

Facial Emotion Recognition with Inter-Modality-Attention-Transformer-Based Self-Supervised Learning

Abstract
:1. Introduction
2. State of the Art
3. Datasets
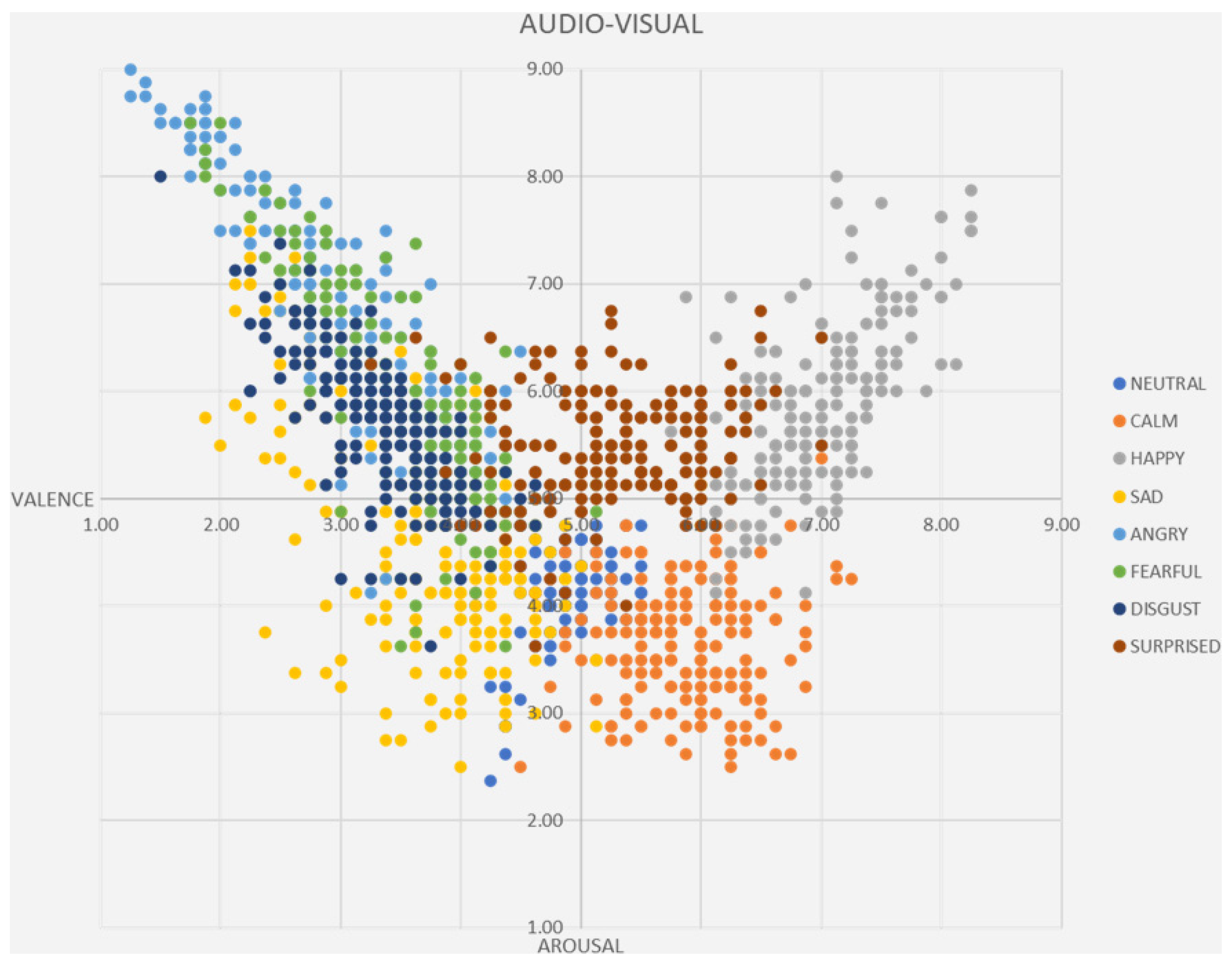
RAVDESS Audio–Visual Dataset
4. Methodology
4.1. Multimodal Feature Extraction Using SSL Models
- (1).
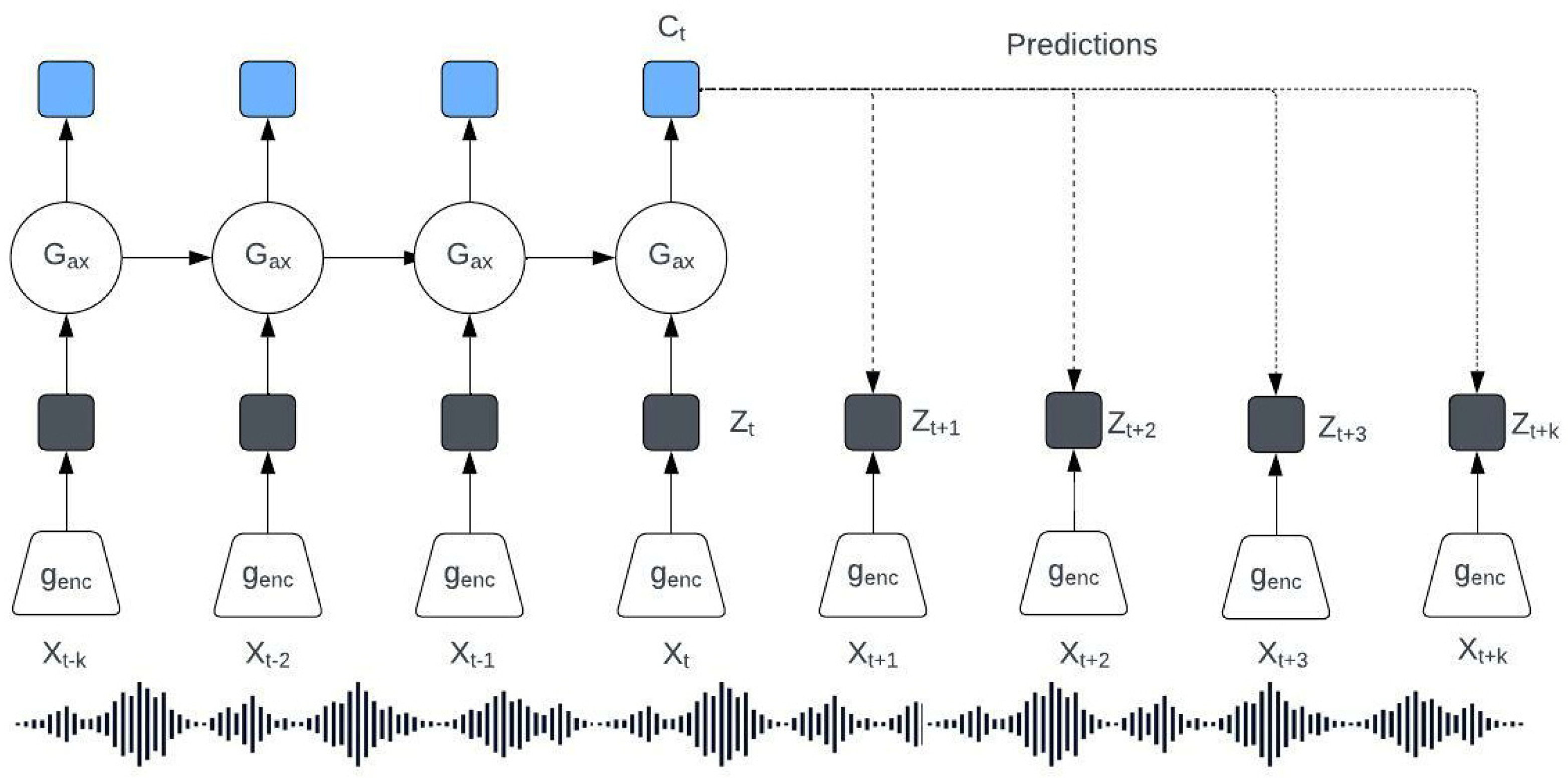
- Wav2Vec
- (2).
- Fab-Net
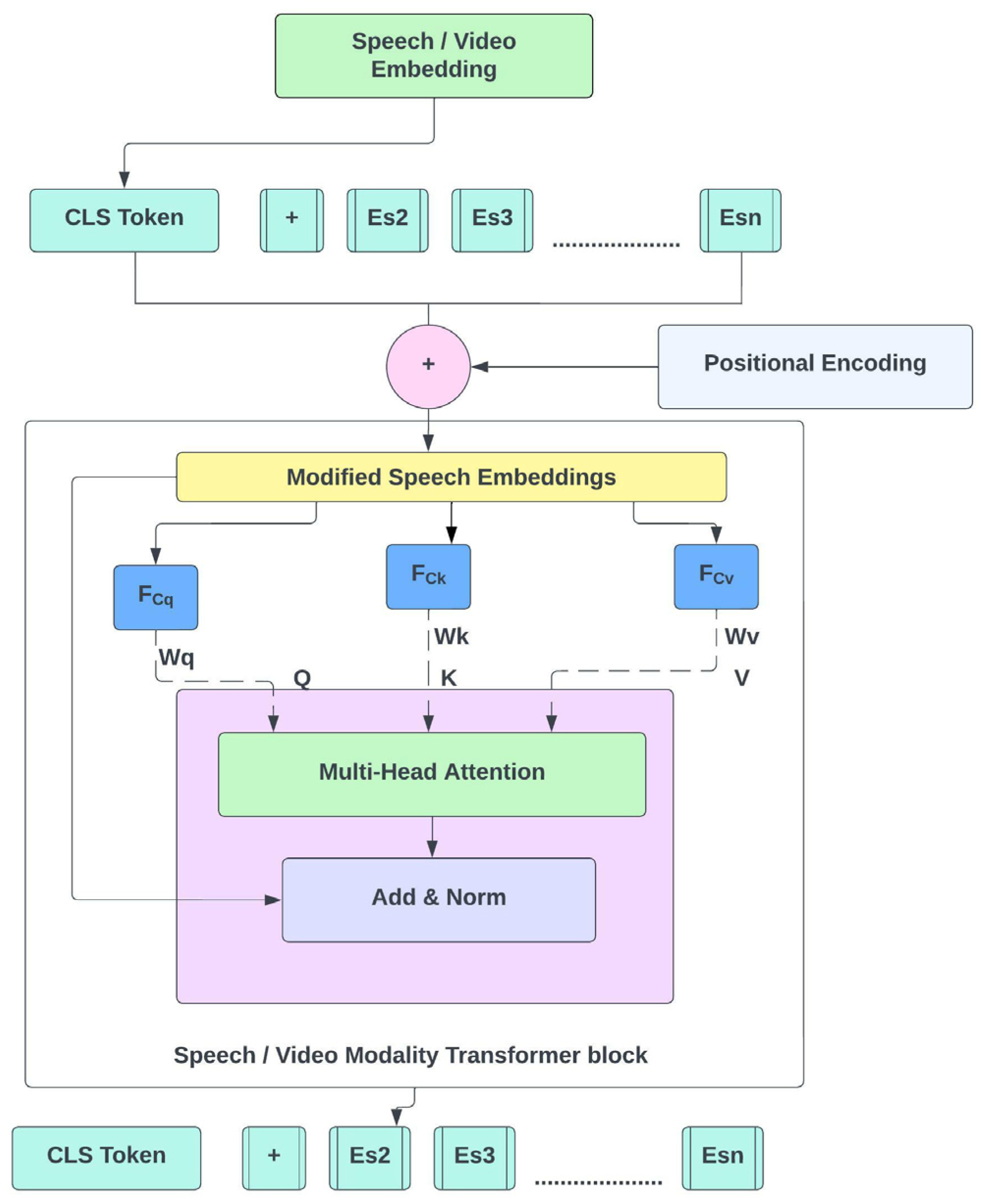
4.2. Feature Extraction Mechanism
4.3. SSL Embedding
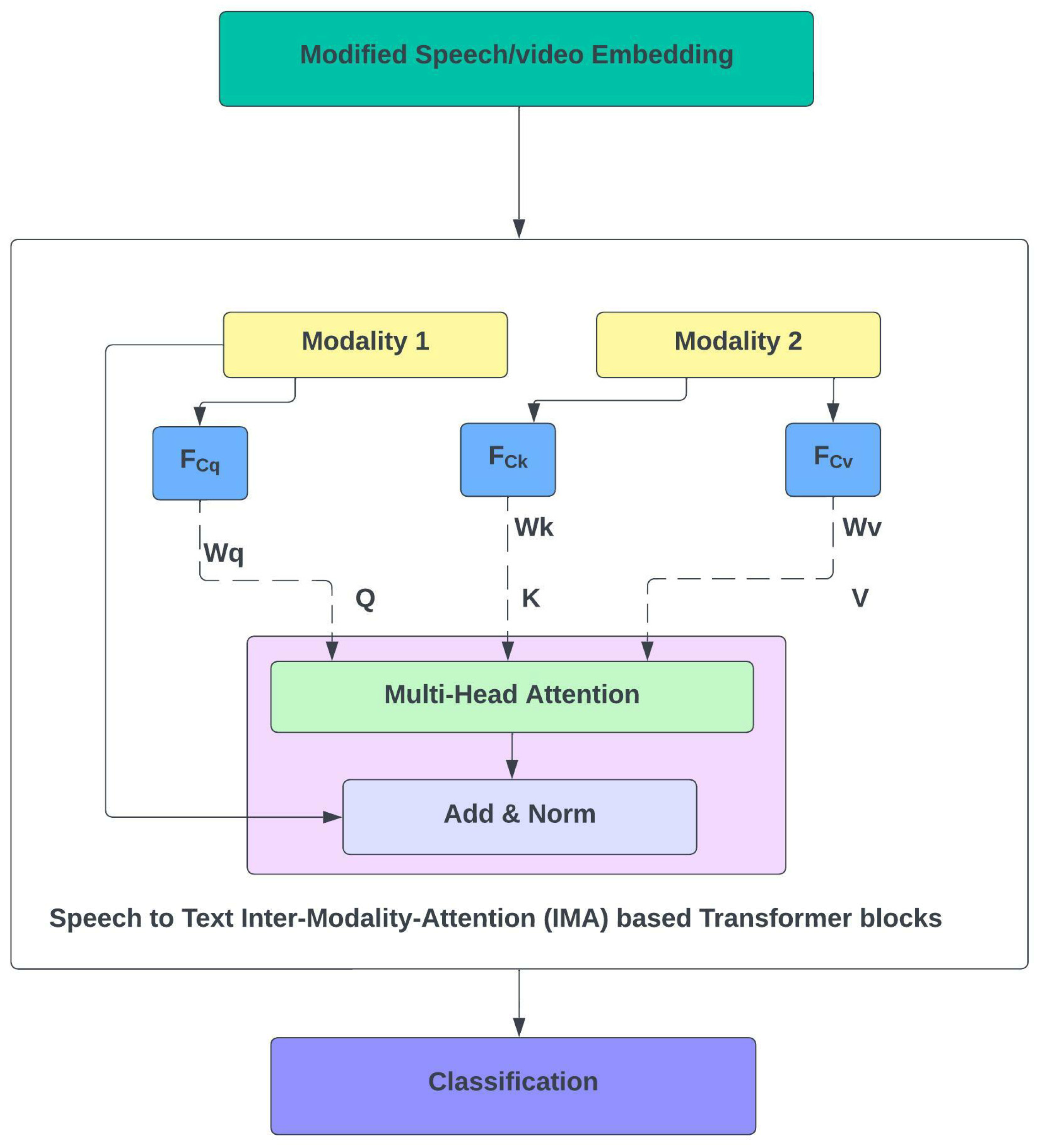
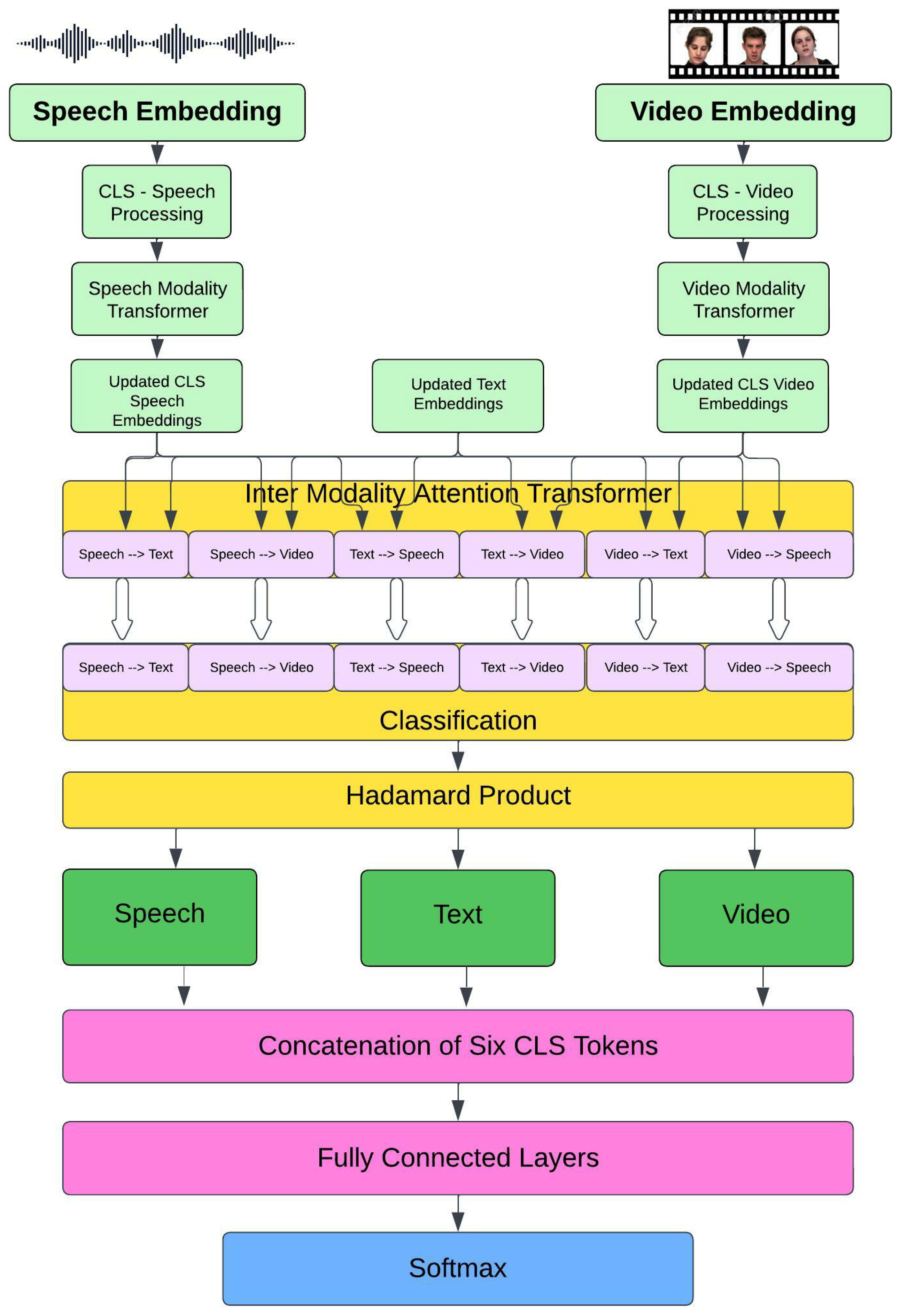
4.4. IMA-Based Fusion Layer
4.5. Hadamard Product
4.6. Synopsis of the Fusion Method
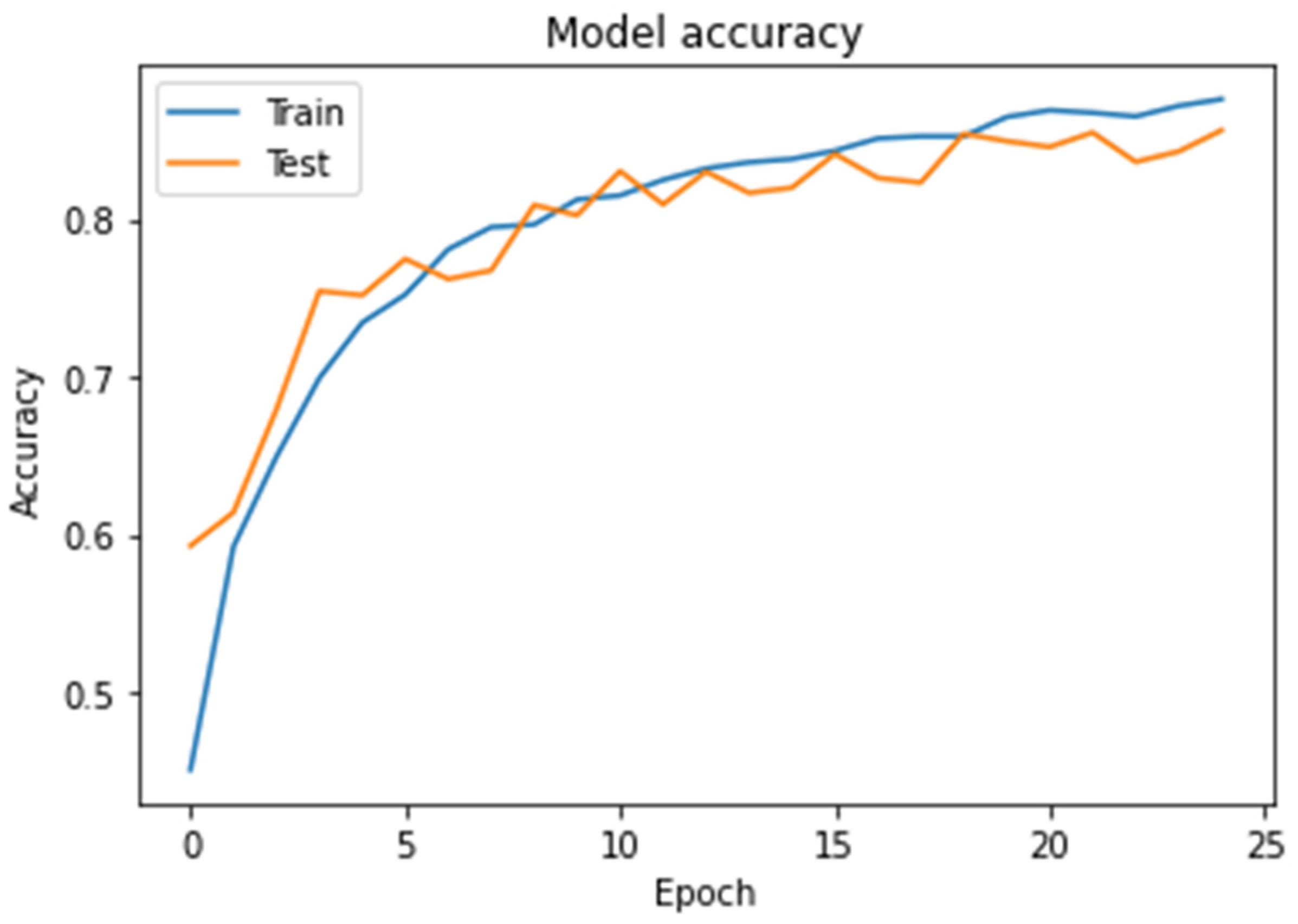
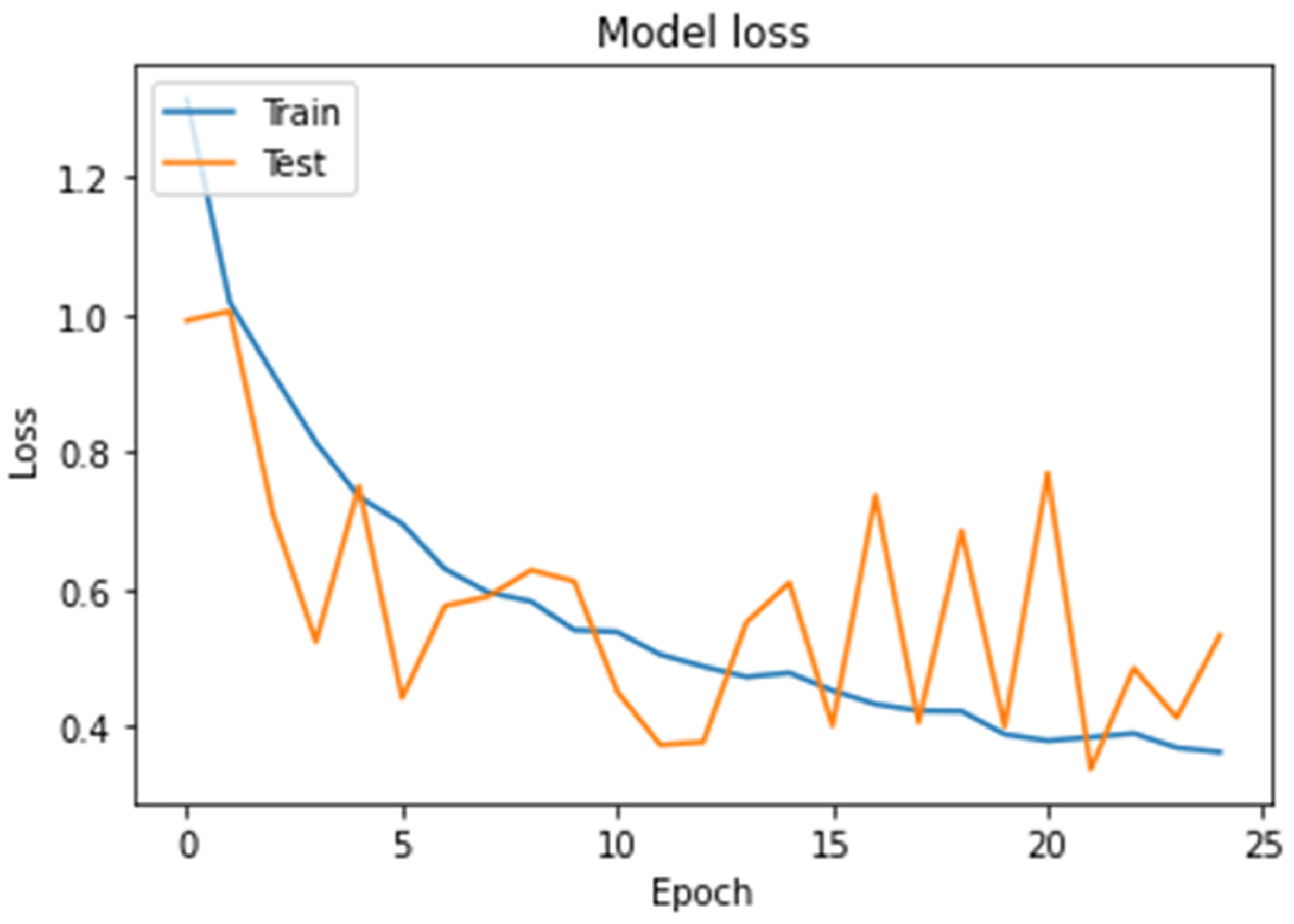
4.7. Implementation Details
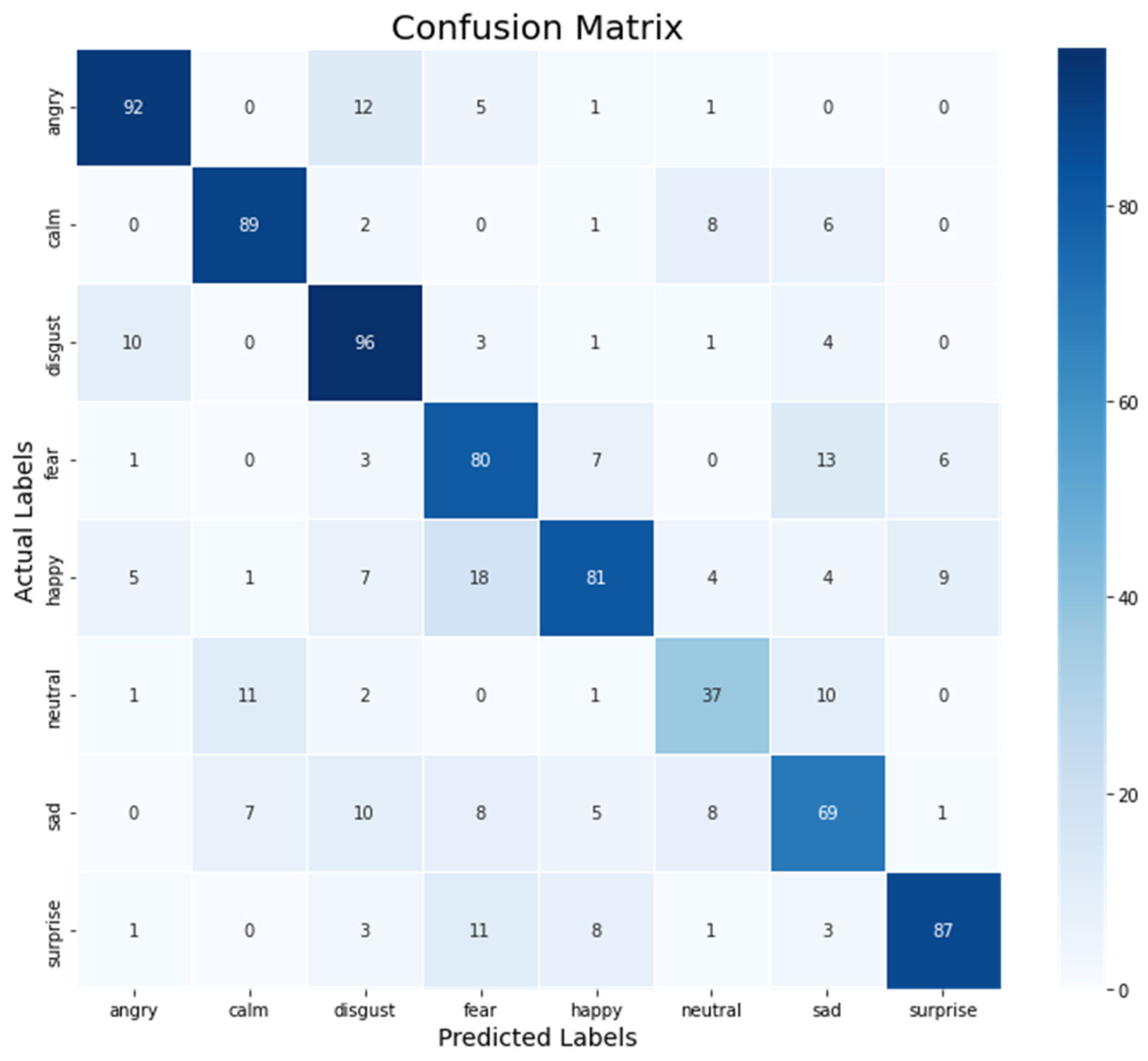
5. Results
6. Comparison with Existing Studies
- Multi-level Multi-Head Fusion Attention RNN Model [28]
- Robust Cross-modality Fusion [29]
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kansizoglou, I.; Bampis, L.; Gasteratos, A. An Active Learning Paradigm for Online Audio-Visual Emotion Recognition. IEEE Trans. Affect. Comput. 2019, 13, 756–768. [Google Scholar] [CrossRef]
- Yoon, S.; Byun, S.; Jung, K. Multimodal Speech Emotion Recognition Using Audio and Text. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018. [Google Scholar]
- Han, Z.; Zhao, H.; Wang, R. Transfer Learning for Speech Emotion Recognition. In Proceedings of the 2019 IEEE 5th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing, (HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS), Washington, DC, USA, 27–29 May 2019; pp. 96–99. [Google Scholar]
- Ezzeldin, M.; ElShaer, A.; Wisdom, S.; Mishra, T. Transfer learning from sound representations for anger detection in speech. arXiv 2019, arXiv:arXiv.1902.02120. [Google Scholar] [CrossRef]
- Nagarajan, B.; Oruganti, V.R.M. Deep net features for complex emotion recognition. arXiv 2018, arXiv:1811.00003. [Google Scholar] [CrossRef]
- Sun, Z.; Sarma, P.; Sethares, W.; Liang, Y. Learning relationships between text, audio, and video via deep canonical correlation for multimodal language analysis. arXiv 2019, arXiv:arXiv.1911.05544. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. arXiv 2019, arXiv:arXiv.1902.06162. [Google Scholar] [CrossRef]
- Wiles, O.; Koepke, A.S.; Zisserman, A. Self-supervised learning of a facial attribute embedding from video. arXiv 2018, arXiv:1808.06882. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. Wav2vec: Unsupervised pre-training for speech recognition. arXiv 2019, arXiv:arXiv.1904.05862. [Google Scholar] [CrossRef]
- Chaudhari, A.; Bhatt, C.; Krishna, A.; Mazzeo, P.L. ViTFER: Facial Emotion Recognition with Vision Transformers. Appl. Syst. Innov. 2022, 5, 80. [Google Scholar] [CrossRef]
- Levi, G.; Hassner, T. Emotion Recognition in the Wild via Convolutional Neural Networks and Mapped Binary Patterns; SC/Information Sciences Institute, the Open University of Israel: Marina del Rey, CA, USA, 2014. [Google Scholar]
- Han, K.; Yu, D.; Tashev, I. Speech Emotion Recognition Using Deep Neural Network and Extreme Learning Machine; Department of Computer Science and Engineering, The Ohio State University: Columbus, OH, USA; Microsoft Research, One Microsoft Way: Redmond, WA, USA, 2014. [Google Scholar]
- Li, S.; Deng, W. Deep facial expression recognition: A survey. IEEE Trans. Affect. Comput. 2020, 13, 1195–1215. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Chen, F.; Lv, S.; Wang, X. Facial Expression Recognition: A Survey. Symmetry 2019, 11, 1189. [Google Scholar] [CrossRef] [Green Version]
- Dhwani, M.; Siddiqui, M.F.H.; Javaid, A.Y. Facial emotion recognition: A survey and real-world user experiences in mixed reality. Sensors 2018, 18, 416. [Google Scholar]
- Ullah, S.; Tian, W. A systematic literature review of recognition of compound facial expression of emotions. In Proceedings of the ICVIP 2020: 2020 the 4th International Conference on Video and Image Processing, Xi’an, China, 25–27 December 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 116–121. [Google Scholar] [CrossRef]
- Rajan, S.; Chenniappan, P.; Devaraj, S.; Madian, N. Facial expression recognition techniques: A comprehensive survey. IET Image Process. 2019, 13, 1031–1040. [Google Scholar] [CrossRef]
- Gupta, A.; Sharma, D.; Sharma, S.; Agarwal, A. Survey paper on gender and emotion classification using facial expression detection. In Proceedings of the International Conference on Innovative Computing & Communications (ICICC) 2020, Delhi, India, 20–22 February 2020. [Google Scholar] [CrossRef]
- Jia, S.; Wang, S.; Hu, C.; Webster, P.J.; Li, X. Detection of genuine and posed facial expressions of emotion: Databases and methods. Front. Psychol. 2021, 11, 3818. [Google Scholar] [CrossRef]
- Rao, K.P.; Chandra, M.V.P.; Rao, S. Assessment of students’ comprehension using multi-modal emotion recognition in e-learning environments. J. Adv. Res. Dyn. Control Syst. 2019, 10, 767–773. [Google Scholar]
- Huddar, M.G.; Sannakki, S.S.; Rajpurohit, V.S. Multi-level context extraction and attention-based contextual inter-modal fusion for multimodal sentiment analysis and emotion classification. Int. J.Multimed. Inform. Retriev. 2020, 9, 103–112. [Google Scholar] [CrossRef]
- Liu, D.; Wang, Z.; Wang, L.; Chen, L. Multi-Modal Fusion Emotion Recognition Method of Speech Expression Based on Deep Learning. Front. Neurorobot. 2021, 15, 697634. [Google Scholar] [CrossRef]
- Elleuch, H.; Wali, A. Unwearable multi-modal gestures recognition system for interaction with mobile devices in unexpected situations. IIUM Eng. J. 2019, 20, 142–162. [Google Scholar] [CrossRef]
- Andy, C.; Kumar, S. An appraisal on speech and emotion recognition technologies based on machine learning. Int. J. Automot. Technol. 2020, 8, 2266–2276. [Google Scholar] [CrossRef]
- Engin, M.A.; Cavusoglu, B. Rotation invariant curvelet based image retrieval and classification via Gaussian mixture model and co-occurrence features. Multimed. Tools Appl. 2019, 78, 6581–6605. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, F. Improved curriculum learning using SSM for facial expression recognition. Vis. Comput. 2020, 36, 1635–1649. [Google Scholar] [CrossRef]
- Jiang, P.; Fu, H.; Tao, H.; Lei, P.; Zhao, L. Parallelized Convolutional Recurrent Neural Network with Spectral Features for Speech Emotion Recognition. IEEE Access 2019, 7, 90368–90377. [Google Scholar] [CrossRef]
- Siriwardhana, S.; Kaluarachchi, T.; Billinghurst, M.; Nanayakkara, S. Multimodal Emotion Recognition with Transformer-Based Self Supervised Feature Fusion. IEEE Access 2020, 8, 176274–176285. [Google Scholar] [CrossRef]
- Xie, B.; Sidulova, M.; Park, C.H. Robust Multimodal Emotion Recognition from Conversation with Transformer-Based Crossmodality Fusion. Sensors 2021, 21, 4913. [Google Scholar] [CrossRef]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-End Multimodal Emotion Recognition Using Deep Neural Networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar] [CrossRef] [Green Version]
- Ioannis, K.; Misirlis, E.; Tsintotas, K.; Gasteratos, A. Continuous Emotion Recognition for Long-Term Behavior Modeling through Recurrent Neural Networks. Technologies 2022, 10, 59. [Google Scholar]
- Zhang, S.; Ding, Y.; Wei, Z.; Guan, C. Continuous emotion recognition with audio-visual leader-follower attentive fusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Kansizoglou, I.; Misirlis, E.; Gasteratos, A. Learning Long-Term Behavior through Continuous Emotion Estimation. In Proceedings of the 14th PErvasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 29 June–2 July 2021. [Google Scholar]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [Green Version]
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. fairseq: A Fast, Extensible Toolkit for Sequence Modeling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations); Association for Computational Linguistics: Minneapolis, MN, USA, 2019. [Google Scholar]
- Deng, J.; Guo, J.; Zhou, Y.; Yu, J.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-stage Dense Face Localisation in the Wild. arXiv 2019, arXiv:1905.00641. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Oord, A.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar] [CrossRef]
- Chung, J.S.; Nagrani, A.; Zisserman, A. VoxCeleb2: Deep Speaker Recognition. In Proceedings of the INTERSPEECH 2018, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019. [Google Scholar]
- Wundt, W.M.; Judd, C.H. Outlines of Psychology (Vol. 1); Scholarly Press: Cambridge, MA, USA, 1897. [Google Scholar]
- Schlosberg, H. Three dimensions of emotion. Psychol. Rev. 1954, 61, 81. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Embedding Size | Max Sequence Length |
|---|---|---|
| Wav2Vec | 512 | 935 |
| Fab-Net | 256 | 300 |
| RoBERTa | 1024 | 512 |
| Emotions | Modalities | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Wav2Vec | Fab-Net | RoBERTa | Multimodal | |||||||||
| PRE | F1 | REC | PRE | F1 | REC | PRE | F1 | REC | PRE | F1 | REC | |
| Neutral | 0.84 | 0.75 | 0.85 | 0.83 | 0.77 | 0.82 | 0.86 | 0.80 | 0.86 | 86.31 | 77.33 | 70.25 |
| Calm | 0.85 | 0.80 | 0.78 | 0.87 | 0.83 | 0.79 | 0.84 | 0.82 | 0.81 | 81.45 | 81.66 | 75.63 |
| Happy | 0.88 | 0.78 | 0.71 | 0.85 | 0.80 | 0.80 | 0.87 | 0.79 | 0.77 | 89.79 | 79.10 | 79.25 |
| Sad | 0.86 | 0.79 | 0.99 | 0.84 | 0.80 | 0.93 | 0.85 | 0.75 | 0.89 | 81.22 | 78.28 | 81.88 |
| Angry | 0.82 | 0.81 | 0.99 | 0.85 | 0.88 | 0.90 | 0.83 | 0.80 | 0.80 | 81.78 | 83.00 | 82.37 |
| Fearful | 0.78 | 0.80 | 0.88 | 0.85 | 0.79 | 0.81 | 0.80 | 0.83 | 0.88 | 88.26 | 80.66 | 83.62 |
| Disgusted | 0.85 | 0.85 | 0.96 | 0.86 | 0.86 | 0.80 | 0.81 | 0.84 | 0.95 | 83.99 | 85.12 | 85.50 |
| Surprised | 0.87 | 0.89 | 0.98 | 0.82 | 0.90 | 0.91 | 0.85 | 0.86 | 0.98 | 89.50 | 88.33 | 77.87 |
| Avg Weightage | 84.37 | 80.87 | 89.25 | 84.62 | 82.87 | 84.50 | 83.87 | 81.12 | 86.75 | 85.28 | 81.68 | 79.54 |
| Experiments | Modality | Accuracy | F1-Score |
|---|---|---|---|
| Multi-level Multi-Head Fusion Attention RNN Model [28] | Multimodal (Audio + Facial + Text) | 64.3 | 63.9 |
| Robust Cross-Modality Fusion [29] | Audio | 48.4 | 32.1 |
| Facial | 47.8 | 31.4 | |
| Text | 62.6 | 61.2 | |
| Multimodal (Audio + Facial + Text) | 65.0 | 64.0 | |
| Our Proposed Approach | Multimodal (Audio + Facial + Text) | 87.6 | 81.68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chaudhari, A.; Bhatt, C.; Krishna, A.; Travieso-González, C.M. Facial Emotion Recognition with Inter-Modality-Attention-Transformer-Based Self-Supervised Learning. Electronics 2023, 12, 288. https://doi.org/10.3390/electronics12020288
Chaudhari A, Bhatt C, Krishna A, Travieso-González CM. Facial Emotion Recognition with Inter-Modality-Attention-Transformer-Based Self-Supervised Learning. Electronics. 2023; 12(2):288. https://doi.org/10.3390/electronics12020288
Chicago/Turabian StyleChaudhari, Aayushi, Chintan Bhatt, Achyut Krishna, and Carlos M. Travieso-González. 2023. "Facial Emotion Recognition with Inter-Modality-Attention-Transformer-Based Self-Supervised Learning" Electronics 12, no. 2: 288. https://doi.org/10.3390/electronics12020288