
Consideration of FedProx in Privacy Protection


Abstract
:1. Introduction
- We propose the DP-Prox algorithm under a unified privacy budget scenario to improve the convergence of the model algorithm under the condition of heterogeneity.
- We propose the PDP-Prox under a personalized privacy budget scenario to improve the balance between privacy and utility through multiple rounds of the adaptive sampling mechanism.
- We conduct a series of comparison experiments with the baseline algorithm on both synthetic and real datasets to demonstrate that our proposed algorithm is not only more adaptable to heterogeneous environments, but also achieves up to nearly 6% improvement in algorithmic accuracy when compared to the commonly used SGD algorithm.
2. Preliminaries
2.1. Differential Privacy and Personalized Differential Privacy
2.2. FedProx
3. Related Work
4. Differential Privacy in FedProx
| Algorithm 1: Differential Privacy SGD (DP-SGD). |
 |
4.1. DP-Prox
| Algorithm 2: Differential Privacy FedProx (DP-Prox) (Proposed Framework). |
 |
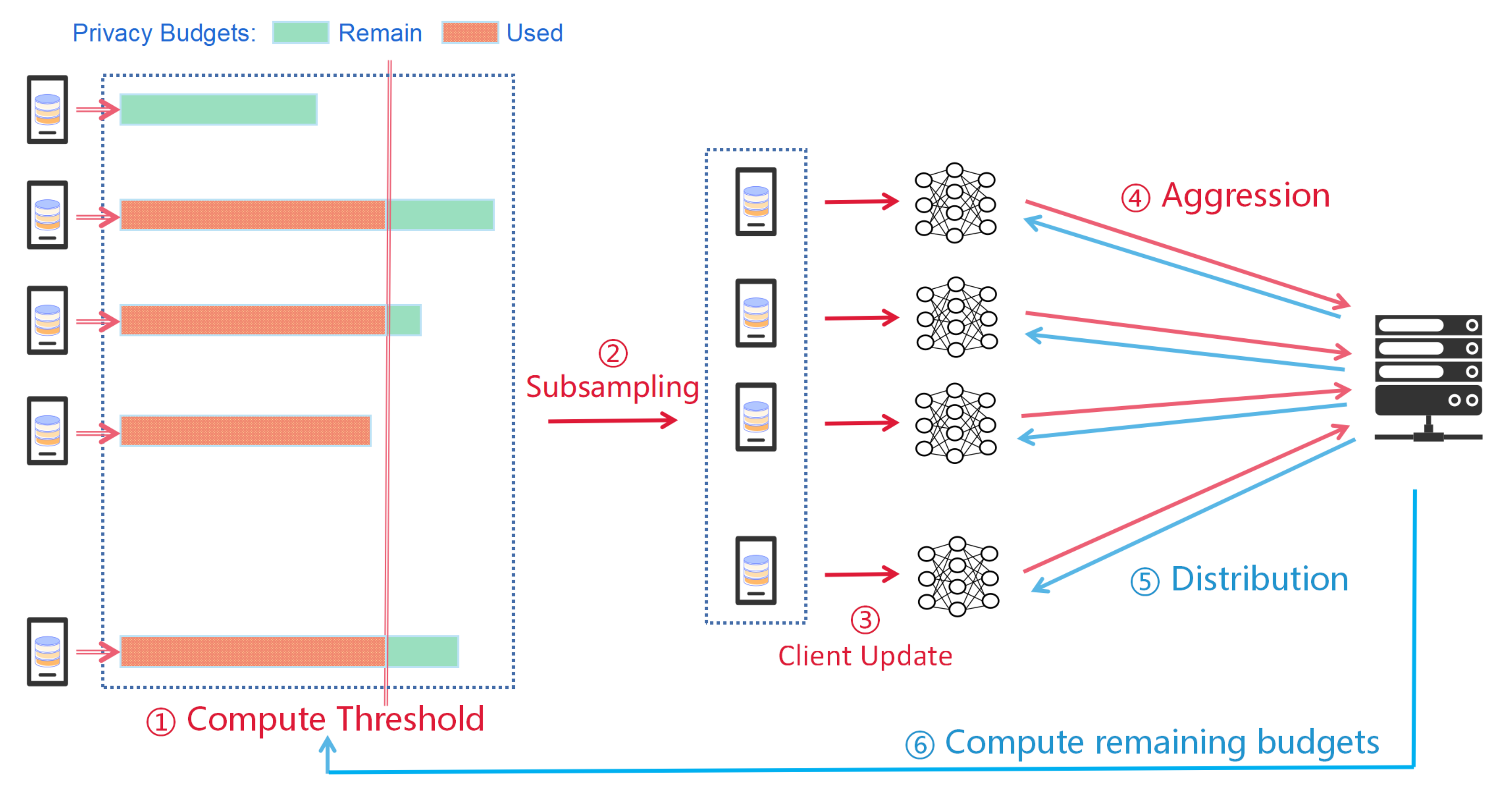
4.2. PDP-Prox
| Algorithm 3: Personalized DP-Prox (PDP-Prox) (Proposed Framework). |
 |
5. Experiment
5.1. Setting
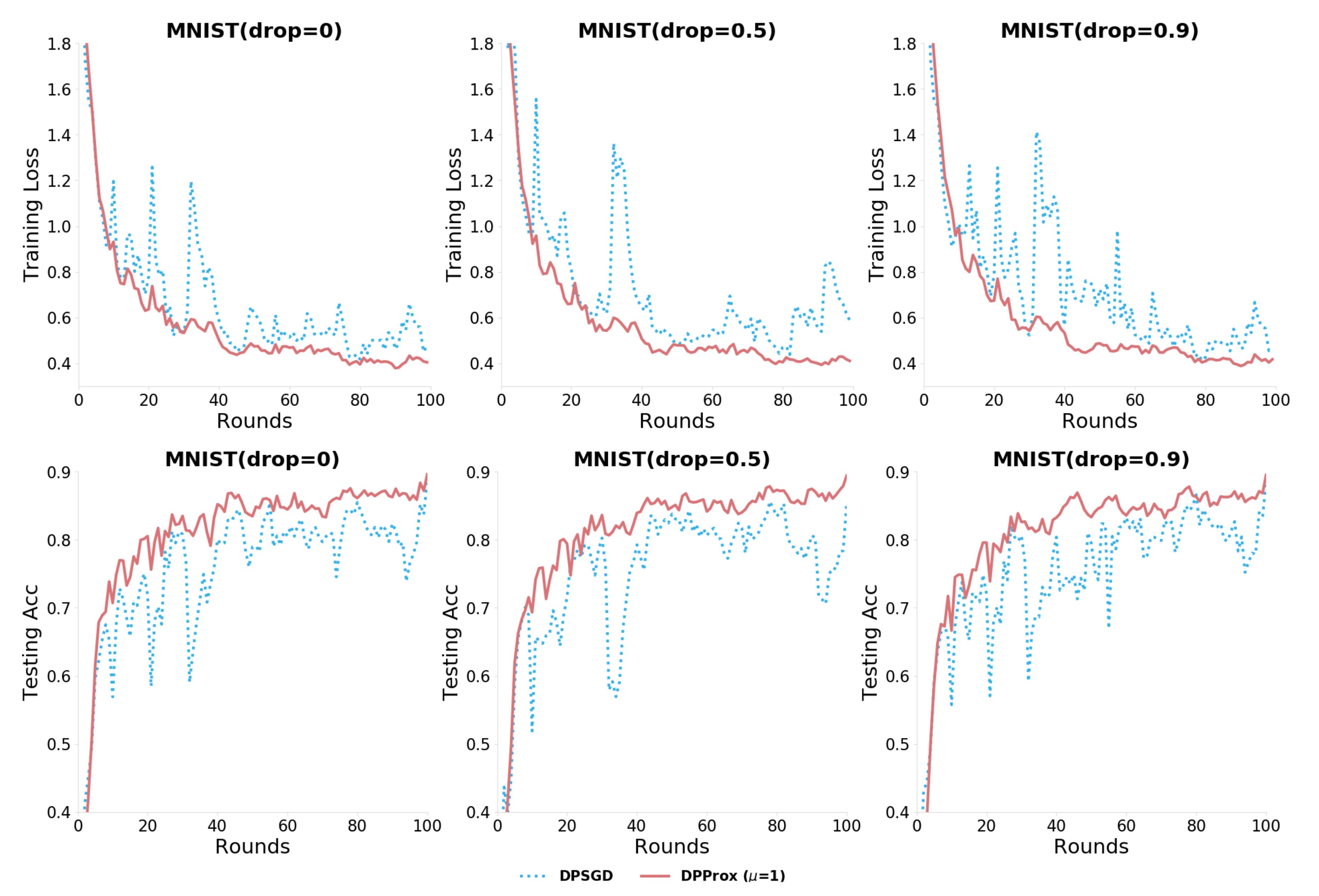
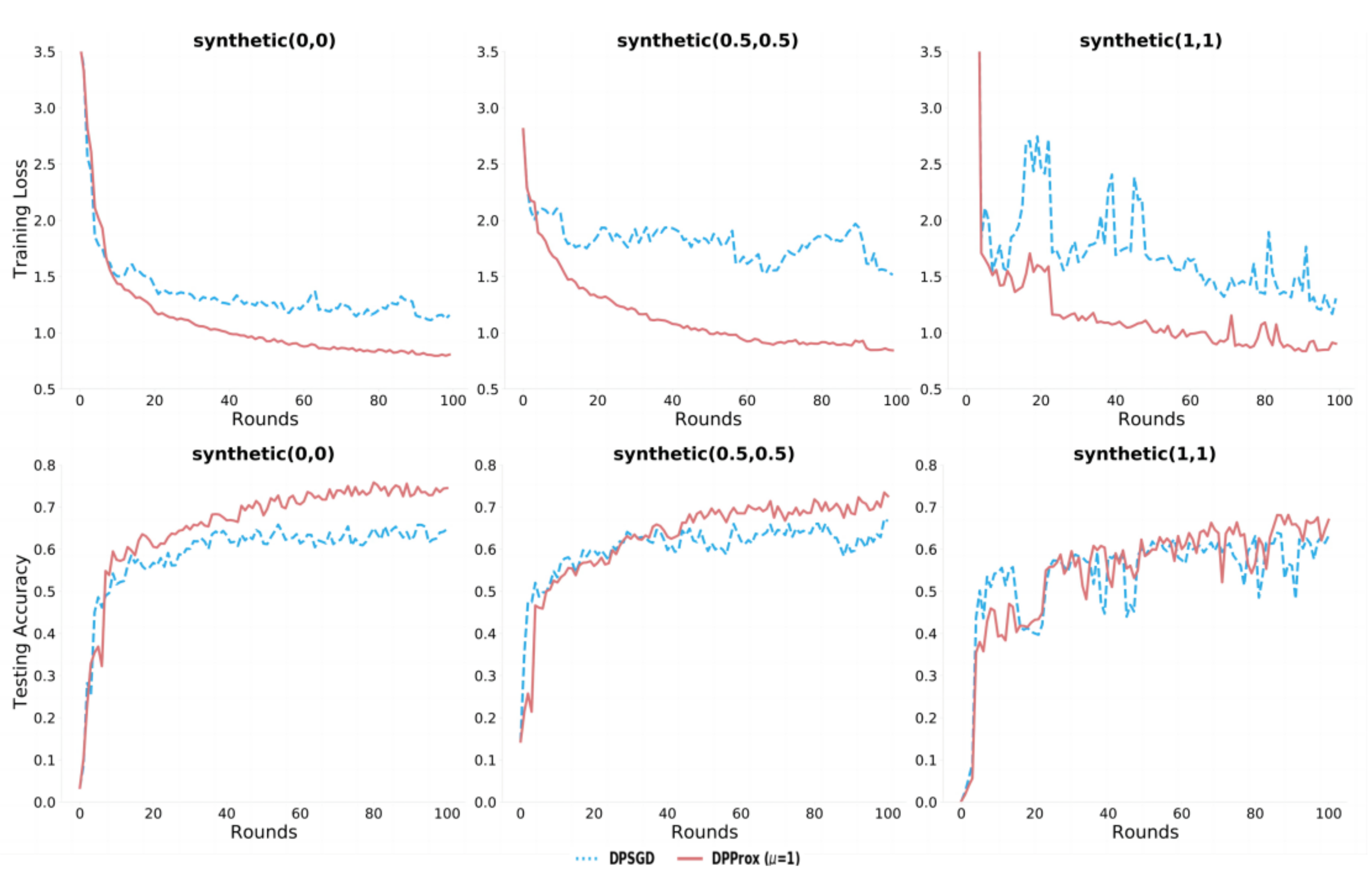
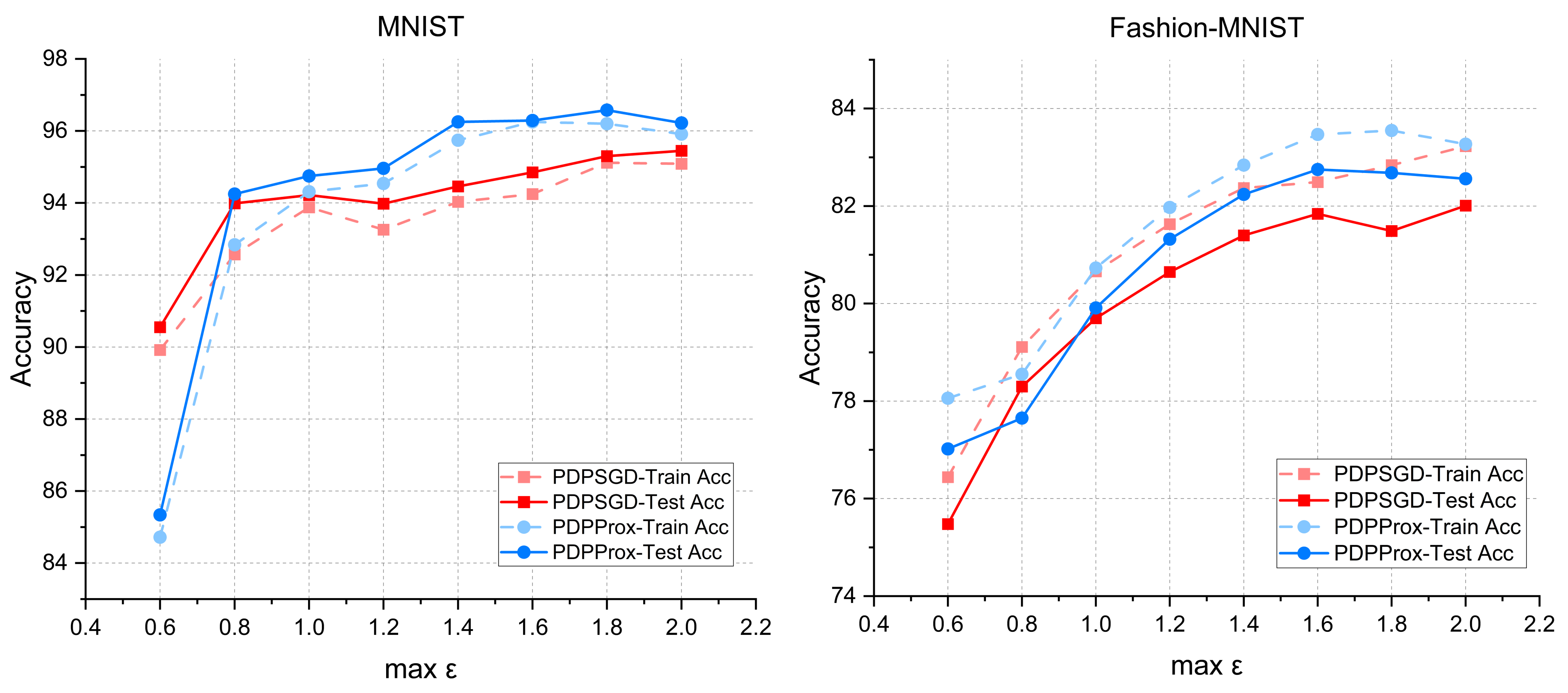
5.2. DP-SGD and DP-Prox
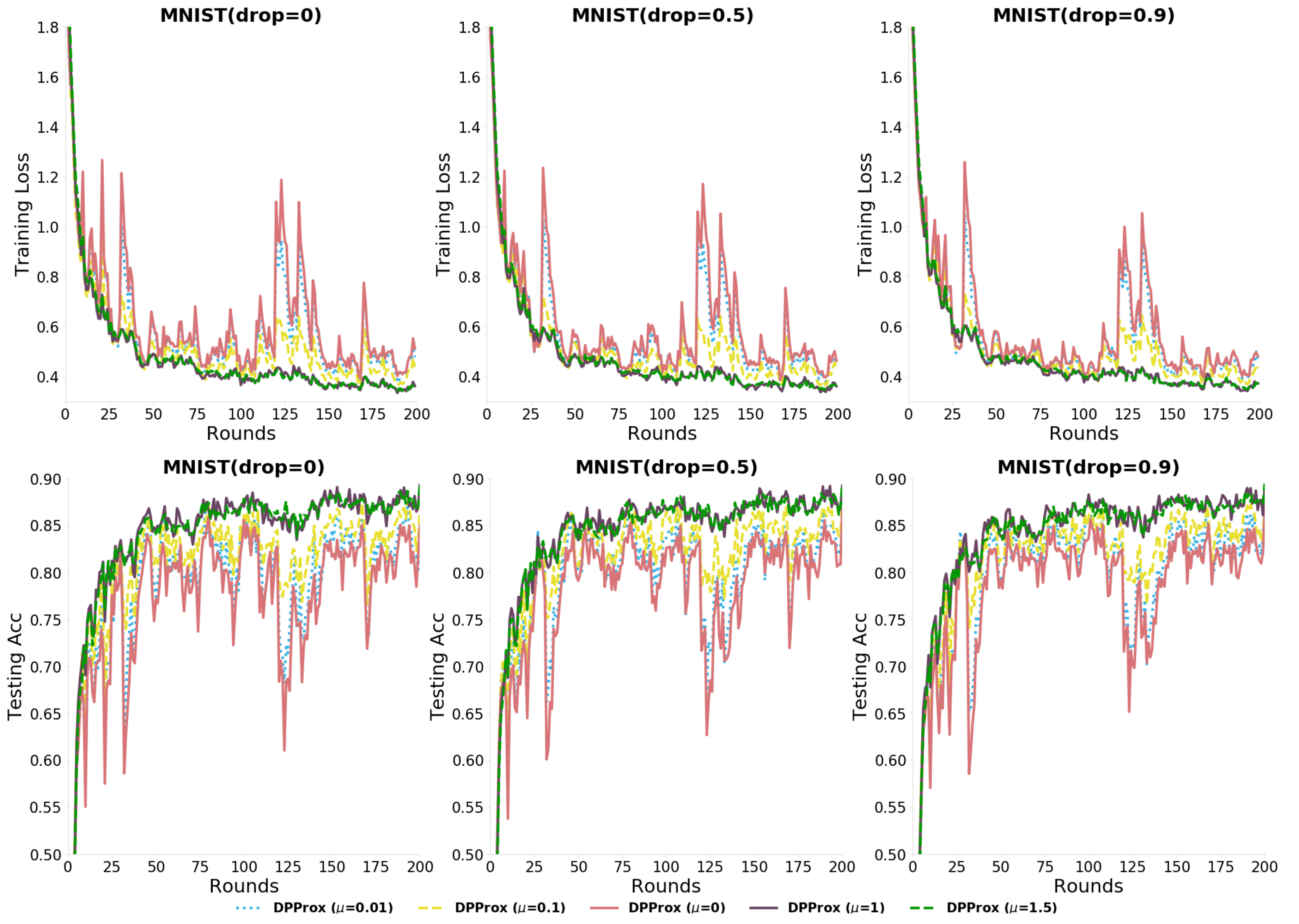
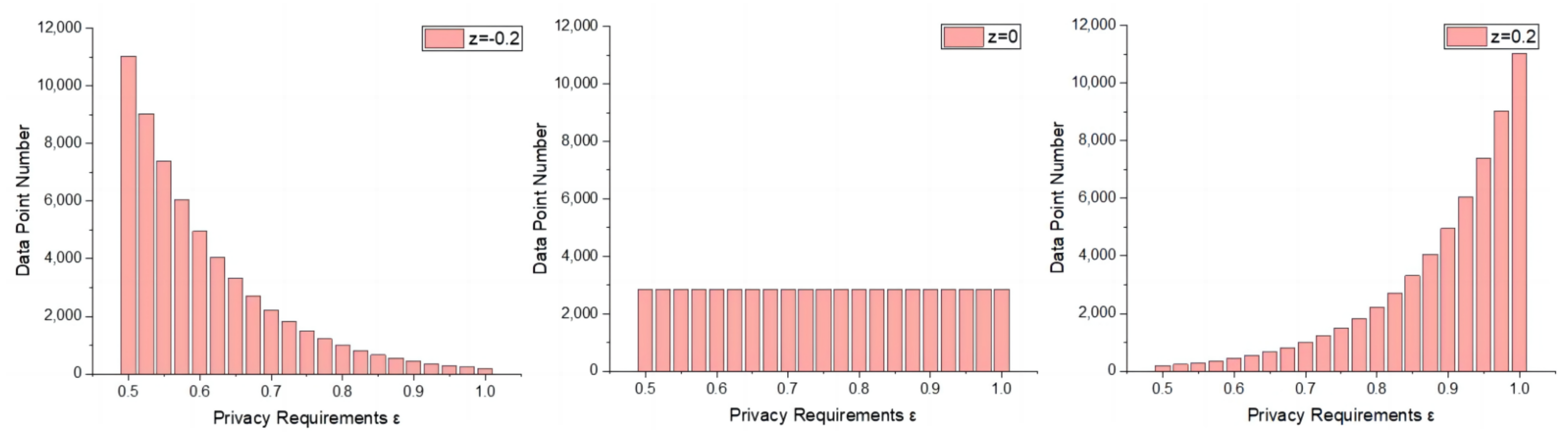
5.3. PDP-SGD and PDP-Prox
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics; PMLR: New York, NY, USA, 2017; pp. 1273–1282. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Truex, S.; Baracaldo, N.; Anwar, A.; Steinke, T.; Ludwig, H.; Zhang, R.; Zhou, Y. A hybrid approach to privacy-preserving federated learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security, London, UK, 15 November 2019; pp. 1–11. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- Xu, G.; Li, H.; Zhang, Y.; Xu, S.; Ning, J.; Deng, R.H. Privacy-preserving federated deep learning with irregular users. IEEE Trans. Dependable Secur. Comput. 2020, 19, 1364–1381. [Google Scholar] [CrossRef]
- Yuan, J.; Yu, S. Privacy preserving back-propagation neural network learning made practical with cloud computing. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 212–221. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Theory of Cryptography: Third Theory of Cryptography Conference (TCC 2006), New York, NY, USA, 4–7 March 2006; Proceedings 3. Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Jorgensen, Z.; Yu, T.; Cormode, G. Conservative or liberal? Personalized differential privacy. In Proceedings of the 2015 IEEE 31St International Conference on Data Engineering, Seoul, Republic of Korea, 13–17 April 2015; pp. 1023–1034. [Google Scholar]
- Kasiviswanathan, S.P.; Lee, H.K.; Nissim, K.; Raskhodnikova, S.; Smith, A. What can we learn privately? SIAM J. Comput. 2011, 40, 793–826. [Google Scholar] [CrossRef]
- Liu, R.; Cao, Y.; Yoshikawa, M.; Chen, H. Fedsel: Federated sgd under local differential privacy with top-k dimension selection. In Proceedings of the Database Systems for Advanced Applications: 25th International Conference (DASFAA 2020), Jeju, Republic of Korea, 24–27 September 2020; Proceedings, Part I 25. Springer: Berlin/Heidelberg, Germany, 2020; pp. 485–501. [Google Scholar]
- Lian, Z.; Wang, W.; Su, C. COFEL: Communication-efficient and optimized federated learning with local differential privacy. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Li, Z.; Chen, H.; Ni, Z.; Shao, H. Balancing Privacy Protection and Interpretability in Federated Learning. arXiv 2023, arXiv:2302.08044. [Google Scholar]
- Zhao, J.; Mao, K.; Huang, C.; Zeng, Y. Utility optimization of federated learning with differential privacy. Discret. Dyn. Nat. Soc. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Shen, X.; Jiang, H.; Chen, Y.; Wang, B.; Gao, L. PLDP-FL: Federated Learning with Personalized Local Differential Privacy. Entropy 2023, 25, 485. [Google Scholar] [CrossRef]
- Akter, M.; Hashem, T. Computing aggregates over numeric data with personalized local differential privacy. In Proceedings of the Information Security and Privacy: 22nd Australasian Conference (ACISP 2017), Auckland, New Zealand, 3–5 July 2017; Proceedings, Part II 22. Springer: Berlin/Heidelberg, Germany, 2017; pp. 249–260. [Google Scholar]
- Yiwen, N.; Yang, W.; Huang, L.; Xie, X.; Zhao, Z.; Wang, S. A utility-optimized framework for personalized private histogram estimation. IEEE Trans. Knowl. Data Eng. 2018, 31, 655–669. [Google Scholar]
- Xie, Y.; Zhang, L. Federated Learning With Personalized Differential Privacy Combining Client Selection. In Proceedings of the 2022 8th International Conference on Big Data Computing and Communications (BigCom), Xiamen, China, 6–7 August 2022; pp. 79–87. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends® Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Dwork, C. Differential privacy. In Proceedings of the International colloquium on automata, languages and programming, Venice, Italy, 10–14 July 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–12. [Google Scholar]
- Kairouz, P.; Oh, S.; Viswanath, P. Extremal mechanisms for local differential privacy. Adv. Neural Inf. Process. Syst. 2016, 17, 492–542. [Google Scholar]
- Sarathy, R.; Muralidhar, K. Evaluating Laplace noise addition to satisfy differential privacy for numeric data. Trans. Data Priv. 2011, 4, 1–17. [Google Scholar]
- Heo, G.; Seo, J.; Whang, S.E. Personalized DP-SGD using Sampling Mechanisms. arXiv 2023, arXiv:2305.15165. [Google Scholar]
- Dong, J.; Roth, A.; Su, W.J. Gaussian differential privacy. arXiv 2019, arXiv:1905.02383. [Google Scholar] [CrossRef]
- Geyer, R.C.; Klein, T.; Nabi, M. Differentially private federated learning: A client level perspective. arXiv 2017, arXiv:1712.07557. [Google Scholar]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.; Poor, H.V. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Truex, S.; Liu, L.; Chow, K.H.; Gursoy, M.E.; Wei, W. LDP-Fed: Federated learning with local differential privacy. In Proceedings of the Third ACM International Workshop on Edge Systems, Analytics and Networking, Heraklion, Greece, 27 April 2020; pp. 61–66. [Google Scholar]
- Hu, R.; Gong, Y.; Guo, Y. Federated learning with sparsification-amplified privacy and adaptive optimization. arXiv 2020, arXiv:2008.01558. [Google Scholar]
- Hu, R.; Guo, Y.; Li, H.; Pei, Q.; Gong, Y. Personalized federated learning with differential privacy. IEEE Internet Things J. 2020, 7, 9530–9539. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, J.; Yang, M.; Wang, T.; Wang, N.; Lyu, L.; Niyato, D.; Lam, K.Y. Local differential privacy-based federated learning for internet of things. IEEE Internet Things J. 2020, 8, 8836–8853. [Google Scholar] [CrossRef]
- Sun, L.; Qian, J.; Chen, X. LDP-FL: Practical private aggregation in federated learning with local differential privacy. arXiv 2020, arXiv:2007.15789. [Google Scholar]
- Niu, B.; Chen, Y.; Wang, B.; Wang, Z.; Li, F.; Cao, J. AdaPDP: Adaptive personalized differential privacy. In Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar]
- Chen, R.; Li, H.; Qin, A.K.; Kasiviswanathan, S.P.; Jin, H. Private spatial data aggregation in the local setting. In Proceedings of the 2016 IEEE 32nd International Conference on Data Engineering (ICDE), Helsinki, Finland, 16–20 May 2016; pp. 289–300. [Google Scholar]
- Yang, G.; Wang, S.; Wang, H. Federated learning with personalized local differential privacy. In Proceedings of the 2021 IEEE 6th International Conference on Computer and Communication Systems (ICCCS), Chengdu, China, 23–26 April 2021; pp. 484–489. [Google Scholar]
- Shen, Z.; Xia, Z.; Yu, P. PLDP: Personalized local differential privacy for multidimensional data aggregation. Secur. Commun. Networks 2021, 2021, 1–13. [Google Scholar] [CrossRef]
- Xue, Q.; Zhu, Y.; Wang, J. Mean estimation over numeric data with personalized local differential privacy. Front. Comput. Sci. 2022, 16, 1–10. [Google Scholar] [CrossRef]
- Mironov, I. Rényi differential privacy. In Proceedings of the 2017 IEEE 30th Computer Security Foundations Symposium (CSF), Santa Barbara, CA, USA, 21–25 August 2017; pp. 263–275. [Google Scholar]
- Deng, L. The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Skew | PDP-SGD | PDP-Prox | ||
|---|---|---|---|---|---|
| Accuracy | Loss | Accuracy | Loss | ||
| MNIST | z = −0.2 | 94.08 ± 0.64 | 0.68 ± 0.07 | 94.99 ± 0.14 | 0.22 ± 0.02 |
| z = 0 | 95.14 ± 0.20 | 0.34 ± 0.02 | 95.34 ± 0.14 | 0.20 ± 0.01 | |
| z = 0.2 | 94.06 ± 0.27 | 0.42 ± 0.04 | 93.80 ± 0.26 | 0.31 ± 0.03 | |
| Fashion-MNIST | z = −0.2 | 75.80 ± 1.01 | 1.09 ± 0.05 | 80.04 ± 0.70 | 0.83 ± 0.03 |
| z = 0 | 79.42 ± 0.77 | 1.13 ± 0.04 | 81.12 ± 0.49 | 0.79 ± 0.03 | |
| z = 0.2 | 79.72 ± 0.78 | 1.45 ± 0.11 | 78.55 ± 0.82 | 0.92 ± 0.04 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, T.; Ma, L.; Wang, W.; Yang, Y.; Wang, J.; Chen, Y. Consideration of FedProx in Privacy Protection. Electronics 2023, 12, 4364. https://doi.org/10.3390/electronics12204364
An T, Ma L, Wang W, Yang Y, Wang J, Chen Y. Consideration of FedProx in Privacy Protection. Electronics. 2023; 12(20):4364. https://doi.org/10.3390/electronics12204364
Chicago/Turabian StyleAn, Tianbo, Leyu Ma, Wei Wang, Yunfan Yang, Jingrui Wang, and Yueren Chen. 2023. "Consideration of FedProx in Privacy Protection" Electronics 12, no. 20: 4364. https://doi.org/10.3390/electronics12204364