
An Iterative Learning Scheme with Binary Classifier for Improved Event Detection in Surveillance Video



Abstract
:1. Introduction
2. Related Work
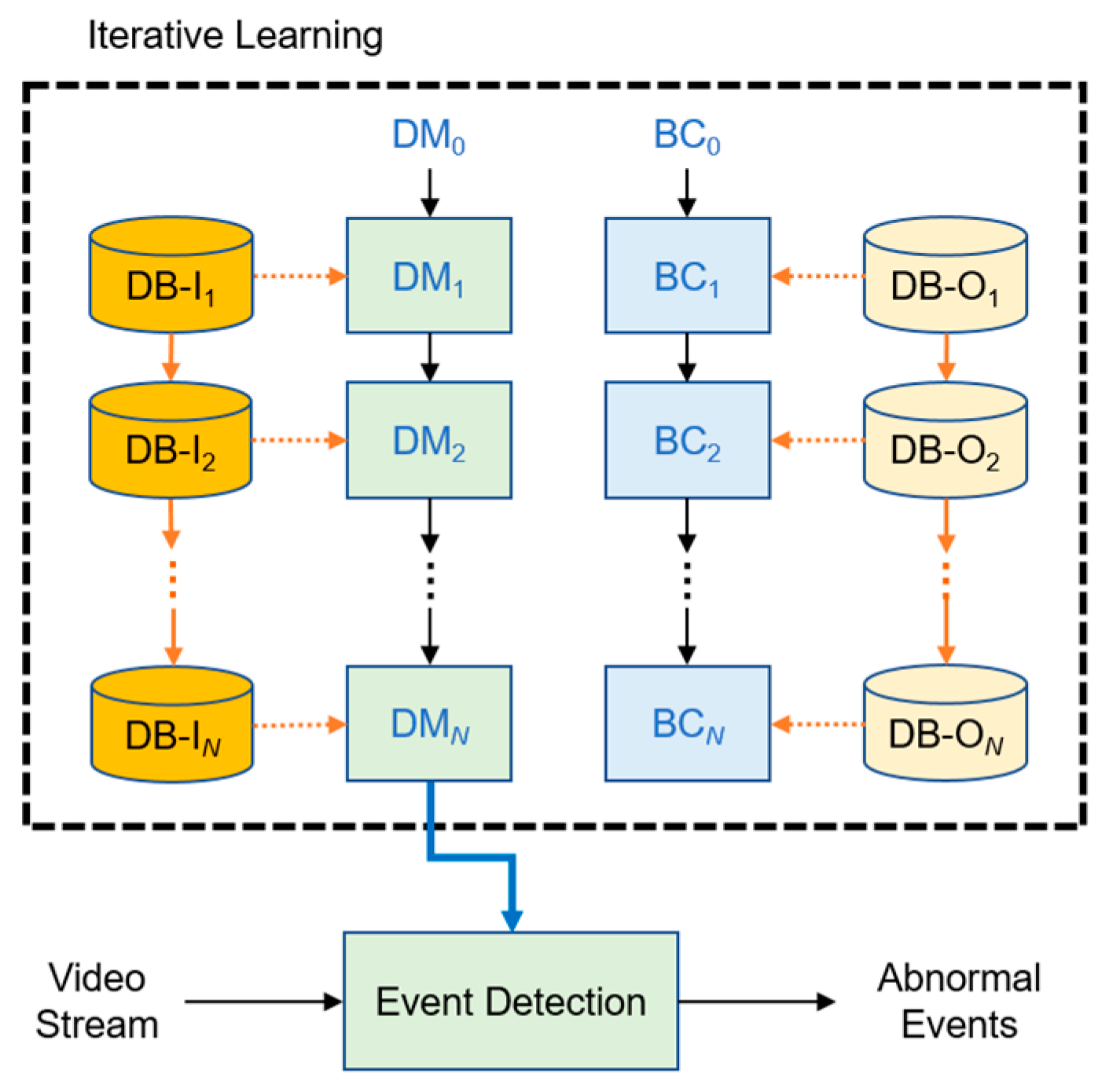
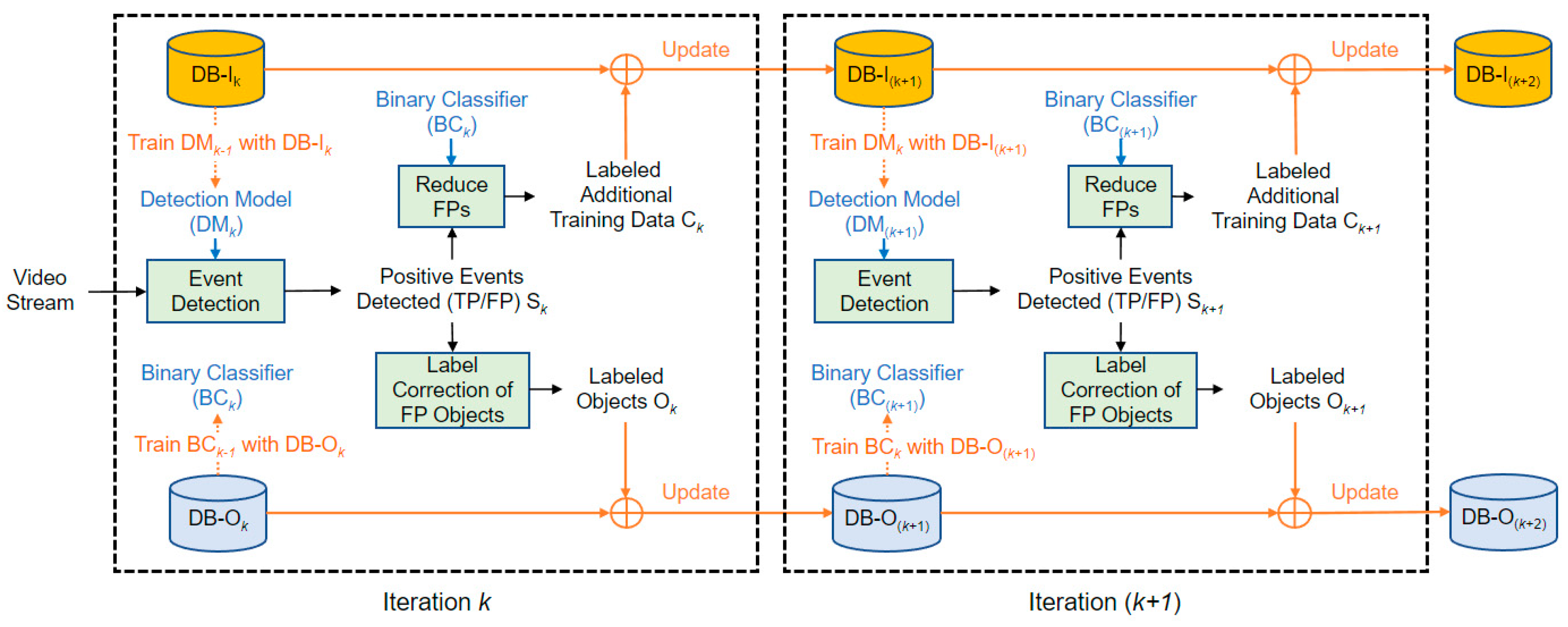
3. Iterative Training of the Detection Model with a Binary Classifier
3.1. Iterative Training Process
3.2. The Model Architectures
3.2.1. Detection Model
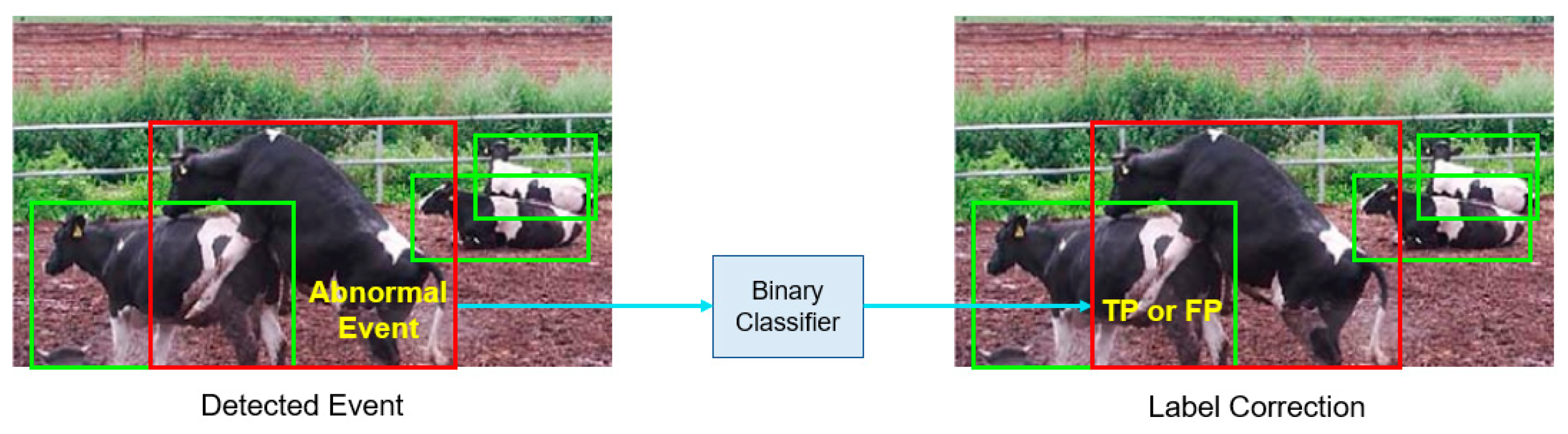
3.2.2. Binary Classifier
4. Experimental Results
4.1. Data Collection
4.2. Building a Base Model for Estrus Cow Detection
4.2.1. Detection Model Implementation
4.2.2. Training the Base Detection Models
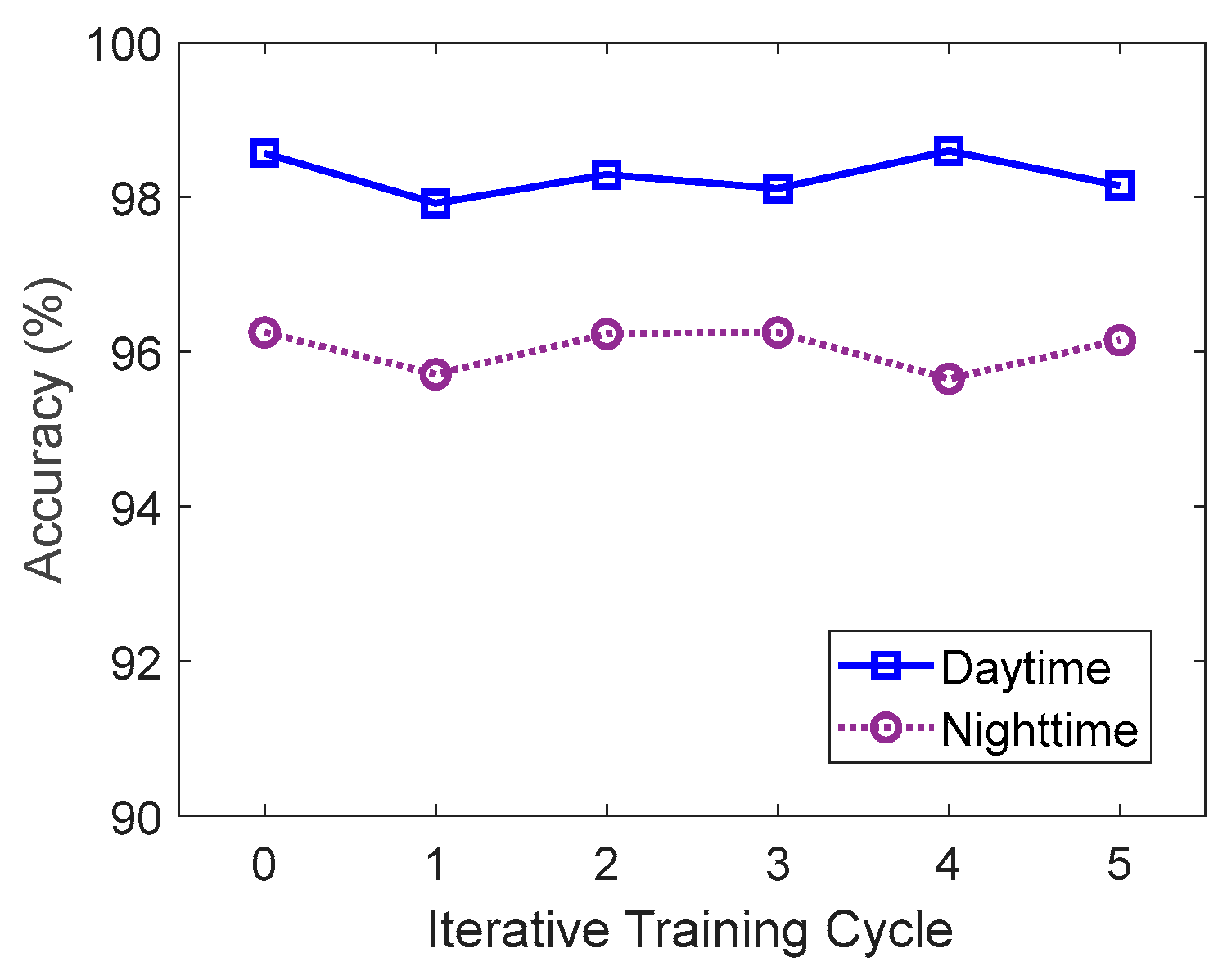
4.3. Iterative Training of the Detection Model
5. Ablation Study
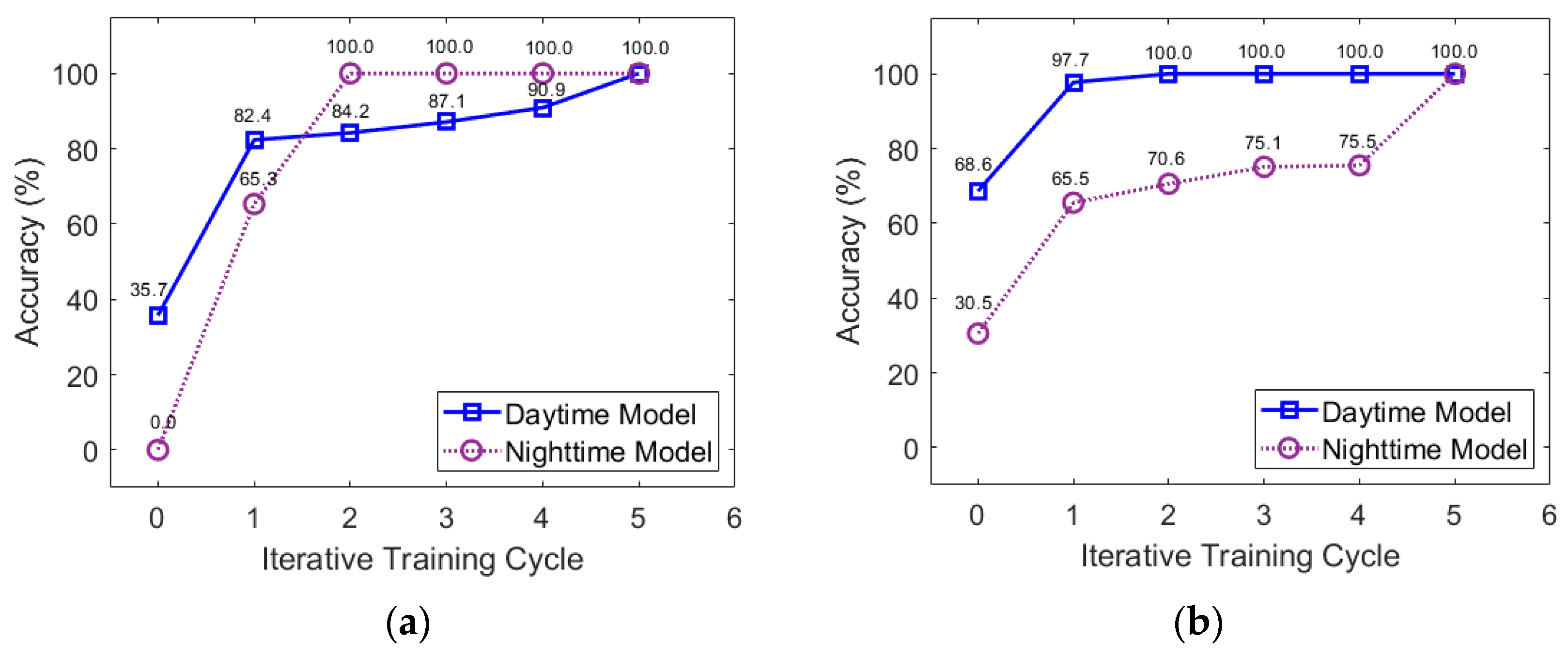
5.1. Iterative Training with Manual Labeling
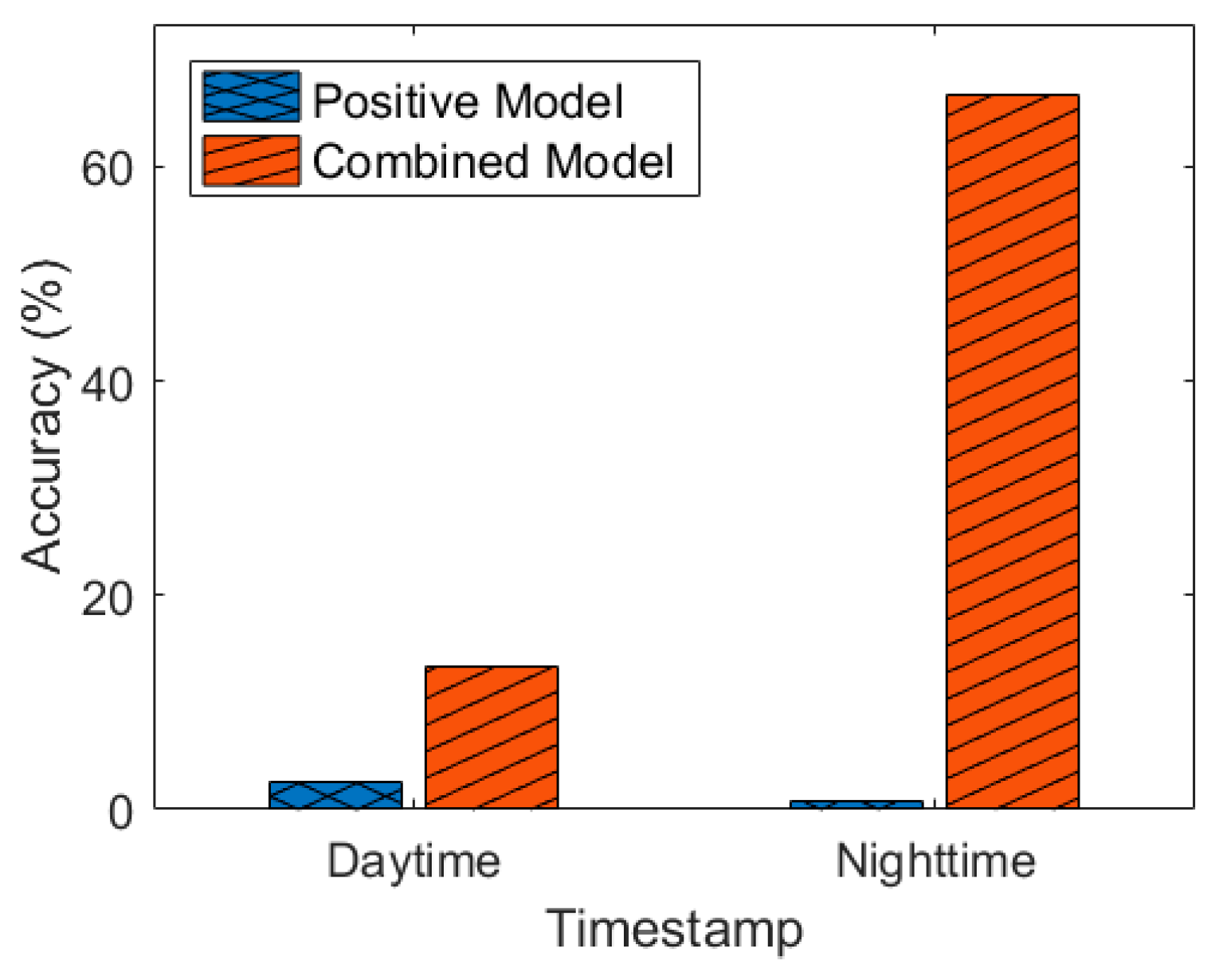
5.2. Positive Training versus Negative Training
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6479–6488. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; Michael, K.; TaoXie; Fang, J.; imyhxy; et al. ultralytics/yolov5: v7.0—YOLOv5 SOTA Realtime Instance Segmentation. Available online: https://zenodo.org/record/7347926#.Y9XPmq1BxPY (accessed on 10 September 2022).
- Fang, M.; Chen, Z.; Przystupa, K.; Li, T.; Majka, M.; Kochan, O. Examination of abnormal behavior detection based on improved YOLOv3. Electronics 2021, 10, 197. [Google Scholar] [CrossRef]
- Balamurugan, G.; Ravi, G.; Shanthakumar, R.G.; Chandru, J. Abnormal Event Detection in Video Surveillance Using Yolov3. J. Algebr. Stat. 2022, 13, 2988–2998. [Google Scholar]
- Ji, H.; Zeng, X.; Li, H.; Ding, W.; Nie, X.; Zhang, Y.; Xiao, Z. Human abnormal behavior detection method based on T-TINY-YOLO. In Proceedings of the 5th International Conference on Multimedia and Image Processing, Nanjing, China, 10–12 January 2020; pp. 1–5. [Google Scholar]
- Hu, C.; Chen, Y.; Hu, L.; Peng, X. A novel random forests-based class incremental learning method for activity recognition. Pattern Recognit. 2018, 78, 277–290. [Google Scholar] [CrossRef]
- Xiao, Q.; Song, R. Action recognition based on hierarchical dynamic Bayesian network. Multimed. Tools Appl. 2018, 77, 6955–6968. [Google Scholar] [CrossRef]
- Sok, P.; Xiao, T.; Azeze, Y.; Jayaraman, A.; Albert, M.V. Activity recognition for incomplete spinal cord injury subjects using hidden markov models. IEEE Sens. J. 2018, 18, 6369–6374. [Google Scholar] [CrossRef] [Green Version]
- Abidine, B.M.; Fergani, L.; Fergani, B.; Oussalah, M. The joint use of sequence features combination and modified weighted SVM for improving daily activity recognition. Pattern Anal. Appl. 2018, 21, 119–138. [Google Scholar] [CrossRef]
- Hu, X.; Hu, S.; Huang, Y.; Zhang, H.; Wu, H. Video anomaly detection using deep incremental slow feature analysis network. IET Comput. Vis. 2016, 10, 258–267. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef] [Green Version]
- Oyedotun, O.K.; Khashman, A. Deep learning in vision-based static hand gesture recognition. Neural Comput. Appl. 2017, 28, 3941–3951. [Google Scholar] [CrossRef]
- Tung, F.; Zelek, J.S.; Clausi, D.A. Goal-based trajectory analysis for unusual behaviour detection in intelligent surveillance. Image Vis. Comput. 2011, 29, 230–240. [Google Scholar] [CrossRef] [Green Version]
- Navneet, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the Computer Vision and Pattern Recognition Conference, San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Adam, A.; Rivlin, E.; Shimshoni, I.; Reinitz, D. Robust real-time unusual event detection using multiple fixed-location monitors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 555–560. [Google Scholar] [CrossRef] [PubMed]
- Zhao, B.; Li, F.; Xing, E.P. Online detection of unusual events in videos via dynamic sparse coding. In Proceedings of the Computer Vision and Pattern Recognition Conference, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3313–3320. [Google Scholar]
- Lu, C.; Shi, J.; Jia, J. Abnormal event detection at 150 fps in MATLAB. In Proceedings of the International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2720–2727. [Google Scholar]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhurry, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 733–742. [Google Scholar]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future frame prediction for anomaly detection—A new baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6536–6545. [Google Scholar]
- Luo, W.; Liu, W.; Gao, S. A revisit of sparse coding-based anomaly detection in stacked RNN framework. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 341–349. [Google Scholar]
- Li, Y.; Dai, Z. Abnormal Behavior Detection in Crowd Scene Using YOLO and Conv-AE. In Proceedings of the 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 1720–1725. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- CVAT. ai Corporation Computer Vision Annotation Tool (CVAT). Zenodo 2022. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Method | Advantages | Disadvantages |
|---|---|---|---|
| Handcrafted feature-based | Low-level trajectories [14] |
|
|
| HOG [15] | |||
| Flow features [16] | |||
| Sparse coding-based | Normal sparse coding dictionary [17,18] |
|
|
| Deep learning based | AutoEncoder [19] |
|
|
| GANs [20] | |||
| Stacked RNN [21] | |||
| YOLO [4,5,6,22] | |||
| Proposed | Iterative training with binary classifier |
|
|
| Training | Testing | |||
|---|---|---|---|---|
| Estrus | Non-Estrus | Estrus | Non-Estrus | |
| Daytime | 4503 | 844 | 1129 | 208 |
| Nighttime | 623 | 774 | 168 | 182 |
| Total | 5126 | 1618 | 1297 | 390 |
| Training | Testing | |||
|---|---|---|---|---|
| Estrus | Non-Estrus | Estrus | Non-Estrus | |
| Daytime | 4500 | 2064 | 1126 | 517 |
| Nighttime | 632 | 1038 | 158 | 260 |
| Total | 5132 | 3102 | 1284 | 777 |
| Precision | Recall | mAP@0.5 | mAP@0.5:0.95 | |
|---|---|---|---|---|
| Daytime | 0.968 | 0.967 | 0.984 | 0.794 |
| Nighttime | 0.945 | 0.93 | 0.968 | 0.758 |
| Confidence Thresholds | ||||
|---|---|---|---|---|
| 0.25 | 0.5 | 0.75 | 0.8 | |
| Daytime | 0.991 | 0.990 | 0.938 | 0.901 |
| Nighttime | 0.977 | 0.974 | 0.929 | 0.891 |
| Models | Metrics | Iteration (k) | |||||
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | ||
| Daytime | Precision | 0.975 | 0.966 | 0.974 | 0.967 | 0.971 | 0.968 |
| Recall | 0.985 | 0.976 | 0.977 | 0.979 | 0.989 | 0.980 | |
| F1-score | 0.980 | 0.971 | 0.976 | 0.973 | 0.979 | 0.974 | |
| Accuracy | 0.986 | 0.979 | 0.983 | 0.981 | 0.986 | 0.982 | |
| Nighttime | Precision | 0.973 | 0.966 | 0.964 | 0.964 | 0.958 | 0.971 |
| Recall | 0.977 | 0.976 | 0.987 | 0.987 | 0.977 | 0.976 | |
| F1-score | 0.975 | 0.971 | 0.975 | 0.975 | 0.967 | 0.973 | |
| Accuracy | 0.962 | 0.955 | 0.962 | 0.963 | 0.950 | 0.962 | |
| Test Stream | Detection Models | Iteration (k) | |||||
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | ||
| Stream 1 | Daytime | 0.737 | 0.964 | 0.988 | 0.989 | 0.991 | 0.995 |
| Nighttime | 0.00 | 0.955 | 0.995 | 0.995 | 0.995 | 0.995 | |
| Stream 2 | Daytime | 0.951 | 0.985 | 0.995 | 0.995 | 0.995 | 0.995 |
| Nighttime | 0.761 | 0.955 | 0.959 | 0.963 | 0.963 | 0.995 | |
| Test Stream | Iteration (k) | Number of Additional Training Images | Manual Labeling | Binary Classifier | |||
|---|---|---|---|---|---|---|---|
| Expert 1 | Expert 2 | Expert 3 | Average | ||||
| Stream 1 | 0 | 184 | 2036 | 2025 | 2040 | 2034 | 12 |
| 1 | 48 | 481 | 451 | 460 | 464 | 5 | |
| 2 | 56 | 601 | 573 | 581 | 585 | 5 | |
| 3 | 43 | 344 | 341 | 337 | 341 | 4 | |
| 4 | 32 | 298 | 300 | 295 | 895 | 3 | |
| 5 | 15 | 152 | 148 | 157 | 152 | 2 | |
| Stream 2 | 0 | 110 | 906 | 912 | 910 | 909 | 10 |
| 1 | 190 | 1395 | 1382 | 1401 | 1393 | 13 | |
| 2 | 20 | 188 | 185 | 192 | 188 | 3 | |
| 3 | 161 | 1264 | 1257 | 1280 | 1267 | 11 | |
| 4 | 79 | 269 | 256 | 271 | 265 | 8 | |
| 5 | 75 | 265 | 251 | 268 | 261 | 7 | |
| (a) Test Stream 1 | |||||||
| Models | Types | Iteration (k) | |||||
| 0 | 1 | 2 | 3 | 4 | 5 | ||
| Daytime | Binary Classifier | 0.357 | 0.824 | 0.842 | 0.871 | 0.909 | 1.0 |
| Manual Labeling | 0.357 | 0.836 | 0.852 | 0.884 | 0.938 | 1.0 | |
| Nighttime | Binary Classifier | 0.0 | 0.653 | 1.0 | 1.0 | 1.0 | 1.0 |
| Manual Labeling | 0.0 | 0.753 | 1.0 | 1.0 | 1.0 | 1.0 | |
| (b) Test Stream 2 | |||||||
| Models | Types | Iteration (k) | |||||
| 0 | 1 | 2 | 3 | 4 | 5 | ||
| Daytime | Binary Classifier | 0.686 | 0.977 | 1.0 | 1.0 | 1.0 | 1.0 |
| Manual Labeling | 0.686 | 0.981 | 1.0 | 1.0 | 1.0 | 1.0 | |
| Nighttime | Binary Classifier | 0.305 | 0.655 | 0.706 | 0.751 | 0.755 | 1.0 |
| Manual Labeling | 0.305 | 0.667 | 0.753 | 0.914 | 1.0 | 1.0 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, C.H.; Kong, S.G. An Iterative Learning Scheme with Binary Classifier for Improved Event Detection in Surveillance Video. Electronics 2023, 12, 3275. https://doi.org/10.3390/electronics12153275
Tran CH, Kong SG. An Iterative Learning Scheme with Binary Classifier for Improved Event Detection in Surveillance Video. Electronics. 2023; 12(15):3275. https://doi.org/10.3390/electronics12153275
Chicago/Turabian StyleTran, Cuong H., and Seong G. Kong. 2023. "An Iterative Learning Scheme with Binary Classifier for Improved Event Detection in Surveillance Video" Electronics 12, no. 15: 3275. https://doi.org/10.3390/electronics12153275