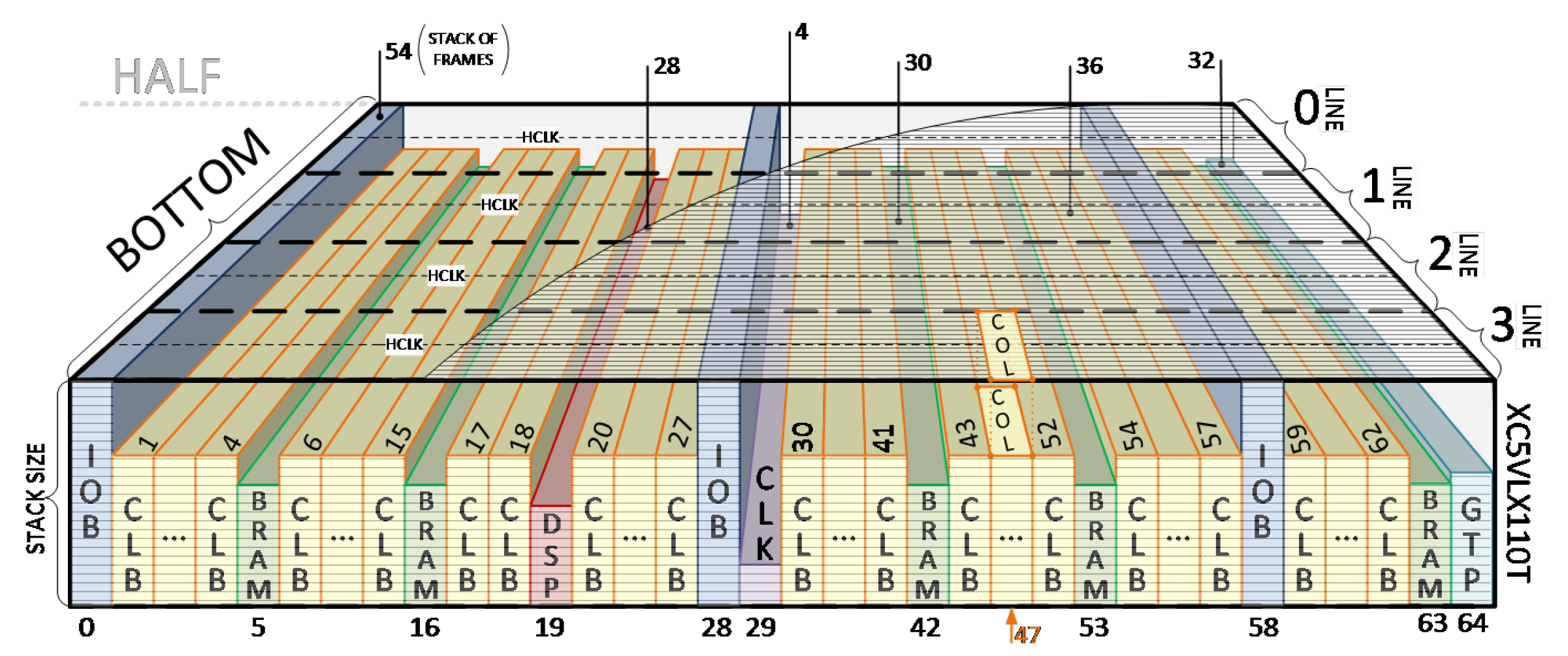
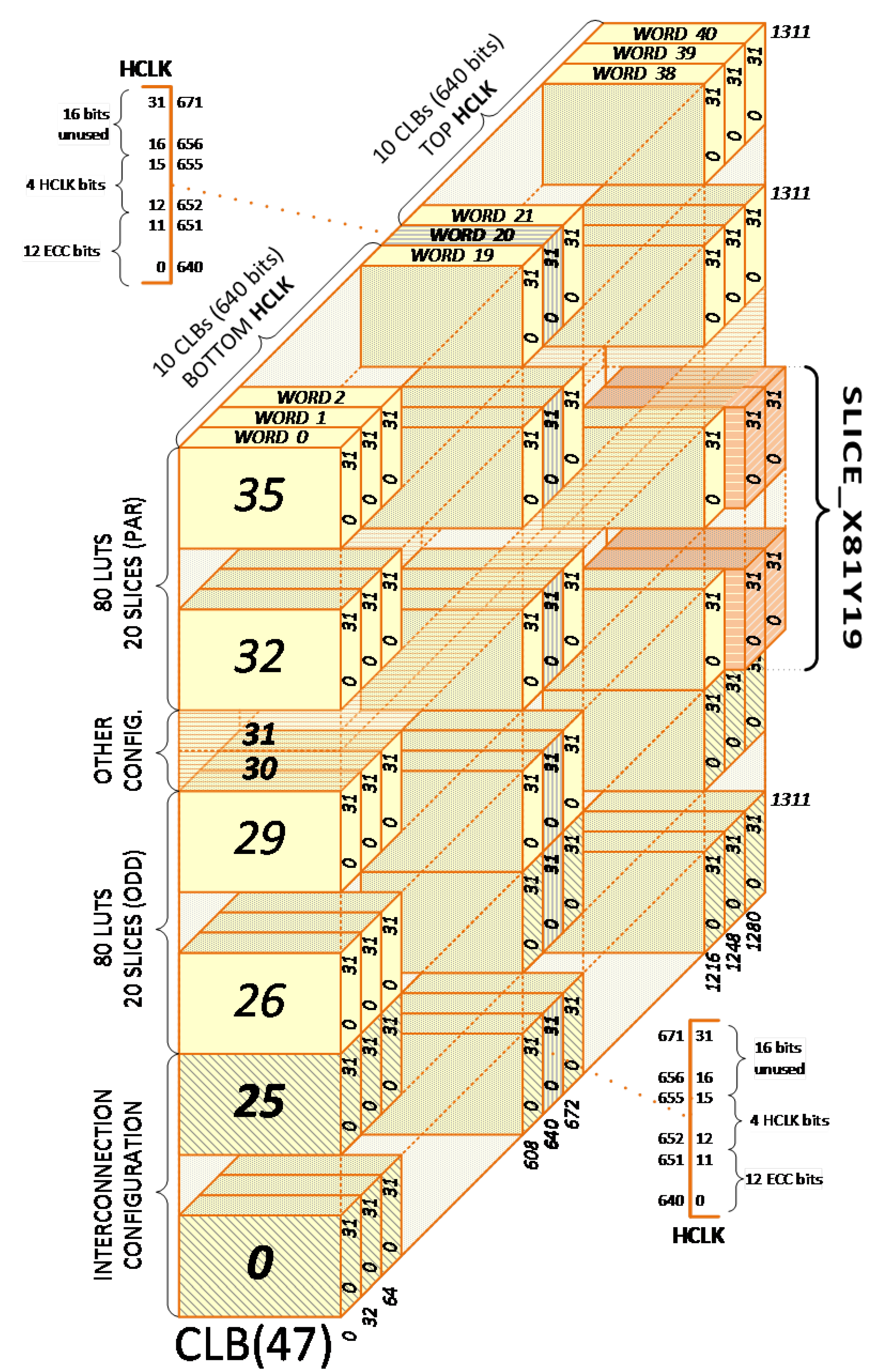
| # | Layer (#)/ Block Type | Stack Size | Total of Columns | Frames per Line | Total FPGA Frames | Total .BIT Frames |
|---|---|---|---|---|---|---|
| 0 | IOB | 54 | 3 | 162 | 1296 | 18,576 |
| CLB | 36 | 54 | 1944 | 15,552 | ||
| BRAM (config.) | 30 | 5 | 150 | 1200 | ||
| DSP | 28 | 1 | 28 | 224 | ||
| GLK | 4 | 1 | 4 | 32 | ||
| GTP | 32 | 1 | 32 | 256 | ||
| JUMP | 2 | 1 | 2 | 16 | ||
| 1 | BRAM (data) | 128 | 5 | 640 | 5120 | 5136 |
| JUMP | 2 | 1 | 2 | 16 | ||
| 2 | PARTIAL (rect.) | 1 | 65 | 65 | 520 | – |
| JUMP | 2 | 1 | 2 | 16 | ||
| 3 | RESERVED | 1 | 5 | 5 | 40 | – |
| JUMP | 2 | 1 | 2 | 16 | ||
| Total FPGA Frames in Configuration Memory | 24,304 | 23,712 | ||||
| Total LUTs | Case Study 1—TMR Counter 4 Bits | ||
|---|---|---|---|
| Design Description | ERROR | TIMEOUT | |
| 12 | Original—Counter with TMR | 0% | 100% |
| 4 | Custom—Counter without TMR | 100% | 0% |
| Resource | Elements Used Original Model | Elements Used without TMR and Carry | Overhead of the Original | Total of Elements |
|---|---|---|---|---|
| ICAPs | 1 | 1 | 0.00% | 2 |
| DSP48Es | 3 | 3 | 0.00% | 64 |
| Slices | 1842 | 1847 | 0.00% | 17,280 |
| Slice Registers (as FF) | 4185 | 4169 | 0.38% | 69,120 |
| Slice Registers (as LatchThrus) | 4 | 4 | 0.00% | |
| Slice LUTs | 3567 | 3557 | 0.28% | 69,120 |
| Slice LUT-FF pairs | 3567 | 3538 | 0.82% | 69,120 |
| Total LUTs 5425 | Case Study 2—OBC with the Bus Monitor | ||
|---|---|---|---|
| Fault Injection Result Description | Total | % | |
| Error | Faults propagated to the outputs | 3916 | 72 |
| Silent/Latent | Faults that become latent silent | 1509 | 18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferlini, F.; Viel, F.; Seman, L.O.; Pettenghi, H.; Bezerra, E.A.; Leithardt, V.R.Q. A Methodology for Accelerating FPGA Fault Injection Campaign Using ICAP. Electronics 2023, 12, 807. https://doi.org/10.3390/electronics12040807
Ferlini F, Viel F, Seman LO, Pettenghi H, Bezerra EA, Leithardt VRQ. A Methodology for Accelerating FPGA Fault Injection Campaign Using ICAP. Electronics. 2023; 12(4):807. https://doi.org/10.3390/electronics12040807
Chicago/Turabian StyleFerlini, Frederico, Felipe Viel, Laio Oriel Seman, Hector Pettenghi, Eduardo Augusto Bezerra, and Valderi Reis Quietinho Leithardt. 2023. "A Methodology for Accelerating FPGA Fault Injection Campaign Using ICAP" Electronics 12, no. 4: 807. https://doi.org/10.3390/electronics12040807