
Personalized Text-to-Image Model Enhancement Strategies: SOD Preprocessing and CNN Local Feature Integration

Abstract
:1. Introduction
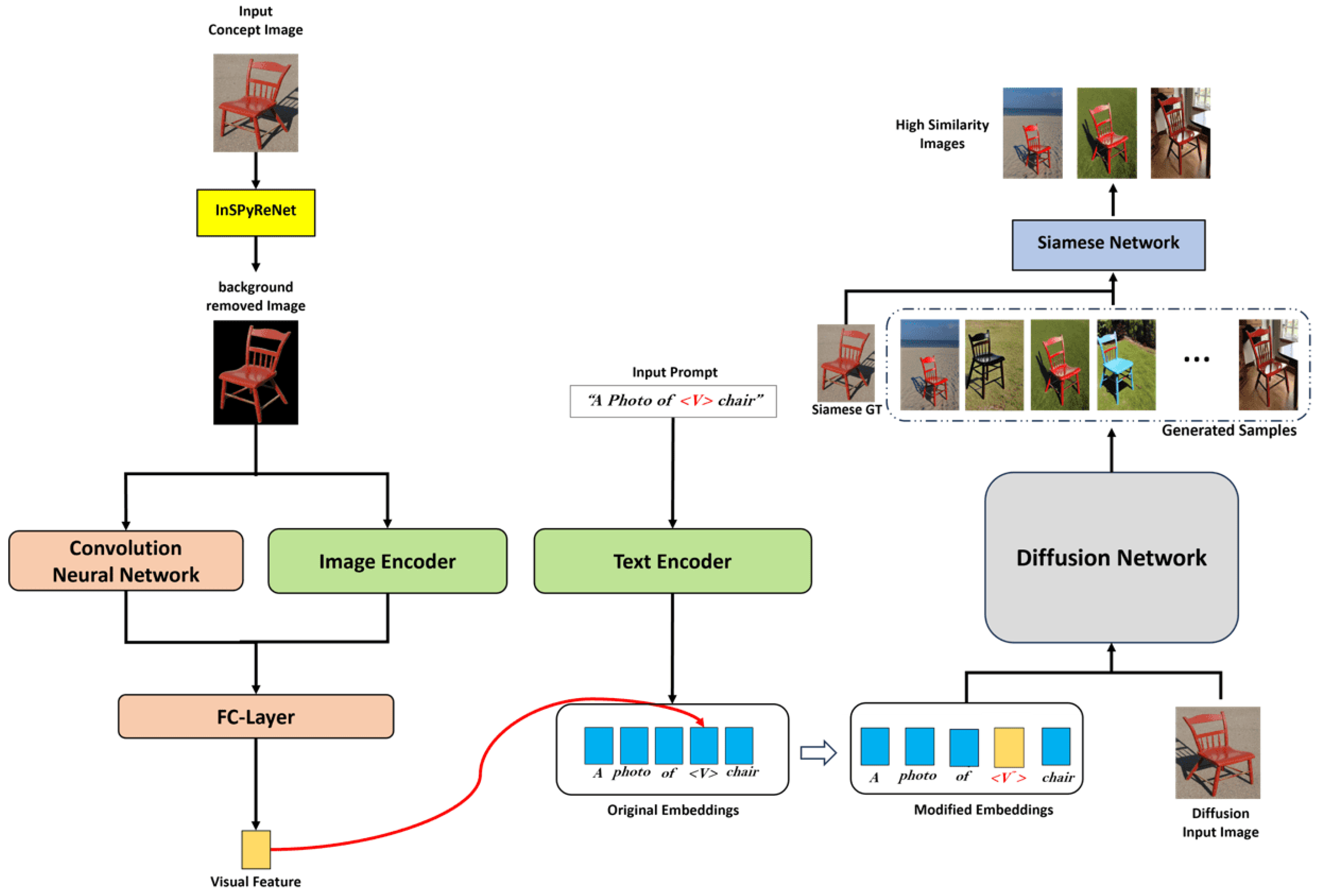
- We have introduced the use of a salient object detection (SOD) mask in the preprocessing phase to remove information other than the prominent object. This ensures that the image generation process is focused on the target object, thereby avoiding the degradation of image quality by irrelevant information.
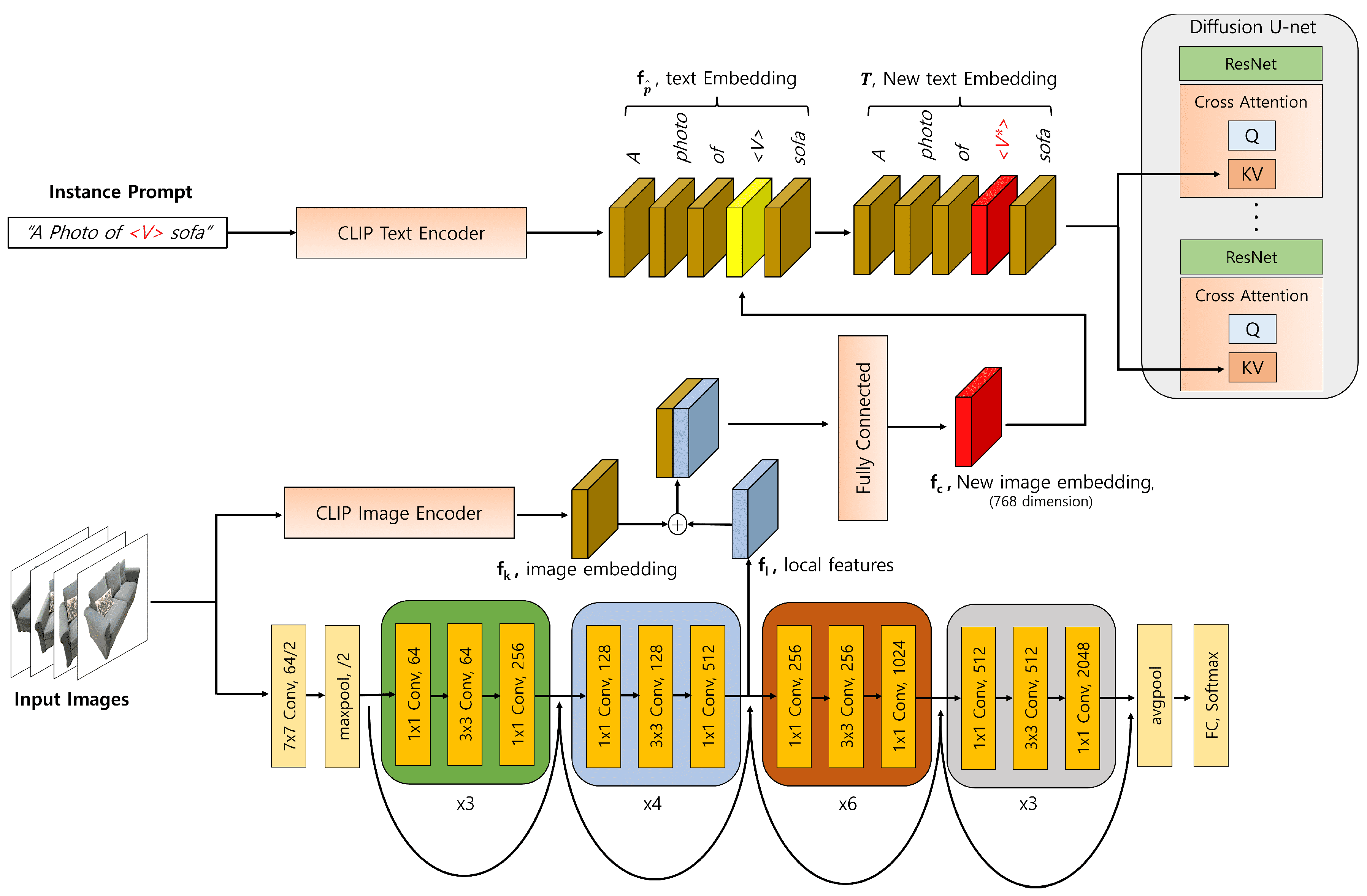
- Instead of relying on text embeddings that represent identifiers, we have mapped the image embeddings obtained from concept images and provided additional local features. This has improved the detail preservation performance of our models.
- We have employed a Siamese network in the postprocessing phase to compare the similarity between the generated images and the concept images, which allows for quality control. This ensures that only the images with high fidelity are selected, enhancing the overall quality of the output.
2. Related Work
2.1. Text-to-Image Models
2.2. Personalized Image Generation
2.3. Salient Object Detetion
2.4. Image Similarity Comparison
3. Method
3.1. Text-to-Image Diffusion Models
3.2. Data Preprocessing with SOD
3.3. Concept Embedding to Text Prompt
3.4. Image Similarity Measurement Using Siamese Networks
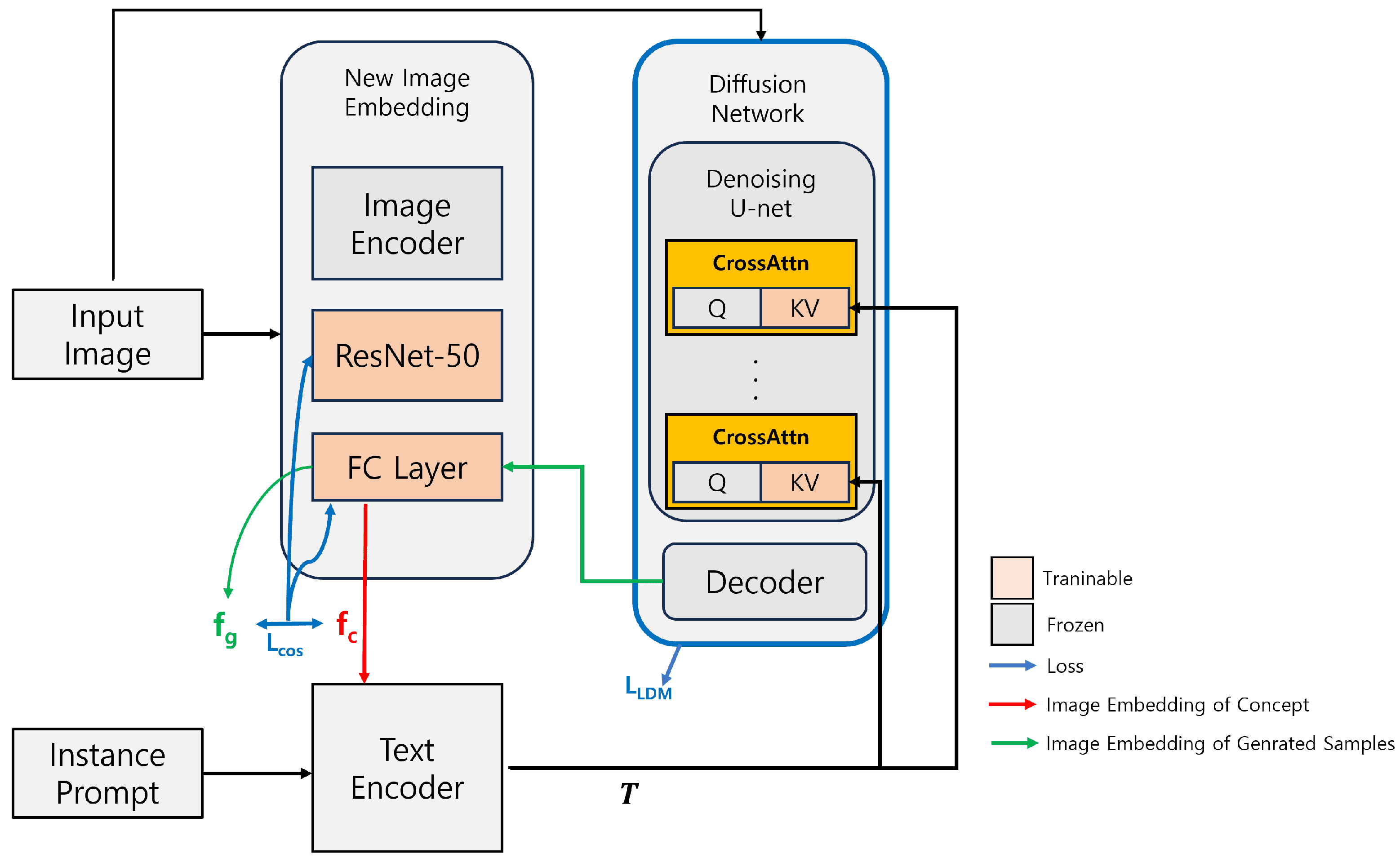
3.5. Model Training
3.5.1. Training Loss
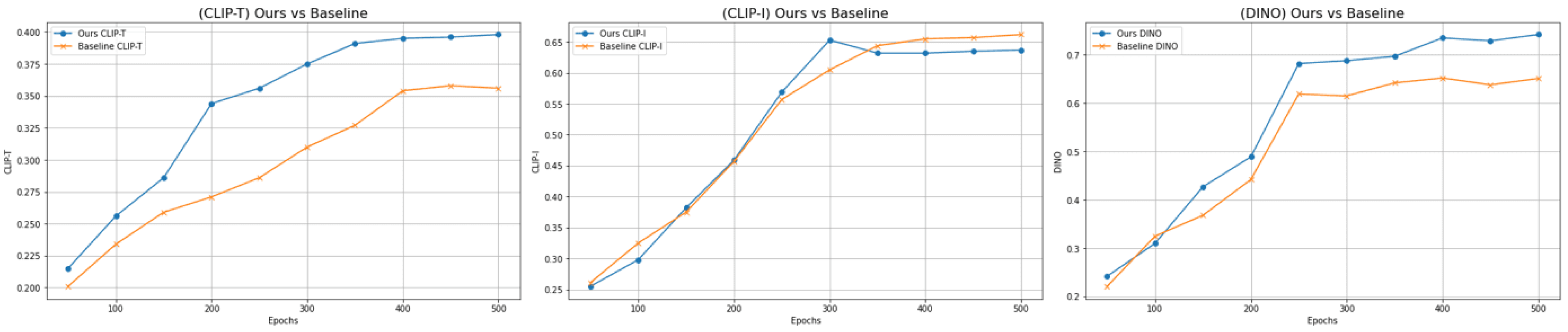
3.5.2. Results Per Training Epochs
4. Experiment
4.1. Dataset and Evaluation
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.2. Implementation Details
4.3. Ablation Study
4.3.1. Preprocessing Using SOD Mask
4.3.2. Cosine Similarity Loss Ablation
4.4. Qualitative Results
Visual Comparison
4.5. Failure Cases
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; Volume 10, pp. 10684–10695. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T.; et al. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36479–36494. [Google Scholar]
- Wang, P.; Yang, A.; Men, R.; Lin, J.; Bai, S.; Li, Z.; Ma, J.; Zhou, C.; Zhou, J.; Yang, H. OFA: Unifying Architectures, Tasks, and Modalities through a Simple Sequence-to-Sequence Learning Framework. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 23318–23340. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Zhang, Y.; Huang, N.; Tang, F.; Huang, H.; Ma, C.; Dong, W.; Xu, C. Inversion-Based Style Transfer with Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 10146–10156. [Google Scholar]
- Balaji, Y.; Nah, S.; Huang, X.; Vahdat, A.; Song, J.; Kreis, K.; Liu, M.Y. eDiffi: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers. arXiv 2022, arXiv:2211.01324. [Google Scholar]
- Tumanyan, N.; Geyer, M.; Bagon, S.; Dekel, T. Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1921–1930. [Google Scholar]
- Sohn, K.; Ruiz, N.; Lee, K.; Chin, D.C.; Blok, I.; Chang, H.; Krishnan, D. StyleDrop: Text-to-Image Generation in Any Style. arXiv 2023, arXiv:2306.00983. [Google Scholar]
- Hertz, A.; Mokady, R.; Tenenbaum, J.; Aberman, K.; Pritch, Y.; Cohen-Or, D. Prompt-to-Prompt Image Editing with Cross Attention Control. arXiv 2022, arXiv:2208.01626. [Google Scholar]
- Kawar, B.; Zada, S.; Lang, O.; Tov, O.; Chang, H.; Dekel, T.; Irani, M. Imagic: Text-based Real Image Editing with Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6007–6017. [Google Scholar]
- Nichol, A.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; McGrew, B.; Chen, M. Glide: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. arXiv 2021, arXiv:2112.10741. [Google Scholar]
- Ruiz, N.; Li, Y.; Jampani, V.; Pritch, Y.; Rubinstein, M.; Aberman, K. Dreambooth: Fine Tuning Text-to-Image Diffusion Models for Subject-driven Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 22500–22510. [Google Scholar]
- Kumari, N.; Zhang, B.; Zhang, R.; Shechtman, E.; Zhu, J.Y. Multi-concept Customization of Text-to-Image Diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1931–1941. [Google Scholar]
- Gal, R.; Alaluf, Y.; Atzmon, Y.; Patashnik, O.; Bermano, A.H.; Chechik, G.; Cohen-Or, D. An Image is Worth One Word: Personalizing Text-to-Image Generation Using Textual Inversion. arXiv 2022, arXiv:2208.01618. [Google Scholar]
- Wei, Y.; Zhang, Y.; Ji, Z.; Bai, J.; Zhang, L.; Zuo, W. Elite: Encoding Visual Concepts into Textual Embeddings for Customized Text-to-Image Generation. arXiv 2023, arXiv:2302.13848. [Google Scholar]
- Shi, J.; Xiong, W.; Lin, Z.; Jung, H.J. Instantbooth: Personalized Text-to-Image Generation without Test-Time Finetuning. arXiv 2023, arXiv:2304.03411. [Google Scholar]
- Kim, T.; Kim, K.; Lee, J.; Cha, D.; Lee, J.; Kim, D. Revisiting Image Pyramid Structure for High Resolution Salient Object Detection. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 108–124. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese Neural Networks for One-Shot Image Recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. No. 1. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sutskever, I. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative Adversarial Text to Image Synthesis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1060–1069. [Google Scholar]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-to-Image Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5802–5810. [Google Scholar]
- Liao, W.; Hu, K.; Yang, M.Y.; Rosenhahn, B. Text to Image Generation with Semantic-Spatial Aware GAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18187–18196. [Google Scholar]
- Gal, R.; Patashnik, O.; Maron, H.; Bermano, A.H.; Chechik, G.; Cohen-Or, D. StyleGAN-NADA: CLIP-guided Domain Adaptation of Image Generators. Acm Trans. Graph. (TOG) 2022, 41, 1–13. [Google Scholar] [CrossRef]
- Patashnik, O.; Wu, Z.; Shechtman, E.; Cohen-Or, D.; Lischinski, D. StyleCLIP: Text-driven Manipulation of StyleGAN Imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2085–2094. [Google Scholar]
- Ding, M.; Yang, Z.; Hong, W.; Zheng, W.; Zhou, C.; Yin, D.; Tang, J. Cogview: Mastering Text-to-Image Generation via Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 19822–19835. [Google Scholar]
- Chang, H.; Zhang, H.; Barber, J.; Maschinot, A.J.; Lezama, J.; Jiang, L.; Krishnan, D. Muse: Text-to-Image Generation via Masked Generative Transformers. arXiv 2023, arXiv:2301.00704. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-Shot Text-to-Image Generation. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; Volume 139, pp. 8821–8831. [Google Scholar]
- Zhang, Z.; Han, L.; Ghosh, A.; Metaxas, D.N.; Ren, J. Sine: Single Image Editing with Text-to-Image Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6027–6037. [Google Scholar]
- Li, Y.; Liu, H.; Wu, Q.; Mu, F.; Yang, J.; Gao, J.; Li, C.; Lee, Y.J. GLIGEN: Open-Set Grounded Text-to-Image Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 22511–22521. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding Conditional Control to Text-to-Image Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 18–22 June 2023; pp. 3836–3847. [Google Scholar]
- Makhmudkhujaev, F.; Hong, S.; Park, I.K. Re-Aging GAN: Toward Personalized Face Age Transformation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3908–3917. [Google Scholar]
- Kim, H.; Choi, Y.; Kim, J.; Yoo, S.; Uh, Y. Exploiting Spatial Dimensions of Latent in GAN for Real-Time Image Editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 852–861. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Hou, Q.; Cheng, M.-M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H.S. Deeply Supervised Salient Object Detection With Short Connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3203–3212. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Xie, C.; Xia, C.; Ma, M.; Zhao, Z.; Chen, X.; Li, J. Pyramid Grafting Network for One-Stage High Resolution Saliency Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11717–11726. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. Multi-Scale Interactive Network for Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9413–9422. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: New York, NY, USA, 2011; pp. 2564–2571. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep Metric Learning Using Triplet Network. In Similarity-Based Pattern Recognition, Proceedings of the Third International Workshop, SIMBAD 2015, Copenhagen, Denmark, 12–14 October 2015; Proceedings 3; Springer International Publishing: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Barz, B.; Denzler, J. Deep learning on small datasets without pre-training using cosine loss. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1371–1380. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning Machine Learning, PMLR, Virtual, 13–18 June 2020; pp. 1597–1607. [Google Scholar]
- Cheng, H.K.; Chung, J.; Tai, Y.W.; Tang, C.K. Cascadepsp: Toward class-agnostic and very high-resolution segmentation via global and local refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8890–8899. [Google Scholar]
- Unsplash. Available online: https://unsplash.com/ (accessed on 8 November 2023).
- Schuhmann, C.; Vencu, R.; Beaumont, R.; Kaczmarczyk, R.; Mullis, C.; Katta, A.; Coombes, T.; Jitsev, J.; Komatsuzaki, A. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv 2021, arXiv:2111.02114. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Bińkowski, M.; Sutherland, D.J.; Arbel, M.; Gretton, A. Demystifying mmd gans. arXiv 2018, arXiv:1801.01401. [Google Scholar]
- Stable-Diffusion v1-4. 2022. Available online: https://huggingface.co/CompVis/stable-diffusion-v-1-4-original (accessed on 11 November 2023).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | CLIP-T ↑ | CLIP-I↑ | DINO↑ | KID↓ |
|---|---|---|---|---|
| Textual Inversion | 0.259 | 0.586 | 0.428 | 32.2 |
| DreamBooth | 0.421 | 0.785 | 0.654 | 16.7 |
| Custom Diffusion | 0.440 | 0.882 | 0.666 | 8.21 |
| Ours | 0.460 | 0.852 | 0.743 | 8.83 |
| Method | CLIP-T ↑ | CLIP-I↑ | DINO↑ | KID↓ |
|---|---|---|---|---|
| w/o SOD mask | 0.415 | 0.657 | 0.572 | 18.2 |
| with SOD mask | 0.424 | 0.763 | 0.691 | 14.5 |
| Method | CLIP-T ↑ | CLIP-I↑ | DINO↑ | KID↓ |
|---|---|---|---|---|
| 0.672 | 0.671 | 0.418 | 6.85 | |
| 0.677 | 0.698 | 0.412 | 6.34 | |
| 0.655 | 0.693 | 0.455 | 7.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Yoo, J.; Kwon, S. Personalized Text-to-Image Model Enhancement Strategies: SOD Preprocessing and CNN Local Feature Integration. Electronics 2023, 12, 4707. https://doi.org/10.3390/electronics12224707
Kim M, Yoo J, Kwon S. Personalized Text-to-Image Model Enhancement Strategies: SOD Preprocessing and CNN Local Feature Integration. Electronics. 2023; 12(22):4707. https://doi.org/10.3390/electronics12224707
Chicago/Turabian StyleKim, Mujung, Jisang Yoo, and Soonchul Kwon. 2023. "Personalized Text-to-Image Model Enhancement Strategies: SOD Preprocessing and CNN Local Feature Integration" Electronics 12, no. 22: 4707. https://doi.org/10.3390/electronics12224707