
Secure Medical Data Collection in the Internet of Medical Things Based on Local Differential Privacy

Abstract
:1. Introduction
- To the first challenge, we propose MDLDP. Unlike existing algorithms that cannot handle key-valued data [18] or treat users’ data keys and values separately, MDLDP perturbs data keys uniformly and locally, maintaining the correlation and availability between data.
- To deal with the second challenge, we propose to encode and collect user data through the Count Sketch, which can be effectively used for large-scale data collection.
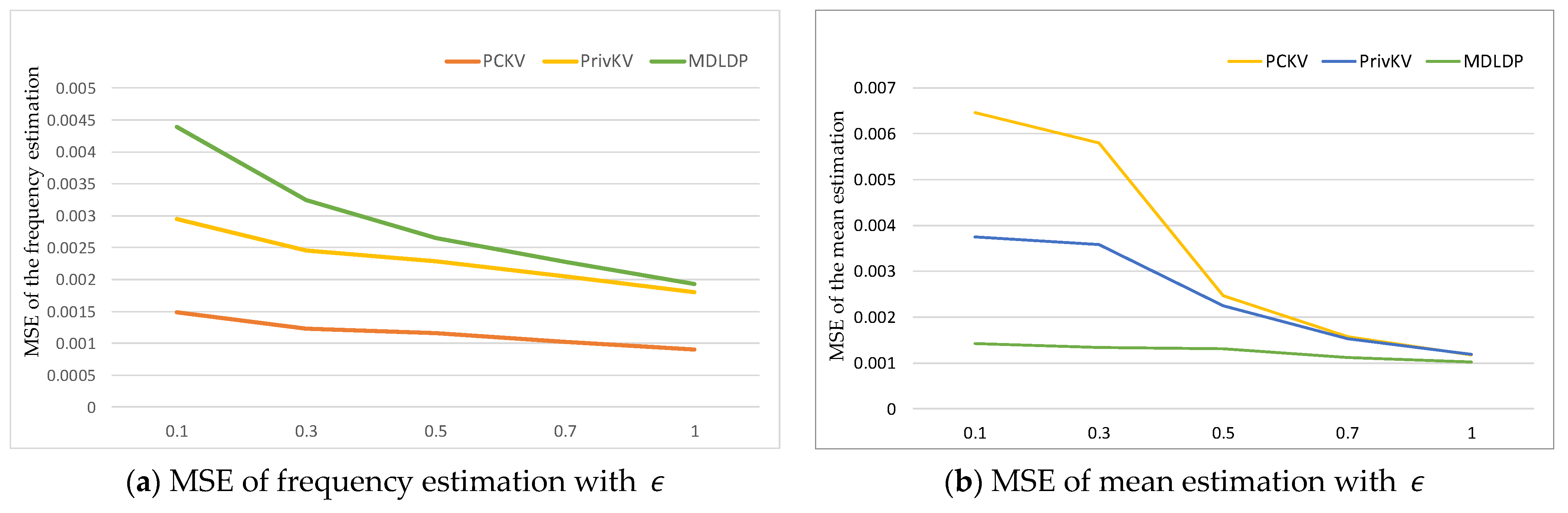
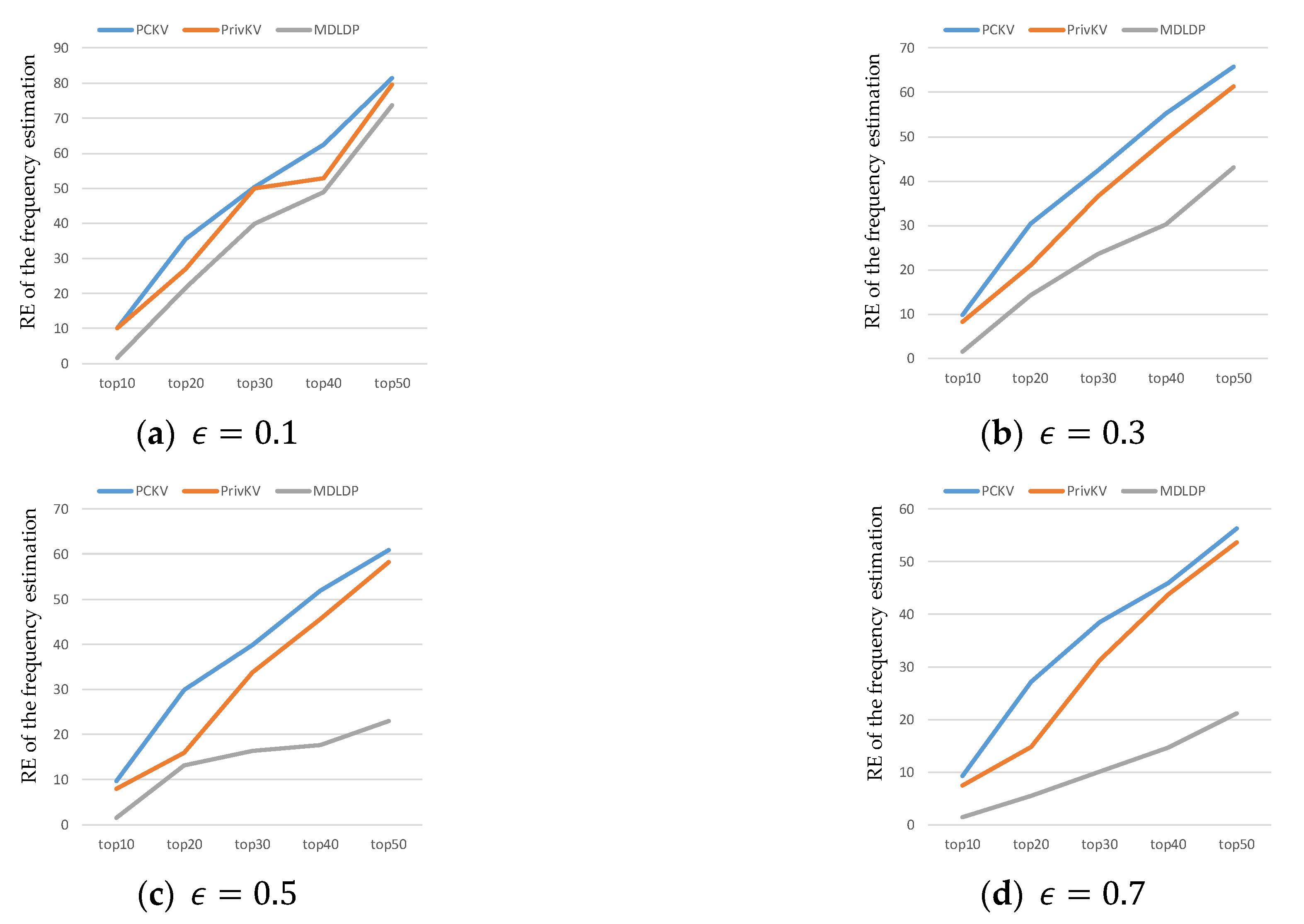
- We theoretically analyzed that MDLDP satisfies -local differential privacy, and that frequency and mean estimations are unbiased. We also compared MDLDP in terms of mean square error and relative error for frequency and mean estimations through comparative experiments to verify its effectiveness in protecting the privacy of key-value type medical data in the IoMT.
2. Related Work
2.1. Privacy Protection in IoMT
2.2. Local Differential Privacy
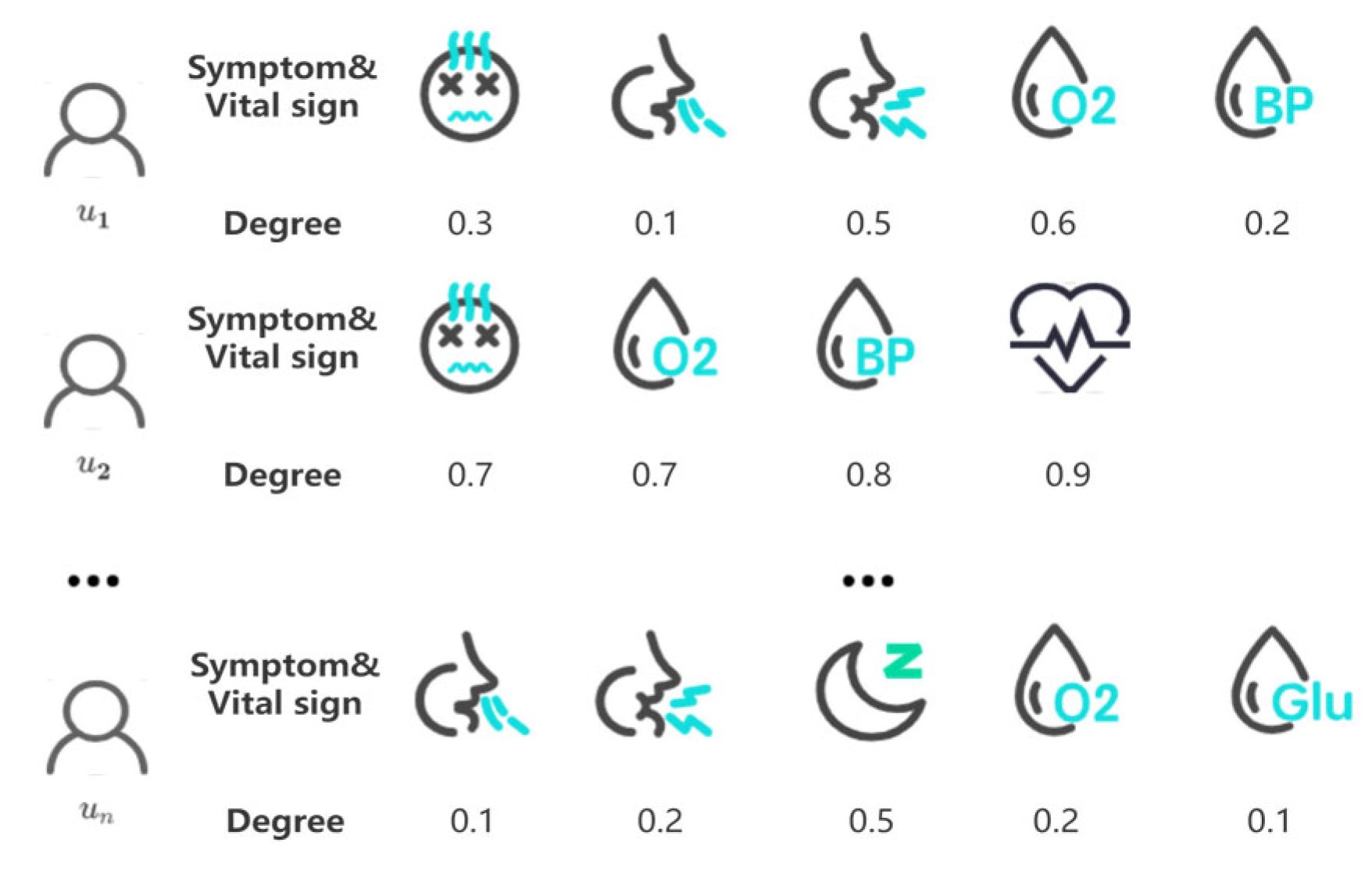
3. Preliminaries and Problem Definition
3.1. Preliminaries
3.2. Problem Definition
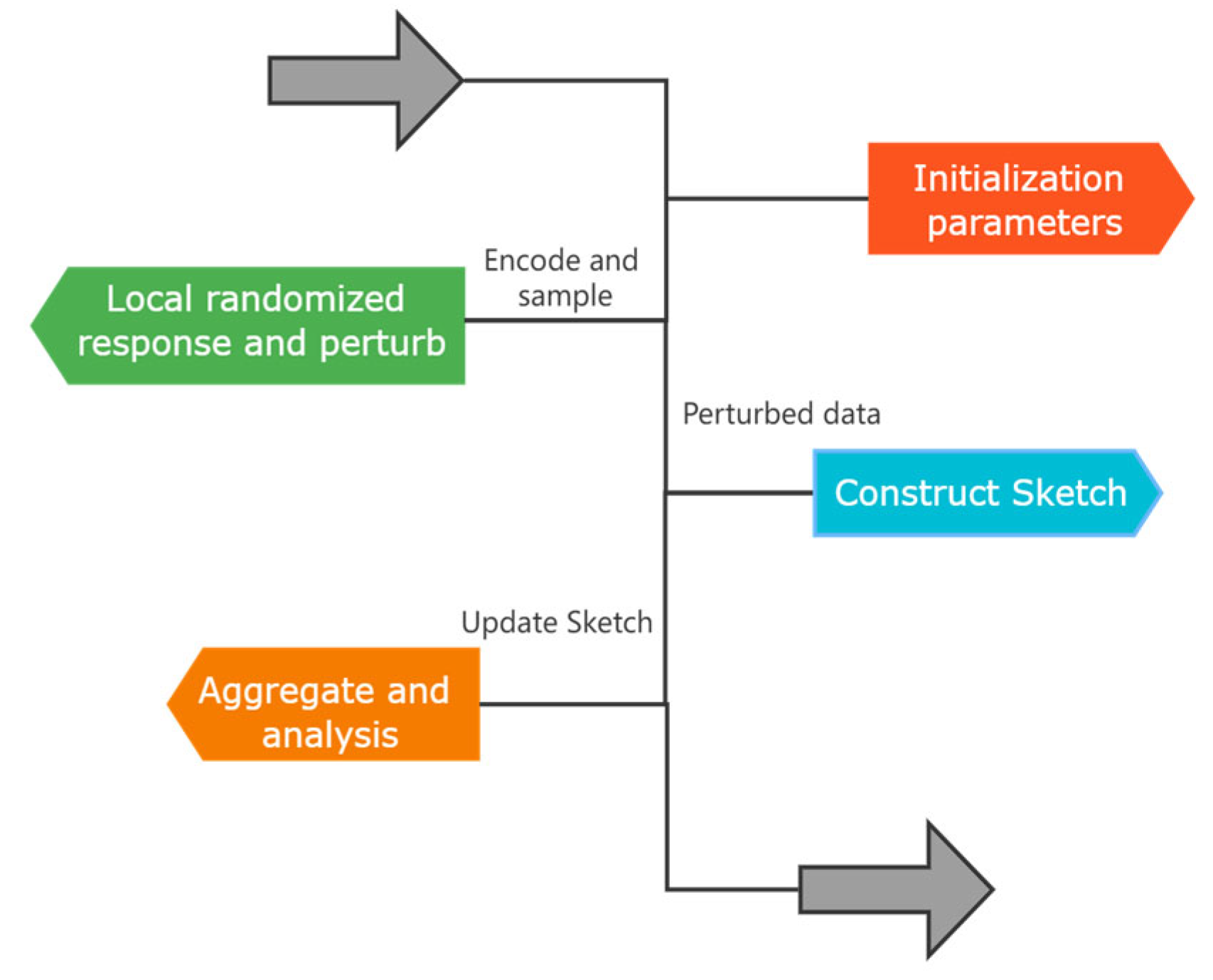
4. Algorithm for Medical Data Collection under LDP
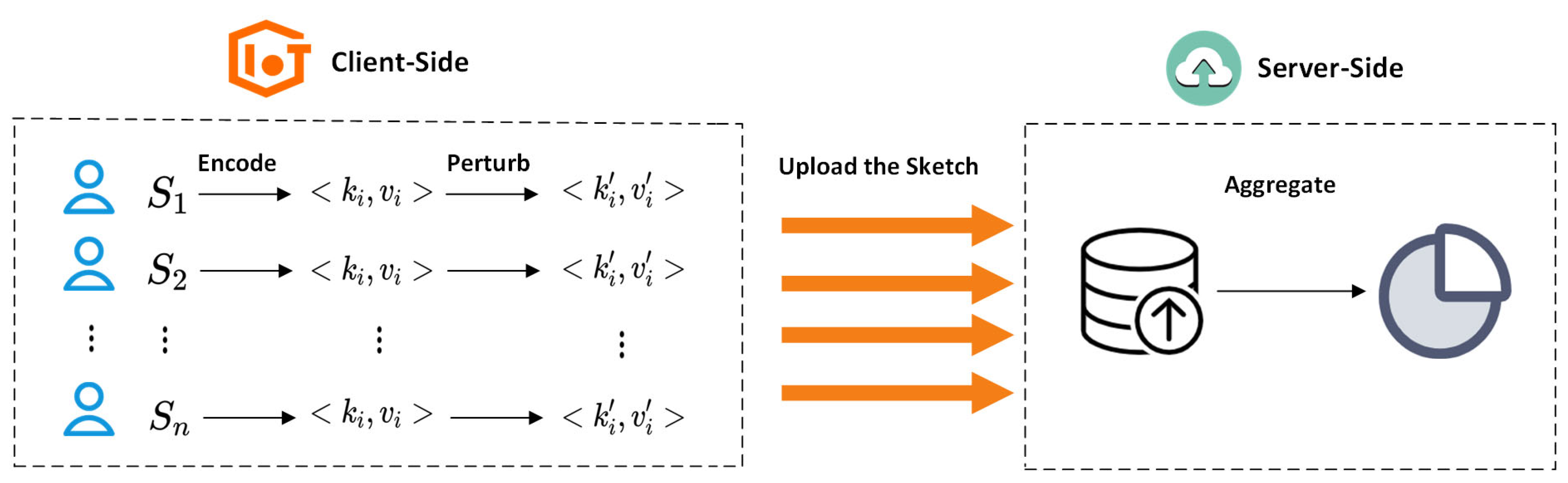
4.1. System Architecture
4.2. Algorithm Design
| Algorithm 1: MDLDP algorithm |
|
|
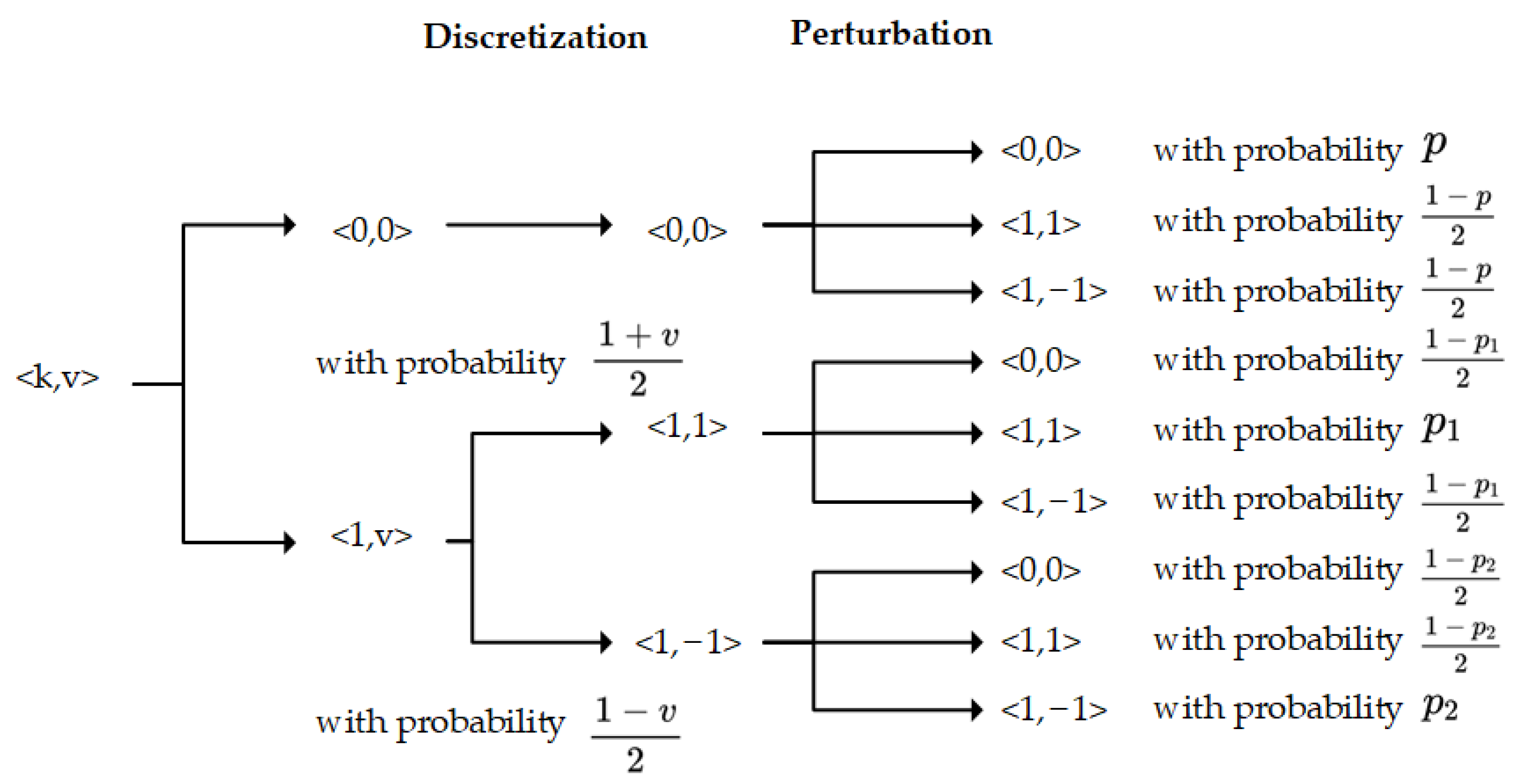
4.3. Local Randomized Response and Perturb
| Algorithm 2: MDLDP-LRR algorithm |
|
|
4.4. Construct Sketch
| Algorithm 3: MDLDP-CS algorithm |
|
|
4.5. Aggregate and Analysis
| Algorithm 4: MDLDP-Aggregate algorithm |
|
|
4.6. Algorithm Analysis
4.6.1. Privacy Analysis
- :
- :
- :
4.6.2. Practical Analysis
- 2.
4.6.3. Complexity Analysis
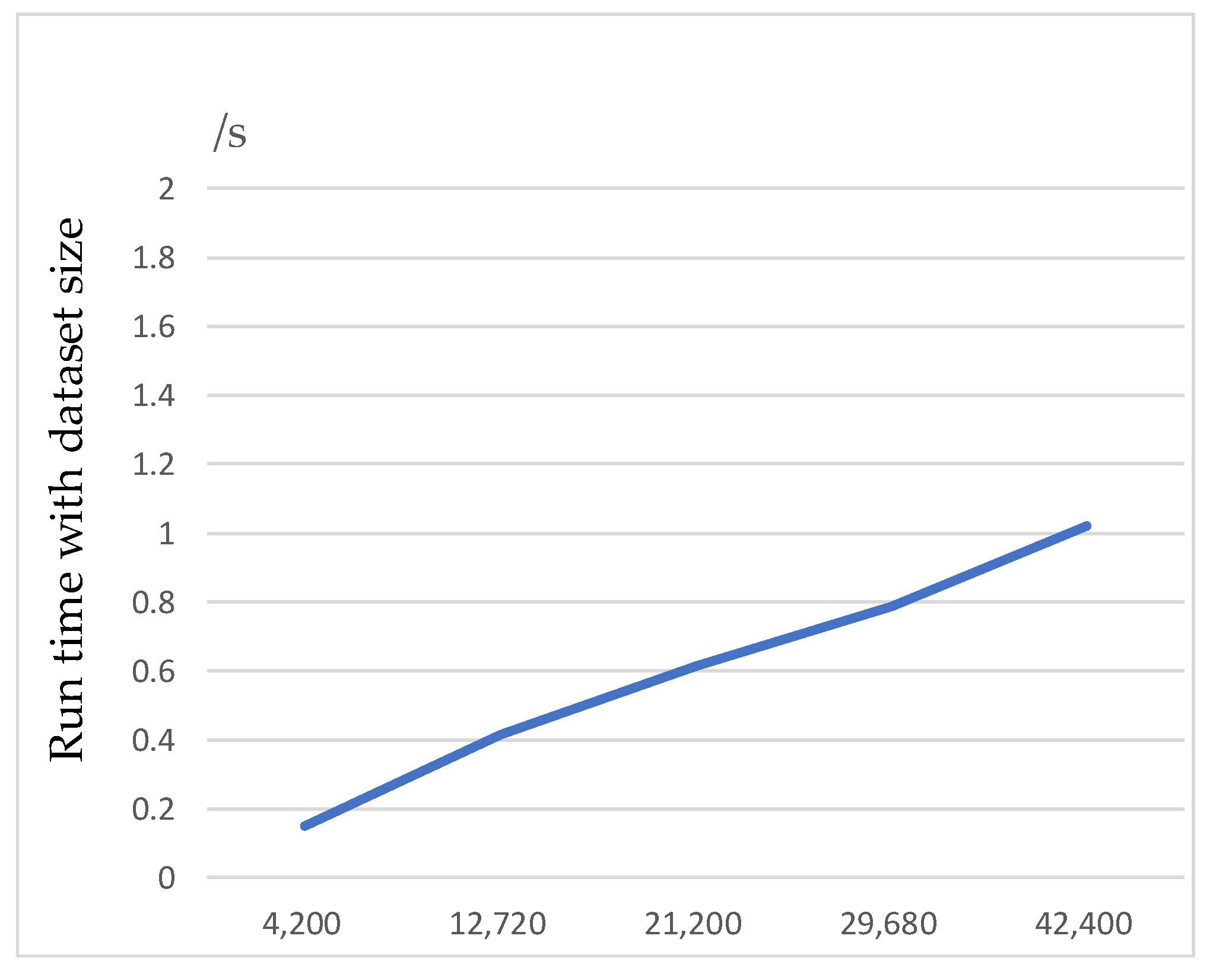
5. Experiment Analysis
5.1. Experiment Environment and Data Set
5.2. Experiment Comparison Analysis
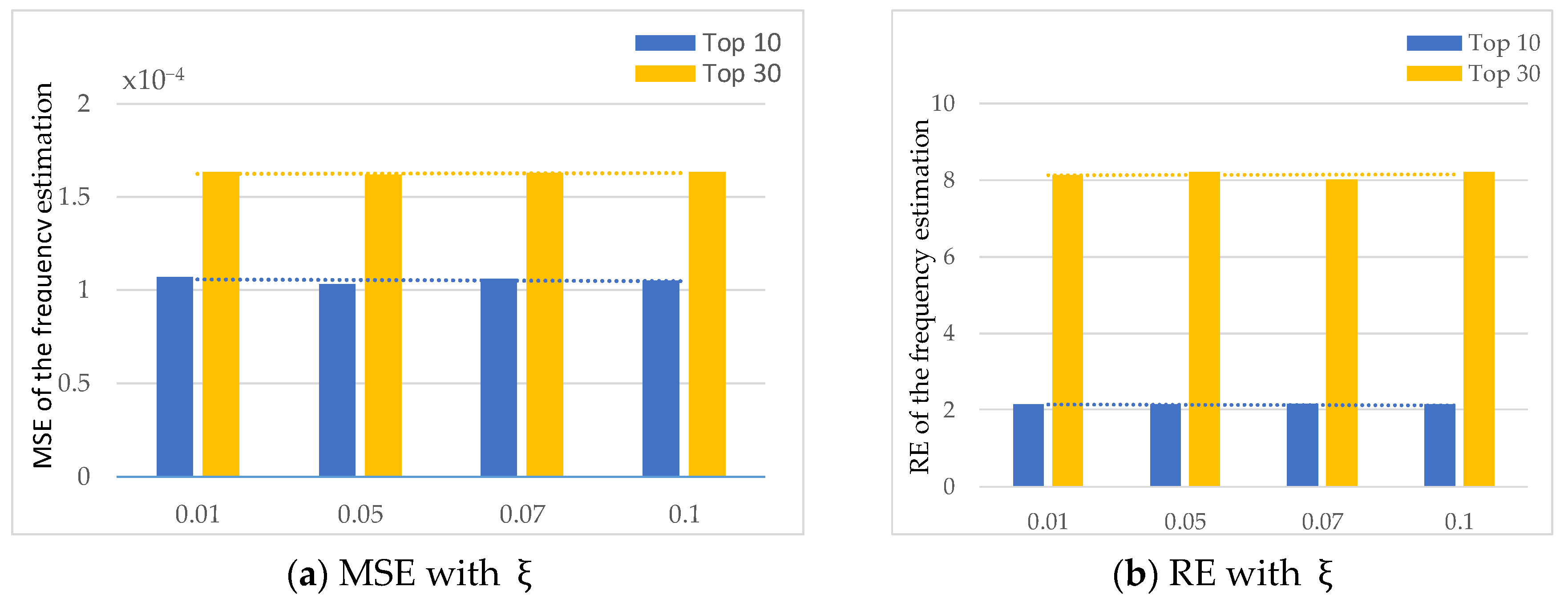
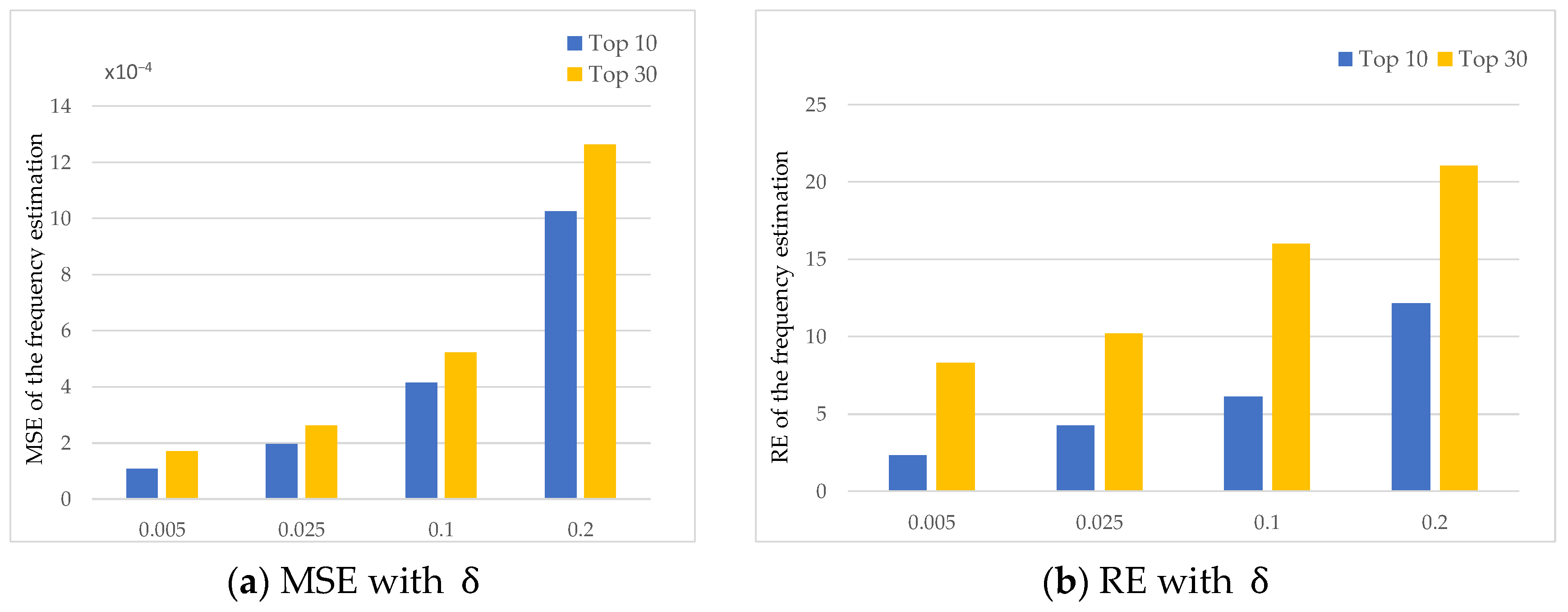
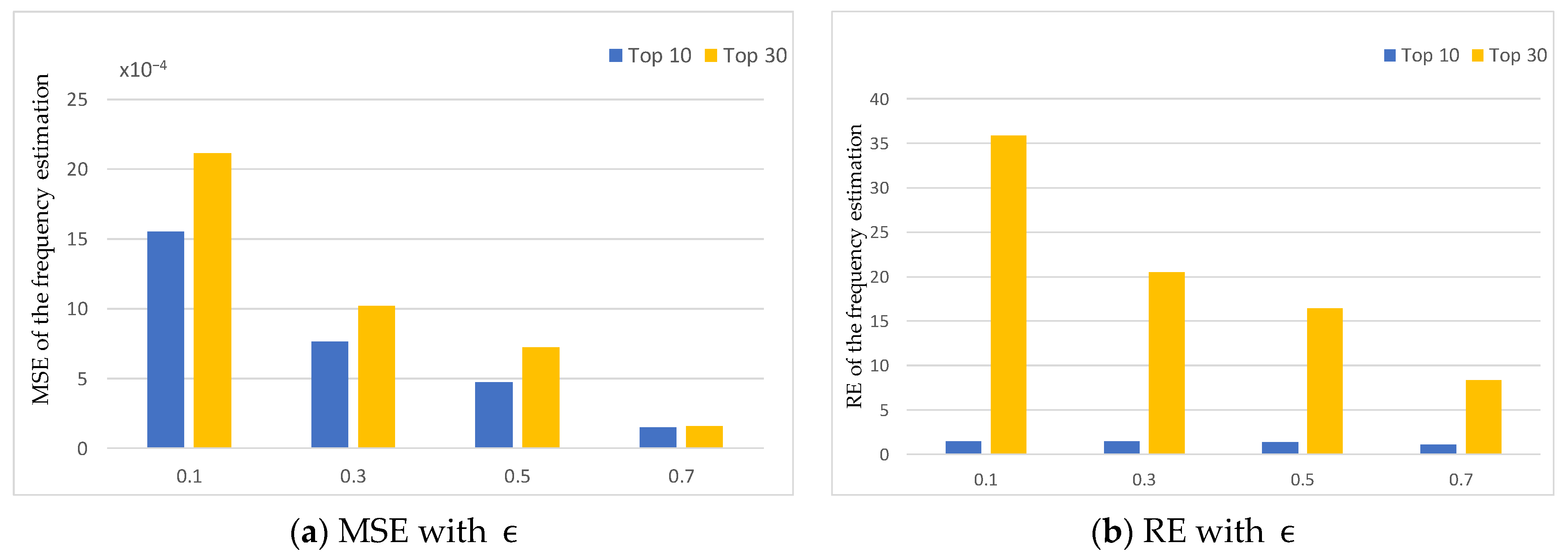
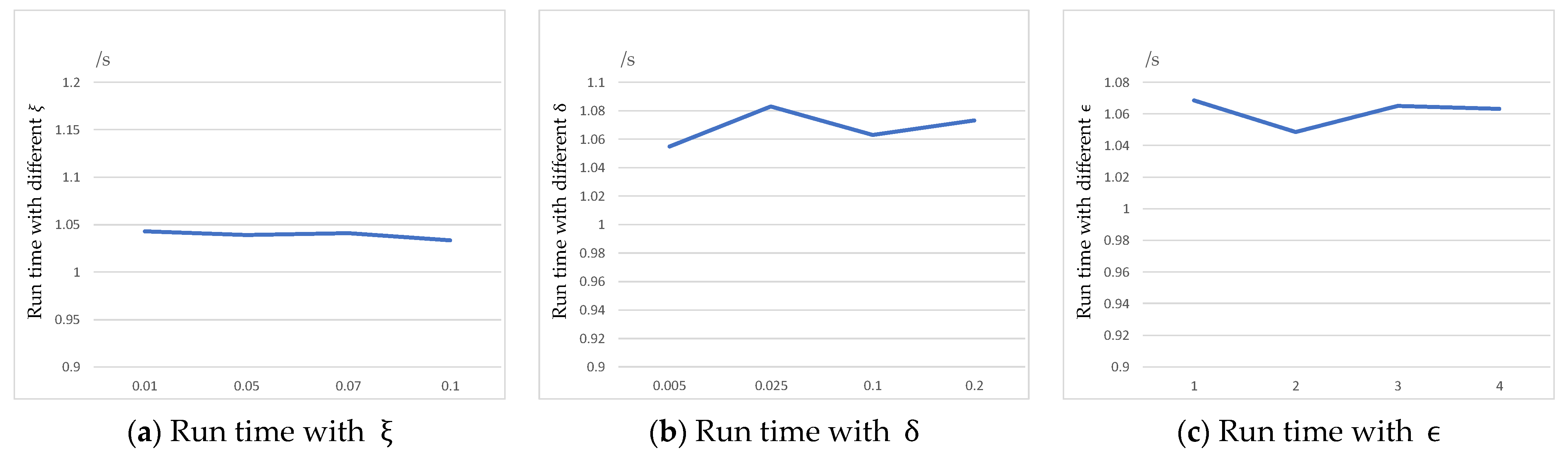
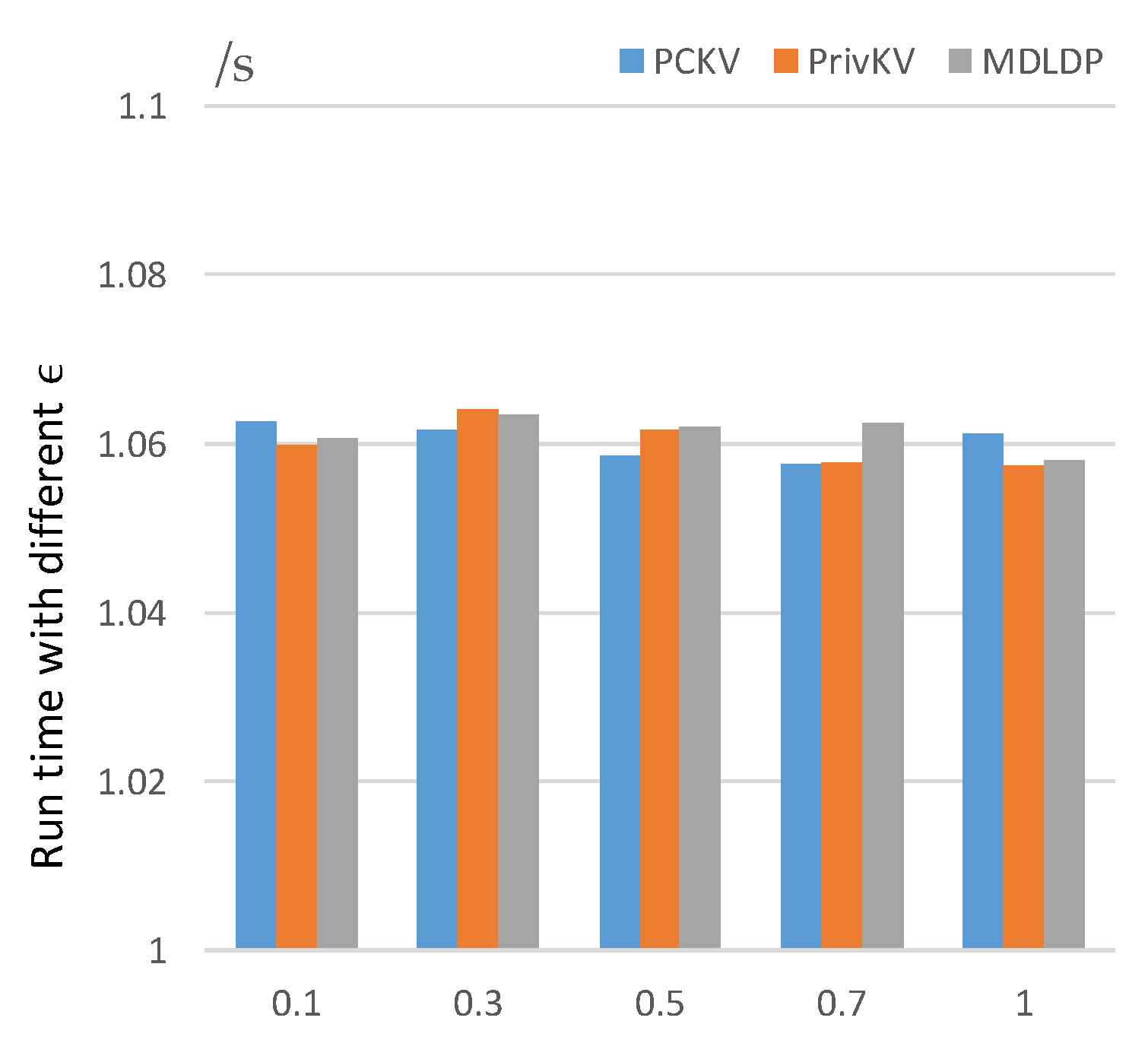
5.2.1. Impact of Parameters
5.2.2. Compare to Other Algorithms
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sapci, A.H.; Sapci, H.A. Digital continuous healthcare and disruptive medical technologies: M-Health and telemedicine skills training for data-driven healthcare. J. Telemed. Telecare 2019, 25, 623–635. [Google Scholar] [CrossRef] [PubMed]
- Vishnu, S.; Ramson SR, J.; Jegan, R. Internet of Medical Things (IoMT)—An Overview. In Proceedings of the 2020 5th International Conference on Devices, Circuits and Systems (ICDCS), Coimbatore, India, 5–6 March 2020; pp. 101–104. [Google Scholar]
- Keikhosrokiani, P. Predicating smartphone users’ behaviour towards a location-aware IoMT-based information system: An empirical study. Int. J. E-Adopt. IJEA 2021, 13, 52–77. [Google Scholar] [CrossRef]
- Singh, R.P.; Javaid, M.; Haleem, A.; Vaishya, R.; Ali, S. Internet of Medical Things (IoMT) for orthopaedic in COVID-19 pandemic: Roles, challenges, and applications. J. Clin. Orthop. Trauma 2020, 11, 713–717. [Google Scholar] [CrossRef] [PubMed]
- Awotunde, J.B.; Folorunso, S.O.; Ajagbe, S.A.; Garg, J.; Ajamu, G.J. AiIoMT: IoMT-Based System-Enabled Artificial Intelligence for Enhanced Smart Healthcare Systems. In Machine Learning for Critical Internet of Medical Things; Springer: Cham, Switzerland, 2022; pp. 229–254. [Google Scholar]
- Deep, S.; Zheng, X.; Jolfaei, A.; Yu, D.; Ostovari, P.; Bashir, A.K. A Survey of Security and Privacy Issues in the Internet of Things from the Layered Context. Trans. Emerg. Telecommun. Technol. 2020, 33, e3935. [Google Scholar] [CrossRef] [Green Version]
- Voigt, P.; von dem Bussche, A. The EU General Data Protection Regulation (Gdpr). A Practical Guide, 1st ed.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10, pp. 10–381. [Google Scholar]
- Garg, N.; Wazid, M.; Singh, J.; Singh, D.P.; Das, A.K. Security in IoMT-driven smart healthcare: A comprehensive review and open challenges. Secur. Priv. 2022, 5, e235. [Google Scholar] [CrossRef]
- Wang, T.; Zheng, Z.; Bashir, A.K.; Jolfaei, A.; Xu, Y. FinPrivacy: A privacy-preserving mechanism for fingerprint identification. ACM Trans. Internet Technol. TOIT 2021, 21, 1–15. [Google Scholar] [CrossRef]
- Weng, J.H.; Chi, P.W. Multi-Level Privacy Preserving K-Anonymity. In Proceedings of the 2021 16th Asia Joint Conference on Information Security (AsiaJCIS), Seoul, Republic of Korea, 19–20 August 2021; pp. 61–67. [Google Scholar]
- Zhang, Z.; Wu, T.; Sun, X.; Yu, J. MPDP k-medoids: Multiple partition differential privacy preserving k-medoids clustering for data publishing in the Internet of Medical Things. Int. J. Distrib. Sens. Netw. 2021, 17, 15501477211042543. [Google Scholar] [CrossRef]
- Lv, Z.; Piccialli, F. The security of medical data on internet based on differential privacy technology. ACM Trans. Internet Technol. 2021, 21, 1–18. [Google Scholar] [CrossRef]
- Duchi, J.C.; Jordan, M.I.; Wainwright, M.J. Local privacy and statistical minimax rates. In Proceedings of the 2013 IEEE 54th Annual Symposium on Foundations of Computer Science, Berkeley, CA, USA, 26–29 October 2013; pp. 429–438. [Google Scholar]
- Erlingsson, Ú.; Pihur, V.; Korolova, A. Rappor: Randomized Aggregatable Privacy-Preserving Ordinal Response. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 1054–1067. [Google Scholar]
- Team Apple Differential Privacy. Learning with Privacy at Scale; Apple: Cupertino, CA, USA, 2017; Volume 1, pp. 1–25. [Google Scholar]
- Nguyên, T.T.; Xiao, X.; Yang, Y.; Hui, S.C.; Shin, H.; Shin, J. Collecting and Analyzing Data from Smart Device Users with Local Differential Privacy. arXiv 2016, arXiv:1606.05053. [Google Scholar]
- Charikar, M.; Chen, K.; Farach-Colton, M. Finding Frequent Items in Data Streams. In International Colloquium on Automata, Languages, and Programming, Proceedings of the International Colloquium on Automata, Languages, and Programming, Malaga, Spain, 8–13 July 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 693–703. [Google Scholar]
- Wu, X.; Khosravi, M.R.; Qi, L.; Ji, G.; Dou, W.; Xu, X. Locally private frequency estimation of physical symptoms for infectious disease analysis in Internet of Medical Things. Comput. Commun. 2020, 162, 139–151. [Google Scholar] [CrossRef] [PubMed]
- Warner, S.L. Randomized response: A survey technique for eliminating evasive answer bias. J. Am. Stat. Assoc. 1965, 60, 63–69. [Google Scholar] [CrossRef] [PubMed]
- Bruck, J.; Gao, J.; Jiang, A. Weighted Bloom Filter. In Proceedings of the 2006 IEEE International Symposium on Information Theory, Seattle, WA, USA, 9–14 July 2006; pp. 2304–2308. [Google Scholar]
- Cormode, G.; Kulkarni, T.; Srivastava, D. Answering Range Queries under Local Differential Privacy. Proc. VLDB Endow. 2019, 12, 1126–1138. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Blocki, J.; Li, N.; Jha, S. Locally Differentially Private Protocols for Frequency Estimation. In Proceedings of the 26th USENIX Security Symposium (USENIX Security 17), Vancouver, BC, Canada, 16–18 August 2017; pp. 729–745. [Google Scholar]
- Ye, Q.; Hu, H.; Meng, X.; Zheng, H. PrivKV: Key-Value Data Collection with Local Differential Privacy. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 317–331. [Google Scholar]
- Gu, X.; Li, M.; Cheng, Y.; Xiong, L.; Cao, Y. {PCKV}: Locally Differentially Private Correlated {Key-Value} Data Collection with Optimized Utility. In Proceedings of the 29th USENIX Security Symposium (USENIX security 20), Boston, MA, USA, 12–14 August 2020; pp. 967–984. [Google Scholar]
- McSherry, F.D. Privacy Integrated Queries: An Extensible Platform for Privacy-Preserving Data Analysis. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, Providence, RI, USA, 29 June–2 July 2009; pp. 19–30. [Google Scholar]
- Christofides, T.C. A generalized randomized response technique. Metrika 2003, 57, 195–200. [Google Scholar] [CrossRef]
- Zhang, X.; Fu, N.; Meng, X. Key-value data collection under local differential privacy. Chin. J. Comput. 2020, 43, 1479–1492. (In Chinese) [Google Scholar]
- Zhang, X.; Xu, Y.; Fu, N.; Meng, X. Towards Private Key-Value Data Collection with Histogram. J. Comput. Res. Dev. 2021, 58, 624–637. [Google Scholar]
- Cormode, G.; Yi, K. Small Summaries for Big Data; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Johnson, A.E.W.; Pollard, T.J.; Shen, L.; Lehman, L.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Default Value | Range of Values |
|---|---|---|
| Numbers of items | 12,488 | |
| Numbers of data | 76,075 | |
| Error | 0.07 | [0.01, 0.05, 0.07, 0.10] |
| Confidence probability | 0.005 | [0.005, 0.025, 0.10, 0.20] |
| Privacy budget | 0.7 | [0.1, 0.3, 0.5, 0.7] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Li, X. Secure Medical Data Collection in the Internet of Medical Things Based on Local Differential Privacy. Electronics 2023, 12, 307. https://doi.org/10.3390/electronics12020307
Wang J, Li X. Secure Medical Data Collection in the Internet of Medical Things Based on Local Differential Privacy. Electronics. 2023; 12(2):307. https://doi.org/10.3390/electronics12020307
Chicago/Turabian StyleWang, Jinpeng, and Xiaohui Li. 2023. "Secure Medical Data Collection in the Internet of Medical Things Based on Local Differential Privacy" Electronics 12, no. 2: 307. https://doi.org/10.3390/electronics12020307