1. Introduction
As an effective machine learning technique, clustering plays an important role in data mining [
1,
2,
3], statistical analysis [
4,
5,
6], and pattern recognition [
7,
8,
9]. It aims to partition the data into different clusters according to the similarity between the data samples [
10]. Therefore, various clustering methods have been developed over the past decades to extract the inherent features and structures of the data [
11,
12]. In the current era of big data, more and more high-dimensional data pose huge challenges to traditional clustering due to insufficient representability. For this reason, some dimensionality reduction [
13] and representation transformation [
14] techniques have been widely studied to map the original data into a new feature space, where the data representation is easier to separate by the existing classifiers. Nevertheless, limited to their high computational complexity, the traditional data transformation methods [
15,
16,
17] fail to process large-scale and high-dimensional data. Although some random feature [
18] methods and random projection [
19] methods can yield a low-dimensional representation and a better approximation of user-specified kernel, the representation ability of features learned from these shallow models is generally limited.
In recent decades, deep learning [
20] based on neural networks has been widely studied to discover good representation of the data. Meanwhile, the optimization of the deep neural network along with unsupervised clustering has exhibited great promise and excellent clustering performance, which is referred to as deep clustering [
21]. Most deep clustering methods can be categorized as either generative models [
22] or discriminative models [
23]. Generative models aim to learn the embedding representation or distribution of the original data through the generative process. The clustering then processes the learned distribution or representation in a simultaneous (end-to-end) or asynchronous fashion. Some of the prominent techniques that have a significant impact are deep clustering methods based on autoencoder (AE) [
24], deep clustering methods based on variational autoencoder (VAE) [
25], and deep clustering methods based on generative adversarial network (GAN) [
26]. However, these clustering methods, which rely on generative models, necessitate complex data generation procedures, which can be computationally expensive and may not be necessary for both clustering and representation learning purposes.
Different from generative models, discriminative models, such as contrastive learning-based methods, remove the costly generation step and directly discriminate the representation by learning the decision boundary. As the most representative contrastive learning method, Simple Framework for Contrastive Learning of Representations (SimCLR) [
27] exploits the representation between different views of samples, wherein the similarities between different views of one sample (positive pairs) are maximized and those between different samples (negative pairs) are minimized. Based on this idea, some two-step clustering models have been designed. Supervised Contrastive Learning for Pretrained Visual Representations (SCAN) [
28] mines the nearest neighbors of each image as prior guidance to optimize the cluster network, while Semantic Pseudo-labeling for Image Clustering (SPICE) [
29] and Robust learning for Unsupervised Clustering (RUC) [
30] generate pseudo-labels via self-learning methods to guide the clustering. These methods employed a two-stage operation where the clustering and the representation learning were decoupled. They focus more on the optimization of the neural networks to achieve more discriminative representations but suffer from a lack of clustering-oriented guidance, which results in suboptimal clustering performance.
Recently, more contrastive learning-based models have been constructed to excavate representation and perform clustering in an end-to-end fashion. Among these methods, Contrastive Clustering (CC) [
31] performs both instance-level contrastive learning for exploiting the discriminative representations and clustering-level contrastive learning for separating different clusters. Following this idea, Graph Contrastive Clustering (GCC) [
32] proposes a graph Laplacian-based contrastive loss to enhance the discriminative and clustering-specific characteristics of features. To further improve the quality of learned representations, Cross-instance guided Contrastive Clustering (C3) [
33] takes into account the cross-sample relationships, thereby increasing the number of positive pairs and reducing the impact of false negatives. Even though the contrastive models above yield excellent clustering results, they usually rely on a large number of negative pairs to capture the uniform representations, which requires a large batch size and high computational complexity. Moreover, different instances from the same cluster are regarded as negative pairs and wrongly pushed away, which may inevitably lead to the cluster collision issue.
Different from these traditional contrastive learning-based models, some self-supervised methods, such as Bootstrap Your Own Latent (BYOL) [
34], perform non-contrastive learning to capture discriminative representations only with positive pairs. However, the absence of negative pairs in contrastive learning hinders the ability of self-supervised representation learning methods to achieve uniform representations across clusters, which may lead to the issue of the collapse of clustering [
35], i.e., assigning all data samples into fewer clusters than desired. Therefore, it is crucial to introduce an effective clustering enhancement method to improve the quality of the clustering assignment.
To solve these issues, a novel end-to-end Self-supervised Clustering model based on BYOL network structure with Instance-level and Cluster-level discriminations (BSC-IC) is proposed in this paper to perform clustering and representation learning simultaneously only with positive pairs. Taking inspiration from the concept of “cluster assignments as representations” [
36], we enhance the original BYOL network by incorporating a Softmax layer to convert representations into cluster assignments. Subsequently, we also integrate adversarial learning [
37] into cluster assignments not only to improve discrimination among clusters but also to mitigate the issue of collapsed clusters. To mitigate the high interdependence between the target and online networks in BYOL, we propose a novel self-enhancement loss. This loss evaluates the similarity of cluster assignments among positive pairs within a mini-batch across the online network itself. To further enhance the clustering-oriented guidance. A new cluster-level discrimination is integrated into the discriminative network to promote clustering performance by measuring the self-correlation between the learned cluster assignments.
The rest of this paper is organized as follows. The related work is presented in
Section 2. The contrastive clustering model with instance-level and cluster-level discrimination is designed in
Section 3. Experiments are performed in
Section 4. The ablation study and its analysis are provided in
Section 5. Conclusions are given in
Section 6.
3. BSC with Instance-Level and Cluster-Level Discriminations
The contrastive-based clustering models usually rely on a large number of negative pairs to capture uniform representations, which requires a large batch size and high computational complexity. In contrast, some self-supervised methods perform non-contrastive learning to capture discriminative representations with only positive pairs but suffer from the collapse of clustering. To solve these issues, a novel end-to-end Self-supervised Clustering model based on BYOL network structure with Instance-level and Cluster-level discriminations (BSC-IC) is designed in this section.
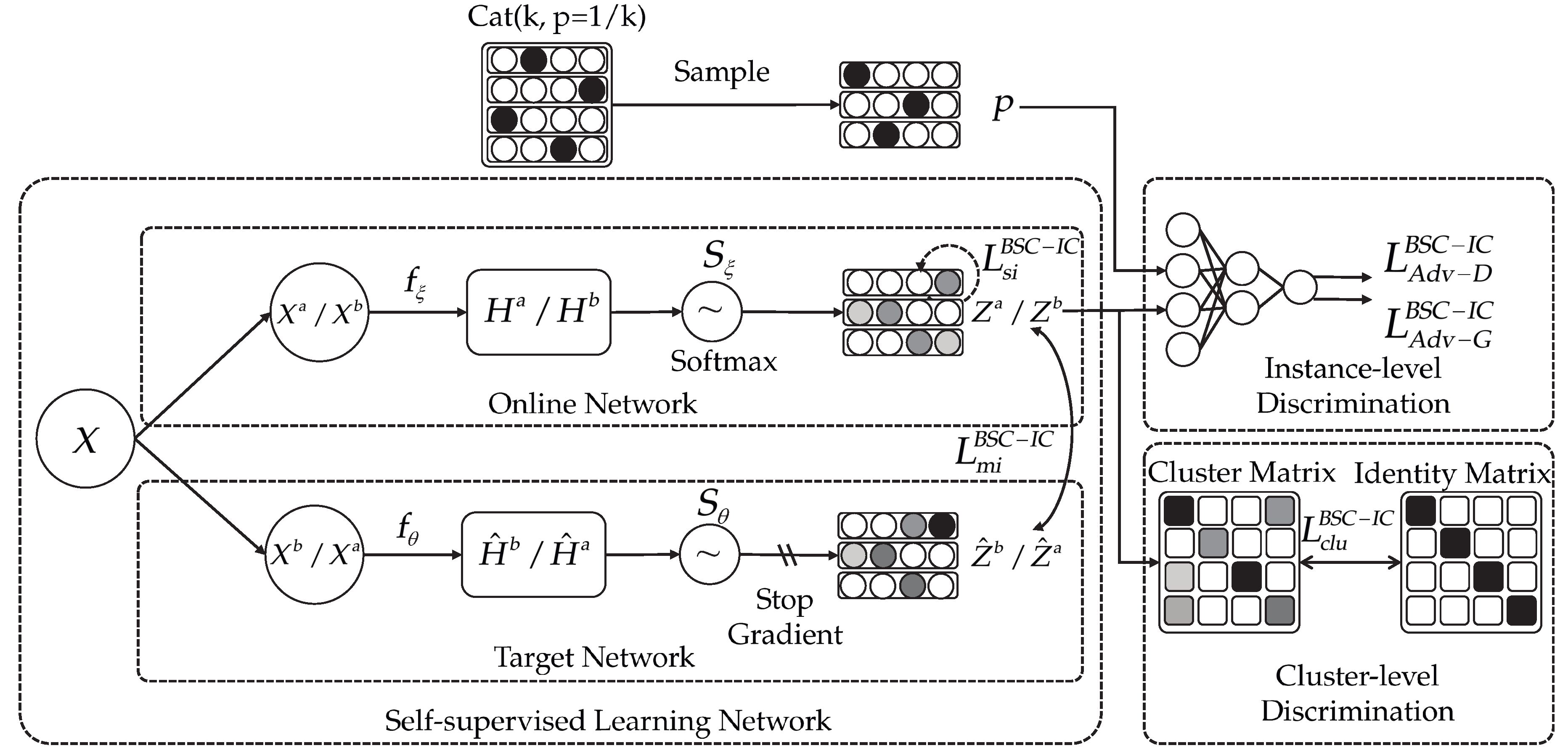
Figure 1 illustrates the framework of the BSC-IC model, which consists of three joint learning components: the self-supervised learning network, the instance-level discriminative network, and the cluster-level discriminative network. The self-supervised learning network adopts a similar structure to BYOL to capture the good cluster assignments of the data with only positive pairs, which includes an online-target network and a target network. A little different from BYOL, the Softmax layer is equipped to convert the representation to the cluster assignment. The novel instance-level discriminative network and cluster-level discriminative network are designed to provide clustering-oriented guidance for self-supervised learning.
3.1. The Self-Supervised Learning Network for Representation Capturing
The self-supervised learning network in BSC-IC is designed for representation learning, and contains an online network and a target network. The online network with parameters is defined by an encoder, , to extract the representation features, which is followed by a Softmax layer, , to convert the representation to the cluster assignment of the input data. The target network has the same architecture as the online network but adopts a different set of parameters, .
In detail, given a set of data in a mini-batch, N is the batch size and D is the dimension of the data. Data augmentations are first conducted to obtain two augmented views of the original data and as positive pairs. The first augmented view then feeds into the online network to outputs the cluster assignment . Simultaneously, the second augmented view is fed into the target network to generate the cluster assignment , where K is the number of clusters.
Self-supervised learning is then performed to maximize the similarity of positive pairs and realize the mutual optimization between the target and online networks. Unlike the cosine distance metric used in BYOL, the similarity of cluster assignments for positive pairs is measured using Kullback–Leibler (KL) divergence. The KL divergence is more suitable for capturing the difference between probability distributions. The loss for the mutual improvement in the self-supervised learning network is defined as (
1).
In order to calculate the overall mutual-improvement loss of BSC-IC, we symmetrize the loss
by separately inputting
into the target network and inputting
into the online network to compute
. Finally, the overall mutual-improvement loss of BSC-IC is denoted as (
2).
The self-supervised learning network above is made up of two highly interdependent networks, in which the poor optimization of any network can deteriorate the whole structure. Particularly, the subsequent clustering may corrupt the quality of representation space and destroy the preservation of local structure. Moreover, to break the highly mutual interdependence across online and target networks, we define a novel loss, named the self-improvement loss, as (
3) to evaluate the similarity of the cluster assignments between positive pairs of the online network itself.
where
and
indicate the cluster assignments obtained by the online network itself from two augmented views, respectively.
3.2. The Instance-Level Discriminative Network for Data Clustering
To alleviate the collapse of clustering, the instance-level discriminative network with parameters in BSC-IC is constructed to provide clustering-oriented guidance for the self-supervised learning network.
Given the data
X in a mini-batch, we input their two augmented views
and
to the online network, and obtain the corresponding cluster assignments
and
. Then, a one-hot-style prior distribution
is imposed on the learned cluster assignments
Z (the alternative to
or
), and the adversarial learning between
Z and
P is conducted to make
Z closer to the form of one-hot, so as to enhance the discrimination of clusters and alleviate the collapse problem. Referring to the WGAN-GP method [
38], the adversarial losses of the instance-level discriminative network for the generator
and the discriminator
are defined as (
4) and (
5), respectively.
where
subject to
is a representation sampled uniformly along straight lines between the prior distribution
P and the soft assignments
Z,
is the one-centered gradient penalty that limits the gradient of the instance-level discriminative network to be around 1, and
is the gradient penalty coefficient.
Here, the adversarial loss for the generator is designed to minimize the Wasserstein distance between the generated assignments and the one-hot distribution, which encourages the generator network to generate more sharp cluster assignments. In contrast, the adversarial loss for the discriminator is formulated to maximize the Wasserstein distance between the generated assignments and the one-hot distribution. Both adversarial losses train the model through the competitive process between the generator and the discriminator.
3.3. Cluster-Level Discriminations Network for Clusters Enhancement
To further benefit from the strength of capturing clustering-oriented information, a new cluster-level discrimination is integrated into the discriminative network to promote clustering performance by measuring the self-correlation between the learned cluster assignments.
Specifically, given a set of data
in a mini-batch, the online network takes in two augmented views as input, denoted as
and
. Subsequently, the cluster assignments
and
are obtained, where
N is the batch size and
K is the number of clusters. Each column of the cluster assignments can be regarded as the representation of one cluster. Let
and
be the
i-th column of
and
for
, and we combine
with
to form the same cluster pair
and leave the other
K−1 pairs as
to be different cluster pairs. A cluster-level similarity matrix
with size
K is defined in the column space of the cluster assignments, where
is measured by the cosine distance as (
6)
Then, the cluster-level discriminative loss
is defined as (
7).
where the diagonal elements as
are restricted to 1 to maximize the similarity between the same clusters, the non-diagonal elements as
are restricted to 0 to minimize the similarity between different clusters, and
is a positive constant to trade off two terms.
3.4. Training of the BSC-IC
Integrating the self-supervised learning network and the instance-level discriminative network, the final loss function of BSC-IC is defined as (
8).
The parameters
,
, and
are used to balance the significance of different loss terms. We use the adaptive moment estimation (Adam) to optimize the parameters of both the self-supervised learning network and the instance-level discriminative network. Notably, the self-supervised learning network is optimized specifically for minimizing
in respect of the online network only while keeping the target network unchanged. This is indicated by the stop-gradient operation in
Figure 1. Consequently, Equation (
9) is only used to update the parameters of the online network
.
where
is the learning rate. Drawing inspiration from BYOL, the target network’s parameters
are updated using a weighted moving average of the online parameters
. This update process can be performed using Equation (
10).
where
represent the target decay rate that controls the moving rate of parameters updating.
Similar to the online network, Equation (
11) is employed to update the parameters of the instance-level discriminative network
. And the overall algorithm of BSC-IC is presented in Algorithm 1.
| Algorithm 1 BSC-IC |
- Input:
Input data X, the batch size N, the number of clusters K, the maximum iterations -
, the hyperparameters , and . -
for epoch do -
for each batch do -
Calculate the mutual-improvement loss by ( 2), the self-improvement loss -
by ( 3), and the instance-level discriminative losses by ( 4) and -
by ( 5), the cluster-level discriminative loss by Equation ( 7); -
Calculate the self-supervised learning network loss by ( 8); -
Update the parameter of online network by ( 9); -
Update the parameter of target network by ( 10); -
Update the parameter of discriminative network by ( 11); -
end for -
end for -
Output:
The online network as clustering network.
|
4. Experiments
In this section, we perform experiments on six well-known real-world datasets to verify the efficiency of the presented model. All the datasets, methods of comparison, evaluation metrics, implementation details, and experimental results are elaborated.
4.1. Datasets, Methods in Comparison, and Evaluation Metrics
For our evaluation, we assess the effectiveness of the proposed method using six image datasets that are divided into two distinct categories. The first category consists of low-detailed grayscale images like Fashion-MNIST and MNIST. Meanwhile, the second category includes high-detailed color images, such as ImageNet-10, CIFAR-10, CIFAR-100, and Tiny-ImageNet.
Table 1 provides a concise description of these datasets.
Twenty-two mainstream clustering methods as the baseline are adopted for the comparative analysis, including traditional distance-based clustering methods, like K-means [
39], SC [
40], AC [
41], and NMF [
42]; deep generative clustering methods, such as AE [
43], DEC [
44], JULE [
45], DEPICT [
46], DAC [
47], VAE [
48], and GAN [
37]; and contrastive-based clustering models, such as IIC [
49], BYOL [
34], DCCM [
50], DCCS [
51], DHOG [
52], GATCluster [
53], DRC [
54], PICA [
55], CC [
31], GCC [
32], and C3 [
33]. It is important to mention that clustering results for the NMF, SC, AE, GAN, VAE, and BYOL methods are obtained by applying k-means on the extracted image features.
Three metrics, i.e., the clustering accuracy (ACC), the normalized mutual information (NMI), and the adjusted rand index (ARI), are utilized to evaluate the clustering performance of different algorithms. For all metrics, a higher value is better. All clustering algorithms are conducted on a computer with two Nvidia TITAN RTX 24G GPUs.
4.2. Implementation Details
Similar image augmentations as DCCS [
51] and CC [
31] are conducted first to obtain the augmented samples. For low-detailed grayscale image datasets, cropping and horizontal flipping are employed as the augmentation strategies. For high-detailed color image datasets, color distortion and grayscale conversion are incorporated. Specifically, the color distortion method alters various attributes of the image, including contrast, saturation, brightness, and hue, while the grayscale conversion step transforms the color image into a grayscale format.
ResNet-18 is employed to extract the representation for the self-supervised learning network of BSC-IC. A Softmax layer is used to convert the representation into the cluster assignment of data with a dimension of cluster number K. A three-layer fully connected network is utilized as the instance-level discriminative network to divide the data samples into different clusters, and the dimensions of various layers are set to K-1024-512-1.
The Adam optimizer with a learning rate of 0.0003 is adopted to simultaneously optimize the self-supervised learning network and the discriminative network. The moving average parameter
in the self-supervised learning network is set to 0.99, the discriminative network’s gradient penalty coefficient
is set to 10, and the default batch size
N is set to 64. The BSC-IC model involves three control parameters, which are utilized to trade off the effects of different terms in the total loss function. The recommended values of various parameters on different datasets are listed in
Table 2.
Table 3 lists the number of hyperparameters of different models. It can be seen that the proposed BSC-IC model has fewer hyperparameters compared with other models, which indicates a simpler model architecture and ease for parameter tuning in BSC-IC.
4.3. Experimental Results
The clustering results of the testing algorithms on six datasets in terms of ACC, NMI, and ARI are listed in
Table 4,
Table 5, and
Table 6, separately, and reveal some interesting observations. The best results are shown in bold.
First and foremost, compared with the traditional distance-based clustering methods, like K-means, AC, NMF, and SC, all the deep clustering methods show obvious advantages. This emphasizes that deep clustering has the ability to enhance clustering performance by the capturing semantic information of samples through deep neural networks.
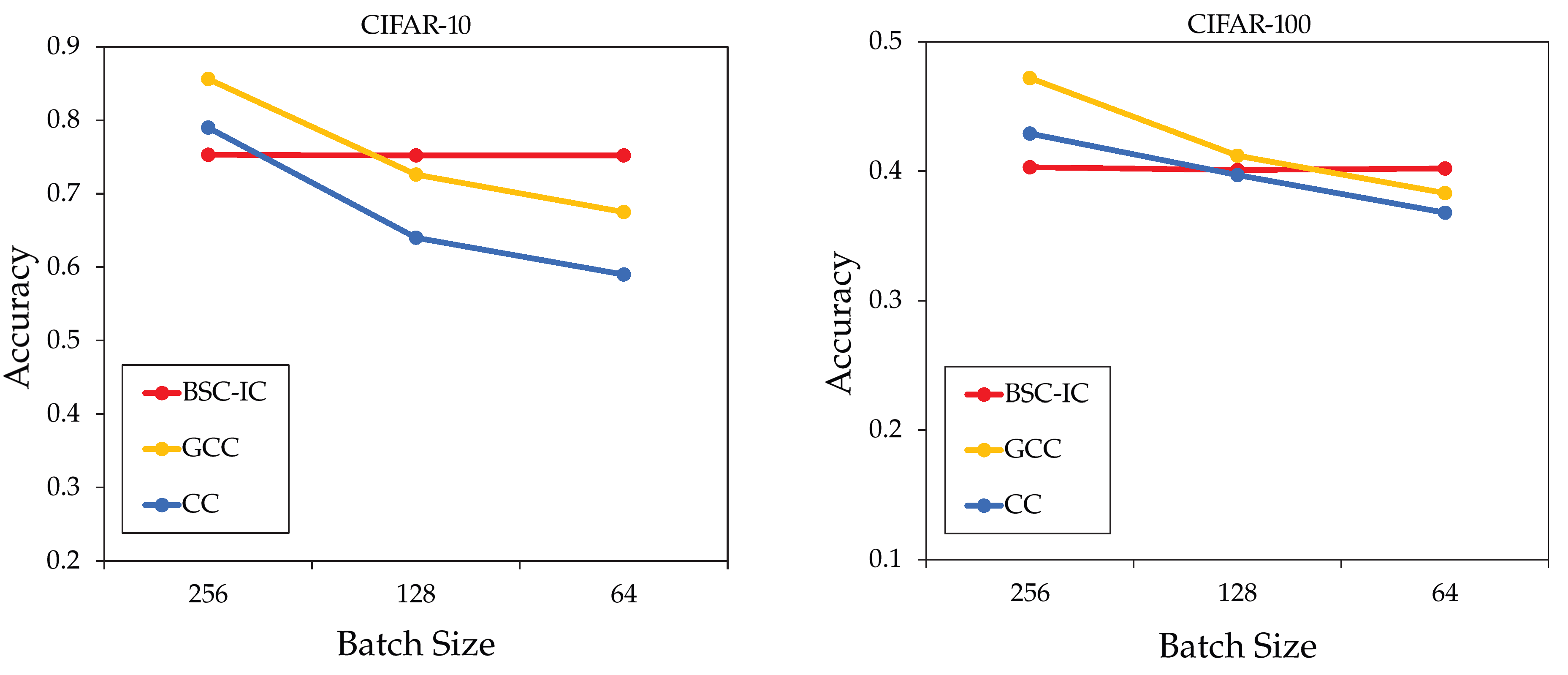
Secondly, BSC-IC significantly outperforms most deep clustering methods on all six datasets. This demonstrates the efficiency of self-supervised representation learning only with positive pairs in our model, which helps to extract the similarities and dissimilarities between different views of samples and capture important clustering-orientated information. It is worth noting that GCC achieves the best performance on the CIFAR-10 and CIFAR-100 datasets. But this relies on a large number of negative pairs to capture the uniform representations, which requires a large batch size, like 256, and high computational complexity. In our model, a smaller batch size, like 64, and only positive pairs can also achieve good clustering performance.
Figure 2 shows the ACC curves obtained by CC, GCC, and our model with different batch sizes on the CIFAR-10 and CIFAR-100 datasets. It can be seen that the ACCs of CC and GCC drop sharply with the decrease in batch size. Specifically, when the batch size changes from 256 to 64, the ACC of GCC drops by approximately 18 percentage points on the CIFAR-10 dataset and 9 percentage points on the CIFAR-100 dataset. Similarly, the ACC of CC drops by about 20 percentage points on the CIFAR-10 dataset and 6 percentage points on the CIFAR-100 dataset. In contrast, our model yields a more stable ACC without the influence of the value of the batch size.
5. Ablation Study and Analysis
The ablation study and analysis are carried out in this section to further understand the effect of each term in the loss function, including the self-improvement term (denoted as SI), the mutual-improvement term (denoted as MI), the instance-level discriminative term (denoted as IL), and the cluster-level discriminative term (denoted as CL). The ablation study of BSC-IC on the MNIST and ImageNet-10 datasets is presented in
Table 7. The check mark and the cross mark respectively represent the inclusion and exclusion of each terms.
In the discriminative network, the instance-level discriminative term focuses on optimizing the assignment of instances within clusters, while the cluster-level discriminative term aims to optimize the relationships between clusters. Together, they provide effective clustering guidance for self-supervised learning. From ➀ and ➁ in
Table 7, it can be seen that the absence of any of them will lead to a suboptimal solution for cluster assignments. The most fatal is that the absence of both of them will lead to a collapse of the clustering as ➂ in
Table 7.
In the self-supervised learning network, the self-improvement term aims to ensure the stability of the network structure, while the mutual-improvement term provides the alignment between positive pairs for the capture of uniform representations. Together, they provide effective optimization over the online and target networks for the capture of discriminative representations. From ➃ and ➄ in
Table 7, it can be seen that the absence of any of them will lead to a decrease in cluster accuracy. Moreover, the absence of both terms as ➅ will disrupt the optimization over the online and target networks and prevent our method from performing clustering.

 ,
, 


{kind=link}
{kind=link}